Прогнозирование уровня воды в сельскохозяйственных водохранилищах с использованием AutoML
Разработка модели почасового прогнозирования уровня воды в малых и средних сельскохозяйственных водохранилищах с использованием AutoML: на примере водохранилища Бэкхак, Южная Корея
Аннотация
Данное исследование посвящено разработке модели почасового прогнозирования уровня воды в малых и средних сельскохозяйственных водохранилищах с применением Tree-based Pipeline Optimization Tool (TPOT) — инструмента автоматизированного машинного обучения (AutoML). В качестве объекта исследования было выбрано водохранилище Бэкхак в Южной Корее, для которого были собраны различные данные, связанные с осадками и объемом воды в водохранилище. На основе собранных данных мы сравнили широко используемые отдельные модели машинного и глубокого обучения с конвейерными моделями, созданными с помощью TPOT. Сравнение показало, что конвейерные модели, включавшие различные методы предварительной обработки данных и ансамблирования, продемонстрировали более высокую точность прогнозирования по сравнению с отдельными моделями машинного и даже глубокого обучения. Производительность оптимальной конвейерной модели была оценена на примере прогнозирования уровня воды во время экстремального ливня, что подтвердило ее эффективность для почасового прогнозирования. Однако были отмечены такие проблемы, как завышение прогнозных пиковых уровней воды и запаздывание в прогнозировании резких изменений уровня. Вероятно, это связано с неточностями в данных сверхкраткосрочного прогноза осадков и отсутствием информации о режиме эксплуатации водохранилища (например, об открытии шлюзов и планах сброса воды для сельскохозяйственных нужд). Это исследование подчеркивает потенциал методов AutoML для использования в гидрологическом моделировании и демонстрирует их вклад в разработку более эффективных стратегий управления водными ресурсами и предотвращения наводнений в сельскохозяйственных водохранилищах.
1. Введение
Межправительственная группа экспертов по изменению климата (МГЭИК) сообщает, что глобальное потепление привело к значительным изменениям в гидрологическом цикле, влияя на режим осадков, эвапотранспирацию, растительность и водные ресурсы по всему миру [1,2]. Во многих регионах наблюдаются изменения в характере осадков, такие как увеличение частоты сильных ливней и рост количества дождливых дней [3,4,5,6]. Эти сдвиги не только увеличивают риски наводнений, но и создают новые проблемы для систем управления водными ресурсами, которые теперь должны адаптироваться к более непредсказуемым и экстремальным погодным условиям [1]. По мере изменения режима осадков точное прогнозирование уровня воды становится необходимым для эффективной эксплуатации водохранилищ, особенно в условиях экстремальных погодных явлений.
Экстремальные осадки, характеризующиеся высокой интенсивностью и короткой продолжительностью, могут вызывать быстрый подъем уровня воды в водохранилищах. Такие события увеличивают риск наводнений, особенно в малых и средних сельскохозяйственных водохранилищах, которые не имеют средств контроля паводков и особенно уязвимы из-за короткого времени отклика водосбора на осадки. Следовательно, существует растущая потребность в разработке технологий краткосрочного прогнозирования уровня воды specifically для таких водохранилищ, чтобы обеспечить своевременные меры по управлению паводками.
Для прогнозирования уровня воды в водохранилищах и озерах использовались различные статистические [7,8,9] и методы машинного обучения (МО) [10,11,12,13], причем методы МО, как правило, превосходят по точности традиционные статистические модели [12]. Несмотря на это, большинство исследований сравнивают отдельные алгоритмы МО, что ограничивает потенциальное повышение точности. Ансамблевый метод, который комбинирует несколько алгоритмов, исследовался лишь в ограниченном числе случаев [14,15,16]. Однако эти исследования, как правило, выбирали модели без оптимизированных стандартов, а не тонко настраивали комбинации алгоритмов с разными принципами работы. Кроме того, feature engineering (например, отбор признаков, масштабирование) сильно варьировался, что влияло на производительность моделей, но требовало значительного опыта в МО и науке о данных. Автоматизированное машинное обучение (AutoML) может стать перспективным решением, автоматизируя процессы разработки моделей, включая feature engineering, кросс-валидацию, оптимизацию гиперпараметров, сравнение моделей, а также применение ансамблей.
Более того, хотя для малых и средних водохранилищ требуются краткосрочные почасовые прогнозы (например, на 1 час, 3 часа) для эффективного управления паводками, исследований по почасовому прогнозированию уровня воды для таких водохранилищ все еще недостаточно. Большинство предыдущих исследований были сосредоточены на месячных или суточных прогнозах уровня воды, которым не хватает необходимого интервала прогнозирования для реагирования на внезапные изменения уровня воды во время экстремальных осадков.
В этом контексте данное исследование направлено на разработку точной и эффективной модели почасового прогнозирования уровня воды в водохранилищах с использованием AutoML, способной эффективно работать в условиях экстремальных осадков. Для достижения этой цели мы анализируем влияние периодов обучающих данных на точность прогнозирования уровня воды, сравниваем различные традиционные алгоритмы МО с конвейерными моделями, созданными AutoML, и определяем модель с наилучшей производительностью. Затем эта модель используется для оценки точности прогнозирования во время экстремальных осадков. Это исследование повышает точность прогнозов и улучшает операционную эффективность управления сельскохозяйственными водохранилищами за счет предоставления своевременных и точных прогнозов уровня воды. В конечном счете, предложенная методология будет способствовать более эффективному управлению водными ресурсами и стратегиям смягчения последствий наводнений для малых и средних сельскохозяйственных водохранилищ.
2. Материалы и методы
2.1. Район исследования
Это исследование сосредоточено на водохранилище Бэкхак, расположенном по адресу: 184 Тонгу-ри, Мён Бэкхак, Уезд Йончхон, Провинция Кёнгидо, Южная Корея (Рис. 1b). Водохранилище имеет отметку гребня 52.70 м, уровень водопропускных сооружений паводковых вод 51.40 м, нормальный подпорный уровень (НПУ) 50.00 м и уровень мертвого объема (УМО) 41.00 м, с полной емкостью 1745.7 тыс. м3 и площадью водосбора 995 га. Водохранилище Бэкхак снабжает сельскохозяйственной водой 136 га пахотных земель. Первоначально построенное в 1942 году, водохранилище было расширено до нынешних масштабов в 1963 году и управляется Корпорацией сельских сообществ Кореи (KRC).
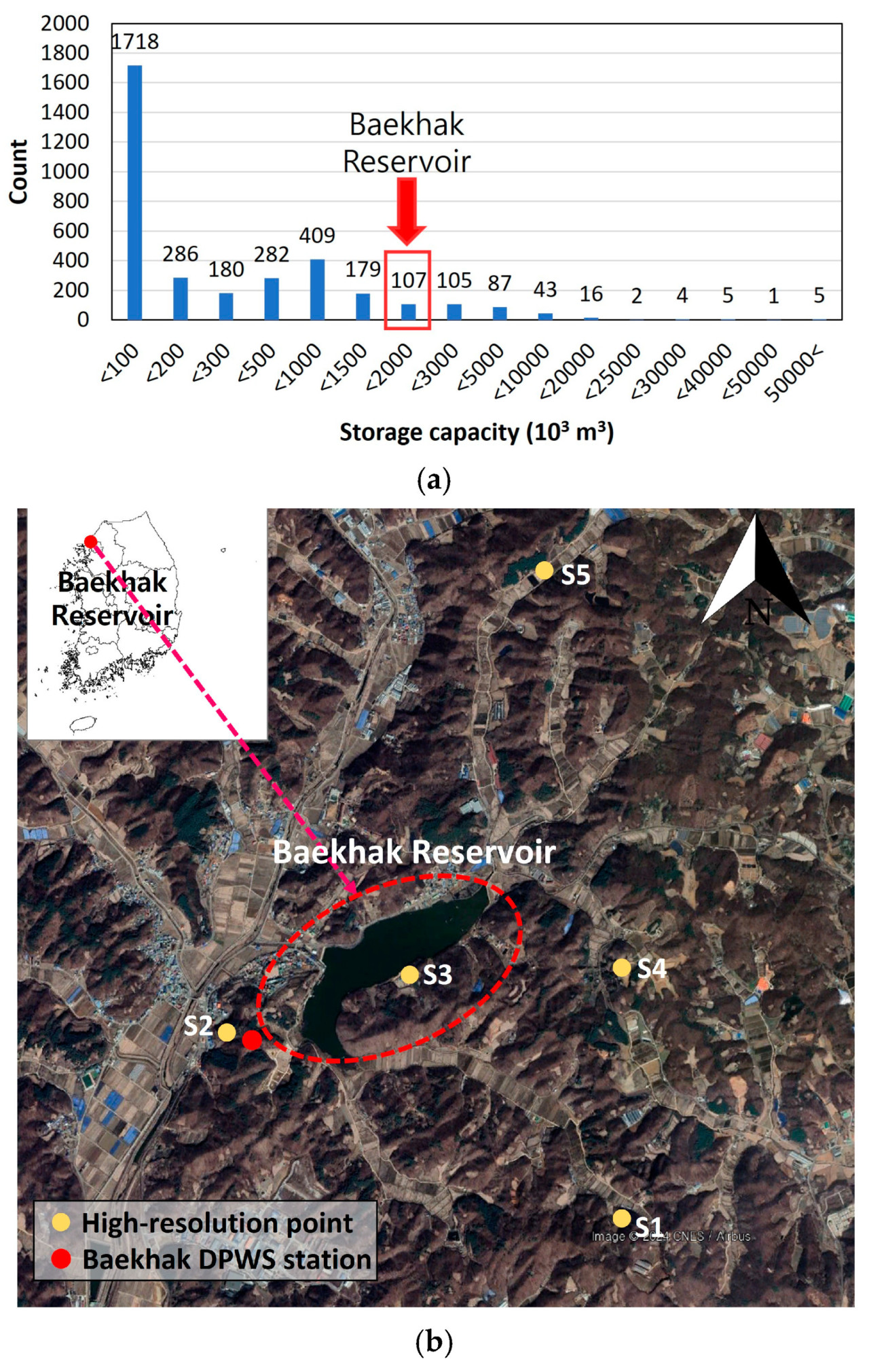
Рисунок 1. (a) Распределение сельскохозяйственных водохранилищ, управляемых Корпорацией сельских сообществ Кореи в Южной Корее, и (b) расположение водохранилища Бэкхак, Метеостанции предотвращения стихийных бедствий (МПСБ) Бэкхак и центральных точек данных высокого разрешения о осадках, использованных для разработки модели.
Водохранилище Бэкхак классифицируется как водохранилище среднего размера среди 3429 сельскохозяйственных водохранилищ, управляемых KRC (Рис. 1a). Малые и средние сельскохозяйственные водохранилища, такие как Бэкхак, широко распространены по всей Южной Корее и играют критически важную роль в управлении водными ресурсами в сельских районах. Эти водохранилища служат основными источниками орошения и составляют большинство водохранилищ. Из-за их ограниченной емкости по сравнению с крупными водохранилищами они особенно уязвимы для экстремальных погодных явлений, которые создают повышенные риски наводнений.
Недавно Метеостанция предотвращения стихийных бедствий (МПСБ) Бэкхак, управляемая Корейским метеорологическим управлением (KMA) и обозначенная оранжевой точкой на Рис. 1b, зафиксировала проливной дождь 17–18 июля 2024 года, суммарно составивший 510 мм — примерно 40% годовой нормы осадков. Эти интенсивные осадки привели к эвакуации жителей ниже по течению из-за риска наводнения, что еще раз подчеркивает необходимость надежных стратегий управления паводками на водохранилище Бэкхак.
