Метод семантической сегментации детализированных 3D-моделей проростков томата с использованием оптимизированной свертки
Задача семантической сегментации трехмерных моделей растений с разделением на стебли и листья является ключевой для систем высокопроизводительного фенотипирования томатов. Однако существующие методы часто демонстрируют недостаточную точность и низкую скорость работы. Для решения этих проблем мы предлагаем новую архитектуру кодера-декодера, в которой используются оптимизированная воксельная свертка и механизм слияния признаков для повышения качества сегментации детализированных 3D-моделей проростков томата.
Аннотация
Для обучения и проверки метода применялся набор данных Pheno4D, содержащий трехмерные модели проростков томата с размеченными классами «лист», «стебель» и «грунт». Чтобы снизить вычислительные затраты и увеличить скорость обработки, модуль свертки был построен на основе остаточных связей и комбинации двух типов сверточных ядер.
Модуль слияния признаков, основанный на механизме внимания, был разработан для того, чтобы автоматически определять наиболее информативные особенности в данных. Это позволяет избежать ситуации, когда семантически разные точки получают схожие характеристики, а также способствует снижению уровня шума.
Для коррекции смещения модели в сторону преобладающих классов, вызванного неравномерным распределением точек, в процессе обучения использовалась комбинированная функция потерь Lovász-Softmax и взвешенной перекрестной энтропии, что позволило повысить общую производительность.
Результаты испытаний показали, что предложенный метод VSCAFF достигает среднего показателя IoU 86.96%, превосходя по точности модели PointNet, PointNet++ и DGCNN. Распределение по классам составило: грунт — 99.63%, стебли — 64.47%, листья — 96.72%. Время обработки одного образца — 35 мс, что также превышает скорость аналогов.
Полученные данные подтверждают, что метод VSCAFF обеспечивает высокую точность и скорость при семантической сегментации детализированных 3D-моделей томатов и может лечь в основу систем автоматического фенотипического анализа.
1. Введение
Томат, являясь одной из важнейших овощных культур, занимает первое место в мире по объему и стоимости экспорта и играет ключевую роль в мировом сельскохозяйственном производстве и торговле, занимая около 30% общемировых посевных площадей [1]. Для удовлетворения растущего спроса на томаты селекционеры применяют эффективные программы генетического отбора для выведения высокоурожайных и качественных сортов [2]. Высокопроизводительный фенотипический анализ растений томата может существенно помочь исследователям в анализе и отслеживании их роста. В последние несколько десятилетий методы компьютерного зрения для высокопроизводительного фенотипического анализа растений вызывают растущий интерес со стороны различных сообществ, таких как специалисты по информатике и современному интеллектуальному сельскохозяйственному семеноводству [3,4]. Для автоматического получения параметров органов растений необходимо точно сегментировать стебли и листья — основные компоненты растения, отвечающие за фотосинтез, транспирацию и характеризующие рост. В последнее время в связи с развитием генетической селекции томата проблема сегментации стеблей и листьев у пространственных структур томата приобрела особую актуальность в исследованиях [2].
В последнее время для получения структурных параметров растений, особенно в исследованиях растительности, применялись методы двумерной (2D) визуализации [5,6]. С помощью анализа полученных изображений на основе 2D-методов возможно мониторить рост растений, оценивать их состояние здоровья и detect заболевания [7,8]. Однако, поскольку 2D-изображение по сути является проекцией в одном направлении, а растения обладают сложными трехмерными (3D) структурами, методы на основе 2D-визуализации имеют существенные ограничения при сегментации стеблей и листьев в условиях сложного фона, взаимных перекрытий, структурной сложности растений, разрешения изображения и т.д. [9,10]. Для преодоления проблемы недостатка пространственной информации в 2D-изображениях стала использоваться технология 3D-облаков точек для получения пространственной информации о растениях [11,12,13]. Например, в [14] была достигнута сегментация листьев салата и оценка их сырого веса с использованием технологии 3D-облаков точек. В [15] на основе данных лидара изучалась сегментация стеблей и листьев у отдельного растения кукурузы. В [16] предложен метод сегментации стеблей и листьев томата на данных облаков точек, полученных с помощью 3D-лазерного сканирования. Хотя упомянутые традиционные алгоритмы сегментации стеблей и листьев растений и достигли успеха для определенных стадий роста или типов растений с малым количеством листьев, им сложно обеспечить адаптивную сегментацию и повысить точность.
С развитием методов машинного обучения для обработки 3D-данных растений стали применяться методы глубокого обучения, позволившие достичь значительных результатов [17,18]. Модель SegNet использовалась для сегментации листьев у отдельных сеянцев тополя с использованием данных 3D-облаков точек в условиях сильных помех [19]. Сегментация стеблей и листьев кукурузы была достигнута с использованием воксельной сверточной нейронной сети и технологии 3D-облаков точек [20,21]. В [22] предложен метод семантической сегментации на основе PointNet++ для автоматического выделения плодов посредством слияния 3D-облаков точек с нескольких сенсоров. Исследователи в основном сосредоточены на использовании глубокого обучения и техник работы с облаками точек для автоматической сегментации листьев и органов растений, однако разрешение облаков точек (приблизительно десятки тысяч точек на растение) остается относительно низким. При работе с высокодетализированными 3D-облаками точек растений до сих пор сохраняются такие недостатки, как недостаточная производительность обработки, слабая адаптивность к условиям окружающей среды и высокая вычислительная сложность. Хотя существующие исследования предоставляют ценные методики для фенотипического анализа растений, дальнейшие улучшения помогут удовлетворить практические требования анализа высокодетализированных 3D-облаков точек растений и повысить производительность моделей в сельскохозяйственных приложениях. Это и побудило нас к дальнейшему изучению проблемы сегментации стеблей и листьев томата на основе высокодетализированных 3D-облаков точек.
В данной работе мы предлагаем структуру типа «кодировщик-декодировщик» с использованием разреженной воксельной свертки (SpConv) и слияния признаков на основе механизма внимания (VSCAFF) для семантической сегментации 3D-облаков точек, полученных при высокопроизводительном сканировании проростков томата. В предложенной структуре сети облака точек проростков томата растеризуются и вокселизуются для облегчения анализа методами глубокого обучения. Одновременно с этим разработан модуль слияния признаков на основе механизма внимания для устранения семантической неоднозначности точек внутри вокселей, что позволяет эффективно объединять воксельные и точечные признаки. Предложенная модель может эффективно выполняться и обеспечивает техническую поддержку для семантической сегментации облаков точек без предварительной обработки данных, такой как понижение разрешения. Семантическая сегментация проростков томата предоставляет мощный инструмент для фенотипического анализа растений, применение которого может направлять селекцию томатов в условиях точного земледелия. Основной вклад данной статьи можно выделить следующим образом:
(1) Разработана SpConv на основе 3D-скелетного ядра свертки для усиления значимости скелета сверточного ядра и уменьшения количества параметров.
(2) Реализован модуль слияния признаков на основе механизма внимания для эффективного объединения признаков из различных ветвей и подавления шума.
(3) Введена комбинированная функция потерь Lovász–Softmax и взвешенной перекрестной энтропии для эффективного устранения проблемы несбалансированности данных и повышения производительности модели.
(4) Построена сеть VSCAFF на основе структуры «кодировщик-декодировщик» для семантической сегментации.
2. Материалы и методы
2.1. Сбор данных облаков точек
Для таких задач, как разметка облаков точек и семантическая сегментация, используется пространственно-временной набор данных облаков точек проростков томата Pheno4D [23], полученный с помощью высокоточного 3D-лазерного сканирующей системы. Система включает лазерный сканер треугольного типа Perceptron Scan Works V5 (Perceptron Inc., Плимут, Мичиган, США), подключенный к измерительному плечу ROMER Infinite 2.0 (Hexagon Metrology Services Ltd., Лондон, Великобритания). Данная система позволяет полностью сканировать поверхность растения томата с различных позиций и углов с пространственной точностью менее одной десятой миллиметра. Этот набор данных сканируется лазерным сканером треугольного типа Perceptron Scan Works V5, рабочее расстояние которого составляет 100 мм. Следовательно, для сканирования томатов крупного размера на практике сканер монтируется на измерительном плече ROMER Infinite 2.0 производства Hexagon Metrology Services Ltd. (Эсплинг, Швеция). Это механическое плечо состоит из семи сочленений и имеет сферическую зону измерения радиусом 140 см. Измерения проводятся в теплице, где выращиваются растения. Каждое растение сканируется отдельно с использованием монтажной системы, которая гарантирует, что горшок имеет одинаковое положение и ориентацию относительно измерительного плеча каждый день. Таким образом, положение и ориентация растения остаются consistent на протяжении всей серии сканирований. Зона измерения достаточна для сканирования растения с разных позиций и углов. Благодаря неинвазивному характеру сканирующей системы измерения могут проводиться без перемещения растения. Всего было получено 140 высокодетализированных облаков точек проростков томата в течение 20 дней от 7 растений, начиная с момента появления у проростков первых почек.
