Распознавание сортов кукурузы в реальном времени с использованием эффективной архитектуры DenXt, оптимизированной для снижения вычислительных затрат
Являясь основной зерновой культурой в сельском хозяйстве Китая, урожайность и качество кукурузы напрямую связаны с продовольственной безопасностью и стабильным развитием аграрной экономики. Сорта кукурузы из разных регионов имеют значительные различия в характеристиках листовой пластины, тычиночных цветков и корневого чехлика, и эти различия обеспечивают основу для классификации сортов. Однако в реальных условиях выращивания характеристики сортов могут смешиваться, что увеличивает сложность идентификации. Исследования в области классификации на основе глубокого обучения, сфокусированные на характерных признаках кукурузы, могут помочь повысить точность классификации, оптимизировать управление посевами, повысить производительность и способствовать развитию технологий селекции и производства.
В данном исследовании мы создали набор данных растений кукурузы на стадии elongation, содержащий 31 000 изображений 40 различных типов, включающих листья, тычиночные цветки и корневые чехлики, и предложили модель каркаса DenXt. В модель DenseNet-121 была введена Representative Batch Normalization (RBN) для повышения способности к обобщению, а также интегрированы модуль SE и глубинная разделяемая свертка (deep separable convolution) для улучшения представления признаков и снижения вычислительной сложности. Кроме того, была применена регуляризация Dropout для дальнейшего повышения способности модели к обобщению и снижения переобучения.
Предложенная сетевая модель достигает точности классификации в 97,79%, что превосходит по производительности модели классификации изображений VGG16, Mobilenet V3, ResNet50 и ConvNeXt. По сравнению с исходной сетевой моделью DenseNet-121, модель DenXt улучшила точность классификации на 3,23% и сократила количество параметров на 32,65%. В заключение, новый подход решает проблемы, присущие сверточным нейронным сетям, и предоставляет легковесные сети, простые в развертывании, для поддержки приложений по распознаванию сортов кукурузы.
1. Введение
Согласно статистике Продовольственной и сельскохозяйственной организации Объединенных Наций (ФАО), мировое производство кукурузы продолжало расти с 1970 по 2022 год [1]. Исследования показали, что кукуруза [2] является важной зерновой культурой рода *Zea* семейства Злаки. Как одна из основных продовольственных культур, она оказывает существенное влияние на глобальную продовольственную безопасность, аграрную экономику, а также рынки биотоплива и промышленного сырья [3]. При классификации сортов кукурузы каждая часть растения играет важную роль в идентификации, поскольку морфологические характеристики различных органов часто отражают особенности сорта и могут служить основой для распознавания и классификации. В частности, форма листьев и текстура жилок могут отражать характеристики роста и адаптивности сорта [4]; размер и форма метелки тесно связаны с эффективностью опыления и генетическими характеристиками [5], в то время как структура корневого чехлика влияет на рост корневой системы и поглощение воды и питательных веществ [6], что проявляется в различиях между разными сортами. При фактическом выращивании характеристики сортов могут смешиваться, что создает трудности для точной идентификации. Эти различия могут служить основой для классификации сортов кукурузы в течение вегетационного периода и помогать различать схожие сорта. Особенно когда сорта похожи, использование характеристик каждой части растения позволяет повысить точность классификации.
В последние годы область компьютерного зрения достигла значительных успехов благодаря технологиям глубокого обучения, в частности, сверточным нейронным сетям (CNN). По сравнению с традиционными методами машинного обучения сверточные нейронные сети обладают значительными преимуществами в способности к обобщению, скорости обучения и извлечения признаков. Они могут автоматически извлекать важные характеристики непосредственно из изображений и классифицировать извлеченные признаки по соответствующим категориям, избегая сложного процесса ручного извлечения признаков в традиционных методах. За последние несколько лет использование технологий глубокого обучения для распознавания изображений также стало очень популярным в сельскохозяйственной отрасли [7]. Применение компьютерных технологий предоставляет эффективные решения для таких задач, как обнаружение вредителей сельскохозяйственных культур [8], классификация сортов [9], прогнозирование урожайности [10], выявление дефектов [11] и другие. В 2006 году Хинтон и др. [12] впервые предложили глубокую сеть доверия (DBN), что ознаменовало начало быстрого развития моделей глубокого обучения. В области мониторинга фенологических фаз сельскохозяйственных культур Расти и др. [13] использовали сверточную нейронную сеть ConvNets для классификации наземных изображений пшеницы и ячменя, собранных на стадии роста до смыкания полога. После трансферного обучения точность модели достигла 99,7–100%; Анами и др. [14] разработали框架 VGG16 CNN для автоматической классификации изображений рисовых культур, находящихся в состоянии стресса, снятых на стадии выхода в трубку, достигнув средней точности 92,89% на наборе данных; Сонг и др. [15] использовали платформу дистанционного зондирования с дронами для сбора многозональных изображений экспериментального поля и идентификации фенологической фазы подсолнечника в соответствии с различными популяционными характеристиками на разных стадиях роста. В сравнительных экспериментах улучшенная сеть PSPNet с использованием взвешенной функции потерь достигла наилучшей точности распознавания 89,01%. Сюй Цзяньпэн и др. [16] использовали сеть ResNet50 и оптимизатор RAdam для реализации идентификации фенологической фазы риса с точностью 97,33%; Лю Пинпин [17] предложила метод определения фазы цветения пшеницы на основе цветовых признаков и суперпиксельной сегментации. Точность распознавания цветка и колоска составила 91% и 90,9% соответственно; Хань Юэтин и др. [18] извлекли морфологические признаки из изображений кукурузы для определения стадий ее роста с хорошими результатами; Чжан Юньдэ и др. [19] применили признаки глубокой свертки для идентификации фенологических фаз кукурузы с точностью 94,81%; Ши Лэй и др. [20] предложили облегченную сетевую модель на основе FasterNet. Путем введения механизма Channel Shuffle и модуля Swin Transformer была достигнута точность распознавания 97,22% для изображений фенологических фаз пшеницы; Чжэн Гуан и др. [21] предложили облегченную модель мониторинга процесса роста пшеницы на основе глубинной разделяемой свертки и атрокусной (hollow) свертки, которая достигла точности распознавания 98,6%.
Несмотря на определенные успехи в сельском хозяйстве, сверточные нейронные сети по-прежнему сталкиваются с некоторыми проблемами в таких конкретных задачах, как распознавание фенологических фаз кукурузы. Большинство существующих исследований сосредоточено на классификации фенологических фаз таких культур, как пшеница и рис [22], и многие методы зависят от устройств с высокой вычислительной мощностью, что не удовлетворяет требованиям развертывания на интеллектуальных терминалах с низкой производительностью. Таким образом, актуальной задачей является исследование того, как использовать малые вычислительные ресурсы, сохраняя при этом высокую точность классификации для моделей идентификации сортов кукурузы по фенологическим фазам в различных условиях окружающей среды. Основной вклад данной статьи заключается в следующем:
Сбор и предварительная обработка данных: Мы собрали изображения листьев, тычиночных цветков и корневых чехликов 40 сортов кукурузы в провинции Ганьсу на стадии образования узлов и обеспечили качество и пригодность данных с помощью методов предварительной обработки и отбора изображений, что предоставило качественную основу для обучения модели.
Оптимизация модели: Мы внедрили структуру Representative Batch Normalization (RBN) в сетевую модель DenseNet121, что повысило способность модели к обобщению при различных распределениях данных и размерах пакетов.
Оптимизация структуры и извлечение признаков: Комбинируя преимущества модуля SE и глубинной разделяемой свертки, мы улучшили способность модели к представлению признаков, одновременно снизив вычислительные затраты, уменьшив сложность модели и обеспечив ее эффективность.
Регуляризация и способность к обобщению: Путем введения регуляризации Dropout снижен риск переобучения модели и повышена устойчивость на новых данных.
Благодаря этим усовершенствованиям мы предлагаем облегченную модель сверточной нейронной сети для идентификации фенологических фаз курурузы, aiming to provide a new technological solution for corn variety identification that can be effectively deployed on low-computing power devices in the field. (Цель — предложить новое технологическое решение для идентификации сортов кукурузы, которое может быть эффективно развернуто на маломощных устройствах в полевых условиях.)
