Революция в теплицах: как фейковые изображения и AI поднимают урожайность томатов на новый уровень
В защищенном грунте точное определение ключевых стадий роста томатов играет важнейшую роль для достижения эффективного управления и высокоточного производства. Однако традиционные подходы часто сталкиваются с такими проблемами, как нестандартизированный сбор данных, несбалансированные наборы данных, низкая эффективность распознавания и ограниченная точность. В данной статье предлагается инновационное решение, сочетающее генеративно-состязательные сети (GAN) и методы глубокого обучения для решения этих проблем.
Аннотация
В частности, модель StyleGAN3 используется для генерации высококачественных изображений стадий роста томата, что эффективно расширяет исходный набор данных более разнообразными изображениями. Затем этот расширенный набор данных обрабатывается с помощью модели Vision Transformer (ViT) для интеллектуального распознавания стадий роста томата в условиях защищенного грунта.
Предложенный метод был протестирован на 2723 изображениях, и было показано, что сгенерированные изображения практически неотличимы от реальных. Совместный подход к обучению, включающий как сгенерированные, так и исходные изображения, позволил получить более высокие результаты распознавания по сравнению с обучением только на исходных изображениях. На проверочной выборке была достигнута точность 99,6%, а на тестовой — 98,39%, что означает улучшение на 22,85%, 3,57% и 3,21% по сравнению с моделями AlexNet, DenseNet50 и VGG16 соответственно. Средняя скорость детектирования составила 9,5 мс. Данный метод представляет собой высокоэффективное средство для определения стадий роста томата в условиях защищенного грунта и предлагает ценные идеи для повышения эффективности и качества производства культур в защищенном грунте.
1. Введение
Помидор, как одна из важнейших экономических культур в мире, требует тщательного мониторинга и определения стадий роста для обеспечения как урожайности, так и качества [1]. Точное распознавание ключевых периодов развития — таких как стадия рассады, цветения, плодообразования и созревания — предоставляет важнейшие данные для точного управления и принятия решений по выращиванию культуры. Этот процесс жизненно важен для повышения эффективности сельского хозяйства и максимизации экономической отдачи [2].
В настоящее время определение и мониторинг стадий роста томата в основном зависят от ручных наблюдений, основанных на опыте специалистов. Этот метод не только неэффективен и затратен, но также в высокой степени подвержен субъективности наблюдателя и влиянию деятельности внутри сооружения, что может сказаться как на качестве, так и на урожайности томатов. Хотя появились такие технологии, как инспекционные роботы и интеллектуальные системы визуализации, их высокая стоимость и сложность обслуживания такого оборудования препятствовали их широкому применению, в частности, в хозяйствах с ограниченными финансовыми ресурсами. Следовательно, существует растущая потребность в исследованиях методов определения стадий роста томата на основе цифровых технологий, которые предлагали бы решения для мониторинга в реальном времени, удобные и эффективные.
Глубокое обучение, являющееся важнейшим направлением машинного обучения, было представлено Хинтоном и др. [3,4] в 2006 году, что вызвало значительную волну исследований в области нейронных сетей. Благодаря своим исключительным возможностям в обучении признакам и классификации, глубокое обучение стало основополагающим инструментом в нескольких областях, включая обнаружение объектов, обработку естественного языка [5], сопоставление текстовой информации [6], сегментацию и классификацию медицинских изображений [7,8], а также семантическую сегментацию видео [9,10]. В последние годы глубокое обучение также находит растущее применение в сельскохозяйственном секторе, особенно в идентификации и классификации болезней и вредителей сельскохозяйственных культур [11,12]. Сверточные нейронные сети (CNN) [13], которые являются одними из наиболее широко используемых и эффективных моделей в этом контексте, были успешно применены к задачам распознавания и классификации сельскохозяйственных культур, причем такие известные архитектуры, как AlexNet [14] и GoogLeNet [15], проложили путь.
Представление модели Vision Transformer (ViT) [16] в 2020 году ознаменовало прорыв в области мониторинга и классификации сельскохозяйственных культур. По сравнению с традиционными подходами на основе CNN, ViT обеспечивает повышенную точность в таких задачах, как распознавание и классификация болезней растений. Бай Юйпэн и др. [17] разработали алгоритм распознавания болезней пшеницы на основе ViT, который достиг впечатляющей средней точности распознавания более 95% для трех различных типов болезней пшеницы. Эта производительность превзошла показатели моделей AlexNet и VGG16 [18] на 6,68% и 4,94% соответственно. В другом исследовании Ван Ян и др. [19] решили проблему слабой устойчивости глубоких сверточных нейронных сетей (DCNN) к шуму путем включения дополнительных модулей, таких как сериализация с увеличением и маскированное многоголовое внимание, в стандартную модель ViT для классификации болезней томата. Их модифицированная модель ViT достигла точности классификации 99,63% на наборе данных по томатам, что более чем на 6% выше по сравнению с классическими моделями, такими как ResNet50 [20]. Однако, несмотря на эти достижения, использование моделей ViT для распознавания стадий роста сельскохозяйственных культур остается ограниченным. Большинство исследователей по-прежнему полагаются на более устоявшиеся модели глубокого обучения для таких задач. Расти и др. [21] исследовали три подхода машинного обучения для определения стадий роста 11 видов пшеницы и 10 видов ячменя: самообучаемую модель Conver Net с пятью слоями, модель VGG19 на основе трансферного обучения и метод опорных векторов. Их результаты показали, что модель на основе трансферного обучения была наиболее эффективной, с точностью, превышающей 99%, и значительным сокращением времени обучения. Между тем, Тан и др. [22] провели сравнительный эксперимент с использованием традиционных методов машинного обучения и подходов глубокого обучения для распознавания стадий роста риса. Их результаты показали, что методы глубокого обучения превзошли традиционные методы, причем модель EfficientNetB4 достигла наивысшей точности распознавания, превысив 99% как по точности, так и по средней точности.
Из-за практических ограничений объем данных изображений, собираемых вручную, ограничен. Набор данных по томатам страдает от таких проблем, как несбалансированность классов. Однако модель Vision Transformer (ViT) требует достаточного объема данных для достижения оптимальной производительности распознавания [23]. Традиционные методы аугментации данных, такие как поворот, смещение и кадрирование, неэффективны и генерируют только изображения с низким отношением сигнал-шум и ограниченным разнообразием. Для решения проблем переобучения и других задач генеративно-состязательные сети (GAN) [24] могут создавать более четкие и реалистичные образцы, но традиционные GAN страдают от таких проблем, как нестабильность обучения и коллапс модели [25]. StyleGAN3 [26], улучшенная версия GAN, представленная NVIDIA в 2021 году на основе StyleGAN2 [27], решает проблемы, такие как запутанность признаков, и способна генерировать изображения более высокого разрешения и более высокого качества. Однако StyleGAN3 также требует значительных вычислительных ресурсов для достижения удовлетворительных результатов обучения, обычно требуя более 5000 итераций. Этот процесс предъявляет высокие требования к производительности оборудования и требует значительного времени и вычислительной мощности, чтобы позволить модели адекватно изучить и уловить сложные распределительные характеристики данных, тем самым генерируя изображения высокого качества. Учитывая эти факторы, в данной работе изначально используется трансферное обучение путем использования предварительно обученной модели в качестве основы для нашей пользовательской модели StyleGAN, что значительно сокращает время обучения. Путем дальнейшего обучения модели на существующем наборе данных для генерации более реалистичных синтетических изображений мы смягчаем проблему нехватки данных, с которой обычно сталкивается модель ViT (Vision Transformer). Этот подход не только повышает качество синтетических изображений, но и расширяет разнообразие обучающего набора данных, предоставляя модели большее разнообразие обучающих образцов. В конечном итоге это способствует повышению точности распознавания стадий роста томата. Благодаря этой стратегии оптимизации мы стремимся улучшить способность модели к обобщению и ее устойчивость, особенно в практических сценариях, где данные ограничены.
