Сокращая затраты: как облегченная сеть P2P-CNF повышает точность агроанализа при меньших вычислительных ресурсах
Точное определение количества и местоположения растений риса играет ключевую роль в таких сельскохозяйственных задачах, как точное внесение удобрений и прогнозирование урожайности. С быстрым развитием глубокого обучения было предложено множество моделей для подсчета растений. Однако многие из этих моделей содержат большое количество параметров, что делает их непригодными для развертывания в условиях сельского хозяйства с ограниченными вычислительными ресурсами. Для решения этой проблемы мы предлагаем новый метод прореживания — Cosine Norm Fusion (CNF), а также облегченную технику слияния признаков — Depth Attention Fusion Module (DAFM).
Аннотация
На основе этих инноваций мы модифицируем существующую сеть P2PNet, чтобы создать P2P-CNF — облегченную модель для подсчета растений риса. Процесс начинается с прореживания обученной сети с использованием CNF, за которым следует интеграция нашего облегченного модуля слияния признаков DAFM. Для проверки эффективности нашего метода мы провели эксперименты на наборах данных по рису, включая набор данных RSC-UAV, полученный с помощью БПЛА. Результаты показывают, что наш метод достигает MAE 3,12 и RMSE 4,12, используя только 33% параметров исходной сети. Мы также протестировали наш метод на других наборах данных по подсчету растений, и результаты демонстрируют, что наш метод обеспечивает высокую точность подсчета при сохранении облегченной архитектуры.
1. Введение
Рис — ключевая продовольственная культура в мировом масштабе, тесно связанная как с продовольственной безопасностью, так и с экономической стабильностью [1]. Исследования риса имеют важнейшее значение для повышения сельскохозяйственной производительности и продвижения технологических инноваций. Точный подсчет рисовых сеянцев необходим для разработки последующих стратегий управления, таких как пересадка и применение воды и удобрений [2]. Такой подсчет позволяет оценивать плотность, эффективность и общее качество роста на рисовых полях [3]. Дополнительно, ранний подсчет растений способствует мониторингу генетических вариаций по полям, что в частности ключевой в крупномасштабных селекционных экспериментах [4]. В настоящее время подсчет риса в основном опирается на ручной отбор проб и статистику [5], что включает выбор конкретных участков для обследования. Однако этот традиционный метод является трудоемким, отнимает много времени и часто дает результаты, нерепрезентативные для всего поля. Ручной подсчет подвержен человеческим ошибкам и может наносить ущерб окружающей среде рисового поля. Оптимальным решением была бы разработка модели, способной автоматически подсчитывать растения риса, тем самым повышая точность и эффективность.
В последние годы развитие технологий глубокого обучения значительно повысило разработку моделей подсчета растений на основе изображений. В основном под руководством сверточных нейронных сетей, эти модели глубокого обучения стимулировали существенные технологические достижения в области подсчета растений. В отличие от традиционных моделей машинного обучения, которые полагаются на выбранные вручную фенотипические признаки, такие как цвет и текстура, модели глубокого обучения используют свои высокие возможности извлечения признаков. Это позволяет им эффективно различать сложные полевые условия и фенотипы растений, приводя к впечатляющим показателям в различных сценариях. Подобно приложениям для подсчета толпы и транспортных средств, модели подсчета растений в основном используют карты плотности и регрессионные боксы для точного количественного определения.
Мотивация. Хотя в моделях подсчета риса были достигнуты значительные успехи, сохраняется несколько нерешенных проблем. Во-первых, многие существующие модели подсчета растений характеризуются чрезмерно большим количеством параметров, требующих значительных вычислительных ресурсов. Это требование делает их непрактичными в условиях сельского хозяйства с ограниченными ресурсами, в частности при развертывании на периферийных устройствах с ограниченными вычислительными возможностями. Дополнительно, распространенные методы, такие как подходы на основе карт плотности [6,7], основаны на покомпонентных регрессионных расчетах, которые не предоставляют конкретной информации о местоположении отдельных растений. Это ограничение затрудняет детальный анализ на уровне растений, который ключевой для точных сельскохозяйственных мероприятий. Наконец, изменчивость морфологии растений на рисовых полях, особенно на разных стадиях роста, создает дополнительные проблемы. Разные сорта риса проявляют отличительные фенотипические признаки, которые могут заметно влиять на точность методов подсчета и локализации.
Появление P2PNet [8] означает ключевой сдвиг от традиционных методов подсчета. Эта point-to-point архитектура отказывается от традиционных карт плотности и методов на основе детектирования; следовательно, она была принята в качестве базовой модели. Работы, такие как работы [9,10], продемонстрировали эффективные адаптации P2PNet для специализированных приложений подсчета растений. Несмотря на эти достижения, расширенные версии P2PNet остаются чрезмерно громоздкими для развертывания в средах с ограниченными вычислительными ресурсами. Более того, модуль слияния признаков P2PNet, который лишь объединяет признаки среднего и глубокого уровней, недостаточен для адекватного захвата различных характеристик растений, присутствующих в сложных условиях рисового поля. Это ограничение подчеркивает необходимость более комплексного подхода к интеграции признаков для повышения применимости и эффективности модели.
Вклад. Для решения вышеуказанных проблем в данной работе представлены три основных вклада:
- Во-первых, в данной статье представлен P2P-CNF, облегченная модель подсчета риса, оптимизированная для сельскохозяйственных условий с ограниченными ресурсами. Уменьшенный размер параметров P2P-CNF обеспечивает его пригодность для расширенных задач подсчета и позиционирования, способствуя эффективному развертыванию в полевых условиях, где вычислительные ресурсы ограничены.
- Во-вторых, предложен новый метод прореживания, Cosine-Norm Fusion (CNF), разработанный для уменьшения количества параметров модели при сохранении максимальной информации от исходной модели. Эта техника прореживания позволяет модели сохранять целостность производительности, обеспечивая минимальную потерю функциональной эффективности.
- И наконец, разработан Depth-Attentive Fusion Module (DAFM), облегченный модуль слияния признаков, который значительно улучшает общую производительность модели. DAFM использует разделяемую по глубине свертку в сочетании с механизмом линейного самовнимания для достижения высоких результатов при сохранении малого количества параметров.
2. Обзор литературы
Этот раздел обсудит соответствующие работы с двух сторон.
2.1. Прореживание сети
В последние годы неуклонное развитие вычислительных возможностей стимулировало значительные достижения в глубоком обучении в различных областях [11], охватывающих компьютерное зрение [12,13,14,15,16] и обработку естественного языка [17,18], что привело к прорывным результатам. Примечательно, что современные визуальные модели, такие как vision transformers, имеют количество параметров до 632 миллионов, в то время как традиционные сверточные нейронные сети (CNN), такие как ResNet-150 и VGG16, имеют 230 миллионов и 528 миллионов параметров соответственно [19,20,21,22,23,24]. Эти высокие количества параметров значительно увеличивают вычислительные затраты, тем самым требуя современного оборудования для развертывания.
Для решения этих проблем были приложены значительные усилия для усовершенствования моделей с помощью различных методов оптимизации, причем прореживание сети стало в частности эффективной стратегией [25,26]. Прореживание сети систематически устраняет веса и параметры, которые минимально влияют на выход модели, тем самым минимизируя снижение производительности. Этот процесс в основном классифицируется на структурированное [27,28,29] и неструктурированное прореживание [30,31]. Неструктурированное прореживание [30,32,33,34] направлено на тщательную оптимизацию модели путем удаления конкретных параметров или соединений, хотя оно часто требует специализированного оборудования для полной эффективности. Напротив, структурированное прореживание [28,35,36] нацелено на целые нейроны или каналы, сохраняя архитектурную структуру сети и облегчая развертывание на стандартном оборудовании без необходимости в специализированной поддержке. Эта дихотомия в методологиях прореживания подчеркивает ключевой аспект современного глубокого обучения — баланс сложности модели с вычислительной эффективностью, что ключевой для практического развертывания на различных платформах.
Значительные успехи были достигнуты в области прореживания сети, в частности в методологиях для прореживания и слияния фильтров внутри сверточных нейронных сетей. He и др. [37] исследовали избыточность фильтров на основе их взаимосвязей внутри одного слоя, впоследствии разработав подход Filter Pruning via Geometric Median (FPGM) для эффективного устранения этих избыточностей. Одновременно Wan [38] разработал алгоритм прореживания на основе корреляции (COP), который повышает простоту модели путем нормализации и сравнения фильтров на различных уровнях с универсальным масштабом.
Включение слоев пакетной нормализации (BN) [39], которые распространены в современных CNN, дополнительно повлияло на стратегии прореживания. Liu и др. [40] использовали параметр гамма в слоях BN в качестве масштабирующего фактора, интегрируя норму L1 в функцию потерь, чтобы вызвать разреженность и выборочно проредить каналы с минимальными значениями гамма. Расширяя эту структуру, You и др. [41] представили подход Tick Lock, применяя разложение Тейлора для оценки значимости значений гамма в слоях BN и облегчая удаление несущественных каналов. Дополнительно, Zhuang и др. [42] предложили поляризационную регуляризацию (PR), аналогичную методу [40], но с тонким подходом, который избегает неразборчивой разреженности, нацеливаясь только на менее ключевые каналы и усиливая значения гамма важнейших каналов. Дополнительный штрафной член был включен для улучшения эффективности нормы L1. Аналогично, структурированное прореживание каналов (SCP) [43] методологически интегрирует процесс прореживания со слоями BN и функциями активации ReLU, иллюстрируя передовую технику для оптимизации эффективности сети и функциональности.
Эти инновации подчеркивают тенденцию к сложным, адаптивным методам прореживания, которые не только уменьшают вычислительные накладные расходы, но и сохраняют или улучшают производительность модели в различных операционных контекстах.
2.2. Подсчет растений
Подсчет и локализация растений были центральными областями исследований в сельскохозяйственных исследованиях, учитывая их ключевой важность как для сельскохозяйственных экспериментов, так и для производственных процессов [44,45]. Более ранние подходы, ограниченные вычислительной мощностью, в основном полагались на методы машинного обучения для достижения подсчета растений [46,47,48]. Эти методы сильно зависели от ручного извлечения фенотипических признаков растений, требуя значительной разработки признаков, что в конечном итоге ограничивало устойчивость этих моделей в сложных реальных условиях.
С появлением глубокого обучения были достигнуты значительные успехи в преодолении этих ограничений. В настоящее время существуют две основные категории методологий подсчета растений: алгоритмы детектирования на основе регрессионных боксов [49] и алгоритмы на основе карт плотности [50,51]. Благодаря достижениям в методах обнаружения объектов, таких как серия YOLO [15] и Faster R-CNN [16], алгоритмы для подсчета и локализации растений достигли значительных прорывов. Например, Buzzy и др. [52] успешно реализовали функции обнаружения и распознавания листьев деревьев с помощью YOLO v3, в то время как Wang и др. [53] разработали систему обнаружения и подсчета цветов, интегрировав модуль Ghost и голову детектирования P2 в YOLOv8. Аналогично, Zhang и др. [54] использовали изображения плотных падубов, снятые с БПЛА, и построили сеть YOLOX, которая продемонстрировала высокую производительность в различных масштабах и сценах. Chen [55] расширил эту работу, используя дроны для съемки сеянцев сорго на разной высоте, проверив результаты подсчета с помощью методов опорных векторов (SVM) наряду с YOLOv5 и YOLOv8, обнаружив, что YOLOv5 достигает высокой точности.
Параллельно, алгоритмы на основе карт плотности также широко применялись в приложениях подсчета растений. Серия TasselNet [56,57,58] эффективно использовала карты плотности в сочетании с методами регрессии для точного подсчета метелок кукурузы. Bai и др. [6,7] представили Ricenet и Rpnet, используя механизмы внимания и потерю положительно-отрицательных примеров для подсчета растений риса в сложных полевых условиях. Дополнительно, Wu и др. [59] сочетали изображения с БПЛА с полностью сверточными сетями и картами плотности для подсчета рисовых сеянцев, предоставляя перспективный подход для оценки урожайности. Предложенная Liu и др. [60] IntegrateNet, новая архитектура, использующая локально контролируемые карты плотности и локальный подсчет, продемонстрировала значительные улучшения в точности подсчета кукурузы.
