AMSformer: модель трансформер для прогноза температуры зерна с адаптивным объединением разномасштабных временных закономерностей
Прогнозирование температуры зерна при хранении играет ключевую роль для безопасности элеватора, позволяя эффективно предотвращать образование плесени и грибка, вызванное повышением температуры зерна, и конденсацию влаги вследствие его охлаждения. Однако существующие методы прогнозирования приводят к избыточности информации при захвате временных и пространственных зависимостей, что снижает точность прогноза. Для решения этой проблемы в данной статье представлена модель трансформера с адаптивным мультимасштабным объединением признаков (AMSformer).
Аннотация
Модель использует механизм адаптивного канального внимания (ACA) для регулировки весов различных каналов в соответствии с характеристиками входных данных, а механизм мультимасштабного внимания (MSA) — для точного захвата временных зависимостей на разных масштабах. Слои ACA и MSA интегрируются с помощью иерархического кодера (HED) для эффективного использования адаптивной мультимасштабной информации, что повышает точность прогнозирования. Эксперименты на реальных данных о температуре зерна и шести публичных наборах данных с сравнением девяти существующих моделей показали, что AMSformer превосходит конкурирующие методы в 36 из 58 тестовых случаев, что подтверждает его преимущества в точности и эффективности.
1. Введение
Китай является самой многонаселенной развивающейся страной в мире, а также крупнейшим в мире производителем, потребителем и импортером продовольствия [1]. На его долю приходится 20% населения мира и менее 9% его пахотных земель [2]. Продовольственное снабжение Китая сталкивается с проблемами из-за ограниченных ресурсов для производства продуктов питания и растущего внутреннего потребления продовольствия. Согласно данным Продовольственной и сельскохозяйственной организации Объединенных Наций (ФАО), потери продовольствия превышают 35 миллиардов килограммов в год, причем наибольшая доля потерь приходится на этап хранения и составляет около 7% [3]. Это означает, что потери зерна на этапе хранения составляют 2,45 миллиарда килограммов, и такие огромные потери оказали серьезное влияние на Китай, значительно увеличив нагрузку на земельные ресурсы. Помимо этого, производство зерна в Китае сталкивается с такими проблемами, как рост затрат на сельскохозяйственное производство, локализация использования водных ресурсов [4] и ограниченность пахотных земель. Для решения этих проблем необходимо сместить акцент с наращивания объемов производства зерна на сокращение его потерь. Сокращение потерь на этапе хранения зерна является одним из наиболее реалистичных и эффективных способов обеспечения продовольственной безопасности Китая [5]. На период хранения зерна наибольшее влияние оказывает температура; слишком низкая температура приведет к явлению конденсации, а слишком высокая температура вызовет быстрое размножение вредителей и плесени, что представляет серьезную угрозу продовольственной безопасности. Поэтому для предотвращения рисков, связанных с хранением зерна, крайне важно заранее прогнозировать изменение температуры в зернохранилище. На китайских элеваторах уже реализован мониторинг температуры зерновых масс в реальном времени за счет размещения массивов датчиков в силосах [6]. Однако прогнозирование будущей тенденции температуры зерна часто relies on the experience of personnel, что может привести к ошибкам в оценке и потенциально cause irreparable consequences для безопасности хранения зерна. Недавние исследования показали перспективные применения моделей агроискусственного интеллекта в точном земледелии, таких как точное орошение, прогнозирование вредителей и болезней и управление ростом crops [7]. Однако эти модели в основном сосредоточены на управлении в полевых условиях, а исследования по интеллектуальному прогнозному моделированию для этапа хранения в зернохранилищах все еще scarce. Для решения этой задачи мы предлагаем AMSformer, который использует структуру трансформера с многомасштабным объединением признаков для решения проблемы избыточности информации при прогнозировании температуры в зернохранилище и повышения обобщающей способности модели. Таким образом, точное прогнозирование температуры зерна имеет crucial importance для обеспечения безопасности его хранения.
В области прогнозирования температуры зерна три проблемы все еще стоят на пути достижения более высокой эффективности и точности прогноза. (1) Существующие модели struggle с эффективным и точным прогнозированием данных с множества датчиков из-за ограничений single output. (2) Большинство моделей упускают из виду пространственную топологию сети датчиков, что ограничивает всестороннее исследование variations температуры в хранящемся зерне. (3) Дискретное распределение датчиков приводит к невозможности построения непрерывного температурного поля, hindering всестороннюю визуализацию. Однако с развитием глубокого обучения было предложено несколько моделей нейронных сетей для прогнозирования температуры хранящегося зерна. Методы на основе трансформера, в частности, показали большой потенциал благодаря своей способности улавливать долгосрочные временные зависимости (trans-temporal dependence) [8]. Помимо trans-temporal зависимости, trans-dimensional зависимость также имеет crucial importance для прогнозирования температуры. То есть для данного измерения информация из связанных рядов в других измерениях может улучшить прогноз. Например, SageFormer использует структуру series perceptual graph для эффективного захвата и моделирования зависимостей между измерениями [9], а Crossformer вводит dimension segmentation (DSW) embedding и two-stage attention layer (TSA) для эффективного захвата cross-temporal и cross-dimensional зависимостей [10]. Однако существующие модели подвержены избыточности информации при захвате cross-time и cross-dimensional зависимостей, в то время как избыточная информация может нарушить процесс обучения модели, ограничивая ее эффективность в практических приложениях и снижая точность прогнозов.
Для решения упомянутых выше проблем в данной статье предлагается модель AMSformer, которая явно использует cross-dimensional зависимости и mitigates избыточную информацию в каналах. Мы разрабатываем механизм adaptive channel attention (ACA) на основе DSW embedding, который подавляет информацию нерелевантных каналов и снижает внимание модели к избыточной информации. Затем мы предлагаем механизм multi-scale attention (MSA), который может гибко адаптироваться к изменениям на разных временных масштабах в данных временных рядов. Будь то долгосрочный тренд, сезонные изменения или краткосрочные колебания, MSA может эффективно захватывать важные features в данных, thus повышая точность прогноза. Вклад данной статьи заключается в следующем:
(1) В данной статье глубоко исследуются существующие варианты прогнозирования температуры на основе трансформера и обнаруживается, что эти модели привносят избыточную информацию при использовании cross-dimensional зависимостей, что, если не handled, может повлиять на точность прогнозирования температуры зерна.
(2) Разработаны механизм adaptive channel attention и механизм multi-scale attention. Первый способен адаптивно регулировать веса различных каналов в соответствии с характеристиками входных данных, одновременно подавляя нерелевантные или избыточные каналы. Второй используется для более точного захвата cross-time зависимостей, и путем вычисления внимания на разных временных масштабах модель способна более comprehensively понимать features и структуры в данных, thus повышая точность и обобщающую способность прогноза.
(3) Мы используем hierarchical encoder для feature-объединения механизма adaptive channel attention и механизма multi-scale attention, что реализует эффективное использование адаптивной многомасштабной информации. Результаты экспериментов показывают, что наша модель достигает state-of-the-art производительности как на реальных, так и на синтетических наборах данных.
2. Обзор литературы
В данной статье рассматриваются предыдущие модели прогнозирования температуры хранения, а также модели прогнозирования многовариантных временных рядов. Чтобы подробно описать преимущества AMSformer для прогнозирования температуры хранения, в этом разделе кратко описаны основные особенности каждого метода, примеры реализации, а также сильные и слабые стороны ключевых выводов.
Модели прогнозирования температуры можно broadly разделить на статистические модели и модели нейронных сетей. Статистические модели можно categorized в модели векторной авторегрессии (VAR) [11] и модели векторной авторегрессии скользящего среднего (VARMA), которые предполагают линейную зависимость между переменными и линейный прогноз по прошлым значениям этой переменной и других переменных. Однако с увеличением объема данных глубокое обучение показывает более высокую производительность, чем статистические модели [12]. Например, Ge et al. использовали multiple convolutional kernels с shared weights на основе сверточных нейронных сетей (CNN) для захвата температурных features в разных locations [13], fully используя температурную информацию вокруг целевой точки. Qu et al. combined multiple outputs и spatiotemporal modeling с graph convolutional networks (GCN) и transformers [14], где GCN захватывали spatial correlation датчиков в зернохранилище и сенсорной сети, а transformers захватывали долгосрочные и краткосрочные временные features и описывали temporal dependencies. Mao et al. предложили алгоритмы прогнозирования температуры с gated recurrent units (GRU) и multivariate linear regression (MLP), а также техники wavelet filtering [15], которые efficiently deal with проблемой разреженности данных и шума. Видно, что на температуру хранения зерна влияет множество complex intertwined факторов. Для достижения более точного прогнозирования температуры мы можем умело использовать модель прогнозирования многовариантных временных рядов. Этот метод может comprehensively рассматривать dynamic relationship множественных переменных во времени, чтобы более comprehensively grasp тенденцию температуры хранения зерна и повысить точность прогноза.
