Исследование по идентификации сортов картофеля на основе улучшенной модели Swin Transformer
Картофель является одной из важнейших продовольственных культур в мире и занимает ключевое положение в развитии сельского хозяйства Китая. Из-за большого количества сортов картофеля и наличия проблемы смешения сортов развитие картофелеводческой отрасли серьезно страдает. Следовательно, точная идентификация сортов картофеля является ключевым звеном для стимулирования развития данной отрасли.
Аннотация
Технологии глубокого обучения позволяют идентифицировать сорта картофеля с высокой точностью, однако количество связанных с этим исследований относительно невелико.
Таким образом, в данной статье представлена улучшенная модель классификации Swin Transformer под названием MSR-SwinT (Multi-scale residual Swin Transformer). Модель использует модуль слияния многомасштабных признаков вместо этапов patch partitioning и linear embedding. Такой подход позволяет эффективно извлекать признаки различных масштабов и повышает способность модели к их извлечению. Кроме того, в блок Swin Transformer интегрирована стратегия остаточного обучения (residual learning), которая эффективно решает проблему исчезновения градиента и позволяет модели более эффективно улавливать сложные признаки. Модель способна лучше捕捉 (улавливать/выявлять) сложные特征 (признаки).
Улучшенная модель MSR-SwinT была проверена на наборе данных изображений растений картофеля и продемонстрировала высокую производительность при распознавании изображений растений картофеля с точностью 94,64%. Это на 3,02 процентных пункта выше по сравнению с исходной моделью Swin Transformer. Экспериментальные данные показывают, что улучшенная модель обладает более высокой производительностью и лучшей обобщающей способностью, предлагая более эффективное решение для идентификации сортов картофеля.
1. Введение
Картофель ( Solanum tuberosum L.), как клубнеплодная культура, стал одним из важнейших продуктов питания в мире благодаря своей высокой адаптивности и питательной ценности. Он входит в семерку основных мировых продовольственных культур после риса, кукурузы и пшеницы [ 1 , 2 , 3 ]. Достижения в области сельскохозяйственных технологий привели к постоянному появлению улучшенных сортов картофеля, повышающих урожайность и устойчивость к болезням, открывая тем самым новые горизонты для сельскохозяйственного производства. Однако этот прогресс также создает трудности в точном определении новых сортов для обеспечения их безопасности и высокого качества, что имеет решающее значение для поддержания продовольственной безопасности.
Традиционно для идентификации сортов картофеля использовались такие методы, как наблюдение за морфологическими признаками, физико-биохимический анализ и метод молекулярных маркеров [ 4 , 5 , 6 ]. Эти подходы требуют много времени, подвержены субъективным предубеждениям и включают сложные процедуры. В последние годы применение алгоритмов машинного обучения [ 7 ] для идентификации сортов повысило эффективность распознавания. Однако эти методы ограничены ограничениями, связанными с необходимостью ручного извлечения признаков, и высокой потребностью в вычислительных ресурсах [ 8 , 9 , 10 ].
Достижения в области искусственного интеллекта, в частности применение сверточных нейронных сетей (CNN) в классификации изображений, сделали возможным автоматическое извлечение признаков, что значительно повысило точность и эффективность классификации [ 11 , 12 , 13 ]. Например, Лю и др. [ 14 ] использовали фреймворк TensorFlow для построения глубокой CNN для классификации 14 сортов яблок, достигнув общей точности 97,11%. Гао и др. [ 15 ] разработали модель CMPNet, интегрировав ResNet-50, SE-ReNet и SE-ReNeXt посредством обучения методом переноса и слоев Concat, что повысило точность идентификации сортов пшеницы до 99,51% при времени вывода всего 0,0212 с. [ 16 ] использовали метод переноса обучения для обучения пяти архитектур сверточных нейронных сетей (CNN) для идентификации четырёх сортов пшеницы, при этом DenseNet201, Inception V3 и MobileNet достигли наивысшей точности тестирования: 95,68%, 95,62% и 95,49% соответственно. Го [ 17 ] улучшил оптимизированную лёгкую модель классификации на основе сети ShuffleNetV2, и эта модель продемонстрировала превосходную производительность при распознавании растений картофеля, эффективно повысив точность и эффективность распознавания.
В июне 2017 года Google представила модель Transformer в своей статье «Внимание — все, что вам нужно» [ 18 ], которая быстро привлекла значительное внимание в академическом сообществе. Начиная с 2018 года, исследователи начали применять модели Transformer для распознавания изображений, что привело к обширным исследованиям в этой области [ 19 , 20 , 21 ]. Ридха Р. и др. [ 22 ] предложили метод классификации изображений сорняков, сочетающий Vision Transformer (ViT) и трансферное обучение, сосредоточившись на полученных с помощью дронов изображениях полей свеклы, петрушки и шпината. Их эксперименты показали, что ViT превзошел самые современные модели, такие как EfficientNet и ResNet, даже с небольшими аннотированными обучающими наборами данных. Борхани Й. и др. [ 23 ] разработали легкий подход к глубокому обучению на основе ViT для автоматической классификации болезней растений. Сравнивая классические сверточные нейронные сети (CNN) с гибридными моделями CNN-ViT, они обнаружили, что, хотя блоки внимания повышают точность, они снижают скорость прогнозирования. Сочетание блоков внимания со слоями CNN смягчило эту проблему скорости. Луо [ 24 ] предложил усовершенствованную модель Swin Transformer для распознавания растений картофеля, которая показала хорошие результаты распознавания.
Вышеупомянутые исследования показывают, что, несмотря на превосходную эффективность сверточных нейронных сетей (CNN) и Vision Transformers в классификации изображений растений, идентификация сортов картофеля остаётся сложной задачей. Сложная структура полей усложняет распознавание изображений, в то время как клубни, растущие под землёй, требуют косвенного получения информации о признаках от надземных растений. Кроме того, в этой области наблюдается нехватка исследований и накопления технологий. Для решения этих проблем в данной статье предлагается модель MSR-SwinT, которая объединяет преимущества локального извлечения признаков CNN с возможностями моделирования зависимостей на больших расстояниях, предоставляемыми Swin Transformers. Такое сочетание значительно улучшает представление признаков и качество классификации растений картофеля, обеспечивая надёжную техническую поддержку для интеллектуального управления сельским хозяйством. Основные достижения данной статьи перечислены ниже:
(1) На экспериментальной станции Юйчжун было собрано в общей сложности 69 изображений растений картофеля. После тщательного отбора и систематизации было сформировано пять наборов данных с различными размерами выборки для различных экспериментальных и аналитических целей.
(2) Мы предлагаем и оптимизируем новую модель MSR-SwinT, основанную на архитектуре Swin Transformer. Эта модель улучшает анализ сложных признаков и включает стратегии остаточного обучения для повышения стабильности и эффективности обучения.
(3) Благодаря сравнительному обучению и проверке с использованием классических сетевых моделей на нашем самостоятельно созданном наборе данных растений картофеля экспериментальные результаты демонстрируют превосходную производительность и эффективность модели MSR-SwinT в задачах классификации.
2. Материалы и методы
2.1. Сбор данных о растениях картофеля и предварительная обработка данных
Данные о листьях картофеля для этого исследования были получены на Опытной станции картофеля в Юйчжунском садоводческом хозяйстве, Ганьсуской академии сельскохозяйственных наук. Координаты станции: 35,85° с. ш. и 104,12° в. д., высота над уровнем моря 1960 м. Ее климатические характеристики включают в себя среднегодовую температуру 6,7 °C, среднегодовое количество осадков 400 мм и безморозный период продолжительностью около 120 дней, что указывает на умеренный полузасушливый климат. Сбор данных осуществлялся с помощью цифровой камеры Nikon COOLPIX B700, установленной в автоматический режим с максимальным значением ISO 1600 и минимальной выдержкой 1/30 с, что обеспечивало получение четких изображений. Все фотографии были сделаны при естественном освещении, а растения картофеля были сфотографированы с разных ракурсов и сохранены в формате JPG с разрешением 2272 × 1704.
Изображения были получены в период с 25 июля 2023 года по 1 августа 2023 года, который включал солнечную погоду, 2 дня с небольшим дождем и 1-2 дня с облачностью; эта изменчивость погоды помогла сделать снимки листьев при разных условиях освещенности. Чтобы увеличить разнообразие данных, для фотографий были выбраны разные периоды, такие как утро, полдень и вечер. Из-за сложности и нерегулярности характера роста растений картофеля, таких как положение роста, состояние ветвления и направление роста, для каждого растения картофеля в наборе данных были сделаны четыре изображения с одним фоном и два изображения с естественным фоном, чтобы сделать модель более эффективной в распознавании растений картофеля в их естественном состоянии. На рисунке 1 показаны некоторые примеры растений картофеля.

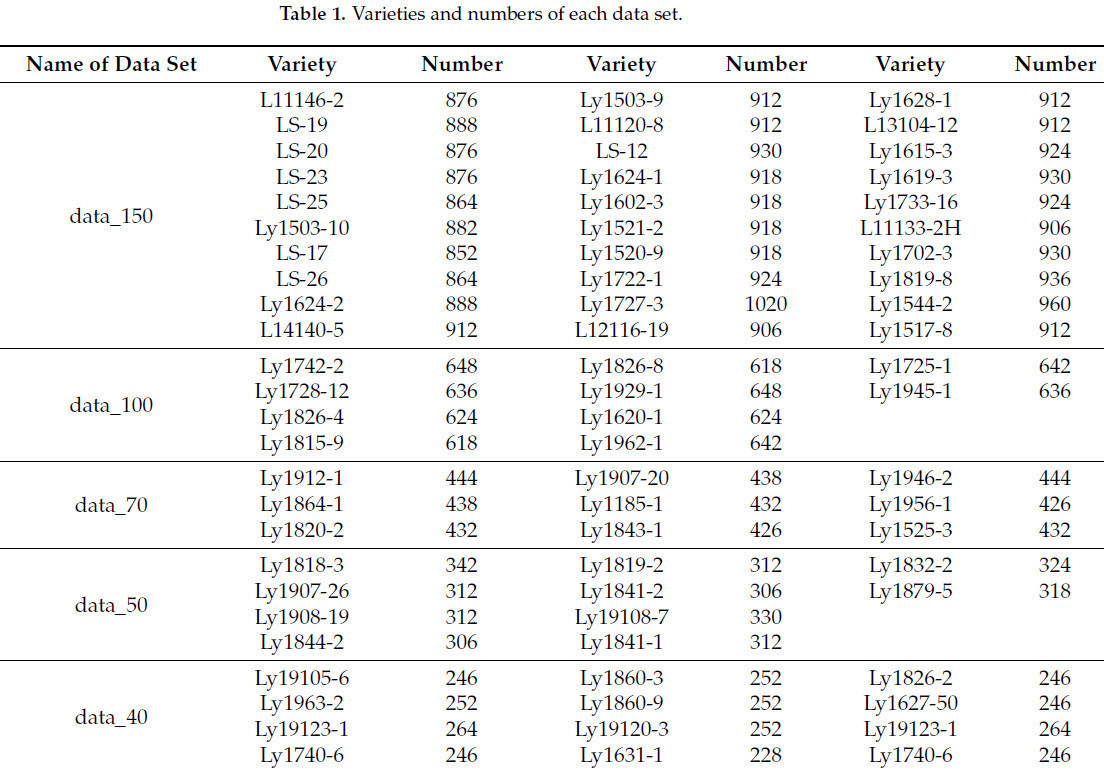
В этом исследовании были собраны пять наборов данных о растениях картофеля различного масштаба, названных data_150, data_100, data_70, data_50 и data_40, которые в совокупности охватывают 69 различных сортов картофеля. В частности, data_150 включает 30 сортов, примерно по 150 растений на сорт, всего 27 300 изображений; data_100 включает 10 сортов, примерно по 100 растений на сорт, всего 6336 изображений; data_70 включает 9 сортов, примерно по 70 растений на сорт, всего 3912 изображений; data_50 включает 10 сортов, примерно по 50 растений на сорт, всего 3174 изображения; data_40 включает 10 сортов, примерно по 40 растений на сорт, всего 2484 изображения. Количество сортов (линий) и каждого вида в каждом наборе данных показано в Таблице 1 .
