ИИ-конвейер для идеального поля: как синтетические данные учат роботов различать культуры и сорняки
Технология точного распознавания и разметки каждого растения на снимке позволяет проводить их идентификацию и совершенствовать системы борьбы с сорняками. Однако разработка подобных моделей сталкивается с серьёзной проблемой — недостатком размеченных данных.
Аннотация
В данной работе представлен конвейер для генерации синтетических данных на уровне патчей, который повышает точность семантической сегментации в естественных полевых условиях. Он создаёт реалистичные учебные примеры, вставляя сегментированные изображения растений (патчи) на фотографии фона почвы. Этот подход сохраняет контекст переднего плана и обеспечивает создание разнообразных и точных данных, что в итоге улучшает способность модели к обобщению.
Базовая модель, обученная только на данных, сгенерированных нашим конвейером, показала более высокую точность, чем модель, обученная исключительно на реальных данных. Средний показатель Intersection over Union (mIoU) вырос примерно на 1.1% (с 0.626 до 0.633).
На основе этого мы создали гибридные наборы данных, комбинируя синтетические и реальные изображения, и изучили влияние объёма синтетики. Увеличение доли синтетических изображений в гибридных наборах с 1× до 20× привело к значительному росту производительности: на отметке 15× прирост mIoU составил 15%. Однако после этого рост эффективности замедлился, и оптимальный баланс между точностью и вычислительными затратами был достигнут при коэффициенте 10×.
Эти результаты подтверждают, что использование синтетических данных является масштабируемой и эффективной стратегией для преодоления challenges, связанных с дефицитом размеченных данных в сельском хозяйстве.
1. Введение
Химические гербициды стали доминирующим методом борьбы с сорняками в сельском хозяйстве, широко принятым благодаря своей эффективности и простоте использования. Эти химикаты применяются как до появления всходов, так и после, чтобы предотвратить или устранить конкуренцию сорняков с культурами, что позволяет лучше управлять урожайностью и ростом [1]. Однако чрезмерная зависимость от химических гербицидов оказала пагубное воздействие как внутри поля, так и за его пределами. Широкое применение гербицидов может привести к потере биоразнообразия, воздействуя на нецелевые виды растений и сокращая доступность среды обитания для других организмов [2]. Эта потеря биоразнообразия негативно влияет на почвенную микробиоту, нарушая структуру и функцию микробного сообщества, которые необходимы для круговорота питательных веществ, плодородия почвы и здоровья растений [3]. Снижение микробного разнообразия может повредить устойчивости почвы, делая экосистемы более уязвимыми к болезням и менее способными восстанавливаться после нарушений [4]. Увеличение разнообразия сорняков может противодействовать некоторым негативным эффектам доминирующих видов сорняков, способствуя более сбалансированной экосистеме при сохранении продуктивности культур [5]. Дополнительно, появление устойчивых к гербицидам видов сорняков становится все более проблематичным, что указывает на необходимость более устойчивых решений для управления сорняками [6,7].
В ответ на эти вызовы, пространственно-точное управление сорняками (site-specific weed management, SSWM) предлагает перспективную альтернативу. Эта техника фокусируется на избирательном воздействии на виды сорняков, которые представляют наибольшую угрозу для культур, сводя к минимуму воздействие на нецелевые растения. SSWM сокращает общее количество применяемого гербицида, тем самым помогая сохранить биоразнообразие на сельскохозяйственных полях [8]. Концентрируя обработку на конкретных участках, фермеры могут снизить свою зависимость от гербицидов и решить растущую проблему устойчивых сорняков, одновременно уменьшая экономические затраты, связанные с химическими обработками. Более того, SSWM согласуется с более широкими инициативами в области устойчивого развития, интегрируя передовые технологии точного земледелия для оптимизации применения гербицидов, снижения воздействия на окружающую среду и повышения эффективности использования ресурсов. Этот подход не только способствует сохранению нецелевых видов растений, но и поддерживает здоровье экосистемы и долгосрочную устойчивость сельского хозяйства, предлагая экологически чистое и экономически жизнеспособное решение для управления сорняками [9].
Расцвет нейронных сетей, в частности глубокого обучения, произвел революцию в обработке изображений. В частности, глубокое обучение продвинуло сегментацию в сельскохозяйственных сценах. Например, спутниковые снимки все чаще используются для мониторинга сельского хозяйства в большом масштабе, позволяя оценивать силу роста культур, обнаруживать вспышки болезней и определять потребности в орошении на обширных территориях [10,11,12]. Дополнительно, дроны и аэроплатформы теперь способны контролировать культуры с высокой плотностью, позволяя проводить масштабный и анализ в реальном времени состояния растений и распределения сорняков [13,14,15]. Более того, наземные автономные роботы, оснащенные системами компьютерного зрения, могут перемещаться по полям для проведения детальной оценки почвы и растений, предоставляя данные высокого разрешения о здоровье растений и состоянии почвы [16,17].
Интегрируя методы компьютерного зрения с данными в реальном времени с этих различных платформ, глубокое обучение позволяет автоматизировать обнаружение сорняков, снижая зависимость от традиционных ручных методов. Однако остается серьезная проблема: системы на основе глубокого обучения требуют для эффективной работы больших размеченных наборов данных. Эти наборы данных, которые должны включать многочисленные изображения, размеченные с использованием экспертных агрономических знаний, требуют много времени и трудозатрат для создания [18]. Более того, применение глубокого обучения к масштабным сельскохозяйственным наборам данных по своей природе увеличивает количество параметров модели, что приводит к более высоким требованиям к вычислительным ресурсам. Эти возросшие требования не только усложняют процесс обучения, но и создают проблемы для приложений, работающих на периферийных устройствах (edge computing), где часто доступны ограниченные вычислительные ресурсы. Следовательно, необходимость в значительной вычислительной мощности и оптимизированных стратегиях управления памятью создает узкое место для масштабирования приложений глубокого обучения в точной прополке.
Синтез данных предлагает жизнеспособное решение для снижения нагрузки по разметке наборов данных. Генерация синтетических данных позволяет создавать искусственные наборы, которые имитируют реальные условия, уменьшая потребность в ручной разметке. Такие методы, как генеративно-состязательные сети (GANs) [19] и методы на основе диффузии [20,21], все чаще используются для генерации синтетических изображений высокого качества, что позволяет более эффективно обучать модели глубокого обучения с меньшим количеством реальных образцов. Этот подход не только смягчает проблему нехватки данных, но и улучшает способность модели к обобщению в различных полевых условиях, что ведет к более масштабируемым и рентабельным применениям глубокого обучения в SSWM.
Ранние усилия в области аугментации данных опирались на традиционные методы, такие как работа Skovsen и др. [22], которые моделировали сцены полей клевера и травы путем наложения сегментированных клеверов, трав и сорняков на изображения почвы. Аналогично, Toda и др. [23] создали синтетические наборы данных для фенотипирования семян культур, случайным образом размещая семена ячменя на виртуальных холстах. Эти подходы позволили более точно оценивать ботанический состав и сегментацию семян, но были ограничены неспособностью полностью воспроизвести естественную изменчивость, такую как условия освещения, текстуры и взаимодействия растений со средой. Sapkota и др. [24] решили проблему нехватки данных при обучении моделей глубокого обучения для обнаружения сорняков, генерируя синтетические изображения с использованием экземпляров растений, вырезанных из реальных изображений, полученных с БПЛА, продемонстрировав эффективность использования синтетического набора данных для улучшения производительности сегментации.
Выходя за рамки ранних применений, GANs появились как преобразующий инструмент для повышения достоверности и разнообразия синтетических данных. Valerio Giuffrida и др. [25] и Zhu и др. [26] продемонстрировали потенциал условных GANs (cGANs), генерируя изображения растений арабидопсиса с заданным количеством листьев, значительно снижая ошибки подсчета в задачах фенотипирования. Madsen и др. [27], Madsen и др. [28], Li и др. [29] дополнительно продвинули эту область, разработав архитектуры GAN, способные создавать изображения высокой достоверности нескольких видов растений, улучшая производительность многоклассовой классификации.
Опираясь на эти основы, достижения в генеративных техниках были сосредоточены на решении более сложных задач в синтезе сельскохозяйственных данных. Например, Fawakherji и др. [30] предложили фреймворк cGAN для замены реальных растений синтетическими в сельскохозяйственных сценах, снижая зависимость от ручных аннотаций. Аналогично, Fawakherji и др. [31] представили Shape and Style GANs для мультиспектральной сегментации культур и сорняков, сосредоточившись на генерации синтетических изображений, которые воспроизводят как геометрию, так и визуальный стиль растений. Picon и др. [32] объединили реальные полевые изображения с синтетическими, чтобы эффективно различать несколько видов культур и сорняков, тем самым улучшая прогнозную производительность. Между тем, Modak и Stein [33] интегрировали базовые модели (foundation models), такие как Segment Anything Model [34] и Stable Diffusion [35], в конвейер генерации синтетических изображений, повышая точность обнаружения сорняков и позволяя осуществлять перенос без дообучения (zero-shot transfer) в новые области. Также, Chen и др. [36] использовали как GANs, так и диффузионные модели для автоматического расширения разнообразия изображений сорняков, существенно улучшив производительность классификации и сегментации в различных моделях глубокого обучения.
Несмотря на эти успехи в повышении достоверности и разнообразия данных, многие подходы остаются ограниченными в своей способности динамически изменять целые сцены, часто улучшая элементы переднего плана, сохраняя при этом фон и композицию статичными. Более того, производительность аугментации данных с помощью синтетических данных зависит не только от достоверности и разнообразия, но и от объема данных. Однако большинство исследований по генеративным моделям в сельском хозяйстве в основном были сосредоточены на улучшении качества и разнообразия синтетических данных, с ограниченным вниманием к масштабированию объема данных.
Следовательно, данное исследование изучает использование синтетических наборов данных для улучшения моделей семантической сегментации в естественных полевых сценах. Основные вклады этого исследования суммированы следующим образом:
• Предложенный конвейер генерации синтетических данных на уровне патчей улучшает производительность семантической сегментации в естественных сельскохозяйственных сценах. Этот конвейер генерирует реалистичные синтетические полевые сцены, вставляя патчи переднего плана (растений) непосредственно на фон (почву), обеспечивая разнообразные и контекстуально точные учебные образцы для улучшения обобщающей способности модели.
