Модель обнаружения зелёных яблок на основе улучшенного трансформера с адаптивным вниманием
В процессе создания интеллектуального сада точное обнаружение целевых плодов является важным условием реализации интеллектуального управления садоводством. Технология детекции зелёных яблок значительно сокращает потребность в ручном труде, снижая затраты и время, а также повышая уровень автоматизации и эффективности процессов сортировки.
Аннотация
Однако сложные условия садовой среды, постоянно меняющееся положение целевых плодов и трудности с обнаружением зелёных плодов, цвет которых схож с фоном, создают новые вызовы для их распознавания.
Для решения проблем, связанных с детекцией зелёных яблок, в данном исследовании в качестве объекта изучения были выбраны именно они, и была предложена модель detection на основе оптимизированного Deformable DETR. Новый метод сначала использует сеть ResNeXt для извлечения признаков изображения, чтобы уменьшить потерю информации в процессе feature extraction; затем повышает точность и оптимизирует результаты detection с помощью механизма deformable attention; и, наконец, использует feed-forward network для прогнозирования результатов.
Результаты экспериментов показывают, что точность усовершенствованной модели detection значительно повысилась: совокупный AP составил 54.1, AP50 – 80.4, AP75 – 58.0, AP для малых объектов (APs) – 35.4, для средних (APm) – 60.2, а для крупных (APl) – 85.0.
Данное исследование может служить теоретической основой для обнаружения других зелёных плодов и овощей.
1. Введение
С развитием науки и технологий сельскохозяйственное производство стремится к интеллектуализации, и технологии компьютерного зрения играют важную роль в производстве и управлении плодоовощной продукцией. Они нашли широкое применение в сельском хозяйстве, например, для прогнозирования урожайности фруктов и овощей [1,2], автоматического сбора [3,4] и детекции плодов [5]. Точность и эффективность обнаружения целевых плодов являются ключевым фактором, определяющим производительность систем интеллектуального сельского хозяйства. Однако в сложных условиях садовой среды на работу системы зрения легко влияют такие факторы, как интенсивность и угол освещения, поза роста плода, цвет фруктов и погодные условия, что сказывается на точности распознавания целевых плодов. Детекция зелёных яблок — это ключевая технология в агропромышленном и пищевом секторах, имеющая глубокие последствия для умного сельского хозяйства, безопасности пищевых продуктов, контроля качества и устойчивого развития. Технология детекции зелёных яблок значительно сокращает затраты на ручной труд и время, повышая уровень автоматизации и эффективности задач сортировки.
Традиционное машинное обучение накопило определённую исследовательскую базу в области обнаружения объектов [6,7] и также добилось promising результатов в детекции зелёных плодов. Традиционное машинное обучение в основном выполняет обнаружение объектов на основе комбинации таких характеристик, как цвет, текстура и форма целевого плода, и его точность распознавания относительно высока. Однако в сложной реальной садовой среде некоторые особенности изображения не являются очевидными или даже отсутствуют из-за влияния освещения в саду, закрытия или перекрытия плодов, что приводит к значительному снижению точности распознавания. Робастность и способность к обобщению таких алгоритмов с трудом удовлетворяют требованиям работы оборудования в реальном времени. В последние годы, с быстрым прогрессом компьютерного аппаратного и программного обеспечения, теории и методы глубокого обучения получили значительное развитие и широко используются в областях обнаружения объектов [8,9], сегментации изображений [10,11], классификации изображений [12,13] и т.д. Глубокие сети могут автоматически извлекать признаки изображения для реализации сквозного обнаружения и существенно повышают точность обнаружения и робастность модели. Поэтому технология глубокого обучения также всё чаще применяется в сельском хозяйстве [14,15]. Многочисленные структуры сетей для обнаружения и сегментации плодов постоянно оптимизируются и применяются для распознавания целевых плодов [16,17]. Согласно предыдущим работам, распознавание зелёных целевых плодов также добилось gratifying успехов. Большинство современных алгоритмов распознавания и обнаружения плодов на основе глубокого обучения разработаны на основе CNN. Их точность, робастность и способность к обобщению превосходят таковые у традиционных методов машинного зрения. Однако при работе в сложной садовой среде возможности работы сельскохозяйственного оборудования в реальном времени нуждаются в дальнейшем улучшении.
Современные алгоритмы обнаружения объектов на основе глубоких сетей в основном делятся на две категории: одноэтапные алгоритмы, представленные YOLO и SSD, и двухэтапные алгоритмы, представленные R-CNN, Fast-RCNN и Faster-RCNN. Эти два типа алгоритмов демонстрируют робастность и способность к обобщению, однако в реальных условиях сада модели сталкиваются с проблемами точности обнаружения, что влияет на их общую эффективность при идентификации целевых плодов. Вдохновлённые подъёмом трансформерных сетей и групповых свёрток в области компьютерного зрения [18,19,20,21], была предложена модель обнаружения зелёных яблок на основе оптимизированного Deformable DETR. В этом методе информация о признаках изображений извлекается сетью ResNeXt для уменьшения потерь информации; использование разреженной способности выборки механизма деформируемого внимания повышает точность обнаружения. Прямоточная сеть используется для предсказания ограничивающих рамок. Новая модель чувствительна к зелёным целевым плодам, обладает высокой точностью обнаружения, что имеет большое значение для автоматического сбора фруктов, замера урожайности сада и научного управления. В общем, данное исследование предлагает, по крайней мере, следующие вклады:
1. Признаки изображения извлекаются с использованием сети ResNeXt для уменьшения потерь информации;
2. Механизм деформируемого внимания используется для повышения точности и оптимизации результатов обнаружения;
3. Новый подход может быть далее расширен для решения задач обнаружения других зелёных сферических фруктов, расширяя таким область применения машинного сбора и замера урожайности сада, и предоставляет теоретическую основу для обнаружения других зелёных плодов и овощей.
Остальная часть статьи организована следующим образом: Во-первых, в Разделе 2 представлен краткий обзор связанных работ с помощью таблицы. Далее, Раздел 3 описывает процесс получения изображений, обработку и разметку набора данных, а также структуру модели и функцию потерь. Раздел 4 демонстрирует преимущества точности и эффективности модели через эксперименты. Наконец, Раздел 5 обобщает сильные стороны, а также ограничения предложенного подхода и даёт прогноз на будущую работу.
2. Обзор литературы
В процессе построения умного сада точное обнаружение целевых плодов является важным условием для реализации интеллектуального управления садами. Однако фоновая среда реального сада очень сложна, что влияет на обнаружение и сегментацию целевых плодов. Например, перекрытие плодов, затенение и закрытие ветками могут привести к неполноте характеристик плода, разные интенсивности и углы освещения могут сделать целевой плод незаметным, а капли дождя на целевом плоде могут привести к изменению его характеристик. По этим причинам всё больше учёных посвящают себя изучению обнаружения и распознавания плодов, как в области традиционного машинного обучения, так и глубокого обучения, а также в исследованиях, основанных на механизмах внимания, которые внесли нестираемый вклад в обнаружение и сегментацию целей. Мы классифицировали и обобщили преимущества и недостатки методов, перечисленных в Таблице 1.