Прогнозирование многовариантных временных рядов (MTS), также известное как multivariate time prediction, focuses на наличии multiple time-dependent переменных в системе. Fan et al. combine temporal convolutional networks (TCN) с spatio-temporal attention механизмами для захвата spatial и temporal зависимостей [16]. Jiang et al. decomposed временные ряды на temporal и spatial члены для интеграции global и local multivariate информации [17]. Li et al. modeled topological relationships между instances с использованием модели BERT и attention механизма [18]. Jin et al. combined graph neural networks (GNN) и attention механизмы для захвата spatial зависимостей через hierarchical signal decomposition на графах [19]. Lu et al. предложили complementary time series (CATS), которые генерируют complementary временные ряды из исходных временных рядов и объединяют relationships между рядами для прогнозирования [20]. Miao et al. designed a progressive quadratic decomposition architecture для извлечения patterns временных рядов, learning для представления spatial topology через graph structure, и gating augmented representation ввода в GNNML для интеграции temporal и spatial информации [21]. Guo et al. предложили matrix attention механизм, который constructs frequency domain модуль и time domain модуль с equal weighting предыдущих точек данных для захвата local dynamics и long-term change patterns, соответственно [22]. Wang et al. utilized две self-attention стратегии, spatial и temporal self-attention, чтобы focuses на наиболее relevant информации во временном ряду, первая для discovery зависимостей между переменными, а вторая для захвата relationships между историческими наблюдениями [23]. Эти модели захватывают как temporal, так и dimensional зависимости, но не принимают во внимание тот факт, что dimensional зависимости уже потенциально включают влияние исторических данных, что может повлиять на точность прогнозов MTS.
В то время как трансформеры широко используются в обработке естественного языка (NLP), компьютерном зрении (CV) и обработке речи, варианты на основе модели трансформера для прогнозирования MTS показывают большой потенциал. Informer [24] использует sparsity оценок внимания через оценку KL расхождения и предлагает ProbSparse self-attention и distillation техники. Autoformer [25] renovates трансформеры в deep decomposition архитектуру и concatenates autocorrelation механизмы. Pyraformer [26] предлагает pyramid attention модуль для достижения linear времени и space сложности. FEDformer [27] утверждает, что временные ряды имеют sparse представление в frequency domain и предлагает frequency domain augmentation структуры. Preformer [28] делит embedded feature векторную последовательность на multiple сегменты и использует segment-based correlation attention для прогнозирования. STFormer [29] combines two-stage трансформер, который захватывает spatio-temporal relationships и решает проблему шума, и adaptive spatio-temporal graph структуру, которая решает проблему неупорядоченных данных. Эти модели в основном focuses на захвате temporal зависимостей и spatial зависимостей, часто ignoring избыточность информации между spatio-temporal зависимостями. В отличие от вышеупомянутых подходов, мы предлагаем AMSformer, который использует adaptive channels и multi-scale feature fusion для подавления избыточных каналов и более точного захвата cross-scale зависимостей.
3. Методология
В прогнозировании температуры хранения зерна обозначение предполагает прошлые 1-T временные шаги наборов температурных данных, которые мы aim предсказать, где τ обозначает будущий временной шаг, который нужно предсказать, T обозначает прошлый временной шаг, а D обозначает размерность данных. Чтобы использовать cross-dimensional зависимость и уменьшить влияние избыточности информации, мы вносим следующий вклад: в разделе 3.1 мы собираем данные о температуре и влажности, а также о температуре и влажности воздуха внутри силоса, размещая температурные кабели и датчики температуры и влажности внутри силоса, и мы получаем доступ к этим данным через centralized систему сбора данных для обработки, чтобы удалить выбросы и пропущенные значения. Обработанные данные сохраняются в базе данных для построения набора данных для прогнозирования температуры зерна. В разделе 3.2 механизм adaptive channel attention (ACA) используется для извлечения global features, захвата global зависимостей между каналами и снижения информационной избыточности. В разделе 3.3 предлагается multi-scale attention слой (MSA) для захвата multi-level информации для эффективного захвата зависимостей между различными временными измерениями. В разделе 3.4 строится hierarchical encoder–decoder модуль с использованием механизма ACA и слоя MSA для интеграции features с разных масштабов с целью генерации итоговой выходной последовательности.
3.1. Наборы данных
Размеры зернохранилища, участвующего в данном исследовании, составляют 42 м в длину и 24 м в ширину, высота линии отвала зерна составляет 6 м, а общая вместимость силоса — 4838,4 тонны. Компоновка кабелей состоит из 10 колонн и 6 рядов, с 7 слоями датчиков в каждой строке и столбце, а общее количество кабелей неизвестно. Стандарт заглубления линии датчиков составляет 0,5 м от стены; верхний датчик находится на расстоянии 0,5 м от поверхности зерна; расстояние между колоннами датчиков составляет 4,56 м; расстояние между рядами составляет 4,6 м; а высота слоя составляет 0,78 м. Распределение температурных кабелей показано на Рисунке 1.
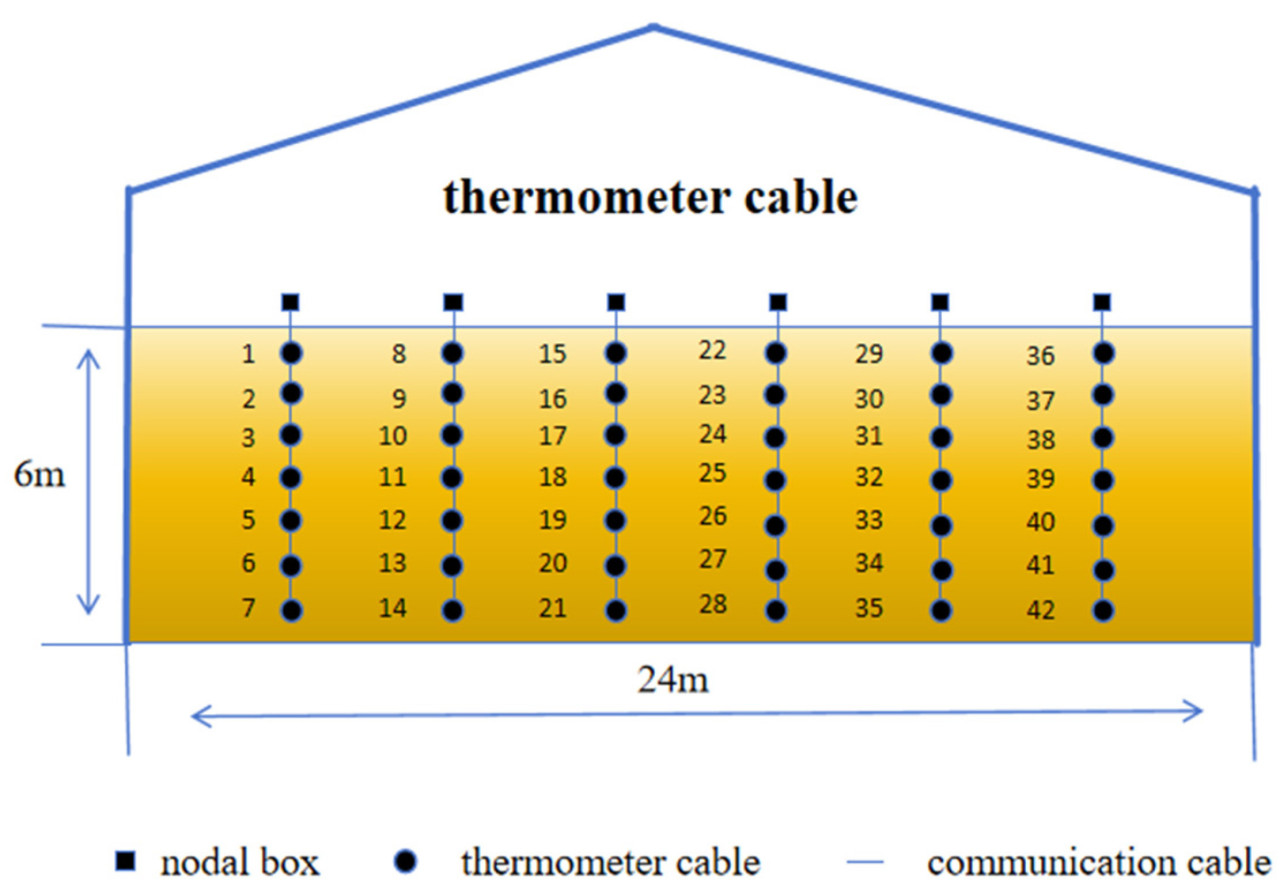
Рисунок 1. В зернохранилище данные о температуре с 420 датчиков собирались в течение временного промежутка в 365 дней, с 1 января 2021 года по 31 декабря 2021 года, причем каждый датчик собирал 6 точек данных в день, в общей сложности за одну сессию сбора данных. Сбор данных датчиками может привести к проблеме пропущенных данных, потому что тенденция данных о температуре хранения зерна является relatively плавной. Предполагается, что точки данных до и после пропущенных значений имеют линейную зависимость, и пропущенные значения оцениваются с использованием линейных уравнений для интерполяции пропущенных данных и корректировки аномальных данных. Данные с 42 датчиков в одном из поперечных сечений, а также температура в бункере, влажность в бункере, температура воздуха, влажность воздуха и другие данные выбираются для интеграции, и окончательный размер тензора представляет 46 датчиков, собирающих 6 точек данных в день в течение 365 дней, в конечном итоге получая собственный набор данных.