2.2. Сбор данных и входные признаки
Это исследование aimed to разработать модель почасового прогнозирования уровня воды в водохранилище, используя только данные об осадках и уровне воды. Данные об осадках были собраны из нескольких источников, включая данные наблюдений с МПСБ Бэкхак, службу соседнего прогноза (сверхкраткосрочный прогноз текущей погоды (nowcast), сверхкраткосрочный прогноз, краткосрочный прогноз) и данные анализа погоды высокого разрешения (Таблица 1). Все наборы данных были предоставлены KMA через API-хаб KMA.
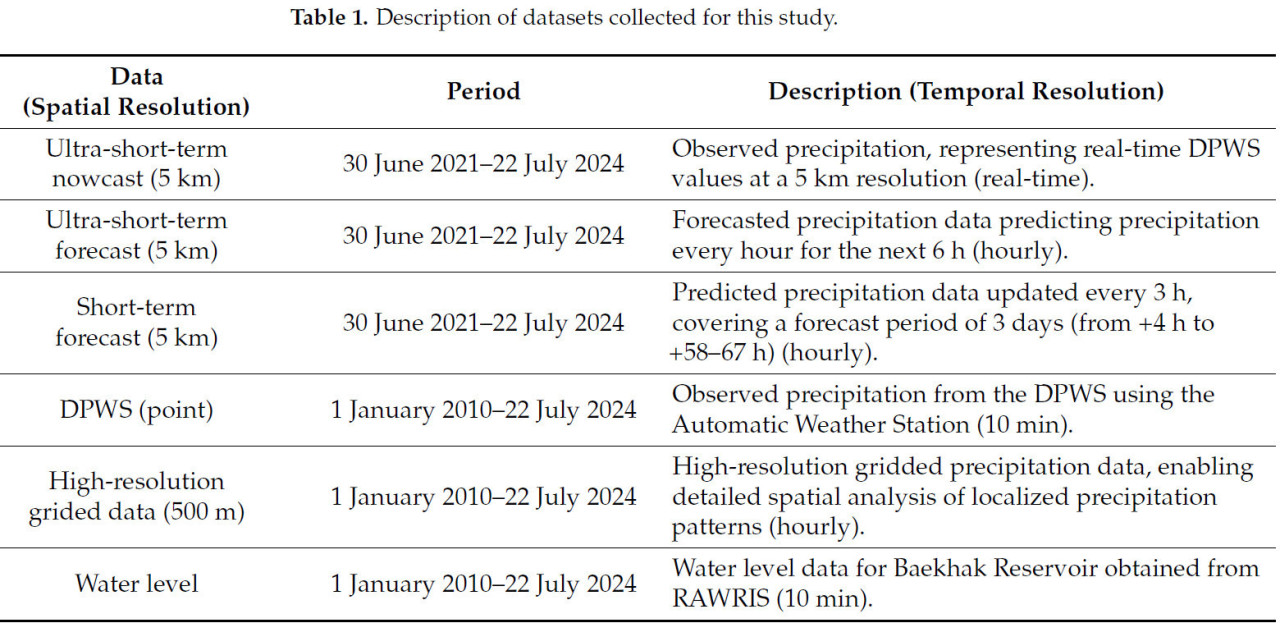
Таблица 1. Описание наборов данных, собранных для данного исследования.
МПСБ Бэкхак — это автоматическая метеорологическая станция (АМС), которая измеряет данные с интервалом в 1 минуту. Данные сверхкраткосрочного прогноза текущей погоды, сверхкраткосрочного прогноза и краткосрочного прогноза были получены от службы соседнего прогноза, которая предоставляет подробную погодную информацию для каждой административной области, разделенной на сетку 5 км × 5 км. Данные сверхкраткосрочного прогноза текущей погоды представляют собой наблюдаемые значения МПСБ для сетки прогноза соседства (разрешение 5 км), в то время как сверхкраткосрочный прогноз предсказывает погоду на следующие 6 часов. Краткосрочный прогноз публикуется каждые 3 часа и охватывает период 3 дня (от +4 ч до +58–67 ч). Кроме того, использовались данные осадков высокого разрешения с разрешением 500 м. Эти данные высокого разрешения производятся путем применения метода 3D объективного анализа, который учитывает влияние рельефа на данные наблюдений АМС, морских буев и маяков [17]. Значения из сеток, расположенных выше по течению от водохранилища Бэкхак, соответствующих верховьям, впадающим в водохранилище (S1–S5 на Рис. 1), были извлечены и использованы в качестве данных осадков высокого разрешения.
Данные об уровне воды для водохранилища Бэкхак были получены из Сельской информационной системы сельскохозяйственных водных ресурсов (RAWRIS). В то время как RAWRIS предоставляет ежедневные данные об уровне воды и коэффициенте заполнения через API, данные в реальном времени с 10-минутным интервалом доступны непосредственно на их веб-сайте. Поскольку исследование aimed to получить почасовые данные об уровне воды, был реализован веб-скрапинг с использованием пакета Python Selenium для сбора данных об уровне воды в 46 минут каждого часа. Выбор времени 46 минут был преднамеренным, поскольку обновления сверхкраткосрочного прогноза текущей погоды и прогноза публикуются в 40 минут каждого часа и становятся доступными в течение 45 минут. Это время обеспечивало синхронизацию с самыми актуальными данными прогноза осадков.
Данные об осадках с МПСБ и данные об уровне воды в водохранилище собирались за период с 1 января 2010 года по 22 июля 2024 года. Однако продукты прогноза для соседних районов (включая сверхкраткосрочный прогноз текущей погоды, сверхкраткосрочный прогноз и краткосрочный прогноз) были доступны только с 30 июня 2021 года. Чтобы учесть различия в доступности данных, мы подготовили два набора входных данных: краткосрочный набор данных (охватывающий 30 июня 2021–22 июля 2024 гг.) и долгосрочный набор данных (охватывающий 1 января 2010–22 июля 2024 гг.). Это позволило нам проанализировать влияние различных периодов данных на обучение модели для прогнозирования уровня воды в водохранилище. Для долгосрочного набора данных, где продукты прогноза для соседних районов были недоступны до 2021 года, мы использовали данные осадков высокого разрешения из точки, ближайшей к МПСБ Бэкхак (S2 на Рис. 1), в качестве замены. Это было достигнуто путем предположения, что наблюдаемые значения с МПСБ соответствуют прогнозируемым значениям в моменты времени прогноза, совпадающим с интервалами каждого набора данных прогноза для соседних районов, несмотря на то, что данные МПСБ являются наблюдаемыми, а не прогнозируемыми. Это предположение позволило нам сохранить согласованность интервалов прогноза в нашем долгосрочном наборе данных.
Признаки, использованные для обучения модели машинного обучения, включают дату (день года от 1 до 365 (или 366 для високосных лет)), время, уровень воды (wl), объем воды (wa), коэффициент заполнения (wr), наблюдаемые осадки с МПСБ Бэкхак (b_obs), прогнозы осадков на 1–6 часов (t1–t6) из сверхкраткосрочного прогноза, прогнозы осадков на 7–12 часов (t7–t12) из краткосрочного прогноза, осадки из данных высокого разрешения (s1–s5), аккумулированные за 6 и 12 часов осадки на МПСБ Бэкхак (sum_6, sum_12), а также данные об объеме воды и осадках за предыдущие 1–3 часа (b1–b3_wa, b1–b3_r). Краткосрочный набор данных состоял из 25 999 образцов, а долгосрочный набор данных содержал 117 414 образцов.
Выбор этих признаков согласуется с широко используемыми типами входных данных в существующих исследованиях по прогнозированию уровня воды в водохранилищах и озерах [12]. Дата и время включены для учета сезонных и суточных закономерностей, mientras que уровень воды, объем воды и коэффициент заполнения являются запаздывающими показателями, которые предоставляют essential информацию о прошлых состояниях водохранилища. Кроме того, различные источники данных об осадках, включая наблюдаемые и прогнозируемые осадки, позволяют модели учитывать как прошлые, так и прогнозируемые дождевые события, которые являются ключевыми факторами для точного прогнозирования уровня воды. При выборе этих признаков исследование также отдавало приоритет данным, которые являются общедоступными в Южной Корее, согласовывая процесс выбора признаков с ресурсами, доступными для управления сельскохозяйственными водохранилищами в этом регионе.
2.3. TPOT
2.3.1. Обзор TPOT
TPOT (Инструмент оптимизации древовидных конвейеров) — это система AutoML с открытым исходным кодом, которая использует алгоритмы генетического программирования (GP) [18,19]. TPOT служит оболочкой для пакета Python scikit-learn и интегрирует XGBoost, предоставляя доступ к различным алгоритмам МО и методам предварительной обработки данных. В TPOT эти алгоритмы и методы представлены в виде операторов, сгруппированных в категории, такие как контролируемая классификация, предварительная обработка признаков и отбор признаков, как показано на Рисунке 2. TPOT строит конвейеры, располагая эти операторы в древовидные структуры, где каждый узел представляет операцию в конвейере. Эта древовидная структура позволяет TPOT исследовать diverse конфигурации конвейеров, создавая diverse и сложные конструкции конвейеров.
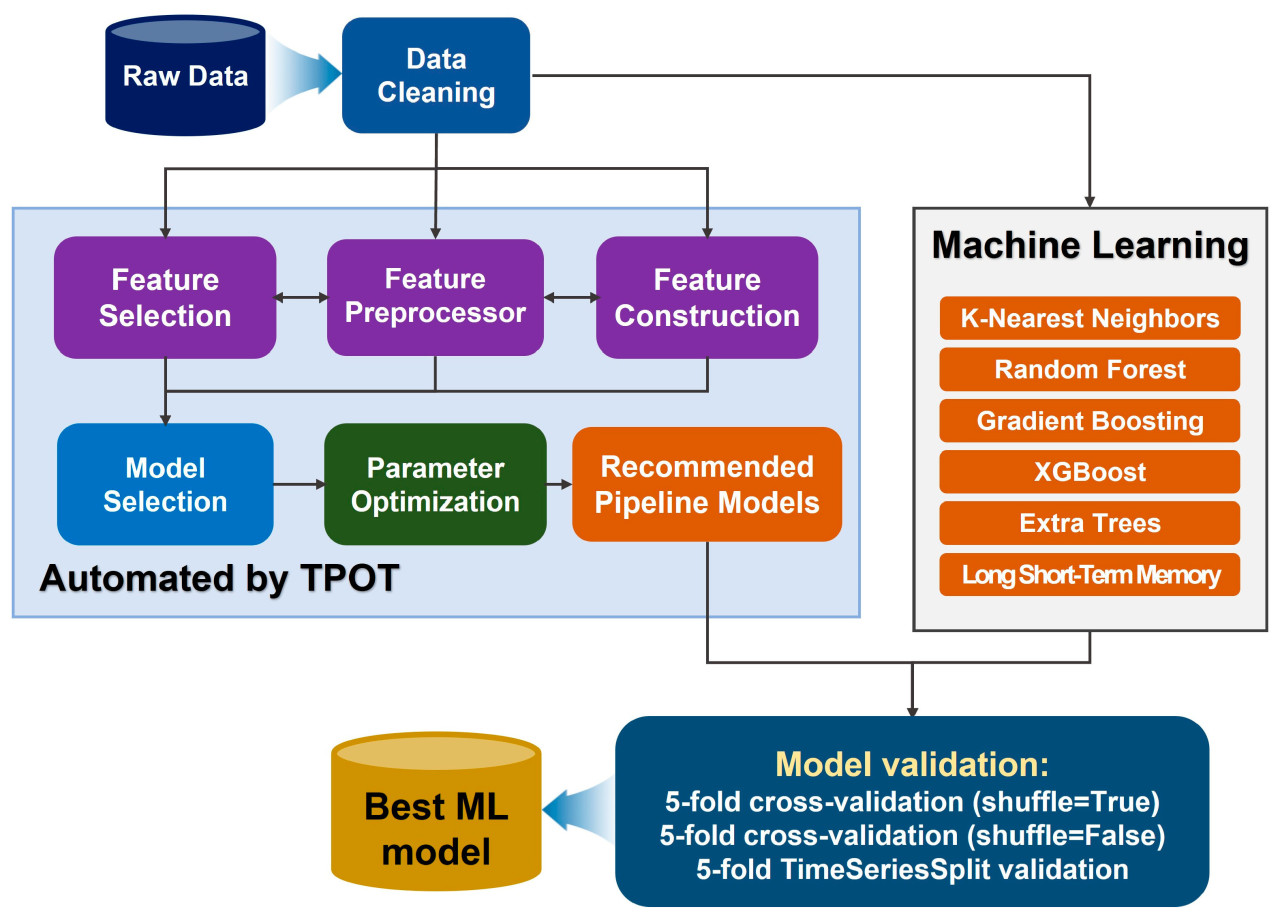
Рисунок 2. Схематическая иллюстрация процесса определения модели с наилучшей производительностью путем сравнения конвейерных моделей, сгенерированных TPOT, с индивидуально обученными моделями машинного обучения.