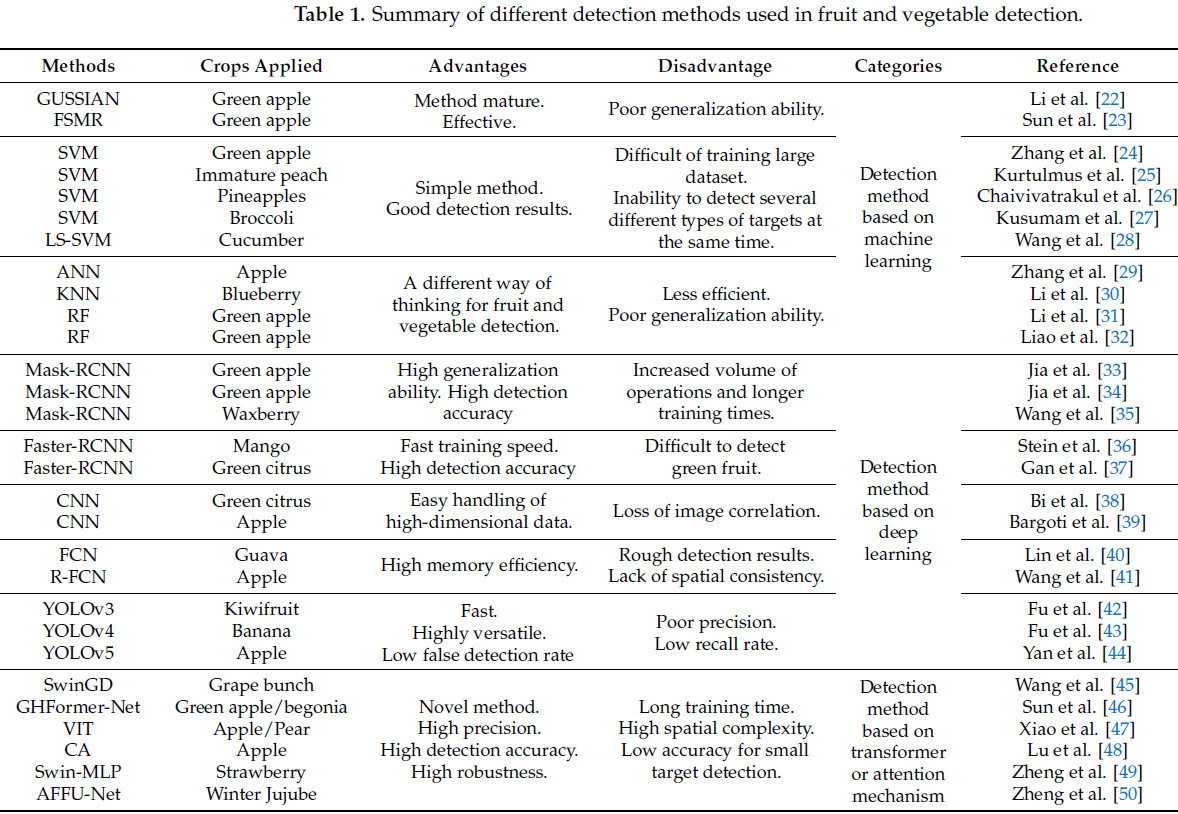
Таблица 1. Сводка различных методов обнаружения, используемых при детекции фруктов и овощей.
2.1. Машинное обучение
Обнаружение фруктов и овощей на основе традиционного машинного обучения появилось рано и внесло значительный вклад в их детекцию. Li et al. [22] использовали критерий значимости и алгоритм аппроксимации гауссовой кривой для обнаружения зелёных яблок в естественных сценах, и эффект обнаружения был замечательным. Sun et al. [23] объединили теорию нечётких множеств и алгоритм ранжирования многообразий (FSMR), что решило проблему идентификации зелёных яблок в областях со схожим фоном. Вышеуказанный метод достигает обнаружения целевых плодов с помощью более зрелой модели и лучше справляется с целевой задачей, но методы устарели и не могут адаптироваться к реальным потребностям обнаружения зелёных яблок в современных сложных условиях. С непрерывными исследованиями в машинном обучении, появление метода опорных векторов (SVM) предоставило новые идеи для обнаружения целевых плодов. Zhang et al. [24], Kurtulmus et al. [25], Chaivivatrakul et al. [26], Kusumam et al. [27] и Wang et al. [28] использовали метод SVM для обнаружения целевых плодов, который прост и эффективен, но сложен в обучении при работе с большими наборами данных и не позволяет одновременно обнаруживать несколько различных видов целей. Zhang et al. [29] идентифицировали яблоки с помощью искусственных нейронных сетей (ANN), Li et al. [30] реализовали обнаружение плодов черники с использованием метода k-ближайших соседей (KNN). Li et al. [31] достигли эффективного обнаружения плодов яблони с помощью алгоритма случайного леса. Liao et al. [32] применили пороговую сегментацию Оцу в RGB-пространстве и фильтрацию к изображениям и использовали алгоритм случайного леса для распознавания зелёных яблок со средней правильной степенью распознавания 88%.
2.2. Глубокое обучение
В настоящее время, с непрерывным прогрессом технологий и развитием аппаратного обеспечения, проблемы большого объёма памяти и длительного времени обучения глубокого обучения были решены, и глубокое обучение теперь играет важную роль в обнаружении фруктов и овощей. Jia et al. [33] заметно улучшили точность обнаружения целей-яблок в условиях перекрытия и закрытия листьями, доработав модель сегментации экземпляров Mask R-CNN для адаптации к обнаружению целей-яблок и объединив ResNet с ResNeXt в качестве сети извлечения признаков исходной модели. Jia et al. [34] расширили Mask R-CNN, встроив механизм внимания для большего фокуса на информативных пикселях, но также подавляя шум, вызванный неблагоприятными факторами (заслонения, перекрытия и т.д.), что могло быть более подходящим и робастным для работы в сложной естественной среде. Wang et al. [35] применили dilated convolution к модулю res4b основной сети Mask RCNN, ResNet, для обнаружения восковницы. Вышеуказанные методы, combined с Mask-RCNN, обладают сильной способностью к расширению и высокой точностью обнаружения, могут быть лучше приспособлены для обнаружения целевых плодов, но модели требуют увеличенного объёма вычислений и более длительного времени обучения. Stein et al. [36] и Gan et al. [37] combined обнаружение фруктов и овощей с Faster-RCNN, что привело к более быстрому обучению моделей обнаружения и более высокой точности обнаружения, что позволяет лучше адаптироваться к обнаружению целевых плодов. Bi et al. [38] и Bargoti et al. [39] применили CNN к обнаружению плодов для обработки многомерных данных и достигли лучших результатов. Lin et al. [40] и Wang et al. [41] представили FCN как модель с эффективной памятью для ускорения обучения модели. С популярностью модели YOLO многие учёные applied разные версии модели YOLO (Fu et al. [42], Fu et al. [43], Yan et al. [44]) к обнаружению фруктов и овощей, что является быстрым, универсальным и имеет низкий уровень ложных обнаружений, но точность модели низкая, а полнота низкая.
2.3. На основе Трансформера или механизма внимания
Модель Трансформер, содержащая несколько механизмов внимания, предложенная Vaswani et al. [20] в 2017 году, впервые позволила ввести модель Трансформер, построенную на механизмах внимания, в модель обнаружения объектов DETR с хорошими результатами, что предоставило новые идеи в области обнаружения объектов. Wang et al. [45] использовали модели Swin Transformer и DETR для обнаружения гроздей винограда, модель получила впечатляющее значение mAP 94% при IoU = 0.5, предоставив новое решение для точного сбора урожая в сельском хозяйстве. Sun et al. [46] предложили модель GHFormer-Net для обнаружения маленьких зелёных яблок или плодов яблони ягодной в ночных условиях, введя механизм gradient harmonizing. Основанный на Трансформере PVTv2-B1 использовался в качестве основной сети для извлечения информации о признаках,打破了 ограничение извлечения информации из локальных областей с помощью пространственной свёртки. Xiao et al. [47] и Lu et al. [48] использовали механизм внимания в обнаружении яблок с высокой точностью и робастностью, что эффективно решает проблему распознавания яблок. Zheng et al. [49] предложили метод, который использует Swin Transformer для извлечения признаков изображения клубники, а затем передаёт признаки в MLP для идентификации клубники. Zheng et al. [50] предложили U-Net с attention feature fusion, названный AFFU-Net, для усиления способности к обучению признаков и повышения точности обнаружения трещин.
