Один для всех: новая модель ИИ считает листья у разных культур
Точная сегментация и подсчет листьев имеют решающее значение для развития фенотипирования сельскохозяйственных культур и совершенствования селекционных программ. В данном исследовании оцениваются модели на основе YOLOv11 для автоматического обнаружения и сегментации листьев у ярового ячменя, яровой пшеницы, озимой пшеницы, озимой ржи и озимой тритикале. Ключевой задачей является оценка того, может ли унифицированная модель, обученная на объединенном наборе данных по нескольким культурам, превзойти модели, специализированные для отдельных культур.
Аннотация
Результаты показывают, что унифицированная модель демонстрирует превосходную производительность в задачах детекции (ограничивающие рамки), с mAP@50 более 0.85 для яровых культур и 0.7 для озимых. Однако в задачах сегментации результаты неоднозначны: специализированные модели иногда превосходят унифицированную по полноте (recall) для озимых культур. Эти результаты подчеркивают преимущества разнообразия данных для улучшения обобщающей способности модели, одновременно указывая на необходимость создания более крупных размеченных наборов данных для учета изменчивости реальных условий. В то время как объединенный набор данных улучшает обобщение, уникальные характеристики отдельных культур могут по-прежнему требовать специализированного обучения.
1. Введение
В современном сельском хозяйстве точное фенотипирование растений имеет ключевое значение для развития программ селекции сельскохозяйственных культур, оптимизации сельскохозяйственных практик и решения глобальной проблемы продовольственной безопасности [1]. Растущий спрос на продовольствие, вызванный увеличением населения, наряду с проблемами, обусловленными изменением климата и ограниченностью пахотных земель, сделал разработку эффективных и точных методов анализа признаков растений важнейшим приоритетом [2]. Среди различных признаков точная сегментация и идентификация листьев на ранних стадиях развития сельскохозяйственных культур в частности важны для понимания здоровья растений, динамики роста и развития в различных сортах. Однако автоматизированный анализ этих признаков остается сложной задачей из-за окклюзии, изменчивости окружающей среды и сложной морфологии сельскохозяйственных растений.
Традиционные методы фенотипирования растений в значительной степени опираются на ручные наблюдения и измерения [3]. Хотя эти методы служили основой селекции культур на протяжении десятилетий, они по своей природе трудоемки, требуют много ручного труда и подвержены человеческим ошибкам. Эти ограничения делают их непригодными для крупномасштабных селекционных программ, где требуется оценка множества признаков в обширных популяциях. Дополнительно, растущее внедрение точного земледелия подчеркивает необходимость в высокопроизводительных и неразрушающих методах фенотипирования, которые повышают эффективность и устойчивость современных сельскохозяйственных систем [4].
Идентификация и подсчет листьев на ранней стадии играют ключевую роль в мониторинге здоровья сельскохозяйственных культур, понимании закономерностей роста и оценке зрелости сельскохозяйственных культур на ранней стадии [5]. Точная идентификация листьев предоставляет ценные данные для селекционеров, позволяя лучше понять динамику роста и способствуя отбору лучших сортов сельскохозяйственных культур. Более того, сегментация ключевая для оценки индекса листовой поверхности (LAI), ключевого показателя для понимания роста сельскохозяйственных культур и структуры полога [6]. Оценка LAI играет важнейшую роль в прогнозировании эффективности фотосинтеза, потенциала урожайности и распределения ресурсов у растений. Однако ручной подсчет непрактичен для крупномасштабных исследований в разнообразных полевых условиях, что требует автоматизированных решений, обеспечиваемых достижениями в области искусственного интеллекта (ИИ) и компьютерного зрения [7].
Классические подходы к подсчету листьев в основном полагались на ручные или полуавтоматические методы. Эти методы часто включают подсчет листьев в поле экспертами-людьми [4]. Методы обработки изображений, такие как обнаружение границ, пороговая обработка и сегментация на основе областей, также применялись к цифровым изображениям сельскохозяйственных культур [8]. Хотя эти методы показывают себя перспективными в контролируемых условиях, их эффективность снижается в реальных условиях, где изменчивость освещения, окклюзия и морфология растений представляют значительные проблемы. Далее, многие классические методы адаптированы для конкретных типов сельскохозяйственных культур, что ограничивает их применимость в нескольким видам [9].
Насколько нам известно, ни одна предыдущая работа всесторонне не решала задачу сегментации и подсчета листьев на ранней стадии в нескольких типах сельскохозяйственных культур — включая яровой ячмень, яровую пшеницу, озимую пшеницу, озимую рожь и озимую тритикале — в разнообразных полевых условиях, что выделяет пробел в литературе.
