Двухэтапный мультимодальный метод прогнозирования внутримышечного жира у свиней
Содержание внутримышечного жира (IMF) существенно влияет на нежность, вкус и сочность свинины. Поддержание оптимального диапазона IMF не только повышает питательную ценность, но и улучшает вкусовые качества мясной продукции. Однако традиционные методы измерения IMF часто являются инвазивными и трудоемкими. Ультразвуковая визуализация предлагает неразрушающее решение, способное прогнозировать содержание IMF, а также оценивать толщину шпика и площадь мышцы длиннейшей спины (longissimus dorsi).
Аннотация
В данном исследовании была разработана двухэтапная мультимодальная сетевая модель. На первом этапе, используя B-режим ультразвуковых изображений, мы применили сегментационную сеть UNetPlus для точного выделения области мышцы длиннейшей спины. Затем мы объединили данные о толщине шпика и площади мышцы, чтобы создать мультимодальный входной набор для прогнозирования содержания IMF с помощью нашей модели. Результаты показывают, что UNetPlus достигает среднего коэффициента пересечения по объединению (mIoU) 94,17% для точной сегментации области мышцы длиннейшей спины. Мультимодальная сеть достигает показателя R² 0,9503 для прогнозирования содержания IMF, со значениями коэффициентов корреляции Спирмена и Пирсона 0,9683 и 0,9756 соответственно, при компактном размере модели 4,96 МБ. Данное исследование подчеркивает эффективность комбинации сегментированных изображений мышцы длиннейшей спины с данными о толщине шпика и площади мышцы в рамках двухэтапного мультимодального подхода для прогнозирования содержания внутримышечного жира.
1. Введение
Оценка качества является ключевым аспектом мясной промышленности, напрямую влияя на здоровье потребителей и коммерческую стоимость пищевой продукции. Содержание внутримышечного жира (IMF), как важный показатель качества мяса, значительно влияет на текстуру, вкус и нежность мяса [1]. Низкое содержание IMF приводит к снижению нежности, сочности, вкусовых качеств и общей приемлемости для потребителей мясной продукции. Напротив, хотя более высокое содержание IMF улучшает различные физико-химические свойства, оно может негативно повлиять на здоровье животного, если превысит определенный уровень [2]. Чрезмерное внимание к выходу постного мяса и скорости роста на протяжении многих лет привело к общему снижению содержания IMF у свиней, что критически сказывается на качестве свинины [3]. Считается, что идеальный диапазон обычно составляет от 3,0% до 3,5% [4,5].
Наиболее точным методом определения содержания IMF является химический анализ [6]; однако этот метод требует убоя свиней, является разрушительным для образцов и чрезмерно трудоемким. Ближняя инфракрасная спектроскопия [7,8] и гиперспектральная визуализация [9,10,11,12] также появились как методы измерения содержания IMF, но эти методы также требуют убоя свиней при применении к товарному мясу. Выявление и контроль содержания IMF в процессе выращивания свиней может экономить время, повышать эффективность производства и защищать благополучие животных. Соответственно, неразрушающие методы на основе ультразвуковой технологии для измерения содержания IMF стали приоритетом.
В ранних исследованиях ученые предполагали, что содержание внутримышечного жира значительно коррелирует с толщиной шпика и площадью мышцы длиннейшей спины [13,14]. Некоторые исследователи извлекали параметры признаков из ультразвуковых изображений глазной мышцы, такие как матрица совпадения уровней серого [15], гистограмма изображения [16], матрица длин серий и вейвлет-преобразование [17], прежде чем строить модели линейной регрессии с использованием этих параметров вместе с толщиной шпика и площадью глазной мышцы. Однако традиционные модели линейной регрессии ограничены с точки зрения сложности и точности прогнозирования.
По мере развития исследований и увеличения объемов данных методы глубокого обучения постепенно внедрялись в исследования по прогнозированию содержания IMF. По сравнению с моделями линейной регрессии, глубокое обучение может обрабатывать более сложные и высокоразмерные данные. Chen [18] использовал модель сверточной нейронной сети (CNN) для отдельного прогнозирования толщины шпика и площади глазной мышцы, а затем применил методы машинного обучения для прогнозирования содержания IMF. Zhao [19] использовал технологию глубокого обучения для сортировки мраморности говядины и разработал мобильное приложение для отображения результатов сортировки в реальном времени, что значительно повысило эффективность инспекции сельскохозяйственной и животноводческой продукции. Liu [20] предложил модель глубокого обучения под названием PIMFP (Prediction of Intramuscular Fat Percentage), которая первой использует сверточную нейронную сеть для прямого прогнозирования содержания IMF по ультразвуковым изображениям. Несмотря на ценность этих вкладов, данные методы все еще имеют ограничения. Например, метод Chen [18] требует отдельного обучения моделям прогнозирования шпика и глазной мышцы, а также моделям машинного обучения, а Zhao [19] сосредоточился только на сортировке говядины. Подход Liu [20] требует точной сегментации областей интереса (ROI), что увеличивает сложность и неопределенность при практических операциях из-за изначально строгих требований к точности предобработки изображений.
Точное и удобное прогнозирование содержания IMF у живых свиней остается значительной проблемой. Чтобы решить ее, мы разработали двухэтапную мультимодальную модель BL-IMF-MNet (Backfat thickness–Longissimus dorsi area Intramuscular fat Multimodal Network) для сегментации области мышцы длиннейшей спины на ультразвуковых изображениях и прогнозирования содержания IMF.
В данном исследовании мы использовали сеть сегментации изображений UNetPlus для сегментации области мышцы длиннейшей спины на ультразвуковых изображениях в качестве ROI, затем объединили эту ROI со значениями толщины шпика и площади мышцы длиннейшей спины через мультимодальную сеть для обучения с целью прогнозирования содержания IMF. Этот подход не только повышает точность прогнозирования содержания IMF, но и снижает зависимость от разрушающего отбора проб, имея значительный прикладной потенциал и практическую ценность.
2. Материалы и методы
2.1. Образцы и получение изображений
Экспериментальные данные для этого исследования были предоставлены исследовательской группой профессора Jianxun Zhang в Чунцинском технологическом университете [18]. Набор данных включает 135 наборов вертикальных ультразвуковых изображений мышцы длиннейшей спины свиней, полученных с помощью ветеринарного ультразвукового аппарата BMV FarmScan® L70 (производства BMV Technology Ltd., Шэньчжэнь, Китай), оснащенного линейным датчиком для измерения шпика, с глубиной обнаружения, установленной на 20 см. Свиньи голодали за день до сбора данных. Перед получением ультразвуковых изображений измерялась живая масса каждой свиньи. Поперечные ультразвуковые изображения были получены с левой стороны туши между 10-м и 11-м ребрами с помощью ультразвукового аппарата. Опытный персонал аннотировал изображения для расчета толщины шпика и площади мышцы длиннейшей спины. После убоя были взяты образцы мышцы длиннейшей спины между 10-м и 11-м ребрами, и содержание внутримышечного жира было определено методом экстракции Сокслета. Были получены ультразвуковые изображения от 130 свиней вместе с соответствующими номерами бирок, живой массой, толщиной шпика, площадью мышцы длиннейшей спины и данными по содержанию IMF. Только данные по живой массе и IMF доступны для оставшихся пяти свиней. Живая масса колебалась от 75,8 кг до 127 кг, в среднем 95,59 кг; толщина шпика — от 0,91 см до 5,48 см, в среднем 2,78 см; площадь мышцы длиннейшей спины — от 11 см² до 53,78 см², в среднем 26,99 см²; содержание IMF во всем наборе данных варьируется от 0,36% до 18,85%, в среднем 3,67%. Диаграмма, иллюстрирующая конкретный диапазон содержания IMF и количество свиней, представлена на Рисунке 1.