Столкнувшись с проблемой ограниченного количества обучающих данных, модель часто склонна к переобучению, то есть к тому, что она слишком подробно изучила обучающие данные, что приводит к снижению её способности к обобщению при работе с новыми данными. Расширение данных добавляет более разнообразные обучающие выборки для эффективного смягчения проблемы переобучения. Это позволяет модели обучаться на более широком массиве выборок, тем самым повышая её способность к обобщению при столкновении с незнакомыми данными. Кроме того, имитируя различные изменения в реальной среде, такие как различия в освещении и углах обзора, расширение данных также может помочь модели адаптироваться к более сложным и изменчивым реальным сценариям. Для наборов данных с относительно небольшим объёмом данных, а именно data_100, data_70, data_50 и data_40, был реализован ряд методов аугментации данных. В частности, для регулировки яркости и контрастности к изображениям с вероятностью 50% применялась операция с коэффициентом регулировки яркости 1,1 для имитации ситуаций при различной интенсивности освещения. Кроме того, все изображения были повернуты на 180° по часовой стрелке. Благодаря комплексному применению этих методов масштаб каждого набора данных удалось увеличить в три раза по сравнению с первоначальным, что обеспечило более обширную базу данных для последующего обучения модели и способствовало повышению её эффективности.
Отдельные наборы данных были разделены на обучающий, проверочный и тестовый в соотношении 8:1:1. Для повышения эффективности обучения модели и производительности распознавания все изображения были масштабированы в соответствии с требованиями сети к количеству входных пикселей. В обучающем наборе входные изображения сначала были случайным образом обрезаны, а затем масштабированы до стандартного размера 224 × 224 пикселя, необходимого для сети. Затем эти изображения были случайным образом отражены по горизонтали и вертикали. Наконец, все изображения, подвергшиеся отражению, были нормализованы с помощью функции Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]). В частности, для каждого значения пикселя в каждом канале изображения преобразование выполняется в соответствии с уравнением (1):
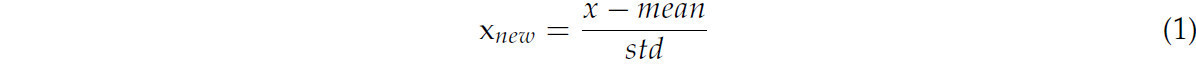
где 𝑥 исходное значение пикселя и 𝑥𝑛𝑒𝑤 — нормализованное значение пикселя.
Среднее значение и стандартное отклонение для каждого канала установлены равными 0,5. Этот процесс нормализации стандартизирует значения пикселей, делая распределение данных более удобным для обучения модели и, следовательно, повышая её эффективность в задачах определения сортов картофеля. В проверочном и тестовом наборах используется один и тот же метод обработки данных, при котором выполняется случайное кадрирование и масштабирование до размера 224 × 224 пикселя с последующей нормализацией. Пример предварительной обработки данных показан на рисунке 2 .

2.2. Трансформатор Swin
Swin Transformer [ 25 ] — это усовершенствованная модель, основанная на архитектуре Transformer, специально разработанная для задач компьютерного зрения. Она превосходно справляется с обработкой изображений, особенно в таких приложениях, как обнаружение объектов и сегментация изображений.
Swin Transformer использует иерархическую структуру, похожую на пирамидальную структуру традиционных свёрточных нейронных сетей. Общая структура показана на рисунке 3 , а её подробная конфигурация — в таблице 2. Сеть разделена на уровни, которые постепенно уменьшают карту признаков и увеличивают количество каналов.
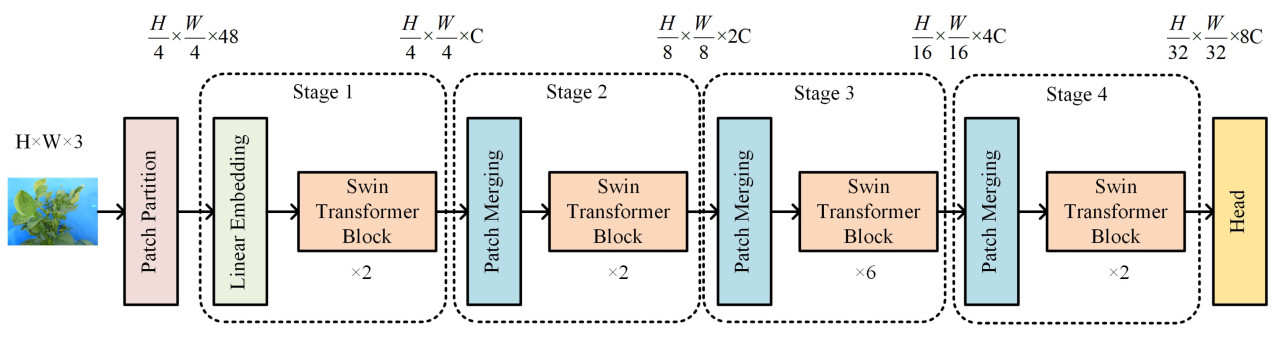

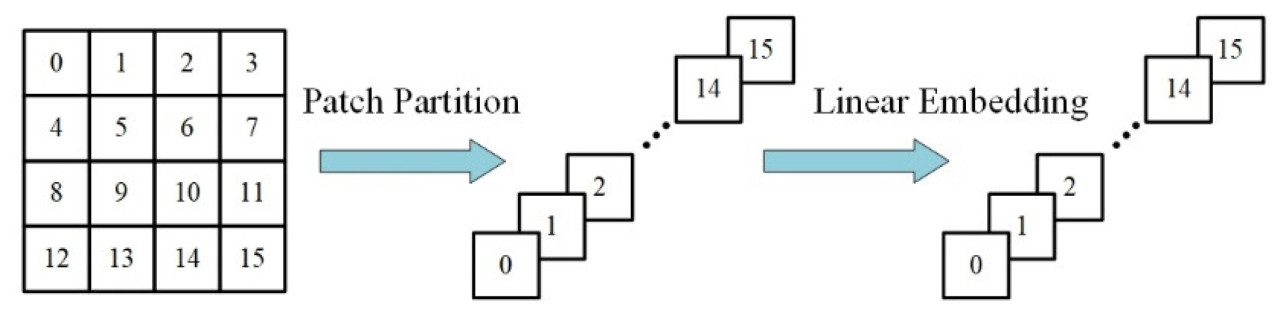
Входное изображение сначала разбивается на патчи с помощью Patch Partition, где каждый 4 × 4
Блок соседних пикселей рассматривается как единый патч и сглаживается вдоль размера канала. Затем эти патчи подвергаются линейному преобразованию с помощью слоя линейного встраивания; подробный процесс показан на рисунке 4. Затем модель конструирует карты признаков различного разрешения, проходя через четыре этапа. Каждый этап включает слой слияния патчей для понижения разрешения, который уменьшает пространственные размеры (ширину и высоту) вдвое, одновременно удваивая количество каналов. На рисунке 5 показан процесс слияния патчей.

После слоя слияния патчей каждый этап объединяет несколько блоков Swin Transformer. Эти блоки состоят из двух взаимодополняющих структур: многоголовочного самовосприятия на основе окна (Window-based Multi-head Self-Attention, W-MSA) и многоголовочного самовосприятия со смещенным окном (Shifted Window Multi-head Self-Attention, SW-MSA). Механизм W-MSA делит карту признаков на окна меньшего размера для снижения вычислительной сложности, в то время как механизм SW-MSA обеспечивает обмен информацией путем смещения позиций окон, тем самым повышая способность модели захватывать глобальную информацию. Архитектура Swin Transformer представлена на рисунке 6 .
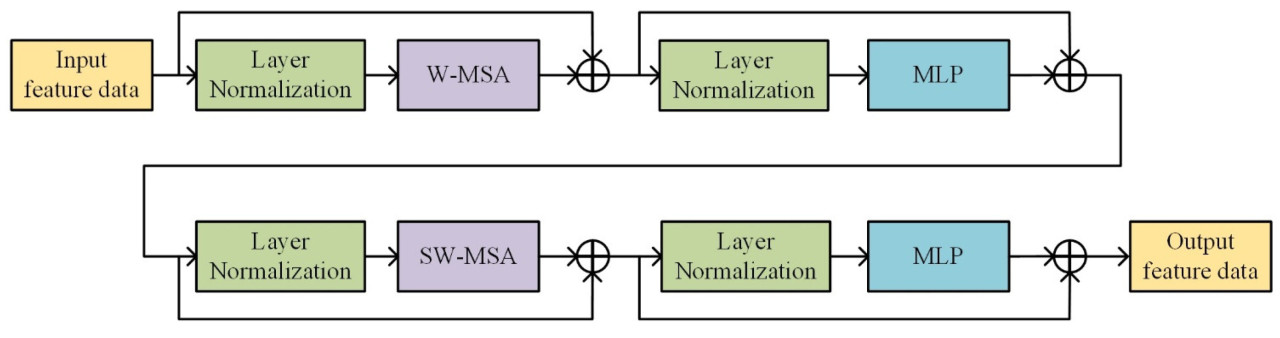
Каждый элемент должен взаимодействовать со всеми другими элементами на карте признаков во время расчета Self-Attention в стандартном модуле Multi-Head Self-Attention (MSA).
Модуль W-MSA использует особый метод: он изначально разбивает карту признаков на несколько небольших неперекрывающихся окон, а затем вычисляет эффект собственного внимания отдельно в каждом окне. Такой подход значительно снижает вычислительную сложность, поскольку каждый пиксель взаимодействует только с пикселями в пределах окна, в котором он находится, тем самым уменьшая объём вычисляемого эффекта собственного внимания. Вычислительная сложность каждого MSA и W-MSA показана в уравнениях (2) и (3):
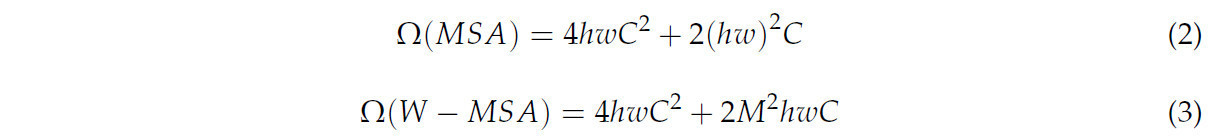
В (уравнениях (1) и (2)), ℎ это высота карты объектов,𝑤ширина карты объектов, 𝐶 это глубина карты объектов, и 𝑀 ширина и высота каждого окна.