2. Материалы и методы
2.1. Экспериментальные материалы и обработка
2.1.1. Сбор изображений
Все наборы данных изображений кукурузы в данном исследовании были собраны на опытном участке инноваций зародышевой плазмы и генетической селекции кукурузы в Научно-технологическом парке современного сельского хозяйства Академии сельскохозяйственных наук провинции Ганьсу (38°56′ с.ш., 100°26′ в.д., средняя высота 1482,7 м, среднегодовое количество осадков 129 мм, годовое количество солнечных часов 3085). На Рис. 1 показаны многоугольные и масштабные фотографии тычиночных цветков, листьев и корневых чехликов растения кукурузы при естественном освещении на открытом воздухе, сделанные с помощью цифровой камеры Nikon COOLPIX B700 (производства корпорации Nikon, Токио, Япония; ISO 1600, выдержка 1/30 с) и сотового телефона (Android 14, автоматический режим HDR), формат изображения — JPG. Изображения собирались с 9 по 13 июля 2024 года, включая три солнечных дня и два дня с небольшим дождем. Съемка охватывала различные погодные условия, освещение и фон, и в общей сложности было собрано 31 000 изображений 40 сортов кукурузы (Таблица 1), включая по 40 растений каждого из 20 гибридных сортов и по 20 растений каждого из 20 родительских сортов, охватывающих несколько частей растения. Набор данных был разделен на обучающую, проверочную и тестовую выборки в соотношении 7:2:1.

Рис. 1. Растение кукурузы. (a) Лист. (b) Тычиночный цветок. (c) Корневой чехлик.
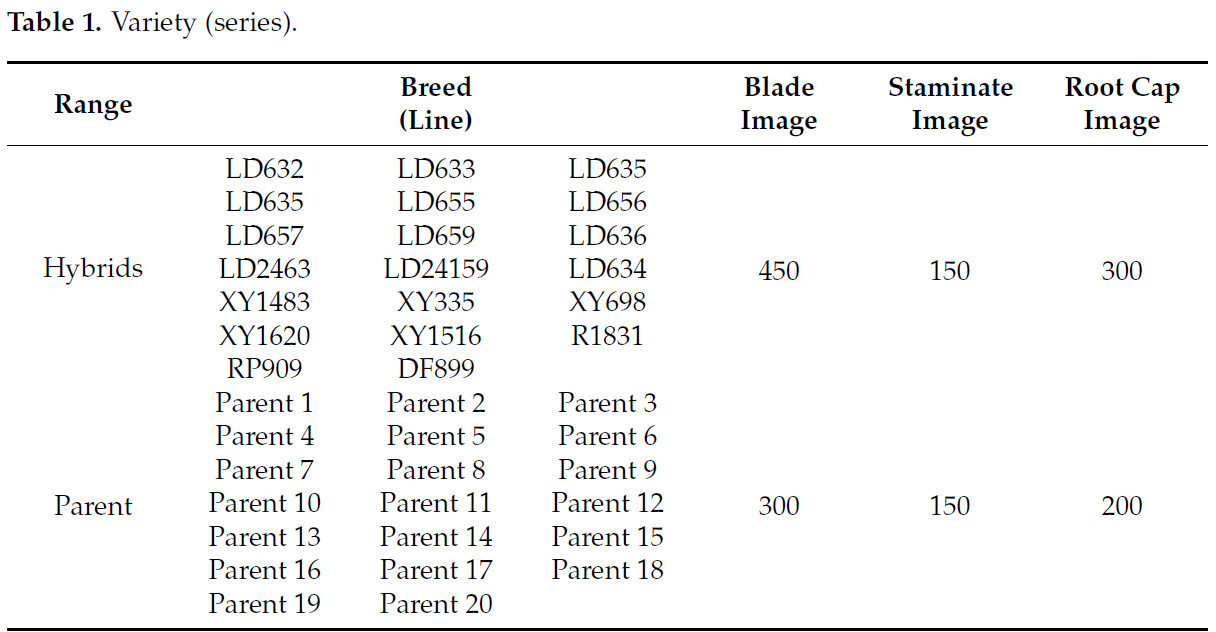
Таблица 1. Сорта (линии).
2.1.2. Обработка изображений
В алгоритмах глубокого обучения качество набора данных критически важно для обучения сетевых моделей и их прогнозной производительности. Чтобы повысить способность к обобщению и устойчивость сетевой модели, размер изображений в обучающем и проверочном наборах был изменен до квадрата 224 × 224 пикселя, чтобы гарантировать одинаковый размер всех изображений. Каждое изображение в обучающей выборке случайным образом отражалось по горизонтали с вероятностью 0,5 для увеличения разнообразия данных и помощи модели в становлении более устойчивой и инвариантной к горизонтальному отражению. Нормализация min-max — это метод масштабирования данных к определенному диапазону [0, 1]. Это масштабирование достигается с помощью простого линейного преобразования, которое корректирует исходные значения данных к единой шкале, повышая стабильность и производительность алгоритма. Формула для нормализации min-max [23] представлена в Уравнении (1), где Nnorm представляет нормализованное значение пикселя изображения; xi представляет значение пикселя входного изображения.
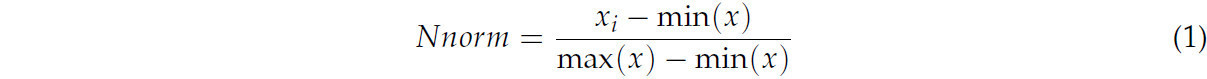
Это преобразование гарантирует, что вклад всех входных признаков в обучение модели сбалансирован, и позволяет избежать отклонений, вызванных различиями в исходных масштабах данных.
2.2. Базовая методология и тестовая среда
2.2.1. Модели для сравнения
В ходе экспериментального процесса данного исследования в качестве базовой модели используется DenseNet [24]. Каждый плотный блок (dense block) состоит из нескольких сверточных слоев, и эти слои объединяются со своими картами признаков посредством прямых соединений. Конкретно, каждый слой получает карты признаков всех предыдущих слоев в качестве входных данных, такая конструкция эффективно передает градиенты и способствует повторному использованию признаков. Как показано на Рис. 2, плотно связанная структура повышает эффективность передачи признаков, ускоряет сходимость сети и уменьшает проблему исчезающего и взрывного градиента. Этот механизм позволяет DenseNet более эффективно захватывать сложные признаки и поддерживать поток информации по всей глубокой сети.

Рис. 2. Схема структуры DenseNet.
Для всесторонней оценки производительности улучшенной модели в классификации фенологических фаз кукурузы в качестве моделей сравнения были выбраны VGG16 [25], MobileNet V3 [26], ResNet50 [27] и ConvNeXt [28]. VGG16 — это классическая глубокая сверточная сеть, способная извлекать признаки высокого уровня из изображений, но она требует больших вычислительных затрат и длительного времени обучения. MobileNet V3 использует облегченную глубинную разделяемую свертку, что снижает вычислительную сложность и подходит для сред с ограниченными ресурсами. ResNet50 решает проблему исчезающего градиента с помощью остаточных соединений, усиливая возможности обучения глубоким признакам. ConvNeXt сочетает преимущества традиционных сверточных сетей и трансформеров, обеспечивая мощные возможности извлечения признаков.
Посредством этих сравнений мы можем оценить производительность различных моделей в классификации фенологических фаз кукурузы с точки зрения точности, скорости сходимости и вычислительной эффективности, тем самым проверяя преимущества улучшенной модели и предоставляя ориентиры для практического применения.
2.2.2. Метрики оценки
В данном исследовании для оценки созданной модели обнаружения сортов кукурузы по листьям использовались объективные критерии оценки: Accuracy (A), Precision (P), Recall (R), а также вводилось значение F1 как средняя оценка сбалансированности [29]. Точность (Accuracy) используется для измерения доли правильных классификаций модели; точность (Precision) отражает правильность предсказаний модели для положительных выборок, особенно важна в сценариях, где关注 ложные срабатывания; полнота (Recall) оценивает долю истинных положительных выборок, захваченных моделью, особенно важна при关注 ложные пропуски. Кроме того, значение F1, как гармоническое среднее точности и полноты, позволяет комплексно учитывать баланс этих двух показателей, особенно при несбалансированных данных, обеспечивая более полную оценку производительности модели. Соответствующие формулы приведены в Таблице 2.

Таблица 2. Сравнительная таблица формул метрик оценки.
Где (TP) обозначает количество выборок, которые являются истинно положительными и предсказаны моделью как положительные; (FP) обозначает количество выборок, которые являются истинно отрицательными, но ошибочно предсказаны моделью как положительные; (FN) обозначает количество выборок, которые являются истинно положительными, но ошибочно предсказаны моделью как отрицательные; и (TN) обозначает количество выборок, которые являются истинно отрицательными и предсказаны моделью как отрицательные.
2.2.3. Тестовая среда
Экспериментальная среда: ОС Windows 10, 64-разрядная, процессор на базе x64, версия Cuda 11.0, и фреймворк глубокого обучения Pytorch на основе языка программирования Python. Компьютер содержит видеокарту NVIDIA GeForce MX150 (производства NVIDIA Corporation, Санта-Клара, Калифорния, США) с 24 ГБ видеопамяти и процессор Intel(R) Core(TM) i7-8550 CPU 8-го поколения с тактовой частотой 1,80 ГГц (производства Intel Corporation, Санта-Клара, Калифорния, США).