3. Материалы и методы
3.1. Материалы
Исследование было сосредоточено на получении изображений незрелых зелёных яблок (сорт Гала) на базе производства яблок «Лунваншань», которая является частью Экспериментальной базы агроинформационных технологий Шаньдунского педагогического университета в районе Фушань, город Яньтай, провинция Шаньдун. Изображения были сняты с помощью зеркальной камеры Canon EOS 80D, оснащённой КМОП-сенсором, producing изображения высокого разрешения 6000 × 4000 пикселей в формате JPG с 24-битным цветом. Процесс получения изображений учитывал реальную среду сада, охватывая различные условия естественного освещения, включая прямой солнечный свет, контровое освещение, сильный и слабый свет, а также искусственное ночное освещение. Изображения также были сделаны под разными углами, с учётом таких факторов, как заслонение листьями, перекрытие плодов и разные дистанции съёмки, как показано на Рисунке 1.

Рисунок 1. Изображения зелёных яблок в различных условиях освещения и ракурсах.
Всего было собрано 1361 изображение, запечатлевшее ряд сложных условий, таких как ночь, перекрывающиеся плоды, контровое освещение, затенение и эффекты после дождя. Эти условия часто затрудняли distinguish целевой плод от фона из-за слабого освещения, перекрытия ветками или листьями, теней и капель дождя. Для подготовки набора данных к обучению модели исходные изображения были обрезаны до 4000 × 4000 пикселей и далее уменьшены до 512 × 512 пикселей. Изображения были вручную размечены с помощью инструмента LabelMe, где был отмечен краевой контур плодов зелёного яблока, а внутренняя часть точек аннотации была designated как плод, а остальное — как фон. Эта информация аннотации была сохранена в JSON-файлах, соответствующих исходным изображениям, и позже преобразована в набор данных формата COCO.
Набор данных включает в себя всего 7137 размеченных зелёных яблок, categorized в три класса размеров согласно определениям MS COCO: 3101 цель крупного масштаба, 2762 цели среднего масштаба и 1274 цели малого масштаба. Эта категоризация обеспечивает сбалансированное представление across разных размеров плодов, что крайне важно для проверки робастности нашей модели обнаружения. Для дальнейшего разъяснения распределения нашего набора данных мы включили распределение данных, иллюстрирующее количество изображений при различных условиях освещения и уровнях заслонения, а также распределение заслонённых и не заслонённых экземпляров яблок, как показано в Таблице 2.
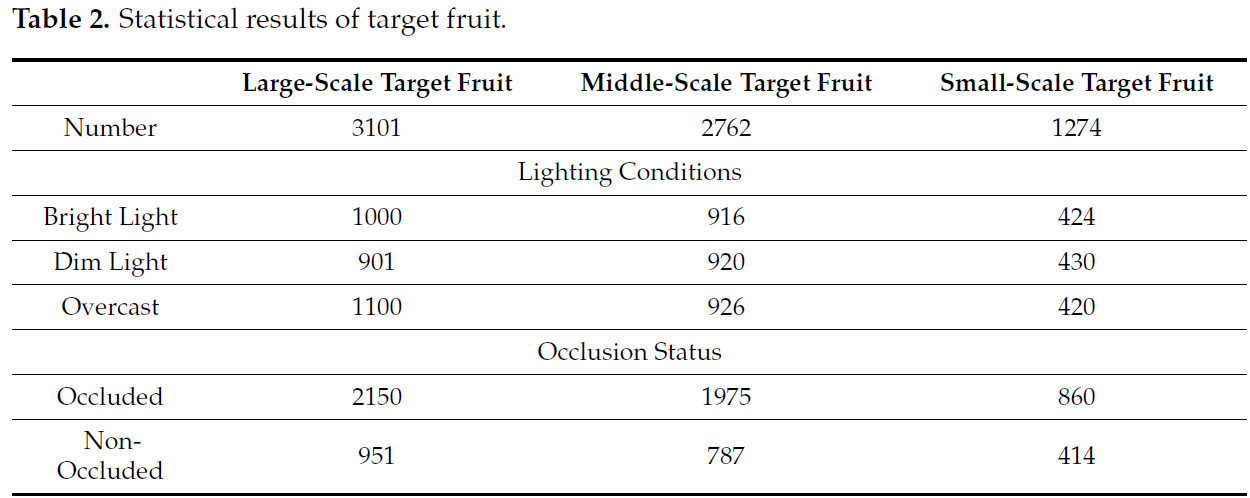
Таблица 2. Статистические результаты по целевым плодам.
Критерии категоризации по размеру следующие:
- Цели малого масштаба: Яблоки, которые занимают менее 32 пикселей на изображении;
- Цели среднего масштаба: Яблоки, которые занимают от 32 до 96 пикселей на изображении;
- Цели крупного масштаба: Яблоки, которые занимают более 96 пикселей на изображении.
Эти пороговые значения основаны на площади объекта на изображении и соответствуют conventions, используемым в наборе данных MS COCO, обеспечивая сопоставимость и стандартизацию в наших оценках.
Набор данных разделён на обучающий набор, состоящий из 953 изображений, и тестовый набор, состоящий из 408 изображений, сохраняя соотношение 7:3. Это разделение позволяет провести всестороннюю фазу обучения, одновременно предоставляя substantial набор данных для rigorous тестирования и валидации производительности нашей модели. Умеренная доля размеров и количества плодов в наборе данных способствует проверке эффективности модели в различных реальных сценариях.
Для более детального понимания состава набора данных и оценки производительности модели на объектах разного размера мы определяем следующие метрики производительности:
AP_S (Средняя точность для малых целей): Средняя точность модели при обнаружении целей-яблок малого масштаба.
AP_M (Средняя точность для средних целей): Средняя точность модели при обнаружении целей-яблок среднего масштаба.
AP_L (Средняя точность для крупных целей): Средняя точность модели при обнаружении целей-яблок крупного масштаба.
Эти метрики будут использоваться для оценки точности модели при обнаружении яблок разных размеров, предлагая nuanced представление о её производительности across набору данных.
3.2. Методы
Реальная рабочая среда сада относительно сложна. Под влиянием освещения и положения камеры полученные изображения отображают различные формы. Кроме того, поскольку цвет зелёных яблок близок к фону, это создаёт новые challenges для обнаружения объектов в системе зрения. В традиционных фреймворках обнаружения объектов процесс распознавания объектов на изображении включает сложную серию шагов. Сначала регионы, которые могут содержать объекты, идентифицируются через сеть предложения регионов, за которыми следует дальнейшая обработка, включая извлечение признаков и классификацию, чтобы определить класс объектов, представленных каждым регионом. Однако DETR отказывается от этой пошаговой стратегии обработки в пользу механизма сквозного предсказания. DETR достигает простоты в процессе обнаружения объектов, предсказывая точное местоположение и метки категорий объектов непосредственно из всего изображения. Модель принимает алгоритм двудольного сопоставления и структуру трансформер-энкодера-декодера для реализации сквозного обнаружения.