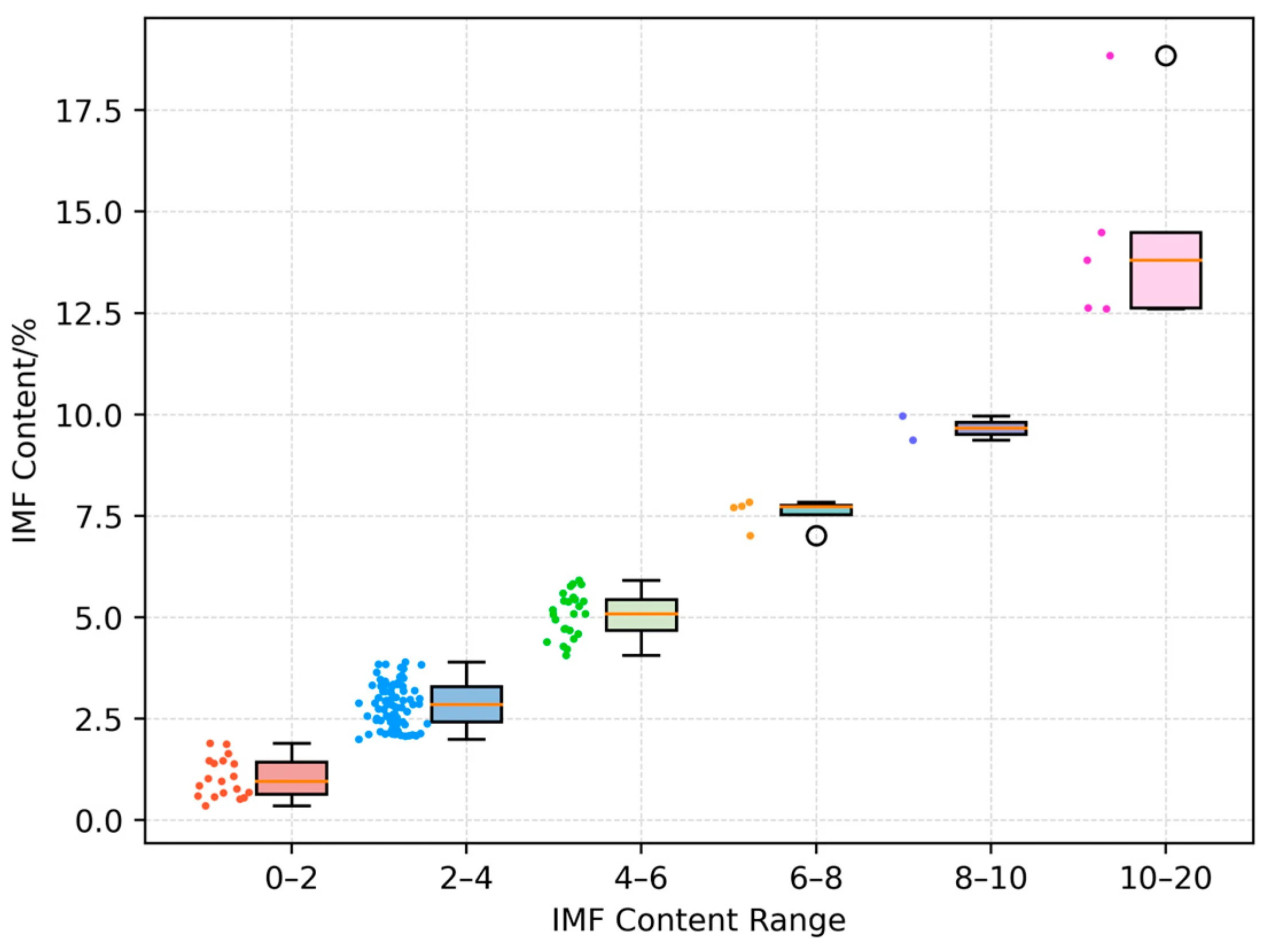
Рисунок 1. Диапазон содержания внутримышечного жира. Каждый прямоугольник представляет межквартильный размах, а отдельные точки данных указывают на конкретные измерения.
2.2. Обзор структуры BL-IMF-MNet
BL-IMF-MNet состоит из пяти компонентов: предобработка данных для сегментации изображений, сеть сегментации изображений UNetPlus, предобработка мультимодальных данных, обучение мультимодальной модели и вывод модели (Рисунок 2). Сначала исходные ультразвуковые изображения предварительно обрабатываются, аннотируются и аугментируются. Затем сеть сегментации изображений UNetPlus используется для сегментации области мышцы длиннейшей спины в качестве ROI. Чтобы выделить такие признаки, как жировая ткань, ROI адаптивно усиливается с использованием ограниченного по контрасту адаптивного выравнивания гистограммы. Данные одновременно фильтруются и аугментируются, чтобы обеспечить эффективность сетевой модели. Затем создается мультимодальный набор данных и вводится в мультимодальную сеть для обучения. Наконец, значение содержания IMF получается путем вывода модели.
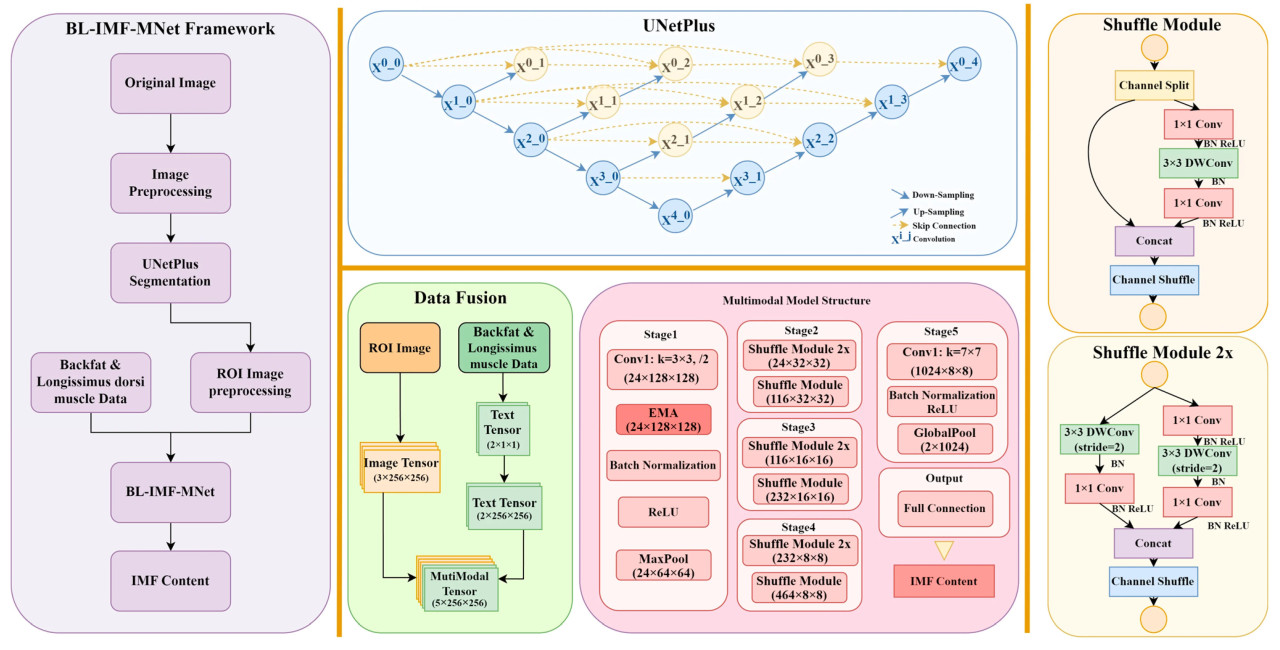
Рисунок 2. Общая структура BL-IMF-MNet (слева); структура UNetPlus (вверху посередине); структура мультимодальной модели (внизу посередине); модуль перемешивания (shuffle) мультимодальной модели (справа).
2.2.1. Предобработка данных для сегментации изображений
В этом эксперименте были получены 135 ультразвуковых изображений свиней в качестве исходных данных для сети сегментации изображений UNetPlus. Разрешение этих исходных изображений составляло 309 × 254. Они были обрезаны, чтобы сохранить только верхнюю половину, поскольку в нижней части изображений присутствовали бесполезные области, изменив разрешение до 220 × 160. На исходных изображениях также были черные рамки, отмеченные ультразвуковым аппаратом, которые были удалены с использованием библиотеки OpenCV путем идентификации черных пикселей на изображениях и их закрытия усреднением значений двух соседних пикселей по горизонтали или вертикали. Впоследствии изображения были аннотированы с помощью Labelme v3.16.7 под руководством экспертов со свинофермы.