С помощью модуля W-MSA расчёт собственного внимания происходит независимо в каждом окне, что ограничивает обмен информацией между ними. Чтобы преодолеть это ограничение, Swin Transformer представляет модуль SW-MSA, который позволяет передавать информацию между соседними окнами путём их смещения (сдвига) для обеспечения обмена информацией между ними, тем самым расширяя возможности модели по сбору глобальной информации.
2.3. Модуль слияния многомасштабных объектов
Модуль слияния многомасштабных признаков разработан с вдохновением от модуля Inception [ 26 ], который подчеркивает интеграцию признаков на нескольких уровнях и масштабах. Модуль Inception превосходно обрабатывает признаки различных масштабов одновременно в сети. Вдохновленная этой идеей, статья представляет модуль слияния многомасштабных признаков. Этот модуль создан для захвата и смешивания признаков изображения на разных уровнях и масштабах, что повышает способность модели распознавать и представлять признаки растений картофеля в сложных сценах. Различные масштабы признаков на изображении могут быть получены при свертке изображения с использованием ядер свертки разных размеров. Например, более мелкие ядра свертки (например, 1 × 1) помогают добиться кросс-канального слияния информации, в то время как более крупные ядра свертки (например, 5 × 5, 7 × 7) способны охватывать большее рецептивное поле и захватывать более сложные структуры изображения. Разумное комбинирование этих сверточных фильтров различных размеров позволяет эффективно извлекать различные локальные особенности изображения, что приводит к более богатому и полному представлению характеристик.
Различные растения картофеля обладают разными характеристиками, включая различные профили формы, потенциалы роста и структуры ветвления. Традиционные сверточные ядра с фиксированным масштабом имеют ограничения в регистрации этих сложных характеристик. Для регистрации этих детальных различий в данном исследовании использовался модуль слияния многомасштабных признаков (MSFF), повышающий точность анализа и идентификации характеристик растений картофеля. Структура модуля MSFF показана на рисунке 7 .
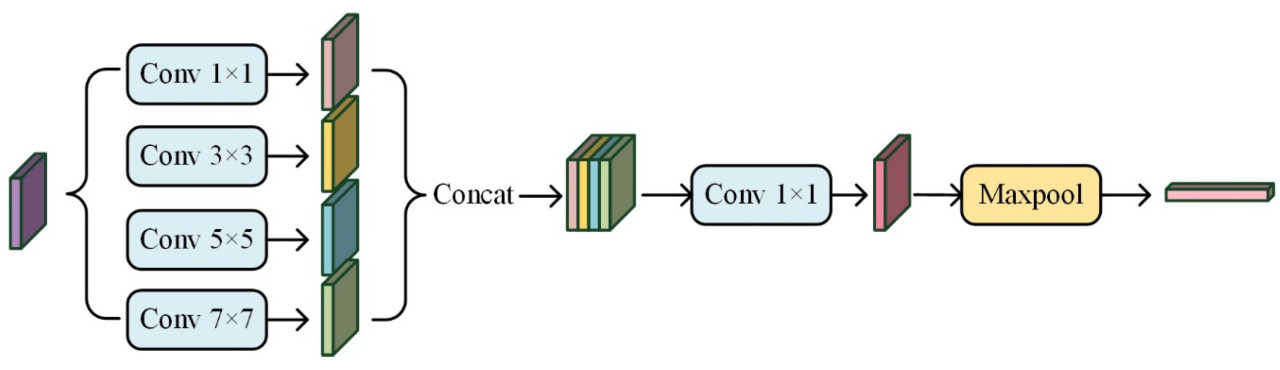
Структура обеспечивает многомасштабное извлечение признаков путем свертки входного изображения с фильтрами разных размеров, включая 1 × 1, 3 × 3, 5 × 5, и 7 × 7.
Каждое из этих ядер свертки отвечает за захват деталей изображения в разных масштабах. Карты признаков этих четырёх масштабов затем объединяются в измерении канала, формируя тензор признаков, содержащий многомасштабную информацию. Затем эти признаки объединяются с помощью 1 × 1 свёрточный слой для регулировки количества выходных каналов. Наконец, применяется операция максимального объединения для понижения разрешения карты признаков, что приводит к компактному и информативному представлению признаков.
Модуль MSFF направлен на улучшение понимания моделью как деталей, так и глобальной информации изображения, однако это также приводит к увеличению параметров сети. В модуле MSFF каждый сверточный слой содержит набор обучаемых сверточных ядер, которые являются основным источником роста параметров. В частности, модуль MSFF содержит пять сверточных слоев, каждый из которых вводит определенное количество параметров, зависящее от размера сверточного ядра, количества входных каналов (in_c) и количества выходных каналов (out_c). Например, сверточный слой будет иметь один параметр, если размер его сверточного ядра равен𝑘× 𝑘. Такое наложение нескольких сверточных слоев значительно увеличивает общее количество параметров в сети.
2.4 Остаточное обучение
Глубокие сверточные нейронные сети достигли значительных успехов в области компьютерного зрения. С увеличением числа слоёв сети извлекаемые признаки изображения становятся более сложными, что приводит к повышению эффективности обучения. Тем не менее, дальнейшее углубление сети может привести к проблеме деградации сети. Эта проблема проявляется в том, что потери в обучающем наборе сначала уменьшаются, а затем выходят на плато или даже увеличиваются по мере увеличения глубины сети. Для решения этой проблемы Хе и др. [ 27 ] предложили остаточную структуру, которая вводит поверхностные признаки путём добавления переходных соединений между слоями.
Фундаментальная концепция остаточного обучения заключается в изменении сложного преобразования входных данных в выходные, которое традиционные нейронные сети изучают напрямую. Вместо этого сеть обучается запоминать более простое «остаточное» преобразование, представляющее собой расхождение между входными данными и желаемым выходным значением. С математической точки зрения, если функция, которую наша сеть хочет выучить, — это , то подход остаточного обучения заключается в том, чтобы сеть научилась 𝐹 ( 𝑥 ) = 𝐻( 𝑥 ) −𝑥. Это позволяет получить конечный результат, 𝑦, который можно получить с помощью уравнения 𝑦 = 𝐹 ( 𝑥 ) + 𝑥. Ключ к этой трансформации заключается в том, что при обучении𝐻( 𝑥 ) напрямую сложно (особенно когда сеть глубокая), изучение относительно простого𝐹 ( 𝑥 ) становится более осуществимым. Остаточная структура показана на рисунке 8 .
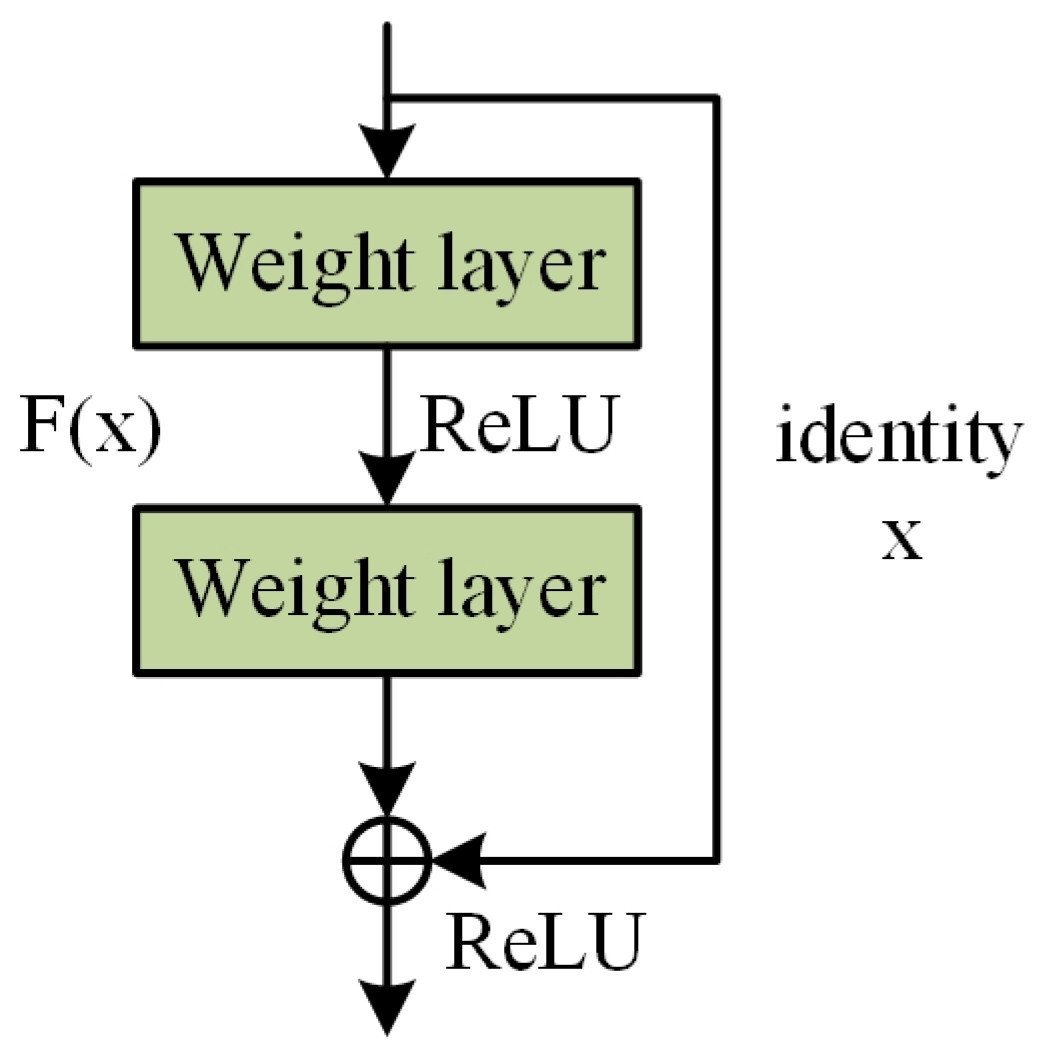
Для реализации вышеупомянутой идеи остаточного отображения в остаточных сетях используется метод, известный как «пропускаемое соединение». Пропускаемое соединение — это часть сети, где входному сигналу разрешено обходить один или несколько слоёв и проходить непосредственно на следующий слой, где он суммируется с преобразованными сигналами этих слоёв для формирования окончательного выходного сигнала. Такой подход не только упрощает задачу обучения, но и гарантирует беспрепятственное распространение сигнала в прямом и обратном направлениях сети, особенно в глубоких сетях, что помогает смягчить проблему исчезновения или взрывного роста градиентов.
Использование остаточного обучения представляет собой эффективную методологию повышения производительности сетей в задачах распознавания изображений. Эта стратегия позволяет сети сосредоточиться на выявлении тонких несоответствий между входными данными и желаемыми выходными данными, изучая остатки вместо полного отображения выходных данных, что проще, чем прямое освоение модели глобального отображения. В результате остаточные сети достигают превосходной сходимости и повышают эффективность обобщения модели на ранее неизвестных данных. Внедрение механизма остаточного обучения эффективно сводит задачу понимания сложных функций к изучению более простых остаточных функций, тем самым снижая нагрузку на обучение и гарантируя, что каждый слой сети будет работать над уточнением существующих признаков и включением новой информации, а не повторно восстанавливать все признаки предыдущего слоя. Особенно важно отметить, что информация может свободно передаваться между несколькими слоями благодаря архитектуре сокращенных соединений. Это позволяет более высоким слоям напрямую использовать признаки нижних слоев, что крайне важно для сохранения и передачи критически важной информации в таких задачах, как распознавание изображений.
