Сравнительная оценка методов мультиспектральной визуализации на основе ИИ и ПЦР-анализа для раннего выявления Botrytis cinerea на растениях перца
Производство перца является критически важным компонентом мировой сельскохозяйственной экономики, объем экспорта в 2023 году достиг впечатляющих 6,9 млрд долларов США. Это подчеркивает значение данной культуры как важного экономического драйвера экспортной выручки для стран-производителей. Botrytis cinerea, возбудитель серой гнили, оказывает значительное воздействие на такие культуры, как фрукты и овощи, включая перец. Раннее выявление этого патогена крайне важно для сокращения зависимости от фунгицидов и предотвращения экономических потерь. Традиционно основным методом обнаружения был визуальный осмотр. Однако симптомы часто появляются уже после начала распространения патогена.
Аннотация
В данном исследовании для сегментации изображений растений по одному классу с целью извлечения пространственных деталей листьев перца используется алгоритм глубокого обучения YOLO. Набор данных включал гиперспектральные изображения на дискретных длинах волн (460 нм, 540 нм, 640 нм, 775 нм и 875 нм), полученные на основе производных вегетационных индексов (CVI, GNDVI, NDVI, NPCI и PSRI), а также RGB-изображения. При пороге пересечения по объединению (IoU) 0,5 средняя точность (mAP50), достигнутая решением для сегментации листьев YOLOv11-Small, составила 86,4%.
Извлеченные сегменты листьев были обработаны несколькими моделями типа Transformer, каждая из которых формировала дескриптор. Эти дескрипторы были объединены в ансамбль и классифицированы на три отдельных класса с использованием методов k-ближайших соседей (KNN), долгой краткосрочной памяти (LSTM) и ResNet. В ансамблевый классификатор, показавший наилучший результат, вошли следующие модели Transformer: Swin-L (P:4 × 4–W:12 × 12), ViT-L (P:16 × 16), VOLO (D:5) и XCIT-L (L:24–P:16 × 16), а также классификатор на основе LSTM, работавший с наборами изображений RGB, CVI, GNDVI, NDVI и PSRI. Общая точность классификатора составила 87,42% с F1-мерой 81,13%. F1-оценки для каждого из трех классов составили 85,25%, 66,67% и 78,26% соответственно.
Кроме того, для обнаружения B. cinerea на начальной, а также латентной (покоящейся) стадиях инфекции до появления симптомов использовались количественные ПЦР-методы (RT-qPCR) для определения биомассы гриба в растительной ткани. Эти данные были интегрированы с результатами, полученными с помощью подхода на основе ИИ, что позволило предложить комплексную стратегию.
Исследование демонстрирует возможность раннего и точного выявления B. cinerea на растениях перца путем комбинации методов сегментации с дескрипторами моделей Transformer, объединенными в ансамбль для классификации. Этот подход представляет собой значительный шаг вперед в обнаружении и управлении болезнями сельскохозяйственных культур, подчеркивает потенциал применения таких методов непосредственно в полевых условиях, например, с помощью мобильных приложений или роботизированных систем.
1. Введение
Спрос на эффективные методы ведения сельского хозяйства в садоводстве и пищевой промышленности быстро растет. Успех садоводства в значительной степени зависит как от качества, так и от количества его продукции. Грибные заболевания могут поражать различные части растений, такие как стебли, листья, цветы и плоды, что приводит к снижению урожайности и общему сокращению производства сельскохозяйственных культур, что влечет за собой экономические потери. Серая гниль, вызываемая Botrytis cinerea (телеоморф Botryotinia fuckeliana), является одним из наиболее разрушительных заболеваний в мировом масштабе. Патоген поражает более 1400 видов растений, включая экономически важные культуры, такие как виноград, тепличные овощи, декоративные растения и различные фрукты [1,2]. Продолжаются усилия по разработке экологически безопасных методов борьбы, таких как РНК-интерференция, биологический контроль и индукторы устойчивости растений, но они пока не достигли эффективности фунгицидов, которые остаются основной стратегией управления. Однако успех химического контроля все чаще сталкивается с проблемой развития устойчивости к фунгицидам в популяциях B. cinerea, что приводит к снижению или полной потере эффективности контроля. Устойчивость возникла в глобальном масштабе ко всем сайт-специфичным фунгицидам из-за мутаций в генах, кодирующих сайты-мишени [3].
В настоящее время диагностика B. cinerea Pers. в основном основана на визуальной оценке симптомов заболевания, а также на выделении и идентификации патогена из инфицированных растительных тканей [4]. Этот процесс не только требует много времени и труда, но и требует опыта. Раннее выявление имеет ключевое значение для обеспечения своевременного и эффективного управления, что помогает ограничить распространение болезни, снизить потери урожая и минимизировать использование химикатов [5]. Исследование паттернов экспрессии генов патогена (профилей экспрессии) на разных стадиях является важнейшим для понимания его поведения и прогрессирования. В последнее время внедрение методов количественной полимеразной цепной реакции в реальном времени (qPCR) для обнаружения вредоносных патогенов значительно улучшило количественный анализ, сочетая чувствительность обычной ПЦР с генерацией специфического флуоресцентного сигнала только тогда, когда зонд образует стабильный гибрид с комплементарной последовательностью ампликона. Обратнотранскриптазная количественная ПЦР (RT-qPCR) высоко ценится как эталон для высокоточного, высокочувствительного и быстрого измерения экспрессии генов. RT-qPCR широко использовалась для обнаружения патогенов, включая бактерии, вирусы и грибы, в тканях растений и почве [6,7]. Метод особенно полезен для выявления латентных инфекций, где количество патогена может быть низким, и обычные методы обнаружения могут давать сбой. Количественно определяя специфичную для патогена мРНК, исследователи могут определить присутствие и активность патогенов в тканях хозяина, что является важнейшим для эффективного управления болезнями. Дополнительно, исследователи могут отслеживать динамические изменения экспрессии генов, которые происходят по мере колонизации грибами своих хозяев, адаптации к условиям окружающей среды и реакции на защитные механизмы растений, что предлагает более четкое понимание взаимодействий гриб-хозяин [8]. Эти исследования являются важнейшими для углубления наших знаний о патогенности грибов и потенциальных стратегиях контроля.
Последние достижения в области компьютерного зрения с использованием глубокого обучения (DL), все чаще доказывают свою ценность как подход для обнаружения болезней сельскохозяйственных культур [1]. В сочетании с гиперспектральной визуализацией производительность обнаружения показывает улучшение, с методами классификации, включая классификаторы на основе деревьев решений, алгоритм k-ближайших соседей (KNN), модели опорных векторов (SVM), сверточные нейронные сети (CNN) и т.д. [1]. Другим развивающимся подходом в этой области является использование ансамблевых методов, которые направлены на улучшение производительности по сравнению с одиночными моделями. Эти методы охватывают различные структурные конфигурации и вариации, что делает их динамичной областью исследований [9].
Методология Transformer изначально была предложена Vaswani и др. [10] в 2017 году для задач обработки естественного языка. Позже, в 2020 году, она также была предложена как применимая модель-решение для задач компьютерного зрения Dosovitskiy и др. [11], под названием Vision Transformer (ViT). Эта модель продемонстрировала способность превосходить ранее доминировавшие сверточные нейронные сети (CNN) при условии предоставления достаточно больших наборов данных. Конечно, у этой модели все еще были некоторые недостатки, такие как квадратичный рост вычислительной стоимости с разрешением изображения. Последующие исследования привели к другим модификациям трансформеров на основе ViT, таким как: (a) модель Swin Transformer [12], с акцентом на обработку вычислительной сложности ViT и фиксированного масштаба; (b) модель DeiT [13], с аналогичной целью и подходом, который включал использование предобученного ViT с пониженной дискретизацией; (c) модель VOLO [14], направленная на более тонкое кодирование признаков и контекста в отличие от грубого моделирования глобальных зависимостей, выполняемого ViT; (d) модель XCiT [15], которая применяет слой перекрестной ковариационной внимательности, предоставляющий линейную сложность для задачи квадратичной сложности в модели ViT; и (e) модель MaxViT [16], которая применяет линейное масштабирование по отношению к разрешению изображения, а также пытается обеспечить глобальный обзор всей сети моделью.
В недавнем исследовании Giakoumoglou и др. (2024) [17] подошли к раннему обнаружению серой гнили на растениях огурца. Они использовали пять мультиспектральных изображений для каждого снимка в сочетании с методами сегментации изображений с использованием CNN и кодировщиков ViT. Этот метод достиг общей точности 90,1% с коэффициентом Dice (DC) 67,7% при пересечении по объединению (IoU) 0,656. Впоследствии Christakakis и др. (2024) [18] сосредоточились на решении проблемы дисбаланса наборов данных путем реализации техники аугментации Cut-and-Paste, что позволило их модели достичь общей точности 92% с DC 79,2% при более высоком IoU 0,816. Дополнительно, Scarboro и др. (2021) [19] подошли к обнаружению B. cinerea на растениях салата, используя бисспектральную визуализацию в качестве основы для классификации отдельных пикселей. В лабораторных условиях их модель показала долю истинно положительных результатов 95,25%, в то время как доля ложноположительных результатов составила 9,316%. Qasrawi и др. (2021) [20] попытались обнаружить и классифицировать пять заболеваний томатов, включая B. cinerea, используя съемку на смартфон с набором данных из 3000 изображений. Использованные модели включали нейронные сети, логистическую регрессию и методы кластеризации, достигнув точности классификации 70,3%, 68,9% и 70% соответственно. Что касается классификации изображений, Lorente и др. (2021) [21] подошли к задаче, применяя стандартизированные методы извлечения дескрипторов, такие как SIFT и SURF [22]. Затем они применили классификацию Bag of Visual Words (BoVW) [23] с помощью ряда алгоритмов и, в зависимости от модели и конфигурации, достигли точности от 0,6 до 0,96. Nagasubramanian и др. (2019) [24] эффективно применили гиперспектральную визуализацию и архитектуру глубокой CNN для классификации стеблей сои, зараженных Macrophomina phaseolina, грибом, вызывающим угольную гниль, экономически важное заболевание сои во всем мире. Модель достигла точности 95,73% с F1-Score 87% для зараженного класса. Это исследование показало, что ближние инфракрасные (NIR) длины волн были наиболее важнейшими для обнаружения зараженных образцов, в то время как физиологическая значимость спектральных областей была продемонстрирована с помощью тестов с длинами волн в видимом спектре (400–700 нм) для обнаружения болезней. Аналогично, Nguyen и др. (2021) [25] объединили DL с гиперспектральной визуализацией для обеспечения раннего обнаружения вируса очистки жилок виноградной лозы (GVCV). Исследование продемонстрировало эффективность в дифференциации здоровых виноградных лоз от зараженных GVCV, даже на ранних бессимптомных стадиях. Были идентифицированы ключевые области длин волн, включая область NIR (900–940 нм) и видимый спектр (449–461 нм), как важнейшие для дифференциации. Физиологические изменения, включая снижение доступности воды в листьях и снижение содержания пигментов в листьях, влияли на картины отражательной способности и оказались неотъемлемыми для обнаружения болезней. Эти исследования подчеркивают возможность гиперспектральной визуализации обеспечить раннее обнаружение фитопатогенов и согласуются с нашим подходом к обнаружению B. cinerea.
В нашем предыдущем исследовании Kapetas и др. (2024) [26] ансамблевая классификация дескрипторов через два подхода (KNN и LSTM) была эффективно применена для классификации листьев томата для раннего обнаружения B. cinerea. Этот метод включал использование пяти гиперспектральных изображений и одного RGB-изображения для каждого снимка. Основная цель настоящего исследования — развить и улучшить предыдущую методологию. Основное внимание сместилось с растений томата на растения перца, при этом основная цель этого исследования по-прежнему остается эффективным обнаружением B. cinerea, особенно на ранних стадиях инфекции или при латентных инфекциях, когда симптомы еще не видны. Была применена комбинация молекулярных методов (RT-qPCR) для оценки накопления биомассы B. cinerea в тканях хозяина, анализа экспрессии генов, вовлеченных в адаптацию гриба, таких как взаимодействия растение-патоген и патогенность, и методов компьютерного зрения. Был захвачен набор данных изображений, состоящий из изображений листьев, охватывающих все три класса, которые необходимо различить: здоровые, невидимая-ботритис и видимая-ботритис. Каждый снимок состоял из одиннадцати изображений: пять, снятых на гиперспектральных длинах волн (460, 540, 640, 775 и 875 нм), одно в RGB и пять из производных вегетационных индексов (CVI, GNDVI, NDVI, NPCI, NPCI). По сравнению с нашим предыдущим исследованием, введение вегетационных индексов стало важным шагом к более надежному подходу к классификации. YOLO [27] был использован для сегментации и извлечения каждого листа из этих изображений. Впоследствии для каждого листа для каждого из 11 изображений каждого снимка с использованием набора моделей Transformer был сгенерирован дескриптор. Также был введен дополнительный этап предварительной обработки, который увеличивал количество изображений листьев перед извлечением дескриптора, чтобы улучшить подход нашего предыдущего исследования. Наконец, были применены три решения классификации дескрипторов: алгоритм KNN [28], модель на основе LSTM (долгая краткосрочная память) [29] и модель на основе ResNet [30], чтобы присвоить каждому листу один из трех различных классов. В качестве дальнейшего шага к улучшению производительности подхода для классификации и обеспечения надежности, множественные результаты, полученные для каждого снимка (по одному для каждого из одиннадцати изображений для каждой из моделей Transformer), были объединены в ансамбль через взвешенный алгоритм голосования. Этот метод ансамблирования эффективно сочетал множественные прогнозы классификации изображений, чтобы дать наиболее точный результат.
2. Материалы и методы
Общая блок-схема представлена на Рисунке 1, описывающая ключевые этапы предлагаемой методологии, которые подробно обсуждаются в следующих разделах.