Для увеличения объема данных для обучения модели и повышения их способности к обобщению применялись методы аугментации данных, включая вращение изображения, горизонтальное отражение и случайное кадрирование. Эти шаги в конечном итоге расширили исходные 135 изображений до 562, чтобы сформировать набор данных для сегментации. Набор данных был разделен на обучающую, валидационную и тестовую выборки в соотношении 8:1:1; обучающая выборка содержала 449 изображений, валидационная — 57 изображений, а тестовая — 56 изображений. Этот процесс изображен на Рисунке 3.
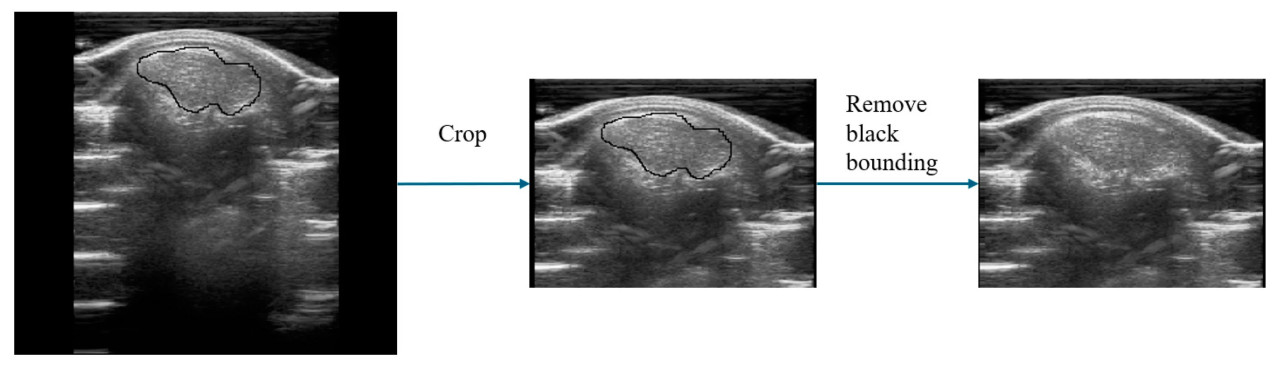
Рисунок 3. Предобработка данных для сегментации изображений. Черная рамка указывает область расчета, отмеченную вручную экспертами.
2.2.2. Сеть сегментации изображений UNetPlus
UNetPlus [21] является улучшенной версией UNet [22], которая широко используется для сегментации изображений в медицинской области. UNet имеет U-образную, полностью симметричную структуру, состоящую из кодера и декодера. Кодер извлекает признаки, постепенно уменьшая размер изображения и увеличивая количество каналов, в то время как декодер восстанавливает изображение до исходного размера путем повышающей дискретизации (апсемплинга) и добавляет пропускные соединения (skip connections) на соответствующих размерностях, чтобы помочь сети захватывать как низкоуровневые, так и высокоуровневые детали признаков.
UNetPlus сохраняет базовую структуру кодера и декодера, но улучшает пропускные соединения, делая их более плотными. Это улучшение позволяет объединять информацию о признаках из разных размерностей и уменьшает семантический разрыв между признаками в подсе сетях кодера и декодера. Между каждым сверточным слоем существует соединительный слой, который объединяет выход предыдущего сверточного слоя в том же плотном блоке с соответствующим уменьшенным (даунсемплированным) выходом следующего плотного блока. Эти плотные пропускные соединения интегрируют выходы каждого кодера, давая более богатую семантическую информацию. Дополнительно, механизм глубокого контроля позволяет модели работать во всех или части ветвей, что уменьшает размер и вычислительную стоимость модели при минимальной потере точности, определяя таким образом ее возможность обрезки и скорость вывода.
2.2.3. Предобработка мультимодальных данных
После получения изображений ROI с помощью модели сегментации изображений UNetPlus требуется дальнейшая обработка для их ввода в мультимодальную прогнозирующую сеть, как показано на Рисунке 4. Сегментация изображений может привести к появлению черных границ вокруг изображений ROI, поэтому мы использовали OpenCV для определения границ ROI на основе точек пикселей, а затем обрезали их.

Рисунок 4. Предобработка данных изображений для мультимодального ввода.
Впоследствии, чтобы выделить такие признаки, как жировая ткань, и позволить сетям глубокого обучения лучше извлекать признаки, мы применили ограниченное по контрасту адаптивное выравнивание гистограммы (CLAHE) [23] для адаптивной регулировки контраста. Этот метод не только помогает уменьшить дефекты изображения, вызванные сегментацией, но также усиливает контраст изображения и делает детали более легко видимыми, оптимизируя таким образом входные данные для задач глубокого обучения.
Однако метод CLAHE применим только к отдельным изображениям. Поскольку наш экспериментальный набор данных содержит изображения различной яркости, мы вычислили среднюю яркость пикселей изображения и нормализовали яркость всех изображений, используя это значение. Это позволило нам смягчить случаи, когда яркость изображения чрезмерно высока или низка, предотвращая тем самым значительные ошибки обучения модели, вызванные яркостью изображения.
Исходный набор данных содержит ультразвуковые изображения, номера бирок, живую массу, толщину шпика, площадь поясничной мышцы и содержание IMF для 130 свиней. Предварительный анализ показал, что только у семи свиней содержание IMF было выше 8%, причем содержание IMF значительно варьировалось в диапазоне от 12% до 18%. На практике свиней с высоким содержанием IMF относительно легко идентифицировать. Соответственно, чтобы обеспечить эффективность процесса обучения мультимодальной сети, мы вручную удалили данные по семи свиньям (включая одну, у которой отсутствовали данные по толщине шпика и площади поясничной мышцы), оставив данные по 124 свиньям.
Мы также применили методы аугментации данных, такие как смещение, вращение и отражение, к данным изображений, чтобы улучшить эффект обучения мультимодальной сети. Впоследствии мы сопоставили аугментированные изображения с текстовыми данными по толщине шпика, площади поясничной мышцы и содержанию IMF, используя номера бирок свиней. Чтобы предотвратить переобучение в этом процессе, мы добавили случайный шум в 1×10⁻⁷ единиц к толщине шпика и площади поясничной мышцы, используя содержание IMF в качестве метки. Это дало 1552 записи данных, которые мы разделили в соотношении 8:1:1, создав обучающий набор из 1241 записи, валидационный набор, содержащий 155 записей, и тестовый набор, содержащий 156 записей.
2.2.4. Слияние признаков
Мы разработали механизм слияния признаков для фазы загрузки данных, чтобы эффективно интегрировать информацию изображений и текста, предоставляя модели более богатые и комплексные входные данные. Сначала данные изображений считывались, изменялись до разрешения 256×256, нормализовались и преобразовывались в тензор. Затем считывались текстовые данные. В наборе данных, используемом для этого эксперимента, текстовые данные включают значения толщины шпика и площади поясничной мышцы, поэтому они были преобразованы в двухканальный тензор. Мы расширили этот тензор текстовых данных, добавив размерности, чтобы соответствовать размеру данных изображений. Наконец, мы объединили тензор данных изображений и тензор текстовых данных по размерности канала, чтобы получить объединенный многоканальный тензор данных.
2.2.5. Структура мультимодальной сети
ShuffleNetV2, предложенный Ma [24], является облегченной сверточной нейронной сетью, которая использует разделяемые по глубине свертки и операции перемешивания каналов. Это позволяет осуществлять более эффективное извлечение признаков при сохранении высокой вычислительной эффективности и низкого количества параметров, что делает ее подходящей для развертывания в средах с ограниченными ресурсами. В ShuffleNetV2 была введена операция разделения каналов (Channel Split), разделяющая входные каналы на две ветви. Одна ветвь подвергается трем сверткам, а другая остается компонентом тождественного отображения для уменьшения вычислительной нагрузки. Дополнительно, чтобы избежать увеличения стоимости доступа к памяти, связанного с чрезмерным использованием групповых сверток, точечные свертки больше не группируются. В процессе слияния ветвей используется Concat вместо Add, за которым следует перемешивание каналов, чтобы обеспечить обмен информацией между ветвями без ущерба для производительности модели (Рисунок 2, правая панель).