3. Улучшения модели
3.1. Улучшение модели DenseNet
3.1.1. Representative BatchNorm (RBN)
Гао [30]等人 (*и др.*) Representative BatchNorm (RBN) — это улучшенный метод пакетной нормализации, предназначенный для повышения эффективности обучения и производительности глубоких нейронных сетей. Традиционный BatchNorm нормализует, вычисляя среднее значение и дисперсию для каждого обучающего пакета, и эти статистики основаны на текущем небольшом пакете данных. Однако этот подход может подвергаться влиянию статистического шума малых пакетов данных. RBN вводит более репрезентативные статистики для нормализации. Эти статистики учитывают не только текущий малый пакет данных, но также incorporate статистическую информацию из исторического процесса обучения. Конкретно, RBN сглаживает среднее значение и дисперсию с помощью стратегии скользящего среднего, чтобы обеспечить более стабильную оценку общего распределения данных. Этот подход смягчает нестабильность статистики малых пакетов данных и обеспечивает consistent производительность сети на этапах обучения и логического вывода.
RBN состоит из двух основных шагов: калибровка центрирования и калибровка масштаба, процесс представлен в Уравнении (2). На этапе калибровки центрирования RBN нормализует признаки так, чтобы их средние значения были ближе к целевому среднему. Это достигается за счет введения дополнительного параметра репрезентативного среднего, который выравнивает среднее значение признаков к желаемому среднему, тем самым уменьшая смещение во время обучения. На этапе калибровки масштаба RBN корректирует дисперсию признаков, чтобы обеспечить closer их распределения к целевой дисперсии. Это достигается за счет введения параметра репрезентативной дисперсии, так что дисперсия признаков соответствующим образом корректируется для повышения стабильности и обобщающей способности модели. Благодаря этим двум шагам RBN не только улучшает процесс нормализации признаков, но и повышает производительность модели на этапах обучения и логического вывода, адаптируясь к различным распределениям данных и требованиям задач, тем самым повышая гибкость и устойчивость модели.
Калибровка центрирования:
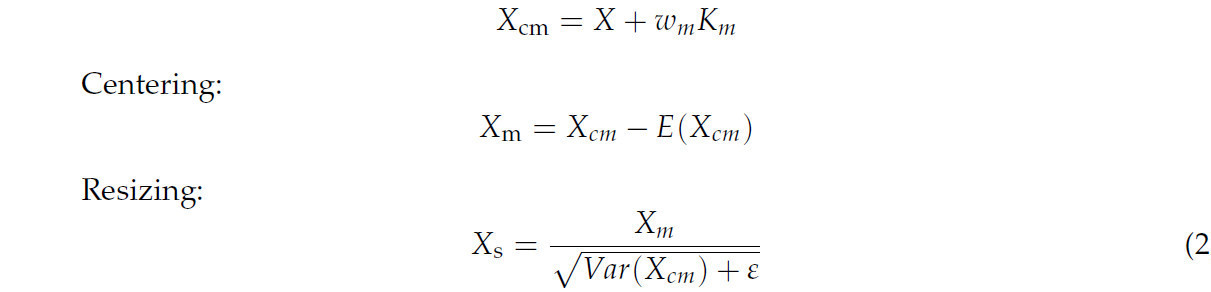
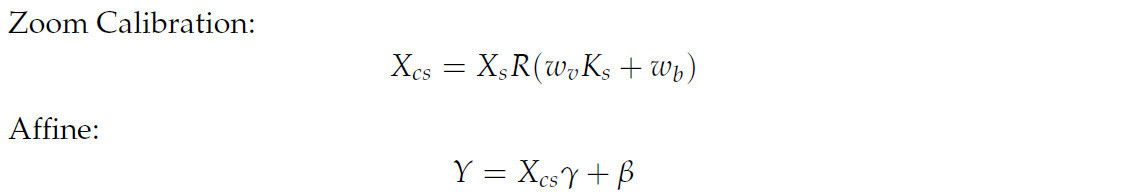
где входные признакиX∈ RN × C × H × W,w m,w v,w bявляются обучаемыми весовыми векторами.k mиK sпредставляют статистику признаков для каждого экземпляра, которую можно получить с помощью глобального среднего объединения.R() является функцией ограничения, которая часто используется с сигмоидой.E(X) иVar(X) обозначают среднее значение и дисперсию, которые используются для центрирования и масштабирования.γиβобозначают коэффициенты масштабирования и смещения аффинного преобразования, а ε используется для избежания нулевой дисперсии. Признаки обрезки можно лучше распознать, заменив исходный BN в DenseNet 121 на RBN, и это было экспериментально подтверждено.
3.1.2. Механизм внимания SE
Механизм внимания имитирует фокусное внимание в человеческом зрении или мышлении, позволяя модели автоматически обучаться фокусировке на определенных частях входных данных и динамически взвешивать информацию признаков в интересующей области, thus efficiently utilizing the limited computational resources [31]. Модуль механизма внимания SE [32] (показанный на Рис. 3) сначала сжимает карты признаков каждого сверточного слоя в single channel через глобальный пулинг по среднему (global average pooling) для захвата глобальной информации о признаках. Далее веса каждого канала генерируются с использованием двух полносвязных слоев и функции активации ReLU. Наконец, эти веса нормализуются к диапазону от 0 до 1 с помощью функции активации Sigmoid. Эти веса корректируют отклик каждого канала исходной карты признаков, thereby увеличивая чувствительность к важным признакам и подавляя нерелевантные признаки, улучшая общую производительность модели.
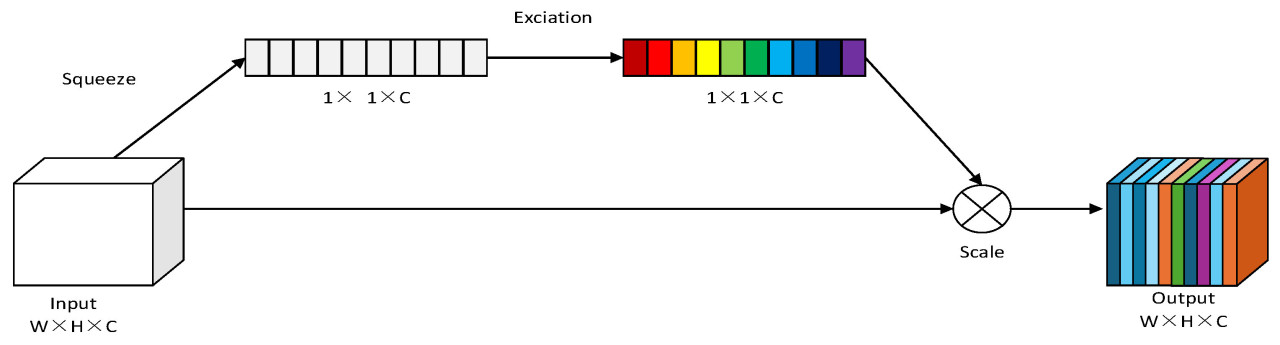
Рис. 3. Модуль SE.
Прямой процесс механизма внимания SE (Squeeze-and-Excitation) выглядит следующим образом: сначала пространственная информация каждого канала сжимается в дескриптор канала размером C с помощью глобального пулинга по среднему для входных карт признаков размером H × W × C. Далее генерируются веса каналов через два полносвязных слоя. Конкретно, дескриптор сначала уменьшается по размерности через полносвязный слой размером C/r (где r — коэффициент сжатия) и получается промежуточное представление с использованием функции активации ReLU. Затем промежуточное представление映射 обратно к исходному количеству каналов C через полносвязный слой, и веса для каждого канала получаются с использованием функции активации Sigmoid. В конечном счете, эти веса используются для корректировки канального отклика исходной карты признаков.
Сжатие (Squeeze): входная карта признаков x подвергается глобальному пулингу по среднему для получения дескриптора канала z:
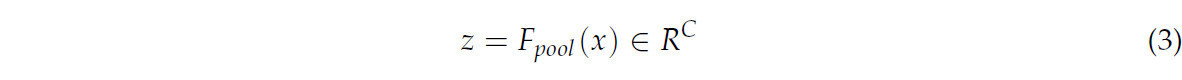
Возбуждение (Excitation): Дескриптор z отображается в промежуточное пространство с использованием полносвязного слоя и обрабатывается через функцию активации ReLU. Затем второй полносвязный слой используется для отображения промежуточного представления обратно к исходному количеству каналов и генерации весов каналов через функцию активации Sigmoid.