2.2. Разметка данных
С использованием CloudCompare (v2.12.2) наборы данных облаков точек проростков томата были размечены семантическими метками, категоризированными как «Лист», «Стебель» и «Грунт», как показано на Рисунке 1. Исходные 3D-облака точек томата показаны на Рисунке 1a, а размеченные облака точек представлены на Рисунке 1b, где зеленая часть, фиолетовая часть и желтая часть обозначают «лист», «стебель» и «грунт» соответственно.
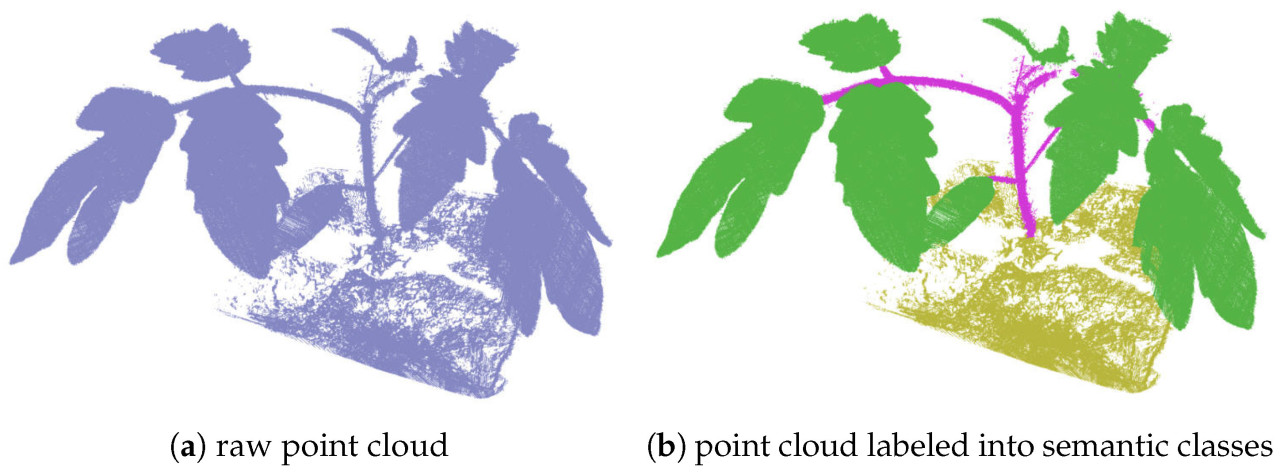
Рисунок 1. Исходное облако точек проростка томата и облако точек, размеченное по семантическим классам «лист», «стебель» и «грунт».
Облака точек одиночного высокодетализированного изображения проростков томата обычно содержат миллионы точек, что позволяет детально передавать особенности органов томата. Усредненное количество точек в облаках для семи проростков томата, собранных в течение 20 дней, варьируется в зависимости от размера проростка на разных стадиях роста. Статистика количества точек за 20 дней представлена в Таблице 1. Как видно из Таблицы 1, среднее количество точек составляет 2,43 миллиона, при этом максимальное количество точек (3,68 миллиона) зафиксировано у растений, отсканированных на 19-й день, а минимальное (1,88 миллиона) — на 17-й день. Стандартное отклонение количества точек составляет 0,47 миллиона, что указывает на неравномерное распределение точек по дням.
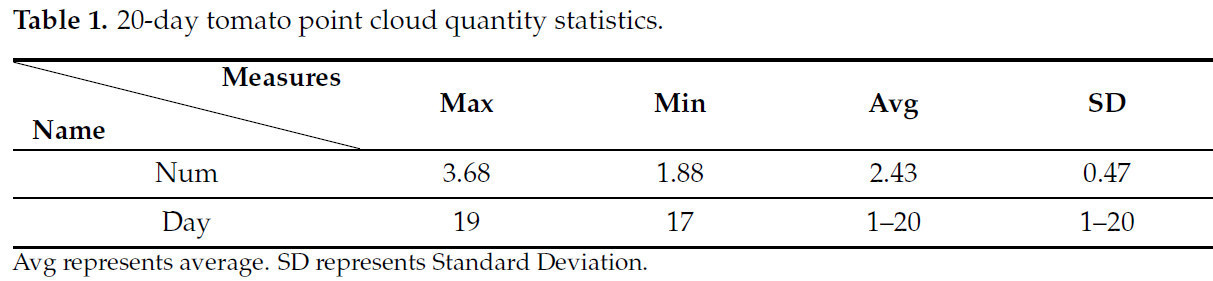
Таблица 1. Статистика количества точек в облаках томата за 20 дней.
В данном исследовании мы использовали 20-дневные наборы данных облаков точек с номерами от 1 до 5 в качестве обучающей выборки, всего 100 облаков точек. Наборы данных облаков точек с номерами 6 и 7, также охватывающие 20 дней, были назначены тестовой выборкой, состоящей из 40 облаков точек. Распределение наборов данных показано в Таблице 2. Как очевидно из Таблицы 2, наборы точек для листьев, стеблей и грунта демонстрируют крайне неравномерное распределение, поскольку проростки томата претерпевают значительные изменения в размере и морфологии на разных стадиях роста, что приводит к вариациям в количестве точек в облаках. В распределении по семантическим классам в обучающей и тестовой выборках точки грунта и листьев составляют более 45% от общего количества точек растения каждый, в то время как точки стеблей — менее 5%. В поточных методах, использующих исходные облака точек в качестве входных данных, сильно неравномерное распределение точек между различными семантическими классами представляет собой значительную проблему для задач семантической сегментации.

Таблица 2. Распределение наборов данных в обучающей и тестовой выборках.
2.3. Сетевая структура для семантической сегментации
Сверточные нейронные сети (CNN) превосходно справляются с извлечением признаков из 2D-изображений и широко используются в различных задачах, включая семантическую сегментацию и обнаружение объектов на 2D-изображениях, демонстрируя значительную эффективность [24,25]. В процессе вычислений в CNN сверточные ядра взаимодействуют с входными данными, используя локальные рецептивные поля, а принцип разделения весов существенно уменьшает количество параметров, тем самым снижая общую сложность модели. Операция свертки опирается на фиксированную сеточную структуру для извлечения признаков, такую как матрица пикселей изображения, где отношения между соседними пикселями хорошо определены. Из-за неупорядоченной природы и неструктурированного характера данных 3D-облаков точек, которым сложно сформировать фиксированные связи, прямое применение традиционных методов 3D-свертки к облакам точек затруднено. Это ограничение стимулировало исследователей к поиску новых сетевых структур и алгоритмов, таких как PointNet и его вариации, для более эффективной обработки и анализа данных облаков точек. Эффективным методом, получившим широкое распространение и показавшим лучшую производительность в задачах распознавания 3D-облаков точек, является вокселизация облаков точек с последующим применением стандартной 3D-свертки для извлечения признаков [26]. При вокселизации на данные облаков точек сильно влияет разрешение, поэтому сложно балансировать производительность модели и эффективность. При использовании более высокого разрешения вокселей модель демонстрирует отличную производительность, но требует больше времени и обладает низкой эффективностью. И наоборот, при использовании более низкого разрешения вокселей модель выполняется быстро и эффективно, но ее производительность значительно падает. Одна из ключевых причин, способствующих этой проблеме, заключается в том, что при использовании более высокого разрешения вокселей увеличение количества пустых вокселей приводит к чрезмерной разреженности 3D-облаков точек, что влечет за собой значительное количество холостых операций при выполнении регулярной 3D-свертки [27].
Структуры облаков точек растений томата более сложны и имеют неправильную форму, что приводит к большей разреженности после вокселизации. Применение обычной 3D-свертки может привести к значительной деформации деталей и повлечь существенные вычислительные затраты. Для решения задачи прямого применения свертки к облакам точек растений томата была разработана сетевая структура типа «кодировщик-декодировщик» на основе SpConv, как проиллюстрировано на Рисунке 2. Ключевые компоненты сети включают три части: структуру «кодировщик-декодировщик» на основе SpConv, скелетное сверточное ядро и метод слияния признаков на основе внимания. Сетевая структура сначала выполняет вокселизацию облаков точек растений томата, а затем извлечение признаков с использованием SpConv. SpConv обозначает модуль разреженной свертки, в то время как DeConv обозначает модуль деконволюции, который используется для восстановления формы вокселей до разреженной свертки. Скелетное сверточное ядро значительно сокращает количество параметров, одновременно повышая производительность модели. Структура «кодировщик-декодировщик» на основе вокселей используется для конечного присвоения одинаковых меток класса всем точкам в пределах одного вокселя. Модуль расширения, представляющий диффузию признаков, используется для распространения воксельных признаков на точечные признаки. Стратегия диффузии, используемая в данной работе, предусматривает общими воксельные признаки внутри одного вокселя. Для обеспечения уникальности точек в пределах одного вокселя необходимо объединить признаки точечной ветви для всех точек с использованием слияния признаков на основе внимания, тем самым устраняя неоднозначность.