В этом эксперименте мы улучшили сеть ShuffleNetV2, сначала изменив количество входных каналов в первом слое на пять, чтобы приспособиться к мультимодальному набору данных. Далее мы заменили последний слой модели на линейный слой, чтобы подходить для задач регрессии. Наконец, мы добавили механизм эффективного многомасштабного внимания (EMA) после первого сверточного слоя сети, чтобы повысить способность модели к извлечению признаков (Рисунок 2, нижняя средняя панель).
EMA, предложенный Ouyang [25], является новым методом межпространственного обучения, который проектирует многомасштабную параллельную подсеть для установления краткосрочных и долгосрочных зависимостей. Он также преобразует часть размерностей каналов в размерности пакета (batch), чтобы сохранить размерность с помощью обычных сверток, и интегрирует выходные карты признаков двух параллельных подсетей с использованием методов межпространственного обучения. Этот подход, сочетающий многомасштабные параллельные подсети и механизмы внимания, извлекает богатую семантическую информацию, не делая модель громоздкой, тем самым повышая производительность и способность к обобщению. Структура EMA проиллюстрирована на Рисунке 5.
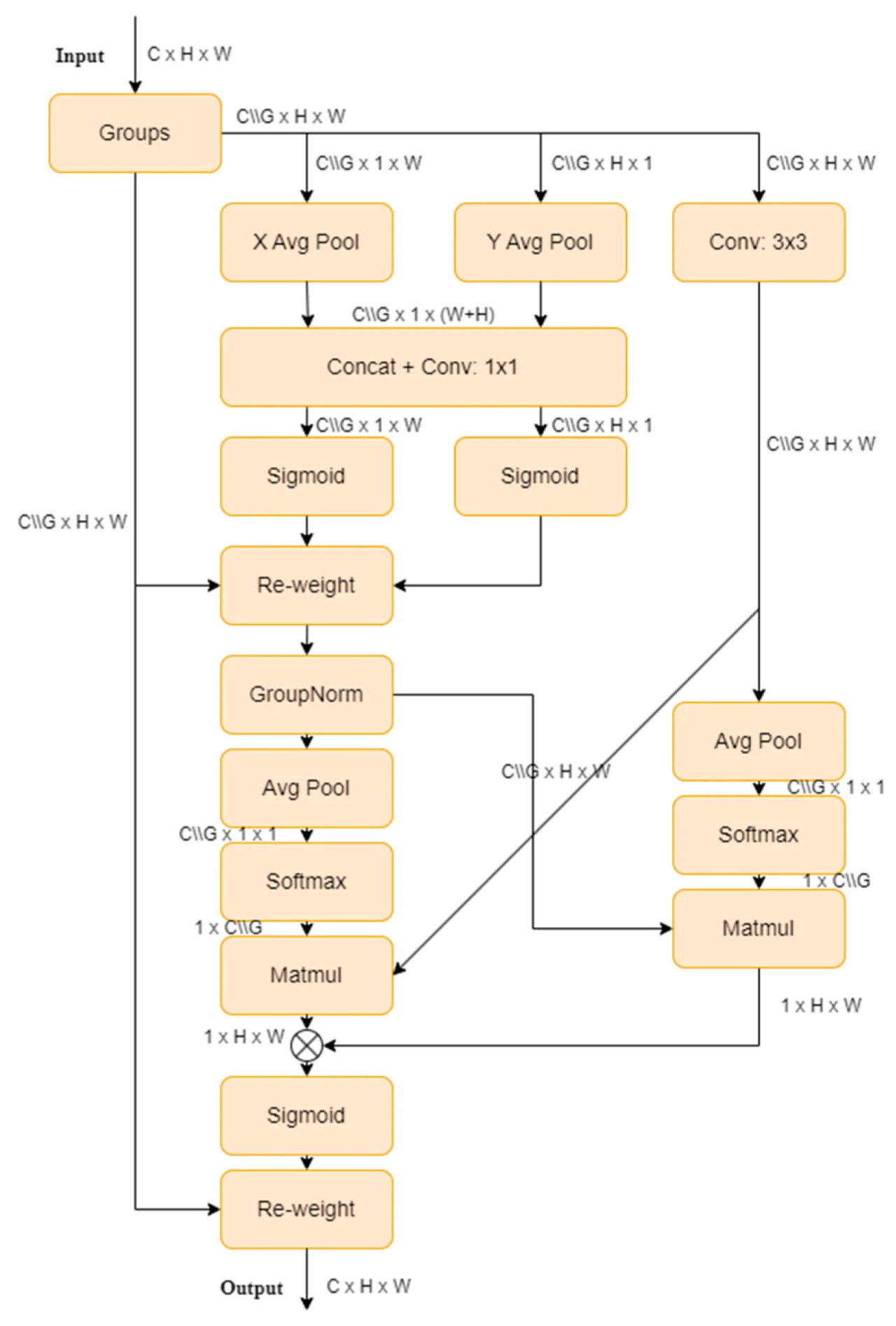
Рисунок 5. Структура механизма EMA.
2.3. Конфигурация среды
Мы проводили эксперименты на следующих аппаратных и программных платформах: два процессора Intel(R) Xeon(R) CPU E5-2690 v4 @2.60 ГГц, две видеокарты NVIDIA RTX A5000 (24 ГБ видеопамяти) с NVLink и 80 ГБ оперативной памяти. Код был написан на Python 3.10.11 и Pytorch 2.0.1, с программным окружением Cuda 12.1. Конкретные гиперпараметры модели описаны в Таблице 1.
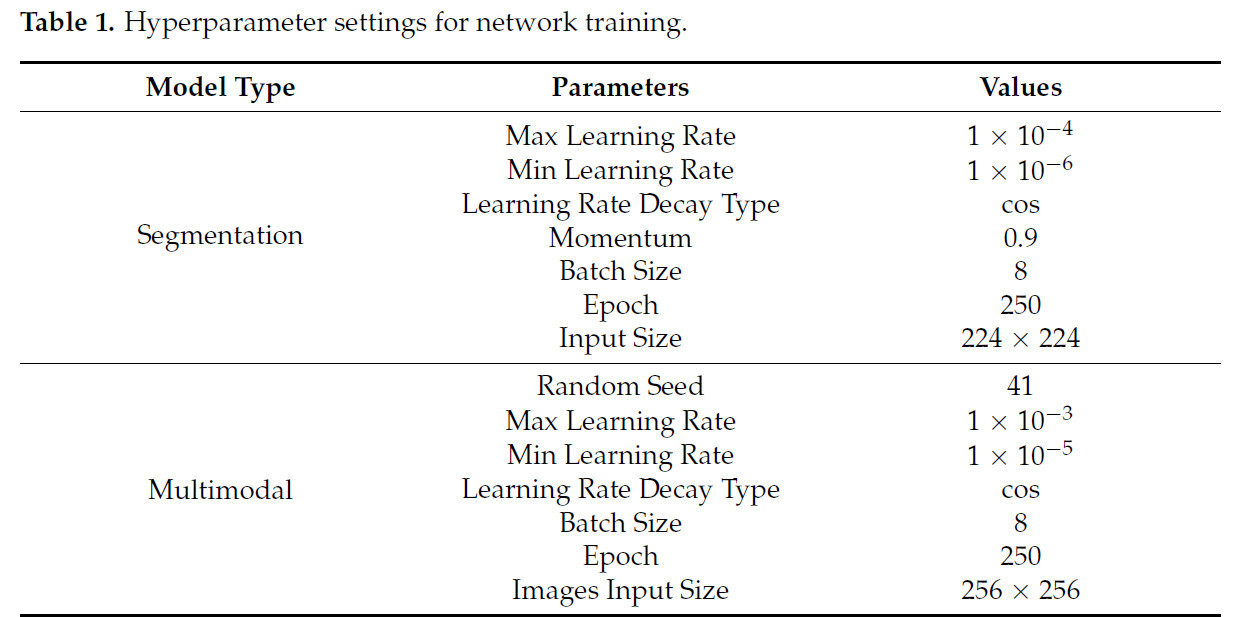
Таблица 1. Настройки гиперпараметров для обучения сети.