3.2. Адаптивное канальное внимание (Adaptive Channel Attention)
Чтобы обосновать наш подход, мы сначала анализируем методы embedding ранее использовавшихся трансформер-моделей для прогнозирования MTS. Informer и autoformer, среди others, embed точки данных одного и того же временного шага в вектор:
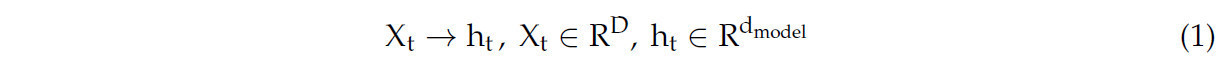
где Xt обозначает все точки данных в D-измерении с размером шага t. Таким образом, входы X1:T embedded в t-векторы {h1, h2, …; hT}. Зависимости между t-векторами затем захватываются для прогнозирования, в то время как cross-dimensional зависимости явно не захватываются во время embedding, что ограничивает их прогностическую силу. Crossformer предложил dimensional segmentation embedding, где nearby точки на каждом измерении делятся на сегменты длиной L, а затем embedded в следующее:
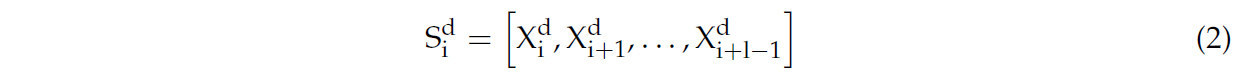
где Sdi — это i-й сегмент длины 1 в измерении d. Каждый сегмент затем embedded в вектор: hi = W si + b с использованием linear projection и positional embedding. Получается двумерный массив векторов, где hi обозначает одномерный сегмент временного ряда, явно захватывая cross-dimensional зависимости. Однако данные разных измерений также могут вносить информационную избыточность. Чтобы решить эту проблему, мы предлагаем механизм adaptive channel attention (ACA), который aims автоматически обучать и регулировать веса различных каналов на основе характеристик входных данных, чтобы более эффективно захватывать и использовать важные features в данных. Этот механизм внимания позволяет модели динамически регулировать веса каналов при работе с разными образцами, что улучшает репрезентативную и обобщающую производительность модели.

где WO — выходная весовая матрица. Наконец, выход внимания используется в качестве входа для dimensional segmented embedding (DSW), получая двумерный массив векторов. Иллюстративная архитектура механизма адаптивного канального внимания показана на Рисунке 2.
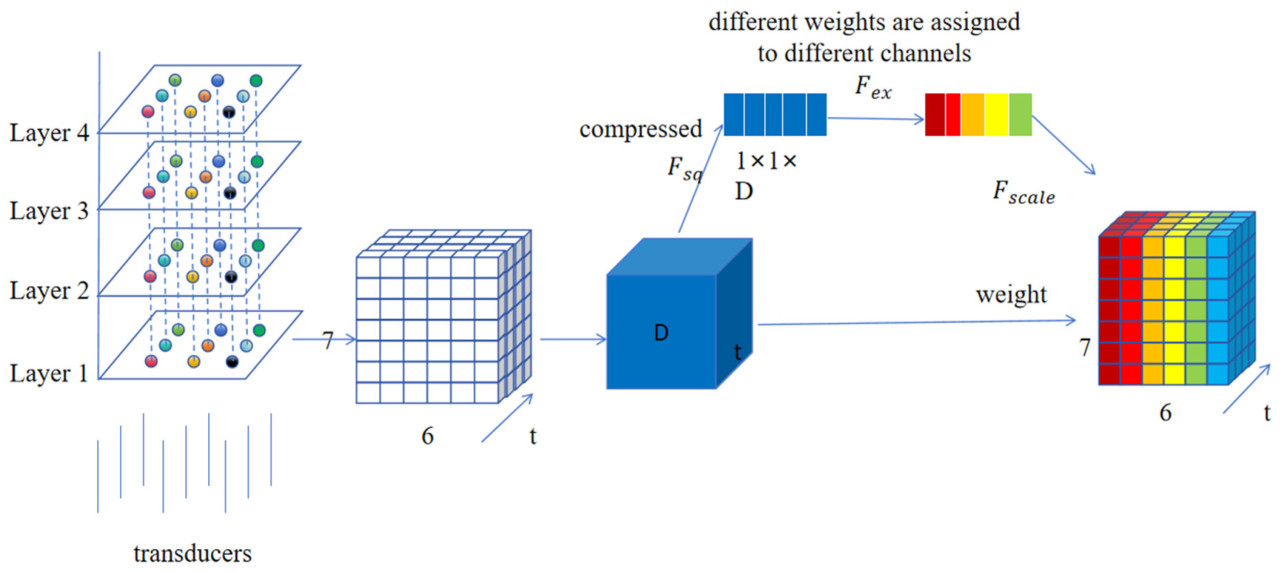
Рисунок 2. Левая часть этого рисунка показывает позиционное relationship между датчиками. Данные о температуре хранимого зерна, собранные датчиками, и пространственная информация данных используются как входные features, затем global пространственная информация входных features сжимается. После сжатия excitation часть входных features learns размерности каналов и получает веса отдельных каналов; наконец, входные features умножаются на веса, чтобы получить окончательную выходную feature карту.
3.3. Механизмы многомасштабного внимания (Multi-Scale Attention)
Выходом dimensional segmented embedding являются multiple одномерные сегменты временных рядов, обозначенные как H: H ∈ Ri×d, где i — количество временных шагов, а d — выходное измерение размерного сегментированного встраивания. Следует учитывать, что шаблоны временных рядов для прогнозирования температуры хранения часто содержат несколько различных временных масштабов, таких как суточные, недельные, месячные и другие, зависящие от цикла шаблоны.
Для представления признаков в каждом временном масштабе применяется механизм множественного внимания. Предположим, что на s-м масштабе находится головка внимания. Для головки внимания h на s-м масштабе веса внимания рассчитываются следующим образом:

Иллюстративная архитектура механизма многомасштабного внимания показана на Рисунке 3.
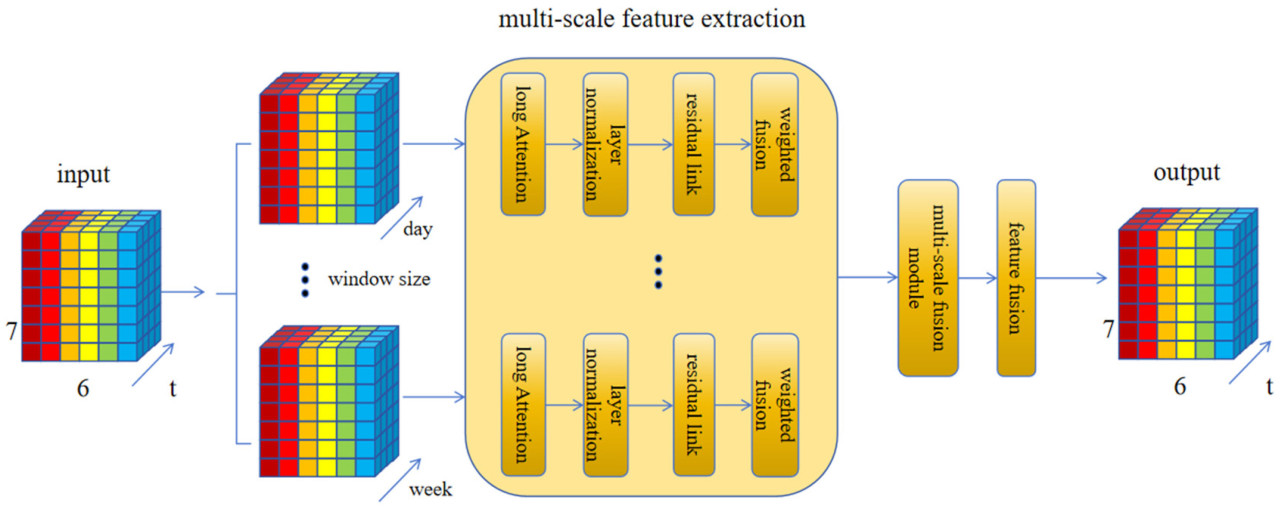
Рисунок 3. Архитектура механизма многомасштабного внимания для анализа временных рядов, которая содержит механизм multi-head внимания, residual connections, layer normalization и multi-scale fusion модуль, aims эффективно захватывать и обрабатывать информацию в данных временных рядов. Сначала входные данные формируются как (batch_size, time_steps, input_dim), и каждый временной шаг содержит multiple features. Затем выполняется multi-scale feature extraction через разные временные окна (например, 1 день, 1 неделя и 1 месяц); затем применяется механизм multi-head внимания для вычисления веса важности каждого временного масштаба, и конкретные шаги включают mapping входных features как query (Q), key (K) и value (V) векторы, вычисление весов внимания и выполнение weighted summation. Затем на выходе многоголовочного механизма внимания выполняется нормализация слоев для повышения стабильности обучения модели. Остаточные связи добавляются между входом многоголовочного механизма внимания и выходом нормализации слоев, чтобы предотвратить исчезновение градиента. Взвешенное суммирование выполняется для признаков на каждой временной шкале в соответствии с весами внимания, чтобы обеспечить эффективную интеграцию признаков. Сшивание и обработка взвешенных объединённых признаков на всех временных шкалах выполняется с помощью модуля многомасштабного слияния для формирования комплексного представления признаков. Дальнейшая обработка выходных данных модуля многомасштабного слияния выполняется с помощью слоя слияния признаков для формирования окончательного представления признаков.