2.5 Общая структура модели идентификации растений картофеля MSR-SwinT
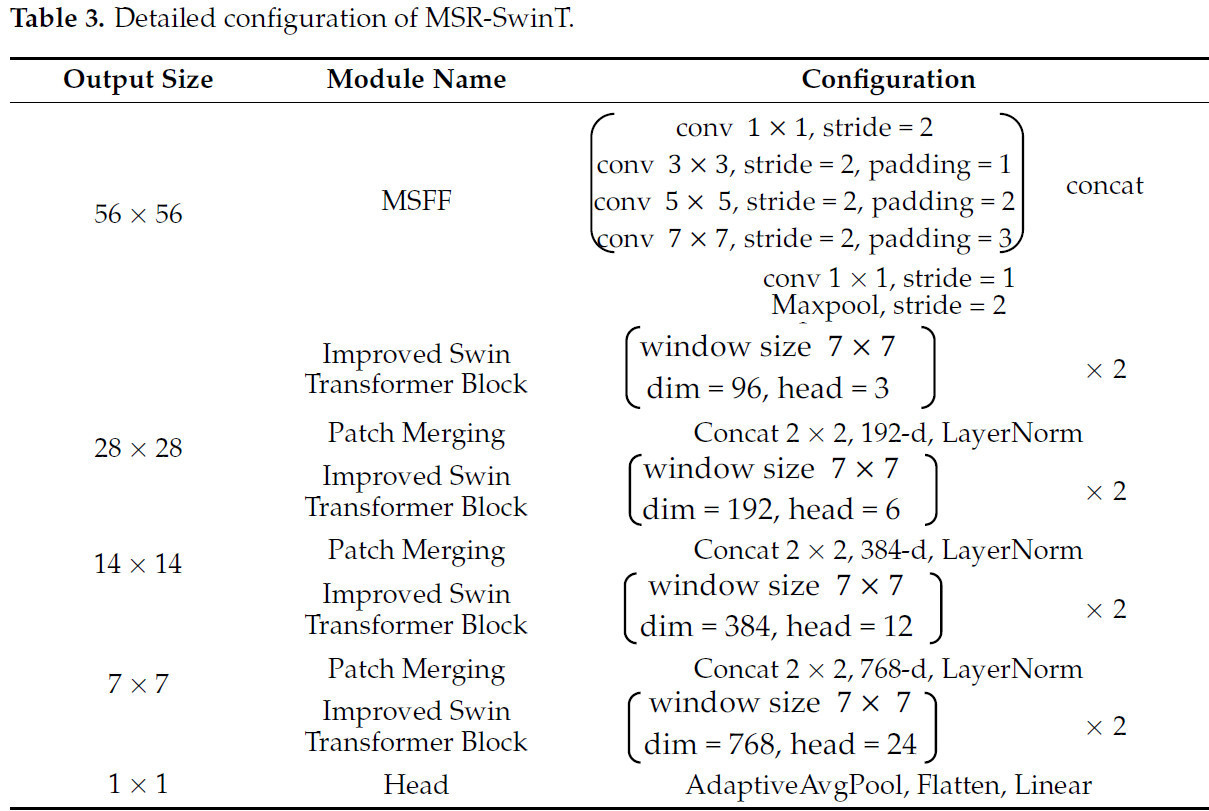
Для решения задачи распознавания сложных признаков у растений картофеля в данном исследовании были внесены два усовершенствования на основе модели Swin Transformer. Во-первых, вместо Patch Partition и Linear Embedding был использован модуль слияния многомасштабных признаков. Во-вторых, в блок Swin Transformer была введена стратегия остаточного обучения. Усовершенствованная модель получила название MSR-SwinT, её общая структура показана на рисунке 9 , а подробная конфигурация — в таблице 3 .
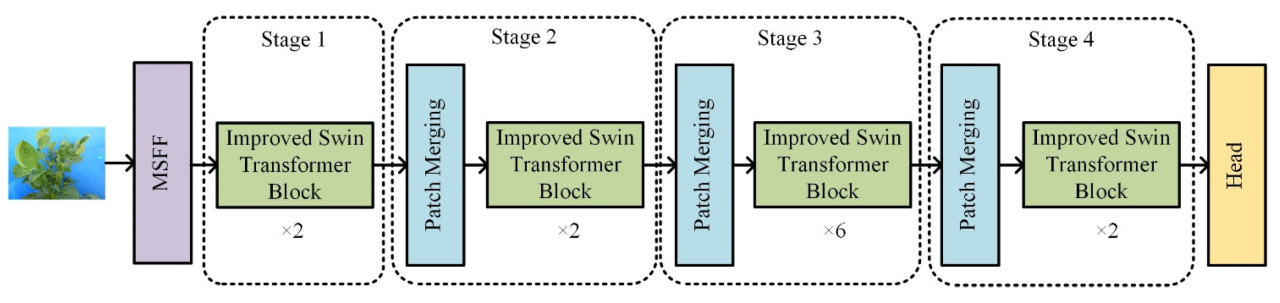
Изображения растений картофеля были сначала пропущены через разработанный модуль слияния многомасштабных признаков. Традиционный метод разбиения на фрагменты разбивает изображение на блоки фиксированного размера, что потенциально приводит к упущению глобальной информации и снижению производительности модели при обработке изображений разного масштаба. Модуль слияния многомасштабных признаков, напротив, эффективно обрабатывает признаки разного масштаба, повышая универсальность модели. Этот модуль учитывает как локальную, так и глобальную информацию, что позволяет модели глубже понимать структуру и содержание изображения. Таким образом, в модели Swin Transformer начальное разбиение на фрагменты и слой линейного встраивания этапа 1 заменены модулем слияния многомасштабных признаков. Это улучшение призвано повысить производительность модели и расширить возможности обобщения.
Полученные многомасштабные объединенные признаки впоследствии вводятся в улучшенный блок Swin Transformer для дальнейшей обработки. В задаче распознавания изображений растений крайне важно тщательно извлекать и использовать признаки, чтобы сеть могла собирать более ценную информацию. Свёрточные нейронные сети обычно используются в задачах распознавания изображений растений. Чтобы повысить производительность сети и смягчить проблему деградации модели из-за чрезмерной глубины сети, в свёрточных сетях часто используются остаточные связи. В этой главе концепция остаточного обучения интегрируется в блок Swin Transformer, показанный на рисунке 10. По сравнению с исходным блоком Swin Transformer, этот улучшенный блок Swin Transformer сохраняет свой механизм наслоения и движущегося окна собственного внимания и дополнительно включает остаточное обучение, которое не только позволяет сети расширяться до более глубокого уровня, но и гарантирует, что градиент может быть передан непосредственно в глубину сети, эффективно смягчая проблему исчезающих градиентов. Конструкция остаточной связности позволяет исходному входному сигналу обходить промежуточный слой и напрямую достигать задней части сети, обеспечивая плавную передачу информации через неё. Кроме того, такая структура помогает сети запоминать более сложные представления признаков, что, в свою очередь, повышает общую производительность при распознавании и классификации.

Затем отображение признаков, обработанное усовершенствованным блоком Swin Transformer, проходит операцию слияния патчей. Этот этап в основном включает агрегацию и снижение размерности локальных окрестностных патчей изображений для построения представлений признаков на более высоком уровне абстракции, тем самым снижая пространственную размерность модели без потери наиболее важной семантической информации.
Наконец, высокоуровневые признаки, сформированные в результате серии описанных выше процессов, поступают непосредственно в классификационный слой. Основываясь на ранее накопленной многоуровневой и многомасштабной информации о признаках, классификационный слой генерирует распределения вероятностей признаков каждой категории растений картофеля через многоуровневый ленточный процессор (MLP), чтобы получить наиболее вероятные категории признаков в качестве конечного результата.
В заключение следует отметить, что модель MSR-SwinT представляет собой мощный инструмент для комплексного анализа признаков растений картофеля, умело объединяющий преимущества многомасштабного извлечения признаков, остаточного обучения и Swin Transformer. Ожидается, что такой подход значительно улучшит автоматизацию и интеллектуальность анализа изображений картофеля.
2.6 Экспериментальная среда и настройка параметров
Эксперимент проводился в компьютерной среде под управлением Windows 11, оснащенной процессором Intel(c) Core(TM) i7-13700 13-го поколения и графическим процессором NVIDIA GeForce RTX 4090. Подробная информация о конфигурации экспериментальной среды представлена в таблице 4 .

Модель была обучена с использованием алгоритма оптимизации AdamW с коэффициентом снижения веса 5E-2. Для расчёта была выбрана функция кросс-энтропийных потерь. В процессе обучения модели размер партии был установлен равным 16, эпоха — 100, и после нескольких итераций и отладки скорость обучения в итоге достигла 0,00002.
2.7. Индикаторы для оценки модели
В области глубокого обучения метрики оценки модели являются центральным средством оценки её эффективности, помогая глубоко понимать и сравнивать эффективность различных моделей, а также играя ключевую роль на этапах выбора и оптимизации модели. Поскольку разные задачи имеют свои уникальные цели обучения, метрики, используемые для оценки эффективности модели, различаются и должны подбираться индивидуально для каждой конкретной задачи. В задачах мультиклассификации сложно полностью отразить эффективность модели одной метрикой. Поэтому для полной оценки эффективности модели необходимо использовать несколько метрик.
Основными метриками оценки, используемыми в данной статье для оценки модели, являются точность, прецизионность, полнота, специфичность, значение F1 и матрица путаницы. Точность — это мера процента правильно классифицированных моделью образцов из общего тестового набора. Это самая простая метрика оценки, однако она может упускать из виду влияние дисбаланса категорий. Точность — это процент всех образцов, предсказанных моделью как положительные случаи, которые действительно являются положительными случаями. Полнота — это доля всех образцов, фактически являющихся положительными случаями, которые правильно предсказаны моделью как положительные случаи. Специфичность — это доля отрицательных случаев, правильно предсказанных моделью, из всех образцов, которые фактически являются отрицательными случаями. F1 — это комбинация точности и полноты, уравновешенная согласованным средним значением точности и полноты. Формулы для каждого показателя показаны в уравнениях (4)–(8).

где TP указывает на то, что модель правильно идентифицирует образцы, относящиеся к положительной категории; FP представляет случаи, когда модель ошибочно классифицирует образцы в отрицательной категории как положительные; TN обозначает ситуацию, когда модель успешно идентифицирует образцы, относящиеся к отрицательной категории; FN означает, что модель не может идентифицировать образцы, которые фактически относятся к положительной категории, и неправильно классифицирует их как отрицательные.
Матрица путаницы [ 28 ] является основополагающим инструментом для оценки эффективности и точности модели в задачах классификации. Она обеспечивает всестороннее и понятное представление оценки. Сравнивая фактическую классификацию с прогнозами модели, матрица путаницы может классифицировать образцы по четырем основным категориям с высокой степенью точности. Четырьмя категориями классификации являются истинно положительные (TP), ложноположительные (FP), истинно отрицательные (TN) и ложноотрицательные (FN). Матрица путаницы обеспечивает систематическую схему этих основных показателей, которые напрямую отражают точность и распределение ошибок модели классификации при оценке каждой категории. Таким образом, она является неотъемлемой частью измерения и понимания производительности модели.