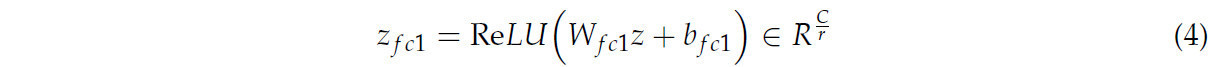
Взвешивание каналов: сгенерированные веса каналов, сигма, изменяются и применяются к исходной карте признаков, x:
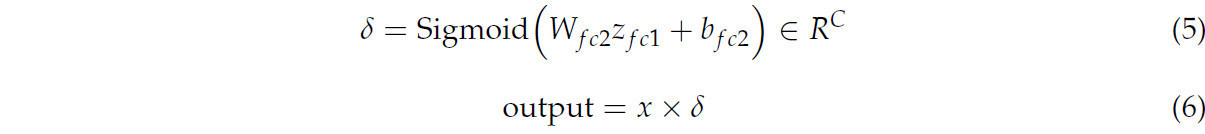
где W_fc1 и W_fc2 — матрицы весов полносвязного слоя, а b_fc1 и b_fc2 — члены смещения. Этот подход позволяет модулю SE адаптивно корректировать веса каждого канала, thus усиливая полезные признаки и подавляя бесполезные, улучшая представление признаков и итоговую производительность сети. Чтобы проверить эффективность модуля SE, мы провели сравнительные эксперименты механизмов внимания SE, ECA и CBAM. Результаты представлены в Таблице 3. Добавление механизма внимания SE значительно улучшает общую производительность обнаружения сети.

Таблица 3. Сравнение производительности механизмов внимания.
3.1.3. Глубинная разделяемая свертка (Depthwise Separable Convolution)
Глубинная разделяемая свертка, предложенная Ховардом и др. [33] в 2017 году, является типичной облегченной сверточной структурой. По сравнению со стандартной сверткой, она значительно сокращает количество параметров, повышает скорость обучения и позволяет разделять каналы и области во время операций свертки. Как показано на Рис. 4, глубинная разделяемая свертка — это операция свертки, которая разделяет традиционную свертку на два отдельных шага: глубинная свертка (depthwise convolution) и поточечная свертка (pointwise convolution). При глубинной свертке каждый входной канал обрабатывается отдельным ядром свертки для генерации выходного канала, равного количеству входных каналов. Поточечная свертка, с другой стороны, использует ядро свертки размером 1 × 1 для обработки выхода глубинной свертки с целью интеграции и сжатия информации каналов для получения итоговой карты признаков. Этот подход позволяет调整 количество каналов без изменения пространственных размеров карты признаков, thus мотивируя сеть изучать более сложные представления признаков.
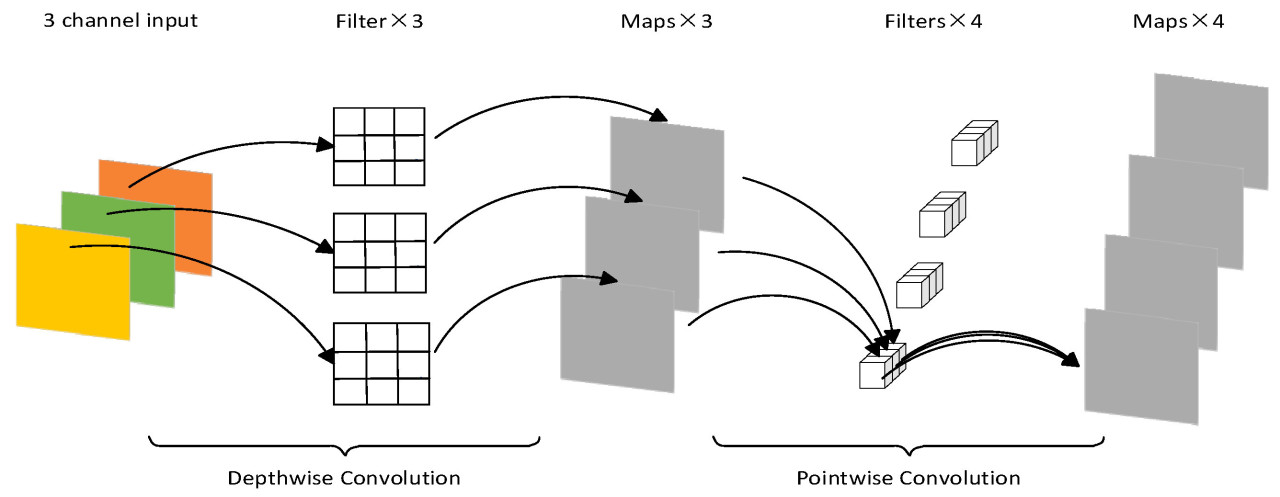
Рис. 4. Глубинная разделяемая свертка.
По сравнению с традиционными методами свертки, глубинная разделяемая свертка сокращает количество параметров, significantly снижая вычислительную стоимость при сохранении производительности модели. Сверточное ядро N H × W × C может быть заменено на C H × W × 1 глубинную свертку и N 1 × 1 × C поточечную свертку. Количество параметров для глубинной свертки составляет (H × W × 1) × C, а количество параметров для поточечной свертки составляет (1 × 1 × C) × N. Количество комбинаций параметров для глубинной разделяемой свертки рассчитывается следующим образом:
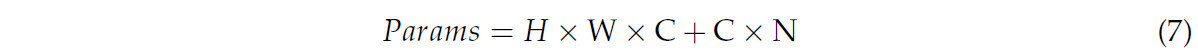
Количество параметров для обычной свертки составляет H × W × C × N. Соотношение между ними сравнивается следующим образом:
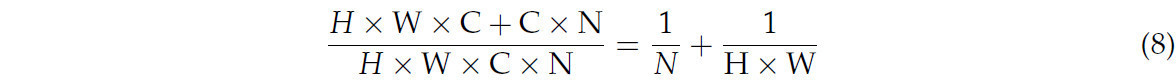
Сравнение параметров DenXt с исходной моделью DenseNet 121 после использования глубинной разделяемой свертки вместо исходной свертки показано в Таблице 4. Исходная модель DenseNet 121 использует целых 6 994 856 параметров, после замены на глубинную разделяемую свертку это число уменьшается на 1 718 192, и модель имеет меньшие параметры, что благоприятствует облегченному сетевому дизайну. Это также улучшает общую производительность модели.

Таблица 4. Сравнение параметров.
3.1.4. Dropout
Dropout — это метод регуляризации, предложенный Хинтоном и др. [34] в 2014 году для предотвращения переобучения нейронных сетей. По сравнению с традиционными методами регуляризации, Dropout проще во время обучения модели и значительно улучшает способность модели к обобщению на новых данных. Как показано на Рис. 5, dropout достигает регуляризации путем случайного «отключения» некоторых нейронов в каждой итерации обучения. Во время обучения dropout устанавливает выход некоторых нейронов в ноль с определенной вероятностью (например, 50%), чтобы уменьшить зависимость сети от конкретных нейронов. На этапе тестирования все нейроны участвуют в вычислениях, но их активационные значения масштабируются в соответствии с вероятностью dropout, использовавшейся на этапе обучения. Таким образом, dropout повышает устойчивость и способность к обобщению сети без добавления дополнительной вычислительной сложности.
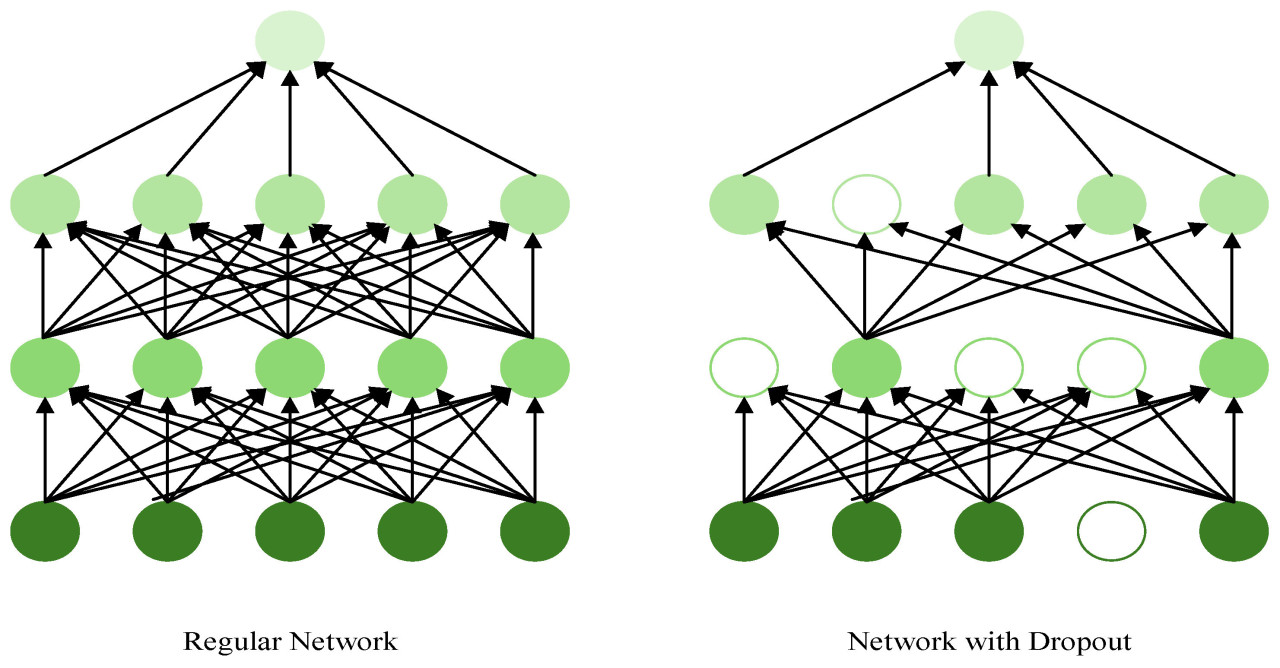
Рис. 5. Процесс обучения (Снизу вверх: входной слой, скрытый слой 1, скрытый слой 2 и выходной слой, где белый цвет означает отброшенные нейроны.).