TPOT использует алгоритм GP, реализованный с помощью пакета Python DEAP, для поиска оптимального конвейера для данной задачи, такой как прогнозирование уровня воды [18]. Этот процесс начинается со случайно сгенерированной популяции конвейеров, оцениваемых по производительности на наборе данных с использованием точности кросс-валидации. Затем TPOT применяет схему выбора NSGA-II для приоритизации конвейеров, которые максимизируют точность, одновременно минимизируя сложность. Выбранные конвейеры подвергаются скрещиванию (crossover) и мутации (mutation) для создания новых кандидатов, и этот эволюционный процесс продолжается в течение указанного числа поколений. Конвейер с наивысшей точностью на фронте Парето, который представляет набор решений, предлагающих оптимальный компромисс между несколькими целями (такими как точность и сложность), выбирается в качестве лучшего решения в конце оптимизации.
Этот автоматизированный подход к оптимизации конвейеров снижает потребность в ручном проектировании и настройке гиперпараметров, делая МО более доступным для пользователей с разным уровнем опыта. TPOT показал свою эффективность в numerous областях [18,20,21], где он consistently превосходит модели, созданные вручную, и снижает усилия, необходимые для разработки высокопроизводительных прогнозных моделей.
2.3.2. Выбор оптимального алгоритма
Чтобы оценить эффективность TPOT, как фреймворка AutoML, и лучшего алгоритма, мы использовали TPOT для генерации и оценки различных конвейерных моделей путем комбинирования различных алгоритмов машинного обучения и этапов предварительной обработки. Для сравнения мы также обучили индивидуальные модели машинного обучения — K-ближайших соседей (KNN), Случайный лес (RF), Градиентный бустинг (GB), XGBoost (XGB) и Extra Trees (ET) — обычно используемые в прогнозировании уровня воды [10,12,22]. Кроме того, была включена Долгая краткосрочная память (LSTM), модель глубокого обучения на основе рекуррентной нейронной сети (RNN), выбранная за ее хорошо задокументированную способность улавливать временные зависимости и ее превосходную производительность в прогнозировании временных рядов [12].
При разработке индивидуальных моделей МО и LSTM мы сосредоточились исключительно на оптимизации гиперпараметров, исключая этапы feature engineering, такие как отбор признаков и масштабирование. Этот подход был принят для того, чтобы подчеркнуть и оценить возможности автоматизации TPOT, который по своей сути упрощает feature engineering наряду с оптимизацией и сравнением моделей. Поскольку настройка гиперпараметров значительно влияет на производительность модели, ее включение обеспечило справедливое сравнение, подчеркивая способность TPOT автоматизировать и улучшать весь рабочий процесс моделирования.
TPOT сгенерировал конвейерные модели, адаптированные для specific сроков упреждения прогноза: LassoLarsCV (sp_LL) для 1 часа, Градиентный бустинг в комбинации с LassoLarsCV (GB_LL) для 2 часов и ансамблевая модель, включающая LassoLarsCV, SGD, AdaBoost и ElasticNetCV (L_S_A_EN) для прогнозов на 3 часа. В Таблице 2 подробно описаны ключевые методы предварительной обработки, гиперпараметры, а также библиотеки и функции, примененные для каждой модели, что дает представление об их конфигурациях и производительности.
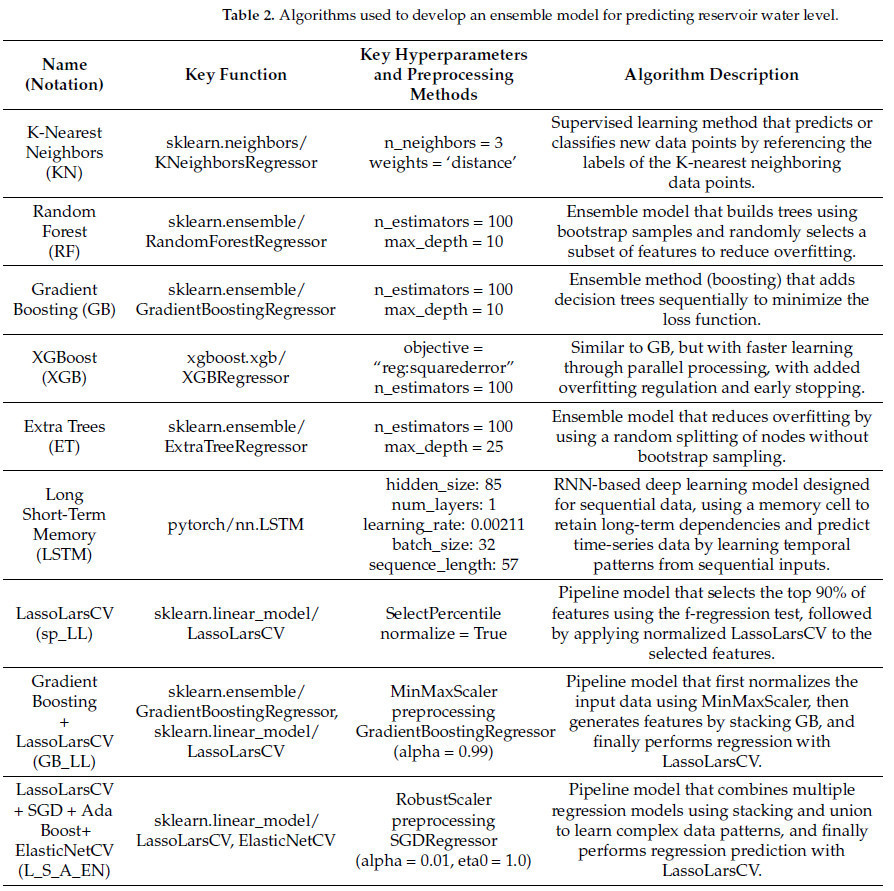
Таблица 2. Алгоритмы, использованные для разработки ансамблевой модели прогнозирования уровня воды в водохранилище.
Чтобы обеспечить надежную оценку производительности, мы использовали три метода кросс-валидации, включая TimeSeriesSplit для данных временных рядов и традиционные методы K-Fold. Кросс-валидация по K блокам (с перемешиванием) делит набор данных на K равных сегментов или «слоев», перемешивая данные для создания различных сценариев обучения и тестирования. Этот подход широко используется в науке о данных благодаря своей способности минимизировать переобучение, exposing модель к различным подмножествам данных [23]. В contrast, кросс-валидация по K блокам без перемешивания сохраняет последовательность данных нетронутой, сохраняя любые inherent закономерности, что особенно важно, когда временные отношения relevant. Для данных, чувствительных ко времени, таких как уровни воды, которые колеблются с течением времени, мы применили третий метод — TimeSeriesSplit. В отличие от случайных разбиений в K-Fold, TimeSeriesSplit incrementally расширяет набор обучающих данных на каждой итерации, гарантируя, что обучение и тестирование модели учитывают временные тенденции [24,25]. Этот sequential метод помогает лучше оценить производительность в реальных приложениях, gradually включая более ранние периоды времени.
Для данного исследования K было установлено равным 5 для каждой кросс-валидации, и, соответственно, наборы данных были разделены на пять слоев, как показано на Рисунке 3. Каждый слой использовался в качестве тестового набора один раз, mientras que остальные четыре слоя использовались для обучения, повторяя процесс пять раз для обеспечения сбалансированной оценки. В общей сложности было выполнено 15 раундов валидации, охватывающих несколько стратегий кросс-валидации для максимизации надежности. На Рисунке 3 показано, как каждый метод разделял обучающие и тестовые наборы, highlighting sequential подход TimeSeriesSplit, который сохраняет временной порядок данных, и более случайное разделение традиционных методов K-Fold.
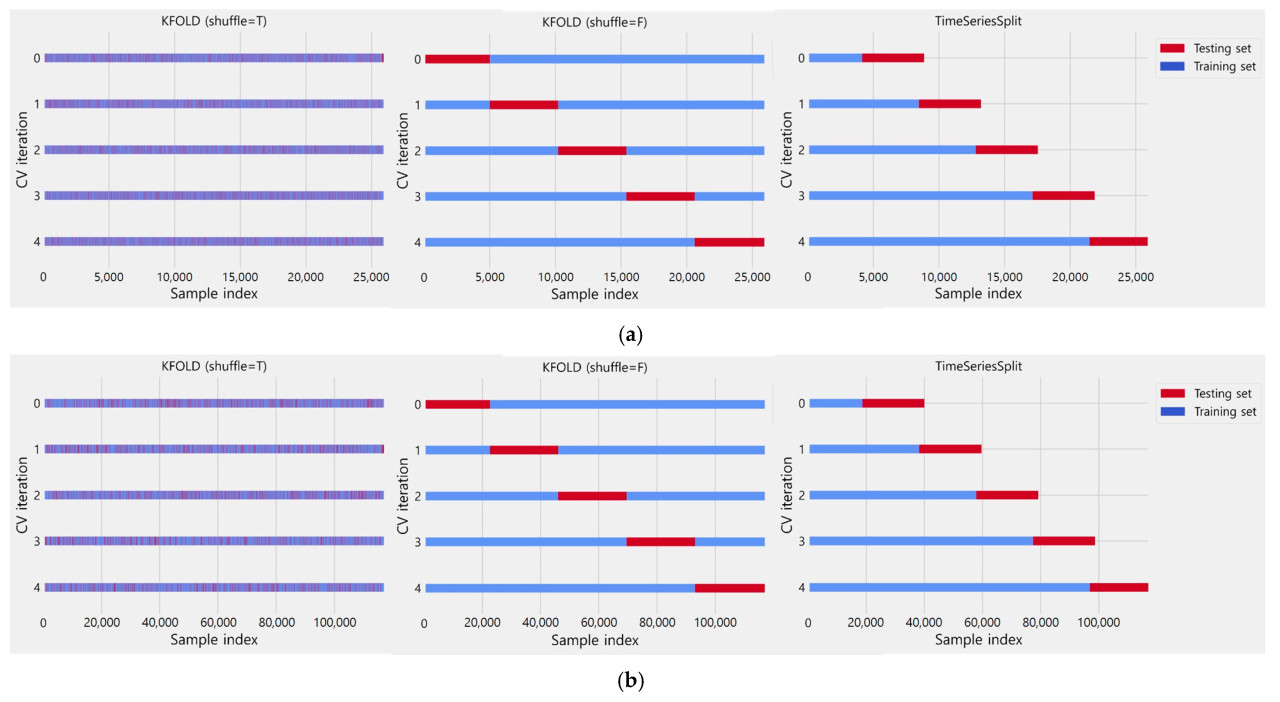
Рисунок 3. Методы разделения обучающих и тестовых данных для каждого набора данных в соответствии с методом кросс-валидации. (a) Краткосрочные наборы данных (30 июня 2021–22 июля 2024, n = 25,999). (b) Долгосрочные наборы данных (1 января 2010–22 июля 2024, n = 117,414).