3. Материалы и методы
3.1. Сбор RGB-изображений на основе БПЛА
В этом исследовании для мониторинга роста риса использовалась RGB-съемка с БПЛА. Полеты БПЛА проводились над рисовым полем, расположенным в Чанше, провинция Хунань, Китай, характеризующемся субтропическим муссонным климатом.
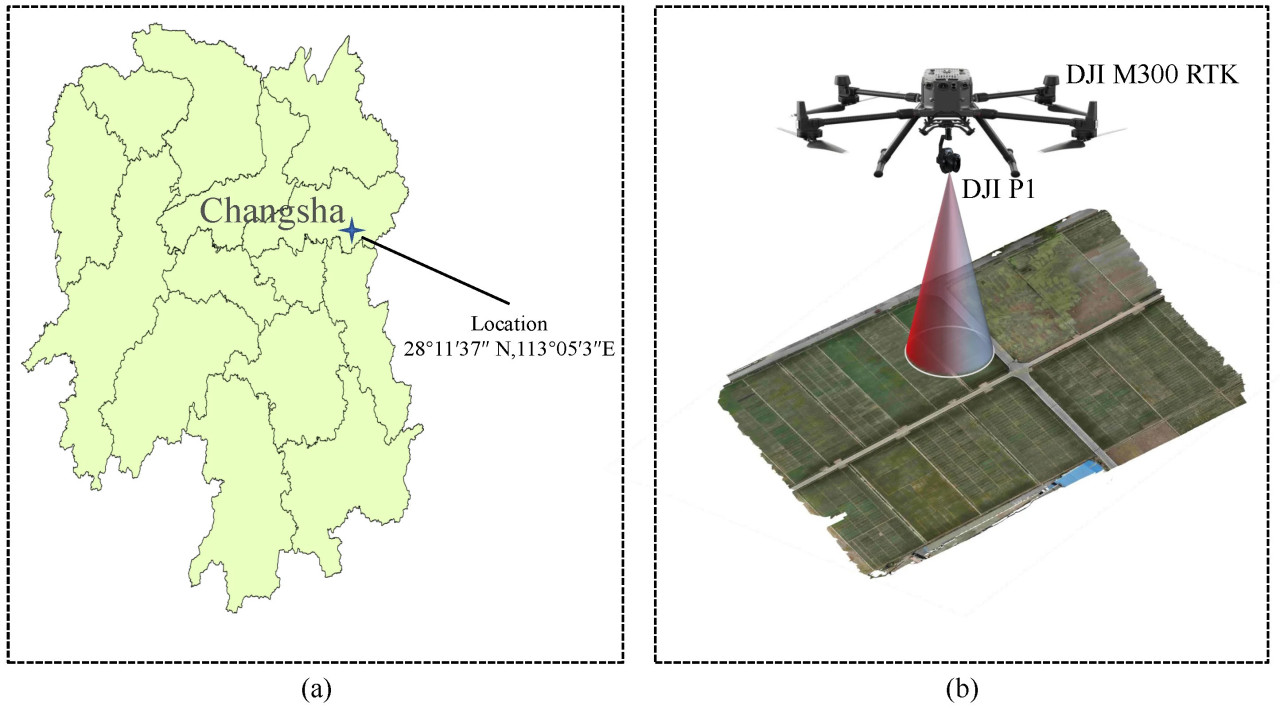
Рисунок 1. (a) Место сбора данных. (b) Оборудование для сбора и соответствующие захваченные изображения.
Данные собирались с мая 2024 года с использованием дрона DJI M300 RTK, оснащенного камерой DJI P1. Полеты планировались ежедневно с 8:00 до 10:00 утра для обеспечения оптимальных условий освещения, предоставляемых достаточным солнечным светом. БПЛА работал на высоте 15 м и скорости 3 м в секунду. Встроенная RGB-камера, расположенная перпендикулярно земле, захватывала высокого разрешения изображения с фокусным расстоянием 35 мм. Захват изображений был стратегически спланирован для достижения 80% фронтального перекрытия и 70% бокового перекрытия между последовательными изображениями, обеспечивая полное покрытие обследуемой области. Результирующие изображения имели разрешение 8192 × 5460 пикселей, облегчая детальный анализ стадий развития культуры.
3.2. Набор данных для подсчета растений риса, собранный с помощью БПЛА
Для решения вычислительных проблем, вызванных высоким разрешением исходных изображений, полученных с помощью БПЛА, изображения были обработаны для выделения определенных стадий кущения риса. Каждое изображение было систематически обрезано до единого размера 1400 × 1400 пикселей, обеспечивая целенаправленный набор данных, подходящий для задач подсчета риса. Этот курируемый набор данных, обозначенный как RSC-UAV (Rice Seedling Counting-UAV), включает 401 высококачественное изображение растений риса на разных стадиях кущения, проиллюстрированных на рисунке 2. Каждое изображение было тщательно размечено с помощью программного обеспечения LabelMe(3.11.2) для идентификации центральной точки отдельных растений риса. Процесс разметки включал ручное обозначение центральной точки каждого рисового сеянца на изображении путем визуального осмотра, обеспечивая точность размещения аннотации. Эти центральные точки служат эталонными данными (ground truth) для обучения и оценки модели подсчета риса. Ground truth относится к размеченным вручную данным, которые представляют правильный ответ для текущей задачи, и в данном случае состоят из точно размеченных центральных точек каждого растения риса на изображении. Они используются для оценки производительности модели путем сравнения ее предсказаний с этими размеченными вручную координатами. Набор данных был разделен на обучающий набор, состоящий из 280 изображений, которые в совокупности содержат 49 428 размеченных центральных точек, причем на каждом изображении представлено от 43 до 212 растений риса. Тестовый набор состоит из 121 изображения с общим количеством 20 340 центральных точек, каждое изображение содержит от 67 до 217 растений риса. Рисунок 3 иллюстрирует распределение обучающего и тестового наборов, предоставляя визуальный обзор состава набора данных и плотности аннотаций растений риса.

Рисунок 2. Образцы растений риса, собранные в разные даты.

Рисунок 3. Распределение обучающих и тестовых наборов данных.
3.3. Другие наборы данных
Набор данных URC: Набор данных URC (UAV-based Rice Plant Counting), собранный с 2018 по 2019 год, является специализированным набором данных для подсчета растений риса [6]. Он состоит из 355 исходных изображений высокого разрешения, каждое размером 5472 на 3648 пикселей. Внутри каждого изображения растения риса размечены по их центральным точкам. Набор данных разделен на обучающий набор из 246 изображений и тестовый набор из 109 изображений, причем отдельные изображения содержат от 84 до 1125 растений риса.
Набор данных WED: Набор данных WED (Wheat Ear Detection), предложенный Madec и др. [4], состоит из изображений разрешением 6000 на 4000, содержащих более 20 различных генотипов пшеницы. Каждое изображение обычно содержит от 80 до 170 колосьев пшеницы. Из-за его аннотаций ограничивающими рамками мы преобразовали их в аннотации центральных точек, чтобы лучше соответствовать нашей методологии.
Набор данных MTC: Набор данных MTC (Maize Tassel Counting), предложенный Lu и др. [56], предназначен для подсчета метелок кукурузы. Он охватывает изображения, полученные с четырех экспериментальных полей в период с 2010 по 2015 год, всего 361 изображение, разделенных на 186 для обучения и 175 для тестирования. Изображения изначально имеют разрешения 3648 × 2736, 4272 × 2848 или 3456 × 2304 соответственно.
3.4. Метод
3.4.1. Определение задачи
Пусть I обозначает изображение рисового поля, содержащее N сеянцев, где 𝑟𝑖=(𝑥𝑖,𝑦𝑖),𝑖∈{1,…,𝑁} представляет координаты центра i-го рисового сеянца на изображении. Полный набор всех центральных точек обозначается как ℛ={𝑟𝑖∣𝑖∈{1,…,𝑁}}. Учитывая модель подсчета рисовых сеянцев 𝑓(𝐼;𝜽𝑓), цель подсчета и локализации рисовых сеянцев состоит в том, чтобы идентифицировать и подсчитать все сеянцы на изображении, выраженное как {ℛ̂,𝒫̂}=𝑓(𝐼;𝜽𝑓). В этой формулировке ℛ̂={𝑟̂𝑗∣𝑗∈{1,…,𝑀}} и 𝒫̂={𝑝̂𝑗∣𝑗∈{1,…,𝑀}} обозначают предсказанные координаты центра сеянцев и их соответствующие оценки достоверности. Здесь 𝜽𝑓 представляет вектор обучаемых параметров модели, а M — количество предсказанных сеянцев.
В этом исследовании наша цель — сделать модель 𝑓(𝜽𝑓) более легковесной, используя стратегии прореживания, в частности сосредоточившись на уменьшении количества параметров и вычислительных затрат при сохранении производительности в подсчете и локализации рисовых сеянцев. Вводя методы прореживания, мы стремимся оптимизировать 𝜽𝑓 так, чтобы 𝑓(𝜽𝑓) стала более эффективной и развертываемой, в частности в сельскохозяйственных условиях с ограниченными ресурсами.
3.4.2. P2P-CNF
P2P, новая сеть для подсчета толпы, разработанная Tencent YouTu Laboratory, отличается от традиционных алгоритмов детектирования, основанных на картах плотности и регрессионных боксах. Она использует архитектуру сети "точка-точка", которая упрощает процесс детектирования, напрямую выводя набор координат точек, представляющих центр объектов. Архитектура сети P2Pnet состоит из трех основных компонентов: экстрактора признаков, модуля слияния признаков и двухветвевой головы предсказания. Экстрактор признаков использовал бэкбон VGG16_BN для получения представлений признаков из входного изображения. На последующем этапе модуль слияния признаков интегрирует эти признаки как на глубоком, так и на среднем уровнях, направляя их к предсказательным головкам — одна для регрессии, определяющей координаты целей, и другая для классификации, оценивающей их уровни достоверности.
P2P-CNF — это передовая легковесная модель, специально разработанная для подсчета риса, предназначенная для реализации в сельскохозяйственных условиях с ограниченными ресурсами при сохранении оптимальной производительности модели. Для достижения баланса между эффективностью модели и точностью подсчета растений риса было интегрировано несколько улучшений:
— Прореживание бэкбон-сети: Мы представляем Cosine-Norm Fusion (CNF), методологию прореживания, которая минимизирует потерю информации, обеспечивая легкость модели при сохранении высокой точности для подсчета риса.
— Облегченный модуль слияния признаков: Улучшенный модуль слияния признаков DAFM значительно сокращает количество параметров, повышая способность модели захватывать и интегрировать многоуровневую информацию эффективно. Это позволяет улучшить распознавание растений риса в различных полевых условиях.
Архитектура P2P-CNF изображена на рисунке 4. Изначально обучается исходная сеть P2P, после чего применяется наш метод CNF для прореживания этой обученной сети. После процесса тонкой настройки получается более компактная и эффективная сеть. Блок-схема процесса иллюстрируется на рисунке 5.