Недавние достижения в области ИИ, в частности в глубоком обучении и компьютерном зрении, преобразовали фенотипирование растений, обеспечив возможность автоматизированного анализа [10,11]. Современные модели, такие как сверточные нейронные сети (CNN) и фреймворки для обнаружения объектов, продемонстрировали замечательный успех в таких задачах, как сегментация листьев сельскохозяйственных культур, анализ признаков на ранней стадии и оценка биомассы [7,12,13]. Дополнительно, высокопроизводительные платформы для фенотипирования с использованием беспилотных летательных аппаратов (БПЛА) и роботизированных систем, оснащенных современными датчиками изображения, сделали сбор данных в крупных масштабах осуществимым [14].
Несмотря на эти достижения, существующие методы на основе ИИ часто сталкиваются со значительными ограничениями при применении к различным типам сельскохозяйственных культур и реальным полевым условиям. Такие проблемы, как меняющееся освещение, окклюзия из-за перекрывающихся структур растений и присущее разнообразие морфологий сельскохозяйственных культур, создают препятствия для надежного обнаружения и сегментации листьев на ранней стадии [7].
Настоящее исследование направлено на оценку того, необходимы ли отдельные модели для сегментации и идентификации листьев в различных типах сельскохозяйственных культур на ранней стадии роста, или же унифицированная модель, обученная на наборе данных, охватывающем несколько культур, может достичь превосходной производительности. Обоснование последнего подхода заключается в гипотезе, что общие морфологические признаки среди сельскохозяйственных культур могут позволить модели эффективно обобщать, тем самым повышая ее надежность и точность. Это исследование критически изучает адаптивность и способность к переносу моделей ИИ в сельскохозяйственных приложениях, с особым вниманием к мониторингу сельскохозяйственных культур на ранней стадии и анализу листьев, ставя целью продвижение автоматизированных методологий фенотипирования.
Оставшаяся часть статьи организована следующим образом: Раздел 2 обсуждает набор данных, использованный в данном исследовании, включая процессы сбора и аннотирования данных. Раздел 3 описывает методологию, использованную для сегментации и подсчета листьев. Раздел 4 описывает обучение и валидацию моделей. Раздел 5 представляет анализ и результаты. Раздел 6 предоставляет обсуждение результатов, и Раздел 7 завершает статью заключительными замечаниями и направлениями будущей работы.
2. Обзор набора данных
Набор данных, использованный в данном исследовании, был собран с пяти сельскохозяйственных полей в Университете Копенгагена. Он включал изображения пяти различных сельскохозяйственных культур: ярового ячменя, яровой пшеницы, озимой пшеницы, озимой ржи и озимой тритикале. Основной целью этого набора данных была поддержка задач сегментации листьев, при этом листья были вручную аннотированы зеленым цветом для наглядности, как показано на Рисунке 1. Примеры изображений из набора данных иллюстрировали разнообразие типов сельскохозяйственных культур и условий съемки. Ручные аннотации были сосредоточены на листьях, которые часто было трудно различить на исходных изображениях, что подчеркивает важность набора данных для задач сегментации. Эти аннотации предоставили необходимые эталонные данные для разработки и оценки моделей сегментации.

Рисунок 1. Примеры изображений из набора данных по яровым и озимым культурам, на которых аннотированные листья выделены зеленым цветом, что иначе было бы сложно различить на исходных изображениях. Изображения ярового ячменя и яровой пшеницы были получены с помощью сельскохозяйственного робота (общая высота приблизительно 2,15 м), в то время как изображения озимой пшеницы, озимой ржи и озимой тритикале были собраны с помощью дрона, летящего на высоте 8 м.
Набор данных был получен с использованием двух различных платформ: изображения ярового ячменя и яровой пшеницы были собраны с помощью сельскохозяйственного робота, который имел общую высоту приблизительно 2,15 м, дорожный просвет 80 см и разрешение изображения 2448 × 2048. Изображения озимой пшеницы, озимой ржи и озимой тритикале были получены с помощью дрона, летящего на высоте 8 м с разрешением изображения 5280 × 395. Источники изображений и высоты подробно описаны на Рисунке 1.
Набор данных состоял из 907 обучающих и 112 тестовых изображений для всех типов сельскохозяйственных культур, с заметным дисбалансом в распределении. В частности, яровой ячмень имел 419 обучающих и 43 тестовых изображения, в то время как яровая пшеница имела 410 обучающих и 38 тестовых изображений. Озимые культуры — озимая пшеница, озимая рожь и озимая тритикале — были распределены равномерно, каждая имея по 25 обучающих и 3 тестовых изображения, как показано на Рисунке 2.