Рисунок 1. Общий обзор предлагаемой методологии. Процесс начинается с подачи RGB-изображения, пяти гиперспектральных изображений и пяти производных индексов в модель YOLO для выполнения сегментации отдельных листьев на всех изображениях. Затем сегментированные изображения листьев обрабатываются через модели Transformer для генерации дескрипторов для каждого листа. Эти дескрипторы впоследствии классифицируются для каждого листа, каждой длины волны и каждой модели. Взвешенный ансамбль голосования интегрирует эти классификации, чтобы определить окончательный класс для каждого листа. Наконец, классификации визуализируются на исходном изображении, обеспечивая всесторонний обзор результатов. Листья классифицируются на три класса: зеленый (здоровые), синий (ботритис-невидимый) и красный (ботритис-видимый).
2.1. Биологический материал и протокол инокуляции
Биоанализы проводились в соответствии с полностью рандомизированным планом в двух контролируемых фитоклиматических камерах на территории Benaki Phytopathological Institute; в одной камере размещались растения, инокулированные B. cinerea, а в другой — растения, подвергнутые фиктивной инокуляции (неинокулированные). Обе камеры поддерживались в одинаковых условиях окружающей среды (21 ± 1 °C, 16 часов света с потоком фотосинтетических фотонов 352,81 мкмоль/с и относительной влажностью 85–90%).
B. cinerea, использованный в исследовании, был выделен из естественно зараженных растений огурца. Для приготовления суспензии конидий (105 конидий мл−1) конидии аккуратно соскабливали с поверхности 12-дневной культуры и суспендировали в стерильной дистиллированной воде (SDW) с добавлением 2% сахарозы и 0,01% Tween® 20 (Sigma-Aldrich, Сент-Луис, Миссури, США) [17].
Растения перца (Capsicum annuum L. cv. ’Soroksari’) сорта KAPTUR F1 (Plantas S.A., Thiva, Греция) были искусственно инокулированы патогеном на стадии четырех полностью развернутых листьев. В частности, второй настоящий лист инокулировали путем опрыскивания адаксиальной поверхности суспензией конидий до точки стекания [17]. Для растений с фиктивной инокуляцией тот же метод проводился с единственной разницей — пропуском инокулята B. cinerea.
2.2. Анализы in planta для оценки интенсивности заболевания и захвата изображений
Биоанализы состояли из двух наборов растений перца: шесть растений, инокулированных B. cinerea (обозначены 1–6), и три контрольных растения, получивших фиктивную инокуляцию (обозначены 1–3). Степень тяжести заболевания оценивали два раза в неделю на основе процента площади листа, показывающего видимые симптомы, и продолжали до тех пор, пока растения не достигли конца своего цикла роста. Для каждого листа степень тяжести заболевания оценивалась в течение 65 дней после инокуляции (dpi). Данные были проанализированы с использованием логит-преобразования для линеаризации прогрессирования заболевания во времени [17]. Затем была применена линейная регрессия для определения скорости прогрессирования заболевания и оценки времени начала инфекции для каждого листа.
Оценки заболевания наносились на график зависимости от времени для построения кривых прогрессирования заболевания. Площадь под кривой прогрессирования заболевания (AUDPC) рассчитывалась с использованием метода трапециевидного интегрирования [31,32]. Степень тяжести заболевания выражалась в процентах от максимально возможного AUDPC за весь период эксперимента, что называется относительным AUDPC.
Начальные и развитые симптомы B. cinerea были зафиксированы с помощью мультиспектральной визуализации. Изображения впоследствии захватывались на 1, 2, 5, 13, 20, 27, 34, 41, 48, 55 и 62 dpi и включали детальные виды отдельных листьев, а также целых растений, демонстрирующих всю их листву. Общее количество снимков, полученных от зараженных B. cinerea и фиктивно инокулированных растений, составило 413 и 372 соответственно. Для визуализации использовалась специальная камера Qcell Phenocheck, Ханья, Греция [33], захватывающая шесть изображений из видимого и NIR-спектра (пять изображений на длинах волн 460 нм, 540 нм, 640 нм, 775 нм и 875 нм и одно RGB-изображение) и генерирующая изображения производных индексов (CVI, GNDVI, NDVI, NPCI, NPCI). Захваченные изображения имели разрешение 3000 × 1900 пикселей. Пример отдельных 11 изображений, составляющих снимок инокулированного B. cinerea растения, показан на Рисунке 2.


Рисунок 2. Одиннадцать изображений, составляющих один снимок: (a) RGB, (b) 460 нм, (c) 540 нм, (d) 640 нм, (e) 775 нм, (f) 875 нм, (g) CVI, (h) GNDVI, (i) NDVI, (j) NPCI, (k) PSRI.
2.3. Биоанализы для анализов экспрессии генов и захвата изображений на ранних стадиях инфекции
Для анализов экспрессии генов биоанализы состояли из трех растений (биологические повторности) на обработку (фиктивная инокуляция и инокуляция B. cinerea) и на момент времени (1, 2 и 5 dpi). Второй настоящий лист каждого растения опрыскивали суспензией конидий, как описано ранее. В каждый момент времени листья с фиктивной и инокуляцией B. cinerea собирали с каждого растения перца, немедленно использовали для мультиспектральной визуализации, быстро замораживали в жидком азоте, измельчали и хранили при –80 °C.
Общую РНК экстрагировали с использованием набора NucleoSpin® RNA Plant and Fungi Kit (Macherey-Nagel GmbH & Co., Дюрен, Германия) в соответствии с протоколом производителя. Концентрацию и чистоту РНК оценивали с помощью спектрофотометра NanoDrop® ND-1000 (Thermo Fisher Scientific, Уилмингтон, Северная Каролина, США), а ее целостность подтверждали с помощью электрофореза в агарозном геле [31,32].
Синтез кДНК вместе с удалением любой остаточной геномной ДНК проводили с использованием набора PrimeScript™ RT Reagent Kit with gDNA Eraser for Perfect Real Time (Takara Bio Inc., Кусацу, Сига, Япония) в соответствии с протоколом производителя. Количественную ПЦР в реальном времени проводили с использованием системы StepOnePlus Real-time PCR (Applied Biosystems, Thermo Fisher Scientific, Уилмингтон, Северная Каролина, США) с SYBR green (KAPA SYBR® FAST qPCR Master Mix (2X), KAPA Biosystems (Pty) Ltd., Кейптаун, Южная Африка) в качестве флуоресцентного репортера. Каждая реакционная смесь объемом 10 мкл состояла из 5 мкл FAST qPCR Master Mix (2X), 0,2 мкл 10 мкМ каждой пары специфичных для гена праймеров, 0,2 мкл 50X ROX High и 1 мкл матрицы кДНК.
Биомассу гриба количественно определяли путем оценки относительной экспрессии референтного гена B. cinerea BcRPL5 (Bcin01g09620) [34]. Также оценивали относительную экспрессию двух связанных с защитой генов перца, Pathogenesis-related protein 1 (PR1) и Defensin 1, связанных с салициловой кислотой (SA) и жасмоновой кислотой (JA) путями в перце соответственно, как в образцах, инокулированных патогеном, так и в фиктивно инокулированных образцах [35]. В качестве внутреннего референса использовали Ubiquitin-conjugating protein CaUbi3 (номер доступа: AY486137.1) [36]. Относительный уровень экспрессии выбранных генов рассчитывали с помощью метода 2−ΔΔCT [32]. Последовательности всех праймеров, использованных в этом исследовании, приведены в Дополнительной таблице S1. Все реакции проводили в двух повторностях. Дополнительно проводили анализ кривых плавления, чтобы подтвердить отсутствие неспецифичных продуктов и димеров праймеров.
2.4. Аннотирование изображений и методы сегментации
Roboflow [37] использовался для аннотирования 785 снимков для полигонального выделения области каждого листа на изображениях. В соответствии с развитием заболевания B. cinerea каждому листу присваивался класс. Листья с 0,1–5% зараженной площади листа были помечены как «ботритис-невидимый», а листья с 5–100% зараженной площади листа были классифицированы как «ботритис-видимый». Все остальные листья были помечены как «здоровые». Для простоты и удобства ссылки классы были переименованы следующим образом: «здоровые» листья как «Класс 0», «ботритис-невидимый» как «Класс 1» и «ботритис-зараженный» как «Класс 2». Изображение истинной маски аннотаций, наложенной на RGB-изображение, показано на Рисунке 3.