Хотя DETR имеет superior производительность, у него также есть некоторые defects: (1) По сравнению с существующими детекторами зелёных яблок, ему требуется более длительное время обучения для сходимости. (2) Производительность обнаружения целевых плодов малого масштаба низкая. Он не использует многоуровневые признаки, потому что карта признаков высокого разрешения увеличит вычислительную сложность до неприемлемой степени. Поэтому мы предлагаем метод на основе оптимизированного deformable DETR детектора зелёных яблок, который вводит сеть ResNeXt для извлечения признаков изображения и уменьшения потерь информации в процессе извлечения признаков, и используется механизм деформируемого внимания для повышения точности. Как показано на Рисунке 2, метод сначала извлекает признаки изображения из входного изображения через ResNeXt, и после групповой свёртки в ResNeXt точность карты признаков оптимизируется, что может эффективно уменьшить потерю точности модели при извлечении признаков и оптимизировать конечный эффект обнаружения. Извлечённые признаки combined с информацией позиционного кодирования поступают в энкодер обнаружения зелёных яблок, вводится механизм деформируемого внимания для обработки признаков, генерируется рамка обнаружения декодером обнаружения зелёных яблок, и избыточные рамки обнаружения устраняются FFN для получения конечного результата обнаружения.

Рисунок 2. Блок-схема новой модели обнаружения объектов.
3.2.1. Базовая сеть ResNeXt
ResNeXt — это сеть с групповой свёрткой, которая получает больше информации о признаках при минимальном количестве параметров на основе признаков. Она повышает повторную используемость признаков до более высокого уровня. Для каждого слоя карты признаков предыдущих слоев используются как вход, карты признаков обрабатываются с использованием 32-групповой групповой свёртки 3 × 3 при обработке признаков, карты признаков интегрируются с использованием свёртки 1 × 1, и карты признаков с каждого шага используются как вход для всех последующих слоёв. Эта структура усиливает производительность передачи признаков и гарантирует, что низкоразмерные признаки не отбрасываются, что может реализовать чувствительность к областям малых целей. Структура сети показана на Рисунке 3. Карты признаков {𝑥𝑙}𝐿−1𝑙=1 (L = 4) с третьего по пятый этапы в ResNeXt извлекаются, и необходимые для модели карты признаков 𝐶0, 𝐶1 и 𝐶2 получаются после преобразования свёрткой 1 × 1.
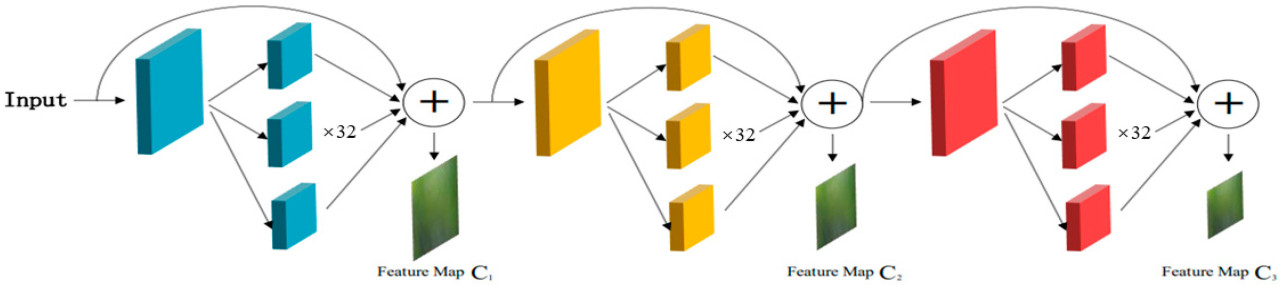
Рисунок 3. Схема структуры ResNeXt.
В этом исследовании модель использует групповую свёртку для извлечения признаков и включает идею групповой свёртки в каждый модуль извлечения признаков, чтобы уменьшить потерю информации при извлечении признаков. Чтобы обеспечить максимальный поток информации между слоями, все слои сети directly соединены. Вход каждого слоя — это сумма отображённых выходов предыдущего слоя и его собственного результата отображения признаков, maintaining свойство feed-forward.
3.2.2. Энкодер обнаружения зелёных яблок

где m— индекс внимания,l обозначает уровень входных данных, а k обозначает точку выборки.

и 𝐶5 сворачивается с помощью свертки 3 × 3 с шагом 2 для получения многомасштабной карты объектов с низким разрешением𝐶6Полученные значения признаков объединяются с кодировкой положения и обрабатываются многомасштабным модулем внимания в декодере. Ключевыми и запросными элементами являются пиксельные точки на многомасштабной карте признаков. Каждый запросный пиксель принимает себя за опорную точку, и для определения слоя признаков, из которого он взят, модель добавляет встраивание масштабного уровня в представление признаков как𝑒𝑙В дополнение к позиционному встраиванию. В отличие от кодирования, которое представляет собой встраивание с фиксированной позицией, встраивание на уровне масштаба {𝑥𝑙}𝐿𝑖 = 1 инициализируется случайным образом и обучается с помощью сети.
В извлеченных многомасштабных картах признаков целевого фрукта, точки признаков, расположенные в разных слоях признаков, могут иметь одинаковые координаты (H,W), поэтому невозможно различить позиционное кодирование. Поэтому для различения слоев признаков добавляется встраивание на уровне масштаба. Кодер оптимизированной модели заменяет нативное внимание деформируемым вниманием. Входом и выходом кодера являются многомасштабные карты признаков с равным разрешением, где разрешение относится к входу разных энкодеров в одном и том же масштабе. Многомасштабные карты признаков напрямую выводятся из последних трех слоев ResNeXt, а не из FPN, поскольку модуль многомасштабного деформируемого внимания может интегрировать и обмениваться информацией разных масштабов.
3.2.3. Декодер обнаружения зелёных яблок
Декодер содержит модуль перекрёстного внимания и модуль самовнимания. Для вышеуказанных модулей query элементы — это object queries. В модуле перекрёстного внимания object queries извлекают признаки из карты признаков и получают ключевые элементы из выхода энкодера. В модуле самовнимания object queries взаимодействуют друг с другом, где ключевые элементы — это object queries. Модуль деформируемого внимания designed для обработки свёрточных отображений признаков как ключевых элементов, и мы заменяем только каждый модуль перекрёстного внимания на многоуровневый модуль деформируемого внимания, оставляя модуль самовнимания неизменным.
Декодер декодирует N разных входных embedding параллельно, используя механизмы много-голового самовнимания и внимания энкодер-декодер. Каждый декодер имеет два входа: результаты, сгенерированные энкодером, и object queries. Последние — это изученное нами позиционное кодирование выхода, чья функция — предоставлять отношение между целью и глобальным изображением в процессе обучения, equivalent к глобальному вниманию. N object queries преобразуются в выходные embedding декодером, а затем independently декодируются в координаты ограничивающих рамок и метки категорий с помощью prediction feed-forward сети, таким образом generating N конечных предсказаний.
Поскольку deformable внимание действует на свёрточный слой, многоуровневое deformable внимание заменяет только модуль перекрёстного внимания, в то время как модуль самовнимания remains unchanged. Для каждого object query, двумерные нормализованные координаты соответствующей опорной точки изучаются через линейный слой и sigmoid функцию, и затем может быть использована операция deformable свёртки. В дополнение, модель возвращает DETR к идее использования относительной координатной регрессии, и расстояние относительно опорной точки регрессируется при предсказании ограничивающей рамки, что также может ускорять сходимость обучения.
3.2.4. Прямоточная сеть (Feed-Forward Network)
DETR использует прямоточную сеть для предсказания выходов декодера. Декодер производит два основных выхода: ветвь классификации, responsible для предсказания меток категорий целевых объектов, и ветвь регрессии, которая предсказывает центральное положение, ширину и высоту ограничивающей рамки целевого объекта. Количество предсказанных ограничивающих рамок фиксировано на 𝑁, что намного больше фактического количества целевых яблок, поэтому метки категорий делятся на целевой плод и фон.