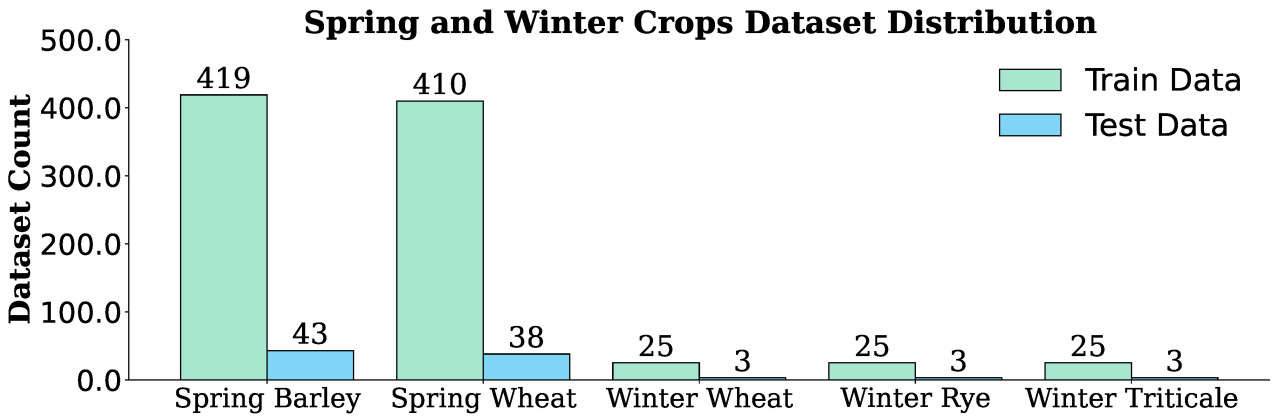
Рисунок 2. Распределение набора данных по яровым и озимым культурам, иллюстрирующее количество изображений в обучающем и тестовом наборах данных для каждого типа культуры.
Дополнительно к распределению изображений, количество аннотированных листьев в наборе данных было ключевым аспектом. Рисунок 3 показывает количество листьев для каждого типа сельскохозяйственной культуры в обучающем и тестовом наборах данных. Обучающий набор ярового ячменя содержал 4987 листьев, с 646 в тестовом наборе. Аналогично, яровая пшеница имела 6990 листьев в обучающем наборе и 832 в тестовом. Озимые культуры имели значительно меньше листьев: озимая пшеница — 2721 лист в обучении и 506 в тестировании, озимая рожь — 3309 в обучении и 229 в тестировании, а озимая тритикале содержала 2730 в обучении и 564 в тестировании. Эти подсчеты продемонстрировали, что обучающие наборы данных были значительно более полными, чем тестовые наборы данных, что обеспечивало надежную разработку модели, одновременно предоставляя достаточные данные для оценки.
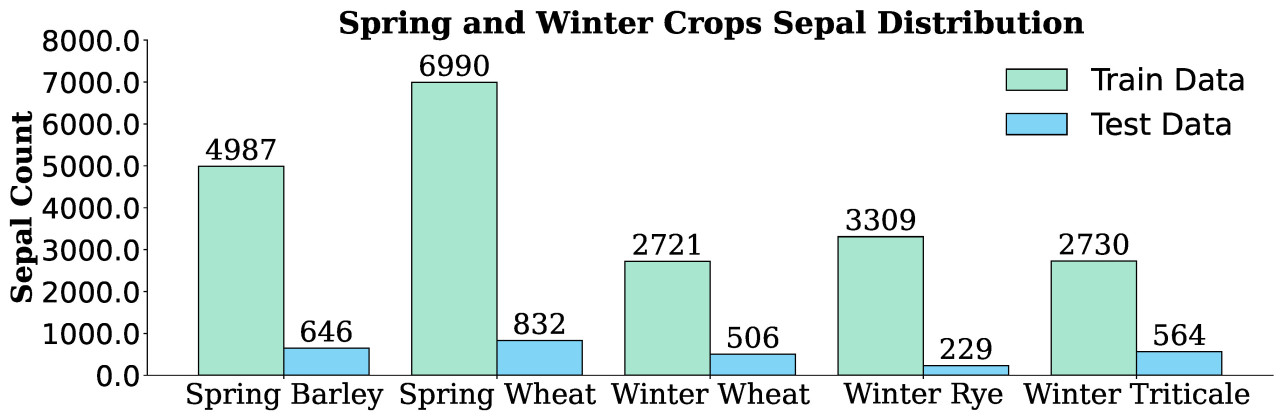
Рисунок 3. Распределение листьев яровых и озимых культур, показывающее количество вручную аннотированных листьев в обучающем и тестовом наборах данных для каждого типа культуры.
Для анализа различий между изображениями, снятыми роботом и дроном, был выполнен анализ главных компонент (PCA) с использованием признаков, извлеченных из предварительно обученной модели ResNet50. Изображения пропускались через модель, и полученные признаки использовались для выполнения PCA с двумя компонентами. Результаты PCA, показанные на Рисунке 4, продемонстрировали отчетливую кластеризацию на основе источника получения изображения.