Статья организована в следующие четыре раздела: Раздел 1 представляет введение, в котором излагается текущее состояние распознавания стадий роста томата в защищенном грунте, а также обзор последних достижений в моделях глубокого обучения для распознавания и классификации сельскохозяйственных культур. Раздел 2 описывает набор данных, использованный в данной работе, а также модели StyleGAN3 и ViT. Раздел 3 представляет экспериментальные результаты и сравнительный анализ с существующими методами. Раздел 4 и Раздел 5 посвящены обсуждению и заключению соответственно.
2. Материалы и методы
В этом разделе представлен обзор набора данных, использованного в данной работе, а также описание используемых моделей. Основной вклад этой статьи разделен на две части: во-первых, с использованием генеративно-состязательной сети StyleGAN3 генерируются высококачественные синтетические изображения; во-вторых, модель ViT применяется для распознавания и классификации стадий роста томата посредством трансферного обучения.
2.1. Набор данных
Изображения томатов были собраны в Демонстрационном парке современных сельскохозяйственных наук и технологических инноваций при Сычуаньской академии сельскохозяйственных наук. Это сооружение расположено в районе Синьду города Чэнду, провинция Сычуань, Китай, в центральной впадине Чэндуской равнины, на высоте 510 м над уровнем моря, в условиях субтропического влажного климата. Рост томатов включает четыре стадии: рассада, цветение, плодообразование и созревание, которые происходят в течение всего года.
В этой работе было собрано в общей сложности 1200 изображений по 4 стадиям роста: рассада, цветение, плодообразование и созревание, по 300 изображений для каждой стадии. Время сбора изображений томатов — 2024 год. На основе исходно собранных данных с использованием GAN было сгенерировано 2723 синтетических изображения. Все изображения были изменены до конечного разрешения 224 × 224. Примеры изображений для четырех категорий вместе с конкретными деталями представлены на Рисунке 1 и в Таблице 1.
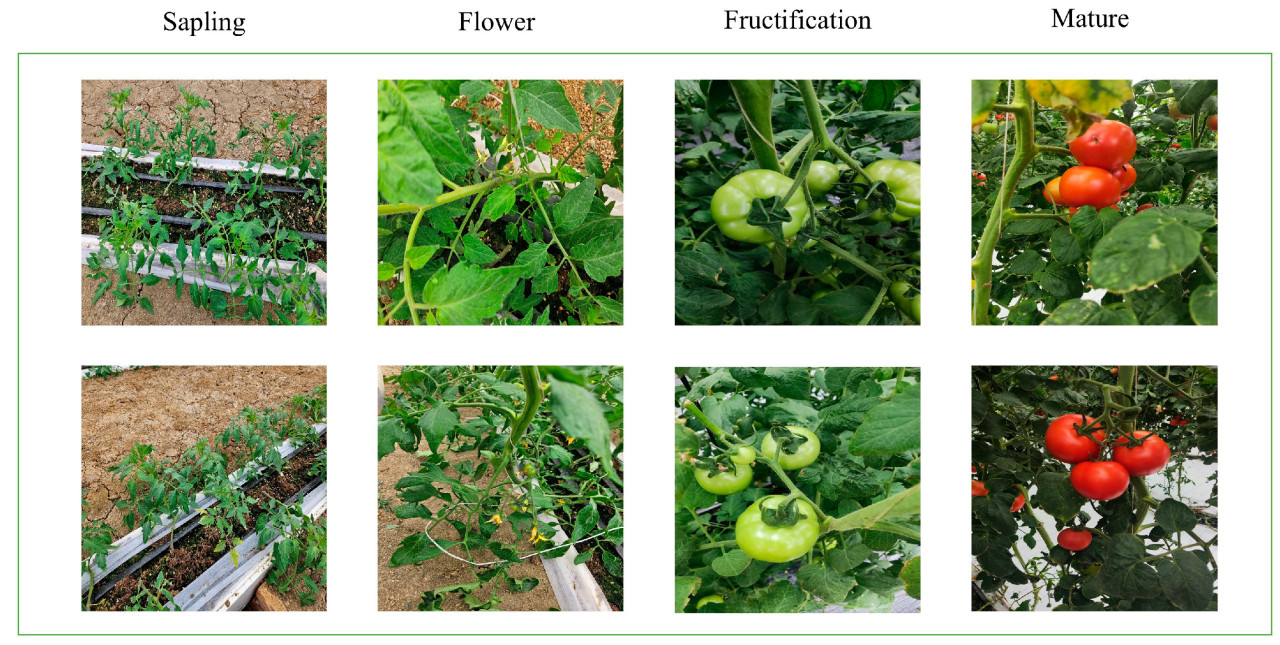
Рисунок 1. Четыре категории периода роста томата.

Таблица 1. Распределение изображений по классам для набора данных периода роста томата.
2.2. StyleGAN3
Генеративно-состязательные сети (GAN) работают путем введения двух состязательных нейронных сетей: генератора и дискриминатора. Эти сети оптимизируются посредством состязательного обучения, в ходе которого генератор создает реалистичные образцы данных, а дискриминатор отличает реальные образцы от синтетических. Благодаря своим мощным генеративным возможностям и широкому спектру потенциальных применений, GAN стали ключевой областью исследований в таких областях, как компьютерное зрение, обработка изображений и машинное обучение. Со временем было предложено несколько вариантов GAN, включая Conditional GAN (CGAN) [28], Deep Convolutional GAN (DCGAN) [29] и BigGAN [30], каждый из которых имеет свои преимущества и недостатки. Например, хотя CGAN и DCGAN обучаются быстрее, они генерируют изображения более низкого разрешения с видимым размытием по краям, что делает их непригодными для задач высокого разрешения, таких как генерация изображений томатов. В то время как BigGAN может создавать изображения высокого разрешения, его значительные требования к оборудованию и длительное время обучения делают его непрактичным для данного применения. В отличие от этого, StyleGAN3 предлагает значительное преимущество: он может генерировать изображения высокого разрешения 1024 × 1024 пикселя и эффективно обучаться на одном GPU благодаря оптимизированным ядрам CUDA, которые повышают скорость обучения и использование памяти.
Как отмечалось ранее, StyleGAN3 эффективно решает проблему запутанности признаков в StyleGAN2, когда мелкие детали сгенерированных изображений не перемещаются согласованно с формой объекта, что приводит к несоответствиям при повороте и смещении. Основная причина этой проблемы кроется в архитектуре генератора существующих моделей, которая использует свертки, нелинейные активации и слои апсемплинга, не достигая адекватной эквивариантности. В отличие от этого, StyleGAN3 использует подход обработки сигналов, отслеживая проблему до алиасинга в сети генератора, и предлагает решение. Рассматривая все сигналы как непрерывные, StyleGAN3 вносит небольшие, но эффективные архитектурные изменения, которые предотвращают непреднамеренную утечку информации в процессе иерархического синтеза, повышая общую производительность модели.