• Было проведено детальное исследование для количественной оценки влияния аугментации данных с помощью предложенного конвейера на производительность сегментации. Изменяя масштаб синтетических данных, генерируемых конвейером, мы проанализировали, как увеличение размера набора данных влияет на производительность сегментации.
2. Материалы и методы
2.1. Исходный базовый набор данных
Эксперименты в этом исследовании основаны на общедоступном наборе данных WE3DS [37]. Этот набор содержит в общей сложности 2568 RGB-D изображений, снятых в условиях естественного освещения в Австрии. Он включает семь видов культур и десять видов сорняков на ранних стадиях роста. Изображения содержат маски «земной истины» (ground-truth) высокого разрешения (1600 × 1140 пикселей), которые сегментируют почву, экземпляры культур и сорняков.

Рисунок 1. Пример набора данных WE3DS. Левое изображение (а) показывает полевую сцену, а правое изображение (b) представляет соответствующую маску семантической сегментации, где разные цвета обозначают разные виды растений.
Левая часть рисунка показывает RGB-изображение поля, снятое в условиях естественного освещения, на котором изображены несколько экземпляров растений. Правая часть отображает соответствующую маску семантической сегментации, где разные цвета представляют разные виды растений или почву. Эти аннотации позволяют точно оценивать модели сегментации, различая экземпляры почвы, культур и сорняков.
Дополнительно, Таблица 1 предоставляет подробную информацию о видах культур и сорняков, включенных в набор данных, вместе с их кодами EPPO и метками классов (культура или сорняк). Этот набор данных служит основой как для базовых сравнений, так и для оценки методов генерации синтетических наборов данных, обеспечивая согласованность и надежность в дизайне эксперимента.
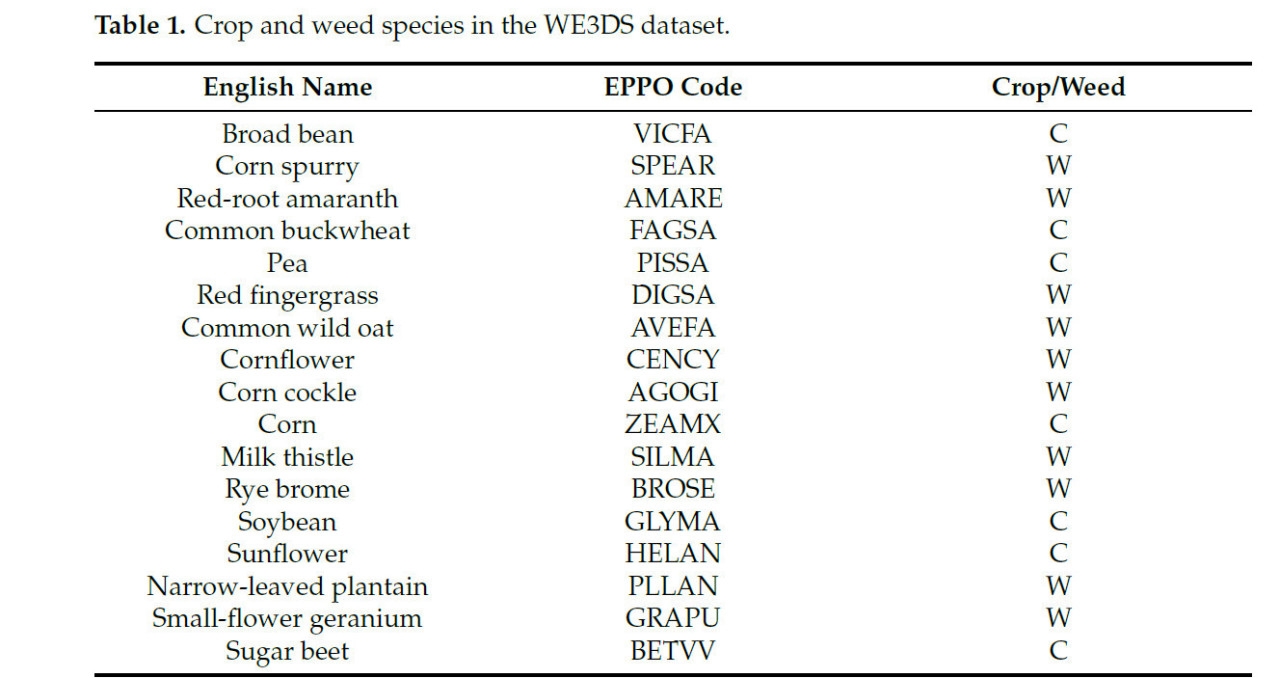
Таблица 1. Виды культур и сорняков в наборе данных WE3DS.
Изначально мы приняли ту же стратегию разделения набора данных, что и в оригинальном исследовании WE3DS, разделив 2568 изображений на 1540 обучающих изображений и 1028 тестовых изображений, используя предоставленные файлы train и test txt. Все обучение и тестирование выполнялись только с использованием RGB-каналов изображений, в то время как информация о глубине была исключена для обеспечения справедливого сравнения.
2.2. Набор данных с традиционной аугментацией
Чтобы обеспечить всестороннее сравнение с подходом синтетического набора данных, мы также изучили использование традиционных методов аугментации данных. В частности, мы выбрали три репрезентативные стратегии аугментации: Random Horizontal Flip (Случайное горизонтальное отражение), Random Resized Crop (Случайное изменение размера и обрезка) и Random Brightness Contrast (Случайная яркость и контраст). Эти стратегии были выбраны из-за их широкого использования и эффективности в увеличении разнообразия обучающих данных без необходимости генерации совершенно новых синтетических изображений.
Мы реализовали три различные комбинации этих стратегий аугментации, чтобы оценить их влияние на производительность модели:
• A: Использованы все три метода аугментации — Random Horizontal Flip, Random Resized Crop и Random Brightness Contrast — для максимизации изменчивости данных.
• B: Исключены аугментации, основанные на цвете, использованы только Random Horizontal Flip и Random Resized Crop для фокусировки на геометрических преобразованиях.
• C: Применена только стратегия Random Horizontal Flip для оценки влияния минимальной аугментации.
2.3. Синтетический набор данных на уровне пикселей
Для генерации синтетического набора данных на уровне пикселей мы приняли метод, основанный на подходе, предложенном Dyrmann и др. [38]. В этом методе отдельные растения извлекаются на уровне пикселей с использованием их точных полигональных аннотаций, что приводит к детальной сегментации переднего плана растения. Затем эти сегментированные передние планы на уровне пикселей используются в сочетании с фонами почвы для создания синтетических полевых сцен.
Этот подход опирается на два основных компонента: пул переднего плана и пул фона. Пул переднего плана состоит из сегментированных экземпляров растений, которые были извлечены из базового набора данных на уровне пикселей с использованием полигональных аннотаций. Эти извлеченные объекты служат основными элементами синтетического набора данных. Пул фона, с другой стороны, состоит из изображений почвы, обрезанных из базового набора данных, которые предоставляют реалистичный контекст для синтетических полевых сцен. Вместе эти пулы формируют основу для генерации синтетических изображений на уровне пикселей.
2.3.1. Построение пула переднего плана
Для построения пула переднего плана для синтетических наборов данных на уровне пикселей отдельные экземпляры растений были сегментированы напрямую с использованием предоставленных масок-аннотаций из оригинального базового набора данных WE3DS. Этот процесс включал извлечение растений с точными полигональными аннотациями, обеспечивая точное отделение переднего плана от фона.
Сводка количества экземпляров для каждого вида в наборе данных представлена в Таблице 2, где для удобства предоставлен код EPPO для каждого вида растений. Дополнительно, в столбце crop/weed (культура/сорняк) C обозначает виды культур, а W — виды сорняков.
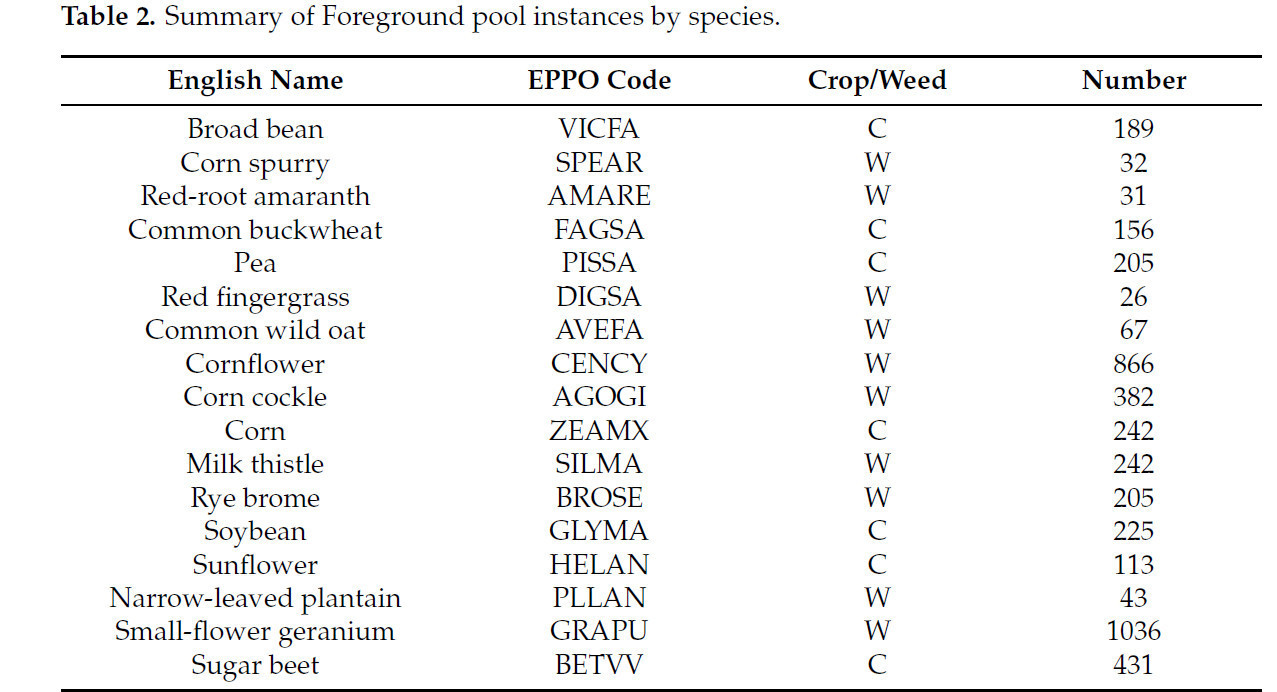
Таблица 2. Сводка экземпляров в пуле переднего плана по видам.