3.4. Иерархический энкодер-декодер (Hierarchical Encoder–Decoder)
В layered энкодере мы focuses на том, как эффективно интегрировать adaptive channel attention (ACA) и multi-scale attention (MSA) слои. При интеграции слоев ACA и MSA мы разрабатываем эффективную стратегию, которая позволяет им работать together и fully использовать их соответствующие преимущества. Сначала применяется слой ACA для захвата channel correlations во входных данных, затем выход ACA используется как вход для слоя MSA. Это позволяет слою MSA лучше понимать multi-scale features входных данных, thus улучшая characterization способность модели. Конкретная архитектура hierarchical энкодера designed как последовательность stacked модулей, каждый из которых содержит слой ACA и слой MSA. Такая архитектура enables feature extraction входных данных на multiple уровнях и эффективно интегрирует информацию из слоев ACA и MSA.
Конкретно, каждый модуль может содержать следующие шаги: adaptive channel attention (ACA) слой: используется для захвата channel correlations во входных данных и взвешивания важной информации между каналами для улучшения understanding модели входных данных; multi-scale attention (MSA) слой: использует выход adaptive channel attention слоя как вход для захвата feature информации в different times через механизм multi-head внимания для достижения effective fusion и interaction features на разных масштабах. Residual connection и layer normalization: для enhancement распространения градиента и training эффекта модели, residual connection и layer normalization операции могут быть добавлены в каждый модуль для улучшения stability и скорости сходимости модели.
Через hierarchical encoder–decoder (HED) структуру в hierarchical энкодере мы можем realize effective использование адаптивной многомасштабной информации. Конкретно, слой ACA может помочь модели автоматически обучать channel correlations во входных данных, что делает модель более внимательной к важным feature каналам, в то время как слой MSA может захватывать correlations features на разных масштабах, promoting effective fusion feature информации. Через эту комбинацию модель способна лучше понимать feature структуру входных данных и достигать лучшей производительности в задачах прогнозирования. Иллюстративная архитектура layered энкодера показана на Рисунке 4.
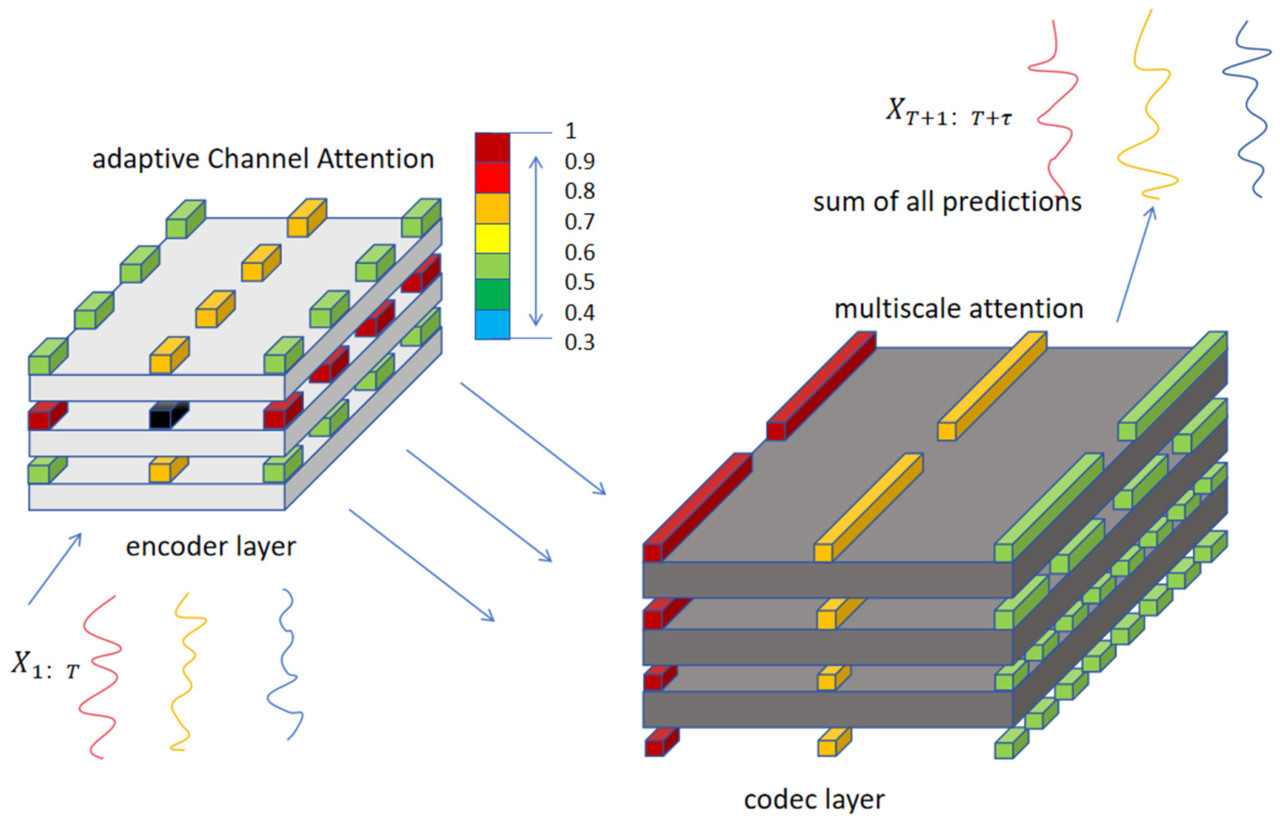
Рисунок 4. Иерархический энкодер интегрирует адаптивное канальное внимание и многомасштабное внимание. Входные исторические температурные данные фильтруются для important каналов с помощью adaptive channel attention, затем используется механизм multi-scale внимания для захвата зависимостей между different временными масштабами, и полученные результаты суммируются для получения окончательного выхода.
4. Эксперименты
4.1. Пространственный и временной корреляционный анализ
Во временном измерении автокорреляционная функция используется для измерения корреляции временных рядов при разных временных лагах и определения того, как один временной ряд влияет на другой. Для набора данных временных рядов автокорреляционные коэффициенты для интервалов рассчитываются следующим образом:
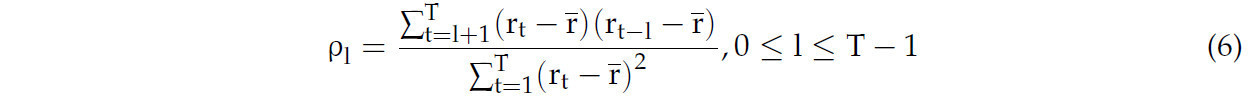
Это уравнение используется для расчета коэффициента автокорреляции, соответствующего данным о температуре для каждого слоя с разным временем запаздывания. На Рисунке 5, по мере увеличения времени лага, наблюдается, что автокорреляционный коэффициент decreases at a relatively медленной скорости от 1 до 0. Поскольку шесть точек данных собираются в день, можно видеть, что этот эффект gradually decreases до нуля в течение периода более трех месяцев, в это время seasonal эффекты играют доминирующую роль, с different сезонами, отрицательно коррелирующими друг с другом.
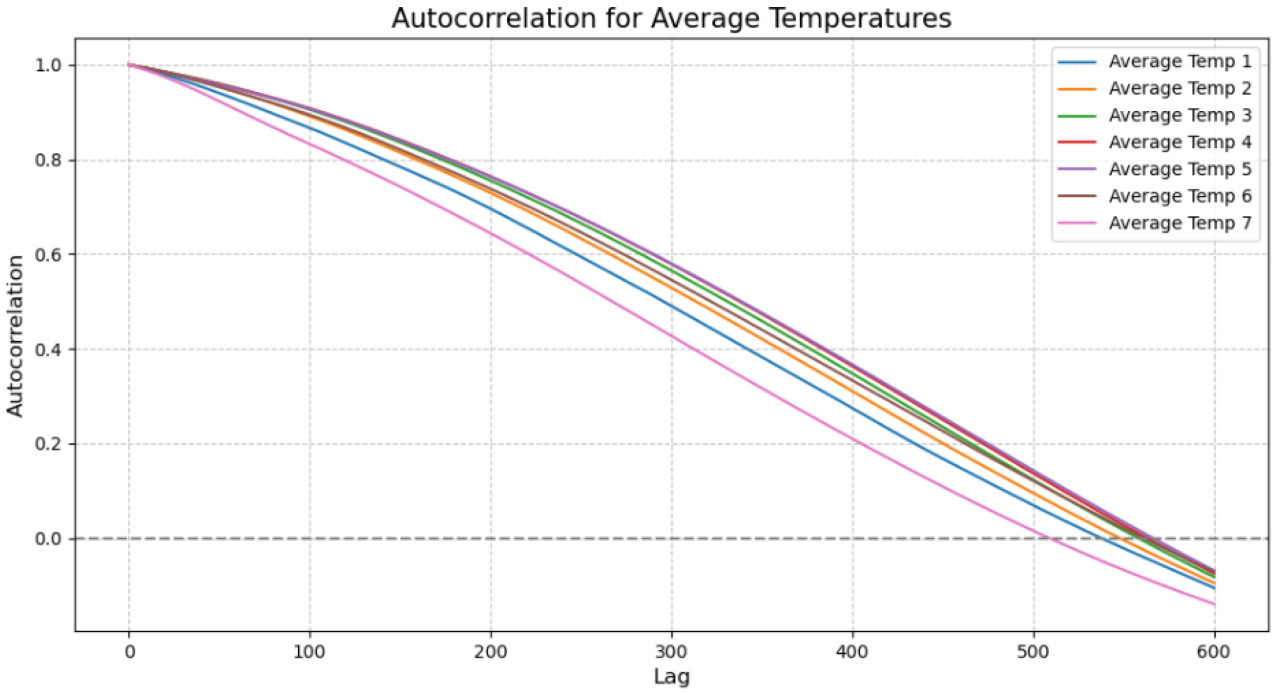
Рисунок 5. Анализ временной корреляции. Ось Y — это автокорреляционный коэффициент, который stronger, чем closer к 1, и weaker, чем closer к 0, а ось X — это изменение времени.