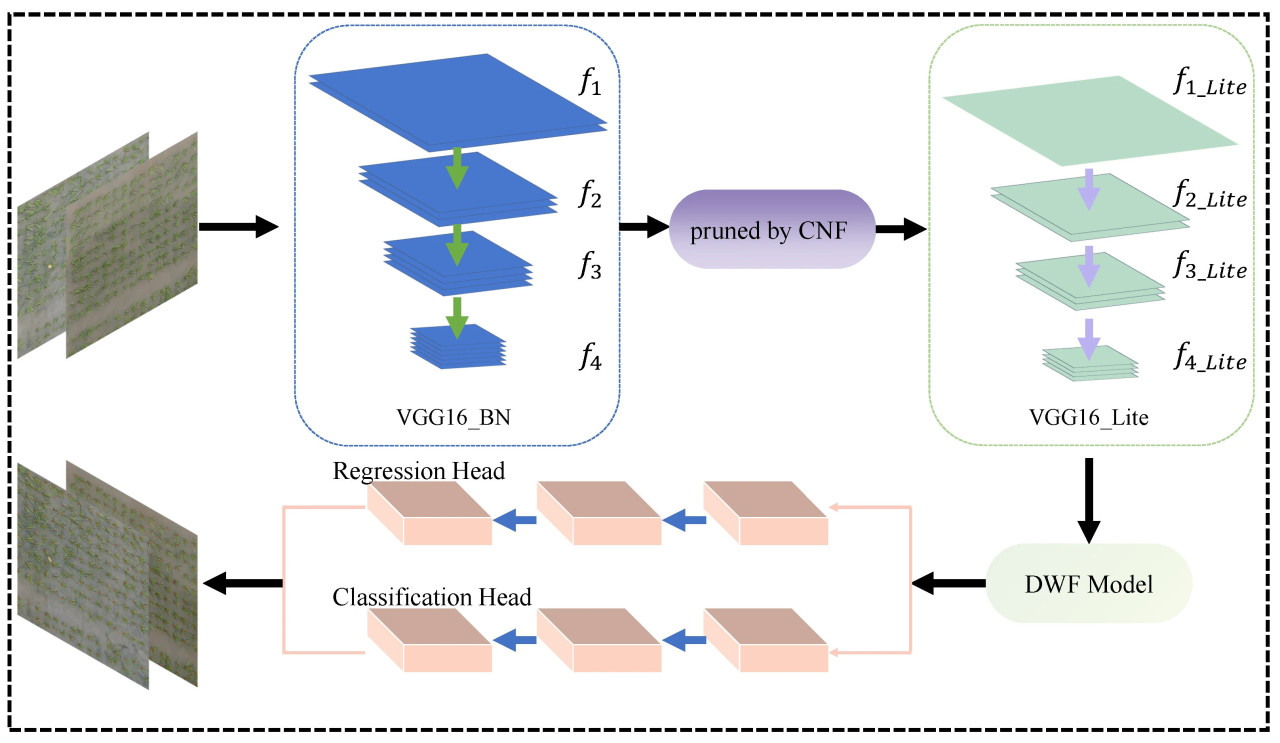
Рисунок 4. Общая архитектура P2P-CNF.

Рисунок 5. Блок-схема процедуры уменьшения сети.
Это сокращение значительно уплотняет объем сети, что приводит к более сжатому представлению информации. Уточненные карты признаков 𝑓1 до 𝑓4 затем подаются в наш Depth-Attentive Fusion Module (DAFM). Внутри DAFM признаки постепенно объединяются от более глубоких к более поверхностным слоям. Перед каждым шагом слияния к каждому слою применяется механизм линейного внимания для улучшения извлечения эффективной информации, тем самым оптимизируя использование многоуровневых слоев признаков. Многоуровневые признаки, которые объединены, затем передаются для выполнения задач регрессии и классификации на голове предсказания. Во время процесса предсказания используется алгоритм Венгерского (Hungarian algorithm) для сопоставления предсказанных точек со сгенерированными точками один к одному, как подробно описано в разделе 3.4.1. На этом этапе генерируется матрица 𝑁×𝑀, где каждый элемент матрицы 𝑒𝑖𝑗 определяется следующим образом:
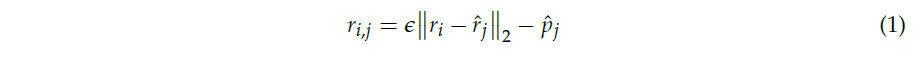
В формулировке 𝜖 служит весовым фактором для модуляции влияния расстояния L2. Переменная 𝑝̂𝑗 обозначает уровень достоверности, связанный с предсказанным положением 𝑐̂𝑗. Впоследствии оптимальное сопоставление определяется путем оценки значений внутри матрицы.
Благодаря принятию нашего метода прореживания CNF, норма L1 используется для создания разреженности в слоях пакетной нормализации (BN). Этот подход приводит к указанной функции потерь:
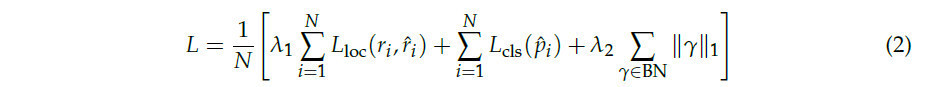
где 𝐿loc — это регрессионные потери, рассчитанные с использованием евклидова расстояния между фактическими и предсказанными позициями, а 𝐿cls представляет собой потери классификации, смоделированные перекрестной энтропией. Член ∥𝛾∥1 налагает штраф за разреженность на коэффициенты 𝛾 внутри слоев BN, контролируемый 𝜆2.
3.4.3. Cosine-Norm Fusion
Это исследование представляет Cosine-Norm Fusion (CNF), новый подход, разработанный для прореживания, чтобы существенно уменьшить количество параметров в нейронных сетях, как показано на рисунке 6. Вдохновленный применением Liu и др. [40] масштабирующих факторов для разреженности каналов и динамического слияния токенов Kim и др. [61] для оптимизации архитектур трансформеров, CNF интегрирует разреженность на уровне каналов с процессами слияния токенов внутри сверточных нейронных сетей. Этот метод стратегически использует слияние норм в процессе прореживания для минимизации потери информации, тем самым сохраняя вычислительную эффективность без значительного ущерба точности. CNF решает постоянную проблему балансирования производительности с компактностью модели, предлагая решение, которое является одновременно инновационным и практичным для передовых приложений нейронных сетей.
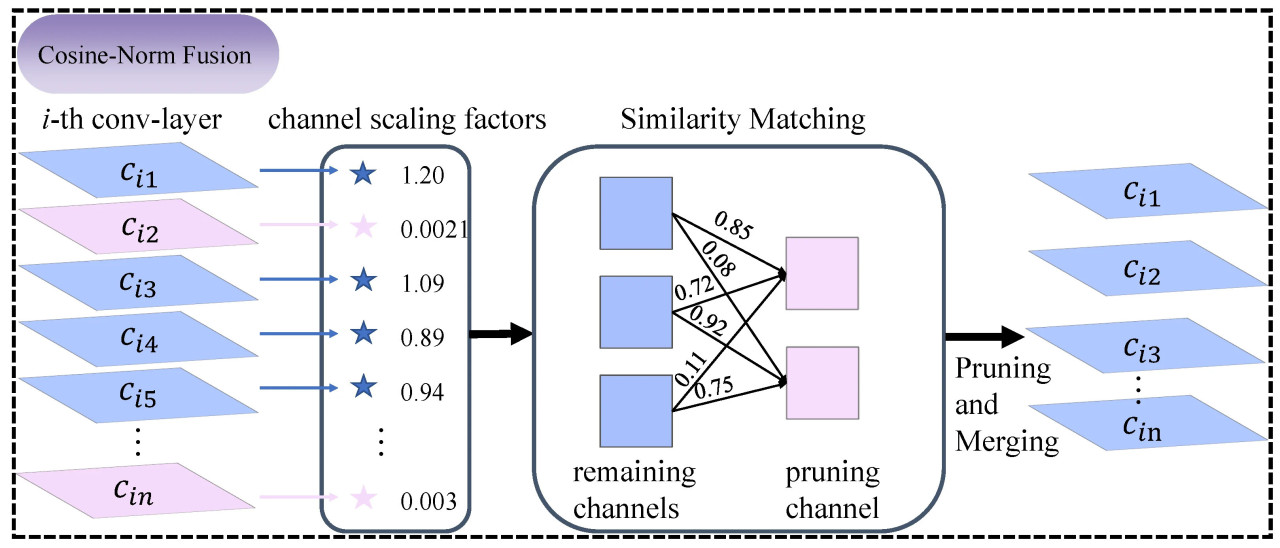
Рисунок 6. В процессе прореживания, используемом Cosine Norm Fusion (CNF), масштабирующие факторы (𝛾) получаются из слоев пакетной нормализации (BN), и регуляризация реализуется на этих факторах во время обучения. Когда каналы, признанные менее важными, становятся разреженными, вычисляется косинусное сходство между прореженными и оставленными каналами, чтобы облегчить их слияние.
CNF следует процессу прореживания, установленному [40], интегрируя как норму L1, так и масштабирующий фактор 𝛾 из слоев пакетной нормализации (BN) в качестве регуляризационных членов в функцию потерь. Используя быструю сходимость и высокие возможности обобщения слоя BN, прореживание оптимизируется путем акцентирования неважных каналов. В слое BN, учитывая вход 𝑥𝑖𝑛, выход 𝑥𝑜𝑢𝑡 и мини-пакет ℬ, преобразование определяется следующим образом:
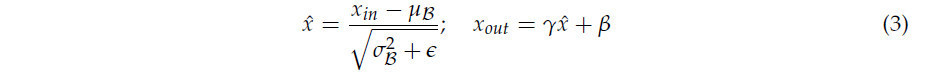
С учетом этого, наша цель оптимизации определяется так:
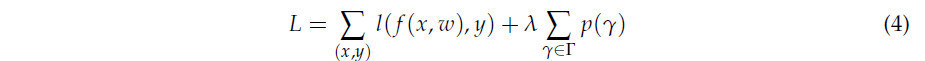
где x и y соответственно представляют вход и цель сети, 𝜇ℬ и 𝜎ℬ — среднее значение и стандартное отклонение значений активации на входе по мини-пакету ℬ, а W представляет веса сети. Функция 𝑝(·) обозначает норму L1, используемую в качестве штрафного члена, и применяется субградиентный спуск для разрежения масштабирующего фактора 𝛾. Параметр 𝜆 — это балансирующий фактор между основной потерей и регуляризационными членами, в то время как 𝛾 и 𝛽 — это обучаемые параметры в слое пакетной нормализации. Для достижения более компактной сети прореживание каналов применяется на основе глобального порога по всем слоям. Конкретно, порог определяется как определенный процентиль всех значений масштабирующего фактора в сети. Например, установив пороговый процентиль на 50%, прореживаются 50% каналов с наименьшими масштабирующими факторами. Этот подход позволяет сократить количество параметров и требований к памяти во время выполнения, а также уменьшить вычислительные накладные расходы, что приводит к оптимизированной для эффективности модели.
Затем косинусное сходство между прореженными каналами и оставленными каналами на том же уровне сети итеративно вычисляется для идентификации пар для слияния. Принимается метод слияния, предложенный [61], с тем отличием, что мы ввели вес для каждого объединенного канала. Чтобы облегчить это, строится двудольный граф, где ребра представляют веса сходства между прореженными и оставленными каналами. Используя алгоритм Венгерского, определяются пары каналов с высшими весами сходства, указывающими на наиболее похожие каналы, и впоследствии выполняется слияние норм. Этот процесс определяется следующими операциями:
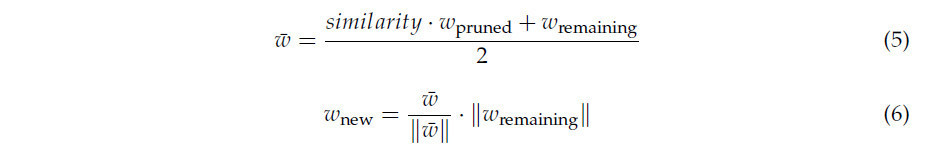
Здесь 𝑤 представляет промежуточный объединенный вес, рассчитанный как среднее значение взвешенного по сходству прореженного канала и оставленного канала. Конечный вес 𝑤new затем нормализуется, чтобы соответствовать величине 𝑤remaining, сохраняя масштаб оставленного канала, включая информацию из прореженного канала.