2.3.2. Построение пула фона
Для построения пула фона для синтетических наборов данных на уровне пикселей был использован метод обрезки наибольшего квадратного участка. В этом методе наибольшие возможные квадратные участки почвы были обрезаны из обучающего набора данных, в результате чего получилось 1540 фоновых изображений. Однако размеры этих наибольших квадратных участков сильно варьировались, и в некоторых случаях соотношения сторон были крайне экстремальными, при этом длина значительно превышала ширину или наоборот. Эта изменчивость создавала проблемы при обработке этих участков во время обучения сети, так как их изменение размера до фиксированного разрешения (например, 640 × 480) приводило к искажениям пропорций объектов.
Чтобы обеспечить основу для сравнения, мы также подготовили фоны, используя метод составного фона. В этом подходе меньшие обрезанные участки случайным образом выбирались и объединялись в один составной фон, соответствующий исходному разрешению (1600 × 1140). Этот метод сохранял соотношения сторон отдельных участков и увеличивал изменчивость в пуле фонов, вводя новые комбинации меньших участков. Два метода были сравнены для оценки их эффективности в генерации синтетических наборов данных для улучшения производительности сегментации.
2.3.3. Стратегия синтеза данных
Стратегия синтеза данных, использованная в этом исследовании, была вдохновлена методом, предложенным Skovsen и др. [39], который включает комбинирование объектов переднего плана с фоновыми изображениями для создания синтетических наборов данных для задач сегментации. В нашем подходе синтетические изображения генерировались следующими шагами:
1. Фоновое изображение случайным образом выбиралось из пула фонов. Этот фон служил холстом для размещения объектов переднего плана.
2. Случайное количество экземпляров культур (от 1 до 3) и сорняков (от 1 до 5) выбиралось из пула переднего плана и вставлялось на фон в случайных координатах. Это обеспечивало разнообразие синтетических изображений и отражало естественную вариацию, наблюдаемую в реальных сценах.
3. Аннотации на уровне пикселей, соответствующие размещению каждого объекта, генерировались для создания парных данных сегментации для обучения.
Выбор количества экземпляров для культур (от 1 до 3) и сорняков (от 1 до 5) был основан на распределении, наблюдавшемся в исходном наборе данных WE3DS, гарантируя, что синтетические данные отражают пропорции, найденные в реальном наборе данных.
Были сгенерированы пять различных масштабов — 1×, 5×, 10×, 15× и 20× от размера реального обучающего набора данных (1540 изображений) — чтобы предоставить широкий диапазон для оценки влияния объема данных на производительность сегментации. (Здесь x представляет коэффициент масштабирования, где 𝑥× указывает, что количество сгенерированных синтетических изображений в x раз больше размера исходного обучающего набора данных. Например, 1× соответствует 1540 синтетическим изображениям, а 5× соответствует 7700 синтетическим изображениям.) Рисунок 2 иллюстрирует пример синтетического набора данных на уровне пикселей, сгенерированного с использованием метода наибольших возможных квадратных участков почвы. Левое изображение показывает сгенерированную синтетическую полевую сцену, а правое изображение отображает соответствующую маску семантической сегментации на уровне пикселей. Разные цвета в маске представляют разные виды растений.

Рисунок 2. Пример синтетического набора данных на уровне пикселей, сгенерированного с использованием метода наибольших возможных квадратных участков почвы. Левое изображение (а) показывает сгенерированную синтетическую полевую сцену, а правое изображение (b) представляет соответствующую маску семантической сегментации на уровне пикселей, где разные цвета обозначают разные виды растений.
2.4. Синтетический набор данных на уровне патчей
Рисунок 3 показывает наш предложенный конвейер синтеза данных на уровне патчей. Процесс начинается с исходного реального набора данных, где объекты переднего плана (например, культуры и сорняки) и фоновые участки почвы извлекаются для формирования пула переднего плана и пула фона соответственно. Затем эти патчи комбинируются для генерации синтетического набора данных на основе патчей согласно определенной логике, который затем может быть объединен с исходным реальным набором данных для создания гибридного набора данных. Наш конвейер может улучшить сегментацию культур и сорняков на уровне вида в сельскохозяйственных сценах, обогащая исходный реальный набор данных синтетическими образцами.
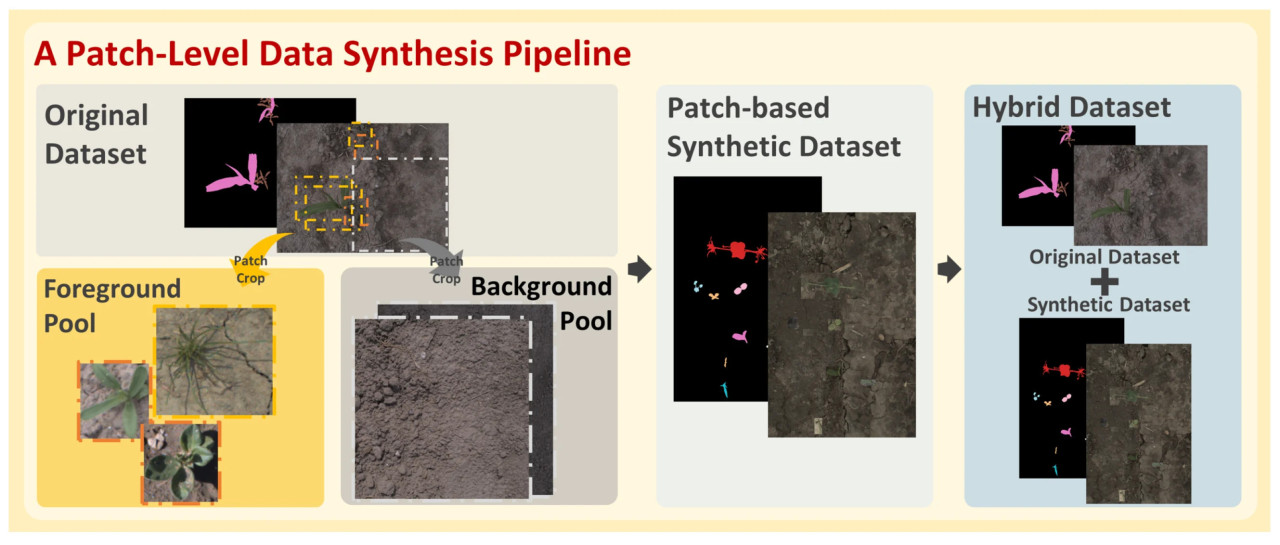
Рисунок 3. Предложенный конвейер синтеза данных на уровне патчей.
Синтетический набор данных на уровне патчей основан на пиксельном подходе с ключевой модификацией процесса извлечения переднего плана. Вместо сегментации экземпляров растений на уровне пикселей с использованием полигональных аннотаций, этот метод извлекает прямоугольные патчи, которые включают как растение, так и часть его непосредственного фона. Эти патчи определяются ограничивающими рамками (bounding boxes) полигональных аннотаций, сохраняя контекстную информацию вокруг растений и предлагая более простую, но эффективную альтернативу точной сегментации.
Построение пула фона для набора данных на уровне патчей следует той же процедуре, что и для набора данных на уровне пикселей. Фоны были подготовлены с использованием метода обрезки наибольшего квадратного участка и метода составного фона для решения проблем, связанных с изменчивостью размера и соотношения сторон. Оба метода предоставляют основу для создания синтетических полевых сцен.
Стратегия синтеза данных для набора данных на уровне патчей идентична пиксельному подходу. Фоны из пула фона комбинировались со случайным количеством экземпляров культур (от 1 до 3) и сорняков (от 1 до 5), выбранных из пула переднего плана на уровне патчей. Координаты размещения генерировались случайным образом, и аннотации на уровне пикселей, соответствующие размещению каждого объекта, создавались для обеспечения парных данных сегментации. Наборы данных генерировались в тех же масштабах 1×, 5×, 10×, 15× и 20×, где x обозначает количество синтетических изображений относительно реального обучающего набора данных (например, 1× соответствует 1540 изображениям, а 5× соответствует 7700 изображениям).

Рисунок 4 иллюстрирует пример синтетического набора данных на уровне патчей. Левая часть рисунка (а) показывает сгенерированную синтетическую полевую сцену, созданную с использованием прямоугольных патчей растений, а правая часть (b) отображает соответствующую маску семантической сегментации на уровне пикселей. Разные цвета в маске представляют различные виды растений, и этот пример наглядно показывает включение контекстной фоновой информации вокруг растений.
2.5. Гибридный набор данных
Чтобы определить оптимальную комбинацию реальных и синтетических данных для задач сегментации, мы создали гибридные наборы данных, смешивая исходный базовый набор данных (1540 изображений) с синтетическими наборами данных.
Если подробно, гибридные наборы данных были построены путем объединения полного реального обучающего набора данных с синтетическими данными в разных соотношениях от 1× до 20×. Например, гибрид 1× включал 1540 реальных изображений и 1540 синтетических изображений, в то время как гибрид 5× состоял из 1540 реальных изображений и 7700 синтетических изображений. Систематически изменяя эти соотношения, мы исследовали, как разные гибридные конфигурации влияют на производительность сегментации и вычислительную эффективность.
2.6. Дообучение на реальных данных
Чтобы предоставить всестороннее сравнение, мы также реализовали стратегию дообучения (fine-tuning), широко принятый метод, при котором модели сначала предобучаются на синтетических данных, а затем дообучаются на реальных данных.
В частности, модели сначала обучались исключительно на синтетических наборах данных с различным объемом данных от 1× до 20×, как описано ранее. После этого модели дообучались на исходном базовом наборе данных с использованием сниженной скорости обучения (learning rate) для адаптации к распределению реальных данных.
2.7. Оценка
Наша задача была направлена на сравнение производительности моделей семантической сегментации видов растений для трех типов наборов данных: набора данных WE3DS (реальные данные), полностью синтетических наборов данных и гибридных наборов данных (комбинации реальных и синтетических данных).