2.4. Настройка эксперимента
В этом исследовании мы проверили производительность сети сегментации изображений UNetPlus и BL-IMF-MNet. Во-первых, мы продемонстрировали превосходство UNetPlus в сегментации ROI, проведя сравнительные эксперименты с сетями сегментации изображений UNet, PSPNet [26], FCN [27] и HRNet [28].
Во-вторых, после получения и обработки изображений ROI мы разработали три группы сравнительных экспериментов, включающих текстовые данные, данные изображений и мультимодальные данные. Наша цель состояла в том, чтобы проверить осуществимость и надежность предлагаемой мультимодальной сети по сравнению с одномодальными сетями, одновременно проверяя улучшения сети с помощью экспериментов с абляцией.
Наш пошаговый процесс можно обобщить следующим образом:
(1) Мы использовали изображения ROI для извлечения 15 параметров из матрицы совпадения уровней серого (GLCM) [29,30] — метода, широко используемого в анализе текстур для количественной оценки пространственных отношений между интенсивностями пикселей. Предыдущие исследования продемонстрировали эффективность этого метода, используя признаки, извлеченные из GLCM, в регрессионных анализах для проверки корреляций с содержанием внутримышечного жира [13,28]. Интегрируя эти текстурные признаки со значениями толщины шпика, площади поясничной мышцы и живой массы, мы получили в общей сложности 18 параметров. В этом исследовании мы стремились повторить эти успешные эксперименты и сравнить их результаты с нашим предлагаемым методом, чтобы проверить улучшения нашего подхода. Впоследствии мы провели сравнительные эксперименты на этом наборе признаков с использованием линейного регрессионного анализа, а также методов KNN [31], SVR [32], BP-нейронных сетей [33], одномерной сверточной CNN и одномерной сверточной TCN [34].
(2) Мы использовали AlexNet [35], VGG16 [36], ResNet [37], MobileNet [38] и ShuffleNetV2 в качестве базовых сетей для регрессионного анализа, чтобы сравнить сетевое производительность одномодальных изображений.
(3) Мы сравнили улучшенную мультимодальную модель с другими сетями извлечения мультимодальных признаков, а именно AlexNet, VGG16, ResNet, MobileNet и ShuffleNetV2.
(4) Мы проверили улучшенную производительность предлагаемой сети с помощью экспериментов с абляцией.
2.5. Оценка производительности
В этом исследовании мы разработали инновационный метод прогнозирования содержания IMF с использованием всей площади поясничной мышцы. Мы предложили двухэтапную модель. На первом этапе используется сеть сегментации изображений UNetPlus для сегментации области ROI, а на втором этапе используется мультимодальная регрессионная сеть для прогнозирования содержания IMF. Мы использовали ряд метрик оценки для оценки производительности модели, включая средний коэффициент пересечения по объединению (mIoU) [39], среднюю точность по пикселям (mPA) [40] и точность (ACC) для сети сегментации изображений, а также коэффициент детерминации (R²) [41], среднюю квадратичную ошибку (MSE), среднеквадратичную ошибку (RMSE) [42], коэффициент ранговой корреляции Спирмена (ρ) [43] и коэффициент корреляции Пирсона (r) [44] для регрессионной сети содержания IMF.
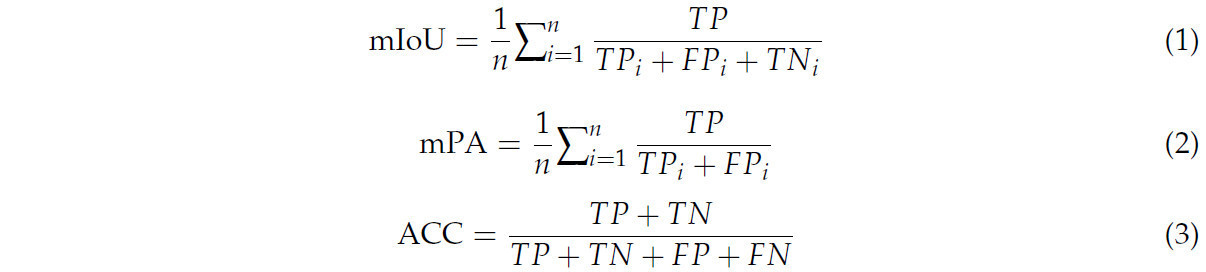
Три формулы выше представляют метрики оценки, необходимые для модели сегментации; `TP_i` обозначает количество истинно положительных для i-й категории, `FP_i` обозначает количество ложноположительных для i-й категории, `TN_i` обозначает количество ложноотрицательных для i-й категории, `n` представляет количество категорий, `TP` представляет общее количество истинно положительных, `TN` — истинно отрицательных, `FP` — ложноположительных, а `FN` — ложноотрицательных.
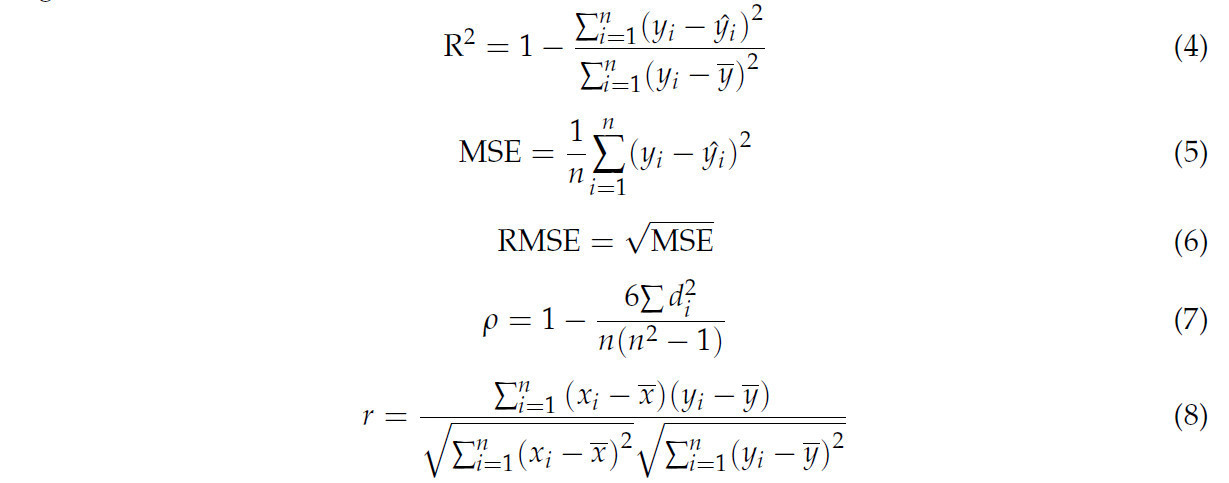

Приведенные выше пять формул — это метрики оценки, которые мы использовали как для одномодальных, так и для мультимодальных сценариев, где y_i представляет наблюдаемое значение, ŷ_i представляет предсказанное значение, ȳ представляет среднее значение наблюдаемых значений, x_i и y_i представляют наблюдаемые значения двух наборов данных соответственно, x̄ представляет среднее значение данных, d_i представляет разницу в рангах между двумя наборами данных, а n представляет количество точек данных.
3. Результаты
3.1. Производительность сегментации UNetPlus
Результаты нашего экспериментального сравнения пяти моделей сетей сегментации обобщены в Таблице 2. UNetPlus превзошел другие модели по показателям mIoU (94,17), ACC (98,89) и размеру модели (35 МБ). PSPNet занял второе место по mIoU — 94,13, далее следуют UNet (93,15), FCN (92,83) и HRNet (92,62). У UNetPlus средняя ACC была на 0,162 выше, чем у других моделей, при общем размере модели на 2,5–143 МБ меньше. Однако у UNetPlus показатель mPA был на 0,46 процентных пункта ниже, чем у PSPNet. Это связано с тем, что PSPNet использует глубокий декодер и модуль ASPP, с декодером более глубоким, чем у UNetPlus, что позволяет захватывать многомасштабные признаки; это повышает воспринимающую и обобщающую способности модели, тем самым улучшая ее производительность.