3. Экспериментальные результаты и обсуждение
3.1 Анализ результатов эксперимента по абляции
Для проверки эффективности улучшенной модели MSR-SwinT в задаче классификации изображений растений картофеля в качестве экспериментальных данных использовался набор данных data_150, а также была принята следующая схема эксперимента: (a) использование только модели Swin Transformer; (b) добавление модуля слияния многомасштабных признаков поверх модели Swin Transformer, обозначенного как Multi-scale-SwinT; (c) введение остаточного обучения в блок Swin Transformer, обозначенного как Res-SwinT; (d) использование улучшенного метода в b и c, т.е. улучшенной модели MSR-SwinT. Экспериментальные результаты четырёх схем удаления представлены в таблице 5 .

Как видно из Таблицы 5 , Схема b после интеграции модуля слияния многомасштабных признаков в модель Swin Transformer, точность тестового набора увеличилась на 2,88% по сравнению с исходной моделью Swin Transformer, и этот результат указывает на то, что модуль слияния многомасштабных признаков может эффективно улучшить извлечение признаков изображений растений картофеля. В схеме c механизм остаточного обучения вводится в блок Swin Transformer, и точность тестового набора модели увеличивается на 1,39% по сравнению с моделью Swin Transformer, что указывает на положительный эффект остаточного обучения в улучшении производительности модели, что помогает модели лучше учиться и сохранять важную информацию о признаках на изображении. Улучшенная модель MSR-SwinT, которая также использует сценарии b и c, достигла точности 94,64% на тестовом наборе, что на 3,02% лучше, чем у исходной модели Swin Transformer, что наглядно демонстрирует превосходную производительность улучшенной модели в задаче классификации изображений растений картофеля.
3.2 Анализ влияния скорости обучения на модель
В данной работе были выбраны четыре различных значения скорости обучения: 0,0001, 0,00005, 0,00002 и 0,00001. Эксперименты проводились на наборе данных data_150. Кривые точности обучения, полученные по результатам экспериментов, показаны на рисунке 11 .
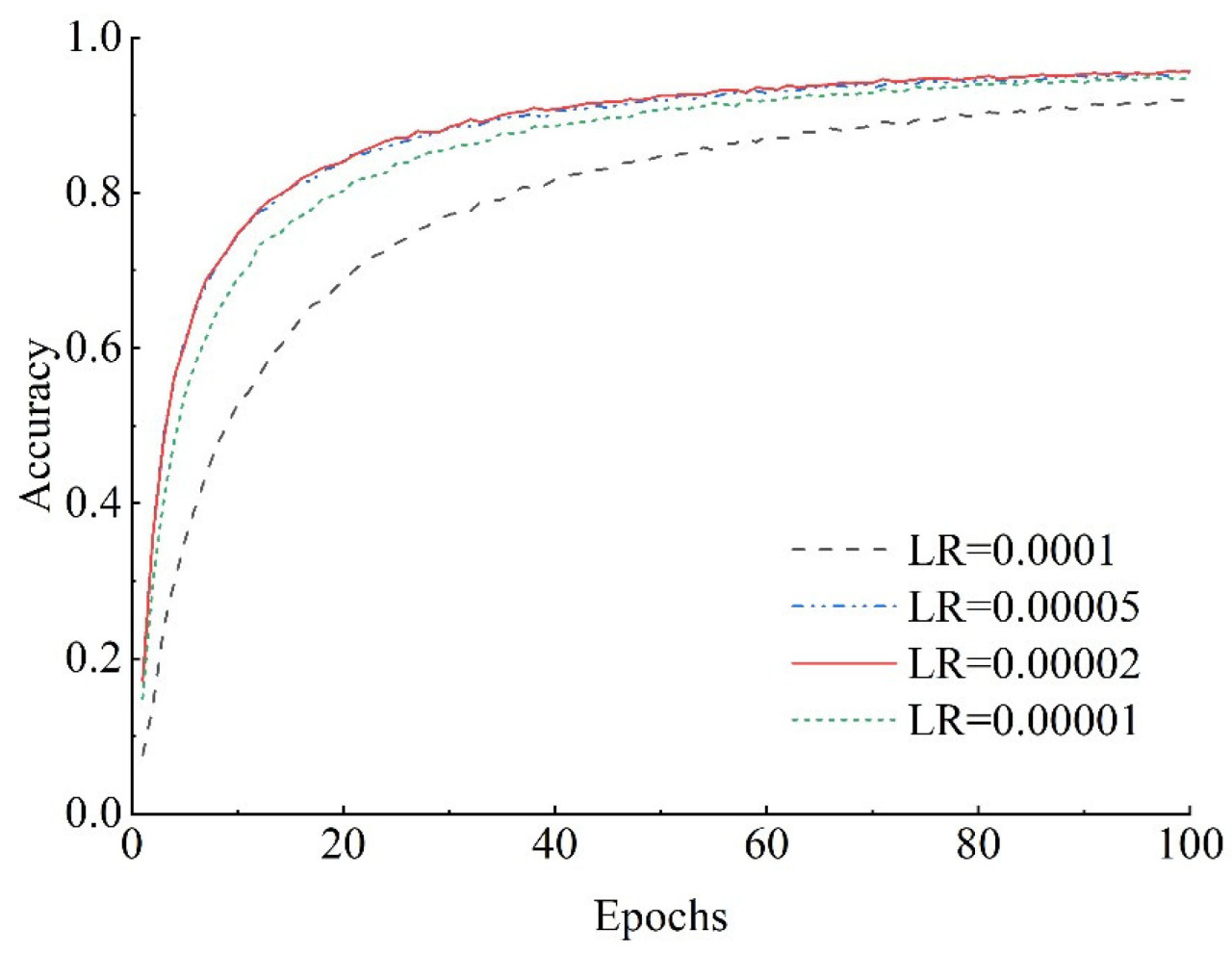
Как видно из рисунка 11 , модель сходится медленнее всего при скорости обучения 0,0001 и начинает постепенно сходиться только примерно после 90 циклов итераций обучения. С другой стороны, другие скорости обучения начинают демонстрировать тенденцию к сходимости примерно после 70 циклов итераций. Сравнивая результаты обучения со скоростью обучения 0,00005 и скоростью обучения 0,00002, было обнаружено, что, хотя большой разницы в точности распознавания между ними не было, модель со скоростью обучения 0,00002 показала гораздо лучшие результаты как с точки зрения скорости сходимости, так и итоговой точности. В целом, было обнаружено, что установка скорости обучения 0,00002 была наилучшим выбором для модели сети в этой главе.
3.3 Оценка эффективности модели
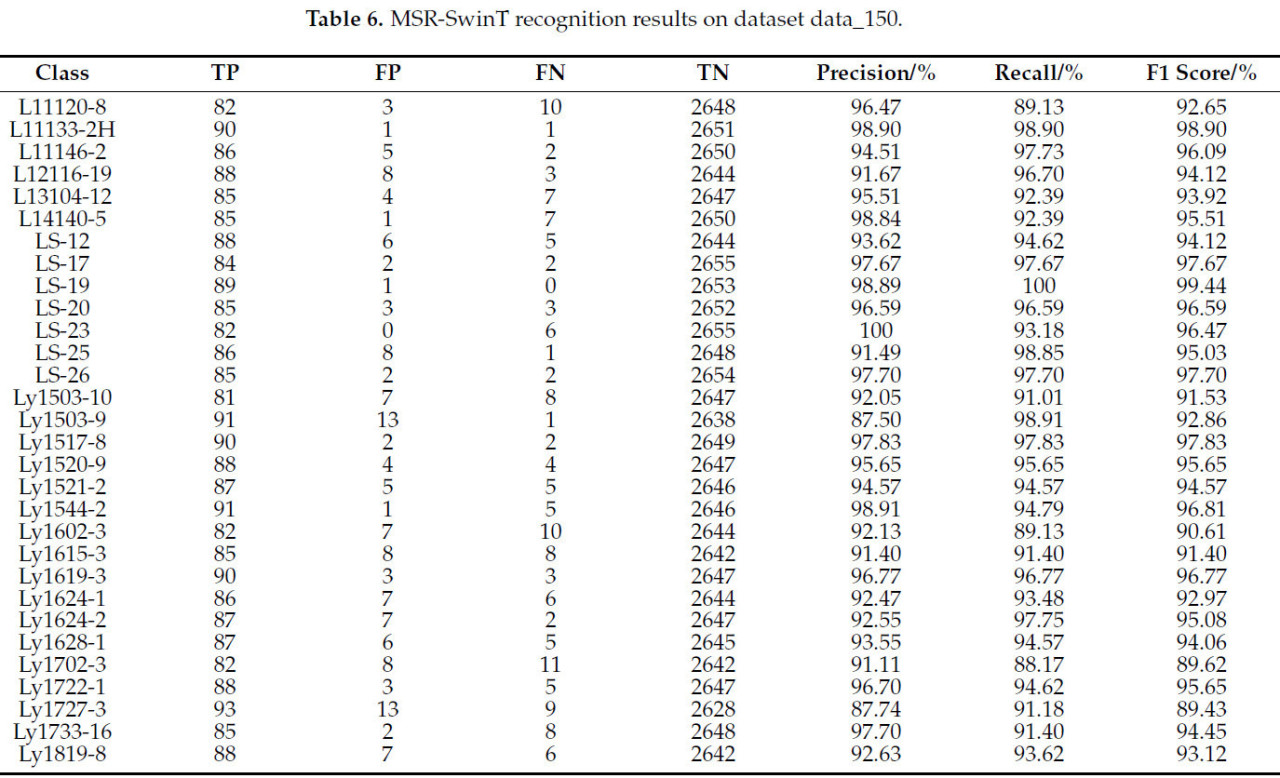
Для проведения всестороннего и глубокого анализа производительности улучшенной модели MSR-SwinT мы проверили ее производительность на тестовом наборе data_150. Результаты представлены в Таблице 6. Результаты анализа показывают, что модель MSR-SwinT демонстрирует наивысшую точность при идентификации сорта LS-19, при этом все 89 образцов были предсказаны правильно. Кроме того, модель продемонстрировала высокую степень точности при идентификации сортов L11133-2H, LS-25 и Ly1503-9. Только один образец в каждом сорте был предсказан неверно, как и другие сорта. Однако модель продемонстрировала неоптимальную производительность при идентификации сортов L11120-8, Ly1602-3 и Ly1702-3, при этом 10 или 11 образцов в каждом из этих сортов были предсказаны неверно соответственно. В целом, модель MSR-SwinT продемонстрировала удовлетворительные результаты по большинству переменных: точность, полнота и значения F1 превысили 90%. Однако для некоторых сортов сохранились некоторые трудности с идентификацией.