2.4. Метрики оценки производительности

2.5. Оценка производительности воспроизведения экстремальных осадков с помощью моделирования сильного дождя
Модель прогнозирования уровня воды в водохранилище для противодействия паводкам на почасовой основе должна быть способна точно моделировать уровни воды даже при экстремальных погодных явлениях. Поэтому окончательно выбранный алгоритм, определенный с помощью различных методов кросс-валидации, был оценен на предмет его способности предсказывать уровни воды во время экстремальных осадков. Оценка specifically была сосредоточена на событии сильного дождя с 17 по 18 июля 2024 года, когда уровни воды превысили нормальный подпорный уровень (НПУ). Для этого мы организовали данные следующим образом: обучающие данные охватывали период с 30 июля 2021 года по 15 июля 2024 года, что исключало тестовый период экстремальных осадков. Затем обученная модель использовалась для прогнозирования на 1, 2 и 3 часа вперед для тестового периода с 16 по 22 июля 2024 года, которые сравнивались с наблюдаемыми уровнями воды. Этот анализ продемонстрировал способность модели эффективно предсказывать уровни воды даже в пиковых условиях, превышающих НПУ, подчеркивая ее пригодность для применения в управлении паводками.
2.6. Анализ чувствительности входных признаков
Чтобы проанализировать чувствительность модели прогнозирования уровня воды в водохранилище к различным входным признакам, были построены три различных набора входных данных (Таблица 3), и модели, обученные на этих наборах данных, были сравнены. input_1 — это базовый набор данных, который включает все признаки. input_2 исключал данные осадков высокого разрешения (s1–s5) и был построен для анализа влияния осадков высокого разрешения на прогнозы уровня воды. input_3 — это набор данных, построенный путем исключения объема воды (wa) и коэффициента заполнения (wr) при одновременном масштабировании уровня воды (wl) на коэффициент 0.1. Эта установка минимизирует влияние информации, связанной с текущим объемом воды, позволяя нам оценить влияние признаков, связанных с текущим объемом воды, на производительность модели. Модели, обученные на каждом наборе данных, использовались для прогнозирования уровня воды на 3 часа вперед, и прогнозируемые значения сравнивались с наблюдаемыми уровнями воды для оценки производительности модели. Это сравнение позволило оценить, как specific входные признаки влияют на производительность прогнозирования уровня воды, и дало представление о чувствительности модели к этим признакам.

Таблица 3. Описание входных наборов данных для анализа чувствительности.
3. Результаты
3.1. Анализ режима осадков и уровня воды в водохранилище по периодам данных
В этом исследовании использовались два набора данных, краткосрочный и долгосрочный, для анализа влияния периодов данных на прогнозирование уровня воды в водохранилище. На Рисунке 4 представлены временные ряды данных об осадках, наблюдаемых на МПСБ, и соответствующих наблюдаемых уровней воды для каждого периода. Краткосрочный набор данных (Рис. 4a) включает событие сильного дождя, произошедшее 17–18 июля 2024 года, показывающее rapid подъем уровней воды, превышающий НПУ (50 м). Однако краткосрочный набор данных не включает каких-либо лет с сильной засухой. С другой стороны, долгосрочный набор данных (Рис. 4b) включает как годы с высоким количеством осадков, такие как сильный дождь в июле 2024 года, так и годы с очень низким количеством осадков из-за засухи. Следовательно, ожидается, что долгосрочный набор данных предоставит более широкий диапазон информации об осадках и уровне воды для обучения модели по сравнению с краткосрочным набором данных.
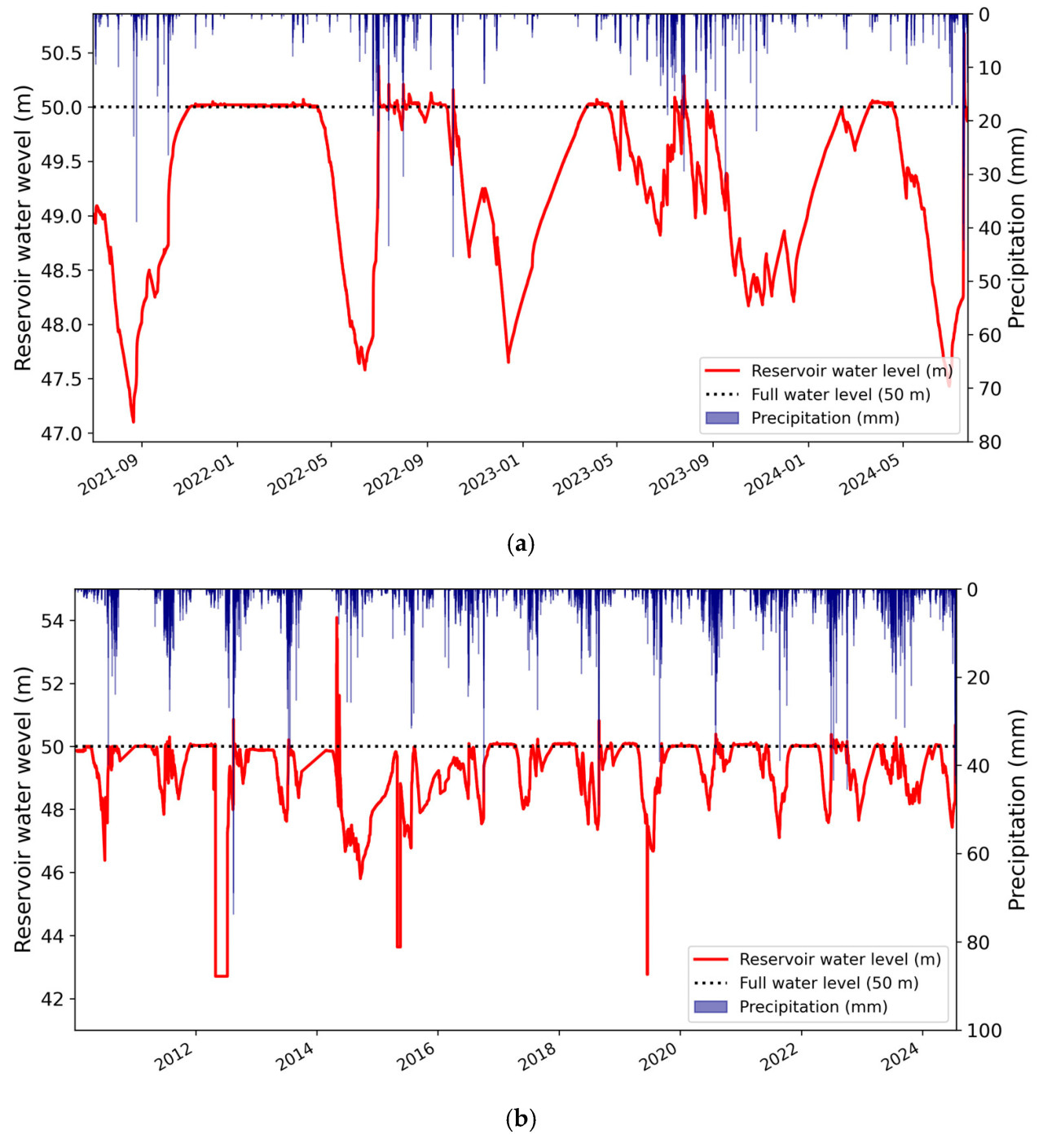
Рисунок 4. Временные вариации уровней воды в водохранилище и осадков в каждом наборе данных. Черные пунктирные линии на каждом графике представляют нормальный подпорный уровень (50 м). (a) Краткосрочные наборы данных (30 июня 2021–22 июля 2024). (b) Долгосрочные наборы данных (1 января 2010–22 июля 2024).
3.2. Статистический анализ признаков и корреляция с уровнями воды в водохранилище
Всего для обучения модели прогнозирования уровня воды в водохранилище использовался 31 признак, включая дату, время, wl, wa, wr, b_obs, t1–t12, s1–s5, sum_6, sum_12, b1_wa, b2_wa, b3_wa, b1_wr, b2_wr и b3_wr. Статистическая информация для каждого признака (среднее значение, стандартное отклонение, минимум, 1-й квартиль, медиана, 3-й квартиль, максимум, асимметрия, эксцесс) представлена в Таблицах 4 и 5.
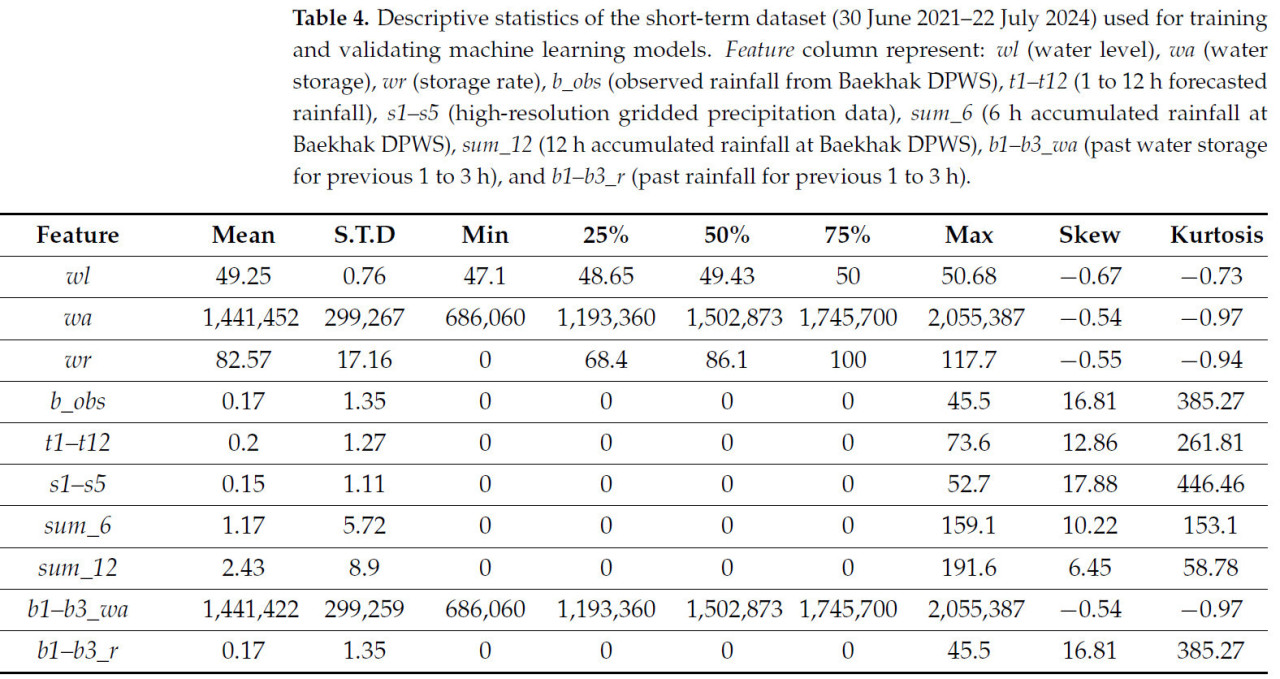
Таблица 4. Описательная статистика краткосрочного набора данных (30 июня 2021–22 июля 2024), использованного для обучения и валидации моделей машинного обучения. Столбец Feature представляет: wl (уровень воды), wa (объем воды), wr (коэффициент заполнения), b_obs (наблюдаемые осадки с МПСБ Бэкхак), t1–t12 (прогнозируемые осадки на 1–12 часов), s1–s5 (данные осадков высокого разрешения), sum_6 (аккумулированные за 6 часов осадки на МПСБ Бэкхак), sum_12 (аккумулированные за 12 часов осадки на МПСБ Бэкхак), b1–b3_wa (объем воды за предыдущие 1–3 часа) и b1–b3_r (осадки за предыдущие 1–3 часа).