Рисунок 3. RGB-изображение с наложенными истинными аннотациями. Листья классифицируются на три класса: зеленый (здоровые), синий (ботритис-невидимый) и красный (ботритис-видимый).
Сегментация изображений — это процесс идентификации и разделения отдельных областей на изображении, где каждый сегмент представляет определенный объект или область интереса [38]. В этом исследовании сегментация выполнялась с использованием модели DL, основанной на архитектуре YOLO.
Эта модель способна распознавать признаки изображения, изучая обобщенные представления объектов из наборов данных изображений. Чтобы достичь баланса между точностью и скоростью вывода, была выбрана предварительно обученная модель YOLO-Small из библиотеки Ultralitics [39] и дообучена. Процесс дообучения включал обучение моделей архитектур YOLOv8 и YOLOv11 в течение 100 эпох с использованием оптимизатора SGD со скоростью обучения 0,01. Дообученные модели тестировались при разрешениях 1024 × 1024 и 1600 × 1600, с размерами пакетов 4 и 8.
2.5. Обработка данных и методы аугментации
В этом исследовании к классификации листьев подошли путем изоляции каждого листа на его собственном отдельном новом изображении, учитывая, что каждое исходное изображение показывает более одного листа. Область на изображении, не занятая этим одним листом, была полностью прозрачной (набор данных-а). Для обеспечения совместимости с моделями Transformer, описанными в Разделе 2.6, отдельные изображения листьев изменяли до единого размера 384 × 384 пикселя. Уменьшение дискретизации с исходного разрешения 3200 × 1900 пикселей до разрешения 384 × 384 пикселя привело к серьезной потере информации для отдельного листа, особенно для листьев, занимающих небольшую часть исходного изображения. Дополнительно, результирующие изображения содержали большое количество прозрачных пикселей, которые по сути не предоставляли почти никакой информации. Чтобы решить эти проблемы, были применены две техники масштабирования. Первый метод эффективно представляет собой четырехкратное увеличение (набор данных-b), которое достигается путем обрезки каждого изображения листа до половины его исходной ширины и высоты перед изменением размера. Этот подход был направлен на сохранение более мелких деталей, обеспечивая при этом, чтобы даже самые большие листья набора данных были все еще полностью видны на изображениях. Второй метод (набор данных-c) был сосредоточен на обрезке изображений близко вокруг области ограничивающей рамки каждого листа, что максимизировало сохраненную информацию пикселей листа в конечном изображении, но, поскольку каждый лист полностью занимал доступное пространство изображения, весь контекст размера листа был потерян. Рисунок 4 иллюстрирует, как наборы данных -a, -b и -c были получены из исходных изображений.
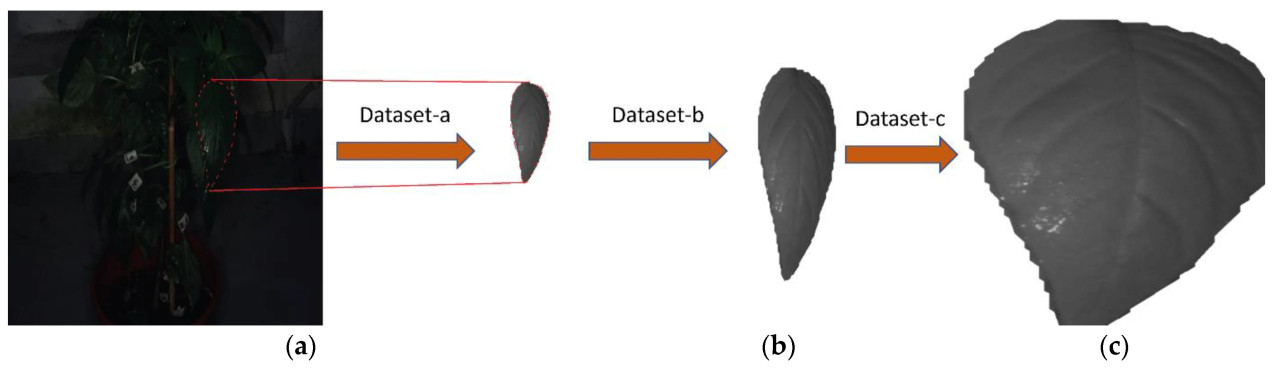
Рисунок 4. Изображение примера изображения листа из наборов данных (a): извлеченного непосредственно из исходного изображения; (b): с четырехкратным увеличением; (c): с обрезкой вокруг области листа. Дополнительно, (a) изображает, как изображение листа было извлечено из исходного изображения визуальным образом.
Результирующий набор данных после извлечения изображений отдельных листов содержал 107 481 изображение в классе «здоровые», 473 в классе «ботритис-невидимый» и 1309 в классе «ботритис-видимый». Этот набор данных включал одиннадцать изображений на снимок (пять из гиперспектральных длин волн, одно RGB-изображение и пять из производных индексов) и включал только листья, занимающие минимум 0,2% площади изображения, поскольку более мелкие листья предоставляли недостаточное количество пикселей для содержания значимой информации для анализа моделями.
Поскольку подход классификации (описанный в Разделе 2.7) требовал относительно сбалансированного количества изображений в каждом классе, непропорционально большое количество изображений класса «здоровые» было сокращено. Во время этого сокращения ключевым моментом было то, что хотя бы один снимок с каждого дня эксперимента оставался в классе «здоровые», сохраняя все одиннадцать изображений на снимок. После сокращения класс «здоровые» содержал 1507 изображений, в то время как два других класса остались неизменными.
Для дальнейшего улучшения производительности модели была применена дополнительная предварительная обработка. В частности, перед сокращением класса «здоровые» была выполнена аугментация данных для расширения классов «ботритис-невидимый» и «ботритис-видимый» путем увеличения количества их изображений. Эта аугментация включала случайное масштабирование и вращение отдельных листьев для создания реалистичных вариаций, в то время как другие распространенные аугментации, такие как размытие, яркость, экспозиция или другие модификации, основанные на цвете, были отклонены, поскольку они могли бы подорвать цель использования отдельных длин волн, где окраска является важной частью информации. Коэффициенты аугментации 3,7 и 2 были применены к классу «ботритис-невидимый» и классу «ботритис-видимый» соответственно. Хотя эти коэффициенты могут показаться высокими, они были необходимы из-за низкого исходного количества изображений, особенно в классе «ботритис-невидимый», в котором было всего 43 отдельных снимка. Затем, применив соответствующее сокращение к изображениям класса «здоровые», как описано ранее, окончательное количество изображений в наборе данных составило 2882, 1749 и 2575 изображений для каждого из классов.
Наконец, набор данных был разделен на обучающую и тестовую подгруппы, что привело к 1133, 352 и 1023 обучающим изображениям и 374, 121 и 286 тестовым изображениям для каждого класса соответственно, для исходного набора данных с сокращенными изображениями «здоровые», в то время как для набора данных, где была применена аугментация данных, разделение привело к 2266, 1320 и 1957 обучающим изображениям и 616, 143 и 407 тестовым изображениям. Ключевым критерием в процессе разделения было то, что хотя бы один снимок для каждого дня и для каждого класса был включен как в обучающий, так и в тестовый набор, причем все 11 изображений на снимок должны были быть назначены вместе либо в один, либо в другой набор.
2.6. Модели Transformer для извлечения дескрипторов
Слой модели машинного обучения выдает дескриптор в качестве выходных данных, который представляет собой вектор, сформированный для характеристики входных данных, которые в данном случае являются изображением, в то время как глобальный дескриптор — это выходной сигнал последнего слоя перед выходным слоем модели [40]. В этом исследовании использовался ряд из 9 моделей Transformer для извлечения 9 глобальных дескрипторов для каждого из одиннадцати изображений каждого снимка. Более конкретно, использовались модели библиотеки timm [41], которые предварительно обучены на ImageNet-1K [42]. Девять моделей трансформеров были следующими: ViT-L (P:16 × 16), ViT-L (P:32 × 32), ViT-B (P:16 × 16–C), ViT-B (P:32 × 32–C), Swin-L (P:4 × 4–W:12 × 12), VOLO (D:5), XCIT-L (L:24–P16 × 16), DEIT-L (P16 × 16) и MaxViT-L.
2.7. Методы классификации
В Разделе 2.6 описано, что для изображений, относящихся к отдельным листьям, на основе каждого изображения извлекался разный дескриптор. Поскольку для каждого изображения листа было 11 дескрипторов, 11 действий классификации выполнялись независимо. Для классификации этих извлеченных дескрипторов были применены три разных подхода.
Классификация KNN была первым выбранным подходом. В этом методе для каждого из одиннадцати изображений, формирующих снимок, создавался отдельный BoVW. Каждый BoVW служил библиотекой визуальных признаков для всех дескрипторов из обучающего набора. Затем для классификации дескрипторов в тестовом наборе, используя метрику расстояния, каждый дескриптор последовательно сравнивался со всеми элементами в соответствующем BoVW для той же длины волны. Полученные расстояния перечислялись, и классификация достигалась усреднением K наименьших расстояний. В этом исследовании использовались три разные метрики расстояния: Евклидово, Брея-Кертиса и Косинусное.
Второй метод включал модель LSTM, построенную с использованием Keras [43]. В этой конфигурации сеть LSTM обучалась на дескрипторах для захвата значимых признаков, с использованием слоя LSTM, слоя пакетной нормализации, а затем еще одного слоя LSTM. Плотный слой с линейной функцией активации отображал выходной сигнал на соответствующую метку изображения. Модель LSTM обучалась на дескрипторах, извлеченных из одной из моделей Transformer для всех обучающих изображений для каждой длины волны, и отдельные модели LSTM обучались для каждой модели Transformer. Это привело к созданию в общей сложности 9 моделей LSTM, по одной для каждой из моделей Transformer. Скорость обучения моделей изначально была установлена на 0,001, с планировщиком скорости обучения. Обучение охватывало 12 эпох для каждой длины волны, а размер пакета был установлен на 128.
Третьим решением было использование архитектуры ResNet, разработанной также с помощью Keras. Модель ResNet состояла из нескольких остаточных блоков, каждый из которых был настроен со слоями Conv1D, пакетной нормализацией и функциями активации ReLU для уточнения процесса извлечения признаков. Каждый остаточный блок включал пропускное соединение для смягчения проблемы исчезающего градиента, позволяя градиентам течь более эффективно во время обратного распространения. Модель начиналась с начального слоя Conv1D с 512 фильтрами и размером ядра 3, за которым следовала последовательность остаточных блоков с различными размерами фильтров и шагами для захвата иерархических признаков. Между блоками были интегрированы слои Dropout для улучшения обобщения и снижения переобучения. Представления признаков затем сжимались с использованием глобального среднего пулинга, а окончательный плотный слой с функцией активации softmax отображал эти признаки на 3 метки классов. Аналогично моделям LSTM, отдельная модель ResNet обучалась для каждого набора дескрипторов, поступающих от каждой из 9 моделей Transformer, при этом каждая модель ResNet обучалась на дескрипторах из всех 11 изображений на снимок. Опять же, как и в подходе LSTM, начальная скорость обучения была инициализирована на уровне 0,001 с планировщиком скорости обучения. Модель обучалась в течение 12 эпох для каждой длины волны.
Чтобы решить проблему дисбаланса классов из-за разного количества изображений в каждом классе, использовался мультипликатор достоверности для каждого класса (PCCM). PCCM рассчитывался путем взятия обратной величины количества изображений в каждом классе и умножения ее на количество изображений в классе с наибольшим количеством изображений. Уравнение (1) иллюстрирует расчет PCCM, в то время как Таблица 1 предоставляет результирующие значения PCCM.
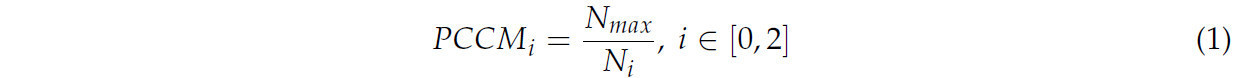
где 𝑁𝑖 представляет количество обучающих изображений в классе 𝑖, а 𝑁𝑚𝑎𝑥 представляет количество обучающих изображений в классе с наибольшим количеством изображений.