В пространственном измерении глобальный индекс Морана используется для оценки корреляции между пространственно-смежными регионами, чтобы объяснить, что значение переменной региона определяется не только его собственными характеристиками, но и влиянием соседних регионов. Индекс Морана I > 0 указывает на положительную пространственную корреляцию, и чем больше значение, тем сильнее пространственная корреляция. Формула выглядит следующим образом:
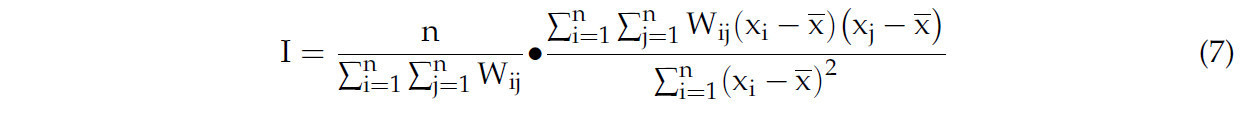
где n обозначает количество разделенных подрегионов, xi и хj – значения температуры датчиков i и j, x – среднее значение температур всех подрегионов, а W — весовая матрица окрестностей датчика. W значения 0 и 1 указывают на то, отключён ли датчик. После построения системы координат тепловая карта корреляции показана на рисунке 6.
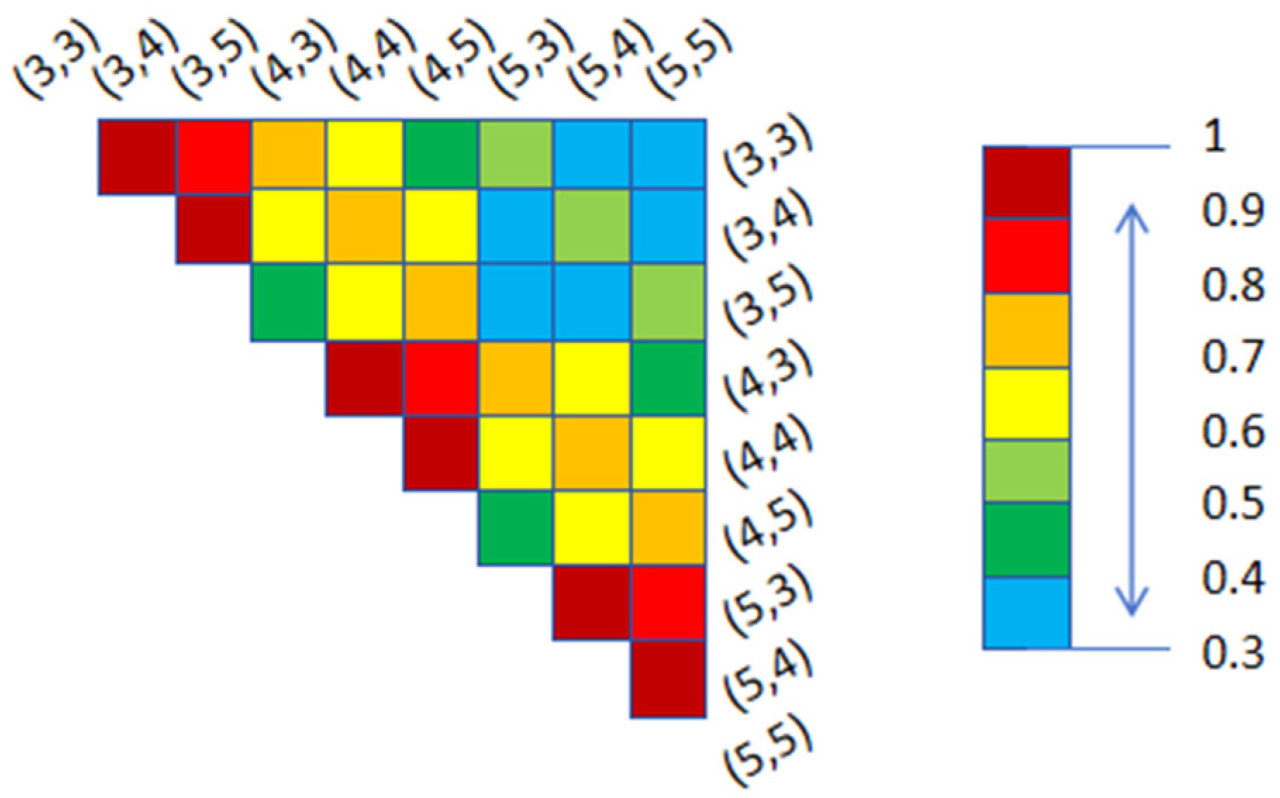
Рисунок 6. Результаты, показанные на рисунке выше, иллюстрируют, что пространственная корреляция отрицательно коррелирует с расстоянием между датчиками, и корреляция между (3,3) и (3,4) сильнее, чем корреляция между (3,3) и (4,3). Существует относительно слабая корреляция между слоями. Из этого можно получить, что разница температур в горизонтальном направлении меньше, а разница температур в вертикальном направлении больше. В заключение, приведенный выше анализ проверяет пространственную корреляцию между температурами.
4.2. Экспериментальная установка и результаты
Набор данных разделен на обучающий набор, набор проверки и тестовый набор с коэффициентом разделения 0.7:0.1:0.2. Размерность скрытого слоя установлена на 256, количество multiple notes установлено на 4, длина сегмента установлена на 6, длина входа равна T, длина выхода равна τ, а размер окна установлен на 2. Обучение проводится с использованием оптимизатора Adam, с размером пакета (batch size), установленным на 32, количество тренировочных раундов установлено на 20, а скорость обучения установлена на 1 × 10^(-4). Процесс обучения останавливается досрочно, если потери на проверке (validation loss) не уменьшаются в течение трех циклов. Мы используем среднюю квадратичную ошибку (MSE) и среднюю абсолютную ошибку (MAE) в качестве метрик оценки, и все эксперименты повторяются пять раз, при этом среднее значение пяти экспериментов используется в качестве отчетной метрики. Диапазон ошибок также был установлен, и чтобы было легче понять диапазон ошибок, мы использовали квадратный корень из MSE, RMSE. Величина RMSE была согласована с исходными данными. Результаты для разных прогнозируемых длин для конкретного датчика в зернохранилище показаны на Рисунке 7, где ось Y указана в градусах Цельсия, а True и Pred представляют фактическую и прогнозируемую температуры соответственно.