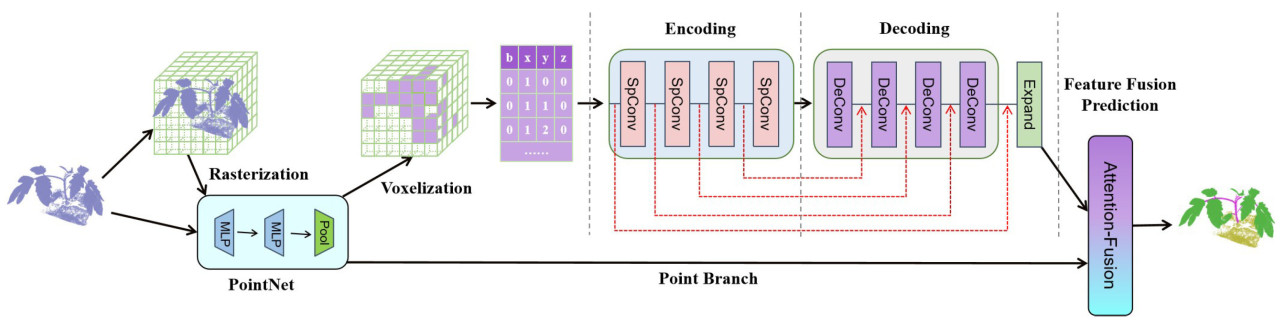
Рисунок 2. Структура сети.
2.3.1. Структура «Кодировщик-Декодировщик» на основе SpConv
В процессе растеризации облаков точек растений томата их разреженность имеет тенденцию увеличиваться с ростом разрешения вокселей. Для точного извлечения семантической информации и геометрических деталей органов растений, таких как стебли, часто требуется более высокое разрешение вокселей для высокодетализированных данных облаков точек, что увеличивает время, необходимое для операций свертки. Поэтому SpConv используется в качестве локального экстрактора признаков для выполнения операций свертки на облаках точек,构建 модуль иерархического извлечения признаков.
В данной работе на основе TorchSparse [28] строится кодировщик признаков на основе SpConv. TorchSparse представляет собой эффективную библиотеку для 3D SpConv, которая ускоряет процесс SpConv посредством адаптивного матричного умножения и векторизации. Кодировщик использует разреженную матрицу признаков облаков точек в качестве входных данных, и процесс ее генерации следующий. Сначала облако точек томата растеризуется с вокселем размером 0,2 в качестве единицы, и точки в пределах каждого вокселя подаются на подсеть Pointnet для изучения детальных признаков из точек. Затем точки в пределах одного и того же вокселя агрегируются (пулинг) для генерации воксельных признаков и построения разреженной матрицы признаков облака точек. Наконец, разреженная матрица используется в качестве входных данных для базовой сети, которая выполняет кодирование признаков.
В секции декодирования feature code подвергается деконволюции, и форма вокселя восстанавливается слой за слоем с использованием таблицы свертки кодирования [29]. Признаки с одинаковой формой вокселя из стадий кодирования и декодирования объединяются (конкатенируются) в качестве входных данных для последующих слоев деконволюции, чтобы полностью использовать семантическую информацию признаков высокого уровня и детальную информацию признаков низкого уровня. Воксельные признаки распространяются на точечные признаки через модуль диффузии, что означает, что все точки в пределах одного вокселя разделяют одни и те же воксельные признаки. Структура «кодировщик-декодировщик» показана на Рисунке 3, где 𝑁𝑖 обозначает количество вокселей, выводимых текущим модулем. Из-за различных уровней разреженности облаков точек от разных растений томата количество выходных вокселей для разных данных также различно. Воксельные признаки распространяются на все точки с помощью модуля диффузии, одновременно восстанавливая исходную форму облака точек.
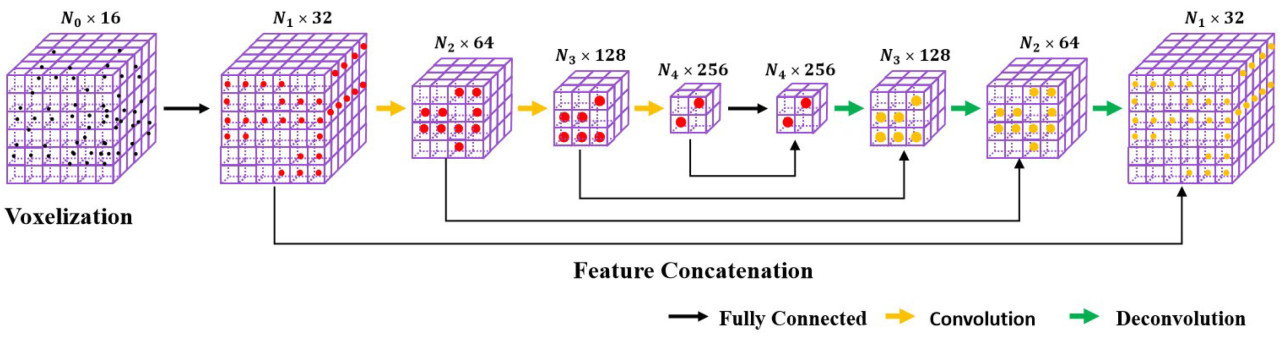
Рисунок 3. Архитектура «кодировщик-декодировщик» на основе SpConv.
2.3.2. Скелетная свертка
Для дальнейшего повышения скорости вывода сети мы разработали 3D скелетную свертку, которая усиливает значимость скелета сверточного ядра, одновременно уменьшая параметры модели, как показано на Рисунке 4a. По сравнению с традиционным 3D сверточным ядром [30], параметры одиночного скелетного сверточного ядра уменьшены почти на 74%, а параметры модуля SpConv, разработанного в статье (показанного на Рисунке 4b), уменьшены на 37% по сравнению с эквивалентным модулем свертки (показанным на Рисунке 4c).
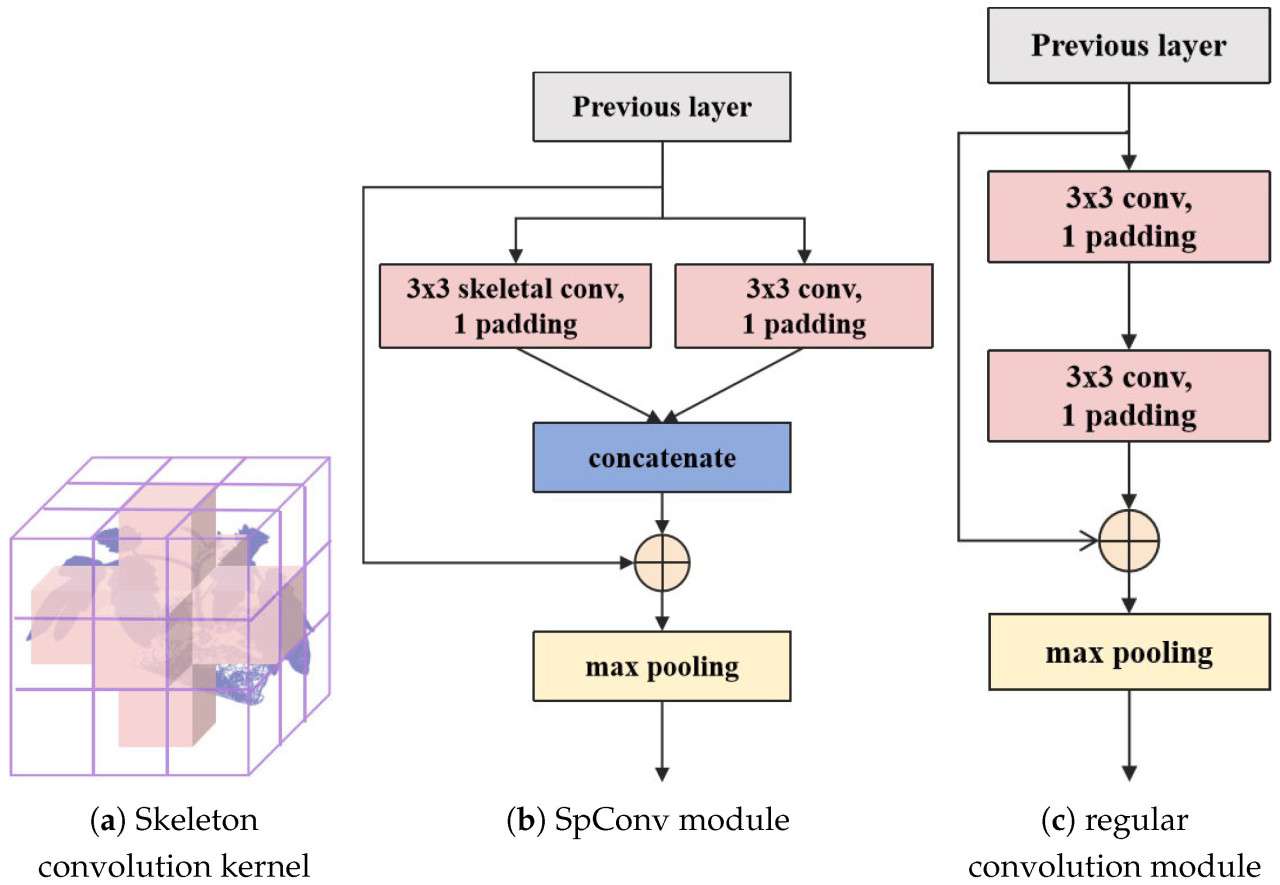
Рисунок 4. Три вида структур сверточных ядер.