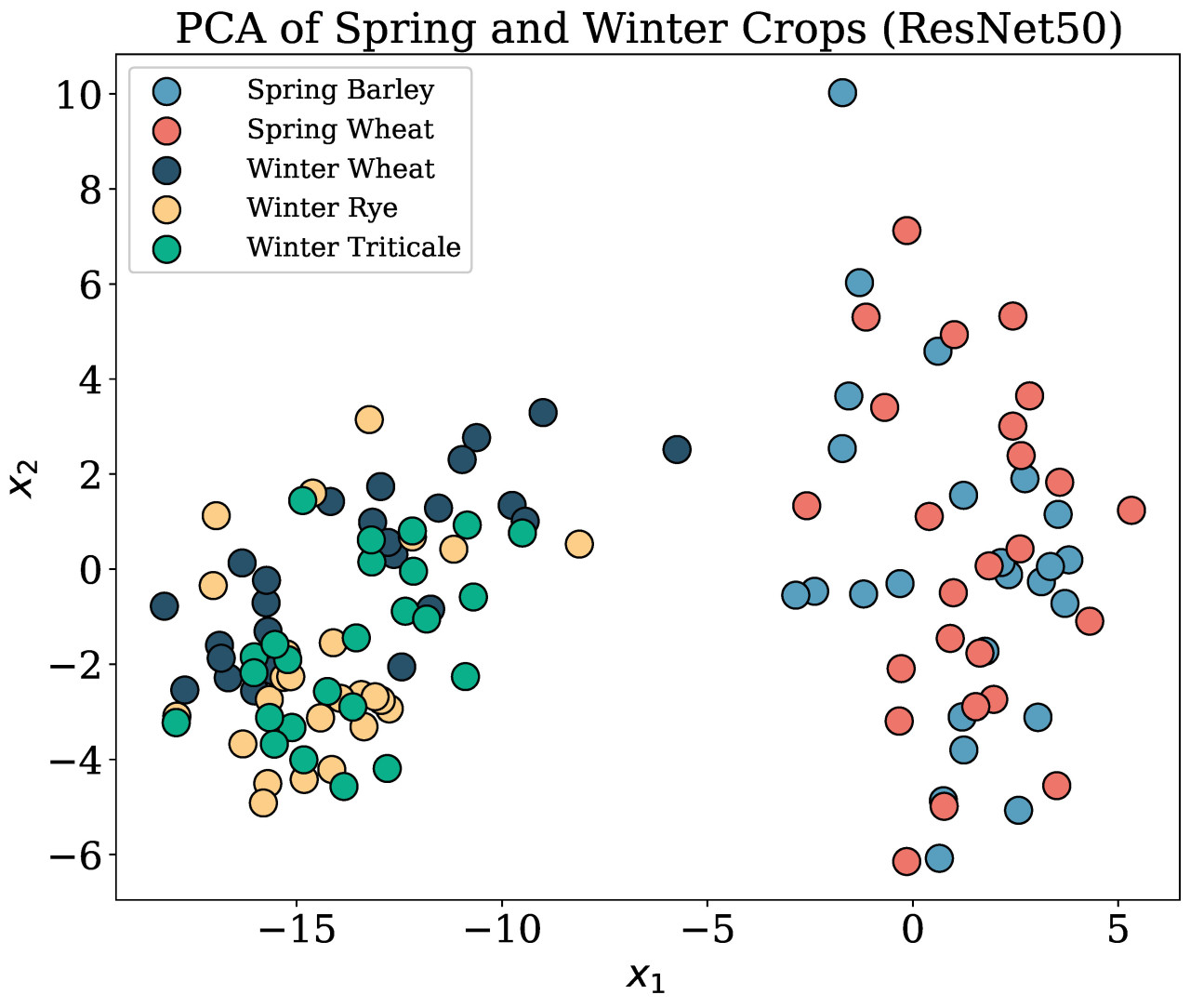
Рисунок 4. PCA яровых и озимых культур, визуализированный с использованием признаков из предварительно обученной модели ResNet50. Кластеризация отражала различия, основанные на высоте: изображения с робота фиксировали большие размеры листьев из-за близости к земле и контролируемых условий, в то время как изображения с дрона показывали меньшие размеры листьев, на которые влияли естественные, неконтролируемые факторы окружающей среды.
Эта кластеризация отражает вариации в размере листьев и условиях съемки. Изображения, полученные роботом, снятые ближе к земле в контролируемых условиях, демонстрировали более крупные и детализированные представления листьев. Эти изображения избегали помех окружающей среды, таких как ветер или непостоянное освещение. Напротив, изображения, полученные с дрона, снятые с больших высот в естественных полевых условиях, подвергались влиянию факторов окружающей среды, что приводило к более мелким и менее однородным представлениям листьев.
В целом, набор данных по яровым и озимым культурам был ценным ресурсом для задач сегментации, в частности для идентификации листьев в различных типах сельскохозяйственных культур. Разнообразие условий съемки в наборе данных — охватывающее изображения, полученные роботом и дроном — добавляло ему надежности. Хотя дисбаланс между образцами яровых и озимых культур был очевиден, тщательно аннотированные листья и комплексные обучающие наборы данных предоставили прочную основу для разработки высокопроизводительных моделей сегментации. Этот набор данных хорошо подходит для приложений в точном земледелии, позволяя исследователям создавать решения для автоматизированного анализа и мониторинга сельскохозяйственных культур.