Таблица 1. Мультипликатор достоверности для каждого класса.
2.8. Метрики оценки
Для оценки результатов подходов классификации, использованных в этом исследовании, которые дифференцировали изображения на три класса, важное замечание состоит в том, что результаты классифицировали каждое изображение в один и только один класс. Метрики, которые были получены из этих результатов, — это истинно положительные (TP), ложноположительные (FP), истинно отрицательные (TN) и ложноотрицательные (FN).
Были рассчитаны метрики производительности для моделей — точность, прецизионность, полнота и F1-Score [44]. Формулы для этих метрик следующие:

Метрики TP, FP, TN и FN были рассчитаны для каждого дескриптора в тестовом наборе для всех трех подходов классификации (KNN, LSTM, ResNet) путем сравнения прогнозов с истинным классом. Производные метрики производительности рассчитывались на всех уровнях абстракции, включая на уровне каждого класса для каждого дня, на уровне каждого класса для всех дней и на уровне каждого дня для всех классов.
2.9. Ансамбль классификации
Как описано в Разделе 2.6, каждое из 11 изображений снимка имело свой собственный дескриптор для каждой из 9 моделей Transformer. Во время классификации для каждого дескриптора из одного снимка делался разный прогноз. Однако окончательный результат должен быть одним и только одним прогнозом для класса каждого снимка. Поэтому был необходим метод для консолидации этих множественных прогнозов в один окончательный результат. Этот метод должен предлагать более высокую производительность классификации по сравнению с любым отдельным набором дескрипторов из одного набора изображений и модели Transformer.
Для достижения этого использовался ансамблевый подход, агрегирующий множественные прогнозы, относящиеся к каждому снимку, и производящий окончательный результат. Расчеты для ансамбля хранились отдельно для множественных длин волн и комбинаций моделей. Эта структура позволила возможность расчета результатов ансамбля множественных вычислений ансамбля для получения окончательного результата.
Для расчета результата ансамбля множественных прогнозов использовалась формула в Уравнении (2) для определения достоверности каждого класса как взвешенной суммы прогнозов для этого класса, где каждый прогноз умножался на F1-score этого класса для этого набора изображений (из 11) соответствующего набора дескрипторов (из 9). Затем класс с наибольшей достоверностью среди трех объявлялся выбранным вариантом. Чтобы определить, какая комбинация наборов дескрипторов и наборов изображений дала лучшие окончательные результаты прогнозирования, этот процесс итеративно применялся ко всем комбинациям 9 наборов дескрипторов, что означает, что не все наборы требовались для достижения лучшего результата, и метод также применялся через множество комбинаций мульти-наборов изображений.
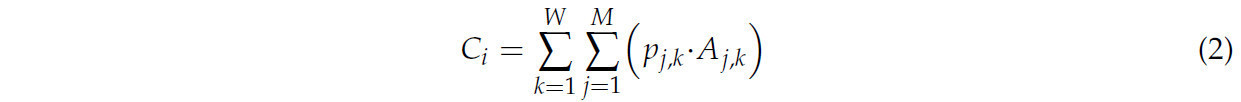
где 𝐶𝑖 соответствует баллу достоверности для класса 𝑖 по всем моделям и длинам волн, 𝑝𝑗,𝑘 указывает, соответствует ли прогноз модели 𝑗 для длины волны 𝑘 классу 𝑖 (1, если да, 0 в противном случае), 𝐴𝑗,𝑘 относится к F1-Score модели 𝑗 для длины волны 𝑘, 𝑀 представляет общее количество моделей, а 𝑊 представляет общее количество изображений на снимок, которые используются.
3. Результаты и обсуждения
3.1. Оценка тяжести серой гнили на растениях перца
Степень тяжести заболевания оценивалась как процент площади листа, показывающей симптомы серой гнили, от общей площади листа для каждого листа всех девяти листьев на растение перца, и периодически регистрировалась в течение 65 dpi. Прогресс заболевания отслеживался с интервалами от 3 до 5 дней.
Что касается второго искусственно инокулированного листа, симптомы заболевания наблюдались только у двух из шести растений перца, использованных в биоанализе, на 9 и 16 dpi, в то время как прогрессирование заболевания регистрировалось только у одного из них (растение №4) (Рисунок 5). Другие инокулированные листья были естественно заражены позже, за исключением одного листа, который оставался незараженным (Рисунок 5).

Рисунок 5. Степень тяжести заболевания (% площади листа, показывающей симптомы серой гнили), зарегистрированная в течение периода 65 dpi на 2-м искусственно инокулированном листе шести растений.
Степень тяжести заболевания в листьях перца прогрессировала с медленной скоростью, при этом AUDPC достиг 17% для второго искусственно инокулированного листа. Дополнительно, остальные листья, которые были естественно и случайно заражены B. cinerea, показали значения AUDPC в диапазоне от 4% до 13% (Рисунок 6). Напротив, цветы и плоды были более восприимчивы к патогену, демонстрируя серьезные симптомы, такие как гниль, с их тканями, покрытыми плотными серыми массами конидий и мицелия (Рисунок 7D,E). Покоящиеся инфекции в бессимптомных листьях являются важнейшими, поскольку они могут перейти в агрессивное состояние по мере старения листьев и вступления в сенисценцию [45].
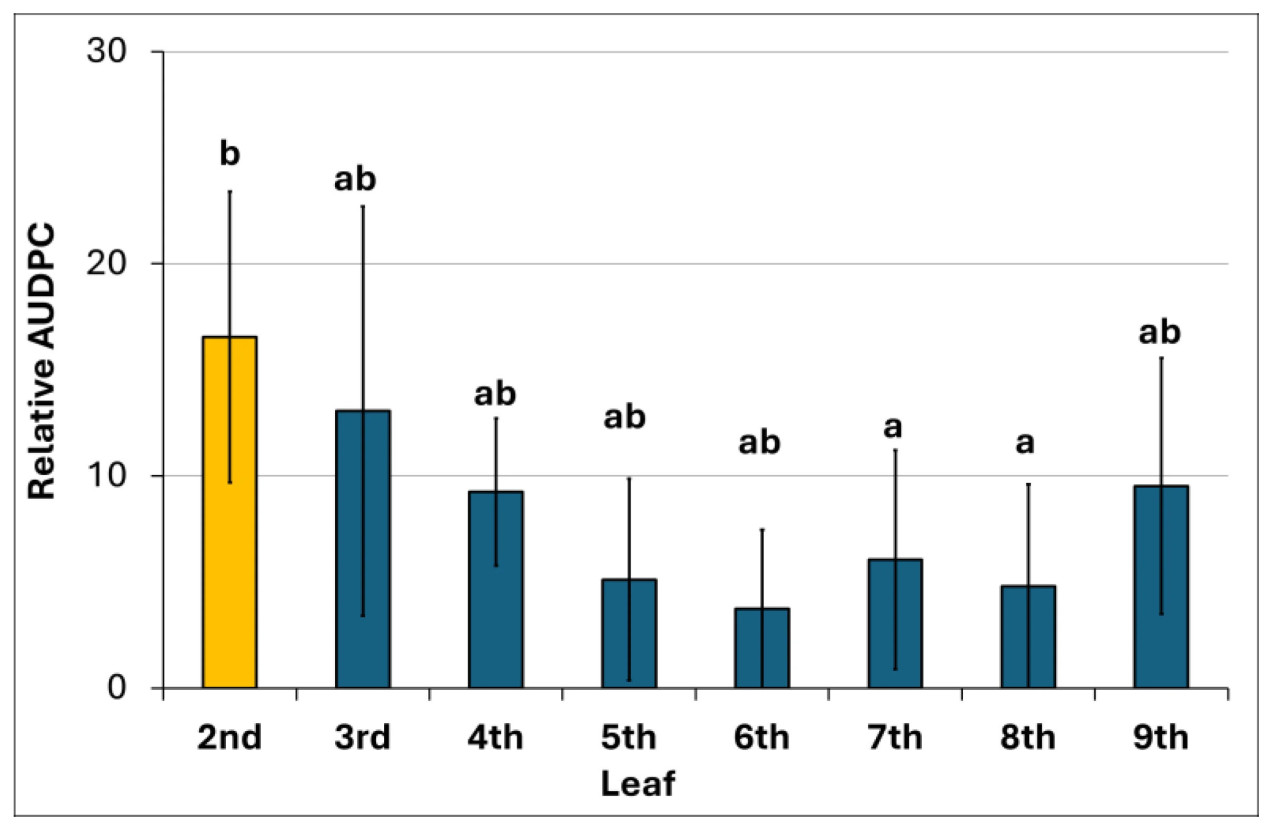
Рисунок 6. Степень тяжести заболевания, выраженная в процентах от максимально возможной площади под кривой прогрессирования заболевания (AUDPC) за весь период эксперимента (65 dpi) на 2-м искусственно инокулированном листе (желтый столбец) и на 3-м и вплоть до 9-го естественно и случайно зараженных листьях (синие столбцы) шести растений, использованных в биоанализе. Столбцы указывают стандартное отклонение. Столбцы с одинаковой буквой не различаются согласно множественному тесту Фишера LSD (p ≤ 0,05).