3D Skeleton Conv извлекает ключевые структуры из обычных сверточных ядер для усиления核心 весов, эффективно соответствуя структурам органов облаков точек растений томата. В процессе фактической свертки перекрытие между сверточным ядром и облаками точек растений томата сосредоточено на горизонтальных и вертикальных скелетных частях. Посредством остаточной конкатенации между скелетным и обычным сверточным ядрами можно удовлетворить извлечение признаков ключевых частей из облаков точек растений томата, сохраняя при этом информацию о границах.
2.3.3. Метод слияния признаков на основе механизма внимания
На позднем этапе стадии декодирования модуль расширения генерирует точечные признаки для воксельных точек. Однако этот модуль генерирует идентичные признаки для всех точек в пределах одного вокселя, что может привести к неоднозначности, поскольку разные семантические точки разделяют одни и те же признаки. Чтобы избежать этой проблемы, точечные признаки, сгенерированные модулем расширения, объединяются с точечными признаками, сгенерированными на этапе вокселизации с помощью PointNet. Традиционные методы слияния признаков обычно полагаются на накопление или конкатенацию различных признаков, но эти подходы часто не позволяют эффективно отфильтровать шум в признаках.
Поэтому метод слияния признаков, разработанный в статье, основан на механизме внимания, интегрируя канальное внимание и самовнимание для расчета канального внимания. Используя данный метод слияния, можно эффективно отфильтровать полезную информацию из большого объема нерелевантных данных. Механизм внимания, используемый моделью, автоматически обучается распределению "внимания". Распределение внимания может динамически调整роваться в зависимости от различных входных данных, демонстрируя определенную гибкость и адаптивность [31]. По сравнению с традиционными механизмами внимания, включение многослойного перцептрона позволяет изучать более сложные шаблоны внимания, обеспечивая лучшее захват сложных взаимосвязей и признаков во входных данных.
Оценки внимания для типа признака рассчитываются на основе воксельного признака и точечного признака каждой точки, а именно вектора весов признаков, как показано в Формуле (1):
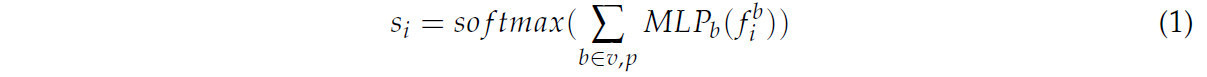
где b — это тип признака, а именно воксельный признак (v) или точечный признак (p). Затем вычисляется произведение вектора весов и соответствующего вектора точечных признаков, что дает итоговый точечный признак, как показано в Формуле (2):
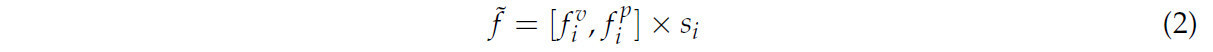
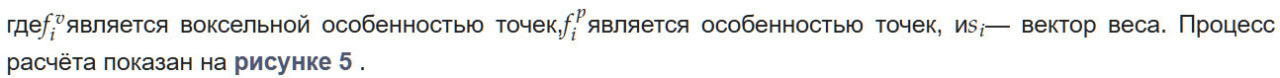
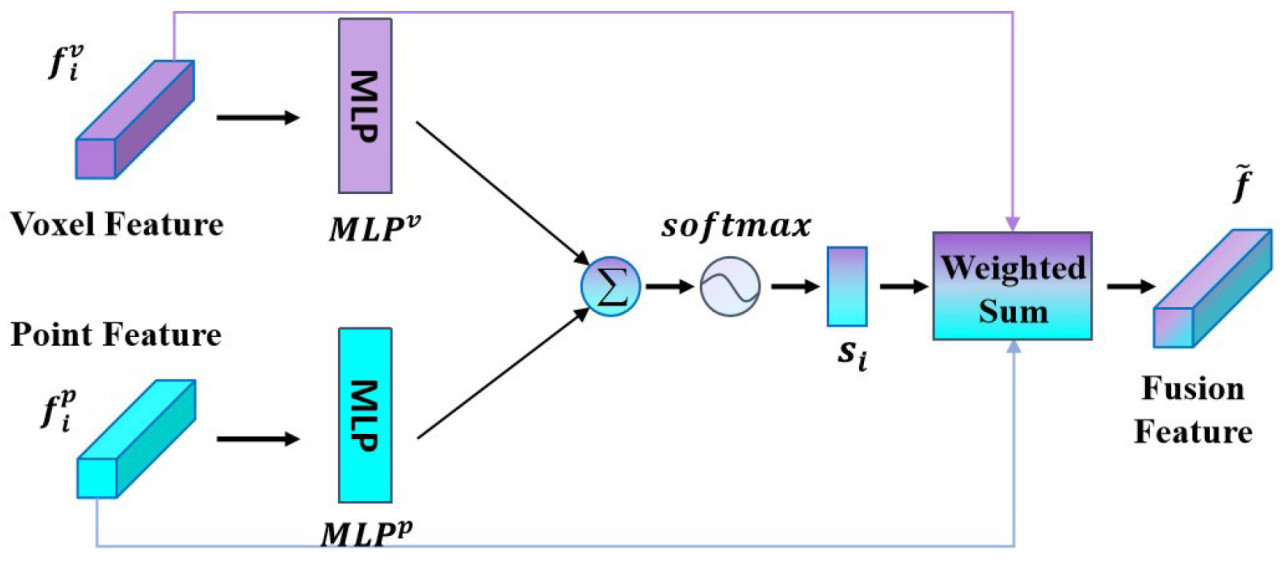
Рисунок 5. Метод слияния признаков на основе внимания.
2.3.4. Функция потерь
Поскольку стебли в облаках точек растений томата составляют лишь 4,56% от общего количества, распределение по классам крайне неравномерно. Эта несбалансированность может привести к смещению модели в сторону классов с большей долей в процессе обучения, что негативно сказывается на ее производительности. Для эффективного устранения неравномерности采用了 взвешенная функция потерь перекрестной энтропии, которая назначает различные веса разным классам. Кроме того, функция потерь Lovász-Softmax напрямую оптимизирует индекс пересечения по объединению и динамически регулирует вклад каждого пикселя, улучшая обучение для классов с малым количеством примеров и повышая точность сегментации, особенно в сложных scenarios, таких как обнаружение мелких объектов [32]. Объединяя эти две функции потерь, модель получает преимущества как в точности классификации, так и в оптимизации общего качества сегментации. Комбинированная функция потерь фокусируется как на способности классификации на уровне пикселей, так и на одновременной оптимизации общей производительности сегментации, как показано в Формуле (3):
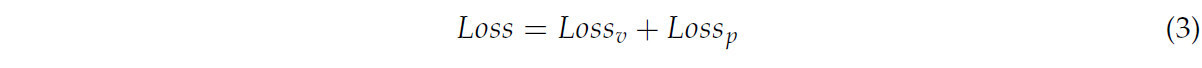
где 𝐿𝑜𝑠𝑠𝑝 отвечает за обучение точечных признаков. 𝐿𝑜𝑠𝑠𝑣 отвечает за оптимизацию обучения воксельных ветвей и состоит из взвешенной перекрестной энтропии и потерь Lovász-Softmax, как показано в Формуле (4):
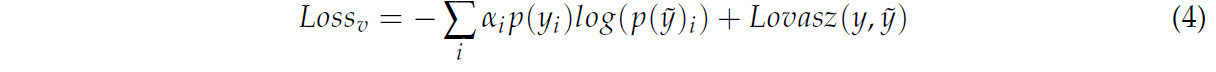
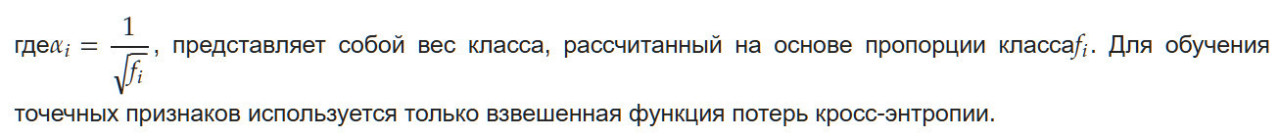
2.4. Экспериментальная платформа
Компьютер в эксперименте был настроен с процессором Intel Core i9-12900, графическим процессором NVIDIA RTX 3090, оперативной памятью 64 ГБ и твердотельным накопителем объемом 2 ТБ. Использовалась операционная система Ubuntu 20.04 и фреймворк глубокого обучения PyTorch 1.18. Реализация модели основана на Python.