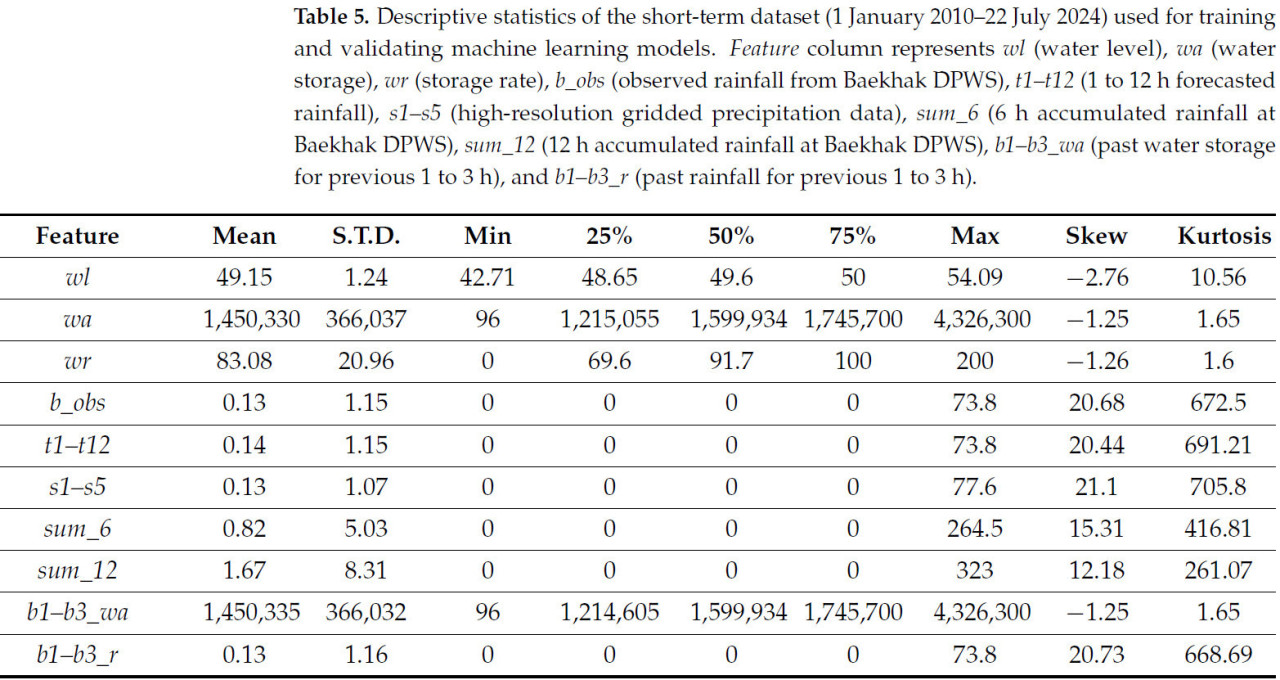
Таблица 5. Описательная статистика долгосрочного набора данных (1 января 2010–22 июля 2024), использованного для обучения и валидации моделей машинного обучения. Столбец Feature представляет: wl (уровень воды), wa (объем воды), wr (коэффициент заполнения), b_obs (наблюдаемые осадки с МПСБ Бэкхак), t1–t12 (прогнозируемые осадки на 1–12 часов), s1–s5 (данные осадков высокого разрешения), sum_6 (аккумулированные за 6 часов осадки на МПСБ Бэкхак), sum_12 (аккумулированные за 12 часов осадки на МПСБ Бэкхак), b1–b3_wa (объем воды за предыдущие 1–3 часа) и b1–b3_r (осадки за предыдущие 1–3 часа).
Согласно статистическому анализу, признаки, связанные с уровнем воды (wl, wa, wr, b1_wa, b2_wa, b3_wa), exhibited асимметричные распределения с правосторонней асимметрией, но значения асимметрии были между −1 и +1, что указывает на умеренную асимметрию [6]. Значения эксцесса были отрицательными, показывая более плоские распределения вокруг центра с более тонкими хвостами. С другой стороны, признаки, связанные с осадками (b_obs, t1–t12, sum_6, sum_12, b1_r, b2_r, b3_r), показали распределения с высокой левосторонней асимметрией (асимметрия > +1) с положительными значениями эксцесса, indicating распределения с более толстыми хвостами и острыми пиками.
В целом, обе группы признаков показали схожие распределения в within их respective категориях, хотя и с varying степенями асимметрии и эксцесса. Это diversity в статистических свойствах среди входных признаков, как ожидается, предоставит ценную и разнообразную информацию в процессе обучения машинного обучения, позволяя модели улавливать широкий спектр закономерностей и улучшать точность прогнозирования.
Кроме того, был проведен корреляционный анализ между целевой переменной (уровень воды на 1 час вперед) и входными признаками с использованием коэффициентов корреляции Пирсона (r) как для краткосрочного, так и для долгосрочного периода (Таблица 6) с их диаграммами рассеяния на Рисунке 5. Результаты показывают, что признаки, связанные с уровнем воды (wl, wa, wr, b1_wa, b2_wa, b3_wa), имели высокие значения корреляции, ranging от 0.8 до 1, indicating сильную linear связь. Specifically, согласно диаграммам рассеяния, b1_wa, b2_wa и b3_wa показали нелинейную зависимость. В contrast, все признаки, связанные с осадками, имели значения r ниже 0.01, suggesting очень слабые корреляции.
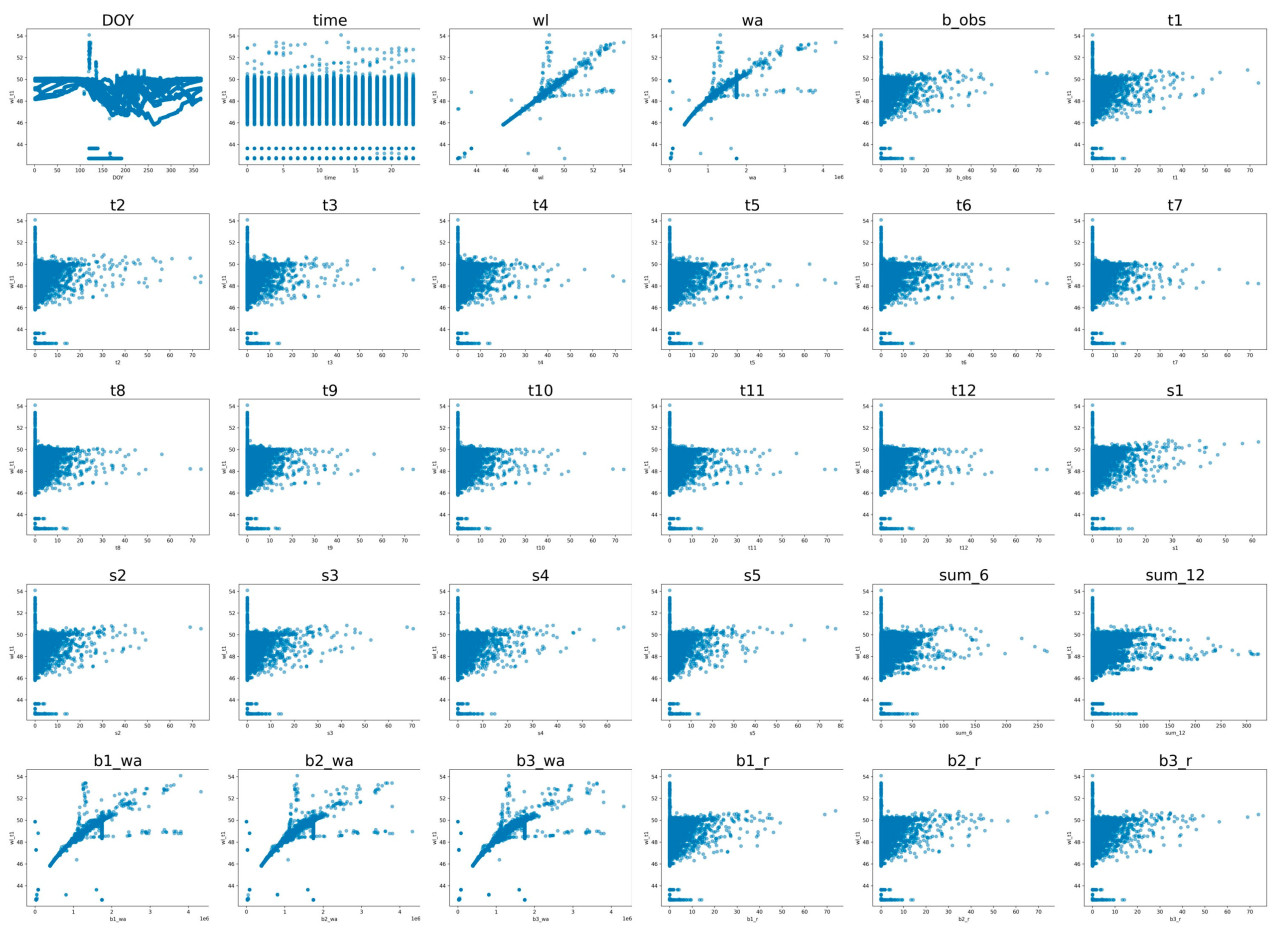
Рисунок 5. Диаграммы рассеяния, показывающие взаимосвязь между уровнем воды на 1 час вперед (м) и каждым признаком в краткосрочном наборе данных. На каждом графике ось y представляет уровень воды на 1 час вперед, а ось x соответствует specific признаку, указанному в заголовке графика.
Таблица 6. Коэффициент корреляции (r) между признаками и уровнями воды на 1 час вперед.
Однако, поскольку коэффициент корреляции Пирсона измеряет только линейные зависимости, наблюдаемые низкие линейные корреляции между признаками и уровнем воды на 1 час вперед не исключают возможности нелинейных зависимостей. Тем не менее, из-за этих низких линейных корреляций традиционные статистические методы, такие как множественная линейная регрессия (MLR), могут иметь ограничения в точном прогнозировании уровня воды на 1 час вперед. Это подчеркивает необходимость в более advanced методах, таких как методы машинного обучения, которые способны обрабатывать сложные нелинейные взаимодействия между признаками.
3.3. Сравнение производительности прогнозирования уровня воды разработанных моделей
Модели прогнозирования уровня воды в водохранилище были построены с использованием отдельных алгоритмов МО и конвейерных моделей, рекомендованных TPOT, с использованием как краткосрочных, так и долгосрочных наборов данных (Рисунок 6).