3.4 Визуализация модели
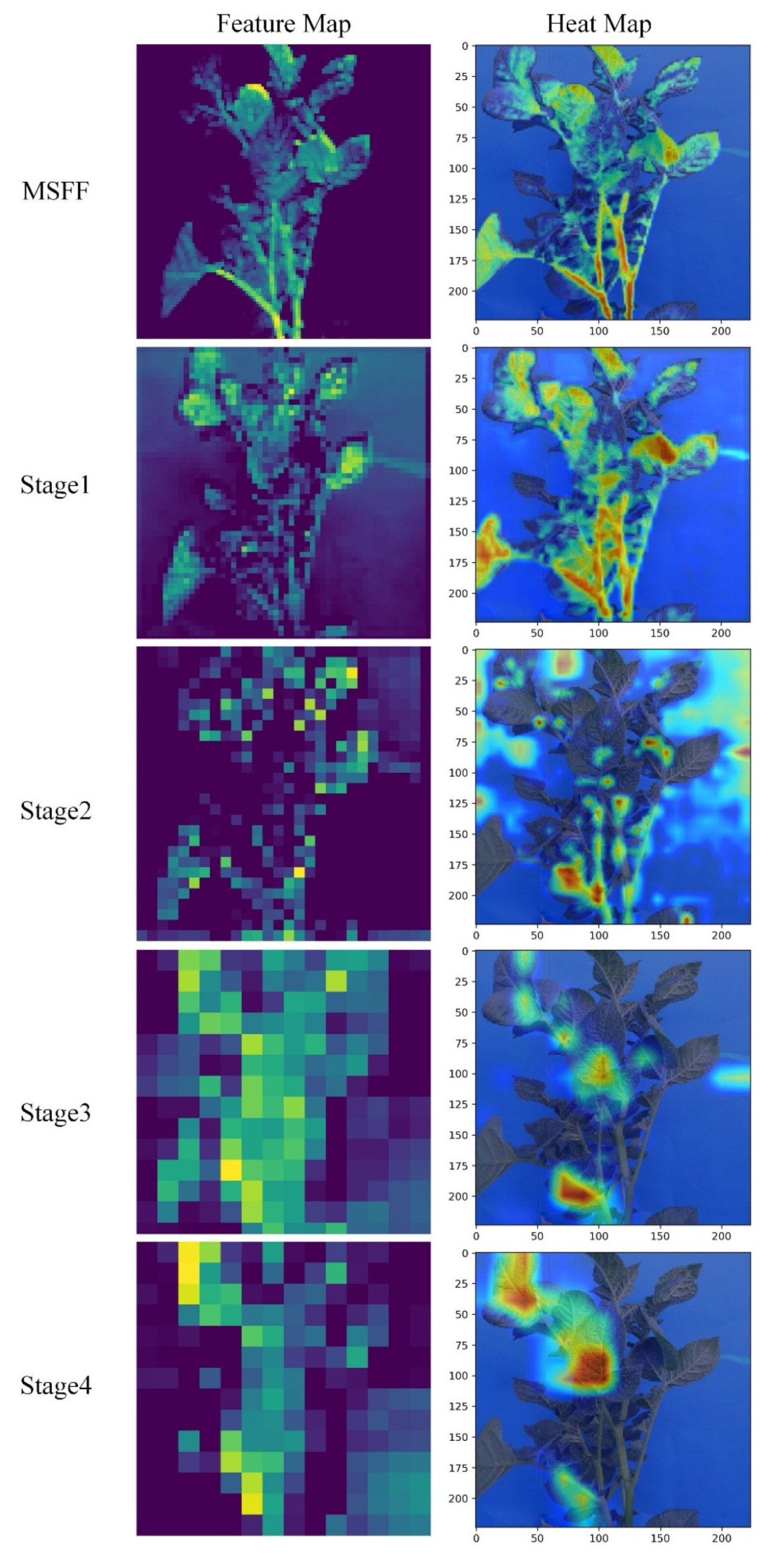
Чтобы визуализировать возможности модели MSR-SwinT в задаче идентификации растений картофеля, модель была визуализирована и проанализирована с использованием карт признаков и тепловых карт, соответственно, а результаты показаны на рисунке 12. Карты признаков одного канала были выбраны для анализа в этом процессе, чтобы более точно понять механизм извлечения признаков в модели. Grad-CAM [ 29 ] использовался для создания тепловых карт, которые выделяли ключевые области в процессе принятия решений при моделировании, тем самым еще больше улучшая визуальный анализ. Карта признаков иллюстрирует, что по мере углубления слоев сети признаки, извлекаемые моделью, эволюционируют от низкоуровневой базовой информации, такой как края и текстуры, к высокоуровневым структурным и семантическим признакам. Это отражает непрерывное абстрагирование и обобщение входной информации в процессе обучения модели. Тепловая карта демонстрирует, что модель MSR-SwinT способна эффективно выделять существенные признаки растения, одновременно уменьшая внимание, уделяемое нерелевантным фоновым факторам.
3.5 Сравнительный экспериментальный анализ различных моделей
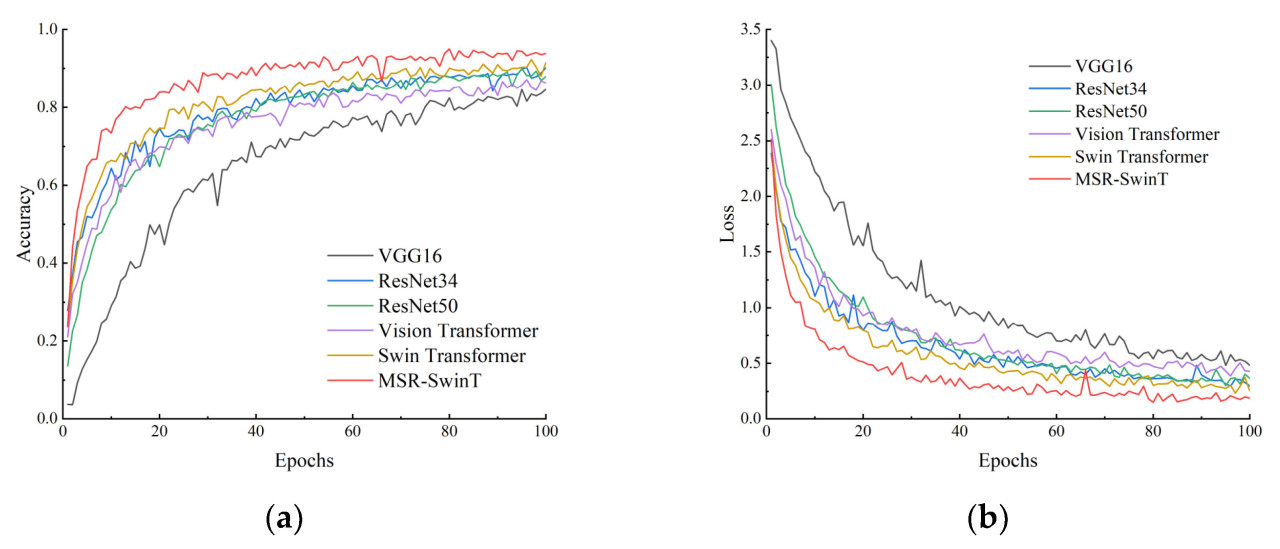
Для дальнейшего анализа производительности улучшенной модели модель MSR-SwinT сравнивается с обычно используемыми моделями сверточных нейронных сетей (включая VGG16 [ 30 ], ResNet34, ResNet50) и моделями Transformer (Vision Transformer [ 31 ] и Swin Transformer) в области распознавания изображений в сравнительных экспериментах на наборе данных data_150, а кривые точности и потерь полученного проверочного набора показаны на рисунке 13. Как видно на рисунке 13 , улучшенная модель MSR-SwinT показывает более быструю сходимость, чем другие модели во время обучения, и достигает 90% точности примерно через 40 эпох, и в то же время ее значение потерь значительно ниже, чем у других моделей. Модель VGG16 имеет самую медленную скорость сходимости и самую низкую точность из всех моделей. Сравнивая модели ResNet34 и ResNet50, можно отметить, что ResNet34 сходится быстрее, чем ResNet50, и имеет немного более высокую итоговую точность, чем ResNet50. Причина этого в том, что ResNet50 может вызывать взрыв градиента, тогда как более поверхностная сеть ResNet34 может лучше избегать проблемы взрыва градиента.
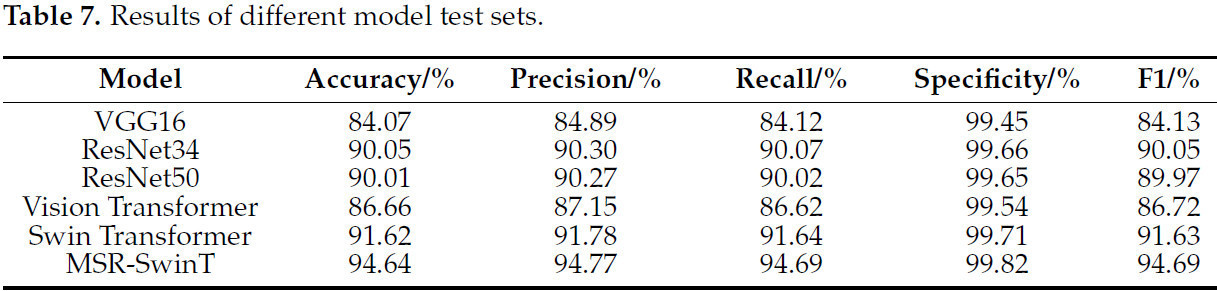
Лучшие веса, полученные из проверочного набора, применяются к тестовому набору, а полученные экспериментальные результаты показаны в Таблице 7. Как видно из Таблицы 7 , улучшенная модель MSR-SwinT превосходит остальные четыре модели по точности, прецизионности, полноте, специфичности и значению F1 с показателями 94,64%, 94,77%, 94,69%, 99,82% и 94,69% соответственно. Этот результат свидетельствует о том, что улучшенная модель MSR-SwinT демонстрирует высокую производительность и эффективность при обнаружении растений картофеля, а ее превосходные характеристики по ключевым показателям, таким как точность, подтверждают хорошую применимость модели в конкретных сценариях применения. В частности, модель может точно идентифицировать и различать растения картофеля, предоставляя надежный инструмент для соответствующих исследований и практики.