2.5. Метрики оценки модели
Производительность модели оценивается с помощью IoU (пересечение по объединению для каждого класса) и mIoU (средний IoU) [33], как показано в Формуле (5):
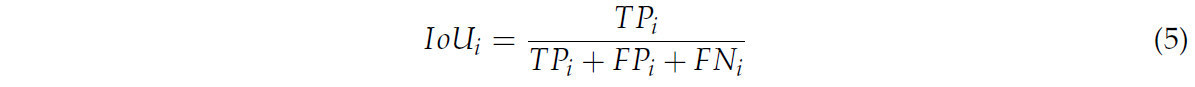
где i — это класс (грунт, стебель или лист), 𝑇𝑃𝑖 (Истинно Положительные) представляет количество образцов, где и прогноз, и эталонная разметка принадлежат одному и тому же классу i. 𝐹𝑃𝑖 (Ложноположительные) обозначает количество образцов, где прогноз относится к классу i, но эталонная разметка — к другому классу. 𝐹𝑁𝑖 (Ложноотрицательные) указывает количество образцов, где прогноз относится к другому классу, но эталонная разметка принадлежит тому же классу i. mIoU вычисляется путем усреднения значений IoU по всем классам, как показано в Формуле (6):
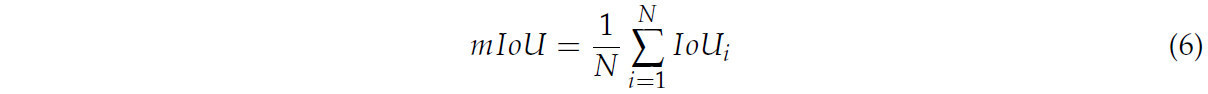
где N представляет общее количество классов.
Для проверки производительности модели с использованием IoU и mIoU предложенная модель сравнивалась с тремя классическими моделями, основанными на различных принципах, такими как PointNet [34] (поточный), PointNet++ [35] (на основе поиска соседей) и DGCNN [36] (на основе графов).
2.6. Абляционные исследования
Для дальнейшей проверки эффективности VSCAFF были проведены абляционные исследования для анализа производительности каждого отдельного модуля. Сначала была построена базовая сеть, состоящая только из кодировщика и декодировщика с обычной разреженной сверткой, где модуль семантической сегментации полностью основан на полносвязных слоях. Затем на этой основе в SpConv последовательно вводились скелетное сверточное ядро, простое слияние ветви извлечения точечных признаков и воксельной ветви, а также модуль слияния признаков на основе внимания. После включения ветви извлечения точечных признаков исследовались различные техники слияния признаков, включая конкатенацию, суммирование и метод на основе внимания, описанный в статье. В конечном итоге, в эксперименте сравнивались взвешенная функция потерь перекрестной энтропии и комбинация взвешенной перекрестной энтропии и функции потерь Lovász-Softmax.
3. Результаты
3.1. Сравнение производительности различных моделей семантической сегментации
Результаты сравнения с другими моделями представлены в Таблице 3.
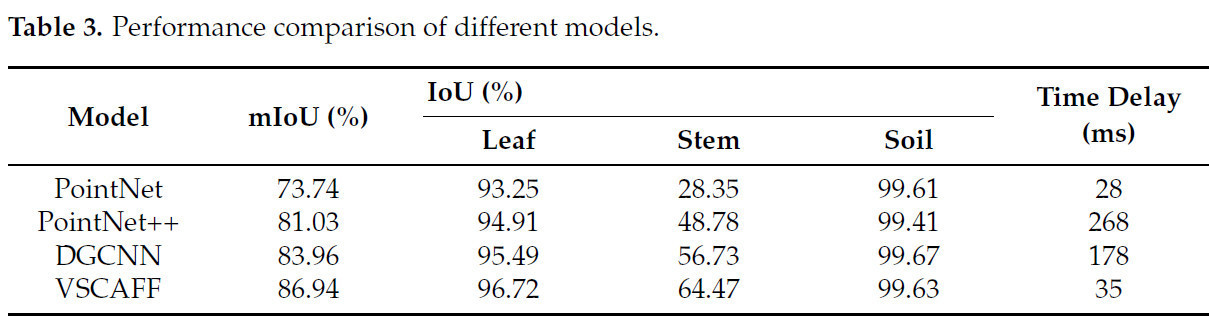
Таблица 3. Сравнение производительности различных моделей.
Как видно из Таблицы 3, модель VSCAFF достигает mIoU 86,96%, превосходя три другие модели. В частности, она превосходит DGCNN на 2,98%, PointNet++ на 5,91% и PointNet на 13,2%. По сравнению с другими моделями, PointNet демонстрирует наихудшую производительность, поскольку сети на основе MLP не учитывают признаки соседних точек, особенно для идентификации малых классов (например, Стебель). PointNet++, основанный на PointNet, вводит изучение признаков соседей и иерархические структуры, значительно улучшая свою способность изучать детали, например, повышая идентификацию стеблей почти на 20%. DGCNN выигрывает от мощных representational возможностей графов. Динамически обновляя граф отношений на каждом слое, он изучает семантические признаки точек, проявляя превосходные способности в изучении локальных признаков соседей. VSCAFF использует воксельные признаки, извлеченные SpConv, и точечные признаки, извлеченные ветвью PointNet, что позволяет учитывать как геометрические отношения точек, так и уникальные особенности самих точек. Кроме того, метод слияния признаков на основе внимания позволяет эффективно объединять признаки, извлеченные с двух разных точек зрения, и более точно идентифицировать детали. Хотя идентификация стебля с помощью VSCAFF неудовлетворительна из-за недостаточного количества точек стебля, она все же имеет преимущество перед другими моделями, особенно на 7,74% выше, чем у DGCNN. Это означает, что в определенных приложениях VSCAFF может оставаться лучшим выбором, учитывая его превосходную производительность в сегментации грунта и листьев. Однако это может привести к неточному распознаванию стеблей в практических приложениях, потенциально влияя на задачи, требующие точного анализа стебля, такие как оценка здоровья растения и обнаружение повреждений, вызванных вредителями.
Что касается скорости вывода, высокодетализированные облака точек обычно требуют значительного вычислительного времени из-за чрезмерного количества точек. В отличие от них, PointNet, с его простой архитектурой, которая полагается только на MLP для извлечения признаков, демонстрирует заметно меньшее время обработки, как показано в Таблице 3. Однако PointNet++ вводит выбор наиболее удаленных точек и K-ближайших соседей в качестве алгоритмов поиска соседей, что приводит к временной сложности 𝑂(𝑛²). Более того, широкое использование иерархических слоев извлечения признаков значительно увеличивает задержку при обработке высокодетализированных облаков точек. DGCNN, который использует ту же стратегию поиска соседей, что и PointNet++, и использует динамическую графовую структуру при построении иерархических признаков, существенно ускоряет обработку и, следовательно, снижает задержку по сравнению с PointNet++. Для оптимизации производительности модели предложенный VSCAFF включает структуру, подобную PointNet, для извлечения точечных признаков, одновременно интегрируя SpConv и скелетные сверточные ядра для извлечения воксельных признаков. Примечательно, что эти операции выполняются параллельно, что приводит к средней задержке обработки облака точек на одно растение, составляющей всего на 7 мс больше, чем у PointNet.