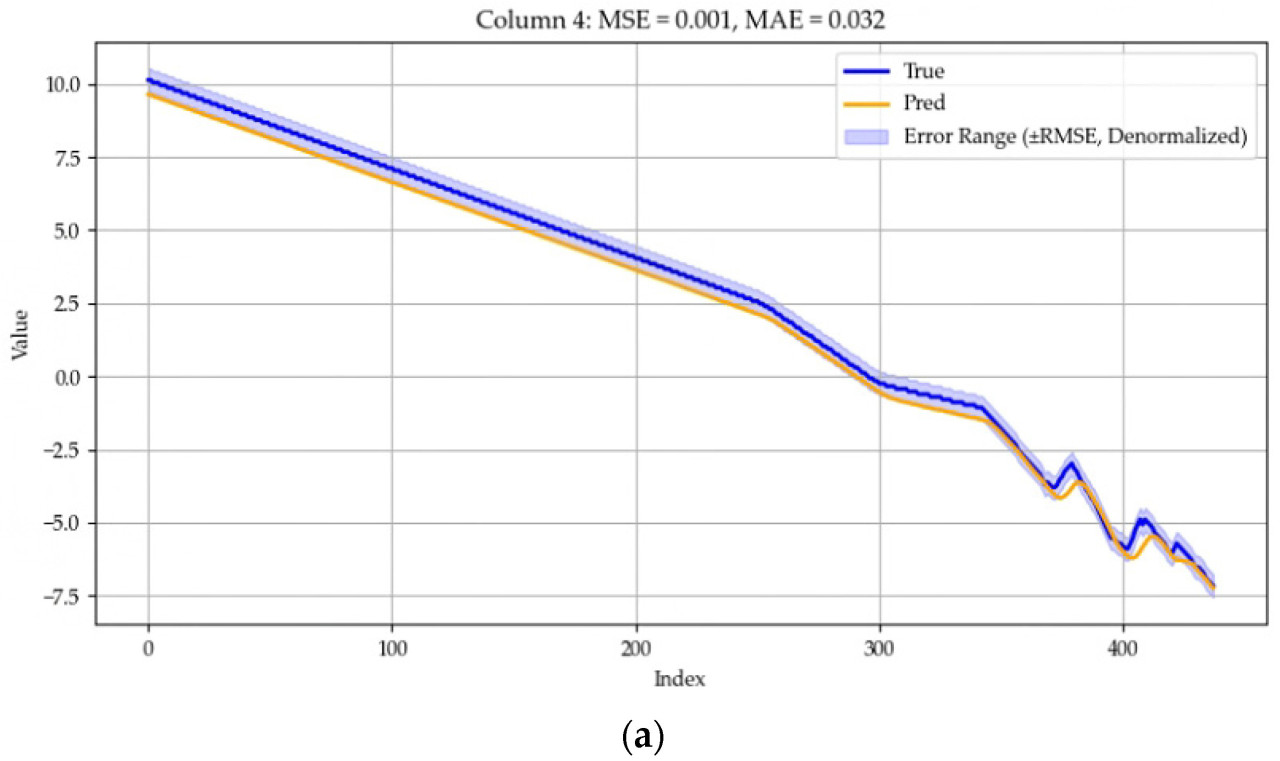
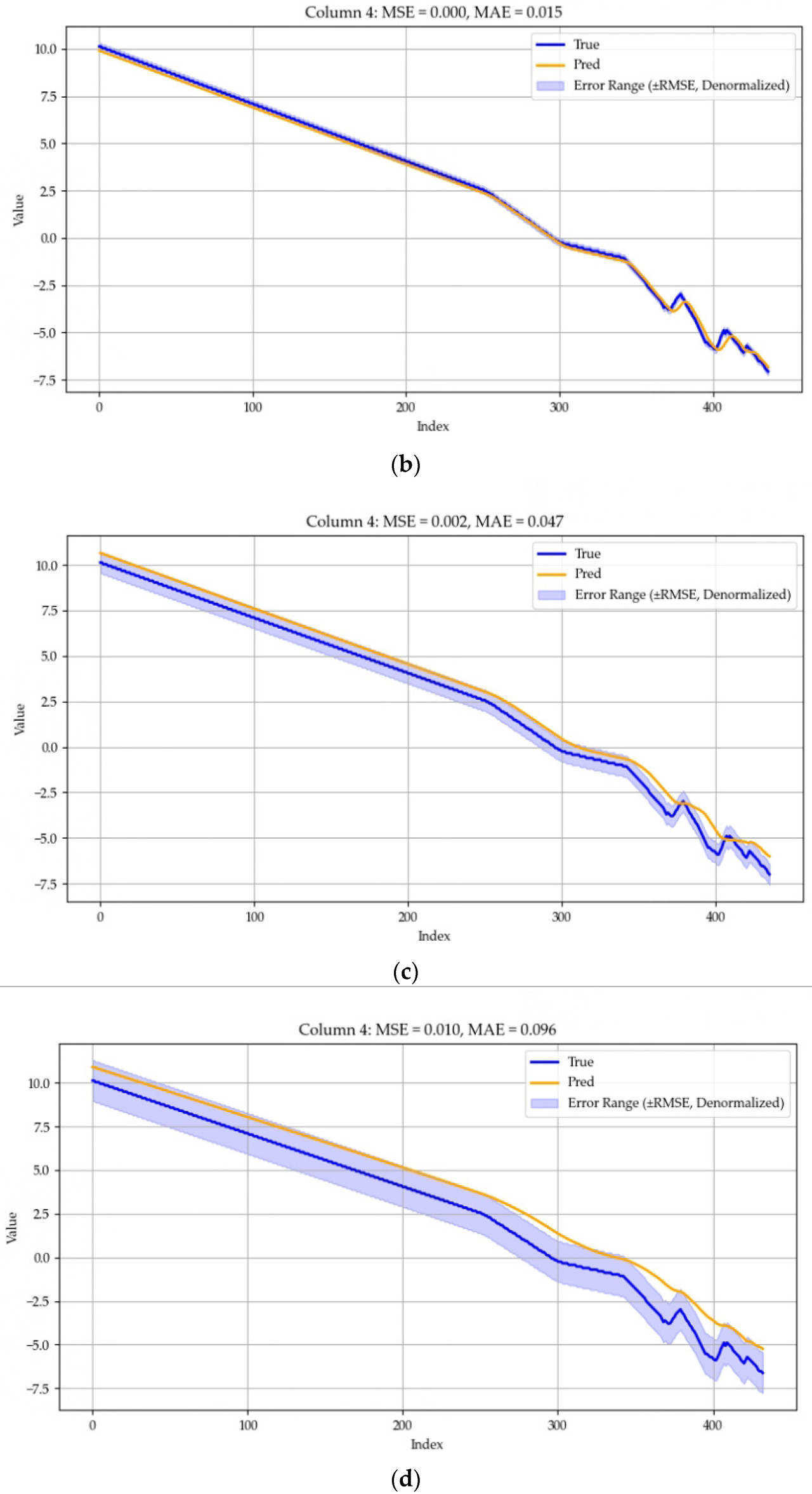
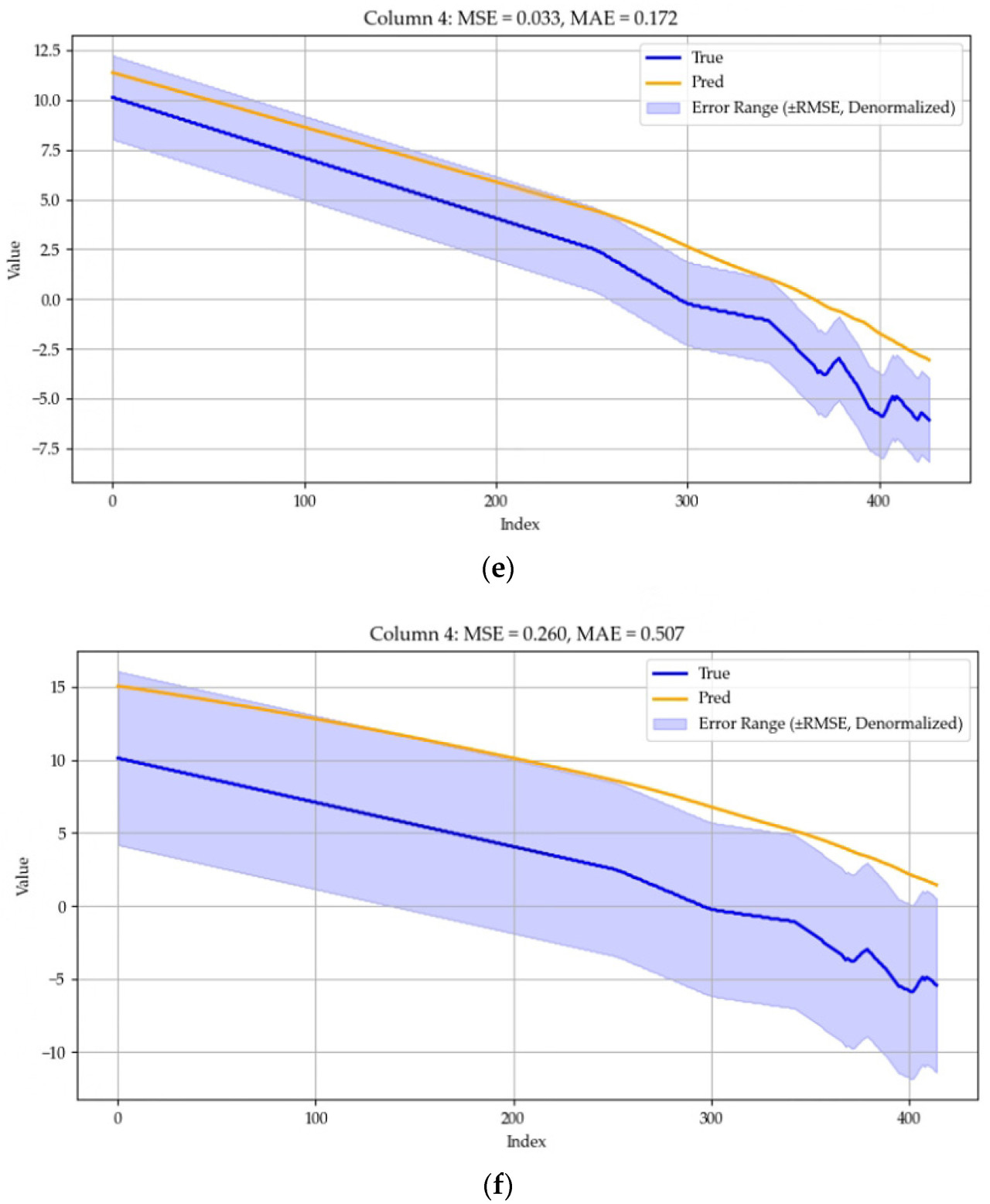
Рисунок 7. (a) Прогнозирование следующей 1 точки данных, MSE составляет 0.001, а MAE составляет 0.032. (b) Прогнозирование следующих 2 точек данных, MSE составляет 0.000, а MAE составляет 0.015. (c) Прогнозирование следующих 3 точек данных, MSE составляет 0.002, а MAE составляет 0.047. (d) Прогнозирование следующих 6 точек данных, MSE составляет 0.010, а MAE составляет 0.096. (e) Прогнозирование следующих 12 точек данных, MSE составляет 0.033, а MAE составляет 0.172. (f) Прогнозирование следующих 24 точек данных, MSE составляет 0.260, а MAE составляет 0.507.