StyleGAN3 достигает инвариантности к вращению за счет двух ключевых изменений. Во-первых, все сверточные слои 3 × 3 по всей сети заменяются свертками 1 × 1, гарантируя, что только операции понижающей и повышающей дискретизации передают информацию между пикселями, тем самым предотвращая ненужную утечку информации в иерархический процесс синтеза. Во-вторых, sinc-фильтры понижающей дискретизации заменяются радиально-симметричными jinc-фильтрами, за исключением двух критических слоев. Эти изменения значительно улучшают инвариантность к вращению без ущерба для FID. Кроме того, на ранних стадиях обучения ко всем изображениям, видимым дискриминатором, применяется гауссовский фильтр для предотвращения коллапса на ранней стадии обучения. Генератор может иногда вводить высокочастотные сигналы с небольшой задержкой, ухудшая производительность дискриминатора. Схема генератора показана на Рисунке 2.
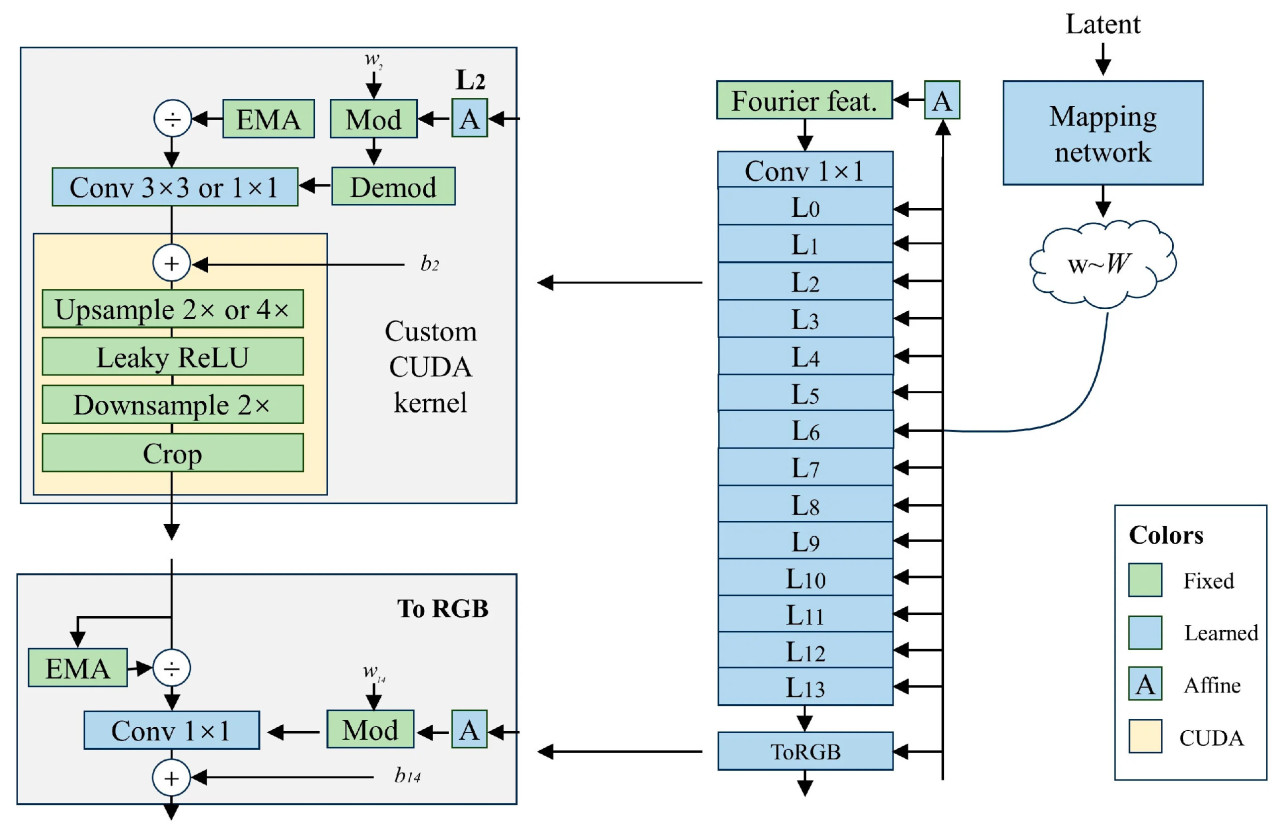
Рисунок 2. Структура генератора StyleGAN3.
В этой работе мы используем StyleGAN3 для генерации изображений, представляющих различные стадии роста томатов, чтобы устранить ограничения набора данных. Для генерации этих изображений мы сначала обучаем модель на наборе данных по томатам. Параметры обучения следующие: конфигурация установлена на stylegan-t (translation equiv); общий размер пакета равен 32; гамма установлена на 32 (вес регуляризации R1); и модель обучается в течение 1000 kimg (общее количество итераций обучения). Кроме того, для улучшения мониторинга и отслеживания процесса обучения частота создания снимков (snap) установлена на 10.
2.3. Vision Transformer (ViT)
В этой работе мы используем модель Vision Transformer (ViT) для распознавания стадий роста томатов посредством трансферного обучения. Архитектура ViT вводит концепцию патчей изображения. Изначально изображение разделяется на неперекрывающиеся патчи одинакового размера, которые затем кодируются в последовательность данных с помощью функции позиционного кодирования. Эти последовательные данные затем подаются в кодировщик Transformer. Выходные данные Transformer обрабатываются через полносвязный слой, а затем через слой softmax для получения окончательного результата классификации. Полная структура Vision Transformer представлена на Рисунке 3.
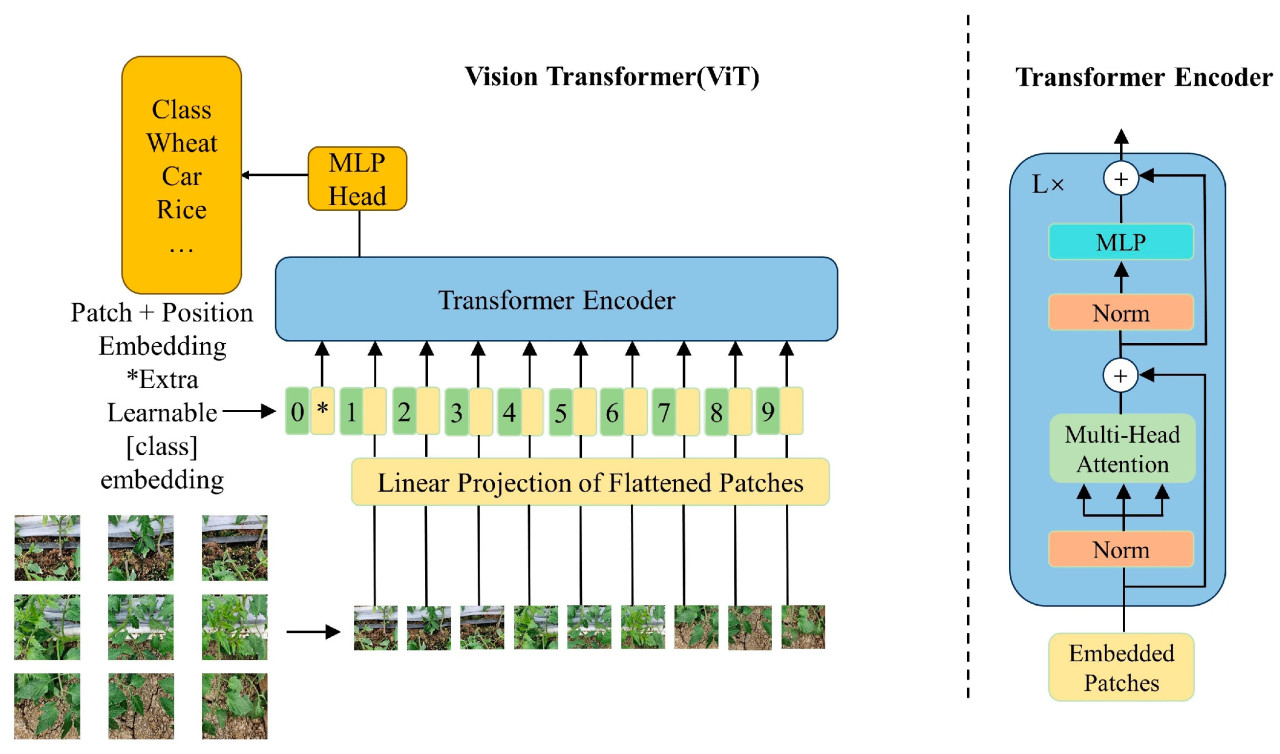
Рисунок 3. Структура модели ViT.