Результаты семантической сегментации растения томата с использованием различных моделей на разных стадиях роста показаны на Рисунке 6, и красная рамка представляет ошибки распознавания. Становится очевидным, что PointNet struggles to detect точки соединения стеблей и листьев, вследствие чего семантическая информация не может быть точно извлечена. Этот недостаток возникает из-за неспособности PointNet моделировать межточечные отношения, что препятствует его способности изучать локальные геометрические детали облаков точек растений томата. В отличие от этого, PointNet++, включая иерархические экстракторы признаков, эффективно моделирует отношения соседей, приводя к значительному улучшению качества сегментации стеблей и листьев. Однако, ограниченный inherent limitations MLP в представлении признаков, PointNet++ не может идентифицировать большое количество органов стебля. DGCNN, используя динамические графы, умело извлекает признаки локальных отношений и преуспевает в представлении детальных характеристик. Как видно из колонки d Рисунка 6, DGCNN превосходит PointNet++ в точной сегментации стеблей и листьев. Тем не менее, он иногда неправильно классифицирует листья. В отличие от этих методов, модель VSCAFF, предложенная в статье, использует несколько ветвей для извлечения признаков на различных масштабах. Этот метод не только захватывает детальные признаки отдельных точек, но и эффективно достигает признаков локальных отношений. Следовательно, VSCAFF обеспечивает более точную сегментацию деталей стебля и листьев, демонстрируя превосходную производительность на разных стадиях роста растений томата.
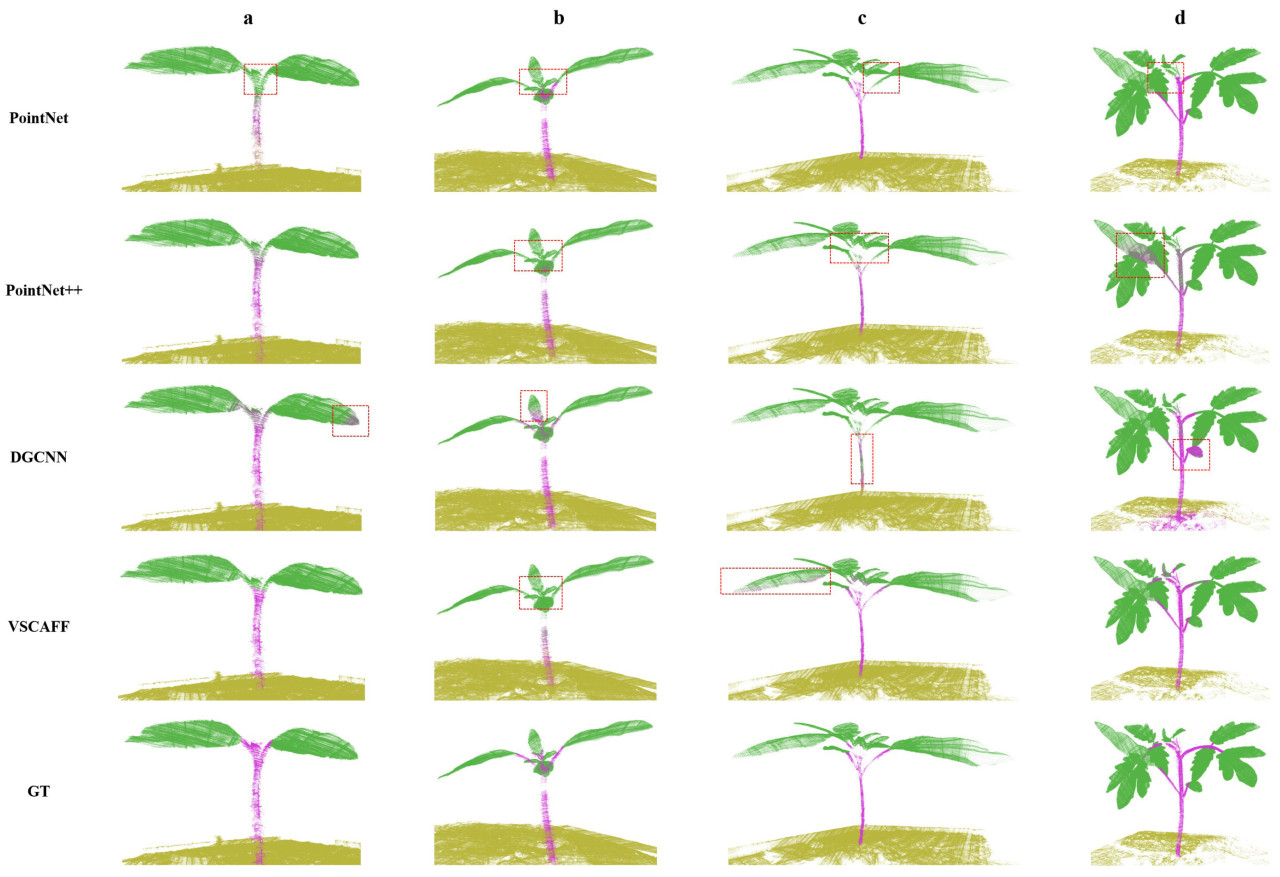
Рисунок 6. Семантическая сегментация облаков точек растений томата. Примечание 1: GT представляет эталонную разметку (Ground Truth). Примечание 2: Представлены облака точек четырех проростков, отсканированные в четыре различных дня.
3.2. Результаты абляционных исследований
Каждый отдельный модуль добавлялся или удалялся из базовой сети. Результаты абляционных исследований подробно описаны в Таблице 4.
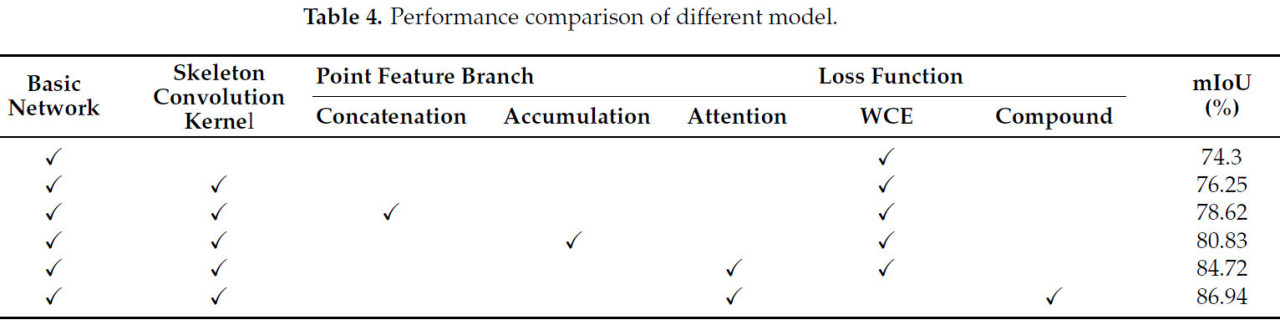
Таблица 4. Сравнение производительности различных [конфигураций] модели.
Как видно из Таблицы 4, введение скелетного сверточного ядра эффективно усиливает значимость исходного сверточного ядра вдоль горизонтальной и вертикальной осей, значительно улучшая распознавание структуры стеблей и листьев у растения томата. В частности, это изменение повышает mIoU на 0,95% по сравнению с базовой сетью при одновременном сокращении параметров. Кроме того, включение ветви извлечения точечных признаков дифференцирует распознавание точек моделью путем внедрения детальных точечных признаков вместе с воксельными признаками, устраняя неоднозначность различных семантических точек внутри одного вокселя, тем самым повышая точность модели. При слиянии признаков использование конкатенации улучшает mIoU на 5,37%, а суммирование — на 3,58%. В contrast, предложенный метод слияния на основе внимания достигает существенного увеличения mIoU на 7,47%, превосходя оба метода, что объясняется его способностью фокусироваться на релевантной информации, минимизируя влияние шума и нерелевантных данных. Метод на основе внимания эффективно извлекает ценную информацию из двух различных точек зрения посредством обучения и снижает влияние бесполезной информации, тем самым более эффективно повышая производительность модели. Напротив, конкатенация и суммирование, на которые все еще может влиять шум, не могут уловить существенные признаки. Наконец, модификация функции потерь со взвешенной перекрестной энтропии на комбинированную функцию потерь, объединяющую Lovász-softmax и взвешенную перекрестную энтропию, приводит к дальнейшему улучшению производительности модели на 1,46%. Этот результат подчеркивает эффективность Lovász-softmax в решении проблем, вызванных несбалансированными наборами данных, подтверждая ее интеграцию в модель.