3.2. Модель DenXt
Модель сосредоточена на улучшении структуры плотного блока (dense block) в DenseNet тремя способами, в то время как остальная часть модели остается consistent с DenseNet. В нашей улучшенной модели DenseNet добавлены три ключевых блока: Squeeze-and-Excitation Block (SEBlock), Depth Separable Convolution (DS Conv), Representative Batch Normalization (RBN) и Dropout Layer, чтобы сформировать всю модель DenXt, как показано на Рис. 6. SEBlock улучшает представление признаков путем адаптивной настройки весов каналов, Depth Separable Convolution повышает эффективность за счет снижения вычислительной сложности и параметров модели, а Representative Batch Normalization упрощает обработку в режиме оценки. Эти улучшения приводят к значительному выигрышу в вычислительной эффективности, использовании памяти и способности к обобщению по сравнению с традиционным DenseNet. Кроме того, модель также поддерживает предотвращение переобучения через dropout, что улучшает способность модели к обобщению. В целом, эти улучшения делают нашу модель DenseNet превосходящей традиционный DenseNet с точки зрения вычислительной эффективности, использования памяти и способности к обобщению, и достигающей более высокой производительности и эффективности. В Таблице 5 показано подробное архитектурное сравнение между DenXt и исходным DenseNet121.
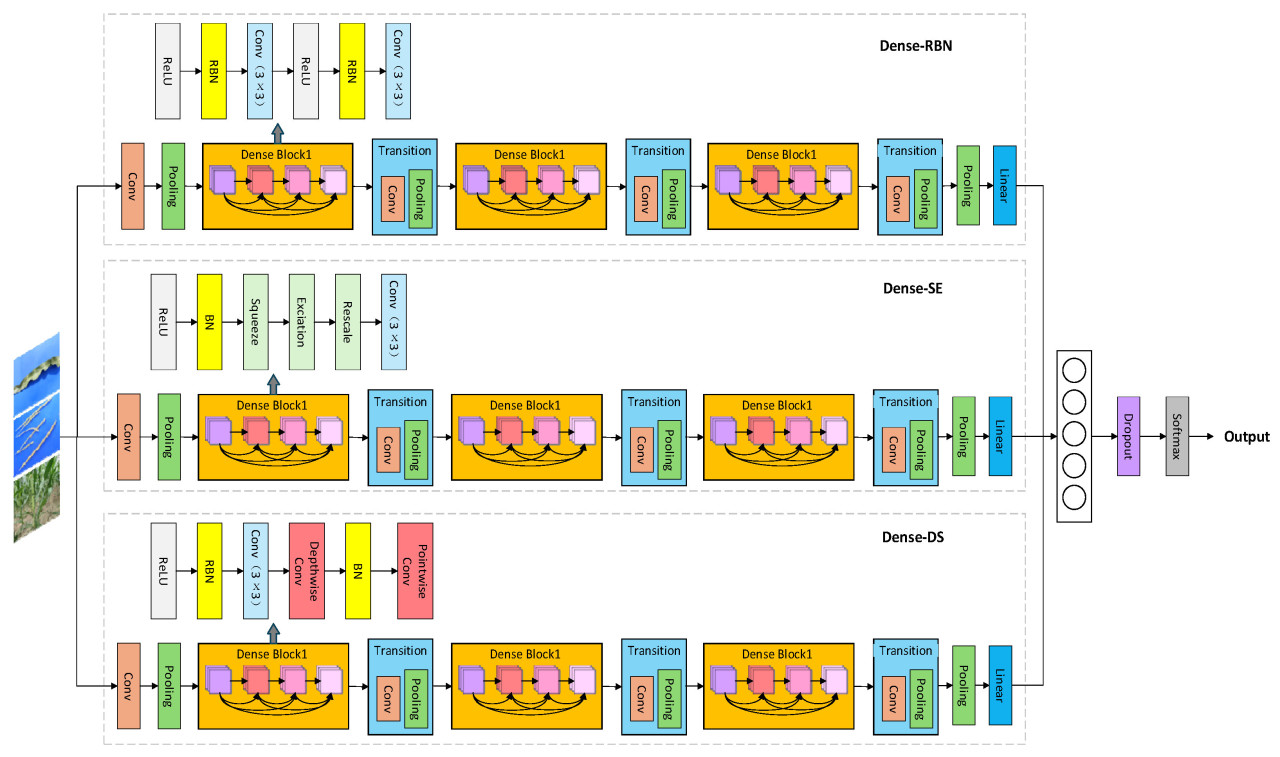
Рис. 6. Схема архитектуры сети DenXt.
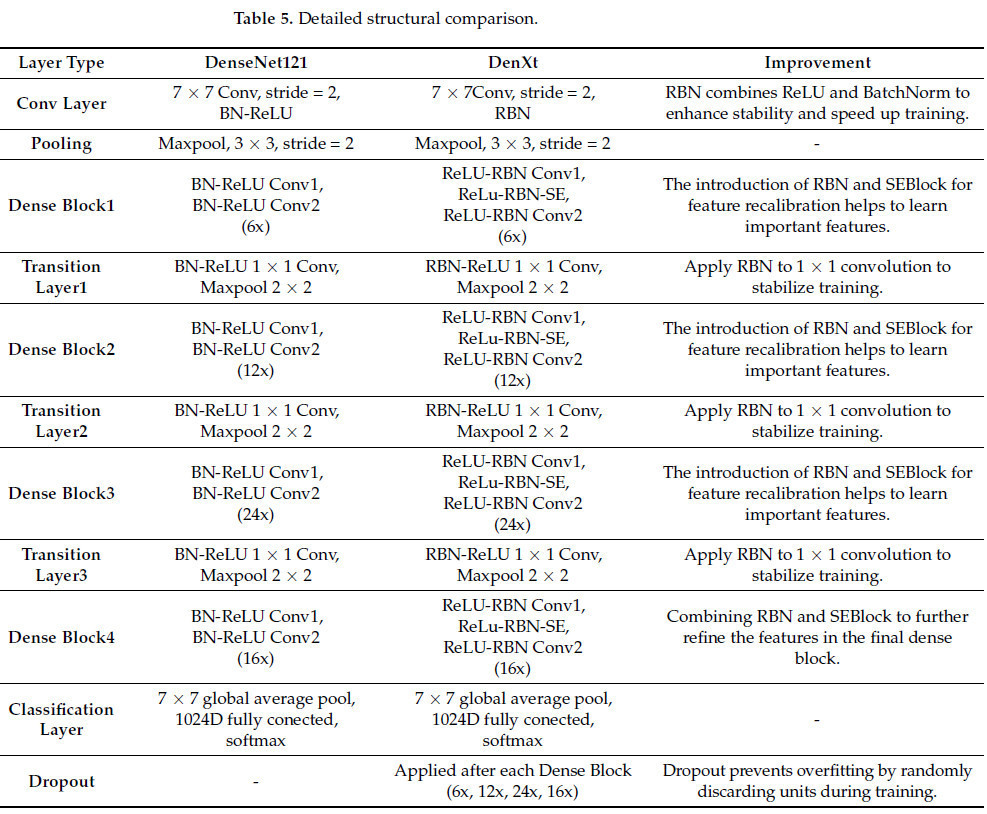
Таблица 5. Детальное структурное сравнение.
4. Результаты и обсуждение
4.1. Абляционные эксперименты и сравнительный анализ
Абляционные эксперименты демонстрируют эффективность ряда улучшений модели DenseNet. В качестве метрик использовались точность на тестовом наборе и F1-Score. Абляционные эксперименты включают влияние модели после использования только модуля RBN, модуля механизма внимания SE, модуля Depth Separable Convolution, а также использования Dropout, а также влияние итоговой модели. Модификации вносились в Dense Block DenseNet. Когда используется модуль RBN, модель именуется Den-RBN; когда используется модуль SE, модель именуется Den-SE; когда используется глубинная разделяемая свертка, модель именуется Den-DW; а когда используется Dropout, модель именуется Den-Drop. Объединяя преимущества улучшенной модели, итоговая модель именуется DenXt. Результаты абляционных экспериментов на тестовом наборе показаны в Таблице 6. Из Таблицы 6 видно, что улучшенные Den-RBN, Den-SE, Den-DS, Den-Drop и DenXt имеют лучшую точность и F1Score по сравнению с моделью DenseNet 121. Den-RBN, полученная путем введения репрезентативной пакетной нормализации, имеет лучшую точность и F1Score для этого модуля по сравнению с до модификации DenseNet-121 на тестовом наборе на 0,46 процентных пункта по точности и на 0,78 процентных пункта по F1Score; Den-SE — на 0,26 процентных пункта по точности и на 0,5 процентных пункта по F1Score на тестовом наборе; Den-DW — на 1,99 процентных пункта по точности и на 2,31 процентных пункта по F1Score на тестовом наборе; и Den-Drop улучшила свою точность на тестовом наборе на 0,34 процентных пункта и свой F1Score на 0,47 процентных пункта; улучшенный DenXt улучшил свою точность на тестовом наборе на 3,24 процентных пункта и свой F1 Score на 3,56 процентных пункта.