Для классификации томатов мы используем модель ViT-Base, которая сегментирует входное изображение на патчи размером 16 × 16 пикселей. Эти патчи затем обрабатываются через 12 слоев кодировщика, каждый из которых состоит из блоков кодировщика, уложенных в общей сложности 12 раз. После прохождения через слой эмбеддинга размерность каждого результирующего вектора составляет 768. Полносвязный слой включает 3072 юнита, а механизм многоголового самовнимания включает 12 голов внимания. Модель содержит 86 M параметров, и ее архитектура подробно описана в Таблице 2.

Таблица 2. Различные версии модели ViT.
2.4. Экспериментальная платформа
Эксперимент использовал среду разработки PyCharm 2024.1.1 вместе с фреймворком глубокого обучения PyTorch, с операционной системой Windows 11. Конфигурация оборудования включала процессор Intel i5-12500 и GPU NVIDIA A5000 с 24 ГБ встроенной памяти. Все сравнительные эксперименты проводились с использованием идентичных системных характеристик.
2.5. Экспериментальная установка и метрики оценки
Данная работа включала три экспериментальных этапа. На первом этапе мы использовали модель StyleGAN3 для обучения на каждой категории набора данных по томатам в течение 1000 эпох, в конечном итоге генерируя модели, соответствующие четырем стадиям роста томата. После обучения мы сгенерировали 1523 синтетических изображения, представляющих стадии роста томата, и провели оценку качества этих изображений. Второй этап включал обучение и валидацию модели ViT-Base как на исходном наборе данных по томатам, так и на расширенном наборе данных, включающем синтетические изображения, что позволило нам сравнить производительность распознавания двух наборов данных. На третьем этапе мы выбрали набор классических моделей классификации и сравнили их точность распознавания стадий роста томата с моделью ViT-Base.
Для оценки производительности моделей мы использовали ряд метрик, включая точность (accuracy), прецизионность (precision), полноту (recall), F1-меру и матрицу ошибок. Формулы для этих метрик оценки следующие:

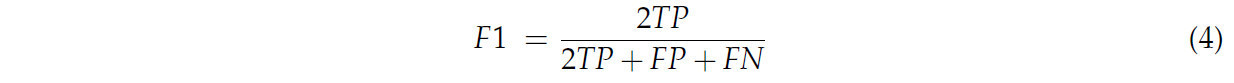
В контексте задач классификации истинно положительные (TP), ложноположительные (FP) и ложноотрицательные (FN) являются важнейшими метриками для оценки производительности прогнозных моделей. Более точно, TP представляет количество экземпляров, которые являются подлинно положительными и правильно классифицируются как таковые моделью; FP обозначает количество экземпляров, которые на самом деле отрицательны, но ошибочно классифицируются как положительные; и FN указывает количество фактически положительных экземпляров, которые ошибочно классифицируются как отрицательные. Эти метрики имеют первостепенное значение в анализе производительности, поскольку они предоставляют ценную информацию о точности классификации модели, ее способности различать классы и характере ее ошибок.
В этой работе мы используем отношение пикового сигнала к шуму (PSNR) для количественной оценки качества сгенерированных изображений. PSNR — это хорошо зарекомендовавшая себя метрика в области обработки изображений и видео, в основном используемая для измерения уровня шума в изображении и оценки качества изображения по сравнению с эталоном. Эта метрика также широко применяется для оценки производительности алгоритмов обработки изображений путем предоставления объективной меры верности изображения. PSNR рассчитывается на основе среднеквадратичной ошибки (MSE), которая представляет собой среднюю квадратичную разницу между исходным и сгенерированным изображениями. Следующие формулы определяют расчеты PSNR и MSE:
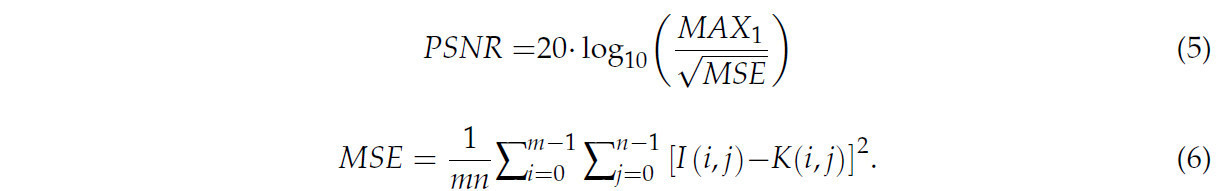
В уравнении (5) MSE представляет среднеквадратичную ошибку, меру средних квадратичных различий между исходным и сгенерированным изображениями. MAX относится к максимальному значению интенсивности пикселей в изображении, что дает верхнюю границу динамического диапазона изображения. В уравнении (6) I и K используются для обозначения исходного и сгенерированного изображений соответственно, в то время как m и n соответствуют количеству строк и столбцов в изображениях. Эти параметры необходимы для вычисления метрик качества изображения, которые оценивают верность сгенерированного изображения по отношению к исходному.
3. Реализация и результаты
Этот раздел начинается с описания аппаратного и программного обеспечения, а также метрик оценки, использованных в экспериментах. Затем оценивается эффект от использования исходных и синтетических изображений томата, анализируется производительность распознавания стадий роста томата с синтетическими изображениями и без них. Раздел завершается сравнением предложенной модели с несколькими классическими моделями.
3.1. Производительность StyleGAN3
Изображения, сгенерированные с использованием StyleGAN3, вместе с исходными изображениями томатов представлены на Рисунке 4. Как показано, сгенерированные изображения четырех категорий томатов очень близки к исходным изображениям, что демонстрирует способность модели производить высокореалистичные результаты. Однако важно подчеркнуть, что StyleGAN3 требует значительных вычислительных ресурсов и энергопотребления, а сложность изображений стадий плодообразования и созревания значительно выше, чем на более ранних стадиях. Для достижения оптимальных результатов обучения для этих стадий требуется более 20 000 эпох. Кроме того, ограничения наличия только одного высокопроизводительного GPU в нашей экспериментальной установке увеличат время обучения; среднее время обучения за итерацию составляет 4 минуты 35 секунд, поэтому для сокращения общего времени обучения мы стремились минимизировать влияние фонового шума на модель и повысить качество генерируемых изображений. Для достижения этой цели мы использовали инструмент Rembg на основе архитектуры U2-Net для удаления фона с изображений, тем самым изолируя объект переднего плана для улучшения выходных данных.