Для оценки мы использовали предопределенное тестовое разделение набора данных WE3DS, которое составляет 40% от общего набора данных, включая 1028 изображений. Это обеспечивает согласованность между оценками и предоставляет надежный эталон для оценки способности модели к обобщению.
2.7.1. Предварительная обработка данных
Чтобы обеспечить справедливое сравнение с исходными результатами WE3DS, мы приняли единообразную стратегию предварительной обработки, изложенную в статье WE3DS, применяя ее единообразно к реальным, синтетическим и гибридным наборам данных без какой-либо дополнительной аугментации данных. В частности, все изображения были изменены до размера 640 × 480 пикселей в соответствии с рекомендациями по предварительной обработке WE3DS. Значения пикселей затем нормализовались с использованием статистики ImageNet (𝑚𝑒𝑎𝑛={0.485,0.456,0.406} и 𝑠𝑡𝑑={0.229,0.224,0.225}), чтобы соответствовать требованиям входа для основы ResNet-50 [40].
2.7.2. Метрики
В семантической сегментации целью является классификация каждого пикселя в определенный класс, такой как почва, а в случае набора данных WE3DS — один из семи видов культур или десяти видов сорняков. Результатом этой задачи является цветная карта семантической сегментации, которая показывает состав и расположение различных видов на изображении.
Для оценки производительности модели мы используем метрику пересечения по объединению (Intersection over Union, IoU). IoU измеряет перекрытие между прогнозируемой сегментацией и «земной истиной» (ground truth) для каждого класса и определяется как
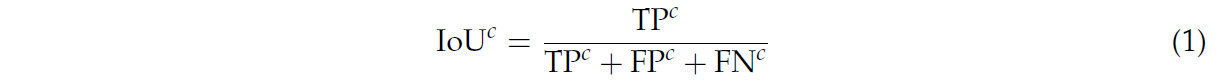
где c представляет класс, и 𝑐∈{1,...,𝑛,}. TP𝑐, FP𝑐 и FN𝑐 представляют истинно положительные, ложно положительные и ложно отрицательные результаты для класса c соответственно.
Для измерения общей производительности сегментации по всем классам рассчитывается среднее пересечение по объединению (mean Intersection over Union, mIoU):
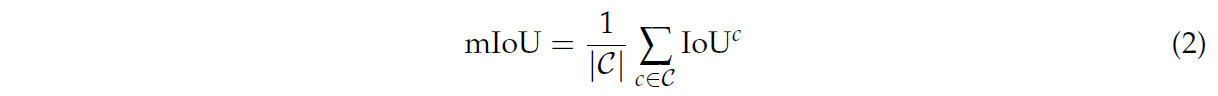
где 𝒞 — множество всех классов. Для этого исследования 𝒞 включает 1 класс почвы, 7 видов культур и 10 видов сорняков.
Однако, поскольку IoU для класса почвы (IoUsoil) стабильно высокий для всех моделей из-за его большой площади и отличительных особенностей, он может непропорционально влиять на расчет mIoU. Чтобы предоставить более точную оценку производительности моделей на видах растений, мы также рассчитываем mIoU, исключая класс почвы:
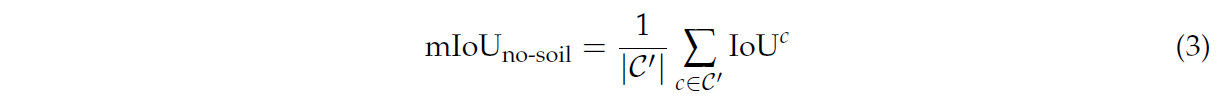
где 𝒞′ — множество всех классов, исключая класс почвы, включающее 7 видов культур и 10 видов сорняков (всего 17 классов).
Временная эффективность аугментации синтетическим набором данных оценивалась с использованием индекса эффективности производительности (Performance Efficiency Index, PEI). Эта метрика объединяет как улучшение производительности, так и вычислительные затраты в единую систему оценки. Вдохновленный метриками эффективности, используемыми в различных областях, PEI определяется как
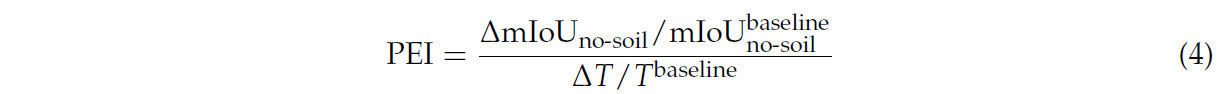
Здесь ΔmIoUno−soil представляет улучшение mIoUno−soil по сравнению с базовой производительностью, в то время как BaselinemIoUno−soil обозначает mIoUno−soil, достигнутый моделью, обученной на базовом наборе данных. Аналогично, Δ𝑇 указывает на разницу во времени обучения по сравнению с базовым временем обучения, и BaselineTime относится ко времени обучения, необходимому для базовой модели.
Этот пропорциональный подход оценивает, насколько эффективно данная стратегия аугментации улучшает производительность сегментации относительно дополнительных вычислительных затрат.
2.7.3. Выбор модели семантической сегментации
Наше исследование в основном сосредоточено на улучшении производительности модели в пределах одной архитектуры, а не на настройке архитектуры для оптимизации метрик производительности. Мы считаем тонкую настройку архитектуры модели последующим шагом, который часто зависит от конкретной области. Однако мы полагаем, что выбор модели с более сильной базовой производительностью лучше демонстрирует потенциал нашего предложенного метода. Таким образом, мы провели сравнительные эксперименты, используя несколько моделей сегментации на основе нейронных сетей, включая UNet [41], UNet++ [42], Xception-style UNet и DeepLab v3+ [43]. Примечательно, что все модели использовали одну и ту же основу ResNet-50 [40], предварительно обученную на ImageNet [44], для поддержания согласованности между экспериментами. Дополнительно, размерность выхода последнего слоя Conv2d была изменена на 18, что соответствует категориям в этом исследовании: 1 класс почвы, 7 видов культур и 10 видов сорняков.
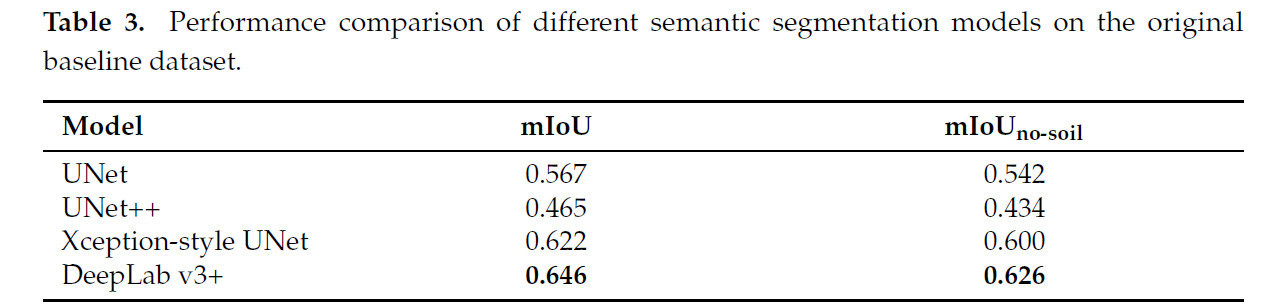
Таблица 3 показывает сравнение производительности на исходном базовом наборе данных, которое выявило, что DeepLab v3+ достиг наивысшего mIoU и mIoUno−soil, превзойдя другие. В результате DeepLab v3+ был выбран в качестве оценочной модели для всех последующих экспериментов.
Мы решили сосредоточиться на моделях на основе нейронных сетей, а не на моделях на основе трансформеров, таких как Vision Transformers [45] и Swin Transformers [46]. Модели на основе трансформеров обычно имеют большее количество параметров и требуют более обширных обучающих наборов данных, что приводит к более высоким требованиям к сбору данных, аннотированию и вычислительным ресурсам. Эти требования делают их менее подходящими для наших текущих целей, которые отдают приоритет вычислительной эффективности с минимальным количеством размеченных данных. Однако мы считаем, что наша методология может быть расширена для улучшения производительности моделей на основе трансформеров в будущих исследованиях.
3. Результаты
Все эксперименты проводились с использованием одной видеокарты NVIDIA RTX 3090 с 24 ГБ оперативной памяти. Модели обучались с размером пакета (batch size) 8 в течение 100 эпох с использованием оптимизатора Adam, со значениями 𝛽1, 𝛽2, установленными на 0.9 и 0.999 соответственно. Начальная скорость обучения была установлена на 0.001 и оставалась постоянной на протяжении всего процесса обучения. Эта конфигурация обеспечивала эффективное обучение при сохранении согласованности для всех наборов данных.
Для эксперимента с дообучением модели, предварительно обученные на синтетических наборах данных с различным объемом данных, дообучались на исходном базовом наборе данных с использованием сниженной скорости обучения 0.0005. Фаза дообучения была ограничена 20 эпохами, в то время как все остальные параметры, включая размер пакета и настройки оптимизатора, оставались неизменными.
3.1. Производительность базовой модели на исходном базовом наборе данных
Чтобы установить базовый уровень для сравнения, мы обучили модель DeepLab v3+ на неизмененном реальном обучающем наборе данных (1540 изображений) без какой-либо аугментации данных. Модель достигла mIoU примерно 0.62 на реальном тестовом наборе данных, предоставив эталон, по которому оценивались синтетические наборы данных.
3.2. Производительность на наборе данных с традиционной аугментацией
Чтобы оценить традиционные методы аугментации данных и сравнить их с методами на основе синтетических данных, мы реализовали три разные конфигурации, чтобы оценить их влияние на производительность сегментации, как описано в Разделе 2.2.
Результаты, проиллюстрированные в Таблице 4, указывают, что модели, обученные без какой-либо аугментации, достигли наивысших показателей mIoU: 0.646 и 0.626 для mIoU и mIoUno-soil соответственно.