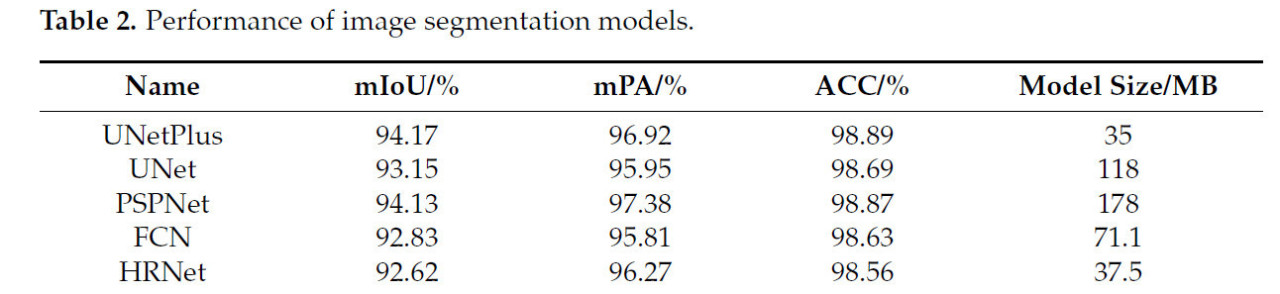
Таблица 2. Производительность моделей сегментации изображений.
3.2. Сравнение одномодальных сетей
Предыдущие исследования показали, что методы линейной регрессии и машинного обучения KNN эффективны в прогнозировании содержания IMF. В этом эксперименте мы сравнили методы линейной регрессии, KNN, BP-нейронной сети и одномерной сверточной сети, включив как только текстовые, так и только изображенческие модальности, чтобы проверить их эффективность при использовании всей площади поясничной мышцы, как показано в Таблице 3.
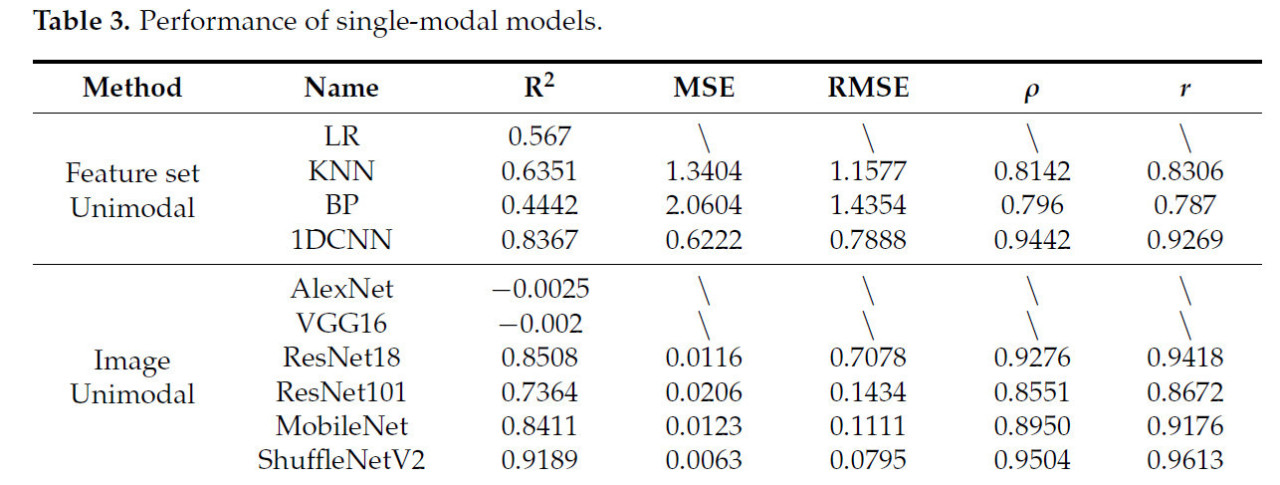
Таблица 3. Производительность одномодальных моделей.
Мы извлекли 15 параметров из матрицы совпадения уровней серого области ROI, объединили их с толщиной шпика, площадью мышцы длиннейшей спины и живой массой в качестве независимых переменных, плюс содержание IMF в качестве зависимой переменной. Метод линейной регрессии применялся в IBM SPSS Statistics 25 с пошаговой регрессией. Окончательно сохраненными параметрами были толщина шпика, дисперсия серого, корреляция, площадь поясничной мышцы, выраженность больших градиентов, инерция, энтропия градиента, неравномерность распределения градиента, среднее значение серого и среднее значение градиента. Используя все сохраненные независимые переменные в качестве входных данных, полученное значение R² составило 0,567.
Мы далее сравнили модели KNN и BP-нейронной сети и обнаружили, что они были менее эффективны, чем одномерная сверточная нейронная сеть, которая достигла значения R² 0,8367, в то время как у KNN и BP они составили 0,6351 и 0,4442 соответственно. Наша мультимодальная сетевая модель превзошла другие по значению R² и общей эффективности прогнозирования, показав улучшение на 11% по сравнению с одномерной сверточной нейронной сетью.
Мы сравнили несколько часто используемых сетевых моделей в экспериментах по регрессии на сверточных сетях с только изображенческими одномодальными данными. ShuffleNetV2 показал наилучшие результаты по всем метрикам со значением R² 0,9189. Далее следуют ResNet18 и MobileNet со значениями R² 0,8508 и 0,8411 соответственно. Напротив, AlexNet и VGG16 показали наихудшие результаты, включая отрицательные значения R², что указывает на плохую пригодность для этой задачи. Коэффициенты корреляции Спирмена и Пирсона для ShuffleNetV2 составили 0,9504 и 0,9613 соответственно, что указывает на высокую корреляцию между прогнозами и фактическими значениями. ResNet18 и MobileNet также имели высокие коэффициенты корреляции, оба превышающие 0,8950.
3.3. Сравнение мультимодальных сетей
Чтобы оценить превосходство предлагаемой BL-IMF-MNet, мы сравнили ее с AlexNet, VGG16, ResNet18, ResNet101, MobileNet и ShuffleNetV2, как показано в Таблице 4. Наша предложенная сеть достигла наилучшей производительности по показателям R², MSE, RMSE, коэффициентам Спирмена и Пирсона, а также по размеру модели. Например, BL-IMF-MNet имела наивысший R² — 0,950, далее следуют ShuffleNetV2 (0,927), ResNet18 (0,885), MobileNet (0,871) и ResNet101 (0,804). AlexNet и VGG показали наихудшие результаты с отрицательными значениями R², указывая, что они не подходят для этой задачи; другие метрики не рассчитывались.
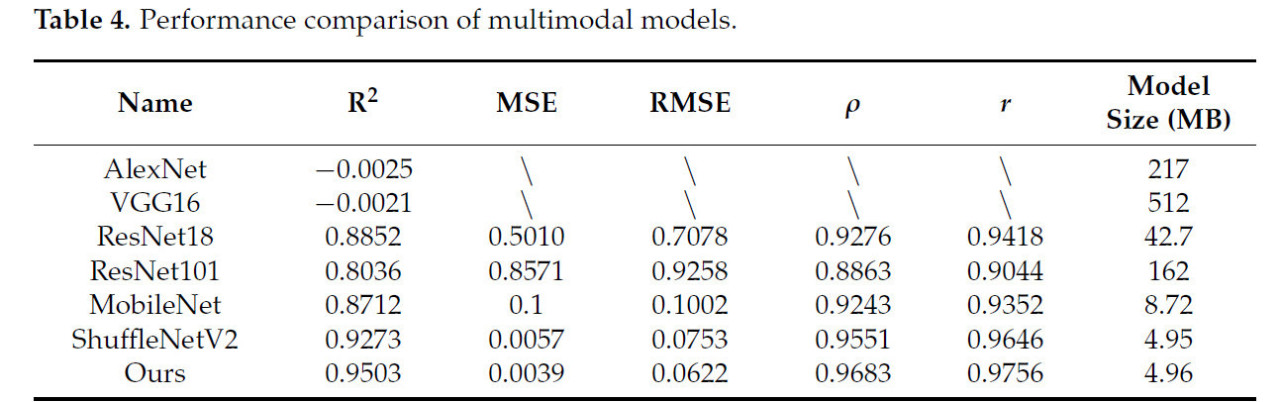
Таблица 4. Сравнение производительности мультимодальных моделей.