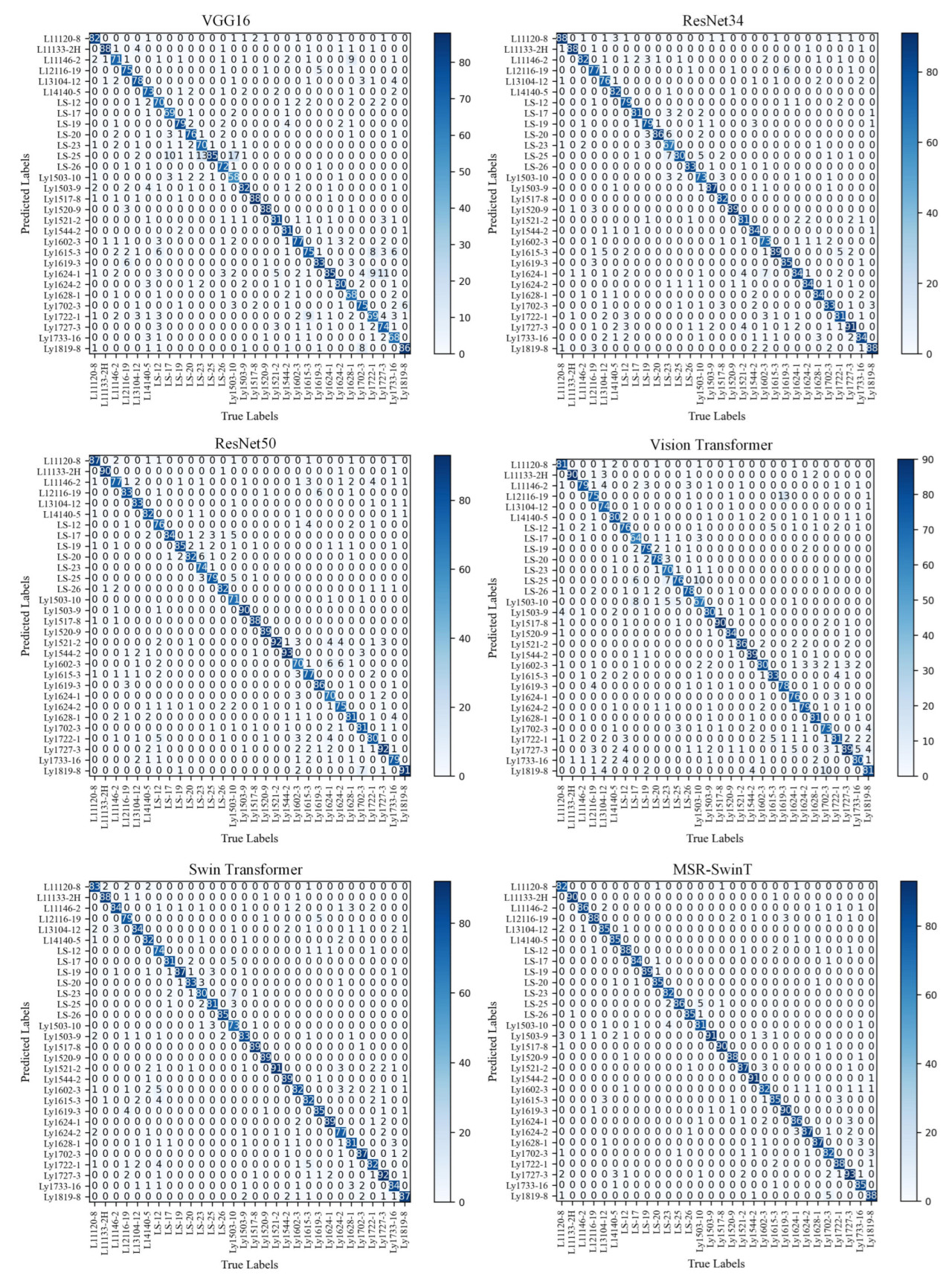
Матрица ошибок для каждой модели на наборе данных data_150 представлена на рисунке 14. Глубина цвета диагональной линии в матрице ошибок отображает точность распознавания каждой категории, причем более темные цвета указывают на более высокую скорость правильного распознавания для этой категории. Как показано на рисунке 14 , матрица ошибок модели MSR-SwinT демонстрирует более темный диагональный цвет по сравнению с другими моделями. Модель MSR-SwinT продемонстрировала особенно высокую производительность при идентификации сорта LS-19, правильно предсказав все 89 образцов. Для сортов L11133-2H, LS-25 и Ly1503-9 модель также показала хорошие результаты, только один образец был неправильно классифицирован для каждого из этих сортов. Это наблюдение убедительно свидетельствует о том, что модель MSR-SwinT демонстрирует превосходную производительность при распознавании видов растений картофеля, демонстрируя самую высокую точность распознавания для каждого вида.
3.6 Анализ экспериментальных результатов с различными размерами выборок
Чтобы исследовать влияние различных размеров выборки на эффективность модели, из исходного набора данных data_150 были созданы четыре новых набора данных путем случайного выбора разного количества образцов для каждого сорта. В частности, для каждого сорта были случайным образом выбраны 100, 70, 50 и 40 растений, чтобы создать четыре набора данных разного размера. Такой экспериментальный дизайн помогает проанализировать вариацию эффективности модели в условиях разного размера выборки, чтобы оценить ее стабильность и надежность. Показатели точности моделей VGG16, ResNet34, ResNet50, Vision Transformer, Swin Transformer и MSR-SwinT на проверочных наборах с размерами выборки 150, 100, 70, 50 и 40 стеблей представлены в Таблице 8 .
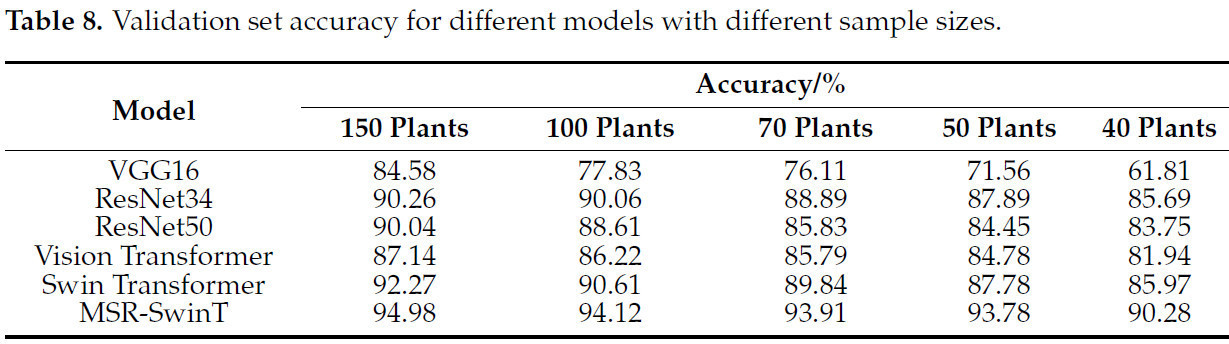
Из Таблицы 8 ясно видно, что улучшенная модель MSR-SwinT демонстрирует лучшие эффекты распознавания, чем другие модели, на наборах данных разного размера. Анализируя несколько наборов данных с разным размером выборки, можно увидеть, что эффективность распознавания каждой модели постепенно улучшается по мере увеличения размера выборки. Причина этого явления заключается в том, что больше данных предоставляет моделям более богатую и разнообразную информацию о признаках, что не только помогает моделям улавливать более тонкие различия категорий, но и позволяет моделям демонстрировать более высокую точность и более сильную обобщающую способность в задаче распознавания. Следовательно, это открытие предполагает, что при достаточном количестве данных каждая модель может демонстрировать значительные преимущества и что в реальных сценариях применения увеличение объема собранных данных, вероятно, дополнительно улучшит производительность моделей.
3.7 Анализ экспериментальных результатов на различных наборах данных
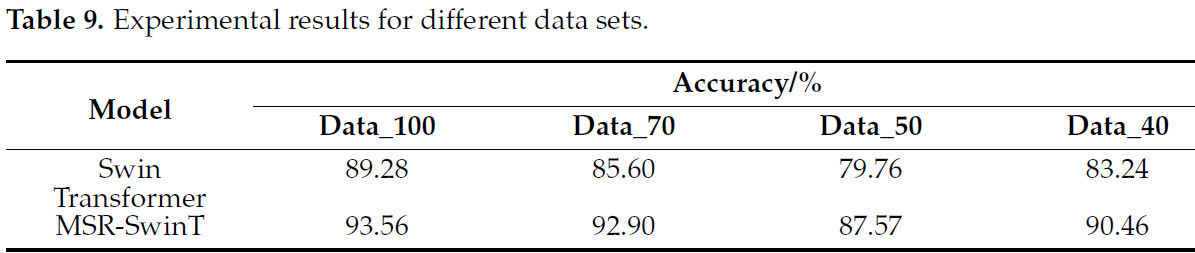
Модель Swin Transformer и модель MSR-SwinT были экспериментально протестированы на различных наборах данных data_100, data_70, data_50 и data_40, а полученные экспериментальные результаты показаны втаблице 9.
Наборы данных data_100, data_70, data_50 и data_40, прошедшие процесс улучшения данных, теперь называются aug_data_100, aug_data_70, aug_data_50 и aug_data_40 соответственно. Затем к расширенному набору данных применяется модель Swin Transformer с моделью MSR-SwinT, и полученные экспериментальные результаты представлены в таблице 10 .
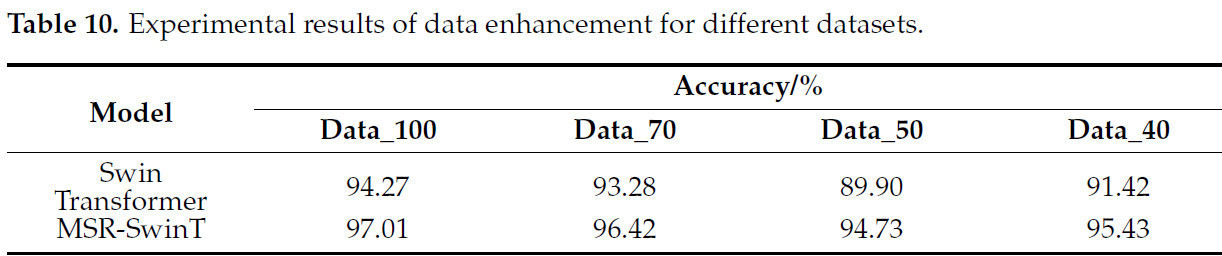
Из Таблицы 9 видно , что точность улучшенной модели MSR-SwinT в целом выше, чем у модели Swin Transformer на различных наборах данных, что подтверждает эффективность мер по улучшению, принятых в данной главе, и указывает на более высокую эффективность модели MSR-SwinT при распознавании изображений растений картофеля. В то же время, из Таблицы 10 видно , что точность как модели Swin Transformer, так и модели MSR-SwinT повышается после расширения данных, что свидетельствует о том, что расширение данных является эффективным средством повышения эффективности распознавания модели.
Table 9 and Table 10 show not only the performance of the MSR-SwinT model on different data sets but also an interesting phenomenon: although the data volume of data_40 is smaller than that of data_50, its accuracy rate is relatively high. By carefully comparing the original images of these two datasets, it was found that the images in the data_50 dataset contained more background and other distracting factors, which may have negatively affected the model’s recognition ability, leading to its relatively low accuracy. This further emphasizes that in an image dataset, in addition to the number of samples, the quality and relevance of the samples are also key factors affecting the performance of the model. Therefore, careful screening and preprocessing of images to minimize the influence of irrelevant factors during the data preparation stage is essential to improve model accuracy.
3.8. Обсуждение
Применение технологий глубокого обучения в области идентификации сортов картофеля может значительно повысить точность идентификации, что положительно сказывается на управлении ресурсами зародышевой плазмы картофеля и обеспечении безопасности пищевых продуктов. Свёрточная нейронная сеть обладает высокой способностью к извлечению локальных признаков изображения, обеспечивает сквозное обучение и вывод на протяжении всего процесса распознавания и эффективно извлекает ключевые локальные признаки из входного изображения для достижения точного распознавания. Уникальной особенностью Visual Transformer является использование механизма самовосприятия, который позволяет эффективно улавливать взаимозависимость между любыми двумя точками изображения, что очень важно для определения ключевых признаков сортов, особенно при обработке глобальной контекстной информации и выявлении потенциальных мелких различий.
В данной работе были собраны и построены наборы данных о растениях картофеля с различными размерами выборки, содержащие в общей сложности 69 сортов картофеля. Для эффективной идентификации растений картофеля была улучшена модель Swin Transformer. Модуль слияния многомасштабных признаков был использован для замены патч-разбиения модели Swin Transformer и линейного встраивания этапа 1, что не только эффективно объединило признаки разных масштабов, но и улучшило обобщающую способность модели. В то же время в блочный механизм Swin Transformer было введено остаточное обучение, что способствует плавному потоку информации и улучшает передачу признаков, тем самым сохраняя более сложные признаки на изображении. Точность распознавания улучшенной модели MSR-SwinT улучшена на 3,02 процентных пункта по сравнению с исходной моделью Swin Transformer.