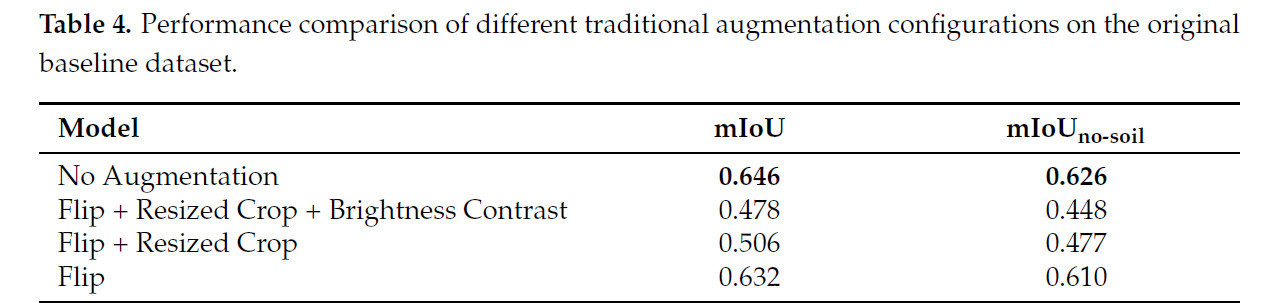
Таблица 4. Сравнение производительности разных конфигураций традиционной аугментации на исходном базовом наборе данных.
Этот контр-интуитивный результат может быть обусловлен несколькими факторами. Во-первых, введенные аугментации могли привести к избыточному преобразованию данных, заставляя модели изучать нерелевантные признаки, а не внутренние характеристики растений. Дополнительно, ограниченное разнообразие, введенное выбранными стратегиями аугментации, могло быть недостаточным для эффективного обобщения в различных реальных сценариях.
Более того, поиск оптимальной комбинации и параметров для аугментации данных может быть трудоемким и вычислительно затратным. Неправильно настроенные аугментации могут ввести шум или артефакты, которые негативно влияют на обучение модели.
Следовательно, для последующих экспериментов мы приняли версию без аугментации в качестве базовой, чтобы обеспечить справедливое и последовательное сравнение с нашим подходом синтетического набора данных.
3.3. Сравнение методов построения переднего плана
Чтобы сравнить эффективность синтетических наборов данных на уровне пикселей и патчей, мы сгенерировали наборы данных с тем же количеством изображений, что и исходный базовый набор данных (1540 изображений). Используя идентичные протоколы обучения, мы обучили модели DeepLab v3+ на:
1. Синтетических наборах данных на уровне пикселей: Они генерировались путем вставки экземпляров растений, извлеченных на уровне пикселей, на случайно выбранные фоны.
2. Синтетических наборах данных на уровне патчей: Они генерировались путем вставки патчей растений (передний план плюс окружающий фон) на фоны.
Таблица 5 представляет производительность mIoU модели DeepLab v3+, обученной на трех различных наборах данных: исходном базовом наборе данных, синтетических данных на уровне пикселей и синтетических данных на уровне патчей. Результаты показаны как для сценариев обучения, так и тестирования, с почвой и без почвы во входных данных.
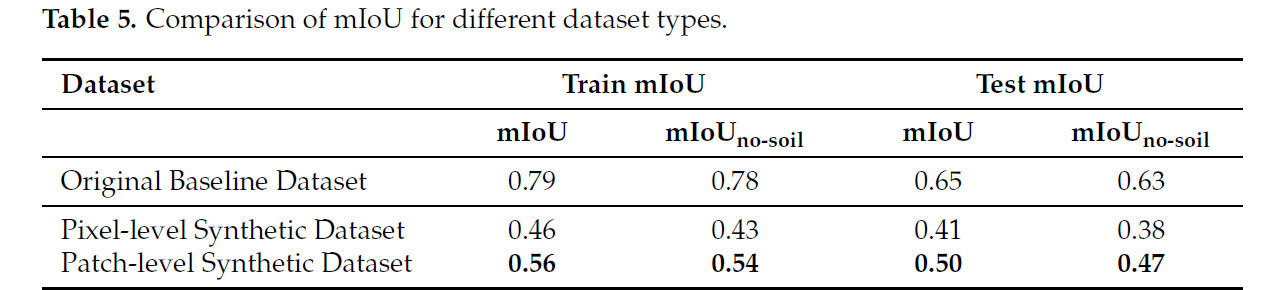
Таблица 5. Сравнение mIoU для разных типов наборов данных.
Базовая модель, обученная на исходном базовом наборе данных, достигла наивысших показателей mIoU: 0.79 и 0.65 для обучения и тестирования (с почвой) соответственно. Для сравнения, модель, обученная на синтетических данных на уровне пикселей, показала значительно более низкую производительность, особенно на фазе тестирования, с показателями mIoU 0.41 (с почвой) и 0.38 (без почвы). Примечательно, что синтетические данные на уровне патчей показали заметные улучшения по сравнению с пиксельным подходом, достигнув показателей тестового mIoU 0.50 (с почвой) и 0.47 (без почвы). Это подчеркивает эффективность метода генерации на уровне патчей, который лучше сохраняет контекстную информацию вокруг объектов, что приводит к улучшенному обобщению модели.
В целом, результаты подчеркивают ограничения синтетических данных на уровне пикселей и важность включения дополнительного контекста через методы уровня патчей для улучшения производительности сегментации. Методы сегментации на уровне пикселей склонны вводить артефакты по краям, приводя к пиксельным ошибкам вдоль границ экземпляров растений. Эти артефакты тесно связаны с точностью полигональных аннотаций, используемых во время извлечения. Дополнительно, пиксельные подходы часто приводят к потере теней переднего плана, которые ключевые для точного представления признаков. Эти проблемы могут вводить сеть сегментации в заблуждение, заставляя ее полагаться на эти нерелевантные или искаженные признаки, а не на характеристики растений, тем самым снижая точность модели. В отличие от этого, методы уровня патчей эффективно сохраняют тени и сводят к минимуму артефакты краев, поддерживая контекстуальную целостность экземпляров растений в их окружающей среде. Хотя края ограничивающих рамок могут вводить разрывы значений пикселей, влияние этих разрывов смягчается через слои пулинга и свертки сети, которые помогают сгладить эти нерегулярности. Следовательно, подходы уровня патчей повышают разнообразие данных при сохранении высокого уровня реализма, приводя к более точной и надежной производительности сегментации.
3.4. Сравнение методов построения фона
Чтобы оценить эффективность различных методов построения фона для синтетических наборов данных на уровне патчей, мы сравнили производительность моделей DeepLab v3+, обученных на наборах данных, сгенерированных с использованием метода обрезки наибольшего квадратного участка и метода составного фона. Для этого сравнения синтетические наборы данных генерировались в различных масштабах: 1×, 5×, 10×, 15× и 20× от размера реального обучающего набора данных (1540 изображений на масштаб). Это масштабирование предоставило последовательную основу для изучения влияния построения набора данных на производительность сегментации. Результаты, измеренные как mIoU на реальном тестовом наборе данных, представлены на Рисунке 5.
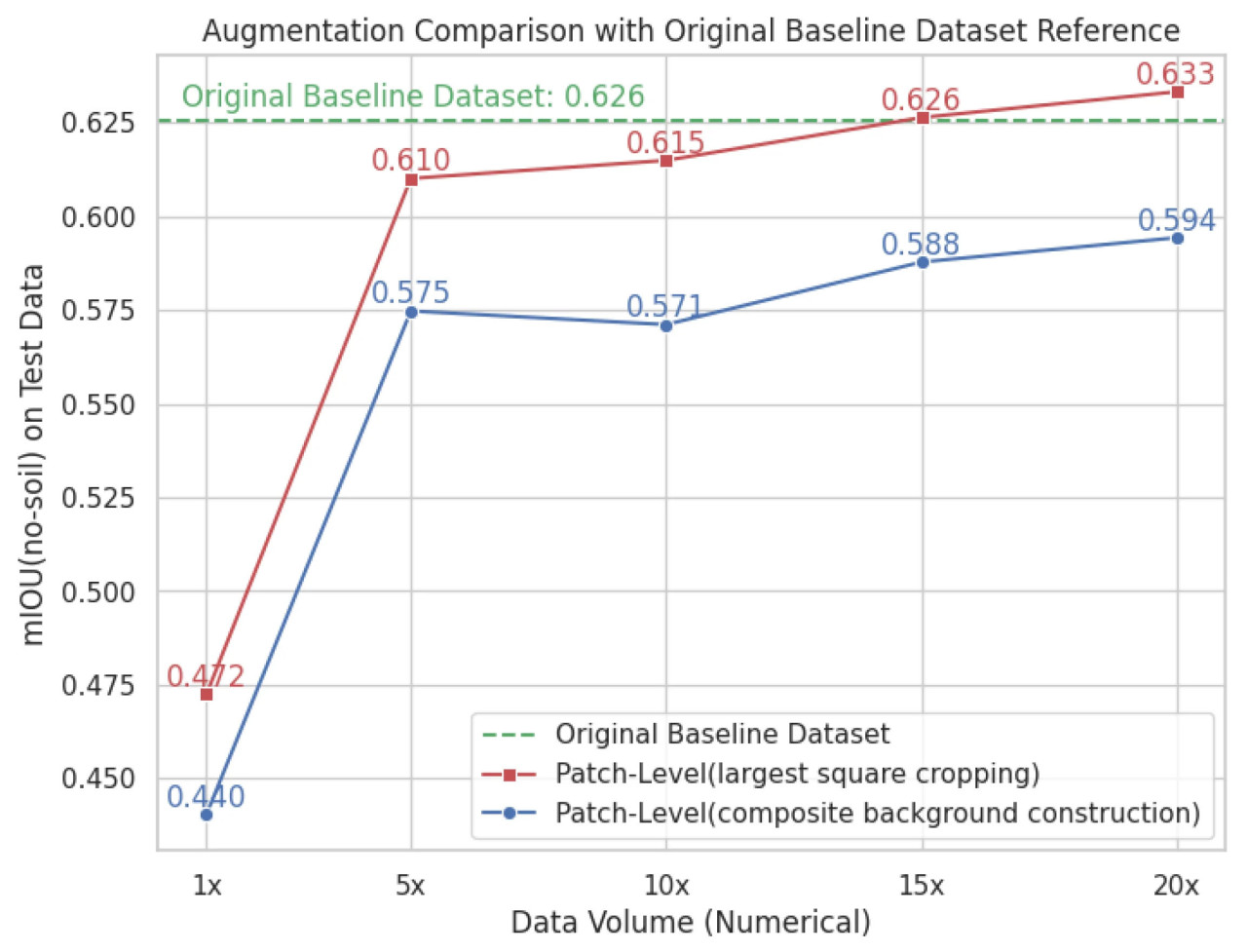
Рисунок 5. Влияние методов построения фона на mIoU для синтетических наборов данных на уровне патчей. Ось x представляет объем данных (масштабированный множителями исходного набора данных), а ось y показывает mIoUno−soil на тестовых данных, исключая области почвы. Зеленая пунктирная линия указывает исходный базовый набор данных, красная линия представляет метод уровня патчей (обрезка наибольшего квадратного участка), а синяя линия представляет метод уровня патчей (составное построение фона).