3.2.5. Функция потерь
Модель реализует способность обнаруживать зелёные плоды, uniquely сопоставляя результаты предсказания с размеченной информацией через функцию потерь. Модель DETR [18] вычисляет потери в два шага: (1) Вычисляется двудольное сопоставление между выходом модели и ground truth. (2) Для успешно сопоставленных пар данных supervise их категории и ограничивающие рамки.


Параметры β1 и β2 используются для настройки зависимости оптимизатора Adam от прошлой информации о градиенте во время обновлений, балансируя стабильность и скорость сходимости процесса обучения. Скорости обучения линейных проекций умножаются на коэффициент 0.1. M=4 — количество голов внимания, и K = 6 — размер окна внимания. Кроме того, вес Focal Loss установлен на 2, а количество object queries увеличено с 100 до 300 для классификации ограничивающих рамок. Энкодер и декодер установлены на 6 слоёв каждый, а базовая сеть для извлечения признаков установлена на 3 слоя. В общей сложности модели обучаются в течение 100 эпох, и скорость обучения затухает на 20-й эпохе на коэффициент 0.1. Кроме того, мы implemented раннюю остановку как критерий для предотвращения переобучения и обеспечения эффективного обучения нашей модели. Мы останавливали процесс обучения, если производительность, измеряемая specified метрикой, не показывала значительного улучшения в течение установленного числа 5 эпох.
3.2.6. Подробности реализации
Мы используем оптимизатор Adam для обучения модели и устанавливаем базовую скорость обучения как 2 ×10− 4, β1= 0,9, β2= 0,999, размер партии как 2, а снижение веса как 10− 4.
Параметры β1 и β2 используются для корректировки зависимости оптимизатора Adam от информации о прошлых градиентах во время обновлений, обеспечивая баланс между устойчивостью и скоростью сходимости процесса обучения. Скорость обучения линейных проекций умножается на коэффициент 0,1.М = 4 — количество головок внимания, а K = 6 — размер окна внимания. Кроме того, вес фокальной потери установлен равным 2, а количество запросов объектов увеличено со 100 до 300 для классификации по ограничивающему прямоугольнику. Кодер и декодер установлены на 6 слоев соответственно, а магистральная сеть для извлечения признаков — на 3 слоя. В общей сложности модели обучаются в течение 100 эпох, и скорость обучения снижается на 20-й эпохе с коэффициентом 0,1. Кроме того, мы реализовали раннюю остановку в качестве критерия для предотвращения переобучения и обеспечения эффективности обучения нашей модели. Мы останавливали процесс обучения, если производительность, измеряемая указанной метрикой, не показывала значительного улучшения для заданного количества эпох из 5.
3.2.7. Оценочные показатели
В этом эксперименте точность (precision) и полнота (recall) используются как эффективные метрики оценки для модели. Точность рассчитывается с использованием Формулы (6), а полнота — с использованием Формулы (7). В приведённых ниже уравнениях TP — это количество истинно-положительных примеров, т.е., когда фактические и предсказанные результаты — это яблоки.
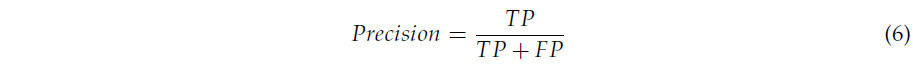

FP — это количество ложно-положительных примеров, т.е., когда фактические результаты — это фон, но предсказанные исходы — яблоки; FN — это количество ложно-отрицательных примеров, т.е., когда фактические результаты — это яблоки, но предсказанные исходы — фон.
Кроме того, как показано в Таблице 3, в этой статье также используются следующие оценочные показатели. Пожалуйста, обратитесь к MS COCO для получения конкретных details определений.

Таблица 3. Экспериментальные оценочные показатели.
4. Экспериментальные результаты
Все связанные эксперименты были завершены на одном серверном устройстве. Основная конфигурационная среда сервера была: Операционная система Ubuntu 16.04.6, графическая карта NVIDIA Tesla V100 и среда CUDA 10.1. Все модели использовали язык Python и библиотеку машинного обучения PyTorch, а экспериментальная среда была built с помощью relevant модулей во фреймворке MMDetection [52].
В эксперименте relevant параметры были установлены следующим образом: количество раундов обучения установлено на 300, размер пакета (batch size) установлен на 16, и после каждого раунда обучения результаты обучения модели проверялись с использованием валидационного набора. Начальная скорость обучения установлена на 0.01, и использовался оптимизатор стохастического градиентного спуска (SGD) с затуханием веса 0.0005 для предотвращения переобучения модели.
4.1. Производительность обнаружения модели
Изображения, собранные в эксперименте, fully учитывают реальные сложные сцены садов, включая изображения под влиянием различного освещения и под разными углами, таких как верхний свет, контровой свет, перекрытие, затенение ветками и листьями, ночь и другие смешанные помехи. Эффект обнаружения яблок оптимизированной моделью обнаружения зелёных целевых плодов, построенной в этом исследовании, показан на Рисунке 4. Рисунок 4a,b показывает эффект обнаружения плодов при дневном ровном свете, Рисунок 4c,d — эффект обнаружения плодов ночью, Рисунок 4e,f — эффект обнаружения плодов при дневном контровом свете, Рисунок 4g,h — эффект обнаружения затенённых плодов, и Рисунок 4i,j — эффект обнаружения перекрытых плодов. Как видно на Рисунке 4, эффект лучше при сравнении эффекта обнаружения плодов при дневном ровном свете с эффектом ночного обнаружения плодов; эффект обнаружения плодов при дневном ровном свете относительно лучше при сравнении с эффектом обнаружения плодов при дневном контровом свете; поскольку дальнее изображение содержит больше плодов с меньшими целями, результат обнаружения хуже по сравнению с эффектом калибровки ближнего изображения; условия заслонения и перекрытия оказывают определённое влияние на обнаружение плодов, и эффект обнаружения slightly хуже. Эффект обнаружения плодов при ровном свете и после дождя relatively хороший, и эффект обнаружения независимых плодов без заслонения и перекрытия является наилучшим.

Рисунок 4. Производительность обнаружения нашего метода. (a,b) показывают результаты обнаружения плодов при ровном свете за 368 дней; (c,d) демонстрируют результаты обнаружения плодов ночью на 369 день; (e,f) иллюстрируют результаты обнаружения плодов при контровом свете днём, в то время как (g,h) представляют результаты обнаружения затенённых плодов, и (i,j) изображают результаты обнаружения перекрытых плодов на 371 день.
4.2. Абляционные эксперименты
Чтобы проверить влияние модулей ResNeXt и механизма деформируемого внимания на производительность модели, это исследование провело серию абляционных экспериментов для тщательного изучения эффективности этих двух подходов. В этих экспериментах мы сначала integrated сеть ResNeXt в базовую модель DETR и сравнили производительность до и после добавления этого модуля для обнаружения, чтобы оценить его эффективность улучшения. Впоследствии модуль механизма деформируемого внимания был further введён, чтобы исследовать его specific влияние на производительность модели. Результаты экспериментов представлены в Таблице 4, предоставляя detailed сравнение производительности при различных конфигурациях модулей.

Таблица 4. Влияние ResNeXt и механизма деформируемого внимания на экспериментальные результаты.