3.4.4. Depth-Attentive Fusion Module
В исходном модуле слияния признаков P2P слияние было ограничено тремя модулями признаков из среднего и глубокого слоев, игнорируя ценную информацию, присутствующую в поверхностных слоях. Дополнительно, использование обычных сверточных операций в процессе слияния вводило значительные накладные расходы по параметрам. Для устранения этих ограничений и повышения эффективности модели в данной статье представлен Depth Attentive Fusion Module (DAFM). Как изображено на рисунке 7, DAFM извлекает и интегрирует четыре модуля признаков, охватывающих от поверхностных до глубоких слоев из бэкбон-сети, значительно обогащая способность представления признаков модели.
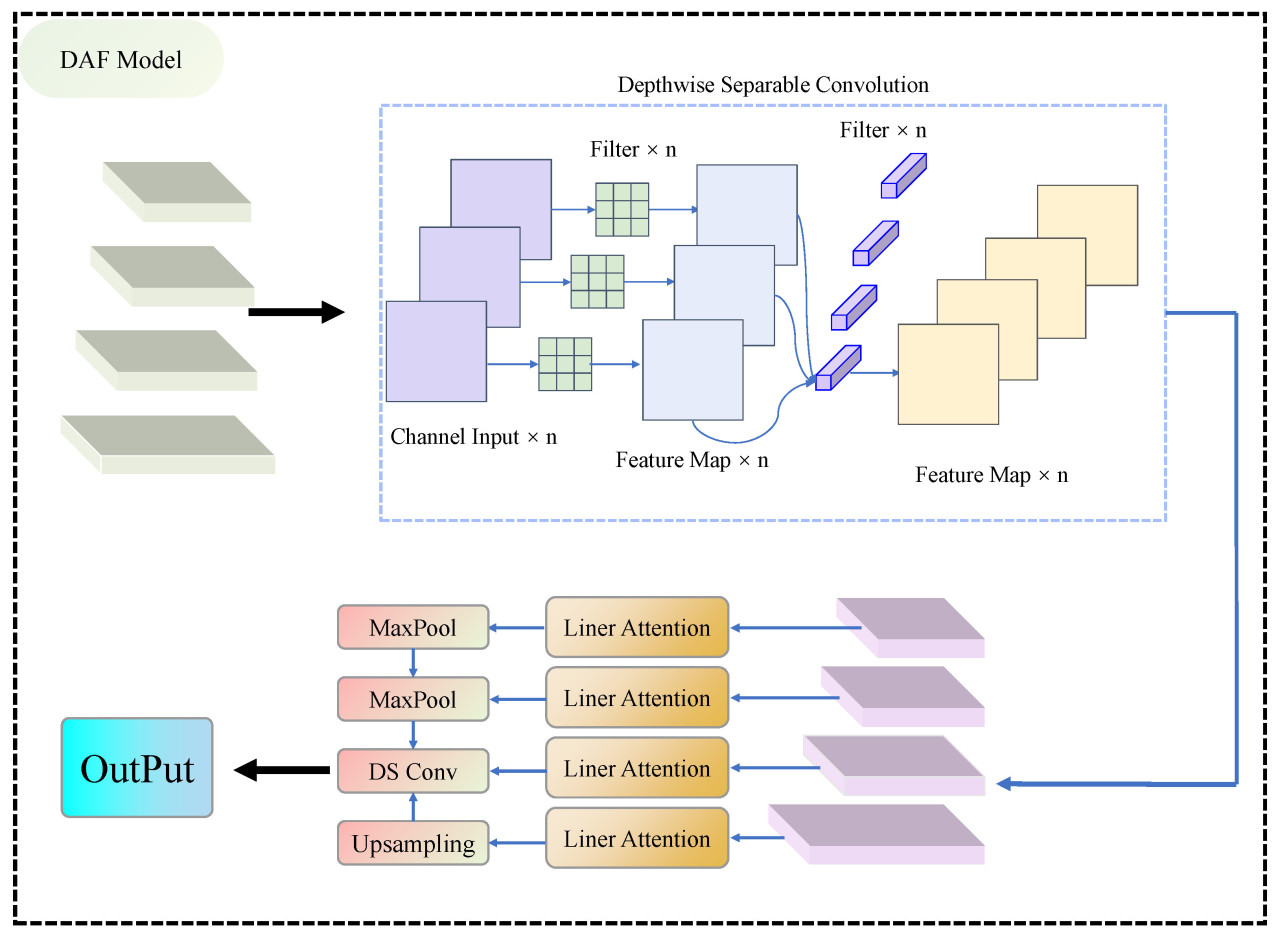
Рисунок 7. Подробный процесс Depth-Attentive Fusion Module (DAFM).
Во время процесса слияния на каждом слое карты признаков сначала проходят разделяемую по глубине свертку, которая регулирует размерность каналов. Эта техника свертки, состоящая из глубинной и поточечной сверток, снижает вычислительные требования, отдельно свертывая каждый входной канал в фазе глубинной свертки и впоследствии комбинируя эти выходы через поточечную свертку. Этот метод резко сокращает вычислительную нагрузку, связанную с традиционными свертками. После этого обработанные модули признаков подаются в механизм линейного внимания. Эта упрощенная версия самовнимания гарантирует, что модель остается легковесной, сохраняя высокую производительность. Линейное внимание работает путем проецирования карты признаков в векторы запроса (q), ключа (k) и значения (v) с использованием полностью связанных слоев:
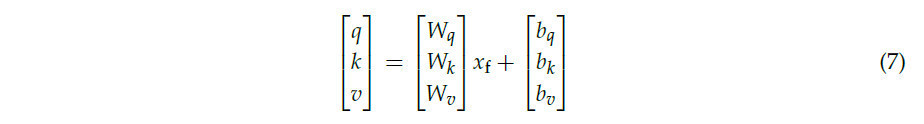
Затем он вычисляет исходные оценки внимания через скалярное произведение q и k, с последующей нормализацией с использованием функции softmax:
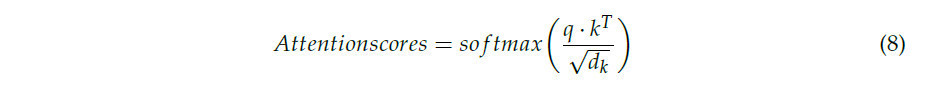
где 𝑑𝑘 — размерность векторов ключа, используемая для масштабирования скалярного произведения для стабилизации. Полученные оценки внимания используются для взвешивания и синтеза вектора значения v, позволяя модели динамически фокусироваться на наиболее релевантных признаках в соответствии с вычисленным вниманием:

Этот выход захватывает интегрированное представление входной карты признаков, существенно повышая способность модели распознавать ключевую информацию. Благодаря интеграции DAFM, наша модель достигает улучшенного слияния признаков, позволяя лучше различать отдельные растения риса в сложных полевых условиях, сохраняя при этом упрощенную архитектуру, тем самым повышая как эффективность, так и точность подсчета.
4. Результаты
4.1. Детали реализации и метрики оценки
Аналогично базовой модели P2PNet [8], во время фазы обучения использовался оптимизатор Adam. Настройки гиперпараметров для обучения были сохранены такими же, как в P2PNet, чтобы обеспечить сопоставимость между моделями. Бэкбон VGG16-BN был инициализирован с использованием предварительно обученных весов, предоставляемых PyTorch. Конкретная экспериментальная среда выполнения подробно описана в таблице 1.

Таблица 1. Конфигурация программного и аппаратного обеспечения для эксперимента.
Для оценки производительности модели использовались две обычно используемые метрики оценки: средняя абсолютная ошибка (MAE) и среднеквадратичная ошибка (RMSE). Эти метрики определяются следующим образом:
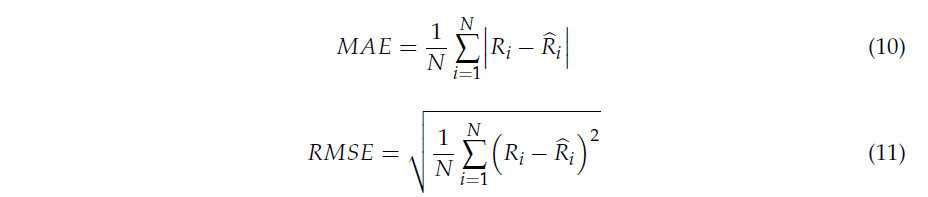
где 𝑅𝑖 представляет фактическое количество растений риса на i-м изображении, 𝑅̂𝑖 обозначает предсказанное количество растений риса для того же изображения, а N — общее количество изображений в тестовом наборе.
Мы используем точность (precision), полноту (recall) и F-меру для оценки показателей позиционирования растений. Их определения следующие:

В этом контексте TP относится к истинно положительным, FP к ложноположительным, а FN к ложноотрицательным.
4.2. Эксперимент на наборе данных RSC-UAV
В этом разделе метод сравнивается с несколькими современными техниками. Конкретно оцениваются как передовые методы фенотипирования растений (RiceNet и RPNet), так и основные модели подсчета популяции (CSRNet, FIDTM, PET и P2PNet), с результатами, представленными в таблице 2. Для этого сравнения мы установили порог разреженности на 60%, что означает, что 60% параметров прореживаются из бэкбон-сети. После прореживания общее количество параметров модели сокращается до 7.31 M, что составляет приблизительно 67% параметров исходной модели P2PNet. Как показано в таблице 2, метод достигает отличных результатов, сохраняя легковесную архитектуру модели. MAE и RMSE модели составляют 3.12 и 4.12 соответственно, что уступает только базовой модели P2PNet. По сравнению с P2PNet, модель отстает всего на 0.18 по MAE, но с значительно меньшим количеством параметров.
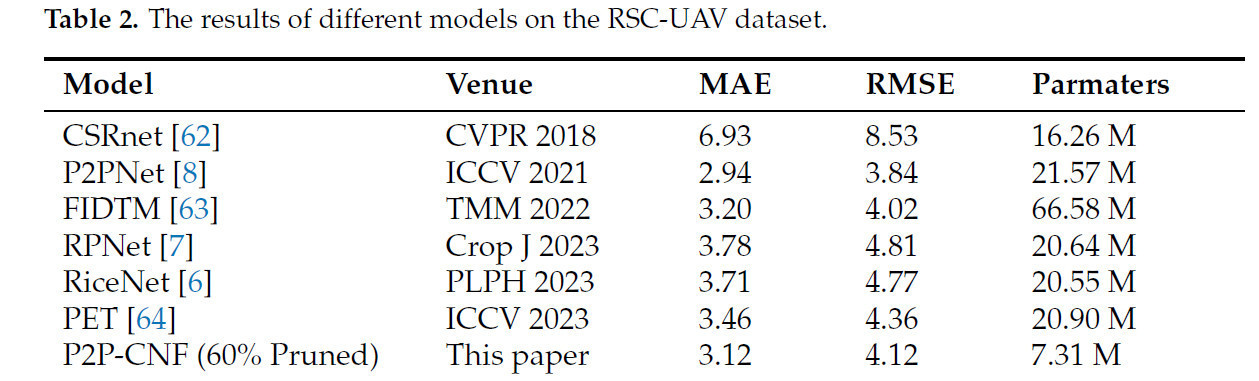
Таблица 2. Результаты различных моделей на наборе данных RSC-UAV.
При сравнении с более новыми моделями подсчета растений риса, RiceNet и RPNet, P2P-CNF демонстрирует явные преимущества. Конкретно, MAE снижается на 17%, а RMSE на 14% по сравнению с RPNet, в то время как количество параметров в модели составляет только 35% от RPNet. При сравнении с RiceNet, MAE уменьшается на 15%, а RMSE на 13%. Дополнительно, по сравнению с несколькими передовыми моделями подсчета толпы (CSRNet, PET и FIDTM), метод достигает лидирующей производительности, с лучшими MAE и RMSE среди этих моделей, сохраняя при этом меньшее количество параметров. Это во многом объясняется модулем DAFM, который интегрирует признаки на различных уровнях легковесным способом, позволяя точно идентифицировать растения риса с разными признаками. Для сравнения производительности локализации мы оценили точность (precision), полноту (recall) и F-меру для PET, FIDTM, P2PNet и P2P-CNF (прореженной на 60%). Как показано в таблице 3, точность, полнота и F-мера P2P-CNF (прореженной на 60%) достигли 95.5%, 96.0% и 95.7% соответственно, что сопоставимо с исходной моделью P2PNet. По сравнению с FIDTM и PET, наш метод продемонстрировал небольшое преимущество, со значительно меньшим количеством параметров.