4. Обсуждение
4.1. Эффективность методов
Для достижения эффективной семантической сегментации 3D-облаков точек высокодетализированных растений томата была построена сетевая модель семантической сегментации на основе SpConv, интегрирующая PointNet. За счет использования скелетных сверточных ядер количество параметров модели сокращается, что, в свою очередь, повышает скорость вывода. Кроме того, механизм внимания используется для слияния признаков, извлеченных с двух различных точек зрения, тем самым успешно выполняя семантическую сегментацию для высокодетализированных облаков точек растений томата. Наконец, комбинированная функция потерь Lovász-softmax и взвешенной перекрестной энтропии эффективно решает проблемы, вызванные неравномерностью наборов данных для облаков точек растений томата, чтобы повысить производительность модели.
Сравнительный анализ с несколькими различными моделями, включая поточный PointNet, основанный на признаках соседей PointNet++, основанный на графах DGCNN, показывает, что поточная модель, из-за отсутствия информации о соседях, демонстрирует наихудшую производительность сегментации, хотя и с самой высокой скоростью вывода. В то время как включение поиска соседей значительно улучшает точность сегментации, оно также влечет за собой существенные затраты памяти и вычислений. Чтобы преодолеть эту проблему, предложенная модель успешно достигает эффективной и точной семантической сегментации высокодетализированных облаков точек растений томата путем слияния признаков, извлеченных с двух различных точек зрения.
Благодаря неинвазивному и физически безвредному характеру семантической сегментации облаков точек проростков томата, измерения могут повторяться без нарушения роста растений, достигая динамического мониторинга. Точная сегментация облегчает извлечение не только морфологических признаков растения, таких как площадь листа, высота растения и диаметр стебля, но и 3D-структурных признаков, таких как углы ветвления и распределение листьев [37]. Это имеет большое значение для понимания механизмов роста растений и генетических вариаций в точном земледелии. Решения, основанные на фенотипе, могут оптимизировать плотность посадки, стратегии орошения и сроки сбора урожая, тем самым повышая урожайность и качество культур. Анализ фенотипа помогает идентифицировать сорта растений с желательными признаками, ускорить процесс селекции и культивировать сорта, лучше adapted к конкретным условиям окружающей среды и рыночным demands [38]. Непрерывный мониторинг фенотипических изменений позволяет рано обнаруживать заболевания или экологический стресс, способствуя своевременному вмешательству для минимизации потерь. Кроме того, персонализированное управление для каждого растения может обеспечить refined практики управления. В summary, сегментация облаков точек проростков томата предлагает мощный инструмент для фенотипического анализа сельскохозяйственных растений, и фенотипическое применение в точном земледелии имеет ключевое значение для содействия устойчивым сельскохозяйственным практикам и повышения сельскохозяйственной производительности.
Усовершенствование исследования фенотипа проростков томата может направлять селекцию томатов. Благодаря высокоточным технологиям фенотипического анализа характеристики роста проростков томата можно более точно идентифицировать и количественно оценивать, помогая селекционерам отбирать растения с желательными признаками [39]. Интегрируя фенотипические данные с генотипическими данными, можно выявить взаимосвязи между конкретными генами или комбинациями генов и связанными с ними фенотипическими признаками, что помогает селекционерам оптимизировать стратегии селекции, выбирая гены, которые положительно способствуют желательным признакам [38]. Используя технологии высокопроизводительного фенотипического анализа, растения, проявляющие благоприятные признаки, могут быть быстро идентифицированы и быстро размножены, тем самым значительно сокращая цикл селекции и повышая эффективность селекции.
4.2. Ограничения методов
С другой стороны, в исследовании все еще существуют некоторые ограничения, такие как малое количество точек стебля, низкий IoU для сегментации стебля. IoU для стеблей с использованием этих сравниваемых методов попадает в относительно большой диапазон (28–64%), что обуславливает различия в сегментации стебля между этими методами. Подобно стеблю, черешок и цветоножка являются тонкими и мелкими, что требует разработки более эффективных и генеративных методов. Когда точек стебля слишком мало, это может привести к следующим проблемам: (1) Разреженность данных: недостаточное количество точек в пространстве или времени затрудняет точное capture закономерностей роста и деформации стебля. (2) Низкая точность статистического анализа: при выполнении статистического анализа, такого как анализ формы стебля или расчет скорости роста, надежность и точность результатов ограничены из-за скудности точек данных. (3) Сложность построения модели: низкое количество точек затрудняет для модели изучение точных features формы, влияя на точность прогнозов и анализа [40]. Для решения проблемы слишком малого количества точек на стебле мы можем увеличить частоту сбора данных, чтобы повысить плотность точек как во времени, так и в пространстве, тем самым получая больше точек стебля. Также могут использоваться алгоритмы интерполяции (например, линейная интерполяция, сплайн-интерполяция) для генерации новых точек между существующими, увеличивая плотность и непрерывность данных. Для улучшения способности модели к обобщению и разнообразия данных можно создавать данные, дополненные с помощью виртуальной реальности, комбинируя их с реальными данными для обучения модели.
4.3. Перспективы будущих исследований
В будущем неоптимальная сегментация стебля может повлиять на приложения, требующие точного анализа стебля. Для повышения точности сегментации стебля возможно добавление большего количества слоев извлечения признаков к существующей модели, использование более мощных структур кодировщика-декодировщика и введение механизмов слияния признаков на нескольких масштабах [41], что может улучшить способность модели захватывать детали стебля и обрабатывать сложные отношения между стеблем и его окружением. Используя эти улучшения, производительность модели VSCAFF для сегментации стебля может быть значительно повышена, чтобы сделать ее более практичной для сельскохозяйственных приложений. В семантической сегментации высокодетализированных 3D-облаков точек для растений томата можно исследовать более продвинутые архитектуры глубокого обучения и интегрировать мультимодальные данные. В то же время следует сосредоточиться на облегченных моделях для адаптации к практическим приложениям, повышая эффективность и точность сегментации. Это обеспечивает мощную поддержку для точного земледелия, способствуя развитию сельскохозяйственной интеллектуализации.
5. Выводы
Поскольку методы семантической сегментации часто страдают от низкой точности и малой скорости вывода, была предложена структура «кодировщик-декодировщик», включающая разреженную воксельную свертку (SpConv) и слияние признаков на основе внимания (VSCAFF). Количество параметров сокращено с использованием модуля SpConv для дальнейшего повышения скорости вывода. Неоднозначность, возникающая из-за точек с различной семантикой, устранена с использованием модуля слияния признаков на основе механизма внимания. Смещение модели в сторону определенных классов при обучении решено с использованием комбинированной функции потерь для улучшения ее производительности.
Результаты экспериментов указывают на следующее: (1) Модель VSCAFF демонстрирует наилучшую производительность сегментации с mIoU 86,96%, а IoU для грунта, стебля и листа достигает 99,63%, 64,47% и 96,72% соответственно, значительно превосходя другие традиционные модели. (2) Предложенная модель достигает наибольшей эффективности (35 мс) при наименьшем количестве параметров и потреблении памяти. (3) Модель VSCAFF полностью использует вычислительные ресурсы, достигая оптимального баланса между производительностью сегментации и скоростью. Результаты демонстрируют, что VSCAFF имеет значительные преимущества в семантической сегментации высокодетализированных облаков точек томата, предоставляя эффективное и практичное решение для высокопроизводительного автоматического фенотипического анализа.