Это исследование employed постепенный подход интеграции для meticulous анализа вклада различных модулей в производительность моделей обнаружения объектов. Базовая модель achieved AP 51.5%, 𝐴𝑃50 79.9% и 𝐴𝑃75 54.2, с точностью при разных размерах (AP) в диапазоне от 82.5% до 31.5% across различных порогов.
При solely интеграции сети ResNeXt AP увеличился до 52.1%, в то время как 𝐴𝑃50 slightly уменьшился до 79.7%. AP при пороге 75% уменьшился до 53.7%, и 𝐴𝑃𝑠 увеличился до 33.6%. 𝐴𝑃𝑚 уменьшился до 58.6, и 𝐴𝑃𝑙 увеличился до 83.3%.
При solely интеграции модуля механизма деформируемого внимания модель exhibited улучшение AP до 53.6% и 𝐴𝑃50 до 80.1%. AP при пороге 75% увеличился до 57.5%, и 𝐴𝑃𝑠 увеличился до 34.8%. 𝐴𝑃𝑚 увеличился до 59.8%, и 𝐴𝑃𝑙 увеличился до 84.5%.
Наконец, при интеграции как модулей ResNeXt, так и механизма деформируемого внимания в модель, AP further улучшился до 54.1%, и 𝐴𝑃50 увеличился до 80.4%, indicating значительное улучшение общей производительности модели. AP при 75% достиг пика 58.0%, и 𝐴𝑃𝑠 увеличился до 35.4%. 𝐴𝑃𝑚 увеличился до 60.2%, и 𝐴𝑃𝑙 увеличился до 85.0%.
Экспериментальные результаты indicate, что каждый модуль вносит вклад в улучшение точности модели. Representative результаты обнаружения на наборе данных цветения яблони illustrated на Рисунке 5. В задачах обнаружения объектов существует компромисс между улучшением производительности модели и количеством involved вычислительных параметров.

Рисунок 5. Производительность обнаружения нашего метода на наборе данных цветения яблони. (a–e) демонстрируют производительность обнаружения модели на наборе данных цветения яблони, achieving хорошую точность в различении между опылённым и неопылённым состоянием цветков.
Экспериментальные результаты indicate, что каждый модуль способствует повышению точности модели, но индивидуальное использование каждого модуля не significantly улучшает производительность модели. Однако при интеграции сети ResNeXt и модуля механизма деформируемого внимания модель showed значительные улучшения в AP, 𝐴𝑃50, 𝐴𝑃75, 𝐴𝑃𝑠, 𝐴𝑃𝑚 и 𝐴𝑃𝑙. Это indicates, что хотя улучшение от использования этих двух модулей по отдельности limited, их combined применение может significantly улучшить общую производительность модели.
4.3. Сравнение производительности обнаружения
Как показано в Таблице 4, несмотря на наличие ложных срабатываний и пропущенных обнаружений, наш предложенный метод значительно превосходит существующие подходы по точности при обнаружении зелёных целевых плодов на сельскохозяйственных изображениях. В частности, средняя точность (AP) нашей модели для обнаружения зелёных хурм составляет 54.1%, showcasing notable улучшение по сравнению с well-established моделями, такими как Faster R-CNN [53] и Mask R-CNN [54], а также более recent моделями, такими как TOOD [55]. По сравнению с TOOD, наш метод демонстрирует улучшение AP на 4.0%, в то же время outperforming Deformable DETR на 2.0%. Кроме того, наша модель achieves значительные выигрыши в средней точности across нескольким оценочным метрикам. Например, наша модель работает с наилучшей точностью для 𝐴𝑃50, 𝐴𝑃75 и 𝐴𝑃𝑙 с точностью 80.4%, 58.0% и 85.0% соответственно. Наш метод на 0.6% выше, чем TOOD, по 𝐴𝑃50, на 8.1% выше, чем Faster R-CNN, по 𝐴𝑃75, и на 11.1% выше, чем Mask. Однако производительность этой модели в 𝐴𝑃𝑠 всего на 1.8% ниже, чем у TOOD, что может удовлетворять большинству потребностей сельскохозяйственного производства. Кроме того, наш метод на 2.9% выше, чем Yolov10, по 𝐴𝑃𝑙, на 2.2% выше, чем Yolov8, по AP, и на 1.2% выше, чем Yolov9, по 𝐴𝑃𝑠. Эти результаты indicate, что по сравнению как со зрелыми, так и с передовыми моделями, наш метод демонстрирует superior точность обнаружения и робастность. Улучшенная точность, особенно при обнаружении зелёных плодов в различных сельскохозяйственных условиях, highlights практическую применимость нашей модели в умном сельском хозяйстве. Более того, модель всё ещё имеет высокую точность и эффективность на наборе данных цветения яблони, доказывая её способность удовлетворять реальным требованиям сельскохозяйственных работ.
Из Таблицы 5 и Рисунка 6 видно, что наш метод имеет улучшенную точность по сравнению с Deformable DETR и может лучше обнаруживать зелёные целевые плоды для задачи в реальной садовой среде. Точность AP нашего метода составляет 54.1%, что на 2.6% лучше, чем у Deformable DETR. Deformable DETR плохо работает в точности малых целей, точность нашей модели по 𝐴𝑃𝑠 составляет 35.4%, и модель улучшается на 3.9% по сравнению с 𝐴𝑃𝑠 Deformable DETR, что может лучше адаптироваться к зелёным целям в садах. Модель может лучше адаптироваться к ситуации с малыми зелёными целевыми плодами в садах. Следовательно, наша модель имеет лучшую точность, чем Deformable DETR, что более подходит для требований точности сельскохозяйственного обнаружения.
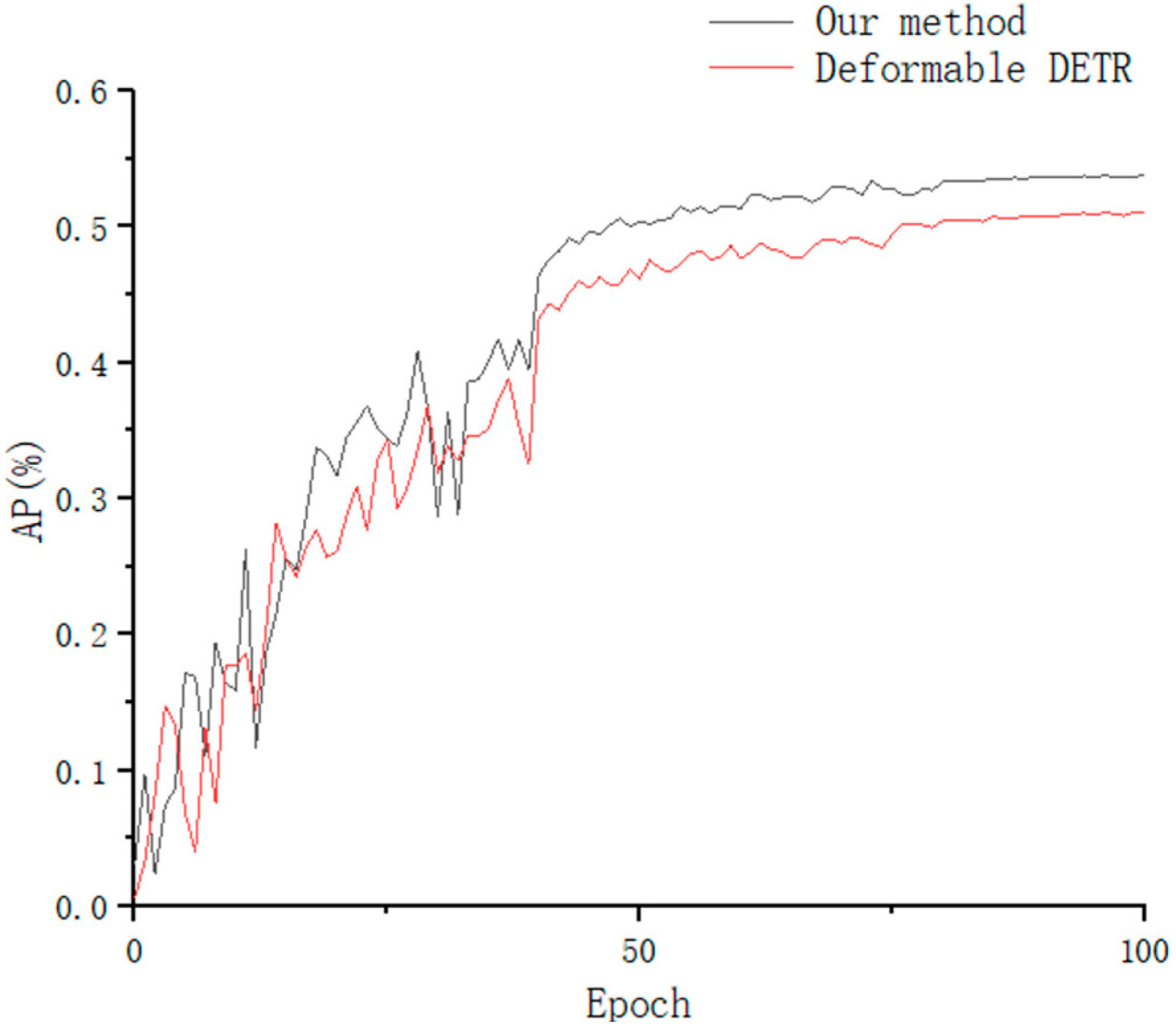
Рисунок 6. Линейный график, сравнивающий точность нашего метода с Deformable DETR.