Различные скорости обучения существенно влияют на результаты обучения модели. Изменение скорости обучения может повлиять на скорость сходимости, стабильность и итоговую производительность модели. Более низкая скорость обучения может повысить стабильность обучения модели, но привести к снижению скорости сходимости, в то время как более высокая скорость обучения может ускорить её, но может увеличить флуктуации в процессе обучения или даже привести к тому, что модель не сойдётся. Поэтому выбор подходящей скорости обучения критически важен для оптимизации модели. Задавая различные скорости обучения для сравнительных экспериментов, мы в итоге решили установить скорость обучения равной 0,00002.
Объем данных также является ключевым фактором, существенно влияющим на эффективность модели. Серия экспериментов с выборками разного размера позволила проследить четкую тенденцию: с увеличением объема обучающих данных эффективность распознавания модели повышается. Другими словами, чем больше объем данных, тем лучше модель справляется с задачей распознавания.
Кроме того, в данной статье для экспериментальной проверки на нескольких различных наборах данных выбраны базовая модель Swin Transformer и улучшенная модель MSR-SwinT. Для дальнейшей проверки влияния объёма данных на производительность модели используются соответствующие методы расширения данных на различных наборах данных. Экспериментальные результаты показывают, что улучшенная модель MSR-SwinT обеспечивает значительное повышение производительности при идентификации растений картофеля, что подтверждает эффективность принятых мер. Более того, расширение набора данных способствует повышению эффективности обнаружения модели. Кроме того, эксперименты показывают, что качество изображений данных существенно влияет на производительность модели и является одним из важнейших факторов, влияющих на её точность распознавания.
4. Выводы
В связи с отсутствием исследований в области классификации сортов картофеля, а также учитывая особенности растений картофеля с мощным ростом, густой листвой и обычно вертикально растущими или стелющимися и раскидистой формой стеблей, была предложена модель распознавания растений картофеля MSR-SwinT. Модель Swin Transformer была улучшена с помощью модуля слияния многомасштабных признаков и механизма остаточного обучения. Улучшенная модель MSR-SwinT хорошо справилась с задачей классификации растений картофеля с точностью 94,64% на тестовом наборе. Улучшение качества классификации MSR-SwinT было дополнительно подтверждено сравнением матриц ошибок моделей Swin Transformer и MSR-SwinT.
Для дальнейшей оценки производительности MSR-SwinT были проведены сравнительные эксперименты с моделями VGG16, ResNet34, ResNet50 и Vision Transformer. Результаты показывают, что точность распознавания модели MSR-SwinT превосходит эти модели на 10,57%, 4,59%, 4,63% и 7,89% соответственно. Это демонстрирует превосходную производительность модели MSR-SwinT в задаче распознавания растений картофеля.
Модель MSR-SwinT демонстрирует образцовые возможности обработки визуальной информации, о чём свидетельствуют интегрированный модуль многомасштабных признаков, метод остаточного обучения и технология Swin Transformer. Модель повышает чувствительность к различным типам размерных признаков благодаря многомасштабной обработке признаков, тем самым углубляя всестороннее понимание локальных, едва заметных особенностей и общей структуры изображения и сцены. Интеграция механизма остаточного обучения эффективно решает распространённую проблему исчезновения градиентов при глубоком обучении сети, тем самым повышая способность модели к обучению сложных представлений признаков, ускоряя процесс обучения и улучшая её производительность. В основе Swin Transformer лежит инновационная система вычисления внутреннего внимания и стратегия динамического скользящего окна, которые совместно обеспечивают заметное повышение вычислительной эффективности. Это достигается при сохранении выразительной мощности архитектуры Transformer.
В настоящее время наблюдается дефицит научной литературы по идентификации сортов картофеля. Данное исследование закладывает основу для последующих исследований в области идентификации сортов картофеля и технической поддержки обеспечения их безопасности. Тем не менее, несмотря на эффективность MSR-SwinT в повышении вычислительной мощности и производительности, его сложная структура и повышенные требования к ресурсам имеют важное значение, особенно в условиях ограниченных аппаратных ресурсов. Более того, если целью является внедрение системы на мобильных устройствах, эти факторы становятся серьёзными проблемами, требующими решения. В будущем для уменьшения размера модели и оптимизации вычислительного процесса могут быть использованы сжатие модели, квантование, обрезка и другие методы, что позволит достичь максимальной производительности в условиях ограниченных ресурсов.
В будущем мы сосредоточимся на повышении эффективности модели и расширении её применения в различных аспектах. С одной стороны, мы будем активно собирать данные о картофеле из разных регионов и сезонов и строить временные ряды для обогащения разнообразия образцов. Одновременно мы будем сравнивать новые модели, появившиеся за последние два года, для оптимизации MSR — SwinT. С другой стороны, мы будем активно изучать её практическое применение в картофелеводстве, например, интегрировать её в автоматизированную систему идентификации в полевых условиях для достижения точного управления посадкой. Мы также изучим её применение в других звеньях производственной цепочки. Кроме того, благодаря целенаправленным корректировкам модель будет адаптирована к различным сортам сельскохозяйственных культур и расширена для решения таких сельскохозяйственных задач, как обнаружение вредителей и болезней и мониторинг окружающей среды, обеспечивая комплексную техническую поддержку для устойчивого развития сельского хозяйства.
Ссылки
1. Yang, Y.; Li, G.; Cheng, C. Optimisation of potato planting layout and restructuring of positioning: An elaboration of social embeddedness theory. Rural Econ. 2023, 03, 48–57. [Google Scholar]
2. Wang, X.; Chen, M. Retrospect and prospect of potato development. Issues Agric. Econ. 2020, 123–130. [Google Scholar] [CrossRef]
3. Zhong, Y. Uses of potato and its development prospect. Rural Sci. Technol. 2016, 39–41. [Google Scholar] [CrossRef]
4. Naznin, F.; Haque, M.A.; Rahman, M.H.S.; Rahman, M.H.A.; Mehedi, M.N.H. Molecular Diversity Analysis of Indigenous Potato Cultivars Using RAPD Markers. Asian J. Biochem. Genet. Mol. Biol. 2020, 6, 43–48. [Google Scholar] [CrossRef]
5. Yin, X.; Zhang, X. Application of AFLP molecular markers in genetic breeding of eggplant and fruit vegetables. Chin. Agric. Sci. Bull. 2009, 25, 25–31. [Google Scholar]
6. Wang, X.; Hui, Z.; Xu, J.; Duan, S.; Bian, C.; Jin, L.; Li, G. Histo-cytological study on potato potato shape development. China Veg. 2020, 67–73. [Google Scholar] [CrossRef]
7. Hu, H. Fundamentals of Machine Learning; Electronic Industry Press: Beijing, China, 2019; p. 384. [Google Scholar]
8. Zhang, H.; Zhang, Y.; Wang, L.; Hu, Z.; Zhou, W.; Tsang, P.W.; Cao, D.; Poon, T.-C. Study of Image Classification Accuracy with Fourier Ptychography. Appl. Sci. 2021, 11, 4500. [Google Scholar] [CrossRef]
9. Zhang, Z.; Ji, Y.; Man, W. Improved random forest algorithm for image classification applications. Comput. Syst. Appl. 2018, 27, 193–198. [Google Scholar]
10. Fu, L.; Zhang, M.; Liu, Z.; Li, H.; He, T. Adaptive hybrid feature extraction for leaf image classification by support vector machine. J. Converg. Inf. Technol. 2012, 7, 160–166. [Google Scholar]
11. Xu, j.; Wang, J.; Xu, X.; Ju, S. Rice fertility image recognition based on RAdam convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 143–150. [Google Scholar]
12. Li, J.; Xu, F.; Song, S.; Qi, J. A maize seed variety identification method based on improving deep residual convolutional network. Front. Plant Sci. 2024, 15, 1382715. [Google Scholar] [CrossRef] [PubMed]
13. Taheri-Garavand, A.; Nasiri, A.; Fanourakis, D.; Fatahi, S.; Omid, M.; Nikoloudakis, N. Automated In Situ Seed Variety Identification via Deep Learning: A Case Study in Chickpea. Plants 2021, 10, 1406. [Google Scholar] [CrossRef] [PubMed]
14. Liu, C.; Han, J.; Chen, B.; Mao, J.; Xue, Z.; Li, S. A Novel Identification Method for Apple (Malus domestica Borkh.) Cultivars Based on a Deep Convolutional Neural Network with Leaf Image Input. Symmetry 2020, 12, 217. [Google Scholar] [CrossRef]
15. Gao, J.; Liu, C.; Han, J.; Lu, Q.; Wang, H.; Zhang, J.; Bai, X.; Luo, J. Identification Method of Wheat Cultivars by Using a Convolutional Neural Network Combined with Images of Multiple Growth Periods of Wheat. Symmetry 2021, 13, 2012. [Google Scholar] [CrossRef]
16. Laabassi, K.; Belarbi, M.A.; Mahmoudi, S.; Mahmoudi, S.A.; Ferhat, K. Wheat varieties identification based on a deep learning approach. J. Saudi Soc. Agric. Sci. 2021, 20, 281–289. [Google Scholar] [CrossRef]
17. Guo, Y. Research and Application of Potato Variety Classification Based on Convolutional Neural Network; Gansu Agricultural University: Lanzhou, China, 2023. [Google Scholar]
18. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
19. Liu, Y.; Liu, H.; Shi, T.; Ouyang, J.; Huang, H.; Xie, T. An optimised Swin Transformer tomato leaf disease identification method. J. China Agric. Univ. 2023, 28, 80–90. [Google Scholar]
20. Fu, L.; Huang, H.; Wang, H.; Huang, S.; Chen, D. Classification of maize growing period based on Swin Transformer model. Trans. Chin. Soc. Agric. Eng. 2022, 38, 191–200. [Google Scholar]
21. Wang, F.; Rao, Y.; Luo, Q.; Jin, X.; Jiang, Z.; Zhang, W.; Li, S. Practical cucumber leaf disease recognition using improved Swin Transformer and small sample size. Comput. Electron. Agric. 2022, 199, 107163. [Google Scholar] [CrossRef]
22. Reedha, R.; Dericquebourg, E.; Canals, R.; Hafiane, A. Transformer Neural Network for Weed and Crop Classification of High Resolution UAV Images. Remote Sens. 2022, 14, 592. [Google Scholar] [CrossRef]
23. Borhani, Y.; Khoramdel, J.; Najafi, E. A deep learning based approach for automated plant disease classification using vision transformer. Sci. Rep. 2022, 12, 11554. [Google Scholar] [CrossRef] [PubMed]
24. Luo, J. Research on Variety Recognition and Classification of Potato Images Based on Deep Learning; Gansu Agricultural University: Lanzhou, China, 2023. [Google Scholar]
25. Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
26. Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
27. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
28. Chen, J.; Han, J.; Liu, C.; Wang, Y.; Shen, H.; Li, L. A Deep-Learning Method for the Classification of Apple Varieties via Leaf Images from Different Growth Periods in Natural Environment. Symmetry 2022, 14, 1671. [Google Scholar] [CrossRef]
29. Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
30. Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
31. Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]

Xing X, Liu C, Han J, Feng Q, Qi E, Qu Y, Ma B. Potato Plant Variety Identification Study Based on Improved Swin Transformer. Agriculture. 2025; 15(1):87.
Перевод статьи «Potato Plant Variety Identification Study Based on Improved Swin Transformer» авторов Xing X, Liu C, Han J, Feng Q, Qi E, Qu Y, Ma B., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)