Ссылки
1. Chitwood-Brown, J.; Vallad, G.E.; Lee, T.G.; Hutton, S.F. Breeding for resistance to Fusarium wilt of tomato: A review. Genes 2021, 12, 1673. [Google Scholar] [CrossRef] [PubMed]
2. Roohanitaziani, R.; de Maagd, R.A.; Lammers, M.; Molthoff, J.; Meijer-Dekens, F.; van Kaauwen, M.P.; Finkers, R.; Tikunov, Y.; Visser, R.G.; Bovy, A.G. Exploration of a resequenced tomato core collection for phenotypic and genotypic variation in plant growth and fruit quality traits. Genes 2020, 11, 1278. [Google Scholar] [CrossRef] [PubMed]
3. He, P.F. Comprehensive Evaluation and Primary Metabolite Analysis of Tomato Quality Characters. Master’s Thesis, Fujian Agriculture and Forestry University, Fuzhou, China, 2023. [Google Scholar] [CrossRef]
4. Zhao, C.J. Big data of plant phenomics and its research progress. J. Agric. Big Data 2019, 2, 5–18. [Google Scholar]
5. Li, K.; Feng, Q.; Zhang, J. Co-segmentation algorithm for complex background image of cotton seedling leaves. J. Comput. Aided Des. Comput. Graph. 2017, 10, 1871–1880. [Google Scholar]
6. Singh, V.; Misra, A.K. Detection of plant leaf diseases using image segmentation and soft computing techniques. Inf. Process. Agric. 2017, 1, 41–49. [Google Scholar] [CrossRef]
7. Hasan, U.; Sawut, M.; Chen, S. Estimating the leaf area index of winter wheat based on unmanned aerial vehicle RGB-image parameters. Sustainability 2019, 23, 6829. [Google Scholar] [CrossRef]
8. Rasti, S.; Bleakley, C.J.; Holden, N.M.; Whetton, R.; Langton, D.; O’Hare, G. A survey of high resolution image processing techniques for cereal crop growth monitoring. Inf. Process. Agric. 2022, 2, 300–315. [Google Scholar] [CrossRef]
9. Shi, W.; van de Zedde, R.; Jiang, H.; Kootstra, G. Plant-part segmentation using deep learning and multi-view vision. Biosyst. Eng. 2019, 187, 81–95. [Google Scholar] [CrossRef]
10. Ma, X.; Jiang, Q.; Guan, H.; Wang, L.; Wu, X. Calculation Method of Phenotypic Traits for Tomato Canopy in Greenhouse Based on the Extraction of Branch Skeleton. Agronomy 2024, 12, 2837. [Google Scholar] [CrossRef]
11. Itakura, K.; Hosoi, F. Automatic Leaf Segmentation for Estimating Leaf Area and Leaf Inclination Angle in 3D Plant Images. Sensors 2018, 10, 3576. [Google Scholar] [CrossRef]
12. Yuan, P.S.; Li, R.L.; Ren, S.G.; Gu, X.J.; Xu, H.L. State-of-the-Art review for representation learning and its application in plant phenotypes. Trans. Chin. Soc. Agric. Mach. 2020, 6, 1–14. [Google Scholar]
13. Zhu, C.; Miao, T.; Xu, T.Y.; Li, N.; Deng, H.; Zhou, Y. Ear segmentation and phenotypic trait extraction of maize based on three-dimensional point cloud skeleton. Trans. CSAE 2021, 6, 295–301. [Google Scholar]
14. Mortensen, A.K.; Bender, A.; Whelan, B.; Barbour, M.M.; Sukkarieh, S.; Karstoft, H.; Gislum, R. Segmentation of lettuce in coloured 3D point clouds for fresh weight estimation. Comput. Electron. Agric. 2018, 154, 373–381. [Google Scholar] [CrossRef]
15. Jin, S.; Su, Y.; Wu, F.; Pang, S.; Gao, S.; Hu, T.; Liu, J.; Guo, Q. Stem–leaf segmentation and phenotypic trait extraction of individual maize using terrestrial LiDAR data. IEEE Trans. Geosci. Remote Sens. 2018, 3, 1336–1346. [Google Scholar] [CrossRef]
16. Peng, C.; Li, S.; Miao, Y.L.; Zhang, Z.; Zhang, M.; Li, H. Stem-leaf segmentation and phenotypic trait extraction of tomatoes using three-dimensional point cloud. Trans. Chin. Soc. Agric. Eng. 2022, 9, 187–194. [Google Scholar]
17. Weng, Y.; Zeng, R.; Wu, C.M.; Wang, M.; Wang, X.J.; Liu, Y.J. A survey on deep-learning-based plant phenotype research in agriculture. Sci. Sin. Vitae 2019, 6, 698–716. [Google Scholar] [CrossRef]
18. Guo, X.; Sun, Y.; Yang, H. FF-Net: Feature-Fusion-Based Network for Semantic Segmentation of 3D Plant Point Cloud. Plants 2023, 12, 1867. [Google Scholar] [CrossRef]
19. Hu, C.H.; Liu, X.; Ji, M.J.; Li, Y.J.; Li, P.P. Single Poplar Leaf Segmentation Method Based on SegNet and 3D Point Cloud Clustering in Field. Trans. Chin. Soc. Agric. Mach. 2022, 6, 259–264. [Google Scholar]
20. Jin, S.; Su, Y.; Gao, S.; Wu, F.; Ma, Q.; Xu, K.; Hu, T.; Liu, J.; Pang, S.; Guan, H.; et al. Separating the structural components of maize for field phenotyping using terrestrial LiDAR data and deep convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 4, 2644–2658. [Google Scholar] [CrossRef]
21. Li, Y.; Wen, W.; Miao, T.; Wu, S.; Yu, Z.; Wang, X.; Guo, X.; Zhao, C. Automatic organ-level point cloud segmentation of maize shoots by integrating high-throughput data acquisition and deep learning. Comput. Electron. Agric. 2022, 193, 106702. [Google Scholar] [CrossRef]
22. Kang, H.; Wang, X. Semantic segmentation of fruits on multi-sensor fused data in natural orchards. Comput. Electron. Agric. 2023, 204, 107569. [Google Scholar] [CrossRef]
23. David, S.; Federico, M.; Rosu, A.R.; Cornelißen, A.; Nived, C.; Stefan, P.; Jens, L.; Sven, B.; Cyrill, S.; Heiner, K.; et al. Pheno4D: A spatio-temporal dataset of maize and tomato plant point clouds for phenotyping and advanced plant analysis. PLoS ONE 2021, 8, e0256340. [Google Scholar]
24. Zhang, Q.; Pang, Y.S.; Li, B. Visual positioning and picking pose estimation of tomato clusters based on instance segmentation. Trans. Chin. Soc. Agric. Mach. 2023, 10, 205–215. [Google Scholar]
25. Li, T.; Sun, M.; He, Q.; Zhang, G.; Shi, G.; Ding, X.; Lin, S. Tomato recognition and location algorithm based on improved YOLOv5. Comput. Electron. Agric. 2023, 208, 107759. [Google Scholar] [CrossRef]
26. Wang, S.P.; Liu, Y.; Guo, Y.X.; Sun, C.Y.; Tong, X. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. TOG 2017, 4, 1–11. [Google Scholar] [CrossRef]
27. Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
28. Tang, H.; Liu, Z.; Li, X.; Lin, Y.; Han, S. Torchsparse: Efficient point cloud inference engine. Proc. Mach. Learn. Syst. 2022, 4, 302–315. [Google Scholar]
29. Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santigo, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
30. Zhu, T.; Ma, X.; Guan, H.; Wu, X.; Wang, F.; Yang, C.; Jiang, Q. A method for detecting tomato canopies’ phenotypic traits based on improved skeleton extraction algorithm. Comput. Electron. Agric. 2023, 214, 108285. [Google Scholar] [CrossRef]
31. Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
32. Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4413–4421. [Google Scholar]
33. Sun, Y.; Guo, X.; Yang, H. Win-Former: Window-Based Transformer for Maize Plant Point Cloud Semantic Segmentation. Agronomy 2023, 11, 2723. [Google Scholar] [CrossRef]
34. Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
35. Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar] [CrossRef]
36. Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 5, 1–12. [Google Scholar] [CrossRef]
37. Sun, Y.Z.; Zhang, Z.X.; Sun, K.; Li, S.; Yu, J.L.; Miao, L.X.; Zhang, Z.G.; Li, Y.; Zhao, H.J.; Hu, Z.B.; et al. Soybean-MVS: Annotated three-dimensional model dataset of whole growth period soybeans for 3D plant organ segmentation. Agriculture 2023, 7, 1321. [Google Scholar] [CrossRef]
38. Darwish, M.A.; Elkot, A.F.; Elfanah, A.M.; Selim, A.I.; Yassin, M.M.; Abomarzoka, E.A.; El-Maghraby, M.A.; Rebouh, N.Y.; Ali, A.M. Evaluation of wheat genotypes under water regimes using hyperspectral reflectance and agro-physiological parameters via genotype by yield*trait approaches in sakha station, delta, egypt. Agriculture 2023, 7, 1338. [Google Scholar] [CrossRef]
39. Wang, X.W.; Wang, Z.F.; Qin, X.Z.; Chen, J.; Dai, J.P.; Zhang, H.T.; Xie, Y.Q.; Feng, L.; Gurinur, A.; Guo, W.C.; et al. The Growth Phenotype of Tomato: Response to Physical and Chemical Properties of Cotton Straw Mixed Seedling Matrix. Chin. Agric. Sci. Bull. 2020, 20, 36–43. [Google Scholar]
40. Xu, M.; Yoon, S.; Fuentes, A.; Park, D.S. A comprehensive survey of image augmentation techniques for deep learning. Pattern Recognit. 2023, 137, 109347. [Google Scholar] [CrossRef]
41. Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]

Li S, Yan Z, Ma B, Guo S, Song H. Semantic Segmentation Method for High-Resolution Tomato Seedling Point Clouds Based on Sparse Convolution. Agriculture. 2025; 15(1):74. https://doi.org/10.3390/agriculture15010074
Перевод статьи «Semantic Segmentation Method for High-Resolution Tomato Seedling Point Clouds Based on Sparse Convolution » авторов Li S, Yan Z, Ma B, Guo S, Song H., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)