Рисунок 5 наглядно показывает сравнительную производительность двух методов построения фона в различных масштабах наборов данных. mIoU исходного базового набора данных (0.626) включен в качестве ориентира. Результаты показывают, что метод обрезки наибольшего квадратного участка стабильно превосходил метод составного построения фона во всех масштабах наборов данных. При меньших масштабах (например, 1× и 5×) метод обрезки наибольшего квадратного участка достигал заметно более высоких значений mIoU: 0.440 против 0.472 при масштабе 1× и 0.575 против 0.610 при масштабе 5×. Эта тенденция продолжилась при больших масштабах: метод обрезки наибольшего квадратного участка достиг 0.594 при масштабе 20× по сравнению с 0.633 для метода составного построения фона.
Оба метода показали улучшение mIoU с увеличением размера набора данных, но метод обрезки наибольшего квадратного участка стабильно давал лучшие результаты. Это может быть объяснено введением различных соотношений сторон в фоновых областях. Эта изменчивость, введенная через прямое изменение размера изображений с несоответствующими размерами, эффективно действует как неявная форма аугментации данных. Такие несоответствия соотношения сторон могут помочь модели лучше обобщать, подвергая ее более широкому диапазону пропорций изображений, тем самым способствуя наблюдаемому росту производительности.
3.5. Определение оптимального соотношения для гибридных наборов данных в семантической сегментации
Подход гибридного набора данных был оценен для определения оптимальной комбинации реальных и синтетических данных для семантической сегментации видов растений. Модели обучались с использованием различных гибридных соотношений, от 1:1 (1540 реальных изображений + 1540 синтетических изображений) до 1:20 (1540 реальных изображений + 30 800 синтетических изображений). Для оценки производительности использовались метрики mIoU и mIoU без почвы (mIoUno-soil), и результаты представлены в Таблице 6.
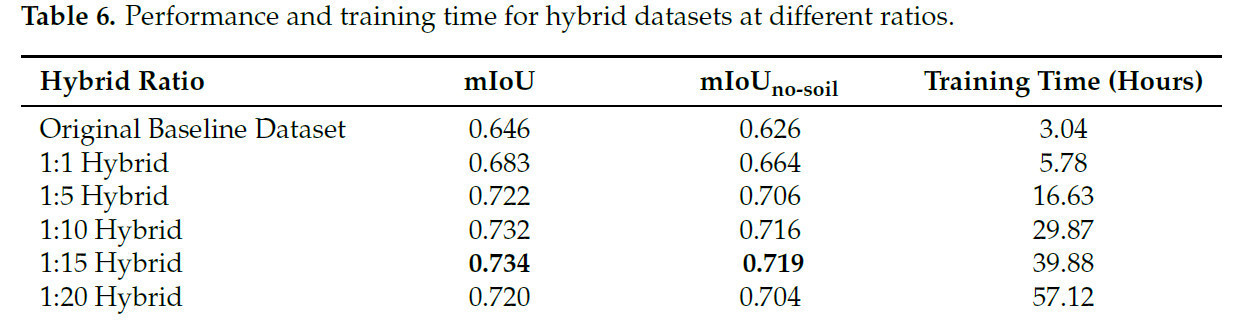
Таблица 6. Производительность и время обучения для гибридных наборов данных при разных соотношениях.
Результаты на Рисунке 6 показывают, что увеличение доли синтетических данных улучшает производительность сегментации, при этом mIoUno-soil достигает пика 0.719 для гибридного соотношения 1:15. Однако улучшение уменьшается с большими соотношениями, такими как 1:20, где mIoUno-soil снижается до 0.704.

Рисунок 6. Производительность vs. время обучения для гибридных наборов данных. Ось y представляет mIoUno-soil, а ось x представляет время обучения в часах. Слева направо точки соответствуют базовому уровню, соотношениям 1:1, 1:5, 1:10, 1:15 и 1:20 реальных данных к синтетическим данным.
Рисунок 7 предоставляет дополнительную перспективу, представляя PEI (индекс эффективности производительности), который оценивает баланс между приростом производительности и требуемым временем обучения. Результаты предполагают, что гибридные соотношения 1:10 и 1:15 обеспечивают оптимальный компромисс, достигая высокого mIoUno-soil с разумным временем обучения. Соотношения больше 1:15 показывают сниженный PEI, указывая на потерю эффективности.
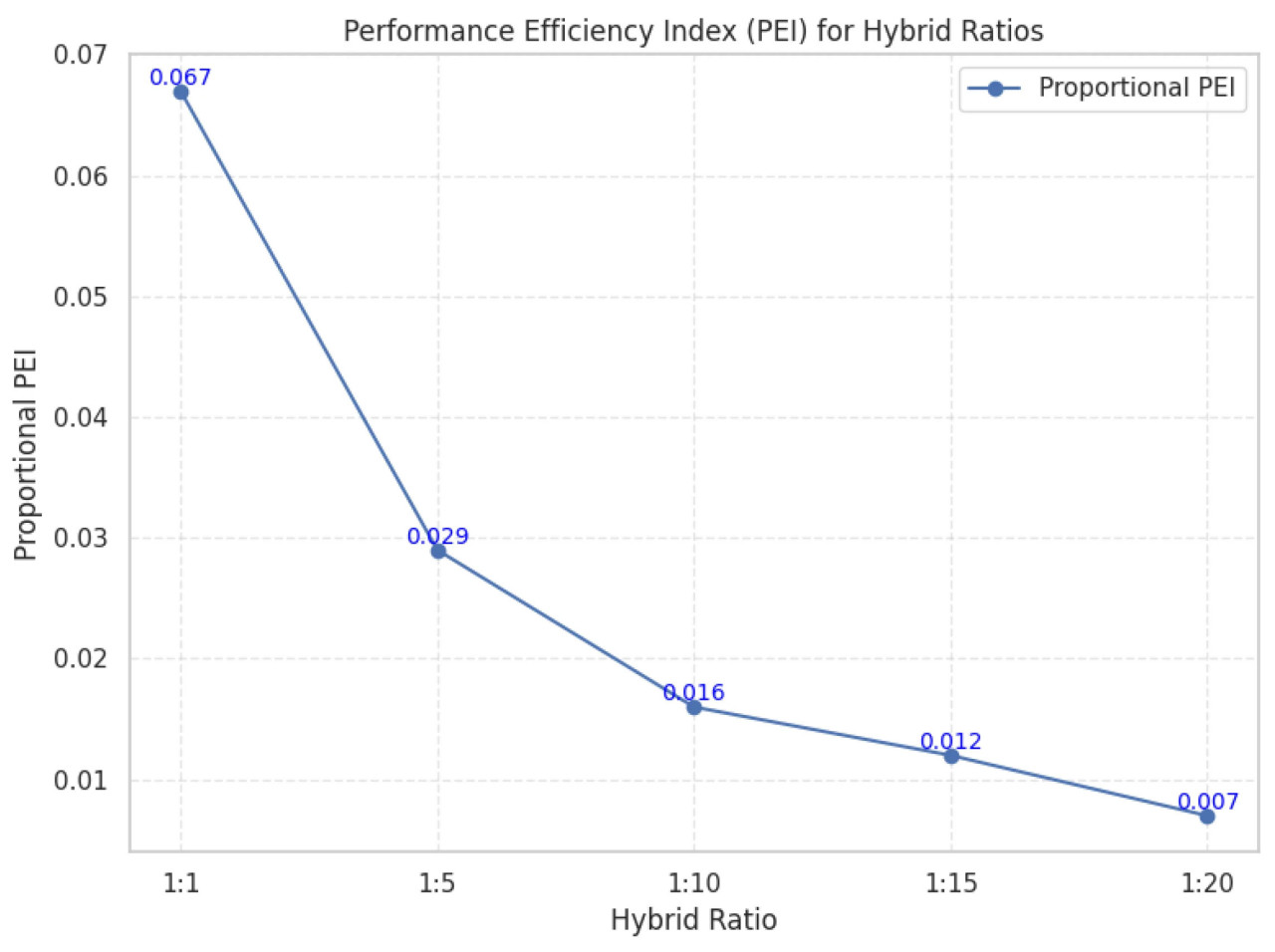
Рисунок 7. PEI для разных гибридных соотношений. Ось y представляет метрику PEI, где более высокие значения указывают на лучшую эффективность в балансировке прироста производительности и времени обучения. Ось x представляет разные гибридные соотношения реальных данных к синтетическим данным, показывая долю реальных данных к синтетическим в процессе обучения.
В целом, анализ подчеркивает важность балансировки размера набора данных, производительности сегментации и вычислительных затрат. Для приложений, отдающих приоритет эффективности, рекомендуется соотношение 1:10, в то время как соотношение 1:15 более подходит для сценариев, требующих пиковой производительности сегментации.
3.6. Результаты дообучения и сравнение с гибридным набором данных
Стратегия дообучения также является часто используемой стратегией для преодоления разрыва между распределениями синтетических и реальных данных. В этом разделе также были проведены эксперименты методов дообучения для сравнения с гибридным набором данных. В частности, модели предварительно обучались исключительно на синтетических наборах данных с различным объемом данных и впоследствии дообучались на исходном базовом наборе данных.
Производительность подхода дообучения оценивалась с использованием метрик mIoU и mIoUno-soil. Результаты представлены в Таблице 7, которая также включает результаты метода гибридного набора данных для сравнения.