4.3. Сравнительный анализ экспериментов
Мы выбрали шесть общедоступных наборов данных для проверки модели, представленной в этой статье: 1. ETTh1 (температура силового трансформатора — почасовой); 2. ETTm1 (температура силового трансформатора — поминутный); 3. WTH (погода); 4. ECL (нагрузка потребления электроэнергии); 5. ILI (гриппоподобное заболевание); 6. трафик. Эти наборы данных были выбраны для всесторонней оценки производительности модели AMSformer на различных типах данных временных рядов, включая высокочастотные данные, сезонные вариации и совместные прогнозы многомерных данных. Первые четыре набора данных имеют то же разделение tra/val/test, что и в informer, а последние два набора данных разделены в соответствии с соотношением autoformer 0.7:0.1:0.2. Это соотношение разделения широко используется в задачах прогнозирования временных рядов и может гарантировать, что модель может использовать достаточное количество исторических данных во время обучения, одновременно обеспечивая независимость наборов проверки и тестирования, чтобы избежать переобучения. Во время обучения модели AMSformer мы использовали поиск по сетке (grid search) для настройки ключевых гиперпараметров, чтобы обеспечить оптимальную производительность модели на разных наборах данных. Ниже приведены ключевые гиперпараметры, которые мы настраивали: 1. Скорость обучения (Learning rate): Мы тестировали разные скорости обучения, чтобы найти оптимальное значение, которое минимизирует потери в процессе обучения. Мы выбрали диапазон [1 × 10−3, 5 × 10−4, 1 ×10−4, 5 ×10−5] и выбрали оптимальную скорость обучения на основе производительности на наборе проверки. 2. Размерности скрытого слоя (Hidden layer dimensions): мы пробовали разные размерности скрытых слоев (например, 64, 128, 256) и оценивали влияние каждой настройки на производительность модели через набор проверки. 3. Размеры пакетов (Batch sizes): мы пробовали разные размеры пакетов (например, 16, 32, 64) и, в конечном итоге, выбрали размер пакета 32, так как это показало оптимальную производительность в большинстве экспериментов. 4. Количество голов много-голового внимания (Number of multi-head attention heads): Мы выбрали разное количество голов [2,4,8] и adjusted размерность много-голового внимания для оптимизации процесса извлечения информации. После проверки четыре головы были выбраны в качестве оптимальной конфигурации.
Мы выполнили multiple раундов тестирования на наборе проверки через поиск по сетке в combination с перекрестной проверкой (cross-validation) для выбора оптимальной комбинации гиперпараметров. Для каждого набора данных мы провели пять экспериментов, вычислили средние метрики производительности (например, MSE и MAE) для каждого эксперимента и, наконец, выбрали комбинацию гиперпараметров с наименьшей ошибкой проверки.
Мы используем следующие популярные модели прогнозирования MTS в качестве базовых линий (baselines): LSTMa [30], LSTNet, MTGNN [31], transformer, informer, autoformer, pyraformer, FEDformer и crossformer. Мы используем ту же настройку, что и выше, с теми же установками: наборы для обучения/проверки/тестирования нормализованы с использованием среднего значения и стандартного отклонения обучающего набора для zero-mean нормализации. На каждом наборе данных мы оценивали производительность при изменении размера будущего окна τ и использовали среднюю квадратичную ошибку (MSE) и среднюю абсолютную ошибку (MAE) в качестве метрик оценки.
Как показано в Таблице 1, наша модель показала leading производительность на большинстве наборов данных, а также при различных настройках длины прогноза, с оптимальными результатами в 36 из общего числа 58 случаев. В наборе данных ETTh1 AMSformer прогнозирует сезонные и трендовые изменения более точно, чем другие модели, такие как LSTM, за счет более эффективного захвата корреляции многомерных данных временных рядов. В задаче прогнозирования на 24 часа в наборе данных WTH AMSformer точно захватывает дневные колебания температуры через MSA, в то время как традиционный трансформер мог упустить некоторые важные features. В наборе данных о трафике AMSformer превосходит pyraformer и FEDformer в cross-level слиянии информации. Набор данных ILI имеет небольшой объем данных и слабые временные features, что вызывает, что механизм многомасштабного внимания AMSformer и механизм канального внимания не могут fully проявить свои преимущества. Помимо этого, наша модель generally превосходит другие базовые линии в краткосрочном прогнозировании.
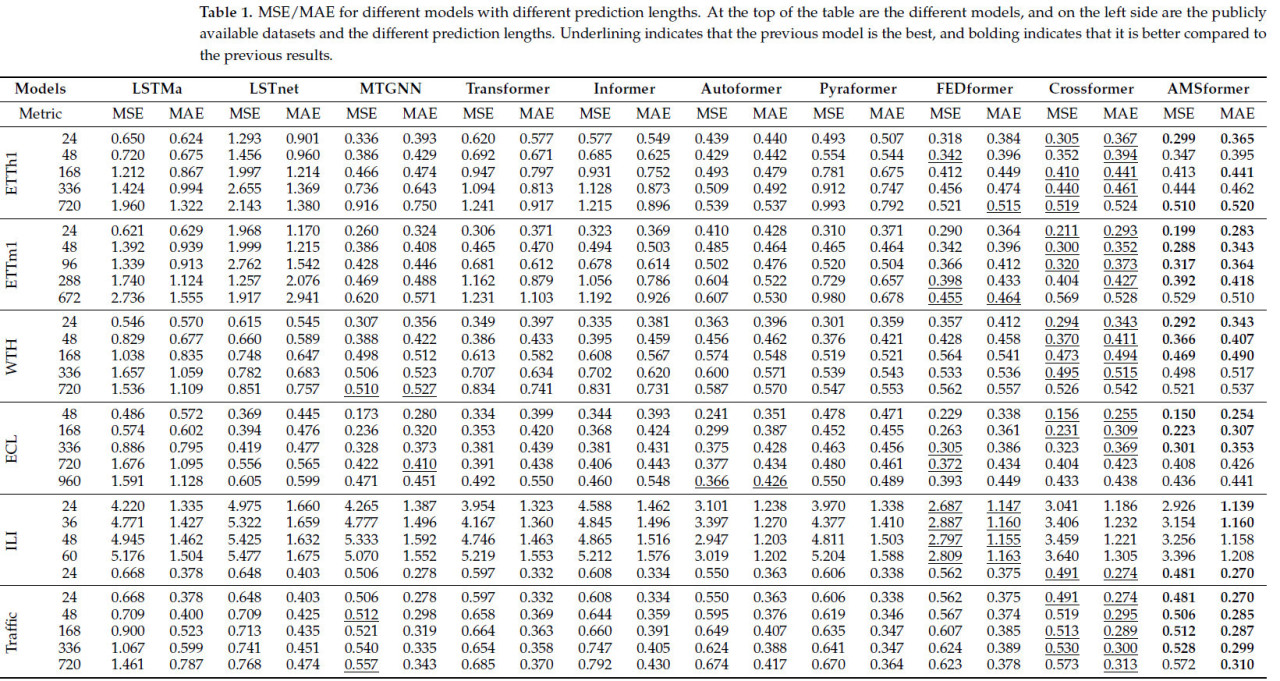
Таблица 1. MSE/MAE для разных моделей с разными длинами прогноза. В верхней части таблицы представлены различные модели, а слева — общедоступные наборы данных и различные длины прогноза. Подчеркивание indicates, что предыдущая модель является лучшей, а выделение жирным шрифтом indicates, что она лучше по сравнению с предыдущими результатами.
4.4. Абляционный эксперимент (Ablation Experiment)
В нашем подходе есть три компонента: слой ACA, слой MSA и HED. Мы используем трансформер в качестве базовой линии (baseline) для сравнения двух абляционных версий: (1) ACA, (2) MSA, (3) ACA + MSA.
Мы анализируем результаты, показанные в Таблице 2. (1) Когда сохраняется только слой ACA, модель способна захватывать local контекстную информацию. Слой ACA в основном усиливает механизм local внимания, что делает модель превосходящей базовый трансформер до определенной степени, но его общее усиление производительности limited из-за отсутствия поддержки multi-scale агрегации информации и hierarchical декодирования. (2) Когда сохраняется только слой MSA, модель способна агрегировать информацию на разных масштабах, усиливая способность понимать global контекст. Хотя слой MSA улучшает агрегацию multi-scale информации, без local контекстной агрегации слоя ACA и hierarchical декодирования HED, модель все еще имеет limited усиление производительности. (3) С добавлением слоя MSA к слою ACA, модель способна захватывать local контекстную информацию, а также агрегировать информацию на разных масштабах. Эта версия значительно улучшает общую производительность модели, indicating, что слой ACA и слой MSA играют важную synergistic роль в агрегации информации и понимании контекста. (4) Полная модель интегрирует слой ACA и слой MSA в HED, что позволяет модели лучше использовать hierarchical embedded информацию на этапе декодирования. Добавление HED значительно улучшает способность модели захватывать детали и общую производительность, в результате чего наилучшая производительность модели становится оптимальной.
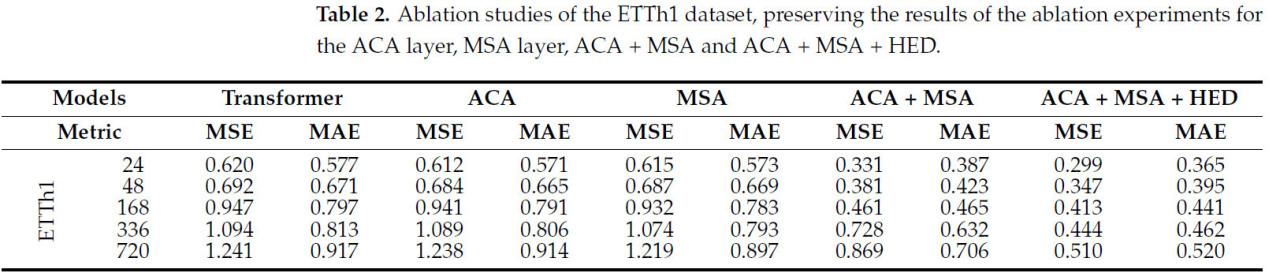
Таблица 2. Абляционные исследования набора данных ETTh1, сохраняя результаты абляционных экспериментов для слоя ACA, слоя MSA, ACA + MSA и ACA + MSA + HED.