BL-IMF-MNet также показала отличную производительность по MSE и RMSE, составив 0,004 и 0,062 соответственно. ResNet18 и ResNet101 показали плохие результаты с соответствующими значениями 0,708, 0,501, 0,926 и 0,857. Наша сеть также достигла наилучших результатов по коэффициентам корреляции Спирмена и Пирсона — 0,976 и 0,968 соответственно, превзойдя другие модели на 0,011–0,074 и 0,013–0,082. ResNet101 показал наихудшие результаты — 0,904 и 0,886, в то время как исходная сеть ShuffleNetV2 была второй по результатам — 0,965 и 0,955.
По сравнению с VGG16, размер нашей предложенной модели был уменьшен на 507,04 МБ, далее AlexNet — на 212,04 МБ, ResNet101 — на 157,04 МБ, ResNet18 — на 37,74 МБ, а MobileNet — на 3,76 МБ. Включение модуля механизма EMA в предложенную сеть увеличило размер модели всего на 0,01 МБ по сравнению с ShuffleNetV2, достигнув 4,96 МБ.
3.4. Эксперимент с абляцией
Мы проверили эффективность предлагаемой мультимодальной сети с помощью экспериментов с абляцией, которые включали три различные модели: E0, которая использует архитектуру ShuffleNetV2 для обучения на одномодальных данных изображений; E1, которая добавляет две точки текстовых данных (толщину шпика и площадь мышцы длиннейшей спины) для формирования мультимодальной сети; и EP, которая дополнительно вводит механизм EMA поверх E1, как показано в Таблице 5.

Таблица 5. Сравнение экспериментов с абляцией.
Обучение на одномодальных данных изображений с использованием архитектуры ShuffleNetV2 (E0) дает значение R² 0,9189, что указывает на высокую степень соответствия для одномодальных данных изображений. Коэффициенты корреляции Спирмена и Пирсона составили 0,9504 и 0,9613 соответственно, указывая на высокую корреляцию между предсказанными и фактическими значениями. Добавление текстовых данных по толщине шпика и площади мышцы длиннейшей спины для формирования мультимодальной сети (E1) увеличило значение R² до 0,9273, что указывает на то, что мультимодальная сеть более эффективна, чем одномодальная. И RMSE, и MSE снизились, в то время как коэффициенты корреляции Спирмена и Пирсона увеличились до 0,9551 и 0,9646 соответственно, что дополнительно подтверждает эффективность мультимодальной сети.
Введение механизма EMA для формирования окончательной мультимодальной сети (EP) улучшило значение R² до 0,9503, демонстрируя существенное повышение производительности. RMSE снизился до 0,0622, MSE — до 0,0039, а коэффициенты корреляции Спирмена и Пирсона достигли 0,9683 и 0,9756 соответственно, что указывает на улучшение прогностической производительности.
По мере улучшения трех моделей от E0 до EP значения R² увеличились на 3,15% с 0,9189 до 0,9503, что указывает на то, что добавление текстовой информации и механизма EMA улучшило прогностическую производительность модели. В частности, мультимодальная сеть, сочетающая данные изображений и текста (E1), превзошла одномодальную сеть (E0), в то время как окончательная мультимодальная сеть с механизмом EMA (EP) достигла наилучшей производительности. Таким образом, предлагаемая мультимодальная сеть превосходит традиционные одномодальные методы в задачах прогнозирования содержания IMF, в частности после включения механизма внимания. Эти результаты подтверждают эффективность слияния мультимодальной информации с механизмом внимания в плане повышения точности прогнозирования.
4. Обсуждение
В данной статье предлагается двухэтапная модель глубокого обучения BL-IMF-MNet для прогнозирования содержания IMF с использованием изображений области мышцы длиннейшей спины и двух параметров — толщины шпика и площади мышцы длиннейшей спины. Примечательно, что мы представляем новый подход, основанный на использовании изображений всей области мышцы длиннейшей спины и мультимодальной модели для прогнозирования содержания IMF.
На первом этапе сеть UNetPlus используется для выполнения сегментации изображений области мышцы длиннейшей спины, генерируя высокоточные изображения этой области. На втором этапе улучшенная мультимодальная сеть используется для прогнозирования содержания IMF, используя мультимодальные данные, включающие сегментированные изображения с первого этапа, а также числовые данные по толщине шпика и площади мышцы длиннейшей спины. Использование сети UNetPlus обеспечивает точность и прецизионность сегментации изображений; улучшенная мультимодальная сеть использует ShuffleNetV2 в качестве базовой сети для извлечения признаков, выигрывая от ее эффективности и точности. Этот подход предлагает преимущества по сравнению с другими моделями.
Мы провели два этапа предобработки набора данных, используемого для тестирования предлагаемого метода. Перед сегментацией изображений из исходных изображений были удалены нерелевантные области, а черные пиксели, аннотированные исходным ультразвуковым аппаратом, были устранены. Перед генерацией мультимодальных данных мы применили CLAHE для улучшения деталей сегментированных изображений области мышцы длиннейшей спины, оптимизировав таким образом изображения для последующих шагов.
Используя сеть сегментации изображений UNetPlus, наша модель достигла mIoU 94,17% и mPA 96,92%, что указывает на высокую производительность сегментации. Дальнейшие, предлагаемая мультимодальная регрессионная сеть BL-IMF-MNet достигла значения R² 0,9503, с коэффициентами корреляции Спирмена и Пирсона 0,9683 и 0,9756 соответственно, демонстрируя свою эффективность в прогнозировании содержания внутримышечного жира (IMF). Эти результаты указывают на то, что наш метод показывает исключительно хорошие результаты как в задачах сегментации, так и прогнозирования.
В настоящее время наша команда исследует дополнительные методы сегментации и расчета толщины шпика и площади мышцы длиннейшей спины на основе ультразвуковых изображений. Цель состоит в том, чтобы заменить ручную аннотацию автоматическим расчетом значений толщины шпика и площади мышцы длиннейшей спины, предоставляя оптимальные данные для ввода в мультимодальные сети. Мы ожидаем, что эта технология позволит осуществлять быструю, неразрушающую и точную детекцию толщины шпика свиней, площади мышцы длиннейшей спины и содержания IMF, формируя таким образом удобную систему обнаружения в один клик.
В будущем мы продолжим увеличивать размер набора данных, чтобы дальнейшим образом улучшить эффективность обучения и способность к обобщению нашей модели. Дополнительно, мы продолжим совершенствовать наши алгоритмы и методы, чтобы внести вклад в развитие этой области.
5. Выводы
В данной статье представлен двухэтапный мультимодальный подход для прогнозирования содержания IMF у живых свиней путем сегментации изображений всей области мышцы длиннейшей спины и объединения числовых значений толщины шпика и площади мышцы длиннейшей спины для формирования мультимодальных данных. Предлагаемый метод демонстрирует преимущества перед существующими методами с точки зрения точности модели, прогностической производительности и размера. Однако, несмотря на достижение удовлетворительных результатов, необходимы дальнейшие исследования для разработки методов автоматического расчета толщины шпика и площади мышцы длиннейшей спины для неразрушающего, быстрого и выполняемого в один клик прогнозирования толщины шпика, площади мышцы длиннейшей спины и содержания IMF.
Результаты данного исследования могут предоставить важную поддержку для продвинутой обработки изображений в ветеринарной медицине и предложить ценные идеи для будущих связанных исследовательских усилий.