3. Архитектура YOLOv11
Архитектура YOLOv11 вводит несколько ключевых усовершенствований для повышения эффективности и точности обнаружения, как проиллюстрировано на Рисунке 5. Конструкция состоит из трех основных компонентов: Backbone (Основная сеть), Neck (Шея) и Head (Голова), каждый из которых включает инновационные механизмы для оптимизации производительности.
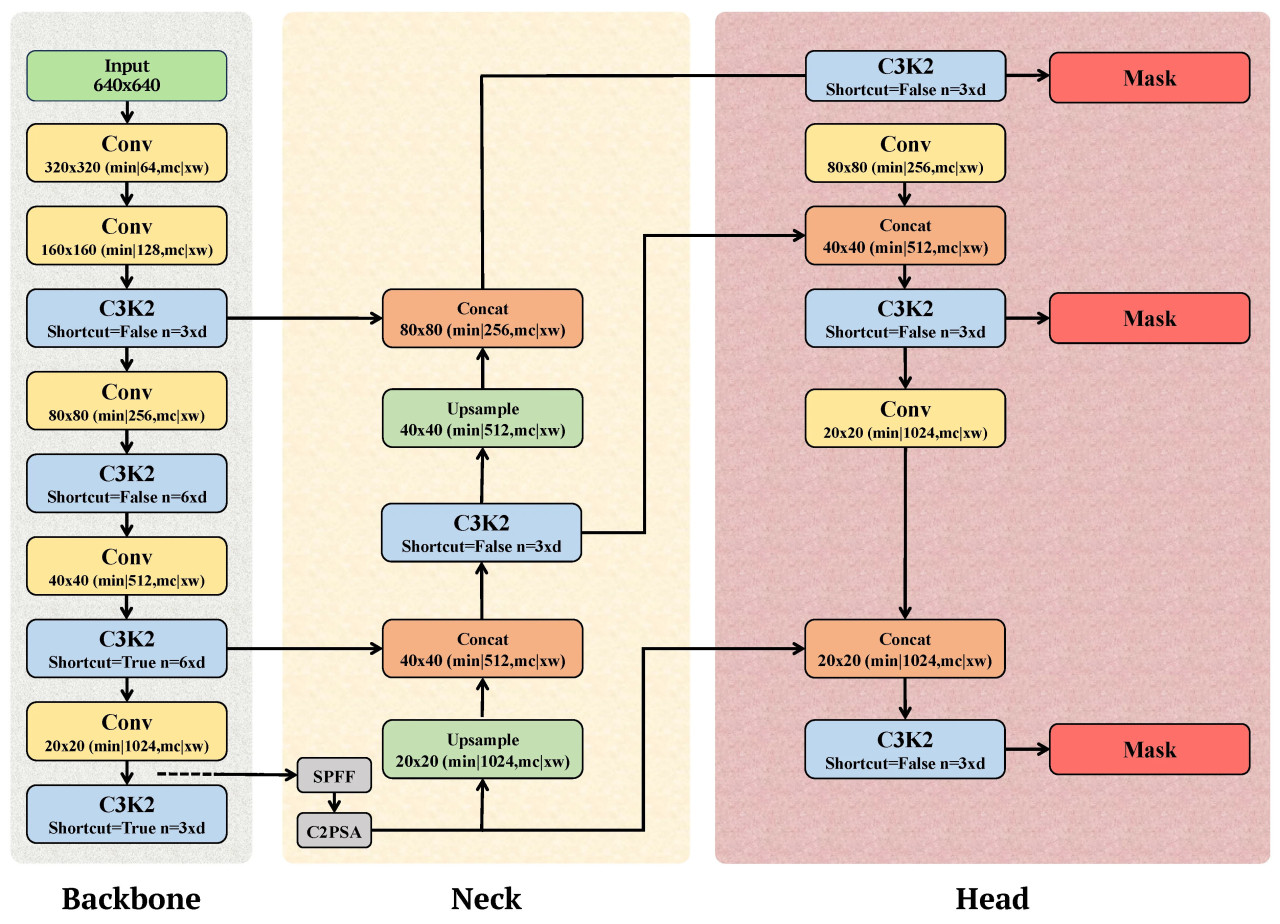
Рисунок 5. Схематическая диаграмма YOLOv11, иллюстрирующая ее три основных компонента: Backbone, Neck и Head. Backbone обрабатывает извлечение признаков в нескольких масштабах с использованием передовых блоков, таких как C3k2 и Быстрый Пространственный Пирамидальный Пулинг (SPPF), разработанных для эффективного представления признаков. Neck агрегирует и уточняет эти признаки с дополнительными механизмами, такими как Кросс-Стадийный Частичный со Пространственным Вниманием (C2PSA). Наконец, Head предсказывает ограничивающие рамки объектов, маски и классификации с использованием усовершенствованной многомасштабной обработки.