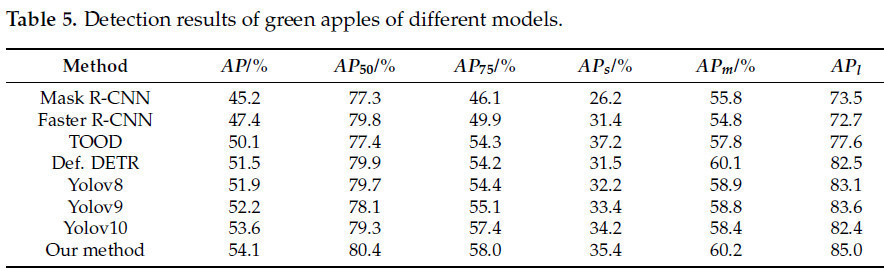
Таблица 5. Результаты обнаружения зелёных яблок разными моделями.
После вышеуказанного анализа, через точность обнаружения целей, данный исследовательский метод achieved relatively хорошие результаты, которые могут basically выполнить задачу обнаружения зелёных целевых плодов, улучшить точность идентификации плодов и адаптироваться к задаче обнаружения зелёных целевых плодов в реальных условиях сада. В то же время, обнаружение статуса опыления цветков яблони на наборе данных цветков яблони также может achieve хорошие результаты, further проверяя, что модель имеет сильную способность к обобщению и робастность, предоставляя новые идеи для обнаружения других объектов в интеллектуальном сельском хозяйстве.
5. Выводы
Чтобы избежать влияния света, позы и других факторов на обнаружение зелёных плодов в сложной садовой среде, предложена оптимизированная модель Deformable DETR для обнаружения зелёных яблок. Метод вводит сеть ResNeXt для извлечения признаков изображения и уменьшения потерь информации в процессе извлечения признаков; механизм деформируемого внимания используется для повышения точности и оптимизации результатов обнаружения. Экспериментальные результаты показывают, что оптимизированная модель обнаружения DETR может эффективно достигать точного обнаружения зелёных целевых плодов, и эффективность работы также улучшается. Новый подход хорошо решает проблему обнаружения целевых плодов в сложных условиях и может быть далее расширен для решения задач распознавания других зелёных сферических фруктов, расширяя thus область применения машинного сбора и замера урожайности сада. Настоящий метод требует больших вычислительных затрат и относительно высоких аппаратных требований. В будущем он будет оптимизирован для проблем с высоким объёмом вычислений, чтобы удовлетворить реальные производственные потребности без снижения точности. Также важно решить проблему плохой точности малых целей из-за poor точности обнаружения модели на основе внимания для маленьких объектов.
Хотя это исследование предоставляет предварительный анализ и результаты для обнаружения зелёных яблок, мы признаём необходимость дальнейшего изучения. Будущая работа будет включать проектирование и проведение серии экспериментов для систематической оценки влияния различных факторов окружающей среды на производительность обнаружения и оптимизации нашего алгоритма обнаружения на основе результатов этих экспериментов. Мы планируем проверять и дорабатывать нашу схему обнаружения через эти эксперименты, с конечной целью разработки системы обнаружения зелёных яблок, которая работает надёжно в различных условиях. Кроме того, мы будем исследовать интеграцию методов машинного обучения в наш процесс обнаружения, чтобы повысить его точность и адаптивность. Мы с нетерпением ждём, что эти будущие исследования предоставят более глубокие идеи и более эффективные решения в области обнаружения зелёных яблок.
Ссылки
1. Joshi, A.; Pradhan, B.; Gite, S.; Chakraborty, S. Remote-sensing data and deep-learning techniques in crop mapping and yield prediction: A systematic review. Remote Sens. 2023, 15, 2014. [Google Scholar] [CrossRef]
2. Kuradusenge, M.; Hitimana, E.; Hanyurwimfura, D.; Rukundo, P.; Mtonga, K.; Mukasine, A.; Uwitonze, C.; Ngabonziza, J.; Uwamahoro, A. Crop yield prediction using machine learning models: Case of Irish potato and maize. Agriculture 2023, 13, 225. [Google Scholar] [CrossRef]
3. Jia, W.; Zhang, Y.; Lian, J.; Zheng, Y.; Zhao, D.; Li, C. Apple harvesting robot under information technology: A review. Int. J. Adv. Robot. Syst. 2020, 17, 25310. [Google Scholar] [CrossRef]
4. Bai, Y.; Mao, S.; Zhou, J.; Zhang, B. Clustered tomato detection and picking point location using machine learning-aided image analysis for automatic robotic harvesting. Precis. Agric. 2023, 24, 727–743. [Google Scholar] [CrossRef]
5. Lv, J.; Xu, H.; Xu, L.; Zou, L.; Rong, H.; Yang, B.; Niu, L.; Ma, Z. Recognition of fruits and vegetables with similar-color background in natural environment: A survey. J. Field Robot. 2022, 39, 888–904. [Google Scholar] [CrossRef]
6. Zou, Z.; Chen, K.; Shi, Z.; Gao, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
7. Xiao, F.; Wang, H.; Li, Y.; Cao, Y.; Lv, X.; Xu, G. Object detection and recognition techniques based on digital image processing and traditional machine learning for fruit and vegetable harvesting robots: An overview and review. Agronomy 2023, 13, 639. [Google Scholar] [CrossRef]
8. Zhao, Z.Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
9. Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
10. Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
11. Taghanaki, S.A.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
12. Gadekallu, T.R.; Rajput, D.S.; Reddy, M.; Lakshmanna, K.; Bhattacharya, S.; Singh, S.; Jolfaei, A.; Alazab, M. A novel PCA–whale optimization-based deep neural network model for classification of tomato plant diseases using GPU. J. Real-Time Image Process. 2021, 18, 1383–1396. [Google Scholar] [CrossRef]
13. Maurício, J.; Domingues, I.; Bernardino, J. Comparing vision transformers and convolutional neural networks for image classification: A literature review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
14. Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
15. Saleem, M.H.; Potgieter, J.; Arif, K.M. Automation in agriculture by machine and deep learning techniques: A review of recent developments. Precis. Agric. 2021, 22, 2053–2091. [Google Scholar] [CrossRef]
16. Tang, Y.C.; Wang, C.; Luo, L.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
17. Yang, Y.; Han, Y.; Li, S.; Yang, Y.; Zhang, M.; Li, H. Vision based fruit recognition and positioning technology for harvesting robots. Comput. Electron. Agric. 2023, 213, 108258. [Google Scholar] [CrossRef]
18. Kong, J.; Deveci, M.; Jin, X.; Zhong, K. ADCT-Net: Adaptive traffic forecasting neural network via dual-graphic cross-fused transformer. Inf. Fusion 2024, 103, 102122. [Google Scholar] [CrossRef]
19. Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
20. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