Ссылки
1. Wood, J.D.; Enser, M.; Fisher, A.V.; Nute, G.R.; Richardson, R.I.; Sheard, P.R. Manipulating meat quality and composition. Proc. Nutr. Soc. 1999, 58, 363–370. [Google Scholar] [CrossRef] [PubMed]
2. Wang, W.; Bai, T.; Han, Q.; Ning, X.; He, J.; Shi, X.; Hu, J. Study on the Factors Affecting Pork Quality. J. Anim. Sci. Vet. Med. 2018, 37, 44–45. [Google Scholar]
3. Lyu, Y.; He, C.; Lan, L. Research Advances on the Relationship Between Intramuscular Fat andMeat Quality and Influence Factor of Intramuscular Fat in Pigs. China Anim. Husb. Velerinary Med. 2020, 47, 554–563. [Google Scholar] [CrossRef]
4. Daszkiewicz, T.; Bąk, T.; Denaburski, J. Quality of pork with a different intramuscular fat (IMF) content. Pol. J. Food Nutr. Sci. 2005, 55, 31–36. [Google Scholar]
5. Fernandez, X.; Monin, G.; Talmant, A.; Mourot, J.; Lebret, B. Influence of intramuscular fat content on the quality of pig meat —2. Consumer acceptability of m. longissimus lumborum. Meat Sci. 1999, 53, 67–72. [Google Scholar] [CrossRef]
6. Hamill, R.M.; McBryan, J.; McGee, C.; Mullen, A.M.; Sweeney, T.; Talbot, A.; Cairns, M.T.; Davey, G.C. Functional analysis of muscle gene expression profiles associated with tenderness and intramuscular fat content in pork. Meat Sci. 2012, 92, 440–450. [Google Scholar] [CrossRef]
7. Fan, Y.; Liao, Y.; Cheng, F. Predicting of intramuscular fat content in pork using near infrared spectroscopy and multivariate analysis. Int. J. Food Prop. 2018, 21, 1180–1189. [Google Scholar] [CrossRef]
8. Fowler, S.M.; Wheeler, D.; Morris, S.; Mortimer, S.I.; Hopkins, D.L. Partial least squares and machine learning for the prediction of intramuscular fat content of lamb loin. Meat Sci. 2021, 177, 108505. [Google Scholar] [CrossRef]
9. Huang, H.; Liu, L.; Ngadi, M.O. Assessment of intramuscular fat content of pork using NIR hyperspectral images of rib end. J. Food Eng. 2017, 193, 29–41. [Google Scholar] [CrossRef]
10. Kucha, C.T.; Liu, L.; Ngadi, M.; Gariépy, C. Assessment of Intramuscular Fat Quality in Pork Using Hyperspectral Imaging. Food Eng. Rev. 2020, 13, 16. [Google Scholar] [CrossRef]
11. Liu, L.; Ngadi, M. Predicting intramuscular fat content of pork using hyperspectral imaging. J. Food Eng. 2014, 134, 16–23. [Google Scholar] [CrossRef]
12. Wu, J.; Peng, Y.; Li, Y.; Wang, W.; Chen, J.; Dhakal, S. Prediction of beef quality attributes using VIS/NIR hyperspectral scattering imaging technique. J. Food Eng. 2012, 109, 267–273. [Google Scholar] [CrossRef]
13. Xing, L.; Zhang, H.J.; Wu, H.W.; Lu, X.L. Correlation Analysis of Intramuscular Fat Content and Important Growth Traits in Duroc Boars. Swine Prod. 2021, 03, 50–52. [Google Scholar] [CrossRef]
14. Ren, Y.F.; Gao, S.C.; Zhao, X.Y.; Wang, Y.P.; Li, Q.X.; Zhang, C.S.; Wang, J.Y. Correlation Analysis among Carcass Weight, Backfat Thickness and Intramuscular Fat Content in Laiwu Pigs. Shandong Agric. Sci. 2021, 53, 109–115. [Google Scholar] [CrossRef]
15. Ma, X.; Cheng, D.; Wang, L.; Liu, X.; Song, X.; Liang, J.; Zhang, L.; Yan, H.; Wang, L.; Chen, L.; et al. Prediction of Intramuscular Fat Percentage in Live Betjing Black Pig UsingReatime Ultrasound Image. Acta Vet. Et Zootech. Sin. 2012, 43, 1511–1518. [Google Scholar]
16. Zhang, J.; Zhang, M.; Zeng, Q.; Zhang, H. Prediction of intramuscular fat in live swine using real-time ultrasound. Guangdong Agric. Sci. 2012, 39, 128–131. [Google Scholar] [CrossRef]
17. Fabbri, G.; Gianesella, M.; Gallo, L.; Morgante, M.; Contiero, B.; Muraro, M.; Boso, M.; Fiore, E. Application of Ultrasound Images Texture Analysis for the Estimation of Intramuscular Fat Content in the Longissimus Thoracis Muscle of Beef Cattle after Slaughter: A Methodological Study. Animals 2021, 11, 1117. [Google Scholar] [CrossRef]
18. Chen, H.; Zhang, J.; Zhu, J.; Zheng, J. B-Ultrasonic Pig Fat Content DetectionBased on Deep Learning. J. Chongqing Univ. Technol. Nat. Sci. 2019, 33, 112–116. [Google Scholar]
19. Zhao, X.; Pong, Y.; Li, Y. Mobile phone evaluation system for grading beef marbling based ondeep learning. Trans. Chin. Soc. Agric. Eng. 2020, 36, 250–256. [Google Scholar] [CrossRef]
20. Liu, Z.; Du, H.; Lao, F.D.; Shen, Z.C.; Lv, Y.H.; Zhou, L.; Jiang, L.; Liu, J.F. PIMFP: An accurate tool for the prediction of intramuscular fat percentage in live pigs using ultrasound images based on deep learning. Comput. Electron. Agric. 2024, 217, 108552. [Google Scholar] [CrossRef]
21. Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
22. Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
23. Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. In Graphics Gems; Heckbert, P.S., Ed.; Elsevier: Amsterdam, The Netherlands, 1994; pp. 474–485. [Google Scholar]
24. Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
25. Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
26. Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
27. Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; p. 10. [Google Scholar]
28. Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
29. Sebastian, B.; Unnikrishnan, A.; Balakrishnan, K. Gray Level Co-Occurrence Matrices: Generalisation and Some New Features. arxiv 2012, arXiv:1205.4831. [Google Scholar]
30. Zhang, X.; Zhang, Y.; Shang, Y.X.; Shi, K.Z.; Zhang, Y.J.; Wang, J.; Chen, Y. Ultrasonic nondestructive examination of intramuscular fat using ultrasonic for live Congjiang pig. Trans. Chin. Soc. Agric. Eng. 2018, 34, 187–191. [Google Scholar]
31. Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
32. Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
33. Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
34. Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arxiv 2018, arXiv:1803.01271. [Google Scholar]
35. Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
36. Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arxiv 2014, arXiv:1409.1556. [Google Scholar]
37. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 770–778. [Google Scholar]
38. Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arxiv 2017, arXiv:1704.04861. [Google Scholar]
39. Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
40. Ahmed, I.; Zabit, U. Fast estimation of feedback parameters for a self-mixing interferometric displacement sensor. In Proceedings of the 2017 International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 8–9 March 2017; pp. 407–411. [Google Scholar]
41. Gelman, A.; Goodrich, B.; Gabry, J.; Vehtari, A. R-squared for Bayesian Regression Models. Am. Stat. 2019, 73, 307–309. [Google Scholar] [CrossRef]
42. Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
43. Spearman, C. The Proof and Measurement of Association between Two Things. Am. J. Psychol. 1904, 15, 72. [Google Scholar] [CrossRef]
44. Edwards, A.W.F. Galton, Karl Pearson and Modern Statistical Theory. In Sir Francis Galton, FRS; Keynes, M., Ed.; Palgrave Macmillan: London, UK, 1993; pp. 91–107. [Google Scholar]

Liu W, Liu T, Zhang J, Wang F. Two-Stage Multimodal Method for Predicting Intramuscular Fat in Pigs. Agriculture. 2024; 14(10):1843. https://doi.org/10.3390/agriculture14101843
Перевод статьи «Two-Stage Multimodal Method for Predicting Intramuscular Fat in Pigs» авторов Liu W, Liu T, Zhang J, Wang F., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)