3.1. Backbone (Основная сеть)
Backbone является основой для извлечения многомасштабных признаков, используя достижения для обеспечения вычислительной эффективности:
• Блок C3k2: Этот блок Кросс-Стадийного Частичного (CSP) узкого места использует размер ядра два, заменяя более старые, более вычислительно сложные блоки. Конструкция снижает общую сложность модели, сохраняя ее способность захватывать ключевые признаки.
• SPPF (Быстрый Пространственный Пирамидальный Пулинг): Адаптированный из YOLOv8, этот блок объединяет признаки через несколько рецептивных полей, улучшая представление объектов в различных масштабах.
• C2PSA (Кросс-Стадийный Частичный со Пространственным Вниманием): Это новое дополнение интегрирует пространственное внимание, позволяя модели сосредотачиваться на ключевых областях внутри входного изображения. Это в частности эффективно для обнаружения мелких или загороженных объектов, что является общей проблемой в сельскохозяйственных наборах данных.
3.2. Neck (Шея)
Neck служит мостом, уточняя признаки, извлеченные Backbone, и подготавливая их для предсказания. Усовершенствования включают следующее:
• Блок C3k2: Эти блоки продолжают эффективно обрабатывать признаки, сохраняя высокую пропускную способность при снижении вычислительных затрат.
• Механизм C2PSA: Уточняя карты признаков через пространственное внимание, Neck улучшает способность модели различать релевантные и нерелевантные признаки.
3.3. Head (Голова)
Head выводит окончательные предсказания, включая ограничивающие рамки объектов, маски и вероятности классов:
• Блоки C3k2: Эти блоки улучшают обработку многомасштабных признаков, обеспечивая детектирование мелких деталей в различных размерах объектов.
• CBS (Свертка-Пакетная Нормализация-SiLU): Это сочетание улучшает нормализацию признаков и стабильность обучения, повышая общую производительность сети.
• Финальный слой детекции: Выводит маски, координаты ограничивающих рамок, оценки объектности и вероятности классов с акцентом на эффективность и точность, ключевые для приложений реального времени.
3.4. Применение в сельском хозяйстве
Архитектурные усовершенствования в YOLOv11, как изображено на Рисунке 5, делают ее в частности хорошо подходящей для сельскохозяйственных приложений. Ее способность обнаруживать мелкие или загороженные объекты является преимуществом в таких задачах, как:
• Мониторинг сельскохозяйственных культур [15]: Идентификация и подсчет специфических для культуры признаков, таких как листья, цветы или плоды, для оценки урожайности.
• Обнаружение сорняков [16]: Различение культур и сорняков для целевого применения гербицидов.
• Идентификация вредителей и болезней [17]: Обнаружение ранних признаков вредителей или болезней для смягчения потенциальных потерь урожая.
• Автоматизированный сбор урожая [18]: Распознавание созревших культур или плодов для эффективного сбора.
Модульная конструкция YOLOv11 обеспечивает гибкость, позволяя адаптироваться к различным вариантам использования в сельском хозяйстве. Интеграция механизмов пространственного внимания и многомасштабной обработки признаков улучшает ее точность в разнообразных полевых условиях, от густо посаженных культур до неоднородных ландшафтов.
4. Настройки обучения и валидации
4.1. Процедура обучения
Архитектура YOLOv11 была использована для выполнения обнаружения и подсчета листьев в пяти типах сельскохозяйственных культур: яровой ячмень, яровая пшеница, озимая пшеница, озимая рожь и озимая тритикале. Набор данных был вручную аннотирован, с листьями, очерченными для предоставления эталонных данных. Изображения были разделены на обучающие и тестовые подмножества, обеспечивая репрезентативные распределения для всех типов культур.
Для оценки влияния стратегий обучения для каждой культуры были обучены две модели. В первом подходе наборы данных от всех пяти культур были объединены для обучения единой модели для конкретной культуры, используя объединенные данные для улучшения обобщения. Во втором подходе для обучения использовался только набор данных конкретной оцениваемой культуры, фокусируя модель на специфических для культуры признаках. Эта двойная стратегия позволила провести сравнительный анализ производительности между обобщенным и специфическим для культуры обучением, предоставляя понимание преимуществ и ограничений обоих подходов в реальных условиях.
4.1.1. Аугментация данных
Для улучшения обобщения модели применялись несколько методов аугментации данных. Они включали случайные повороты, горизонтальные и вертикальные отражения, случайное кадрирование и настройки яркости и контрастности. Дополнительно, передовые аугментации, такие как размытие по Гауссу, медианное размытие, преобразования в оттенки серого и CLAHE, использовались для имитации различных реальных условий съемки.