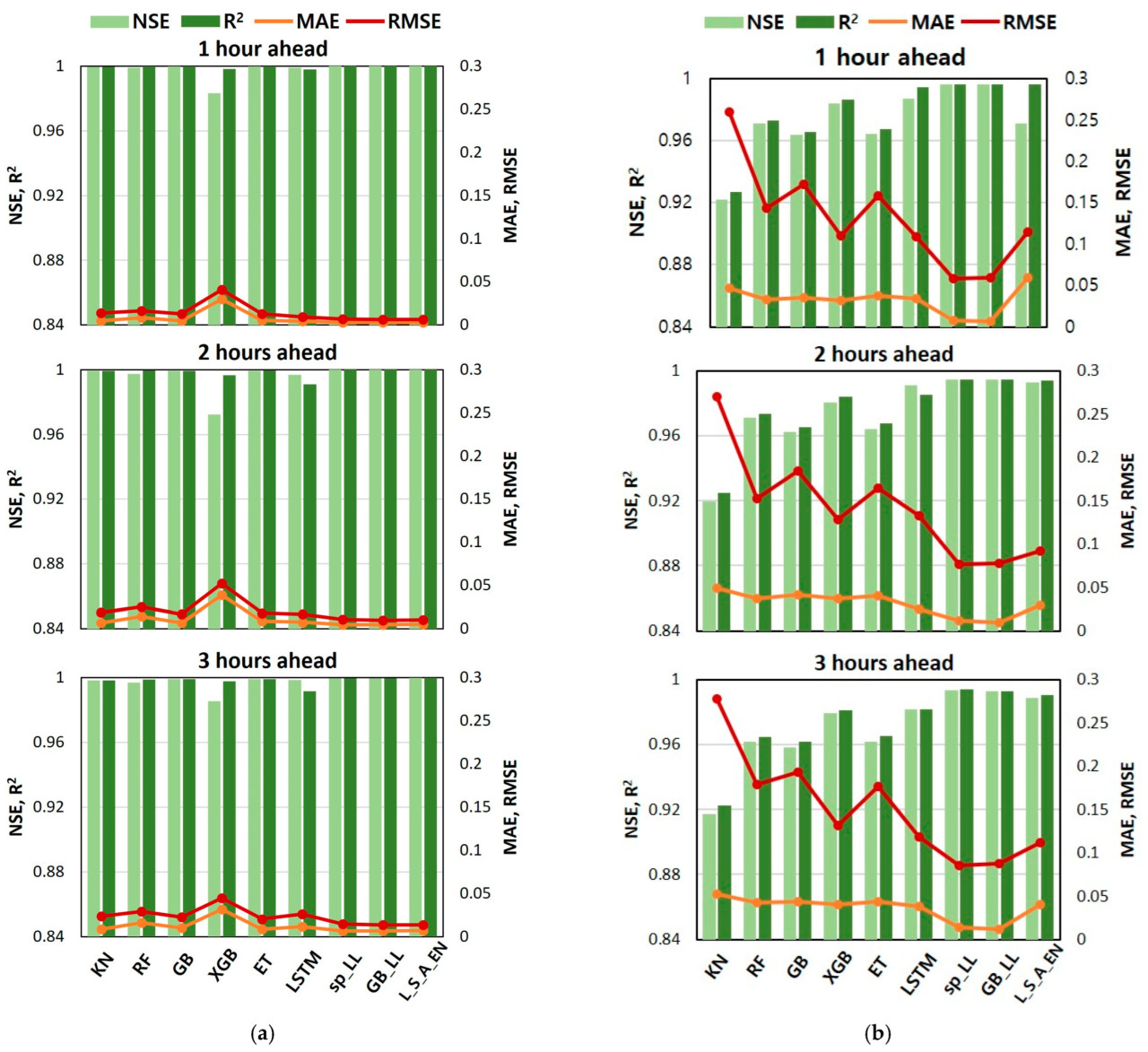
Рисунок 6. График сравнения результатов 15-кратной кросс-валидации. (a) Краткосрочные наборы данных (30 июня 2021–22 июля 2024). (b) Долгосрочные наборы данных (1 января 2010–22 июля 2024).
Для краткосрочного набора данных различия в производительности между моделями были незначительными. Однако XGB consistently проявлял самую низкую точность across сроки упреждения 1 ч, 2 ч и 3 ч, с самыми низкими значениями NSE и R2 и более высокими значениями MAE и RMSE, за ним следовал LSTM. Другие индивидуальные алгоритмы МО показали высокую точность прогнозирования со значениями NSE и R2, близкими к 1, на всех сроках упреждения. RF показал небольшое снижение NSE и точности для срока упреждения 3 ч. Среди конвейерных моделей, сгенерированных TPOT, sp_LL, GB_LL и L_S_A_EN показали slightly превосходящую и более стабильную производительность across сроков упреждения, причем L_S_A_EN достиг самых низких MAE и RMSE, что сделало его самым точным алгоритмом на краткосрочном наборе данных.
В contrast, модели, обученные на долгосрочном наборе данных, exhibited большее variation в производительности прогнозирования (Рис. 6b). Точность generally снижалась для срока упреждения 3 ч по сравнению со сроком упреждения 1 ч. KNN показал самую низкую точность среди индивидуальных МО на всех сроках упреждения, mientras que LSTM показал более высокую точность, чем индивидуальные МО, но все же показал худшую производительность по сравнению с конвейерными моделями, сгенерированными TPOT. Среди моделей TPOT sp_LL был самым точным, за ним следовал GB_LL, хотя различия в производительности были минимальными.
Превосходная производительность конвейерных моделей, сгенерированных TPOT, подчеркивает эффективность TPOT, especially учитывая, что LSTM, алгоритм глубокого обучения, хорошо подходящий для прогнозирования временных рядов, typically превосходит conventional алгоритмы МО в прогнозировании уровня воды [12,26,27]. Этот результат может быть attributed к автоматизированным ансамблевым техникам TPOT и оптимальным этапам предварительной обработки, которые улучшают производительность без requiring обширного ручного вмешательства. В то время как гиперпараметры LSTM были оптимизированы, его прогностическая точность могла бы быть потенциально улучшена за счет более тонкого feature engineering. Однако такие улучшения require значительного опыта, навыков программирования и временных затрат. В contrast, TPOT предлагает эффективное и экономичное решение, automatically сравнивая модели, применяя ансамблевые техники и генерируя конвейеры с различными методами feature engineering.
В конечном счете, модель с наилучшей производительностью была выбрана на основе моделей, обученных на краткосрочных наборах данных, которые показали более высокую точность, чем модели, обученные на долгосрочном наборе данных. Среди них L_S_A_EN был выбран за его превосходную производительность across всех статистических метрик. Следовательно, конвейер L_S_A_EN, который объединяет и stackирует несколько регрессионных моделей через union и выполняет окончательное регрессионное прогнозирование с использованием LassoLarsCV (Таблица 2), был выбран в качестве оптимальной модели.
3.4. Воспроизведение экстремального дождевого события и оценка точности модели с использованием модели L_S_A_EN
Используя конвейерную модель L_S_A_EN, выбранную в качестве оптимальной модели с помощью 15-кратной кросс-валидации, мы оценили, может ли она воспроизвести событие, когда уровень воды превысил НПУ из-за сильного дождя, произошедшего 17–18 июля 2024 года. Тестовый период был установлен с 16 по 22 июля 2024 года, и краткосрочный набор данных, исключающий данные за тестовый период, был использован для обучения модели L_S_A_EN. Прогнозируемые уровни воды на 1, 2 и 3 часа вперед затем сравнивались с наблюдаемыми уровнями воды в течение тестового периода (Рисунок 7).
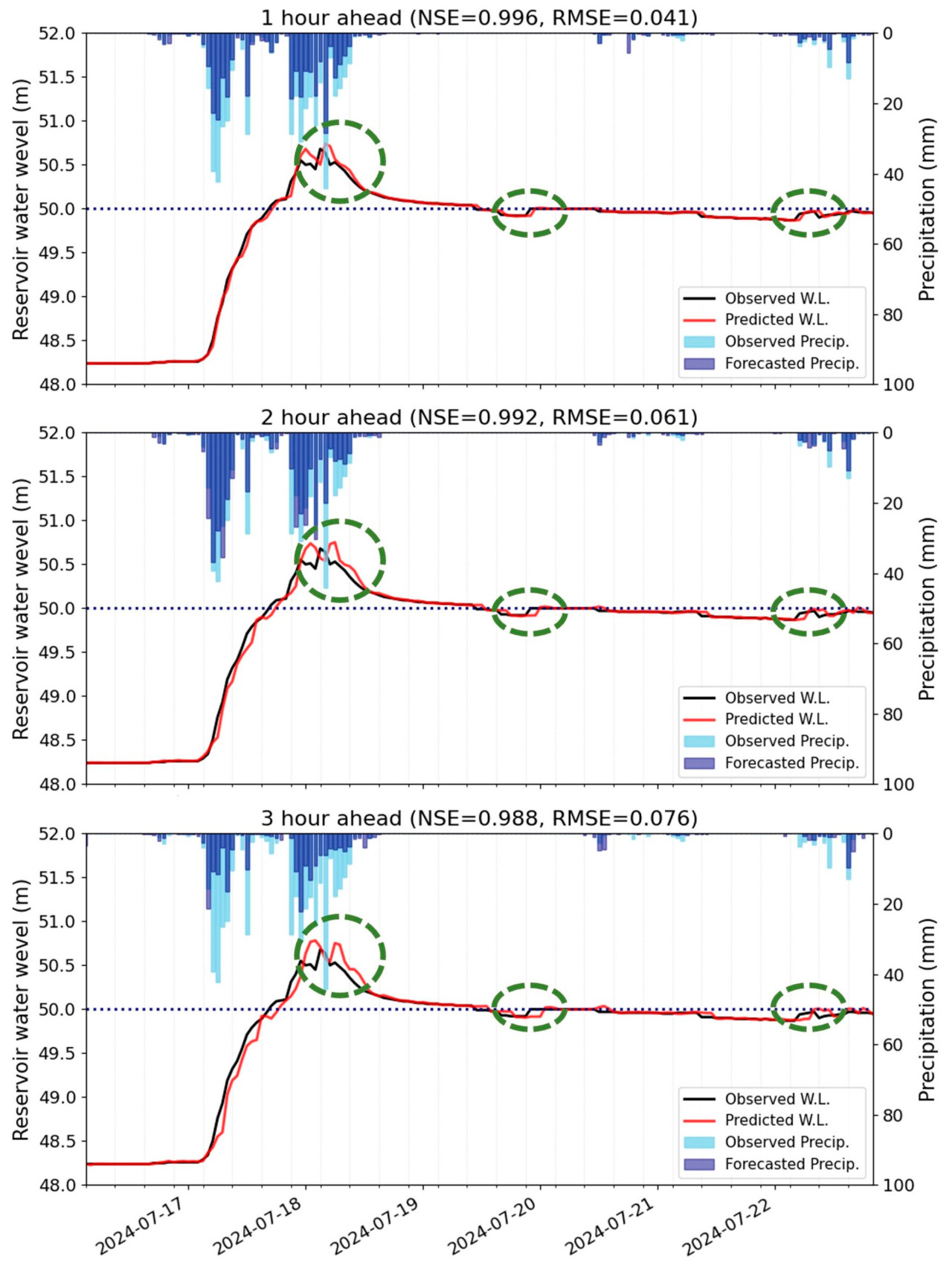
Рисунок 7. Временные вариации прогнозируемого и наблюдаемого уровня воды в водохранилище в течение тестового периода. Синие пунктирные линии обозначают нормальный подпорный уровень 50 м водохранилища Бэкхак. В легенде на каждом графике «Pecip.» обозначает осадки, а «W.L.» обозначает уровень воды. «Forecast Precip.» обозначает сверхкраткосрочный прогноз осадков. Зеленые кружки выделяют места, где возникли временные несовпадения, которые усиливались с увеличением времени упреждения.
Модели прогнозирования уровня воды на 1, 2 и 3 часа вперед все точно captured общую тенденцию наблюдаемых уровней воды. Значения NSE и RMSE для моделей с упреждением 1, 2 и 3 часа indicated самую высокую точность модели с упреждением 1 час. Specifically, модель с упреждением 1 час точно предсказала момент, когда уровень воды превысил НПУ (50 м). Однако на пиковом уровне воды модель slightly завысила фактическое значение. Кроме того, когда произошел первый пик, прогнозируемый уровень воды поднимался медленнее, чем наблюдаемый уровень воды. Аналогично, после первого пика снижение прогнозируемого уровня воды также запаздывало по сравнению с фактическим уровнем воды, и та же картина наблюдалась во время второго пика. Эти временные несовпадения были наиболее заметны во время резких изменений уровня воды (выделены зелеными кружками на Рис. 7) и становились более выраженными с увеличением времени упреждения.
Завышение пиковых уровней воды и временное несовпадение связаны с низкой точностью данных сверхкраткосрочного прогноза осадков. Сравнение наблюдаемых и прогнозируемых осадков на Рисунке 7 показывает значительные ошибки как в величине, так и во времени прогнозируемых осадков. В частности, данные сверхкраткосрочного прогноза осадков на 3 часа exhibited значительные ошибки, предсказывая менее половины фактического количества осадков и displaying совершенно другое распределение осадков до и после пиковых уровней воды. Это расхождение между прогнозируемыми и фактическими осадками suggests, что снижение точности прогнозов уровня воды при более длительных сроках упреждения stems от зависимости модели от неточных прогнозов осадков.