Рисунок 4. Исходные изображения томата и изображения, сгенерированные StyleGAN3: с первого по четвертый столбец представлены четыре категории стадий роста томата. Первый ряд показывает исходные изображения четырех стадий роста томата, а со второго по четвертый ряд отображаются сгенерированные изображения, соответствующие каждой категории.
Таблица 3 предоставляет подробный статистический анализ PSNR между исходными и сгенерированными изображениями томата. Результаты ясно демонстрируют, что качество изображений, сгенерированных с использованием StyleGAN3, близко приближается к качеству реальных, исходных изображений. StyleGAN3 производит изображения различного качества в зависимости от категории. Для категорий рассады и цветения значения PSNR составляют приблизительно 28 дБ, что предполагает, что сгенерированные изображения несколько искажены по сравнению с оригиналами. Эти искажения, вероятно, незначительны и могут быть нелегко обнаруживаемы человеческим глазом. В отличие от этого, категории плодообразования и созревания показывают заметное улучшение качества изображения, при этом значения PSNR увеличиваются до примерно 39 дБ. Это значительное повышение PSNR указывает на то, что сгенерированные изображения сохраняют больше мелких деталей, с минимальными искажениями, и близко отражают исходные изображения с точки зрения визуальной верности.

Таблица 3. Значения PSNR (в дБ) между исходными изображениями и изображениями, сгенерированными GAN, для четырех категорий.
Из Таблицы 4 видно, что StyleGAN3 демонстрирует различный уровень качества изображений с точки зрения SSIM (индекса структурного сходства) для разных категорий. SSIM — это метрика, которая оценивает структурное, яркостное и контрастное сходство между двумя изображениями. Более высокое значение SSIM, близкое к 1, указывает на большее структурное сходство между исходным и сгенерированным изображениями. В категориях рассады и цветения значения SSIM заметно низкие — 0,066 и 0,454 соответственно. Однако эти низкие значения не обязательно указывают на плохое качество изображения, поскольку SSIM в первую очередь оценивает структурные аспекты изображений. Категории рассады и цветения содержат более сложные элементы, такие как листья и стебли, что может способствовать более низким значениям SSIM. Поэтому значения SSIM для категорий рассады и цветения следует интерпретировать в сочетании со значениями PSNR и визуальной оценкой человека. С другой стороны, в категориях плодообразования и созревания наблюдается заметное увеличение значений SSIM. В категории плодообразования SSIM возрастает с 0,833 до 0,85, в то время как в категории созревания он немного снижается с 0,85 до 0,84. Эти значения указывают на то, что сгенерированные изображения в обеих категориях сохраняют высокую степень структурного сходства с исходными изображениями. Несмотря на небольшое снижение SSIM в категории созревания, качество изображения остается высоким, с минимальными искажениями.

Таблица 4. Значения SSIM между исходными изображениями и изображениями, сгенерированными GAN, для четырех категорий.
3.2. Производительность модели ViT
Как упоминалось ранее, для оценки производительности классификации модели классификации томатов мы выбрали точность (Acc), прецизионность, полноту и F1-меру в качестве метрик оценки качества модели. Таблица 5 представляет производительность классификации модели ViT-Base как на исходных изображениях, так и на комбинированном наборе данных из исходных и сгенерированных изображений. Метрики оценки для модели ViT-Base с включением сгенерированных изображений составляют 98,39%, 98,47%, 98,39% и 98,39% для точности, прецизионности, полноты и F1-меры соответственно. Эти результаты представляют собой улучшение на 3,81%, 3,48%, 3,81% и 3,98% по сравнению с производительностью, достигнутой при использовании только исходных изображений. Это демонстрирует, что включение сгенерированных изображений в модель ViT значительно улучшает способность модели к классификации и обобщению, особенно при дисбалансе данных, а также смягчает риск переобучения.

Таблица 5. Влияние синтетических изображений на ViT-Base.
Рисунок 5 представляет результаты матрицы ошибок для задачи классификации, которая выполнялась с использованием как исходных изображений, так и изображений, сгенерированных StyleGAN. Матрица показывает, что производительность классификации — особенно в различении истинно положительных и ложноположительных случаев между стадиями цветения и рассады — была заметно снижена при использовании только исходных изображений. В отличие от этого, значительное улучшение способности модели точно классифицировать эти стадии наблюдалось при включении изображений, сгенерированных StyleGAN, что привело к заметному повышению общей производительности классификации. В частности, матрица ошибок для комбинированного набора данных, состоящего как из исходных, так и сгенерированных изображений, демонстрирует существенное увеличение общей точности, а также более сбалансированное распределение между истинно положительными и ложноположительными случаями. Эти результаты подчеркивают значительные преимущества расширения набора данных сгенерированными изображениями, выделяя их ключевую роль в повышении устойчивости и эффективности модели классификации.
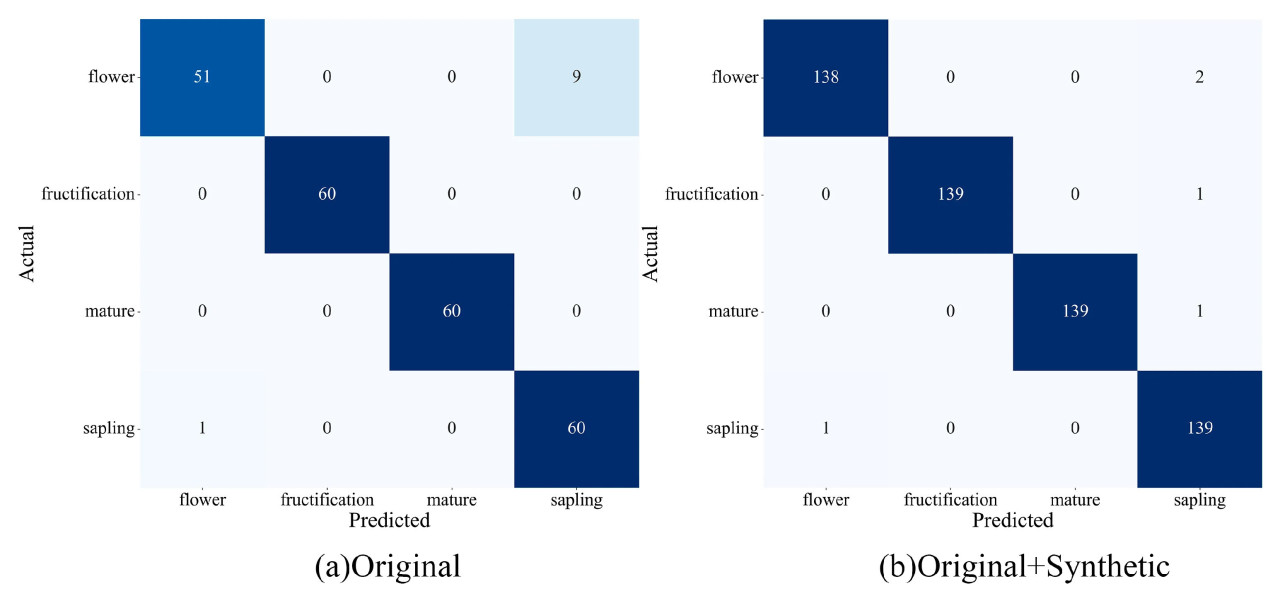
Рисунок 5. Матрица ошибок классификации стадий роста томата с использованием предложенного метода.