4.1.2. Конфигурация обучения
Модель обучалась с использованием оптимизатора Adam с начальной скоростью обучения 0.0001, управляемой через косинусный график затухания. Размер пакета восемь использовался для оптимизации вычислительной эффективности с учетом аппаратных ограничений. Ранняя остановка применялась со значением терпения 10 эпох, обеспечивая предотвращение переобучения. Гиперпараметры обучения, такие как момент, затухание веса и стратегии разогрева, были точно настроены для оптимальной производительности, как описано в Таблице 1.
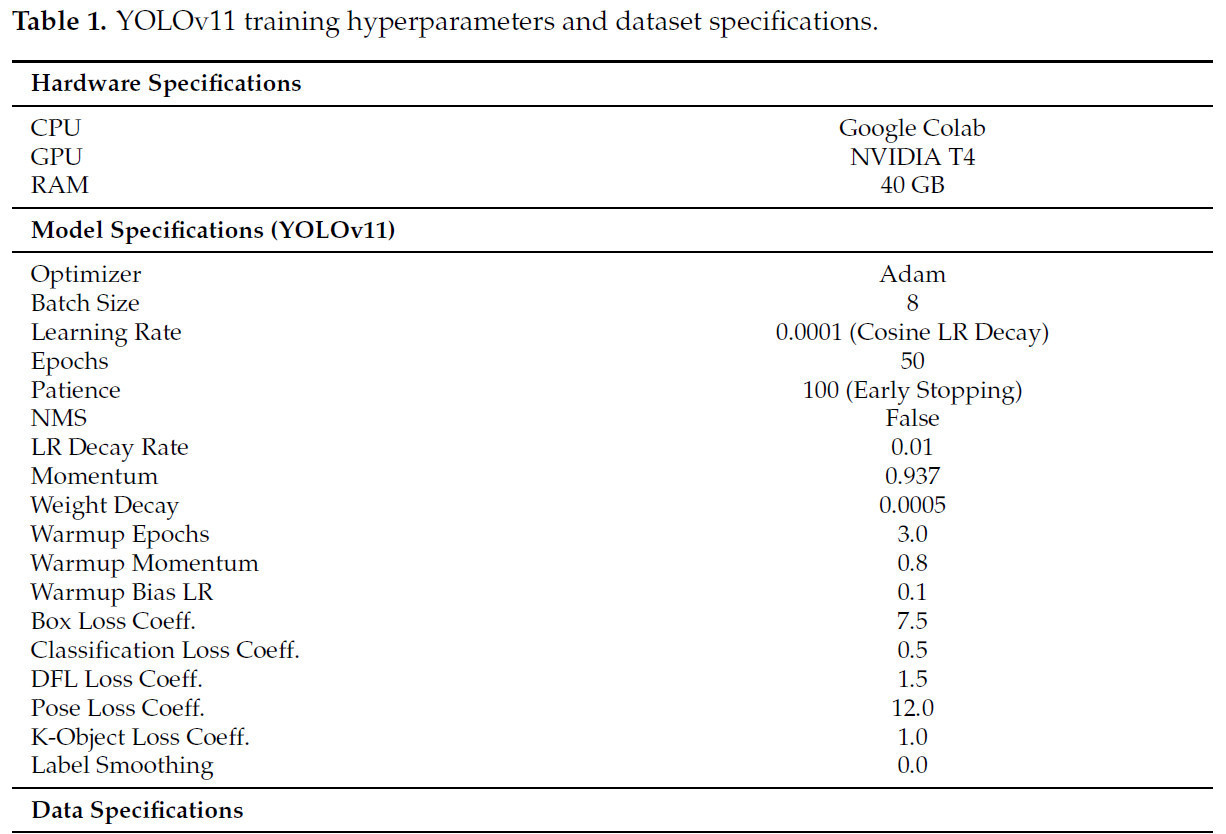

Таблица 1. Гиперпараметры обучения YOLOv11 и спецификации набора данных.
4.1.3. Функции потерь
Использовались следующие функции потерь. Для задач ограничивающих рамок, Фокальная Потеря Распределения (DFL) использовалась для повышения чувствительности к сложным примерам путем акцента на более трудные для классификации ограничивающие рамки, в то время как Полная Потеря Пересечения по Объединению (CIoU) предоставляла комплексную метрику для выравнивания ограничивающих рамок, учитывая перекрытие, расстояние между центрами и соотношение сторон. Для задач сегментации, Бинарная Перекрестная Энтропия (BCE) обеспечивала эффективную поточечную классификацию, и Потеря IoU использовалась для максимизации перекрытия между предсказанными и эталонными масками, что ключевое для точной сегментации.
4.1.4. Аппаратные характеристики
Эксперименты по обучению проводились в среде Google Colab, оснащенной графическим процессором NVIDIA T4 и 40 ГБ оперативной памяти. Эта установка позволяла эффективно обрабатывать изображения высокого разрешения 640 × 640 пикселей и ускорять циклы обучения.
4.2. Валидация и оценка
Производительность моделей YOLOv11 оценивалась на валидационном наборе каждого типа культуры. Метрики оценки в основном фокусировались на следующем:
• Точность обнаружения: Способность правильно идентифицировать и локализовать листья внутри изображений.