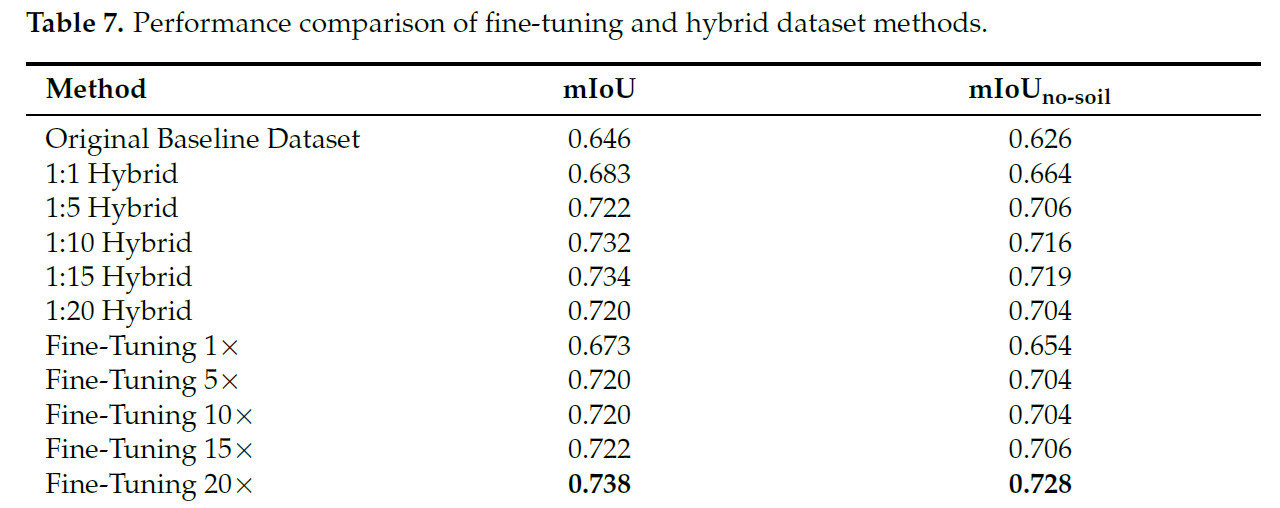
Таблица 7. Сравнение производительности методов дообучения и гибридного набора данных.
Результаты показали, что как метод дообучения, так и подход гибридного набора данных улучшают производительность сегментации по сравнению с обучением только на исходном базовом наборе данных. Примечательно, что метод дообучения достиг немного более высокого mIoU 0.738 и mIoUno-soil 0.728 при объеме данных 20×, превзойдя гибридный набор данных 1:15, который достиг 0.734 и 0.719 соответственно. Оба метода продемонстрировали схожее время обучения, указывая, что включение синтетических данных либо через гибридные наборы данных, либо через дообучение не накладывает дополнительных вычислительных нагрузок сверх начальной фазы обучения.
Метод гибридного набора данных предлагает простой и эффективный способ одновременного использования как реальных, так и синтетических данных в процессе обучения. Этот подход упрощает рабочий процесс обучения, устраняя необходимость в отдельной фазе дообучения, тем самым снижая сложность конвейера обучения. Дополнительно, гибридный метод эффективно балансирует разнообразие данных и вычислительную эффективность, гарантируя, что модель получает выгоду от богатого представления признаков, предоставляемого синтетическими данными, сохраняя при этом надежную производительность на реальных данных.
Напротив, подход дообучения, хотя и достигает немного более высоких показателей mIoU, требует дополнительной фазы обучения, которая включает настройку модели на реальных данных после начального обучения на синтетических данных. Этот двухэтапный процесс может вносить сложности в рабочий процесс обучения и требует тщательного управления параметрами обучения, чтобы избежать переобучения во время дообучения. Тем не менее, дообучение предоставляет гибкую структуру для дополнительного повышения производительности модели, особенно когда становится доступно больше реальных данных.
В целом, как методы гибридного набора данных, так и дообучения демонстрируют значительные улучшения в производительности сегментации за счет включения синтетических данных. Выбор между этими методами зависит от конкретных требований и ограничений приложения, таких как необходимость упрощенных процессов обучения в противовес желанию дополнительного прироста производительности через специализированные фазы обучения.
4. Обсуждение
По сравнению с другими исследованиями в области сельскохозяйственной семантической сегментации, наш метод генерации синтетических данных на основе патчей предлагает отличительные преимущества. По сравнению с традиционными подходами, которые полагаются на сбор обширных наборов реальных данных, наш метод использует синтетические данные для аугментации существующих наборов, уменьшая потребность в обширном сборе полевых данных. По сравнению с методами, которые также используют синтетические данные для улучшения моделей сегментации, эти методы часто полагаются на дополнительные модели глубокого обучения для генерации синтетических данных, в то время как наш метод использует простую технику «копирования-вставки». Это не только снижает вычислительную сложность и потенциальную нестабильность, вносимую обучением новых моделей, но и достигает сопоставимых или даже лучших улучшений в производительности модели.
Хотя предложенный метод генерации синтетических данных на основе патчей показывает перспективность, существуют и ограничения. Вставка патчей на фоны почвы не учитывает вариацию условий почвы, таких как влажность, сухость или изменения цвета, которые могут значительно отличаться в различных условиях окружающей среды или сезонах. Будущая работа может устранить эти ограничения, разрабатывая методы, которые динамически адаптируют патчи к различным типам почвы, текстурам, уровням влажности и условиям освещения. Одна перспективная стратегия — интеграция GANs для моделирования изменчивости почвы. GANs можно обучать для генерации реалистичных фонов почвы с разнообразными характеристиками, такими как разные уровни влажности, текстуры и вариации цвета, тем самым повышая реализм и разнообразие синтетических данных.
Дополнительно, подход предполагает, что один и тот же вид культуры или сорняка выглядит одинаково в различных стадиях роста, что не всегда отражает реальность. Эти факторы ограничивают обобщаемость синтетических наборов данных, созданных с этим методом, делая их наиболее эффективными при применении к конкретным участкам, стадиям роста или условиям окружающей среды. Это ограничение можно устранить, включив временные данные стадий роста, которые фиксируют прогрессию развития растений с течением времени, включая изменения в размере, форме, цвете и плотности. Интегрируя временные данные стадий роста в конвейер, синтетические наборы данных могут точнее представлять динамическую природу роста растений. Практически это может быть достигнуто путем создания библиотек патчей, специфичных для стадий, которые отражают разные фенологические стадии, и систематического обновления этих патчей по мере созревания растений.
Расширение предложенного метода генерации синтетических данных на основе патчей на другие культуры или наборы данных перспективно, но требует тщательного учета характеристик культур и свойств наборов данных. Когда несколько экземпляров одной категории перекрываются в маске, семантическая сегментация не может различать отдельные растения, что приводит к патчам, содержащим перекрывающиеся особи или растения из других категорий. Хотя эта проблема оказывает незначительное влияние на данные с низкой плотностью из-за ее редкости, она создает значительные проблемы для реальных сценариев с высокой плотностью посадки. В средах с высокой плотностью патчи с большей вероятностью будут включать множество перекрывающихся особей или растений других категорий, что приводит к уменьшению количества пригодных патчей и снижению разнообразия. Дополнительно, наличие нескольких категорий в одном патче может вносить шум в аннотации, вводя модель в заблуждение во время обучения и снижая точность сегментации. Эти факторы в совокупности ограничивают обобщаемость синтетических наборов данных, созданных текущим методом, при применении к плотно засаженным сельскохозяйственным полям. Чтобы повысить обобщаемость, будущие адаптации метода на основе патчей должны включать аннотации на уровне экземпляров и использовать передовые техники для точного моделирования перекрытий растений и сохранения целостности аннотаций в условиях высокой плотности.
Будущая работа может быть сосредоточена на решении нескольких ключевых задач и расширении потенциала генерации синтетических данных для семантической сегментации. Улучшение разнообразия как элементов переднего плана, так и фона является ключевым, поскольку текущие методы в основном сосредоточены на разнообразии композиции. Такие техники, как аугментация текстуры и формы на основе GAN, а также методы, которые совместно синтезируют компоненты переднего плана и фона, могли бы улучшить визуальный реализм и устранить несоответствия на границах. Дополнительно, решение проблемы дисбаланса классов, особенно для мало представленных видов, остается ключевым; будущие усилия могли бы интегрировать передовые стратегии выборки или методы полуконтролируемого обучения для лучшей обработки редких классов. Улучшение достоверности и разнообразия данных, генерируемых GAN, через передовые архитектуры и функции потерь также будет ключевым. Наконец, использование новых генеративных моделей, таких как диффузионные модели или фреймворки текст-в-изображение, может открыть новые возможности для генерации высоко разнообразных и реалистичных синтетических наборов данных. Обеспечение надежности и применимости этих методов в реальных сценариях, с различными условиями окружающей среды и культур, будет жизненно важным для продвижения использования моделей сегментации в сельскохозяйственных приложениях.
5. Выводы
В этом исследовании мы изучили генерацию и интеграцию синтетических наборов данных для улучшения семантической сегментации для сельскохозяйственных применений. Был предложен конвейер генерации синтетического набора данных на уровне патчей, который превзошел исходный базовый набор данных по точности сегментации. Дополнительно, мы исследовали гибридные наборы данных, комбинирующие реальные и синтетические данные в различных соотношениях, и определили оптимальный баланс между производительностью и вычислительной эффективностью. Для этого мы предложили PEI, новую метрику эффективности для количественной оценки прироста производительности от добавления синтетических данных относительно связанных вычислительных затрат. Результаты подчеркивают потенциал использования синтетических данных, при этом лучший гибридный набор данных достиг значительных улучшений в метриках сегментации по сравнению только с реальными данными.
В заключение, наше исследование подчеркивает потенциал синтетических данных как инструмента в сельскохозяйственных исследованиях, позволяя рентабельные и масштабируемые решения для задач семантической сегментации. Мы внесли вклад в продвижение методологий синтетических данных, проанализировав разные техники генерации переднего плана и фона, введя метрику эффективности для оценки производительности относительно стоимости обучения и исследовав ограничения аугментации разнообразия на основе GAN. Эти вклады закладывают основу для дальнейших инноваций в генерации синтетических данных в различных условиях окружающей среды и влияния на точное управление сорняками на реальных полях.