Рисунок 6 иллюстрирует кривые AUC в процессе обучения для ViT-Base, сравнивая исходный набор данных (Рисунок 6a) с набором данных, расширенным за счет сгенерированных изображений (Рисунок 6b). AUC, который оценивает производительность модели при различных порогах классификации, обеспечивает более комплексную оценку, минимизируя влияние единого порога. Результаты показывают, что добавление сгенерированных изображений значительно улучшает производительность ViT-Base в задаче классификации на четыре класса, с меньшими колебаниями по сравнению с использованием только исходного набора данных, и модель VIT может лучше выполнять свою работу. Это свидетельствует о том, что изображения, сгенерированные StyleGAN3, могут эффективно повышать точность классификации модели.
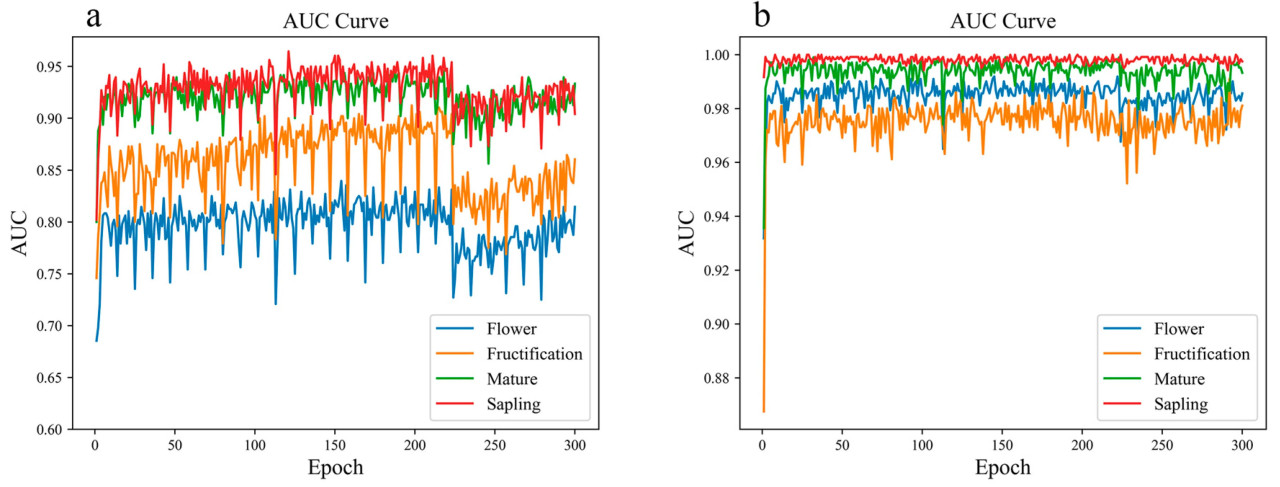
Рисунок 6. Сравнение AUC производительности ViT-Base с исходным набором данных (a) и набором данных, расширенным сгенерированными изображениями (b) в процессе обучения.
3.3. Сравнение производительности
В этом подразделе мы сначала проводим подробный анализ кривых четырех моделей, изучая их производительность при обучении и валидации с точки зрения точности и потерь. В частности, мы исследуем модель ViT-Base, дополненную сгенерированными изображениями, и сравниваем ее производительность в четырехклассовой классификации с производительностью трех широко используемых моделей — AlexNet, DenseNet50 [31] и VGG16 — дополненных сгенерированными изображениями. Как представлено на Рисунке 7, анализ кривых показывает, что модель ViT-Base достигает наиболее стабильной и благоприятной производительности. Она демонстрирует плавную сходимость, самое быстрое снижение потерь и впечатляющую точность валидации 99,6%. В отличие от этого, другие модели показывают различные уровни нестабильности, причем AlexNet демонстрирует заметные проблемы переобучения. Эти результаты свидетельствуют о том, что модель ViT-Base не только превосходит другие по точности, но и сохраняет большую стабильность на протяжении всего процесса обучения.
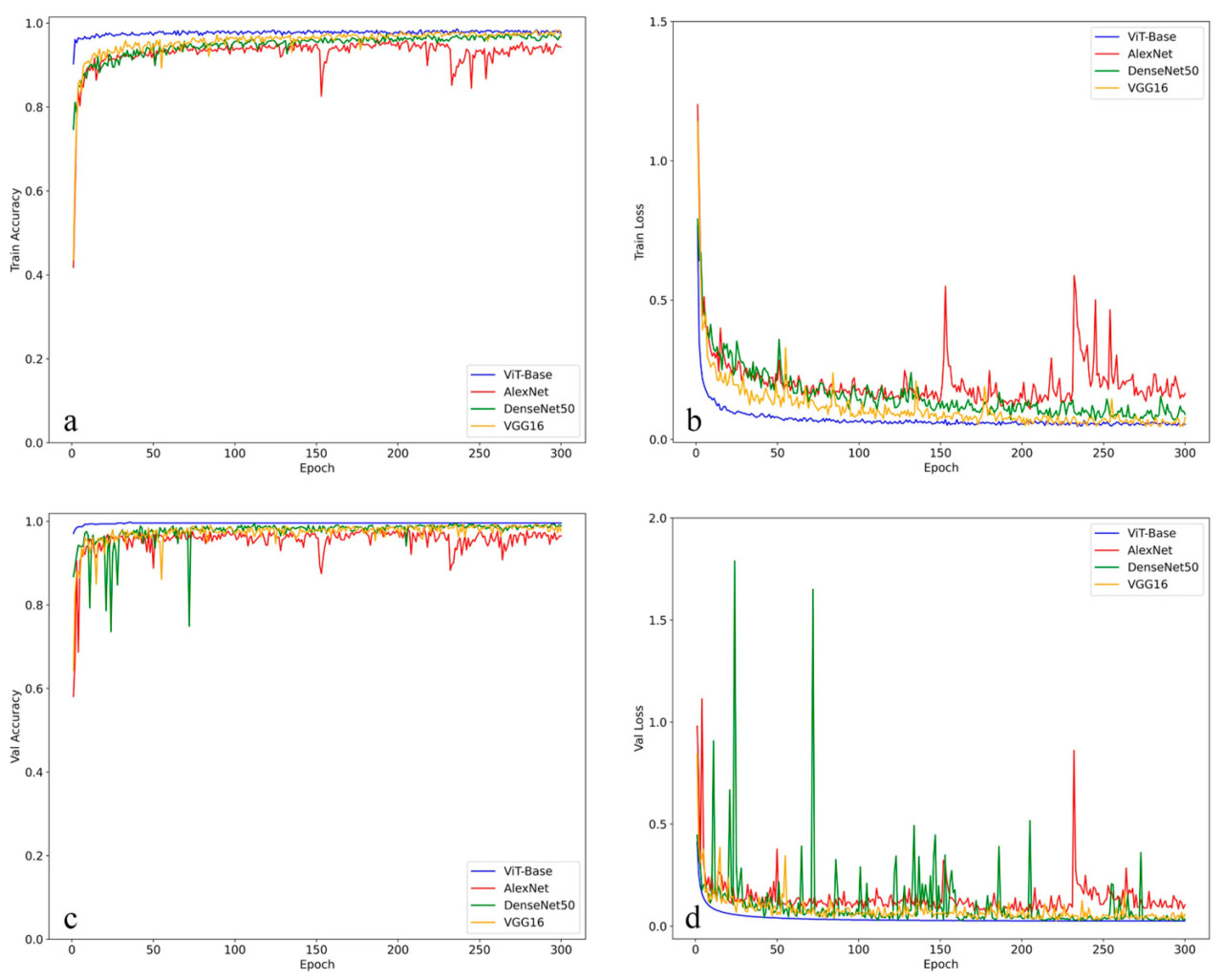
Рисунок 7. Производительность параметров обучения для четырех моделей. (a) Точность обучения, (b) потери при обучении, (c) точность валидации, (d) потери при валидации.