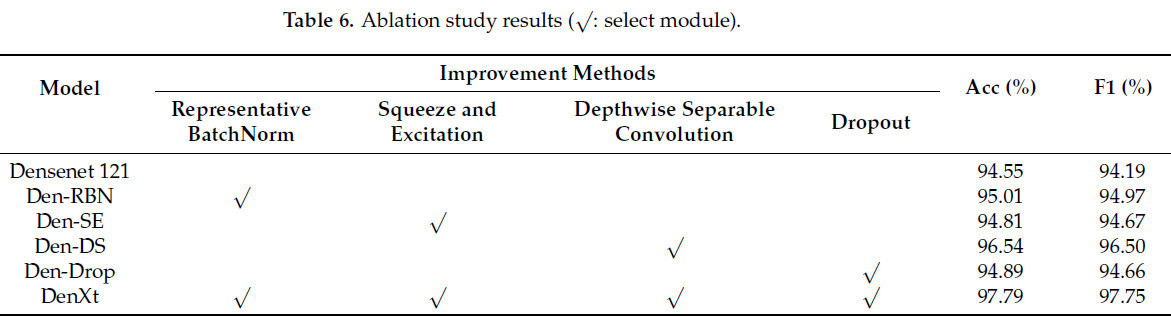
Таблица 6. Результаты абляционного исследования (√: выбранный модуль).
4.2. Анализ результатов классификации
Улучшенная модель DenXt была оценена с использованием тестового набора данных, и на Рис. 7 показана матрица неточностей улучшенной модели DenXt для классификации внешнего вида сортов кукурузы в тестовом наборе. Морфология листьев, тычиночных цветков и корневых чехликов растений кукурузы очень близка, и различия незначительны. Поэтому есть некоторые ошибки распознавания. Проанализированные с точки зрения Accuracy, Precision, Recall и F1 value, все сорта (линии) были выше 95,45%, 94,29%, 95,45% и 95,45% соответственно, и эти результаты указывают на то, что существует значительная разница в производительности модели между разными сортами (линиями), а также указывают на то, что улучшенная модель хорошо работает на наборе данных по листьям кукурузы и способна эффективно дифференцировать большинство сортов (линий).
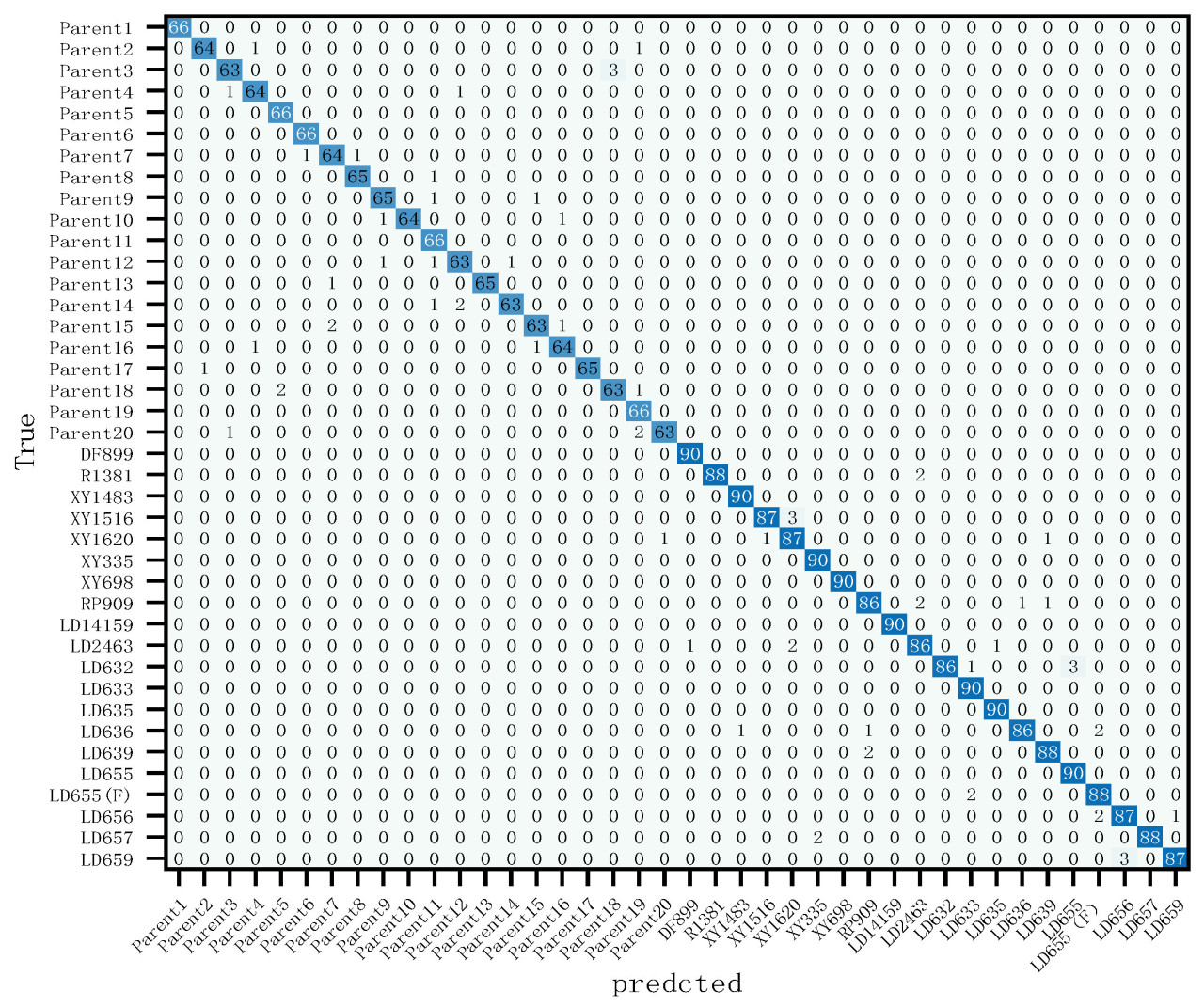
Рис. 7. Матрица неточностей (Confusion Matrix).
4.3. Сравнение с другими моделями
Чтобы лучше оценить производительность улучшенной сети DenXt в данной статье, в качестве метрик для экспериментов сравнения с сетевыми моделями DenseNet 121, VGG16, MobileNet V3, ResNet50 и ConvNeXt в Таблице 7 используются Accuracy, Precision, Recall, F1 value, размер параметров и значения оценки памяти GPU. Точности классификации различных моделей на тестовом наборе показаны на Рис. 8, где улучшенная модель DenXt достигает средней точности 97,79% на тестовом наборе, что на 3,3–8,34 процентных пункта выше, чем у других моделей, и средней точности (Precision) 97,77%, что на 3,31–8,1 процентных пункта выше, чем у других сетевых моделей. Аналогично, средняя полнота (Recall) была улучшена на 3,52–8,52 процентных пункта до 97,75% по сравнению с другими моделями, в то время как значение F1 score достигло 97,75%, что было улучшено на 3,52–8,56 процентных пункта по сравнению с другими моделями. В contrast, другие модели показали более низкую точность в классификации образцов изображений сортов растений кукурузы. Хотя облегченные модели, такие как MobilenetV3 (с параметрами всего 16,22 МБ), имеют некоторые преимущества с точки зрения занимаемой памяти и вычислительной эффективности, их точность и другие метрики оценки (например, Precision, Recall и F1 Score) значительно ниже, чем у DenXt. Производительность DenXt по Precision и Recall также лучше, чем у этих облегченных моделей, что указывает на то, что она не только превосходит другие малые модели по общей точности, но также более точна и комплексна в обработке задач классификации. В то же время, время вывода (inference time) DenXt (2265,95 мс) также лучше, чем у других моделей, особенно Densenet 121 (28 774,34 мс) и VGG16 (13 243,09 мс). Его более низкая задержка делает его особенно выдающимся в сценариях с высокими требованиями к реальному времени. Эти findings предоставляют доказательства превосходной производительности модели, предложенной в данной статье.