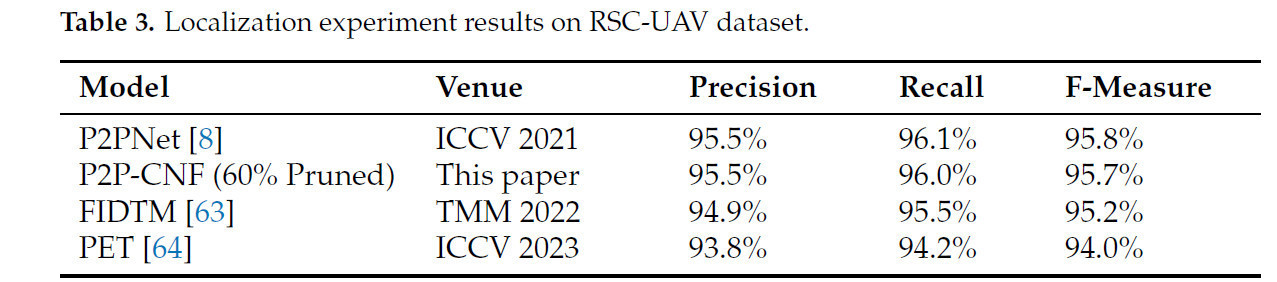
Таблица 3. Результаты эксперимента по локализации на наборе данных RSC-UAV.
Чтобы дополнительно продемонстрировать эффективность метода, визуализированы результаты детектирования этих моделей на рисунке 8. Рисунок 8a представляет эталонные данные (ground truth), за которыми следуют результаты детектирования от разных моделей, отображенные с рисунка 8b по h. Модель, P2P-CNF (прореженная на 60%), проявляет высокую точность распознавания на разных стадиях роста риса, в частности на поздней стадии кущения. Стоит отметить, что на последнем изображении рисунка 8b P2P-CNF успешно идентифицирует растения риса, которые расположены в шахматном порядке вместе, в то время как базовая модель P2PNet испытывает трудности в этом сценарии. Это улучшение можно объяснить легковесным многоуровневым модулем слияния признаков. В целом, метод достигает отличной производительности, сохраняя баланс между эффективностью модели и точностью, что делает его хорошо подходящим для сельскохозяйственных сред с ограниченными вычислительными ресурсами.
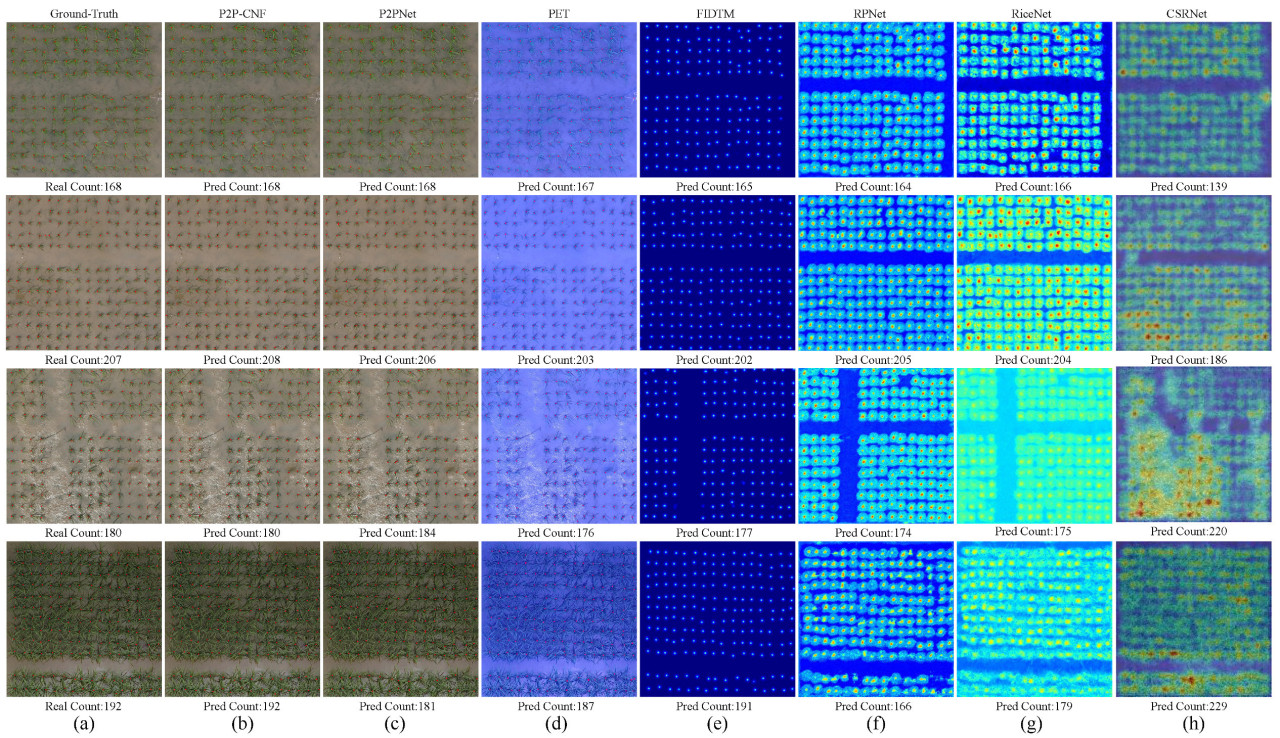
Рисунок 8. Представлена визуализация различных моделей на наборе данных RSC-UAV, где (a) показывает эталонные данные (ground truth). "Real count" относится к фактическому количеству точек; (b–h) показывают результаты, предсказанные различными моделями, где "pred count" указывает количество точек, предсказанное каждой моделью.
4.3. Влияние параметров прореживания на производительность набора данных RSC-UAV
В этой главе исследуется влияние уменьшения сети на производительность подсчета путем прореживания от 40% до 80% параметров бэкбона модели. Эксперименты проводились на наборе данных RSC-UAV, результаты суммированы в таблице 4. Непрореженная модель P2PNet дала MAE 2.94 и RMSE 3.84. Когда 40% и 50% параметров были прорежены из бэкбон-сети, получившиеся модели P2P-CNF имели 8.63 M и 10.42 M параметров соответственно. Эти модели показали небольшое влияние на MAE и RMSE, предполагая минимальное ухудшение производительности по сравнению с исходной моделью.
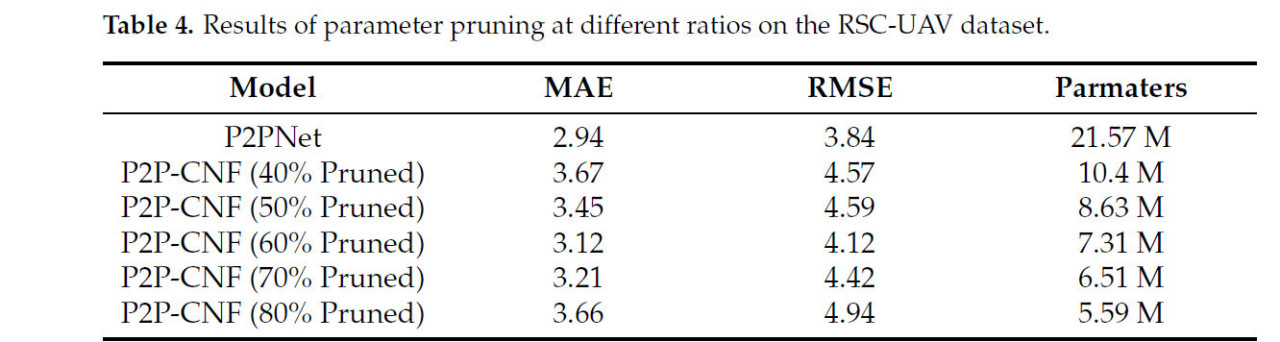
Таблица 4. Результаты прореживания параметров в разных соотношениях на наборе данных RSC-UAV.
Лучшие результаты были получены при прореживании 60% параметров, что дало MAE 3.12 и RMSE 4.12. В этом случае MAE увеличилась всего на 0.18, а RMSE на 0.28 по сравнению с исходной моделью. Дополнительно, по сравнению с конфигурацией прореживания 50%, MAE уменьшилась на 9%, а RMSE на 8%, что демонстрирует эффективность дальнейшего прореживания. Когда было прорежено 70% параметров, общее количество параметров в модели P2P-CNF сократилось до 6.51M, что составляет всего 30% от исходной модели. При этом уровне прореживания MAE составила 3.21, уступая только конфигурации прореживания 60%. При уровне прореживания 80% параметры модели были значительно сокращены, и MAE оставалась относительно высокой на уровне 3.66, всего на 0.72 выше, чем у исходной модели P2PNet.
Чтобы предоставить более комплексный анализ влияния различных соотношений прореживания на производительность модели, визуализированы результаты детектирования и тепловые карты для каждой прореженной версии. Эти визуализации показаны на рисунке 9, где рисунок 9a представляет эталонные данные, за которыми следуют результаты моделей с постепенно прореженными параметрами с рисунка 9b по f. Стоит отметить, что на втором изображении рисунка 9a в эталонных данных отсутствуют маркеры для нескольких растений риса. Модель все еще могла эффективно идентифицировать растения риса. По мере того как растения риса приближались к поздней стадии кущения, исходная модель P2PNet начала проявлять повторяющееся распознавание, где растения риса постоянно помечались. Однако наш легковесный метод успешно смягчил эту проблему, благодаря Depth-Attentive Fusion Module (DAFM). Этот модуль использует разделяемые по глубине свертки в сочетании с механизмом линейного самовнимания, позволяя модели более точно фокусироваться на растениях риса, сохраняя при этом легковесную архитектуру. Следовательно, модель была лучше подготовлена для идентификации перекрывающихся растений риса и обработки окклюзий, что привело к улучшенной общей производительности в сложных сценариях.
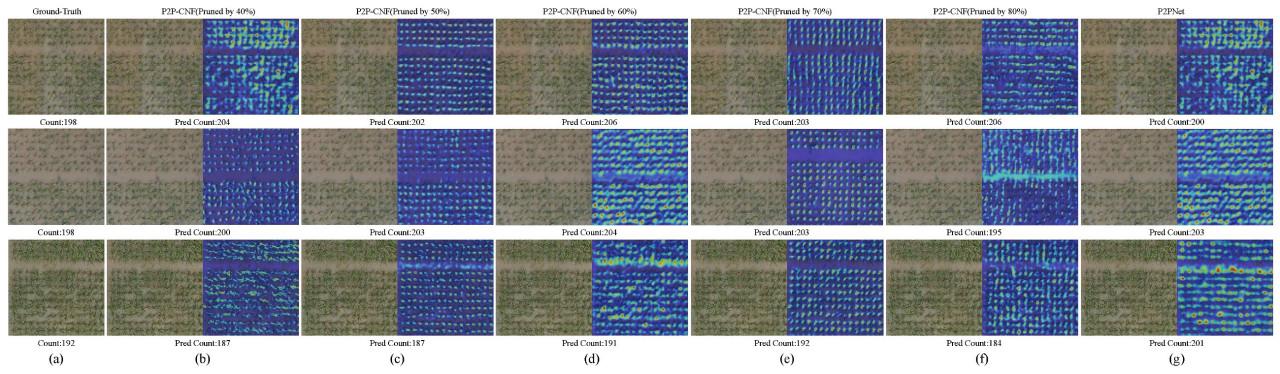
Рисунок 9. Представлена визуализация на наборе данных RSC-UAV, где эталонные данные показаны на (a), за которыми следуют модели бэкбон-сети с постепенно прореженными соотношениями параметров с (b–f), и исходная модель отображена на (g). Визуализация включает как результаты детектирования, так и их соответствующие тепловые карты.