Таблица 6 демонстрирует, что модель ViT-Base достигает наивысшей производительности, с улучшением точности на 22,85%, 3,57% и 3,21% по сравнению с AlexNet, DenseNet50 и VGG16 соответственно. Эта превосходная производительность может быть в значительной степени объяснена требованием модели ViT-Base к большому набору данных для полной реализации своего классификационного потенциала. Примечательно, что обширный набор изображений, сгенерированных моделью StyleGAN3, играет ключевую роль в компенсации некоторых присущих ограничений модели ViT-Base. Расширяя обучающие данные этими синтетическими изображениями, мы смогли удовлетворить требования модели к данным, тем самым позволив ей достичь лучших результатов. Более того, сравнение с Таблицей 4 показывает, что при расширении сгенерированными изображениями модели DenseNet50 и VGG16 работают сопоставимо с моделью ViT-Base, обученной исключительно на исходных изображениях, или даже превосходят ее. Эти результаты подчеркивают значительное влияние аугментации данных в стратегическом использовании изображений, сгенерированных StyleGAN3, и в повышении производительности моделей глубокого обучения.
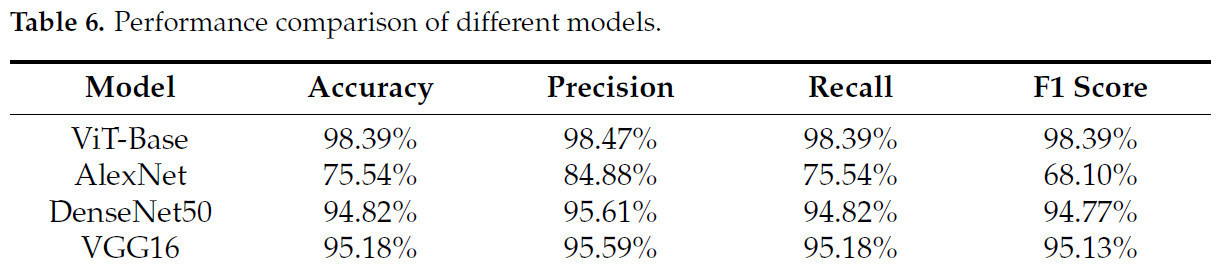
Таблица 6. Сравнение производительности различных моделей.
4. Обсуждение
Данная работа представляет метод распознавания стадий роста томатов, использующий модель StyleGAN3 для генерации синтетических изображений в сочетании с моделью ViT-Base. Экспериментальные результаты в Разделе 3 демонстрируют, что сгенерированные изображения близко напоминают реальные изображения, что обеспечивает прочную основу для их использования в задаче распознавания. Включив эти сгенерированные изображения в модель ViT-Base, достигается превосходная производительность в идентификации различных стадий роста томатов. Посредством сравнительных экспериментов видно, что производительность модели ViT-Base в сочетании со сгенерированными изображениями для идентификации стадии роста томата значительно лучше, чем у AlexNet, DenseNet50, VGG16 и других классических моделей в сочетании со сгенерированными изображениями. Было показано, что ViT-Base превосходит традиционные CNN-модели в некоторых задачах компьютерного зрения, таких как классификация изображений, обнаружение объектов и сегментация, особенно когда доступны крупномасштабные наборы данных. Механизм самовнимания ViT способен улавливать глобальные зависимости, чего трудно достичь с помощью сверточных операций в некоторых задачах. С другой стороны, DenseNet50 и VGG16 получают больше преимуществ от аугментации данных в основном из-за их более глубоких архитектур и большей сложности моделей. Их способность изучать более детальные и обобщенные признаки, в сочетании с большим количеством параметров и слоев, позволяет им полностью использовать разнообразие, вносимое аугментацией. В отличие от этого, AlexNet, будучи более мелкой сетью с меньшим количеством параметров, менее способна полностью использовать возросшее разнообразие данных, что приводит к сравнительно меньшему приросту производительности.
При выборе модели ViT для классификации томатов изначально существовала неопределенность относительно того, стоит ли выбирать более новую и улучшенную модель Swin, которая продемонстрировала превосходную производительность в некоторых задачах. Однако после углубленных обсуждений среди авторов мы определили, что ViT более подходит для основной направленности нашей работы на классификацию. В отличие от таких задач, как сегментация и обнаружение, которые требуют интенсивного прогнозирования и в которых модель Swin преуспевает, наша работа не включала такие задачи. Хотя ViT требует более длительного времени обучения по сравнению со Swin, он сохраняет высокую точность в задачах классификации, особенно при улучшении данных. Более того, относительно простая архитектура модели ViT в сочетании с доступностью обширных предварительно обученных моделей сделала ее более практичным выбором для целей обучения, тем самым позволив более эффективно разрабатывать модель для классификации.
Хотя сгенерированные StyleGAN3 изображения в этой работе в целом близки к реальным изображениям, их качество в зашумленных сценах все еще недостаточно, что требует предварительной обработки, как это типично во многих исследованиях. Например, наборы данных стадий плодообразования и созревания томата в этом исследовании были обработаны для удаления фонового шума. Кроме того, длительное время обучения StyleGAN3 создает трудности, особенно при ограниченных вычислительных ресурсах, приводя к значительному потреблению времени и энергии. Для смягчения этих проблем можно использовать трансферное обучение или облачные ресурсы. Поэтому критически важной областью для будущих исследований будет разработка методов для быстрой генерации высококачественных изображений напрямую, без необходимости предварительной обработки.
В течение длительного периода наша исследовательская группа использовала технологии компьютерного зрения для решения практических проблем в сельскохозяйственном производстве. В ходе нашей работы мы также стремились распространить наши исследования на более сложные производственные среды, такие как открытые поля и сады. В рамках этого усилия мы использовали изображения, собранные с камер в яблоневых и цитрусовых садах, для создания базового набора данных. Применяя модель StyleGAN3, разработанную в этом исследовании, для аугментации данных, мы успешно создали модели распознавания стадий роста, адаптированные к конкретным сортам яблок и цитрусовых. Хотя контролируемые условия в защищенном грунте создают относительно стабильную среду, сложность садов создает дополнительные проблемы. Хотя наш подход показал некоторые перспективные результаты в условиях сада и продемонстрировал свою потенциальную применимость в других сценариях, фактические результаты тестирования были не такими эффективными, как в контролируемой среде производства томатов. Этот разрыв указывает на то, что необходимы дальнейшие улучшения, и совершенствование этого аспекта будет основным направлением наших будущих исследовательских усилий.