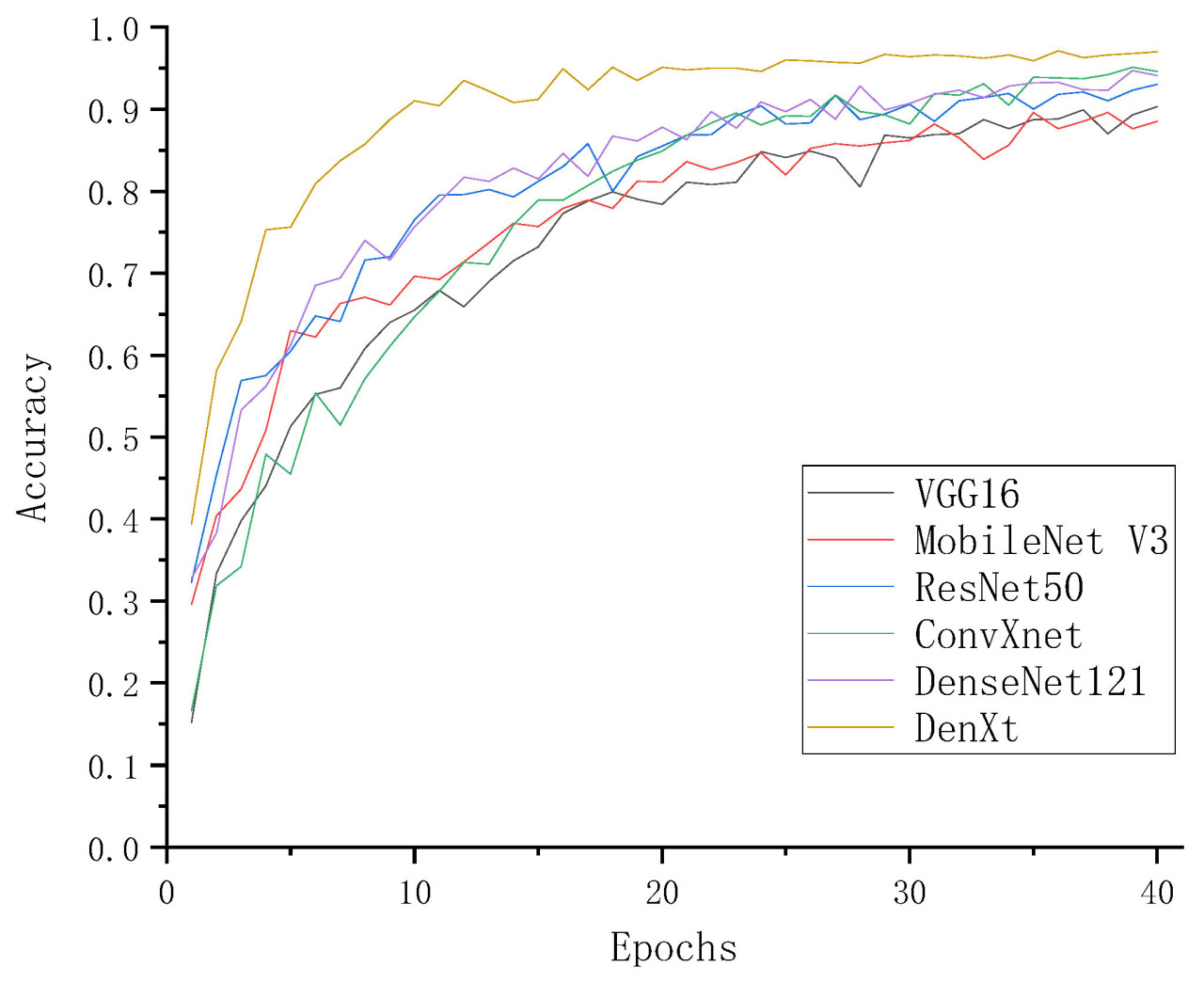
Рис. 8. Сравнение точности.
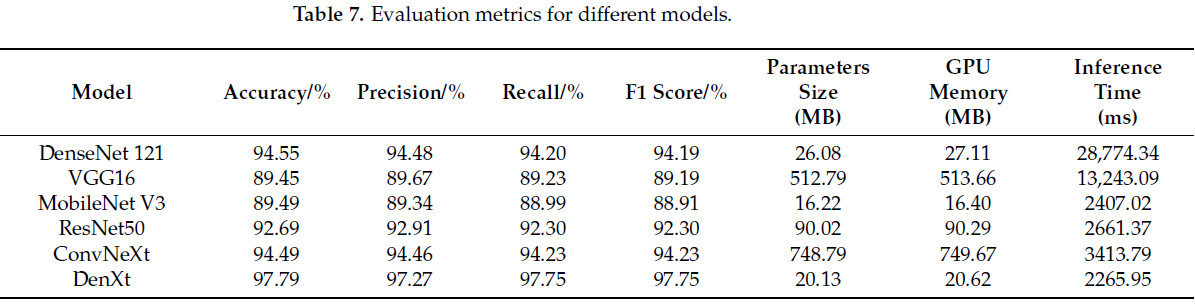
Таблица 7. Метрики оценки для различных моделей.
4.4. Визуализация сети
Чтобы лучше наблюдать способность модели DenXt к изучению признаков растений кукурузы на стадии elongation, мы использовали Grad-CAM для визуализации листьев, тычиночных цветков и корневых чехликов кукурузы. В данном исследовании мы выбрали последний слой модели DenXt в качестве слоя визуализации признаков сети для визуализации признаков, как показано на Рис. 9. Наблюдая за результатами визуализации, мы обнаружили, что модель DenXt точно идентифицирует ключевые области различных частей. Кроме того, мы заметили, что модель уделяет меньше внимания нерелевантным и сложным фонам, таким как почва вокруг растения. Таким образом, эти результаты подтверждают сильную способность модели DenXt к изучению характеристик растений на стадии uprooting кукурузы.
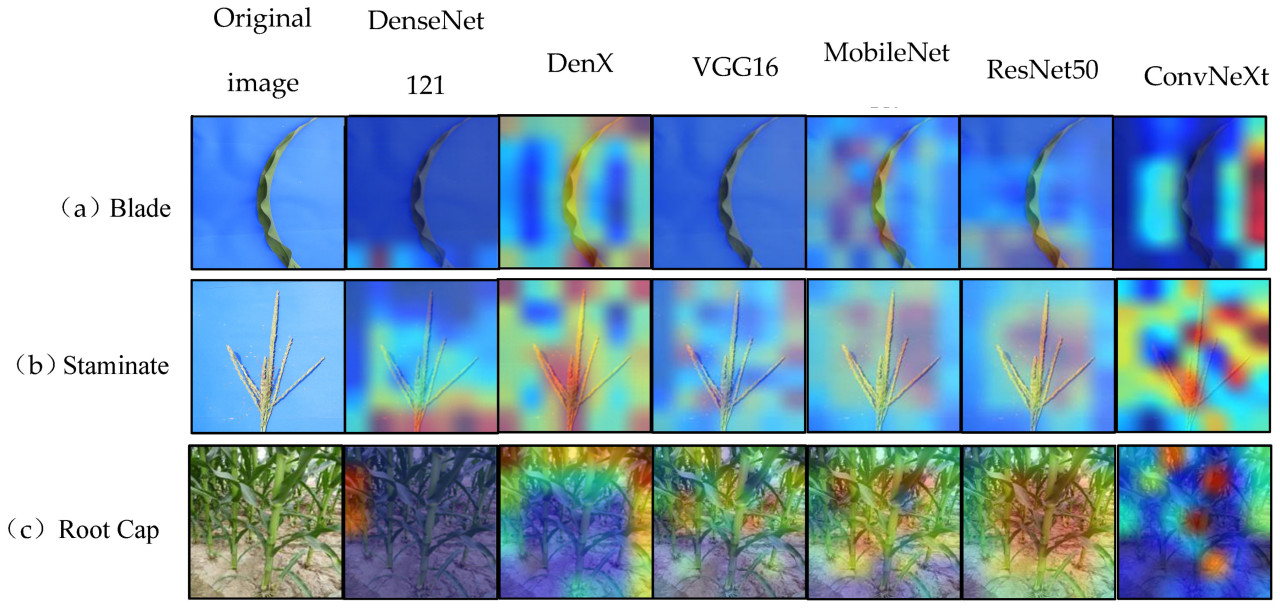
Рис. 9. Тепловая карта обнаружения и анализ (Thermogram detection and analysis).