Рисунок 7. Симптомы серой гнили: (A) Ранняя и (B,C) поздняя стадии заражения листа. (D,E) Заражение цветка и плода.
Прогрессирование заболевания находилось под влиянием сочетания факторов, таких как стадия развития листа, пространственное расположение на стеблях, питательный состав ткани листа, защитные механизмы растений против вторгающегося патогена и вторичные циклы заболевания, инициированные воздушно-капельными конидиями B. cinerea, выделяемыми не только из начальных грибных инфекций на искусственно инокулированных тканях листьев, но также из других, более восприимчивых растительных тканей, таких как цветы и плоды (Рисунок 7). Патоген наиболее разрушителен на зрелых или сенисцентных тканях хозяина, но когда он вторгается в эти ткани на более ранней стадии развития культуры, он остается в покое в течение длительных периодов и становится активным, как только условия окружающей среды становятся благоприятными, и физиология хозяина меняется [46]. Возникновение латентности или покоящихся инфекций представляет важный компонент цикла заболевания и осложняет усилия по управлению болезнями.
3.2. Ответ перца на инфекцию Botrytis cinerea
Из-за сложности визуального обнаружения симптомов серой гнили на начальных стадиях инфекции, прогрессирование гриба оценивали по относительной экспрессии грибного референтного гена BcRPL5 (Bcin01g09620). В частности, биомасса B. cinerea в растительных тканях фиктивно и инокулированных B. cinerea вторых листьев перца количественно определялась через относительную транскрипционную обильность BcRPL5 с помощью RT-qPCR. Результаты показали, что инокулированные листья демонстрировали значительное увеличение грибной биомассы в своих тканях по сравнению с фиктивно инокулированными во все моменты времени (1, 2 и 5 dpi) (Рисунок 8). Относительные уровни транскриптов гена BcRPL5 значительно увеличивались день ото дня, достигая самых высоких уровней на 5 dpi (Рисунок 8). Это постепенное увеличение относительных уровней транскриптов грибного референтного гена указывает на то, что B. cinerea активно экспрессировал свои гены с течением времени, отражая рост и патогенность патогена, особенно на ранних стадиях инфекции, когда видимые симптомы отсутствовали.

Рисунок 8. Относительная обильность гриба Botrytis cinerea, определенная с помощью анализа RT-qPCR грибного референтного гена BcRPL5 (Bcin01g09620) в фиктивно и инокулированных Botrytis cinerea вторых листьях перца на 1, 2 и 5 dpi. Столбцы представляют средние значения трех независимых образцов листьев на обработку (фиктивная инокуляция и инокуляция B. cinerea). Столбцы с разными буквами статистически различаются согласно множественному тесту Фишера LSD (p ≤ 0,05).
Дополнительно, мы провели анализы экспрессии связанных с защитой генов Capsicum annuum, чтобы понять ответы хозяев на инфекцию B. cinerea. В частности, были выполнены анализы количественной RT-PCR для исследования относительной экспрессии зависимого от жасмоновой кислоты гена DEF1, кодирующего белок дефензин 1 Capsicum annuum, и зависимого от SA гена PR1, кодирующего белок 1, связанный с патогенезом, Capsicum annuum [47]. При грибной инфекции экспрессия DEF1 была подавлена в инокулированных B. cinerea листьях по сравнению с фиктивно инокулированными на 2 и 5 dpi (Рисунок 9, левая диаграмма). Напротив, PR1 был сверхэкспрессирован в инокулированных листьях на 5 dpi (Рисунок 9, правая диаграмма). Подавление DEF1, маркера, связанного с путем передачи сигналов JA, свидетельствует о том, что защитные ответы, опосредованные JA, были подавлены в ответ на инфекцию B. cinerea. Это может указывать на стратегию патогена по уклонению от защитных механизмов растения, которые обычно эффективны против некротрофных патогенов. Сверхэкспрессия PR1, отличительная черта пути передачи сигналов SA, подчеркивает сдвиг в защитной стратегии растения. Это указывает на то, что, хотя защитные механизмы, опосредованные JA, могут быть скомпрометированы, путь SA активируется для борьбы с грибной инфекцией, предполагая сложное взаимодействие между этими двумя путями. Противоположная регуляция DEF1 и PR1 подтверждает идею антагонистических взаимодействий между путями передачи сигналов SA и JA. Хотя JA обычно ассоциируется с защитой от травоядных и некротрофных патогенов, таких как B. cinerea [48,49], активация пути SA указывает на локализованный иммунный ответ на грибную инфекцию. Наблюдаемые изменения в экспрессии генов в разные моменты времени (2 и 5 dpi) предполагают, что защитный ответ растения динамичен. Первоначальное подавление DEF1 может быть выгодно патогену, но по мере прогрессирования инфекции активация PR1 указывает на надежную активацию пути SA для управления растущей угрозой, создаваемой патогеном.
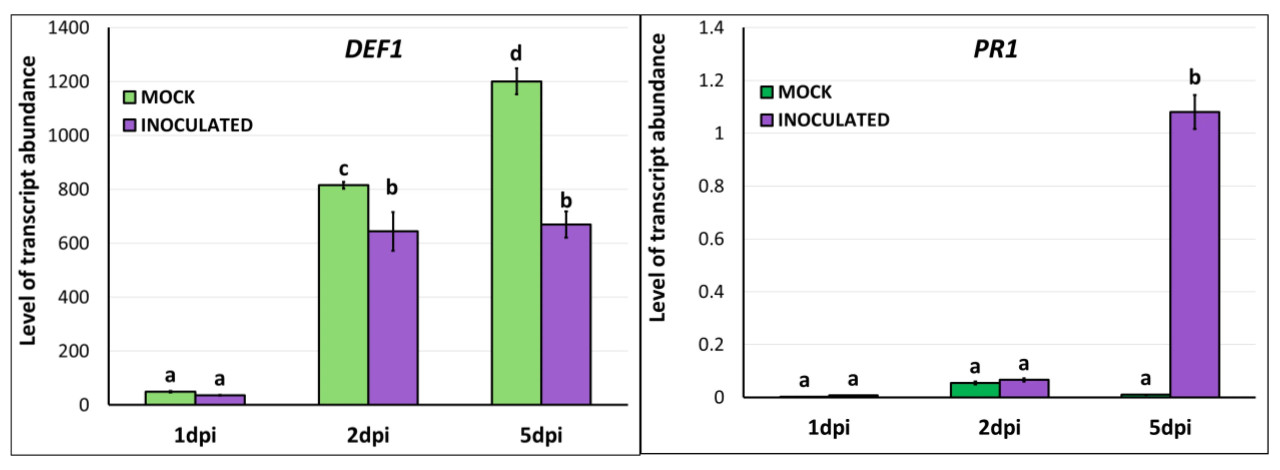
Рисунок 9. Относительная экспрессия чувствительных к заболеваниям генов перца DEF1 (Дефензин 1) и PR1 (Белок 1, связанный с патогенезом) в фиктивно и инокулированных Botrytis cinerea вторых листьях перца на 1, 2 и 5 dpi с помощью RT-qPCR. Столбцы представляют средние значения трех независимых образцов листьев на обработку (фиктивная инокуляция и инокуляция B. cinerea). Столбцы указывают стандартное отклонение, и столбцы с одинаковой буквой не различаются согласно множественному тесту Фишера LSD (p ≤ 0,05).
Эти временные изменения в экспрессии генов подчеркивают динамический защитный механизм, при котором хозяин корректирует свою стратегию на основе прогрессирования патогена. Таким образом, наблюдаемые вариации в биомассе B. cinerea в тканях перца и ответы хозяев на атаку патогена согласуются с наблюдаемыми паттернами прогрессирования заболевания, иллюстрируя сложность взаимодействий растение-патоген.
3.3. Оценка производительности сегментации
Из обученных моделей YOLO-Small лучшей оказалась YOLOv11-Small, обученная с разрешением 1600 × 1600 пикселей и размером пакета, установленным на четыре, достигнув 86,4% mAP50. Таблица 2 представляет метрики результатов для обученных моделей. Также Рисунок 10 предоставляет визуализированные примеры сегментации листьев в действии.

Рисунок 10. (a) RGB-изображения, захваченные камерой, и (b) соответствующие прогнозы YOLO, визуализированные красным цветом.

Таблица 2. Метрики производительности (mAP50, полнота и прецизионность) для моделей YOLO.
3.4. Оценка производительности классификации
Все три метода классификации (KNN, LSTM и ResNet) были применены ко всем трем наборам данных (исходный набор данных-а, 4× увеличенный набор данных-b и набор данных-c с увеличением листа), и все дескрипторы из всех девяти моделей Transformer были классифицированы. Впоследствии была выполнена ансамблевая классификация одиннадцати отдельных дескрипторов для каждого снимка. Метрики оценки включали точность, прецизионность, полноту и F1-Score. F1-Score был выбран в качестве решающей метрики для оценки производительности модели, поскольку он обеспечивает сбалансированную меру, учитывая как прецизионность, так и полноту, тогда как одна точность иногда может давать вводящее в заблуждение представление об эффективности модели. Таблица 3 подробно показывает F1-Scores (%) каждого метода классификации для каждого из трех наборов данных для каждого набора дескрипторов, полученного из девяти моделей Transformer по всем классам. Основываясь на этих данных, набор данных-b превзошел наборы данных-a и -c в среднем на 1,76% и 1,46% соответственно. Это свидетельствует о том, что набор данных-a всегда превосходился аналогами с увеличением и что информация о первоначальной форме и размере листа была важной для сохранения в балансе, а не для максимизации информации о пикселях, которая сохранялась в наборе данных-c. Исходя из этого результата, все последующие эксперименты были сосредоточены только на наборе данных-b, в то время как два других набора данных были исключены. Дополнительно, стоит упомянуть, что решение KNN в этом случае было рассчитано с использованием значения K, равного 3, и функции расстояния Евклида.