5. Выводы
Данная работа начинается с использования генеративно-состязательной сети StyleGAN3 для генерации изображений, решения таких проблем, как ограниченность обучающих данных и дисбаланс данных. После этого модель ViT-Base применяется для распознавания стадий роста томатов в теплицах, давая перспективные результаты с точки зрения производительности классификации. Основные выводы следующие:
(1) Качество изображений, сгенерированных StyleGAN3, почти идентично качеству реальных изображений, со средним временем генерации 153 миллисекунды на изображение. Этот метод оказывается эффективным решением для аугментации данных, особенно для случаев с ограниченными обучающими данными, таких как наборы данных с малым количеством образцов. Однако когда вычислительные ресурсы ограничены, необходимы трансферное обучение или методы удаления фонового шума для сокращения времени обучения.
(2) Генерируя изображения через генеративно-состязательную сеть (GAN) и затем применяя модель ViT-Base для распознавания стадий роста томата, этот метод достигает превосходной производительности по сравнению с прямым распознаванием с использованием исходных изображений. Комбинация ViT со сгенерированными изображениями достигла точности 98,39% на тестовом наборе и средней скорости обнаружения 9,5 миллисекунд. При сравнении с AlexNet, DenseNet50 и VGG16, этот метод показал улучшение точности на 22,85%, 3,57% и 3,21% соответственно, демонстрируя свою повышенную эффективность в задачах классификации.
(3) В районах с ограниченным доступом к интеллектуальным устройствам использование изображений, сгенерированных генеративно-состязательной сетью (GAN), значительно снижает трудозатраты и несоответствия при ручном сборе изображений. Более того, применение модели ViT-Base для распознавания стадий роста томата может предоставить важнейшие данные для обоснованного принятия решений и точного управления условиями роста томата. Этот подход предлагает значительную экономическую ценность за счет повышения эффективности производства томатов. Кроме того, он может быть распространен на другие аналогичные категории сельскохозяйственных культур, такие как яблоки и цитрусовые, помимо томатов.
Ссылки
1. Alajrami, M.A.; Abu-Naser, S.S. Type of Tomato Classification Using Deep Learning. Int. J. Acad. Pedagog. Res. 2020, 3, 21–25. [Google Scholar]
2. Wei, Y.; Qin, R.; Ding, D.; Li, Y.; Xie, Y.; Qu, D.; Zhao, T.; Yang, S. The impact of the digital economy on high-quality agricultural development--Based on the regulatory effects of financial development. J. Huazhong Agric. Univ. 2023, 43, 9–21. [Google Scholar]
3. Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
4. Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neuralcomputation 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
5. Tomas, M.; Kai, C.; Greg, C.; Jeffrey, D. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
6. Jacob, D.; Ming, W.; Kenton, L.; Kristina, T. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
7. Mahesh, G.; Sweta, J. Stacked Convolutional Neural Network for Diagnosis of COVID-19 Disease from X-ray Images. arXiv 2020, arXiv:2006.13871. [Google Scholar]
8. Mahesh, G.; Sweta, J.; Raghav, A. DeepRNNetSeg: Deep Residual Neural Network for Nuclei Segmentation on Breast Cancer Histopathological Images. In Proceedings of the International Conference on Computer Vision and Image Processing (CVIP), Singapore, 27–29 September 2019; pp. 243–253. [Google Scholar]
9. Xu, Y.S.; Fu, T.J.; Yang, H.K.; Lee, C.Y. Dynamic video segmentation network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6556–6565. [Google Scholar]
10. Tang, H.; Ding, L.; Wu, S.; Ren, B.; Sebe, N.; Rota, P. Deep Unsupervised Key Frame Extraction for Efficient Video Classification. ACM Trans. Multimedia Comput. Commun. Appl. 2023, 119, 1–17. [Google Scholar] [CrossRef]
11. Amreen, A.; Sweta, J.; Mahesh, G.; Swetha, V. Tomato plant disease detection using transfer learning with C-GAN synthetic images. Comput. Electron. Agric. 2021, 187, 106279. [Google Scholar]
12. Xu, J.; Wang, J.; Xu, X.; Ju, S. Image recognition for different developmental stages of rice by RAdam deep convolutional neural networks. Trans. Chin. Soc. Agric. Eng. 2021, 37, 143–150. [Google Scholar]
13. Zhang, X.; Hou, T.; Hao, Y.; Shangguan, H.; Wang, A.; Peng, S. Surface Defect Detection of Solar Cells Based on Multiscale Region Proposal Fusion Network. IEEE Access 2021, 9, 62093–62101. [Google Scholar] [CrossRef]
14. Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
15. Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using GoogLeNet. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium(IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 89–96. [Google Scholar]
16. Alexey, D.; Lucas, B.; Alexander, K.; Dirk, W.; Zhai, X.; Thomas, U.; Mostafa, D.; Matthias, M.; Georg, H.; Sylvain, G.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
17. Bai, P.; Feng, Y.; Li, G.; Zhao, M.; Zhou, H.; Hou, Z. Algorithm of wheat disease image identification based on Vision Transformer. J. Chin. Agric. Mech. 2024, 45, 267–274. [Google Scholar]
18. Karen, S.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
19. Wang, Y.; Li, Y.; Xu, J.; Wang, A.; Ma, C.; Song, S.; Xie, F.; Zhao, C.; Hu, M. Crop Disease Recognition Method Based on Improved Vision Transformer Network. J. Chin. Comput. Syst. 2024, 45, 887–893. [Google Scholar]
20. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
21. Rasti, S.; Bleakley, C.J.; Silvestre, G.C.M.; Holden, N.M.; Langton, D.; Gregory, M.P.; O’Hare, G.M. Crop growth stage estimation prior to canopy closure using deep learning algorithms. Neural Comput. Appl. 2021, 33, 1733–1743. [Google Scholar] [CrossRef]
22. Tan, S.; Liu, J.; Lu, H.; Lan, M.; Yu, J.; Liao, G.; Wang, Y.; Li, Z.; Qi, L.; Ma, X. Machine Learning Approaches for Rice Seedling Growth Stages Detection. Front. Plant Sci. 2022, 13, 914771. [Google Scholar] [CrossRef] [PubMed]
23. Liu, W.; Lu, X. Research Progress of Transformer Based on Computer Vision. Comput. Eng. Appl. 2022, 58, 1–16. [Google Scholar]
24. Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farly, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
25. Han, X.; Li, Y.; Gao, A.; Ma, J.; Gong, Q.; Song, Y. Data Augmentation Method for Sweet Cherries Based on Improved Generative Adversarial Network. Trans. Chin. Soc. Agric. Mach. 2024, 55, 1–17. [Google Scholar]
26. Karras, T.; Aittala, A.; Laine, S.; Harkonen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-Free Generative Adversarial Networks. arXiv 2021, arXiv:2106.12423. [Google Scholar]
27. Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2018, arXiv:1812.04948. [Google Scholar]
28. Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
29. Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
30. Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
31. Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]

Huo Y, Liu Y, He P, Hu L, Gao W, Gu L. Identifying Tomato Growth Stages in Protected Agriculture with StyleGAN3–Synthetic Images and Vision Transformer. Agriculture. 2025; 15(2):120. https://doi.org/10.3390/agriculture15020120
Перевод статьи « Identifying Tomato Growth Stages in Protected Agriculture with StyleGAN3–Synthetic Images and Vision Transformer» авторов Huo Y, Liu Y, He P, Hu L, Gao W, Gu L., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)