5. Выводы и перспективы
Данное исследование направлено на решение проблем классификации сортов кукурузы на репродуктивной стадии и достигает этой цели путем разработки эффективной модели сверточной нейронной сети (CNN). Мы сначала собрали и предварительно обработали изображения листьев, мужских початков и корневых чехликов 40 сортов кукурузы в провинции Ганьсу на стадии elongation, чтобы обеспечить качество и репрезентативность данных и предоставить надежную основу для обучения модели. В части улучшения модели мы внедрили структуру Representative Batch Normalization (RBN) в сеть DenseNet-121, и это улучшение повысило способность модели к обобщению при различных распределениях данных и размерах пакетов, сделав распределение признаков более стабильным. Чтобы усилить фокус модели на информации каналов, мы интегрируем модуль SE и глубинную разделяемую свертку, что не только улучшает способность к представлению признаков, но и эффективно снижает вычислительные затраты времени и сложность модели. Кроме того, введение регуляризации dropout эффективно снижает риск переобучения, и путем случайного «отключения» некоторых нейронов модель избегает чрезмерной зависимости от обучающих данных в процессе обучения, что улучшает широту изучения признаков и устойчивость модели. Предложенная сетевая модель DenXt превосходит другие популярные модели классификации изображений, включая VGG16, MobileNet V3, ResNet50 и ConvNeXt, при сохранении низкой сложности модели. По сравнению с исходной сетевой моделью, точность нашей сетевой модели DenXt повышена на 3,23%, а количество параметров сокращено на 32,56%. В заключение, предложенный новый метод показывает хорошую производительность в применении для идентификации сортов кукурузы на стадии pulling out, что демонстрирует возможность его развертывания для использования на маломощных интеллектуальных сельскохозяйственных оборудованных платформах в полевых условиях.
Ссылки
1. Food and Agriculture Organization of the United Nations (FAO). FAOSTAT Database. 2023. Available online: https://www.fao.org/faostat/en/#home (accessed on 20 August 2024).
2. Edmeades, G.O.; Trevisan, W.; Prasanna, B.M.; Campos, H. Tropical maize (Zea mays L.). In Genetic Improvement of Tropical Crops; Springer: Cham, Switzerland, 2017; pp. 57–109. [Google Scholar]
3. Erenstein, O.; Jaleta, M.; Sonder, K.; Mottaleb, K.; Prasanna, B.M. Global maize production, consumption and trade: Trends and R&D implications. Food Secur. 2022, 14, 1295–1319. [Google Scholar]
4. Guerra, A.; Scremin-Dias, E. Leaf traits, sclerophylly and growth habits in plant species of a semiarid environment. Braz. J. Bot. 2018, 41, 131–144. [Google Scholar] [CrossRef]
5. Chen, F.; Liu, J.; Liu, Z.; Chen, Z.; Ren, W.; Gong, X.; Wang, L.; Cai, H.; Pan, Q.; Yuan, L.; et al. Breeding for high-yield and nitrogen use efficiency in maize: Lessons from comparison between Chinese and US cultivars. Adv. Agron. 2021, 166, 251–275. [Google Scholar]
6. Ganesh, A.; Shukla, V.; Mohapatra, A.; George, A.P.; Bhukya DP, N.; Das, K.K.; Kola, V.S.R.; Suresh, A.; Ramireddy, E. Root cap to soil interface: A driving force toward plant adaptation and development. Plant Cell Physiol. 2022, 63, 1038–1051. [Google Scholar] [CrossRef] [PubMed]
7. Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
8. Tiwari, V.; Joshi, R.C.; Dutta, M.K. Dense convolutional neural networks based multiclass plant disease detection and classification using leaf images. Ecol. Inform. 2021, 63, 101289. [Google Scholar] [CrossRef]
9. Laabassi, K.; Belarbi, M.A.; Mahmoudi, S.; Mahmoudi, S.A.; Ferhat, K. Wheat varieties identification based on a deep learning approach. J. Saudi Soc. Agric. Sci. 2021, 20, 281–289. [Google Scholar] [CrossRef]
10. Oikonomidis, A.; Catal, C.; Kassahun, A. Deep learning for crop yield prediction:a systematic literature review. N. Zeal. J. Crop Hortic. Sci. 2023, 51, 1–26. [Google Scholar] [CrossRef]
11. Wang, Z.; Huang, W.; Tian, X.; Long, Y.; Li, L.; Fan, S. Rapid and non-destructive classification of new and aged maize seeds using hyperspectral image and chemometric methods. Front. Plant Sci. 2022, 13, 849495. [Google Scholar] [CrossRef]
12. Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
13. Rasti, S.; Bleakley, C.J.; Silvestre, G.C.; Holden, N.M.; Langton, D.; O’Hare, G.M. Crop growth stage estimation prior to canopy closure using deep learning algorithms. Neural Comput. Appl. 2021, 33, 1733–1743. [Google Scholar] [CrossRef]
14. Anami, B.S.; Malvade, N.N.; Palaiah, S. Deep learning approach for recognition and classification of yield affecting paddy crop stresses using field images. Artif. Intell. Agric. 2020, 4, 12–20. [Google Scholar] [CrossRef]
15. Song, Z.; Wang, P.; Zhang, Z.; Yang, S.; Ning, J. Recognition of sunflower growth period based on deep learning from UAV remote sensing images. Precis. Agric. 2023, 24, 1417–1438. [Google Scholar] [CrossRef]
16. Xu, J.; Wang, J.; Xu, X.; Ju, X. Rice growth stage image recognition based on RAdam convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 143–150. [Google Scholar]
17. Liu, P.; Liu, L.; Wang, C.; Zhu, Y.; Wang, H.; Li, X. Method for determining the flowering stage of wheat in the field based on machine vision. J. Agric. Mach. 2022, 53, 251–258. [Google Scholar]
18. Han, Y.; Xing, H.; Jin, H. Design of an automatic detection system for maize seedling emergence and three-leaf stage based on OpenCV. J. Electron. Meas. Instrum. 2017, 31, 1574–1581. [Google Scholar] [CrossRef]
19. Zhang, Y.; Liu, R.; Liu, M.; Gong, Y. Recognition of maize growth stages based on deep convolutional features. Electron. Meas. Technol. 2018, 41, 79–84. [Google Scholar] [CrossRef]
20. Shi, L.; Lei, J.; Wang, J.; Yang, C.; Liu, Z.; Lei, X.; Xiong, S. A lightweight wheat growth stage recognition model based on improved FasterNet. J. Agric. Mach. 2024, 55, 226–234. [Google Scholar]
21. Zheng, G.; Wei, J.; Ren, Y.; Liu, H.; Lei, X. Research on a lightweight wheat growth monitoring model based on deep separable and dilated convolutions. Jiangsu J. Agric. Sci. 2022, 50, 226–232. [Google Scholar] [CrossRef]
22. Sheng, R.T.-C.; Huang, Y.-H.; Chan, P.-C.; Bhat, S.A.; Wu, Y.-C.; Huang, N.-F. Rice growth stage classification via RF-based machine learning and image processing. Agriculture 2022, 12, 2137. [Google Scholar] [CrossRef]
23. Mo, H.; Wei, L. SA-ConvNeXt: A hybrid approach for flower image classification using selective attention mechanism. Mathematics 2024, 12, 2151. [Google Scholar] [CrossRef]
24. Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
25. Yang, H.; Ni, J.; Gao, J.; Han, Z.; Luan, T. A novel method for peanut variety identification and classification by Improved VGG16. Sci. Rep. 2021, 11, 15756. [Google Scholar] [CrossRef]
26. Koonce, B.; Koonce, B. MobileNetV3. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: New York, NY, USA, 2021; pp. 125–144. [Google Scholar]
27. Mukti, I.Z.; Biswas, D. Transfer learning based plant diseases detection using ResNet50. In Proceedings of the 2019 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
28. Feng, J.; Tan, H.; Li, W.; Xie, M. Conv2NeXt: Reconsidering Conv NeXt Network Design for Image Recognition. In Proceedings of the 2022 International Conference on Computers and Artificial Intelligence Technologies (CAIT), Quzhou, China, 4–6 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 53–60. [Google Scholar]
29. Xing, X.; Liu, C.; Han, J.; Feng, Q.; Lu, Q.; Feng, Y. Wheat-seed variety recognition based on the GC_DRNet model. Agriculture 2023, 13, 2056. [Google Scholar] [CrossRef]
30. Gao, S.H.; Han, Q.; Li, D.; Cheng, M.M.; Peng, P. Representative batch normalization with feature calibration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8669–8679. [Google Scholar]
31. Mi, Z.; Zhang, X.; Su, J.; Han, D.; Su, B. Wheat stripe rust grading by deep learning with attention mechanism and images from mobile devices. Front. Plant Sci. 2020, 11, 558126. [Google Scholar] [CrossRef]
32. Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
33. Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
34. Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]

Zhao J, Liu C, Han J, Zhou Y, Li Y, Zhang L. Real-Time Corn Variety Recognition Using an Efficient DenXt Architecture with Lightweight Optimizations.
Перевод статьи «Real-Time Corn Variety Recognition Using an Efficient DenXt Architecture with Lightweight Optimizations» авторов Zhao J, Liu C, Han J, Zhou Y, Li Y, Zhang L., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)