Таблица 3. Метрики F1-Score (F1) в процентах по каждой модели Transformer, по решению (KNN/LSTM/ResNet) и по набору данных.
Таблица 4 показывает результаты применения PCCM. Данные демонстрируют в среднем улучшение на 1,83% по сравнению со случаями, когда PCCM не применялся. Таким образом, любые дальнейшие эксперименты всегда будут включать PCCM.
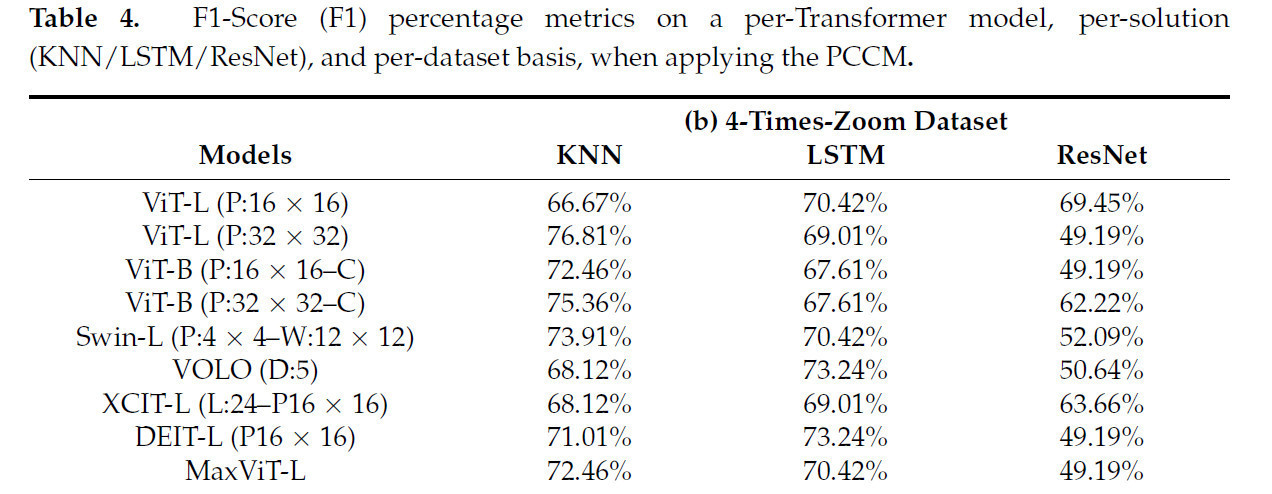
Таблица 4. Метрики F1-Score (F1) в процентах по каждой модели Transformer, по решению (KNN/LSTM/ResNet) и по набору данных при применении PCCM.
Применяя аугментации данных к набору данных-b, наблюдалось заметное среднее улучшение на 4,44%, 1,07% и 24,3% для каждого из решений классификации KNN, LSTM и ResNet соответственно. Таблица 5 показывает F1-Scores на том же уровне, что и предыдущая таблица, с примененными аугментациями данных. Основываясь на этом улучшении производительности, все дальнейшие эксперименты будут иметь примененную аугментацию данных.
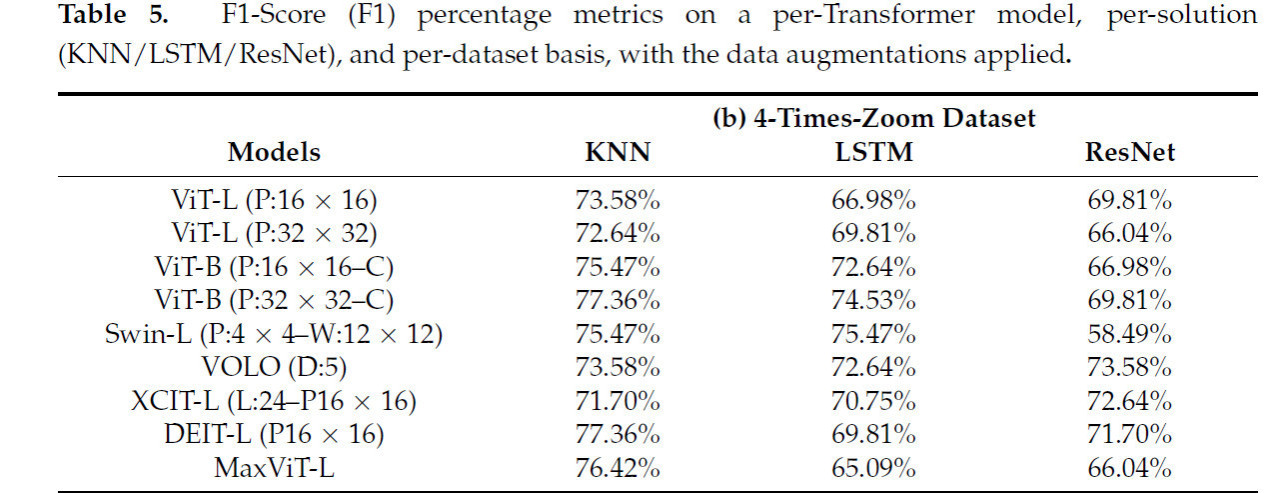
Таблица 5. Метрики F1-Score (F1) в процентах по каждой модели Transformer, по решению (KNN/LSTM/ResNet) и по набору данных с примененными аугментациями данных.
Решение KNN не проходило обучение, поскольку это алгоритмическое решение. Как объяснено в Разделе 2.7, для каждого из 11 дескрипторов, соответствующих каждому снимку из 9 моделей Transformer, создавался отдельный BoVW. Эта модульность позволяла классифицировать различные наборы изображений без остаточного эффекта от любого другого набора изображений. F1-Scores (%) по каждому набору изображений и по каждой модели Transformer решения KNN представлены в Таблице 6.

Таблица 6. F1-Scores (%) решения KNN по каждой модели Transformer и по каждому набору изображений.
С другой стороны, для моделей LSTM и ResNet были обучены девять отдельных моделей, по одной для каждой модели Transformer. Все дескрипторы из всех различных наборов изображений (11 до этого момента) способствовали обучению модели и, следовательно, результату. Этот подход создает проблему: если один или несколько наборов изображений показали худшую производительность по сравнению с другими во время обучения, производительность всей модели была бы снижена. Наблюдение за средними значениями F1-Score в Таблице 6 показывает заметные вариации производительности по всем 11 наборам изображений.
Для дальнейшего улучшения производительности моделей было исследовано выборочное удаление некоторых из худших наборов изображений из обучающих данных. Был применен итеративный процесс, который тестировал удаление всех комбинаций наборов изображений с длин волн 460, 640, 775 и 875 нм. Для подхода LSTM лучшие результаты были получены моделями, в которых наборы изображений с длин волн 460 и 640 нм были отброшены. Этот подход превзошел предыдущее решение на средний F1-Score по модели на 2,36%. Однако для подхода ResNet случай со всеми 11 наборами изображений оказался лучшим. Последующий анализ с подходом LSTM не включал ни длины волн 460, ни 640 нм. Таблица 7 показывает обновленные F1-Scores (%) по каждой модели для моделей LSTM, обученных без наборов изображений длин волн 460 или 640 нм.

Таблица 7. F1-Scores (F1) в процентах по каждой модели для решений LSTM и ResNet без использования каких-либо изображений из наборов изображений 460 и 640 нм.
Таблица 8 предоставляет детальные метрики производительности на уровне каждого набора дескрипторов для девяти моделей Transformer для решения KNN, для различных функций расстояния и значений K. В таблице представлен F1-Score для функций расстояния Евклида, Косинуса и Брея-Кертиса для значения K, равного 3, и F1-Score для значений K, равных 1, 3, 5 и 7, для функции расстояния Евклида. Результаты демонстрируют, что функция расстояния Евклида была лучше на 0,91% и 1,19%, чем функции Брея-Кертиса и Косинуса, соответственно. Дополнительно, значение K, равное 3, было на 0,18%, 1,13% и 1,42% более эффективным, чем значение K, равное 1, 5 или 7, соответственно. Следовательно, эти результаты подчеркивают выбор значения K, равного 3, и функции расстояния Евклида, которые были применены в Таблицах 3, 4, 5 и 6 для решения KNN.

Таблица 8. Сравнение производительности F1-Scores различных моделей Transformer для (a) функций расстояния Евклида, Брея-Кертиса, Косинуса для значения K, равного 3; и (b) значений K, равных 1, 3, 5, 7, для функции расстояния Евклида.
Результаты совокупностного подхода
Лучший F1-Score классификации для подходов KNN, LSTM и ResNet по всем классам составил 77,36%, 79,24% и 73,58% соответственно. Методология ансамбля, описанная в Разделе 2.9, достигла пикового F1-Score по всем классам с набором данных-b и решением классификации LSTM. Общий F1-Score для этой лучшей комбинации моделей составил 81,13%, в то время как на уровне каждого класса F1-Scores составили 85,25%, 66,67% и 78,26% для классов «здоровые», «ботритис-невидимый» и «ботритис-видимый» соответственно. Таблица 9 представляет все доступные метрики на уровне каждого класса для лучшего понимания производительности классификации.

Таблица 9. Метрики производительности на уровне каждого класса от лучшей ансамблевой модели, основанной на подходе классификации LSTM.
Этот результат ансамбля был получен путем агрегирования прогнозов множественных наборов дескрипторов, но не всех девяти из них. Более конкретно, дескрипторы четырех моделей Transformer оказались дающими лучшую комбинацию для лучшего результата. Этими четырьмя моделями были: Swin-L (P:4 × 4–W:12 × 12), ViT-L (P:16 × 16), VOLO (D:5) и XCIT-L (L:24–P:16 × 16). Также агрегация выполнялась на уровне каждого набора изображений. Этот лучший результат был комбинацией только наборов изображений RGB, CVI, GNDVI, NDVI и PSRI, в то время как остальные наборы изображений, за исключением наборов с длин волн 460 и 640 нм, использовались только во время обучения. Это доказывает, что включение вегетационных индексов было важным шагом для улучшения. Таблица 10 показывает комбинации наборов изображений, которые были протестированы, и их результаты в метрике F1-Score в целом и индивидуально для каждого класса.
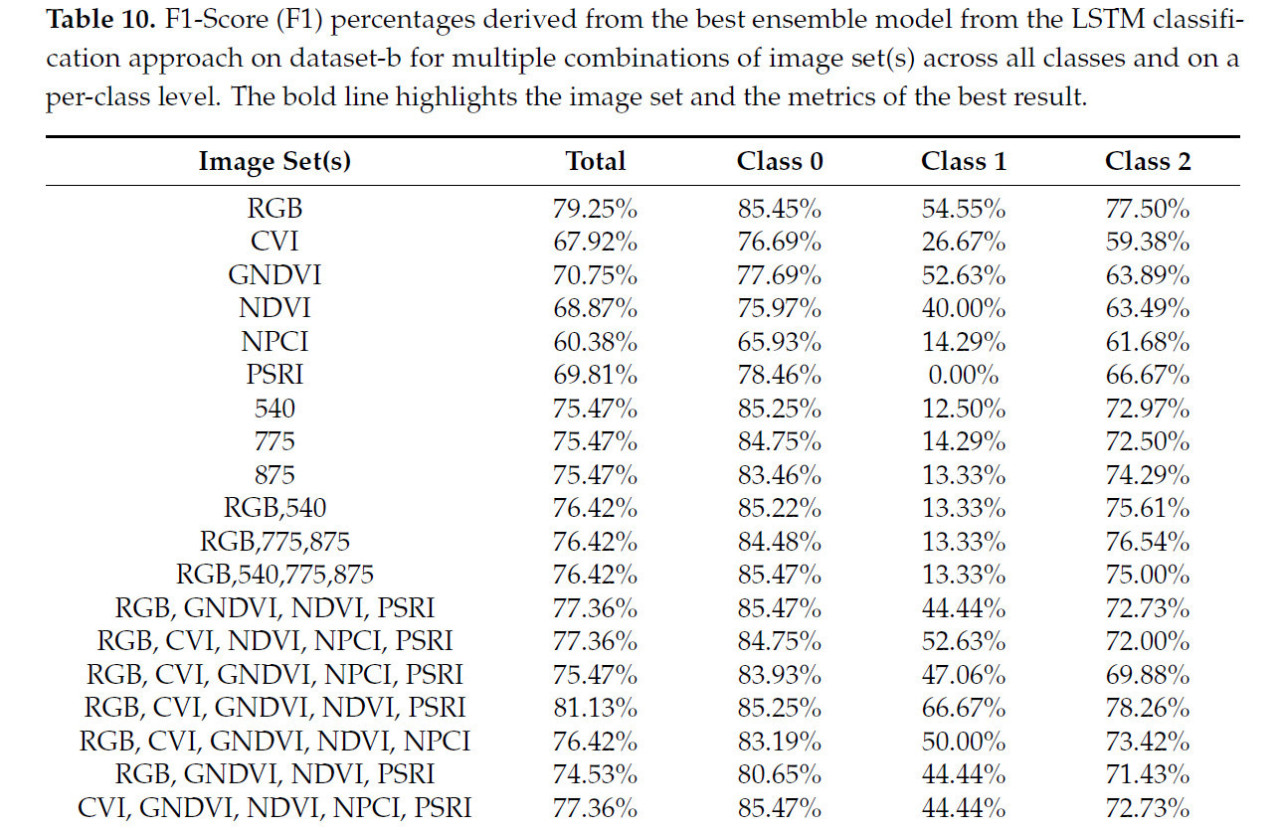
Таблица 10. F1-Score (F1) в процентах, полученные от лучшей ансамблевой модели из подхода классификации LSTM на наборе данных-b для множественных комбинаций наборов изображений по всем классам и на уровне каждого класса. Жирная линия выделяет набор изображений и метрики лучшего результата.
Для сравнения, лучшая ансамблевая модель KNN дала общий F1-Score 80,18% с значениями по классам 84,90%, 66,67% и 77,64% для классов «здоровые», «ботритис-невидимый» и «ботритис-видимый» соответственно. Лучшая ансамблевая модель ResNet дала F1-Score 82,07% в целом и 89,28%, 40,00% и 82,50% на уровне каждого класса. Хотя общий F1-Score был немного выше для ResNet по сравнению с решением LSTM, низкий F1-Score (<60%) в классе «ботритис-невидимый» считался большим недостатком, что делало модель ResNet менее жизнеспособной в качестве превосходящей альтернативы.
3.5. Визуализация результата
Это исследование направлено на решение важнейшей задачи диагностики болезней растений в управлении культурами, в частности направлено на точное обнаружение B. cinerea на растениях перца. Рисунок 11 представляет сравнительную визуализацию классификации листьев, противопоставляя (a) процесс ручной аннотации и (b) результаты, полученные предлагаемой методологией в этом исследовании. Как показано, модель либо успешно обнаруживала патоген, либо, в некоторых случаях, неправильно классифицировала некоторые «здоровые» листья как зараженные. Стоит упомянуть, что эти ошибки классификации потенциально могут показывать неточности в процессе ручной аннотации, и дальнейшие исследования могут включать повторное изучение и проверку некоторых из этих случаев.