4.4. Абляционный эксперимент
Чтобы продемонстрировать эффективность модуля прореживания CNF и модуля слияния признаков DAFM, были проведены обширные абляционные эксперименты на наборе данных RSC-UAV, результаты представлены в таблице 5.
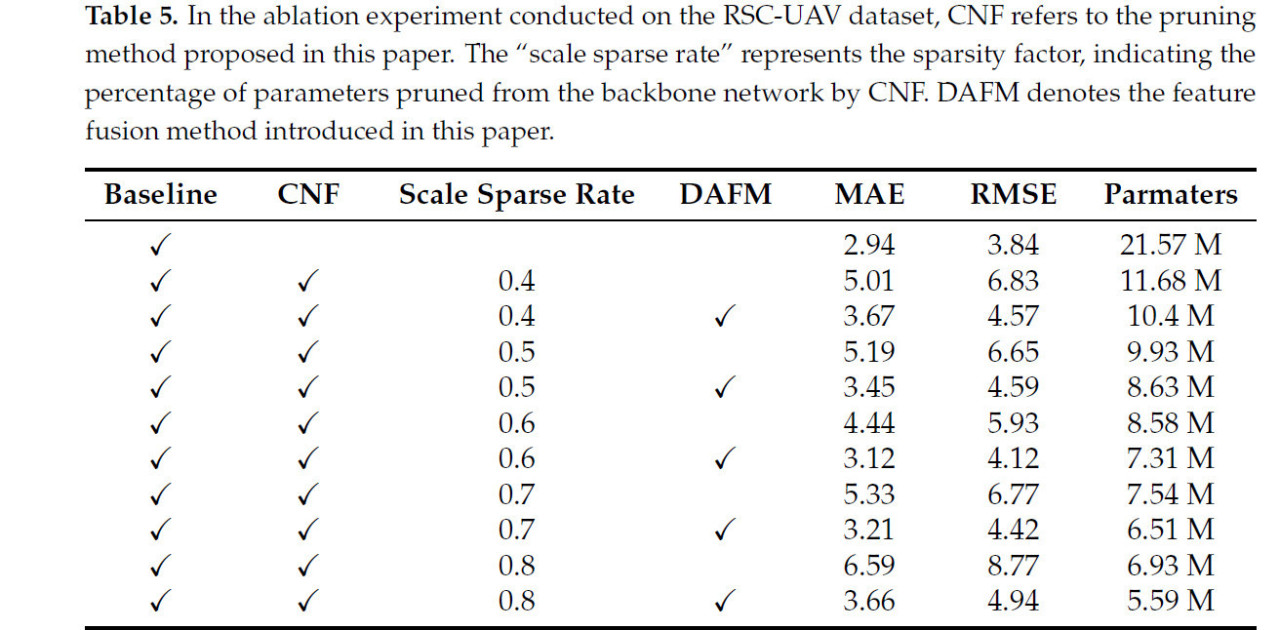
Таблица 5. В абляционном эксперименте, проведенном на наборе данных RSC-UAV, CNF относится к методу прореживания, предложенному в данной статье. "Scale sparse rate" представляет фактор разреженности, указывающий процент параметров, прореженных из бэкбон-сети с помощью CNF. DAFM обозначает метод слияния признаков, представленный в данной статье.
Изначально базовая модель, P2PNet, была применена для локализации и подсчета риса, дав MAE 2.94 и RMSE 3.84. Когда scale sparse rate был установлен на 0.4, указывая на 40% сокращение количества параметров из бэкбон-сети с помощью метода прореживания CNF, MAE увеличилась до 5.01, а RMSE поднялась до 6.83, с размером модели, уменьшенным до 11.68 M параметров. Добавление DAFM к сети после прореживания CNF сократило количество параметров модели до 10.4 M, что привело к улучшенной производительности с MAE 3.67 и RMSE 4.57. По сравнению с сетью после только прореживания CNF, модель с DAFM продемонстрировала значительное сокращение как MAE (на 1.34), так и RMSE (на 2.26), указывая на существенное улучшение как точности, так и точности подсчета.
Когда scale sparse rate был установлен на 0.6, производительность прореживания метода CNF достигла оптимального уровня. Без интеграции DAFM, MAE составила 4.44, RMSE 5.93, и модель содержала 8.58M параметров. Интеграция DAFM дополнительно уменьшила MAE и RMSE до 3.12 и 4.12 соответственно, при этом сократив количество параметров на дополнительные 1.27 M, делая модель одновременно более легкой и более точной. При scale sparse rate 0.8, большинство параметров было прорежено из модели. Модель без интеграции DAFM имела 6.93M параметров, с MAE 6.59 и RMSE 8.77. Однако при интеграции DAFM, как MAE, так и RMSE значительно снизились до 3.66 и 4.94 соответственно, с дальнейшим сокращением параметров. Это ясно демонстрирует эффективность модуля DAFM в повышении эффективности и производительности модели.
Чтобы дополнительно исследовать влияние различных компонентов на производительность модели, мы использовали тепловые карты для более комплексного анализа. Была выбрана scale sparse rate 0.6, наряду с базовой моделью, для анализа визуализации. Как показано на рисунке 10, тепловые карты предоставляют содержательные визуализации. На рисунке 10c видно, что бэкбон-сеть модели после прореживания с помощью CNF сохраняет высокую способность извлекать значимые признаки. Рисунок 10d иллюстрирует наш полный метод, P2P-CNF, где интеграция DAFM улучшает фокусировку внимания модели на признаках. Это улучшение во многом объясняется механизмом самовнимания, который позволяет модели более эффективно фокусироваться на ключевых признаках растений риса, что приводит к лучшей производительности локализации и подсчета.

Рисунок 10. Абляционный эксперимент на наборе данных RSC-UAV проиллюстрирован следующим образом: (a) показывает эталонные данные; (b) представляет результаты после прореживания 60% параметров с помощью CNF; (c) иллюстрирует модель P2PNet, использующую только прореживание CNF; (d) демонстрирует полный метод P2P-CNF, который включает DAFM для улучшенного слияния признаков.
4.5. Эксперименты на наборе данных URC
Чтобы ускорить обучение, набор данных URC был изменен по размеру путем уменьшения как ширины, так и высоты вдвое перед обучением с P2PNet. Впоследствии применялась методология прореживания, за которой следовала другая фаза обучения. Результаты задокументированы в таблице 6.
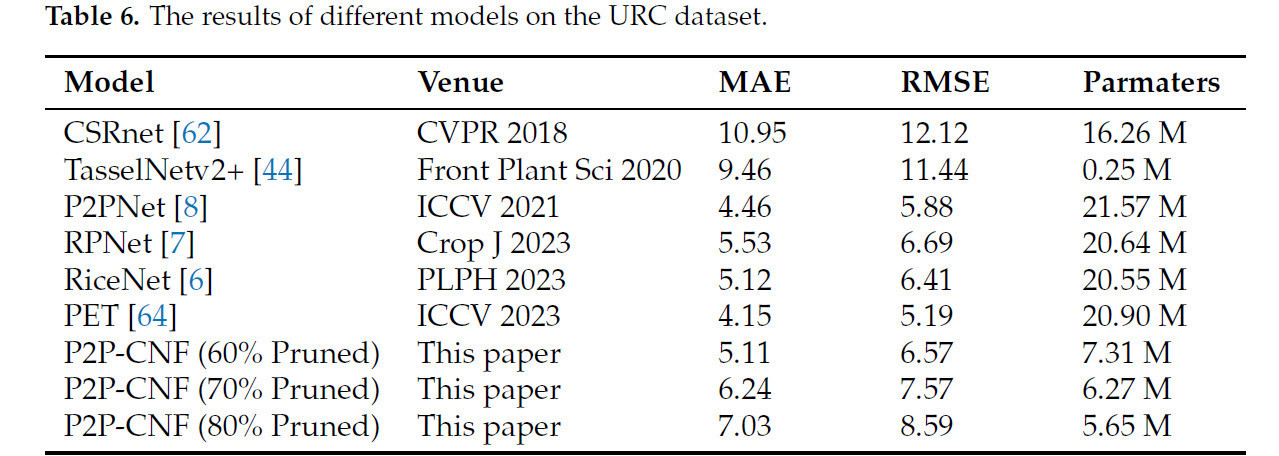
Таблица 6. Результаты различных моделей на наборе данных URC.
Наша оптимальная модель достигла MAE 5.11 и RMSE 6.57. На этом этапе количество параметров модели составляло 7.31 M. Примечательно, что MAE модели была на 0.96 выше, чем у оптимальной модели PET, однако наши параметры составляли только 35% от параметров в модели PET, а MAE была на 0.65 выше, чем у базовой модели P2PNet. Эти результаты предполагают, что стратегии прореживания и слияния признаков эффективно смягчают потерю информации, обычно связанную с сокращением параметров. По сравнению с RiceNet и RPNet, метод достигает немного лучшей MAE после прореживания 60% параметров, сохраняя при этом значительно меньшее количество параметров.
Чтобы дополнительно продемонстрировать влияние наших методов, мы сравнили базовую модель P2PNet и наши две наиболее эффективные стратегии на наборе данных URC, включая результаты из двух различных сценариев сокращения параметров. Рисунок 11b–d иллюстрирует их производительность подсчета, в то время как рисунок 12b–d отображает визуализации тепловых карт.

Рисунок 11. В визуализации набора данных URC, (a) представляет эталонные данные. Результаты подсчета для P2PNet, P2P-CNF (прореженной на 60%) и P2P-CNF (прореженной на 70%) показаны на (b–d) соответственно.
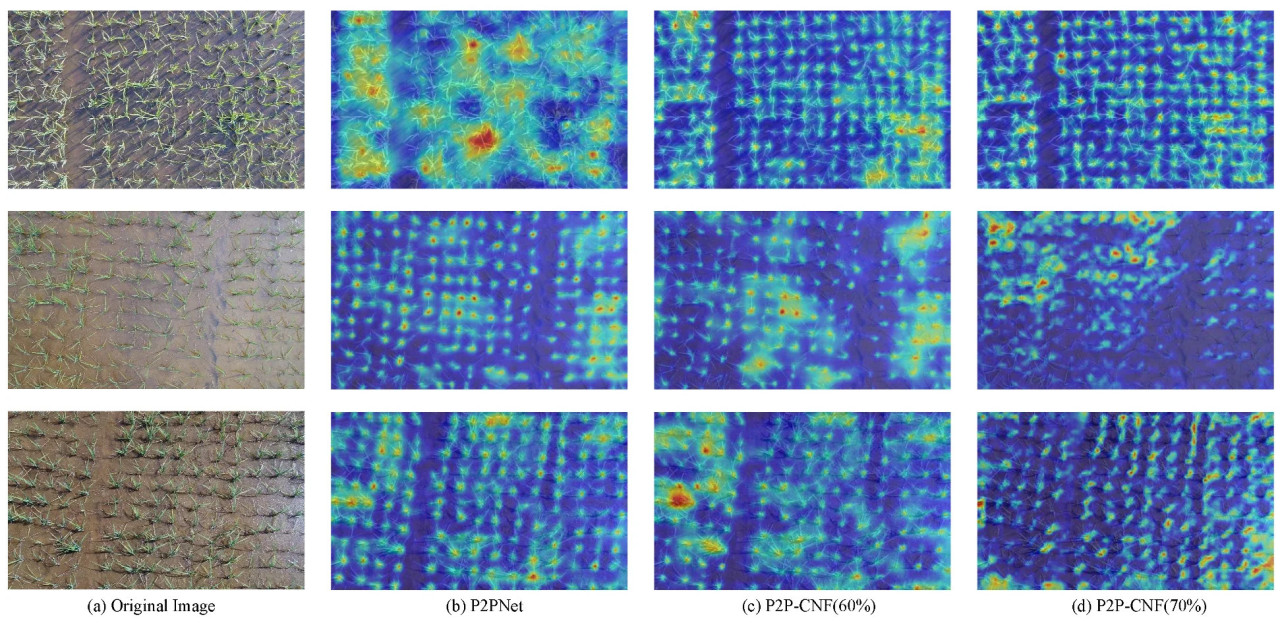
Рисунок 12. В визуализации тепловых карт на наборе данных URC, исходное изображение расположено на (a). Последующие столбцы с (b–d) отображают результаты тепловых карт для P2PNet, затем P2P-CNF (прореженной на 60%) и P2P-CNF (прореженной на 70%).