Кроме того, на точность модели также могут влиять другие природные факторы, включая удерживающую и инфильтрационную способность берегов водохранилища, задержку стока в пределах водосборного бассейна и наличие растительности в водохранилище и вокруг него. Эти природные элементы влияют на колебания уровня воды, но не были явно смоделированы в данном исследовании. Более того, контролируемые человеком факторы, такие как графики орошения и операции сброса воды для предотвращения наводнений, также могут способствовать несовпадению между прогнозируемыми и наблюдаемыми уровнями воды, particularly в долгосрочных прогнозах. Включив эти дополнительные факторы в будущую работу, точность модели при использовании для долгосрочных прогнозов может быть потенциально улучшена.
3.5. Анализ чувствительности производительности прогнозирования уровня воды на основе входных признаков
Чтобы изучить чувствительность прогнозов уровня воды к различным входным признакам, были построены три входных набора данных (Таблица 3), и модели, обученные на каждом наборе данных, были использованы для прогнозирования уровней воды на 3 часа вперед, по сравнению с наблюдаемыми уровнями воды (Рисунок 8). Модели, обученные на input_1 и input_2, продемонстрировали одинаковую точность (NSE = 0.99; RMSE = 0.08), suggesting, что данные осадков высокого разрешения имеют minimal влияние на производительность прогнозирования уровня воды. Следовательно, исключение данных осадков высокого разрешения из модели рекомендуется для снижения сложности и повышения вычислительной эффективности. С другой стороны, модель, обученная на input_3, показала slightly более низкую точность (NSE = 0.98; RMSE = 0.09), indicating, что информация, связанная с текущим объемом воды, имеет significant влияние на время прогноза. Фактически, в результатах от input_3, который исключал признаки, связанные с водохранилищем, величина прогнозируемых уровней воды осталась почти identical, но временные несовпадения были более выраженными. Это suggests, что в то время как признаки, связанные с текущим объемом водохранилища, имеют limited влияние на величину прогнозируемых уровней воды, они предоставляют critical информацию относительно времени изменений уровня воды. Учитывая это, будущие исследования должны включать дополнительные признаки, связанные с объемом водохранилища (например, градиент уровня воды, первые разности), и анализировать, улучшают ли они временную точность.
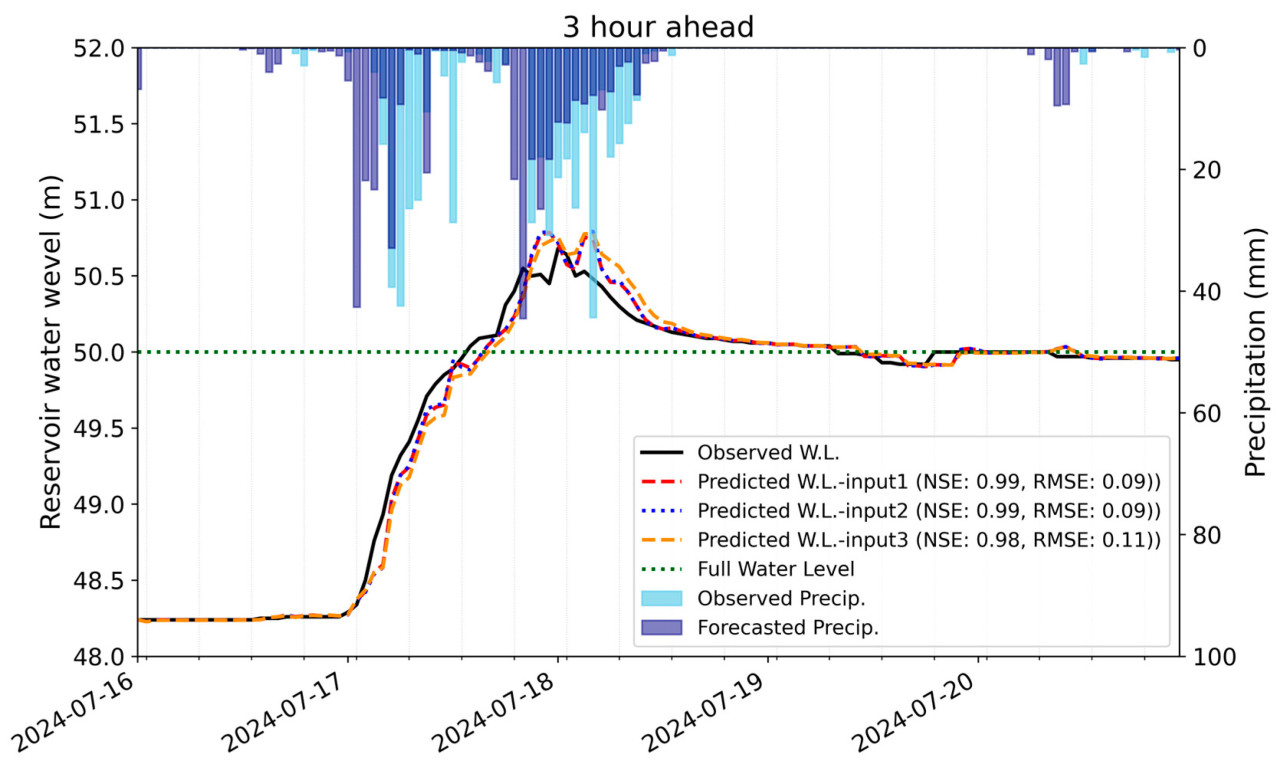
Рисунок 8. Сравнение прогнозируемых и наблюдаемых уровней воды (время упреждения = 3 ч) на основе различных входных признаков.
4. Обсуждение
4.1. Ключевые выводы и интерпретация
Корреляционный анализ Пирсона revealed слабую или отсутствующую корреляцию между входными признаками и уровнем воды на 1 час вперед (Таблица 6). Несмотря на это, модели МО продемонстрировали высокую точность, suggesting, что даже при низких линейных корреляциях могут существовать сложные нелинейные взаимодействия между признаками и целевой переменной, как показано на диаграммах рассеяния на Рисунке 5. Это демонстрирует ограничения традиционных статистических методов, таких как множественная линейная регрессия (MLR), в точном прогнозировании уровней воды, в то время как модели машинного обучения могут эффективно идентифицировать и моделировать сложные нелинейные зависимости.
Это исследование также оценило влияние периода данных на производительность моделей, сравнивая краткосрочные и долгосрочные наборы данных. Результаты показывают, что модели, обученные на краткосрочном наборе данных, превзошли модели, обученные на долгосрочном наборе данных. Обычно можно было бы ожидать, что более длинные наборы данных приведут к лучшей производительности, учитывая generally положительную связь между объемом обучающих данных и точностью модели [28]. Однако в данном исследовании это было не так. Одно из возможных объяснений заключается в том, что при создании долгосрочного набора данных периоды без данных прогноза осадков для соседних районов (сверхкраткосрочный прогноз текущей погоды, сверхкраткосрочный прогноз и краткосрочный прогноз) были заполнены с использованием данных осадков высокого разрешения, что могло внести несогласованность. Эти два источника данных fundamentally различаются по входным требованиям и основным алгоритмам, что приводит к varying характеристикам, таким как смещения. Поэтому объединение этих наборов данных в один обучающий набор без статистического ансамблевого метода для уменьшения несогласованности в каждом наборе данных могло увеличить общую неопределенность в данных. Это подчеркивает важность качества данных, предварительной обработки данных и обработки неопределенностей во время обучения модели.
4.2. Сравнение с существующими исследованиями и ограничения
Это исследование использовало TPOT, технику AutoML, для разработки конвейерных моделей МО и сравнило их производительность с индивидуальными алгоритмами МО и LSTM, чтобы оценить возможности автоматизации TPOT. Сгенерированные TPOT конвейерные модели продемонстрировали превосходную прогностическую точность по сравнению с индивидуальными МО и даже LSTM, моделью глубокого обучения, известной своей высокой производительностью в задачах прогнозирования временных рядов [12]. Эффективность AutoML была установлена в различных областях [29,30,31,32], и данное исследование расширяет ее продемонстрированную полезность для почасового прогнозирования уровня воды в водохранилищах. В то время как модели МО и глубокого обучения широко применялись в исследованиях прогнозирования уровня воды [11,13,33,34], применение AutoML остается relatively ограниченным. Успешно применив TPOT в этой области, данное исследование предоставляет ценные сведения о практичности и потенциальных преимуществах использования AutoML, особенно TPOT, для прогнозирования уровня воды на почасовой основе.
Однако, несмотря на высокую точность оптимальной модели L_S_A_EN, она exhibited запаздывающие прогнозы при прогнозировании внезапных изменений уровня воды. Например, когда уровни воды быстро поднимались или падали, модель tended предсказывать значения с задержкой. Это временное несовпадение становилось более выраженным с увеличением времени упреждения, common проблема в прогнозировании временных рядов [35,36], вызванная неспособностью модели fully учитывать зависящие от времени закономерности. Чтобы решить эту проблему, следует рассмотреть больше признаков, связанных с объемом водохранилища, которые, как было обнаружено, чувствительны к проблеме запаздывающего прогноза. Эти признаки могут включать скорость изменения уровней воды или разности первого порядка между временными шагами.
Кроме того, эти запаздывающие прогнозы могут быть частично due к тому, что на сельскохозяйственные водохранилища влияют не только природные факторы, но и вмешательство человека, такое как графики орошения и операции сброса. Однако признаки, использованные в этом исследовании, не отражали такие контролируемые человеком факторы, что могло бы объяснить часть ограничений модели. Поэтому в будущих исследованиях следует включать данные об эксплуатации водохранилища, такие как расходы сброса, графики орошения и модели сельскохозяйственной деятельности. Включение этих факторов позволит создать более комплексные модели, которые учитывают как природные, так и контролируемые человеком факторы, влияющие на колебания уровня воды. Включение этих признаков может улучшить способность модели более точно предсказывать изменения уровня воды и уменьшить временное несовпадение, наблюдавшееся в данном исследовании.
Методология, предложенная данным исследованием, была применена с использованием одного объекта исследования, что ограничивает ее обобщаемую применимость, хотя и была продемонстрирована осуществимость подхода. Учитывая огромное количество малых и средних водохранилищ в Южной Корее, необходима более комплексная валидация по нескольким водохранилищам для достижения более широкого обобщения. К счастью, входные наборы данных и предложенная методология были разработаны так, чтобы быть применимыми ко всем сельскохозяйственным водохранилищам, управляемым Корпорацией сельских сообществ Кореи в Южной Корее. Эта адаптируемость делает возможным распространение подхода на другие водохранилища в будущих исследованиях, что мы и aim to сделать, чтобы повысить обобщаемость наших выводов. Расширение применения на diverse спектр водохранилищ обеспечит более robust понимание сильных и слабых сторон методологии в varying гидрологических и экологических условиях, типичных для малых и средних водохранилищ.
5. Выводы
Это исследование продемонстрировало эффективность использования методов AutoML, specifically фреймворка TPOT, для повышения точности прогнозов уровня воды в сельскохозяйственных водохранилищах с почасовым разрешением. Предложенная конвейерная модель L_S_A_EN превзошла традиционные модели машинного обучения, улавливая сложные нелинейные зависимости между входными признаками и уровнями воды. Высокая прогностическая точность suggests, что модель может быть instrumental в улучшении стратегий управления паводками и эксплуатации водохранилищ.