Рисунок 11. Сравнительная визуализация трех изображений с классами листьев, нарисованными на листьях из (a) процесса ручной аннотации и (b) результата всей методологии этого исследования. Зеленые листья представляют класс «здоровые», синие листья представляют класс «ботритис-невидимый», а красные листья представляют класс «ботритис-видимый».
Дополнительно, проверка была выполнена путем сравнения грибной обильности, определенной с помощью RT-qPCR, с выходными результатами предлагаемого подхода (Рисунок 12). В частности, на Рисунке 12 изображения (a–c) демонстрируют точную классификацию отделенных здоровых листьев, не показывающих симптомов заболевания. Изображения (d–e) подчеркивают способность модели обнаруживать и классифицировать присутствие B. cinerea на ранних стадиях инфекции, уже на 1 dpi. В частности, изображение (f) представляет случай, наблюдаемый на 5 dpi, когда модель классифицировала отделенный лист «ботритис-невидимый» как «ботритис-видимый». Эта классификация согласуется с постепенным увеличением экспрессии BcRPL5, подтверждая чувствительность модели в обнаружении патогена на ранних стадиях инфекции или в латентные периоды, когда симптомы еще не появились.

Рисунок 12. Визуализация классификации отдельных отделенных листьев, использованных для оценки грибной биомассы с помощью RT-qPCR. Изображения (a–c) представляют фиктивно инокулированные листья, в то время как изображения (d–f) изображают инокулированные Botrytis cinerea листья на 1, 2 и 5 dpi, соответственно.
4. Выводы и будущая работа
В естественных условиях растения сталкиваются с рядом биотических и абиотических стрессоров, включая вредителей, патогенов и нарушения окружающей среды, которые часто вызывают сходные симптомы стресса. Однако сами по себе эти симптомы могут быть недостаточными для точной идентификации их конкретных причин, что делает необходимым лабораторные тесты для определения возбудителя болезни — процесс, требующий много времени и труда. Внедрение стратегий раннего обнаружения B. cinerea в культурах является важнейшим для эффективного управления болезнями. Дополнительно, латентные инфекции могут привести к внезапным вспышкам, если за ними не следить эффективно. Перспективным подходом является использование искусственного интеллекта (ИИ), в частности методов DL для улучшения возможностей обнаружения и разработки протоколов для целенаправленных ответов, таких как точное применение фунгицидов или других профилактических мер на основе предупреждений, сгенерированных ИИ.
Это исследование было сосредоточено на обнаружении B. cinerea на различных стадиях развития заболевания серой гнилью на растениях перца с использованием 11 наборов изображений (RGB, мультиспектральные и производные индексы) и двухэтапного подхода: (1) Сегментация листьев с использованием YOLOv11 достигла mAP50 86,4%, эффективно определяя местоположение листьев перца на изображениях. (2) Классификация листьев по стадии инфекции использовала три увеличенных набора данных, аугментацию данных и дескрипторы на основе Transformer. Классификация на основе LSTM превзошла модели KNN и ResNet, причем набор данных-b показал лучшую производительность по сравнению с наборами данных-a и -c. Аугментация данных улучшила средний F1-Score на 1,07%, в то время как исключение изображений на 460 и 640 нм улучшило производительность в среднем на 2,36%.
Оптимальный ансамбль, который сочетал дескрипторы от моделей Swin-L, ViT-L, VOLO и XCIT-L, улучшил средний F1-Score на 2,38%. В целом, подход использовал наборы изображений RGB, CVI, GNDVI, NDVI и PSRI и достиг F1-Score 81,13% с производительностью на уровне классов 85,25%, 66,67% и 78,26% для трех классов соответственно. Эти результаты ансамбля подчеркивают, что решение хорошо работало на классе «здоровые» с высокой полнотой, очень высокой прецизионностью и, следовательно, сильным F1-Score. Для класса «ботритис-невидимый» решение показало высокую полноту, но среднюю прецизионность, указывая на наличие ложноположительных результатов. Наконец, для класса «ботритис-видимый» высокая полнота и прецизионность выше среднего подчеркнули способность решения эффективно обрабатывать видимые симптомы. В целом, решение продемонстрировало надежную производительность.
Результаты этого исследования подчеркивают важность мониторинга не только видимых симптомов, но и ранних стадий инфекции B. cinerea, когда симптомы отсутствуют, с использованием молекулярных маркеров в сочетании с DL и мультиспектральной сегментацией изображений. В частности, раннее обнаружение инфекции серой гнили до появления симптомов было достигнуто путем количественного определения биомассы B. cinerea в растительных тканях, количественно выраженного как относительные уровни транскриптов грибного референтного гена BcRPL5, и анализа экспрессии связанных с защитой генов перца в сочетании с выходными данными предлагаемой архитектуры. В частности, относительные уровни транскриптов BcRPL5 прогрессивно увеличивались каждый день в течение первых 5 dpi, отражая рост и патогенность патогена на начальных стадиях инфекции, когда видимые симптомы еще не присутствовали. Противоположная регуляция DEF1 и PR1 отражает антагонистические взаимодействия между путями передачи сигналов SA и JA, подчеркивая динамический защитный ответ растения. Первоначальное подавление DEF1 может быть выгодно патогену, в то время как более поздняя активация PR1 указывает на сильный ответ, опосредованный SA, для противодействия угрозе. Эти изменения в экспрессии генов вместе с вариациями в биомассе B. cinerea иллюстрируют адаптивную стратегию хозяина и сложность взаимодействий растение-патоген во время прогрессирования заболевания.
Вышеупомянутый интегрированный подход предоставляет ценные новые инструменты для идентификации заболевания серой гнилью в обычно возделываемых культурах на ранних и поздних стадиях. В частности, это исследование представляет усилия по применению техник DL к растениям, выращенным в контролируемых условиях, напоминающих условия теплицы. Более того, он способствует своевременным вмешательствам для защиты здоровья культур, одновременно снижая зависимость от химических средств, поскольку предлагаемый подход смог выполнить точное обнаружение B. cinerea на листьях уже на первом dpi.
Компьютерное зрение и методы мягких вычислений, такие как использование изображений листьев, использовались несколькими исследователями для автоматизации обнаружения болезней растений [50]. Согласно нашему исследованию, степень тяжести заболевания прогрессирует медленнее в листьях перца по сравнению с цветами и плодами, которые более уязвимы к патогену. Это открытие подчеркивает необходимость целенаправленного мониторинга этих репродуктивных структур, поскольку они играют важнейшую роль в распространении болезни и потерях урожая. Поэтому будущие исследования должны быть сосредоточены на изучении применения этих инструментов к другим частям растений, помимо листьев. Дополнительно, дальнейшая работа может быть сосредоточена на таких областях, как расширение сбора данных, проверка данных вручную и аугментация данных. Также текущие решения классификации, такие как LSTM и ResNet, могут быть оптимизированы дальнейшим образом из-за их модульной природы, в то время как изучение других решений классификации, таких как вариации CNN и SVM, или их комбинаций с подходами в этом исследовании, может улучшить возможности обнаружения.
Дополнительные материалы
Следующая вспомогательная информация может быть загружена по адресу: https://www.mdpi.com/article/10.3390/agriculture15020164/s1, Дополнительная таблица S1: Праймеры, использованные в этом исследовании.
Ссылки
1. Molly, F.M.D.; Grant-Downton, R. Botrytis-biology, detection and quantification. In Botrytis—The Fungus, the Pathogen and Its Management in Agricultural Systems; Fillinger, S., Elad, Y., Vivier, M., Eds.; Springer: Cham, Switzerland, 2015; pp. 17–34. [Google Scholar] [CrossRef]
2. Shaw, M.W.; Emmanuel, C.J.; Emilda, D.; Terhem, R.B.; Shafia, A.; Tsamaidi, D.; Emblow, M.; van Kan, J.A.L. Analysis of cryptic, systemic Botrytis infections in symptomless hosts. Front. Plant Sci. 2016, 7, 625. [Google Scholar] [CrossRef] [PubMed]
3. Sofianos, G.; Samaras, A.; Karaoglanidis, G. Multiple and multidrug resistance in Botrytis cinerea: Molecular mechanisms of MLR/MDR strains in Greece and effects of co-existence of different resistance mechanisms on fungicide sensitivity. Front. Plant Sci. 2023, 14, 1273193. [Google Scholar] [CrossRef] [PubMed]
4. Huang, Y.; Duan, C.X.; Lu, M.; Yang, D.F.; Zhu, Z.D. Identification of the pathogens causing chocolate spot on the broad bean. Plant Prot. 2012, 6, 025. [Google Scholar]
5. Terentev, A.; Badenko, V.; Shaydayuk, E.; Emelyanov, D.; Eremenko, D.; Klabukov, D.; Fedotov, A.; Dolzhenko, V. Hyperspectral Remote Sensing for Early Detection of Wheat Leaf Rust Caused by Puccinia triticina. Agriculture 2023, 13, 1186. [Google Scholar] [CrossRef]
6. López, M.M.; Bertolini, E.; Olmos, A.; Caruso, P.; Gorris, M.T.; Llop, P.; Penyalver, R.; Cambra, M. Innovative tools for detection of plant pathogenic viruses and bacteria. Int. Microbiol. 2003, 6, 233–243. [Google Scholar] [CrossRef]