4.6. Эксперименты на наборе данных WED
Учитывая, что набор данных WED содержит только аннотации ограничивающих рамок, они были преобразованы в точечные аннотации для облегчения единообразного сравнения. Дополнительно, учитывая высокое разрешение изображений набора данных, разрешение изображения было уменьшено до одной восьмой от исходного размера перед обучением. Протокол обучения был сохранен, как установлено ранее, начиная с предварительного обучения с использованием P2PNet, за которым следует прореживание с помощью метода.
Таблица 7 представляет сравнительные результаты на наборе данных WED. Примечательно, что RPNet и P2PNet достигли оптимальной MAE 3.61, при этом P2PNet продемонстрировал более низкую RMSE. Хотя наш метод не достиг наилучшей производительности, он занял близкое место после этих моделей, с MAE 3.95, всего на 0.34 выше лидирующего результата. Относительно базовой модели P2PNet, P2P-CNF требовала только 32% параметров, значительно повышая эффективность модели. Рисунок 13b,c иллюстрирует визуальные результаты для базовых моделей P2PNet и P2P-CNF (прореженной на 60%). Тепловая карта ясно показывает, что, несмотря на существенное сокращение параметров, наш метод успешно сохраняет фокус на цели.

Рисунок 13. Визуализация результатов на наборе данных WED (a). (b) показывает результат подсчета P2PNet вместе с его визуализацией тепловой карты, в то время как (c) представляет результат визуализации P2P-CNF (прореженной на 60%).
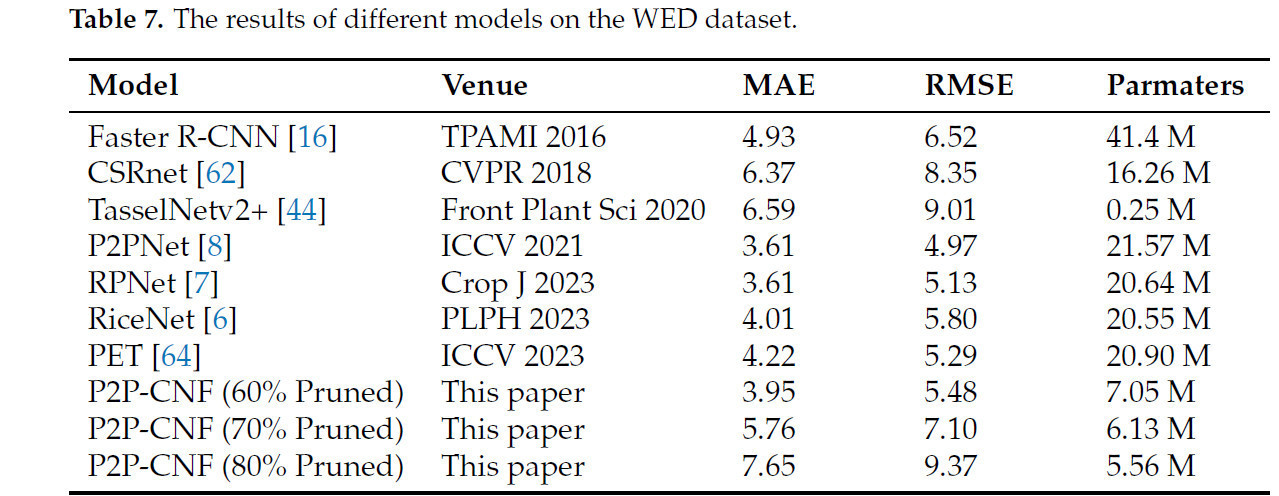
Таблица 7. Результаты различных моделей на наборе данных WED.
4.7. Эксперименты на наборе данных MTC
Перед началом обучения набор данных MTC был обработан путем масштабирования более коротких сторон изображений до 512 пикселей и пропорциональной корректировки более длинных сторон для ускорения обучения. Результаты представлены в таблице 8. Удивительно, но P2P-CNF впервые превзошел базовую модель P2PNet, достигнув лучшей MAE 2.94, сравнимой с RPNet. Хотя RMSE RPNet была немного ниже, чем у этой модели, наша модель использовала только 33% параметров RPNet, соблюдая баланс между производительностью и эффективностью.

Таблица 8. Результаты различных моделей на наборе данных MTC.
Когда приблизительно 80% параметров были прорежены из бэкбон-сети, параметры P2P-CNF сократились до 5.54 M, всего 25% от базовой модели P2PNet. Тем не менее, ее производительность оставалась сравнимой с P2PNet. Несмотря на большее количество параметров, чем у более легкой TasselNetv2+, наш метод достиг высокой точности. В целом, мы успешно сбалансировали высокую производительность с легковесной архитектурой.
Дополнительно, мы визуализировали результаты различных конфигураций параметров P2P-CNF и базовой модели P2PNet на наборе данных MTC. Рисунок 14b–f отображает визуализацию результатов подсчета, полученных нашим методом. Результаты подсчета ясно демонстрируют, что наш метод также преуспевает в разреженных сценариях.
Рисунок 14. Визуализация набора данных MTC включает эталонные данные на (a). С (b–f), последующие изображения отображают карты эффектов подсчета P2P-CNF с разными соотношениями параметров столбцов, завершая картами эффектов подсчета базовой модели, P2PNet, на (g).
5. Обсуждение
В этой статье мы представили новый метод прореживания, Cosine Norm Fusion (CNF), и технику слияния признаков, Depth Attention Fusion Module (DAFM). CNF использует расчеты косинусного сходства во время прореживания, чтобы минимизировать потерю информации, в то время как DAFM сочетает разделяемые по глубине свертки с механизмом линейного самовнимания, чтобы создать легковесный модуль признаков. Эти техники были включены в модель архитектуры "точка-точка", P2PNet, в результате чего получилась легковесная модель подсчета риса, P2P-CNF. Ключевой аспект метода прореживания CNF — определение глобального порога для прореживания. Глобальный порог устанавливается на основе процентиля значений масштабирующего фактора из слоев пакетной нормализации (BN). Наши эксперименты демонстрируют, что установка коэффициента разреженности на 0.6 и 0.7, что соответствует прореживанию 60% или 70% параметров из бэкбон-сети, приводит к оптимальной производительности модели. Это сокращение параметров не влияет значительно на точность модели. Чтобы дополнительно смягчить снижение производительности, вызванное сокращением параметров и потенциальным дисбалансом в слоях сети, мы вводим Depth Attentive Fusion Module (DAFM). Этот модуль эффективно интегрирует информацию из оставшихся каналов, используя механизм самовнимания, позволяя модели больше фокусироваться на наиболее релевантных признаках. В результате модель может быть развернута эффективно в сельскохозяйственных условиях, обеспечивая как высокую производительность, так и легковесную архитектуру.
Дополнительно, чтобы получить более глубокое понимание эффекта слияния DAFM, мы провели тщательное исследование, сравнивая производительность различных стратегий слияния после прореживания CNF на наборе данных RSC-UAV. Конкретно мы оценили экспериментальные результаты, используя различные модули слияния, включая исходный модуль слияния P2PNet, модуль DAFM и версию модуля DAFM без механизма линейного самовнимания. Результаты этих сравнений представлены в таблице 9.
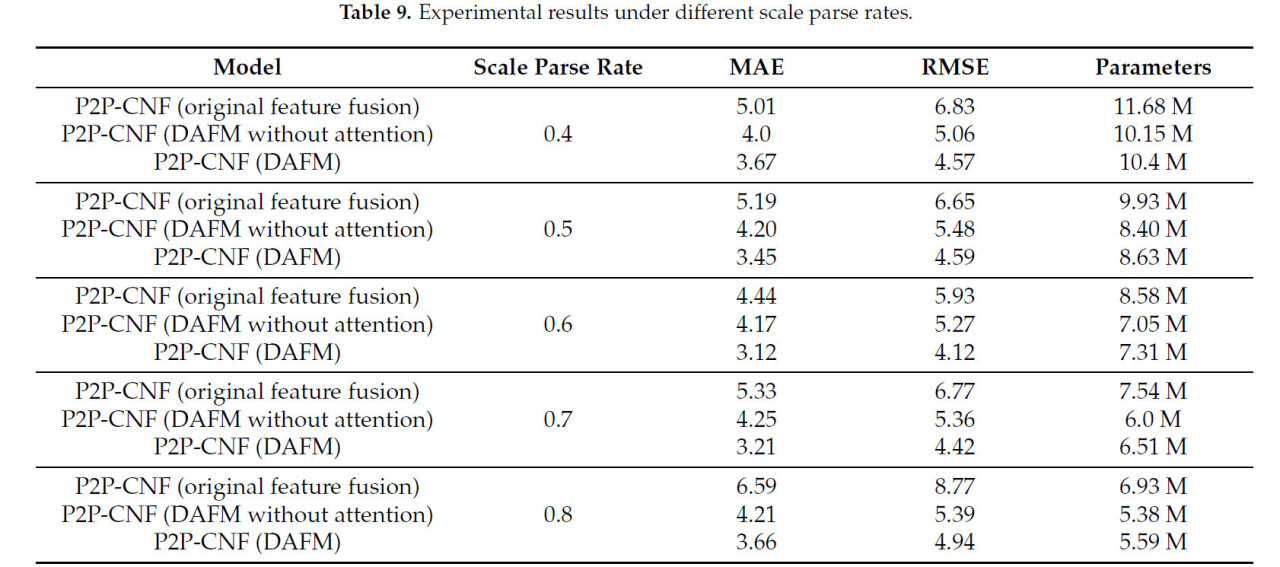
Таблица 9. Результаты экспериментов при различных коэффициентах разреженности.
Очевидно, что даже модуль DAFM без механизма самовнимания превосходит исходный метод слияния признаков P2PNet как по эффективности параметров, так и по точности. Это улучшение можно объяснить более разнообразными стратегиями слияния признаков, используемыми DAFM. Более того, интеграция механизма линейного самовнимания дополнительно повышает его производительность. Механизм внимания специально фокусируется на внутренних характеристиках растений риса, что способствует значительному увеличению точности.
6. Выводы
В данной статье предложен легковесный метод, P2P-CNF, основанный на P2PNet. Используя CNF для прореживания и интегрируя модуль DAFM для слияния признаков, модель эффективно сохраняет высокую точность при работе в сельскохозяйственных условиях с ограниченными вычислительными ресурсами. Чтобы оценить производительность P2P-CNF, мы построили набор данных RSC-UAV, специально предназначенный для подсчета растений риса с использованием изображений с БПЛА, и провели обширные эксперименты на нескольких наборах данных, включая URC, WED и MTC. Результаты демонстрируют, что P2P-CNF достигает выдающейся производительности на этих разных наборах данных, с меньшим количеством параметров, чем текущие основные модели подсчета растений. В перспективе будущие исследования будут сосредоточены на дальнейшем уточнении легковесных методологий и стремлении к еще более высокой точности при минимизации количества параметров модели, обеспечивая лучшую адаптируемость к средам с ограниченными ресурсами.