Однако модель столкнулась с проблемами при прогнозировании резких изменений уровней воды, especially во время экстремальных погодных явлений. Временное несовпадение, особенно на более длительных сроках упреждения, indicated, что дополнительные признаки, связанные с динамикой объема водохранилища или контролируемыми человеком факторами, такие как графики сброса и орошения, могли бы улучшить точность прогнозирования. В будущей работе следует сосредоточиться на включении этих факторов, чтобы устранить эти ограничения и улучшить временную точность прогнозов. Более того, это исследование highlighted влияние различных входных наборов данных на производительность модели. Модели, обученные на краткосрочных наборах данных, показали лучшие результаты, чем модели, обученные на долгосрочных наборах данных. Это suggests, что качество и согласованность входных данных играют significant роль в определении прогностических возможностей моделей машинного обучения.
В целом, это исследование вносит вклад в растущий объем знаний об использовании AutoML в гидрологическом моделировании, предоставляя основу для будущих исследований, aimed to улучшить управление водными ресурсами в реальном времени в сельскохозяйственных водохранилищах.
Ссылки
1. Chen, S.; Johnson, F.; Drummond, C.; Glamore, W. A New Method to Improve the Accuracy of Remotely Sensed Data for Wetland Water Balance Estimates. J. Hydrol. Reg. Stud. 2020, 29, 100689. [Google Scholar] [CrossRef]
2. Ahn, S.R.; Jeong, J.H.; Kim, S.J. Assessing Drought Threats to Agricultural Water Supplies under Climate Change by Combining the SWAT and MODSIM Models for the Geum River Basin, South Korea. Hydrol. Sci. J. 2016, 61, 2740–2753. [Google Scholar] [CrossRef]
3. Van Oldenborgh, G.J.; Van Der Wiel, K.; Sebastian, A.; Singh, R.; Arrighi, J.; Otto, F.; Haustein, K.; Li, S.; Vecchi, G.; Cullen, H. Attribution of Extreme Rainfall from Hurricane Harvey, August 2017. Environ. Res. Lett. 2017, 12, 124009. [Google Scholar] [CrossRef]
4. Fischer, E.M.; Knutti, R. Anthropogenic Contribution to Global Occurrence of Heavy-Precipitation and High-Temperature Extremes. Nat. Clim. Chang. 2015, 5, 560–564. [Google Scholar] [CrossRef]
5. Pearce, W.; Holmberg, K.; Hellsten, I.; Nerlich, B. Climate Change on Twitter: Topics, Communities and Conversations about the 2013 IPCC Working Group 1 Report. PLoS ONE 2014, 9, e94785. [Google Scholar] [CrossRef] [PubMed]
6. Al-Kindi, K.M.; Al Nadhairi, R.; Al Akhzami, S. Dynamic Change in Normalised Vegetation Index (NDVI) from 2015 to 2021 in Dhofar, Southern Oman in Response to the Climate Change. Agriculture 2023, 13, 592. [Google Scholar] [CrossRef]
7. Seo, Y.; Choi, E.; Yeo, W. Reservoir Water Level Forecasting Using Machine Learning Models. J. Korean Soc. Agric. Eng. 2017, 59, 97–110. [Google Scholar] [CrossRef]
8. Üneş, F.; Demirci, M.; Taşar, B.; Kaya, Y.Z.; Varçin, H. Estimating Dam Reservoir Level Fluctuations Using Data-Driven Techniques. Pol. J. Environ. Stud. 2019, 28, 3451–3462. [Google Scholar] [CrossRef]
9. Young, C.-C.; Liu, W.-C.; Hsieh, W.-L. Predicting the Water Level Fluctuation in an Alpine Lake Using Physically Based, Artificial Neural Network, and Time Series Forecasting Models. Math. Probl. Eng. 2015, 2015, 708204. [Google Scholar] [CrossRef]
10. Castillo-Botón, C.; Casillas-Pérez, D.; Casanova-Mateo, C.; Moreno-Saavedra, L.M.; Morales-Díaz, B.; Sanz-Justo, J.; Gutiérrez, P.A.; Salcedo-Sanz, S. Analysis and Prediction of Dammed Water Level in a Hydropower Reservoir Using Machine Learning and Persistence-Based Techniques. Water 2020, 12, 1528. [Google Scholar] [CrossRef]
11. Das, M.; Ghosh, S.K.; Chowdary, V.M.; Saikrishnaveni, A.; Sharma, R.K. A Probabilistic Nonlinear Model for Forecasting Daily Water Level in Reservoir. Water Resour. Manag. 2016, 30, 3107–3122. [Google Scholar] [CrossRef]
12. Ozdemir, S.; Yaqub, M.; Yildirim, S.O. A Systematic Literature Review on Lake Water Level Prediction Models. Environ. Modell. Softw. 2023, 163, 105684. [Google Scholar] [CrossRef]
13. Sapitang, M.; Ridwan, W.M.; Kushiar, K.F.; Ahmed, A.N.; El-Shafie, A. Machine Learning Application in Reservoir Water Level Forecasting for Sustainable Hydropower Generation Strategy. Sustainability 2020, 12, 6121. [Google Scholar] [CrossRef]
14. Li, F.; Ma, G.; Chen, S.; Huang, W. An Ensemble Modeling Approach to Forecast Daily Reservoir Inflow Using Bidirectional Long- and Short-Term Memory (Bi-LSTM), Variational Mode Decomposition (VMD), and Energy Entropy Method. Water Resour. Manage. 2021, 35, 2941–2963. [Google Scholar] [CrossRef]
15. Nguyen, A.D.; Le Nguyen, P.; Vu, V.H.; Pham, Q.V.; Nguyen, V.H.; Ngu yen, M.H.; Nguyen, T.H.; Nguyen, K. Accurate Discharge and Water Level Forecasting Using Ensemble Learning with Genetic Algorithm and Singular Spectrum Analysis-Based Denoising. Sci. Rep. 2022, 12, 19870. [Google Scholar] [CrossRef] [PubMed]
16. Barzegar, R.; Aalami, M.T.; Adamowski, J. Coupling a Hybrid CNN-LSTM Deep Learning Model with a Boundary Corrected Maximal Overlap Discrete Wavelet Transform for Multiscale Lake Water Level Forecasting. J. Hydrol. 2021, 598, 126196. [Google Scholar] [CrossRef]
17. KMA (Korea Meteorological Administration). Final Report on Development of High-Resolution Meteorological Analysis and Prediction Systems for Smart Cities and Prototype Weather-Climate Convergence Technology; KMA: Seoul, Republic of Korea, 2021. [Google Scholar]
18. Olson, R.S.; Bartley, N.; Urbanowicz, R.J.; Moore, J.H. Evaluation of a Tree-Based Pipeline Optimization Tool for Automating Data Science. In Proceedings of the GECCO 2016—Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; Association for Computing Machinery, Inc.: New York, NY, USA, 2016. [Google Scholar]
19. Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. Adv. Neural Inf. Process. Syst. 2015, 28, 2962–2970. [Google Scholar]
20. Wang, C.; Bäck, T.; Hoos, H.H.; Baratchi, M.; Limmer, S.; Olhofer, M. Automated Machine Learning for Short-Term Electric Load Forecasting. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
21. Olson, R.S.; Urbanowicz, R.J.; Andrews, P.C.; Lavender, N.A.; Kidd, L.C.; Moore, J.H. Automating Biomedical Data Science through Tree-Based Pipeline Optimization. In Proceedings of the Applications of Evolutionary Computation: 19th European Conference, EvoApplications 2016, Porto, Portugal, 30 March–1 April 2016. [Google Scholar]
22. Wang, Q.; Wang, S. Machine Learning-Based Water Level Prediction in Lake Erie. Water 2020, 12, 2654. [Google Scholar] [CrossRef]
23. Wong, T.-T.; Yeh, P.-Y. Reliable Accuracy Estimates from K-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
24. Bergmeir, C.; Hyndman, R.J.; Koo, B. A Note on the Validity of Cross-Validation for Evaluating Autoregressive Time Series Prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
25. Lainder, A.D.; Wolfinger, R.D. Forecasting with Gradient Boosted Trees: Augmentation, Tuning, and Cross-Validation Strategies: Winning Solution to the M5 Uncertainty Competition. Int. J. Forecast. 2022, 38, 1426–1433. [Google Scholar] [CrossRef]
26. Liang, C.; Li, H.; Lei, M.; Du, Q. Dongting Lake Water Level Forecast and Its Relationship with the Three Gorges Dam Based on a Long Short-Term Memory Network. Water 2018, 10, 1389. [Google Scholar] [CrossRef]
27. Costa Nogueira, A., Jr.; de Sousa Almeida, J.L.; Auger, G.; Watson, C.D. Reduced Order Modeling of Dynamical Systems Using Artificial Neural Networks Applied to Water Circulation. In Proceedings of the International Conference on High Performance Computing, Frankfurt, Germany, 22–25 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 116–136. [Google Scholar]
28. Cerqueira, V.; Torgo, L.; Soares, C. Machine Learning vs Statistical Methods for Time Series Forecasting: Size Matters. arXiv 2019, arXiv:1909.13316. [Google Scholar]
29. Guo, Y.; Quan, L.; Song, L.; Liang, H. Construction of Rapid Early Warning and Comprehensive Analysis Models for Urban Waterlogging Based on AutoML and Comparison of the Other Three Machine Learning Algorithms. J. Hydrol. 2022, 605, 127367. [Google Scholar] [CrossRef]
30. Ferreira, L.; Pilastri, A.; Martins, C.M.; Pires, P.M.; Cortez, P. A Comparison of AutoML Tools for Machine Learning, Deep Learning and XGBoost. In Proceedings of the International Joint Conference on Neural Networks 2021, Piscataway, NJ, USA, 18–22 July 2021. [Google Scholar] [CrossRef]
31. Santamaria-Bonfil, G.; Arroyo-Figueroa, G.; Zuniga-Garcia, M.A.; Azcarraga Ramos, C.G.; Bassam, A. Power Transformer Fault Detection: A Comparison of Standard Machine Learning and AutoML Approaches. Energies 2023, 17, 77. [Google Scholar] [CrossRef]
32. Tamayo-Vera, D.; Wang, X.; Mesbah, M. A Review of Machine Learning Techniques in Agroclimatic Studies. Agriculture 2024, 14, 481. [Google Scholar] [CrossRef]
33. Azad, A.S.; Sokkalingam, R.; Daud, H.; Adhikary, S.K.; Khurshid, H.; Mazlan, S.N.A.; Rabbani, M.B.A. Water Level Prediction through Hybrid SARIMA and ANN Models Based on Time Series Analysis: Red Hills Reservoir Case Study. Sustainability 2022, 14, 1843. [Google Scholar] [CrossRef]
34. Kusudo, T.; Yamamoto, A.; Kimura, M.; Matsuno, Y. Development and Assessment of Water-Level Prediction Models for Small Reservoirs Using a Deep Learning Algorithm. Water 2021, 14, 55. [Google Scholar] [CrossRef]
35. Jhin, S.Y.; Kim, S.; Park, N. Addressing Prediction Delays in Time Series Forecasting: A Continuous GRU Approach with Derivative Regularization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; ACM: New York, NY, USA, 2024. [Google Scholar]
36. Ty, A.J.A.; Fang, Z.; Gonzalez, R.A.; Rozdeba, P.J.; Abarbanel, H.D.I. Machine Learning of Time Series Using Time-Delay Embedding and Precision Annealing. Neural. Comput. 2019, 31, 2004–2024. [Google Scholar] [CrossRef]

Han J, Bae JH. Developing an Hourly Water Level Prediction Model for Small- and Medium-Sized Agricultural Reservoirs Using AutoML: Case Study of Baekhak Reservoir, South Korea. Agriculture. 2025; 15(1):71. https://doi.org/10.3390/agriculture15010071
Перевод статьи «Developing an Hourly Water Level Prediction Model for Small- and Medium-Sized Agricultural Reservoirs Using AutoML: Case Study of Baekhak Reservoir, South Korea» авторов Han J, Bae JH., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)