7. Schneider, S.; Widmer, F.; Jacot, K.; Koelliker, R.; Enkerli, J. Spatial distribution of Metarhizium clade 1 in agricultural landscapes with arable land and different semi-natural habitats. Appl. Soil Ecol. 2012, 52, 20–28. [Google Scholar] [CrossRef]
8. Rezaei, A.; Mahdian, S.; Babaeizad, V.; Hashemi-Petroudi, S.H.; Alavi, S.M. RT-qPCR Analysis of Host Defense-Related Genes in Nonhost Resistance: Wheat-Bgh Interaction. Russ. J. Genet. 2019, 55, 330–336. [Google Scholar] [CrossRef]
9. Mohammed, A.; Kora, R. A comprehensive review on ensemble deep learning: Opportunities and challenges. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 757–774. [Google Scholar] [CrossRef]
10. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
11. Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
12. Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
13. Touvron, H.; Cord, M.; Jégou, H. DeiT III: Revenge of the ViT. arXiv 2022, arXiv:2204.07118. [Google Scholar] [CrossRef]
14. Yuan, L.; Hou, Q.; Jiang, Z.; Feng, J.; Yan, S. VOLO: Vision Outlooker for Visual Recognition. arXiv 2021, arXiv:2106.13112. [Google Scholar] [CrossRef] [PubMed]
15. El-Nouby, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. XCiT: Cross-Covariance Image Transformers. arXiv 2021, arXiv:2106.09681. [Google Scholar] [CrossRef]
16. Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MaxViT: Multi-Axis Vision Transformer. arXiv 2022, arXiv:2204.01697. [Google Scholar] [CrossRef]
17. Giakoumoglou, N.; Kalogeropoulou, E.; Klaridopoulos, C.; Pechlivani, E.M.; Christakakis, P.; Markellou, E.; Frangakis, N.; Tzovaras, D. Early detection of Botrytis cinerea symptoms using deep learning multi-spectral image segmentation. Smart Agric. Technol. 2024, 8, 100481. [Google Scholar] [CrossRef]
18. Christakakis, P.; Giakoumoglou, N.; Kapetas, D.; Tzovaras, D.; Pechlivani, E.-M. Vision Transformers in Optimization of AI-Based Early Detection of Botrytis cinerea. AI 2024, 5, 1301–1323. [Google Scholar] [CrossRef]
19. Scarboro, C.G.; Ruzsa, S.M.; Doherty, C.J.; Kudenov, M.W. Quantification of gray mold infection in lettuce using a bispectral imaging system under laboratory conditions. Plant Direct 2021, 5, e00317. [Google Scholar] [CrossRef]
20. Qasrawi, R.; Amro, M.; Zaghal, R.; Sawafteh, M.; Polo, S.V. Machine Learning Techniques for Tomato Plant Diseases Clustering, Prediction and Classification. In Proceedings of the 2021 International Conference on Promising Electronic Technologies (ICPET), Deir El-Balah, Palestine, 17–18 November 2021; pp. 40–45. [Google Scholar] [CrossRef]
21. Lorente, Ò.; Riera, I.; Rana, A. Image Classification with Classic and Deep Learning Techniques. arXiv 2021, arXiv:2105.04895. Available online: http://arxiv.org/abs/2105.04895 (accessed on 14 June 2024).
22. Mistry, D.; Banerjee, A. Comparison of Feature Detection and Matching Approaches: SIFT and SURF. GRD J. Glob. Res. Dev. J. Eng. 2017, 2, 7–13. [Google Scholar]
23. Mansoori, N.S.; Nejati, M.; Razzaghi, P.; Samavi, S. Bag of visual words approach for image retrieval using color information. In Proceedings of the 2013 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–6. [Google Scholar] [CrossRef]
24. Nagasubramanian, K.; Jones, S.; Singh, A.K.; Sarkar, S.; Singh, A.; Ganapathysubramanian, B. Plant disease identification using explainable 3D deep learning on hyperspectral images. Plant Methods 2019, 15, 98. [Google Scholar] [CrossRef] [PubMed]
25. Early Detection of Plant Viral Disease Using Hyperspectral Imaging and Deep Learning. Available online: https://www.mdpi.com/1424-8220/21/3/742 (accessed on 19 September 2024).
26. Kapetas, D.; Kalogeropoulou, E.; Christakakis, P.; Klaridopoulos, C.; Pechlivani, E.M. Multi-spectral image transformer descriptor classification combined with molecular tools for early detection of tomato grey mould. Smart Agric. Technol. 2024, 9, 100580. [Google Scholar] [CrossRef]
27. Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar] [CrossRef]
28. Cunningham, P.; Delany, S.J. k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples). ACM Comput. Surv. 2022, 54, 1–25. [Google Scholar] [CrossRef]
29. Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
30. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
31. Kalogeropoulou, E.; Beris, D.; Tjamos, S.E.; Vloutoglou, I.; Paplomatas, E.J. Arabidopsis β-amylase 3 affects cell wall architecture and resistance against Fusarium oxysporum. Physiol. Mol. Plant Pathol. 2023, 124, 101945. [Google Scholar] [CrossRef]
32. Kalogeropoulou, E.; Aliferis, K.A.; Tjamos, S.E.; Vloutoglou, I.; Paplomatas, E.J. Combined Transcriptomic and Metabolomic Analysis Reveals Insights into Resistance of Arabidopsis bam3 Mutant against the Phytopathogenic Fungus Fusarium oxysporum. Plants 2022, 11, 3457. [Google Scholar] [CrossRef]
33. Qcell—Spectral Vision Camera Systems. Available online: https://qcell.tech/ (accessed on 11 September 2024).
34. Petrasch, S.; Silva, C.J.; Mesquida-Pesci, S.D.; Gallegos, K.; van den Abeele, C.; Papin, V.; Fernandez-Acero, F.J.; Knapp, S.J.; Blanco-Ulate, B. Infection Strategies Deployed by Botrytis cinerea, Fusarium acuminatum, and Rhizopus stolonifer as a Function of Tomato Fruit Ripening Stage. Front. Plant Sci. 2019, 10, 223. [Google Scholar] [CrossRef]
35. Poveda, J.; Calvo, J.; Barquero, M.; González-Andrés, F. Activation of sweet pepper defense responses by novel and known biocontrol agents of the genus Bacillus against Botrytis cinerea and Verticillium dahliae. Eur. J. Plant Pathol. 2022, 164, 507–524. [Google Scholar] [CrossRef]
36. Wan, H.J.; Yuan, W.; Ruan, M.; Ye, Q.; Wang, R.; Li, Z.; Zhou, G.; Yao, Z.; Zhao, J.; Liu, S.; et al. Identification of reference genes for reverse transcription quantitative real-time PCR normalization in pepper (Capsicum annuum L.). Biochem. Biophys. Res. Commun. 2011, 416, 24–30. [Google Scholar] [CrossRef] [PubMed]
37. Roboflow: Computer Vision Tools for Developers and Enterprises. Available online: https://roboflow.com/ (accessed on 2 July 2024).
38. Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar] [CrossRef] [PubMed]
39. Ultralytics. Home. Available online: https://docs.ultralytics.com/ (accessed on 14 June 2024).
40. Zhang, P.; Wu, Y.; Liu, B. Leveraging Local and Global Descriptors in Parallel to Search Correspondences for Visual Localization. arXiv 2020, arXiv:2009.10891. [Google Scholar] [CrossRef]
41. timm (PyTorch Image Models). Available online: https://huggingface.co/timm (accessed on 3 July 2024).
42. Papers with Code-ImageNet-1K Dataset. Available online: https://paperswithcode.com/dataset/imagenet-1k-1 (accessed on 2 July 2024).
43. Keras: Deep Learning for Humans. Available online: https://keras.io/ (accessed on 2 July 2024).
44. Harikrishnan, N.B. Confusion Matrix, Accuracy, Precision, Recall, F1 Score. Analytics Vidhya. Available online: https://medium.com/analytics-vidhya/confusion-matrix-accuracy-precision-recall-f1-score-ade299cf63cd (accessed on 2 July 2024).
45. Braun, P.; Sutton, J. Infection cycles and population dynamics of Botrytis cinerea in strawberry leaves. Can. J. Plant Pathol. 1988, 10, 133–141. [Google Scholar] [CrossRef]
46. Williamson, B.; Tudzynski, B.; Tudzynski, P.; Van Kan, J.A.L. Botrytis cinerea: The cause of grey mould disease. Mol. Plant Pathol. 2007, 8, 561–580. [Google Scholar] [CrossRef]
47. Kim, D.S.; Hwang, B.K. An important role of the pepper phenylalanine ammonia-lyase gene (PAL1) in salicylic acid-dependent signalling of the defence response to microbial pathogens. J. Exp. Bot. 2014, 65, 2295–2306. [Google Scholar] [CrossRef]
48. Pieterse, C.M.J.; van der Does, D.; Zamioudis, C.; Leon-Reyes, A.; van Wees, S.C.M. Facilitated Adaptation to Stress: SA-JA Interaction and Crosstalk. Plant Physiol. 2012, 158, 1743–1754. [Google Scholar]
49. Thomma, B.P.H.J.; Nurnberger, T.; Joosten, M.H.A.J. Signal Interactions in the Establishment of Plant Immunity. Curr. Opin. Plant Biol. 2011, 14, 482–489. [Google Scholar]
50. Vishnoi, V.K.; Kumar, K.; Kumar, B. Plant disease detection using computational intelligence and image processing. J. Plant Dis. Prot. 2021, 128, 19–53. [Google Scholar] [CrossRef]

Kapetas D, Kalogeropoulou E, Christakakis P, Klaridopoulos C, Pechlivani EM. Comparative Evaluation of AI-Based Multi-Spectral Imaging and PCR-Based Assays for Early Detection of Botrytis cinerea Infection on Pepper Plants. Agriculture. 2025; 15(2):164. https://doi.org/10.3390/agriculture15020164
Перевод статьи «Comparative Evaluation of AI-Based Multi-Spectral Imaging and PCR-Based Assays for Early Detection of Botrytis cinereaInfection on Pepper Plants» авторов Kapetas D, Kalogeropoulou E, Christakakis P, Klaridopoulos C, Pechlivani EM., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык.

















































































































Комментарии (0)