21. Friedman, D.; Wettig, A.; Chen, D. Learning transformer programs. Adv. Neural Inf. Process. Syst. 2023, 37, 49044–49067. [Google Scholar]
22. Li, B.R.; Long, Y.; Song, H.B. Detection of green apples in natural scenes based on saliency theory and Gaussian curve fitting. Int. J. Agric. Biol. Eng. 2018, 11, 192–198. [Google Scholar] [CrossRef]
23. Sun, S.S.; Wu, Q.; Jiao, L.; Long, Y.; He, D.; Song, H. Recognition of green apples based on fuzzy set theory and manifold ranking algorithm. Optik 2018, 165, 395–407. [Google Scholar] [CrossRef]
24. Zhang, C.L.; Zhang, J.; Zhang, J.X.; Li, W. Recognition of green apple in similar background. Trans. Chin. Soc. Agric. Mach. 2014, 45, 277–281. (In Chinese) [Google Scholar]
25. Kurtulmus, F.; Lee, W.S.; Vardar, A. Immature peach detection in colour images acquired in natural illumination conditions using statistical classifiers and neural network. Precis. Agric. 2014, 15, 57–79. [Google Scholar] [CrossRef]
26. Chaivivatrakul, S.; Dailey, M.N. Texture-based fruit detection. Precis. Agric. 2014, 15, 662–683. [Google Scholar] [CrossRef]
27. Kusumam, K.; Krajník, T.; Pearson, S.; Cielniak, G.; Duckett, T. Can you pick a broccoli? 3D-vision based detection and localisation of broccoli heads in the field. 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 646–651. [Google Scholar]
28. Wang, H.Q.; Ji, C.Y.; Gu, B.X.; An, Q. In-greenhouse cucumber recognition based on machine vision and least squares support vector machine. Trans. Chin. Soc. Agric. Mach. 2012, 43, 163–167. [Google Scholar]
29. Zhang, Y.; Li, M.; Qiao, J.; Liu, G. A segmentation algorithm for apple fruit recognition using artificial neural network. Aktualni zadaci mehanizacije poljoprivrede. Zb. Rad. 2008, 2008, 359–367. [Google Scholar]
30. Li, H.; Lee, W.S.; Wang, K. Identifying blueberry fruit of different growth stages using natural outdoor color images. Comput. Electron. Agric. 2014, 106, 91–101. [Google Scholar] [CrossRef]
31. Li, W.; Chen, M.; Xu, S.; Chen, X.; Qian, J.; Du, S.; Li, S.; Li, M. Diameter measurement method for immature apple based on watershed and convex hull theory. Trans. Chin. Soc. Agric. Eng. 2014, 30, 207–214. [Google Scholar]
32. Liao, W.; Zhang, L.; Li, M.; Sun, H.; Yang, W. Green apple recognition in natural illumination based on random forest algorithm. Trans. Chin. Soc. Agric. Mach. 2017, 48 (Suppl. 1), 86–91. (In Chinese) [Google Scholar]
33. Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
34. Jia, W.; Zhang, Z.; Shao, W.; Ji, Z.; Hou, S. RS-Net: Robust segmentation of green overlapped apples. Precis. Agric. 2022, 23, 492–513. [Google Scholar] [CrossRef]
35. Wang, Y.; Lv, J.; Xu, L.; Gu, Y.; Zou, L.; Ma, Z. A segmentation method for waxberry image under orchard environment. Sci. Hortic. 2020, 266, 109309. [Google Scholar] [CrossRef]
36. Stein, M.; Bargoti, S.; Underwood, J. Image based mango fruit detection, localisation and yield estimation using multiple view geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef]
37. Gan, H.; Lee, W.S.; Alchanatis, V.; Ehsani, R.; Schueller, J.K. Immature green citrus fruit detection using color and thermal images. Comput. Electron. Agric. 2018, 152, 117–125. [Google Scholar] [CrossRef]
38. Bi, S.; Gao, F.; Chen, J.W.; Zhang, L. Detection method of citrus based on deep convolution neural network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 181–186. [Google Scholar]
39. Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
40. Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Li, J. Guava detection and pose estimation using a low-cost RGB-D sensor in the field. Sensors 2019, 19, 428. [Google Scholar] [CrossRef] [PubMed]
41. Wang, D.; He, D. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network. Trans. Chin. Soc. Agric. Eng. 2019, 35, 156–163. [Google Scholar]
42. Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
43. Fu, L.; Duan, J.; Zou, X.; Lin, J.; Zhao, L.; Li, J.; Yang, Z. Fast and accurate detection of banana fruits in complex background orchards. IEEE Access 2020, 8, 196835–196846. [Google Scholar] [CrossRef]
44. Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
45. Wang, J.; Zhang, Z.; Luo, L.; Zhu, W.; Chen, J.; Wang, W. SwinGD: A robust grape bunch detection model based on Swin Transformer in complex vineyard environment. Horticulturae 2021, 7, 492. [Google Scholar] [CrossRef]
46. Sun, M.; Xu, L.; Luo, R.; Lu, Y.; Jia, W. GHFormer-Net: Towards more accurate small green apple/begonia fruit detection in the nighttime. J. King Saud Univ. -Comput. Inf. Sci. 2022, 34, 4421–4432. [Google Scholar] [CrossRef]
47. Xiao, B.; Nguyen, M.; Yan, W. Fruit ripeness identification using transformer model. SSRN 2022, 4129908. [Google Scholar] [CrossRef]
48. Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-attention-YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar] [CrossRef]
49. Zheng, H.; Wang, G.; Li, X. Swin-MLP: A strawberry appearance quality identification method by Swin Transformer and multi-layer perceptron. J. Food Meas. Charact. 2022, 16, 2789–2800. [Google Scholar] [CrossRef]
50. Zheng, Z.; Hu, Y.; Yang, H.; Qiao, Y.; He, Y.; Zhang, Y.; Huang, Y. AFFU-Net: Attention feature fusion U-Net with hybrid loss for winter jujube crack detection. Comput. Electron. Agric. 2022, 198, 107049. [Google Scholar] [CrossRef]
51. Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
52. Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, W.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
53. Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39(6), 1137–1149. [Google Scholar] [CrossRef]
54. He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
55. Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE Computer Society, Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]

Liu Q, Meng H, Zhao R, Ma X, Zhang T, Jia W. Green Apple Detector Based on Optimized Deformable Detection Transformer. Agriculture. 2025; 15(1):75.
Перевод статьи «Green Apple Detector Based on Optimized Deformable Detection Transformer» авторов Liu Q, Meng H, Zhao R, Ma X, Zhang T, Jia W., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)