Ссылки
1. Parven, A.; Meftaul, I.M.; Venkateswarlu, K.; Megharaj, M. Herbicides in modern sustainable agriculture: Environmental fate, ecological implications, and human health concerns. Int. J. Environ. Sci. Technol. 2024, 22, 1181–1202. [Google Scholar] [CrossRef]
2. Schütte, G.; Eckerstorfer, M.; Rastelli, V.; Reichenbecher, W.; Restrepo-Vassalli, S.; Ruohonen-Lehto, M.; Saucy, A.G.W.; Mertens, M. Herbicide resistance and biodiversity: Agronomic and environmental aspects of genetically modified herbicide-resistant plants. Environ. Sci. Eur. 2017, 29, 5. [Google Scholar] [CrossRef]
3. Hartmann, M.; Six, J. Soil structure and microbiome functions in agroecosystems. Nat. Rev. Earth Environ. 2023, 4, 4–18. [Google Scholar] [CrossRef]
4. Wagg, C.; Bender, S.F.; Widmer, F.; Van Der Heijden, M.G. Soil biodiversity and soil community composition determine ecosystem multifunctionality. Proc. Natl. Acad. Sci. USA 2014, 111, 5266–5270. [Google Scholar] [CrossRef] [PubMed]
5. Adeux, G.; Vieren, E.; Carlesi, S.; Bàrberi, P.; Munier-Jolain, N.; Cordeau, S. Mitigating crop yield losses through weed diversity. Nat. Sustain. 2019, 2, 1018–1026. [Google Scholar] [CrossRef]
6. Sharma, A.; Kumar, V.; Shahzad, B.; Tanveer, M.; Sidhu, G.P.S.; Handa, N.; Kohli, S.K.; Yadav, P.; Bali, A.S.; Parihar, R.D.; et al. Worldwide pesticide usage and its impacts on ecosystem. SN Appl. Sci. 2019, 1, 1446. [Google Scholar] [CrossRef]
7. Kraehmer, H.; Laber, B.; Rosinger, C.; Schulz, A. Herbicides as weed control agents: State of the art: I. Weed control research and safener technology: The path to modern agriculture. Plant Physiol. 2014, 166, 1119–1131. [Google Scholar] [CrossRef]
8. Wiles, L. Beyond patch spraying: Site-specific weed management with several herbicides. Precis. Agric. 2009, 10, 277–290. [Google Scholar] [CrossRef]
9. Lati, R.N.; Rasmussen, J.; Andujar, D.; Dorado, J.; Berge, T.W.; Wellhausen, C.; Pflanz, M.; Nordmeyer, H.; Schirrmann, M.; Eizenberg, H.; et al. Site-specific weed management—constraints and opportunities for the weed research community: Insights from a workshop. Weed Res. 2021, 61, 147–153. [Google Scholar] [CrossRef]
10. Nguyen, T.T.; Hoang, T.D.; Pham, M.T.; Vu, T.T.; Nguyen, T.H.; Huynh, Q.T.; Jo, J. Monitoring agriculture areas with satellite images and deep learning. Appl. Soft Comput. 2020, 95, 106565. [Google Scholar] [CrossRef]
11. Waldner, F.; Diakogiannis, F. Extracting field boundaries from satellite imagery with a convolutional neural network to enable smart farming at scale. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 3–8 May 2020; p. 102. [Google Scholar]
12. Papadomanolaki, M.; Vakalopoulou, M.; Zagoruyko, S.; Karantzalos, K. Benchmarking deep learning frameworks for the classification of very high resolution satellite multispectral data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 83–88. [Google Scholar] [CrossRef]
13. Feng, Q.; Yang, J.; Liu, Y.; Ou, C.; Zhu, D.; Niu, B.; Liu, J.; Li, B. Multi-temporal unmanned aerial vehicle remote sensing for vegetable mapping using an attention-based recurrent convolutional neural network. Remote Sens. 2020, 12, 1668. [Google Scholar] [CrossRef]
14. Ye, Z.; Yang, K.; Lin, Y.; Guo, S.; Sun, Y.; Chen, X.; Lai, R.; Zhang, H. A comparison between Pixel-based deep learning and Object-based image analysis (OBIA) for individual detection of cabbage plants based on UAV Visible-light images. Comput. Electron. Agric. 2023, 209, 107822. [Google Scholar] [CrossRef]
15. Reedha, R.; Dericquebourg, E.; Canals, R.; Hafiane, A. Transformer neural network for weed and crop classification of high resolution UAV images. Remote Sens. 2022, 14, 592. [Google Scholar] [CrossRef]
16. Sujatha, K.; Reddy, T.K.; Bhavani, N.; Ponmagal, R.; Srividhya, V.; Janaki, N. UGVs for Agri Spray with AI assisted Paddy Crop disease Identification. Procedia Comput. Sci. 2023, 230, 70–81. [Google Scholar] [CrossRef]
17. Xu, R.; Li, C. A review of high-throughput field phenotyping systems: Focusing on ground robots. Plant Phenomics 2022, 2022, 9760269. [Google Scholar] [CrossRef] [PubMed]
18. Silva, J.A.O.S.; de Siqueira, V.S.; Mesquita, M.; Vale, L.S.R.; da Silva, J.L.B.; da Silva, M.V.; Lemos, J.P.B.; Lacerda, L.N.; Ferrarezi, R.S.; de Oliveira, H.F.E. Artificial Intelligence Applied to Support Agronomic Decisions for the Automatic Aerial Analysis Images Captured by UAV: A Systematic Review. Agronomy 2024, 14, 2697. [Google Scholar] [CrossRef]
19. Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
20. Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
21. Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
22. Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Steen, K.A.; Green, O.; Eriksen, J.; Gislum, R.; Jørgensen, R.N.; Karstoft, H. Estimation of the botanical composition of clover-grass leys from RGB images using data simulation and fully convolutional neural networks. Sensors 2017, 17, 2930. [Google Scholar] [CrossRef]
23. Toda, Y.; Okura, F.; Ito, J.; Okada, S.; Kinoshita, T.; Tsuji, H.; Saisho, D. Training instance segmentation neural network with synthetic datasets for crop seed phenotyping. Commun. Biol. 2020, 3, 173. [Google Scholar] [CrossRef] [PubMed]
24. Sapkota, B.B.; Popescu, S.; Rajan, N.; Leon, R.G.; Reberg-Horton, C.; Mirsky, S.; Bagavathiannan, M.V. Use of synthetic images for training a deep learning model for weed detection and biomass estimation in cotton. Sci. Rep. 2022, 12, 19580. [Google Scholar] [CrossRef]
25. Valerio Giuffrida, M.; Scharr, H.; Tsaftaris, S.A. Arigan: Synthetic arabidopsis plants using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Paris, France, 2–6 October 2017; pp. 2064–2071. [Google Scholar]
26. Zhu, Y.; Aoun, M.; Krijn, M.; Vanschoren, J.; Campus, H.T. Data Augmentation using Conditional Generative Adversarial Networks for Leaf Counting in Arabidopsis Plants. In Proceedings of the BMVC 2018, Newcastle, UK, 3–6 September 2018; Volume 2018, pp. 121–125. [Google Scholar]
27. Madsen, S.L.; Dyrmann, M.; Jørgensen, R.N.; Karstoft, H. Generating artificial images of plant seedlings using generative adversarial networks. Biosyst. Eng. 2019, 187, 147–159. [Google Scholar] [CrossRef]
28. Madsen, S.L.; Mortensen, A.K.; Jorgensen, R.N.; Karstoft, H. Disentangling information in artificial images of plant seedlings using semi-supervised GAN. Remote Sens. 2019, 11, 2671. [Google Scholar] [CrossRef]
29. Li, T.; Asai, M.; Kato, Y.; Fukano, Y.; Guo, W. Channel Attention GAN-Based Synthetic Weed Generation for Precise Weed Identification. Plant Phenomics 2024, 6, 0122. [Google Scholar] [CrossRef] [PubMed]
30. Fawakherji, M.; Potena, C.; Pretto, A.; Bloisi, D.D.; Nardi, D. Multi-spectral image synthesis for crop/weed segmentation in precision farming. Robot. Auton. Syst. 2021, 146, 103861. [Google Scholar] [CrossRef]
31. Fawakherji, M.; Suriani, V.; Nardi, D.; Bloisi, D.D. Shape and style GAN-based multispectral data augmentation for crop/weed segmentation in precision farming. Crop Prot. 2024, 184, 106848. [Google Scholar] [CrossRef]
32. Picon, A.; San-Emeterio, M.G.; Bereciartua-Perez, A.; Klukas, C.; Eggers, T.; Navarra-Mestre, R. Deep learning-based segmentation of multiple species of weeds and corn crop using synthetic and real image datasets. Comput. Electron. Agric. 2022, 194, 106719. [Google Scholar] [CrossRef]
33. Modak, S.; Stein, A. Synthesizing training data for intelligent weed control systems using generative ai. In Proceedings of the International Conference on Architecture of Computing Systems; Springer: Berlin/Heidelberg, Germany, 2024; pp. 112–126. [Google Scholar]
34. Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
35. Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10684–10695. [Google Scholar]
36. Chen, D.; Qi, X.; Zheng, Y.; Lu, Y.; Huang, Y.; Li, Z. Synthetic data augmentation by diffusion probabilistic models to enhance weed recognition. Comput. Electron. Agric. 2024, 216, 108517. [Google Scholar] [CrossRef]
37. Kitzler, F.; Barta, N.; Neugschwandtner, R.W.; Gronauer, A.; Motsch, V. WE3DS: An RGB-D image dataset for semantic segmentation in agriculture. Sensors 2023, 23, 2713. [Google Scholar] [CrossRef]
38. Dyrmann, M.; Mortensen, A.K.; Midtiby, H.S.; Jørgensen, R.N. Pixel-wise classification of weeds and crops in images by using a fully convolutional neural network. In Proceedings of the International Conference on Agricultural Engineering, Aarhus, Denmark, 26–29 June 2016; pp. 26–29. [Google Scholar]
39. Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Laursen, M.S.; Gislum, R.; Eriksen, J.; Farkhani, S.; Karstoft, H.; Jorgensen, R.N. The GrassClover image dataset for semantic and hierarchical species understanding in agriculture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
40. He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
41. Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
42. Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
43. Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
44. Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
45. Dosovitskiy, A. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
46. Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]

Li T, Burridge J, Blok PM, Guo W. A Patch-Level Data Synthesis Pipeline Enhances Species-Level Crop and Weed Segmentation in Natural Agricultural Scenes. Agriculture. 2025; 15(2):138. https://doi.org/10.3390/agriculture15020138
Перевод статьи «A Patch-Level Data Synthesis Pipeline Enhances Species-Level Crop and Weed Segmentation in Natural Agricultural Scenes» авторов Li T, Burridge J, Blok PM, Guo W., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)