5. Выводы
Мы предлагаем AMSformer — модель на основе трансформера, использующую адаптивное многомасштабное объединение признаков для прогнозирования температуры зерна при хранении. В частности, механизм адаптивного канального внимания (ACA) назначает различные веса каждому каналу, позволяя модели selectively концентрироваться на наиболее значимых для задачи прогнозирования каналах. Механизм многомасштабного внимания (MSA) вычисляет веса внимания на различных временных масштабах и осуществляет взвешенное объединение признаков. Также был разработан иерархический энкодер-декодер (HED) для интеграции временных и межканальных зависимостей с использованием ACA и MSA. Результаты эксперимента подтверждают высокую эффективность предложенного подхода.
Мы также анализируем ограничения нашей работы. Во-первых, хотя AMSformer показала значительные результаты в прогнозировании температуры зерна, ее производительность может зависеть от качества и объема данных. На практике наличие шума или пропущенных значений в наборах данных может оказывать определенное влияние на прогнозные результаты модели. Во-вторых, сложность и вычислительная стоимость модели также требуют внимания. Использование механизмов многомасштабного и адаптивного канального внимания увеличивает сложность и вычислительные потребности модели. При ограниченных ресурсах может потребоваться дополнительная оптимизация структуры и параметров модели для снижения вычислительных затрат и повышения эффективности.
Для решения этих ограничений мы планируем проведение дальнейших исследований и усовершенствований в будущей работе. Во-первых, мы исследуем более эффективные методы обработки зашумленных и неполных данных для повышения устойчивости и обобщающей способности модели. Во-вторых, мы будем оптимизировать структуру и параметры модели для снижения вычислительной стоимости и улучшения прогнозной производительности. Будут применены методы адаптивной фильтрации, такие как фильтр Калмана, для динамической оценки и корректировки зашумленных данных. Внедрение маскированных автокодировщиков позволит модели непосредственно обрабатывать входные данные с пропусками. Также будет исследовано использование разреженных механизмов внимания для дальнейшего снижения вычислительной сложности, а также обучение со смешанной точностью для ускорения вычислений и сокращения требований к видеопамяти. Кроме того, мы исследуем возможность применения AMSformer в других смежных областях для проверки ее обобщающей способности и масштабируемости.
Ссылки
1. Cao, B.; Tang, L.; Hu, B.; Zhao, X. Global Grain Crisis and China’s Grain Security. Int. Econ. Rev. 2021, 2, 9–21. [Google Scholar]
2. Liu, Z.; Zhong, H.; Li, Y.; Wen, Q.; Liu, X.; Jian, Y. Change in grain production in China and its impacts on spatial supply and demand distributions in recent two decades. J. Nat. Resour. 2021, 36, 1413–1425. [Google Scholar] [CrossRef]
3. Oliveira, L.F.P.; Moreira, A.P.; Silva, M.F. Advances in agriculture robotics: A state-of-the-art review and challenges ahead. Robotics 2021, 10, 52. [Google Scholar] [CrossRef]
4. Heller, M.C.; Willits-Smith, A.; Mahon, T.; Keoleian, G.A.; Rose, D. Individual US diets show wide variation in water scarcity footprints. Nat. Food 2021, 2, 255–263. [Google Scholar] [CrossRef] [PubMed]
5. Chen, X.; Wu, L.; Shan, L.; Zang, Q. Main factors affecting post-harvest grain loss during the sales process: A survey in nine provinces of China. Sustainability 2018, 10, 661. [Google Scholar] [CrossRef]
6. Zhao, L.; Wang, J.; Li, Z.; Hou, M.; Dong, G.; Liu, T.; Sun, T.; Grattan, K.T. Quasi-distributed fiber optic temperature and humidity sensor system for monitoring of grain storage in granaries. IEEE Sens. Journal. 2020, 20, 9226–9233. [Google Scholar] [CrossRef]
7. SS, V.C.; Hareendran, A.; Albaaji, G.F. Precision farming for sustainability: An agricultural intelligence model. Comput. Electron. Agric. 2024, 226, 109386. [Google Scholar] [CrossRef]
8. Chen, W.; Wang, W.; Peng, B.; Wen, Q.; Zhou, T.; Sun, L. Learning to rotate: Quaternion transformer for complicated periodical time series forecasting. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 146–156. [Google Scholar]
9. Zhang, Z.; Wang, X.; Gu, Y. Sageformer: Series-aware graph-enhanced transformers for multivariate time series forecasting. arXiv 2023, arXiv:2307.01616. [Google Scholar]
10. Zhang, Y.; Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
11. Duan, S.; Yang, W.; Wang, X.; Mao, S.; Zhang, Y. Grain pile temperature forecasting from weather factors: A support vector regression approach. In Proceedings of the 2019 IEEE/CIC International Conference on Communications in China (ICCC), Changchun, China, 1–13 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 255–260. [Google Scholar]
12. Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM 2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
13. Ge, L.; Chen, C.; Li, Y.; Mo, T.; Li, W. A CNN-based temperature prediction approach for grain storage. Int. J. Internet Manuf. Serv. 2020, 7, 345–357. [Google Scholar] [CrossRef]
14. Qu, Z.; Zhang, Y.; Hong, C.; Zhang, C.; Dai, Z.; Zhao, Y.; Gu, Z. Temperature forecasting of grain in storage: A multi-output and spatiotemporal approach based on deep learning. Comput. Electron. Agric. 2023, 208, 107785. [Google Scholar] [CrossRef]
15. Mao, B.; Tao, S.; Li, B. Grain Temperature Prediction Based on GRU Deep Fusion Model. Int. J. Inf. Technol. Decis. Mak. 2024, 1–19. [Google Scholar] [CrossRef]
16. Fan, J.; Zhang, K.; Huang, Y.; Zhu, Y.; Chen, B. Parallel spatio-temporal attention-based TCN for multivariate time series prediction. Neural Comput. Appl. 2023, 35, 13109–13118. [Google Scholar] [CrossRef]
17. Jiang, Z.; Ning, Z.; Miao, H.; Wang, L. STDNet: A Spatio-Temporal Decomposition Neural Network for Multivariate Time Series Forecasting. Tsinghua Sci. Technol. 2024, 29, 1232–1247. [Google Scholar] [CrossRef]
18. Li, X.; Luo, S.; Pan, L.; Wu, Z. Adapt to small-scale and long-term time series forecasting with enhanced multidimensional correlation. Expert Syst. Appl. 2024, 238, 122203. [Google Scholar] [CrossRef]
19. Kim, J.; Lee, H.; Yu, S.; Hwang, U.; Jung, W.; Yoon, K. Hierarchical Joint Graph Learning and Multivariate Time Series Forecasting. IEEE Access 2023, 11, 118386–118394. [Google Scholar] [CrossRef]
20. Lu, J.; Han, X.; Sun, Y.; Yang, S. CATS: Enhancing Multivariate Time Series Forecasting by Constructing Auxiliary Time Series as Exogenous Variables. arXiv 2024, arXiv:2403.01673. [Google Scholar]
21. Miao, H.; Zhang, Y.; Ning, Z.; Jiang, Z.; Wang, L. TDG4MSF: A temporal decomposition enhanced graph neural network for multivariate time series forecasting. Appl. Intell. 2023, 53, 28254–28267. [Google Scholar] [CrossRef]
22. Guo, K.; Yu, X. Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains. Appl. Sci. 2024, 14, 2893. [Google Scholar] [CrossRef]
23. Wang, D.; Chen, C. Spatiotemporal Self-Attention-Based LSTNet for Multivariate Time Series Prediction. Int. J. Intell. Syst. 2023, 2023, 9523230. [Google Scholar] [CrossRef]
24. Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
25. Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
26. Liu, S.; Yu, H.; Liao, C.; Li, J.; Lin, W.; Liu, A.X.; Dustdar, S. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In Proceedings of the Tenth International Conference on Learning Representations (ICLR 2022) New Orleans, Louisiana, USA, 25–29 April 2022. [Google Scholar]
27. Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the 39th International Conference on Machine Learning (PMLR), Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
28. Du, D.; Su, B.; Wei, Z. Preformer: Predictive transformer with multi-scale segment-wise correlations for long-term time series forecasting. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
29. Xiao, Y.; Liu, Z.; Yin, H.; Wang, X.; Zhang, Y. STFormer: A dual-stage transformer model utilizing spatio-temporal graph embedding for multivariate time series forecasting. J. Intell. Fuzzy Syst. 2024, 46, 6951–6967. [Google Scholar] [CrossRef]
30. Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
31. Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, San Diego, CA, USA, 6–10 July 2020; pp. 753–763. [Google Scholar]

Zhang Q, Zhang W, Huang Q, Wan C, Li Z. AMSformer: A Transformer for Grain Storage Temperature Prediction Using Adaptive Multi-Scale Feature Fusion. Agriculture. 2025; 15(1):58. https://doi.org/10.3390/agriculture15010058
Фото: freepik
Перевод статьи «AMSformer: A Transformer for Grain Storage Temperature Prediction Using Adaptive Multi-Scale Feature Fusion» авторов Zhang Q, Zhang W, Huang Q, Wan C, Li Z., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)