Ссылки
1. Zeigler, R.S.; Barclay, A. The relevance of rice. Rice 2008, 1, 3–10. [Google Scholar] [CrossRef]
2. Adhikari, B.; Mehera, B.; Haefele, S. Impact of rice nursery nutrient management, seeding density and seedling age on yield and yield attributes. Am. J. Plant Sci. 2013, 4, 146–155. [Google Scholar] [CrossRef]
3. Wang, X.; Li, Z.; Tan, S.; Li, H.; Qi, L.; Wang, Y.; Chen, J.; Yang, C.; Chen, J.; Qin, Y.; et al. Research on density grading of hybrid rice machine-transplanted blanket-seedlings based on multi-source unmanned aerial vehicle data and mechanized transplanting test. Comput. Electron. Agric. 2024, 222, 109070. [Google Scholar] [CrossRef]
4. Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution RGB imagery using deep learning technique. Agric. For. Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
5. Li, H.; Li, Z.; Dong, W.; Cao, X.; Wen, Z.; Xiao, R.; Wei, Y.; Zeng, H.; Ma, X. An automatic approach for detecting seedlings per hill of machine-transplanted hybrid rice utilizing machine vision. Comput. Electron. Agric. 2021, 185, 106178. [Google Scholar] [CrossRef]
6. Bai, X.; Liu, P.; Cao, Z.; Lu, H.; Xiong, H.; Yang, A.; Cai, Z.; Wang, J.; Yao, J. Rice plant counting, locating, and sizing method based on high-throughput UAV RGB images. Plant Phenomics 2023, 5, 20. [Google Scholar] [CrossRef] [PubMed]
7. Bai, X.; Gu, S.; Liu, P.; Yang, A.; Cai, Z.; Wang, J.; Yao, J. Rpnet: Rice plant counting after tillering stage based on plant attention and multiple supervision network. Crop J. 2023, 11, 1586–1594. [Google Scholar] [CrossRef]
8. Song, Q.; Wang, C.; Jiang, Z.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Wu, Y. Rethinking counting and localization in crowds: A purely point-based framework. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3365–3374. [Google Scholar]
9. Zhao, J.; Kaga, A.; Yamada, T.; Komatsu, K.; Hirata, K.; Kikuchi, A.; Hirafuji, M.; Ninomiya, S.; Guo, W. Improved field-based soybean seed counting and localization with feature level considered. Plant Phenomics 2023, 5, 26. [Google Scholar] [CrossRef]
10. Yao, M.; Li, W.; Chen, L.; Zou, H.; Zhang, R.; Qiu, Z.; Yang, S.; Shen, Y. Rice Counting and Localization in Unmanned Aerial Vehicle Imagery Using Enhanced Feature Fusion. Agronomy 2024, 14, 868. [Google Scholar] [CrossRef]
11. Cheng, H.; Zhang, M.; Shi, J.Q. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10558–10578. [Google Scholar] [CrossRef]
12. Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
13. Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
14. Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
15. Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
16. Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
17. Vaswani, A. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
18. Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Hambro, E.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language models can teach themselves to use tools. In Proceedings of the 38th Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
19. Joo, D.; Kim, D.; Kim, J. Slimming ResNet by Slimming Shortcut. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7677–7683. [Google Scholar]
20. Li, M.; Ding, D.; Heldring, A.; Hu, J.; Chen, R.; Vecchi, G. Low-rank matrix factorization method for multiscale simulations: A review. IEEE Open J. Antennas Propag. 2021, 2, 286–301. [Google Scholar] [CrossRef]
21. Saha, R.; Srivastava, V.; Pilanci, M. Matrix compression via randomized low rank and low precision factorization. In Proceedings of the 37th Annual Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
22. Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
23. Sun, S.; Ren, W.; Li, J.; Wang, R.; Cao, X. Logit standardization in knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15731–15740. [Google Scholar]
24. Bakhtiarifard, P.; Igel, C.; Selvan, R. EC-NAS: Energy consumption aware tabular benchmarks for neural architecture search. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5660–5664. [Google Scholar]
25. Gao, S.; Huang, F.; Cai, W.; Huang, H. Network pruning via performance maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9270–9280. [Google Scholar]
26. Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]
27. Ma, X.; Fang, G.; Wang, X. Llm-pruner: On the structural pruning of large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 21702–21720. [Google Scholar]
28. Gao, S.; Zhang, Z.; Zhang, Y.; Huang, F.; Huang, H. Structural alignment for network pruning through partial regularization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17402–17412. [Google Scholar]
29. Wang, Z.; Li, C.; Wang, X. Convolutional neural network pruning with structural redundancy reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14913–14922. [Google Scholar]
30. Liao, Z.; Quétu, V.; Nguyen, V.T.; Tartaglione, E. Can Unstructured Pruning Reduce the Depth in Deep Neural Networks? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1402–1406. [Google Scholar]
31. Pietroń, M.; Żurek, D.; Śnieżyński, B. Speedup deep learning models on GPU by taking advantage of efficient unstructured pruning and bit-width reduction. J. Comput. Sci. 2023, 67, 101971. [Google Scholar] [CrossRef]
32. Wilkinson, L.; Cheshmi, K.; Dehnavi, M.M. Register Tiling for Unstructured Sparsity in Neural Network Inference. Proc. ACM Program. Lang. 2023, 7, 1995–2020. [Google Scholar] [CrossRef]
33. Frantar, E.; Alistarh, D. Sparsegpt: Massive language models can be accurately pruned in one-shot. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 10323–10337. [Google Scholar]
34. Dhahri, R.; Immer, A.; Charpentier, B.; Günnemann, S.; Fortuin, V. Shaving Weights with Occam’s Razor: Bayesian Sparsification for Neural Networks Using the Marginal Likelihood. arXiv 2024, arXiv:2402.15978. [Google Scholar]
35. Sun, X.; Shi, H. Towards Better Structured Pruning Saliency by Reorganizing Convolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 2204–2214. [Google Scholar]
36. Chen, T.; Ji, B.; Ding, T.; Fang, B.; Wang, G.; Zhu, Z.; Liang, L.; Shi, Y.; Yi, S.; Tu, X. Only train once: A one-shot neural network training and pruning framework. Adv. Neural Inf. Process. Syst. 2021, 34, 19637–19651. [Google Scholar]
37. He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4340–4349. [Google Scholar]
38. Wang, W.; Fu, C.; Guo, J.; Cai, D.; He, X. COP: Customized deep model compression via regularized correlation-based filter-level pruning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3785–3791. [Google Scholar]
39. Ioffe, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
40. Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
41. You, Z.; Yan, K.; Ye, J.; Ma, M.; Wang, P. Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
42. Zhuang, T.; Zhang, Z.; Huang, Y.; Zeng, X.; Shuang, K.; Li, X. Neuron-level structured pruning using polarization regularizer. Adv. Neural Inf. Process. Syst. 2020, 33, 9865–9877. [Google Scholar]
43. Kang, M.; Han, B. Operation-aware soft channel pruning using differentiable masks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5122–5131. [Google Scholar]
44. Lu, H.; Cao, Z. TasselNetV2+: A fast implementation for high-throughput plant counting from high-resolution RGB imagery. Front. Plant Sci. 2020, 11, 541960. [Google Scholar] [CrossRef] [PubMed]
45. Karami, A.; Crawford, M.; Delp, E.J. Automatic plant counting and location based on a few-shot learning technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5872–5886. [Google Scholar] [CrossRef]
46. Pape, J.M.; Klukas, C. Utilizing machine learning approaches to improve the prediction of leaf counts and individual leaf segmentation of rosette plant images. Proc. Comput. Vis. Probl. Plant Phenotyping (CVPPP) 2015, 3, 1–12. [Google Scholar]
47. Giuffrida, M.V.; Minervini, M.; Tsaftaris, S.A. Learning to count leaves in rosette plants. In Proceedings of the Computer Vision Problems in Plant Phenotyping (CVPPP), Swansea, UK, 7–10 September 2015. [Google Scholar]
48. Qureshi, W.S.; Payne, A.; Walsh, K.; Linker, R.; Cohen, O.; Dailey, M. Machine vision for counting fruit on mango tree canopies. Precis. Agric. 2017, 18, 224–244. [Google Scholar] [CrossRef]
49. Sam, D.B.; Peri, S.V.; Sundararaman, M.N.; Kamath, A.; Babu, R.V. Locate, size, and count: Accurately resolving people in dense crowds via detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2739–2751. [Google Scholar]
50. Bai, S.; He, Z.; Qiao, Y.; Hu, H.; Wu, W.; Yan, J. Adaptive dilated network with self-correction supervision for counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4594–4603. [Google Scholar]
51. Hu, Y.; Jiang, X.; Liu, X.; Zhang, B.; Han, J.; Cao, X.; Doermann, D. Nas-count: Counting-by-density with neural architecture search. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 747–766. [Google Scholar]
52. Buzzy, M.; Thesma, V.; Davoodi, M.; Mohammadpour Velni, J. Real-time plant leaf counting using deep object detection networks. Sensors 2020, 20, 6896. [Google Scholar] [CrossRef]
53. Wang, N.; Cao, H.; Huang, X.; Ding, M. Rapeseed flower counting method based on GhP2-YOLO and StrongSORT algorithm. Plants 2024, 13, 2388. [Google Scholar] [CrossRef]
54. Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
55. Chen, H.; Chen, H.; Huang, X.; Zhang, S.; Chen, S.; Cen, F.; He, T.; Zhao, Q.; Gao, Z. Estimation of sorghum seedling number from drone image based on support vector machine and YOLO algorithms. Front. Plant Sci. 2024, 15, 1399872. [Google Scholar] [CrossRef] [PubMed]
56. Lu, H.; Cao, Z.; Xiao, Y.; Zhuang, B.; Shen, C. TasselNet: Counting maize tassels in the wild via local counts regression network. Plant Methods 2017, 13, 79. [Google Scholar] [CrossRef]
57. Xiong, H.; Cao, Z.; Lu, H.; Madec, S.; Liu, L.; Shen, C. TasselNetv2: In-field counting of wheat spikes with context-augmented local regression networks. Plant Methods 2019, 15, 150. [Google Scholar] [CrossRef] [PubMed]
58. Lu, H.; Liu, L.; Li, Y.N.; Zhao, X.M.; Wang, X.Q.; Cao, Z.G. TasselNetV3: Explainable plant counting with guided upsampling and background suppression. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
59. Wu, J.; Yang, G.; Yang, X.; Xu, B.; Han, L.; Zhu, Y. Automatic counting of in situ rice seedlings from UAV images based on a deep fully convolutional neural network. Remote Sens. 2019, 11, 691. [Google Scholar] [CrossRef]
60. Liu, W.; Zhou, J.; Wang, B.; Costa, M.; Kaeppler, S.M.; Zhang, Z. IntegrateNet: A deep learning network for maize stand counting from UAV imagery by integrating density and local count maps. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6512605. [Google Scholar] [CrossRef]
61. Kim, M.; Gao, S.; Hsu, Y.C.; Shen, Y.; Jin, H. Token fusion: Bridging the gap between token pruning and token merging. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1383–1392. [Google Scholar]
62. Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
63. Liang, D.; Xu, W.; Zhu, Y.; Zhou, Y. Focal inverse distance transform maps for crowd localization. IEEE Trans. Multimed. 2022, 25, 6040–6052. [Google Scholar] [CrossRef]
64. Liu, C.; Lu, H.; Cao, Z.; Liu, T. Point-query quadtree for crowd counting, localization, and more. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2 2023; pp. 1676–1685. [Google Scholar]

Sun H, Tan S, Luo Z, Yin Y, Cao C, Zhou K, Zhu L. Development of a Lightweight Model for Rice Plant Counting and Localization Using UAV-Captured RGB Imagery. Agriculture. 2025; 15(2):122. https://doi.org/10.3390/agriculture15020122
Перевод статьи «Development of a Lightweight Model for Rice Plant Counting and Localization Using UAV-Captured RGB Imagery» авторов Sun H, Tan S, Luo Z, Yin Y, Cao C, Zhou K, Zhu L., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)