• Метрики потерь: Тренды потерь при обучении и валидации отслеживались на протяжении всего процесса обучения для оценки сходимости модели и обобщения.
5. Анализ и результаты
Производительность моделей на основе YOLOv11 оценивалась с использованием валидационных наборов данных для каждого типа культуры, с фокусом на метриках ограничивающих рамок (BBox) и сегментации. Эти оценки оценивали способность моделей точно обнаруживать и подсчитывать листья в яровом ячмене, яровой пшенице, озимой пшенице, озимой ржи и озимой тритикале. Результаты обобщены ниже, с подробным анализом и визуализациями, предоставленными на Рисунке 6, Рисунке 7, Рисунке 8 и Рисунке 9 и в Таблице 2.
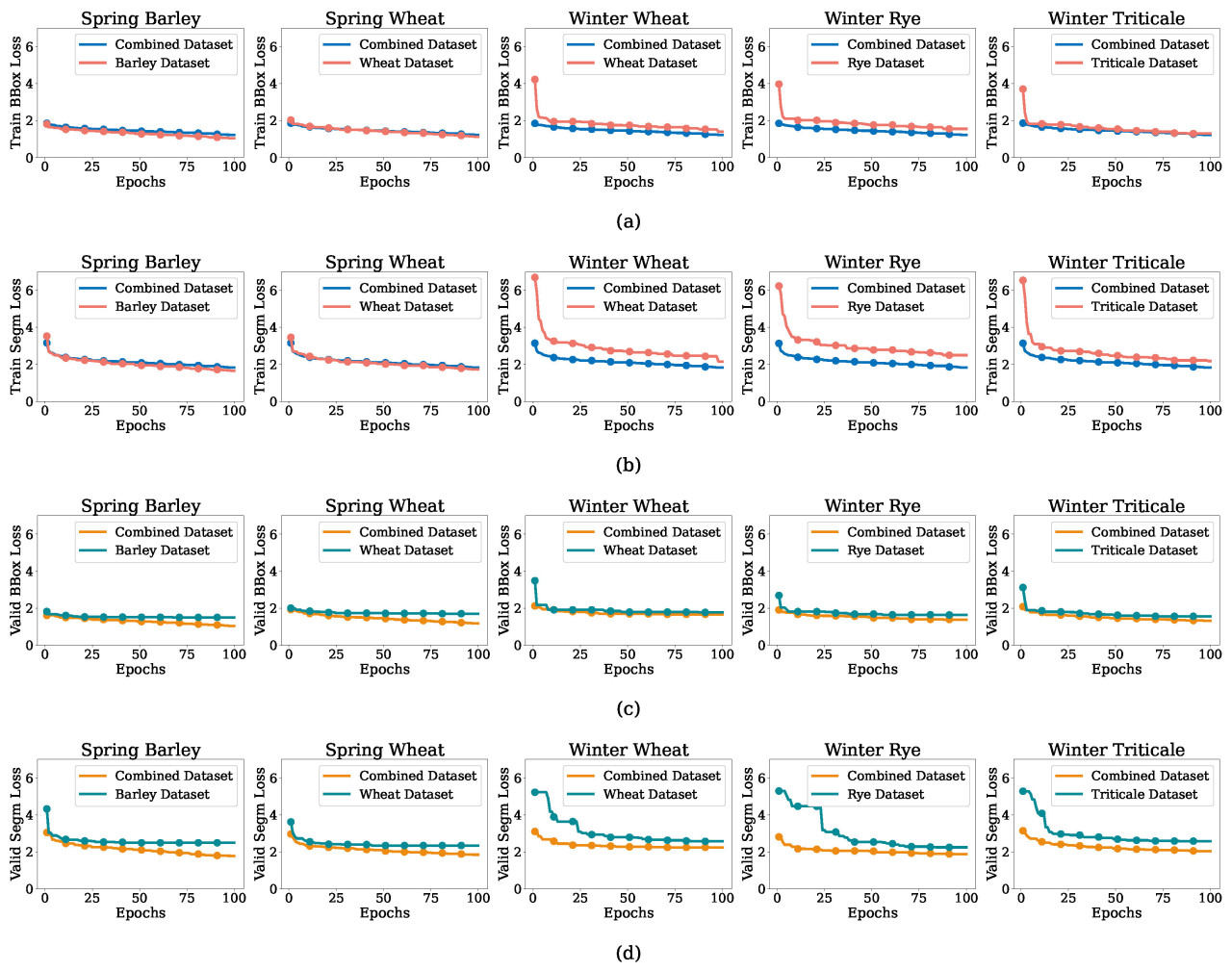
Рисунок 6. (a–d) Потери при обучении и валидации для ярового ячменя, яровой пшеницы, озимой пшеницы, озимой ржи и озимой тритикале в объединенных и отдельных наборах данных, показывающие потери для рамок и сегментации.
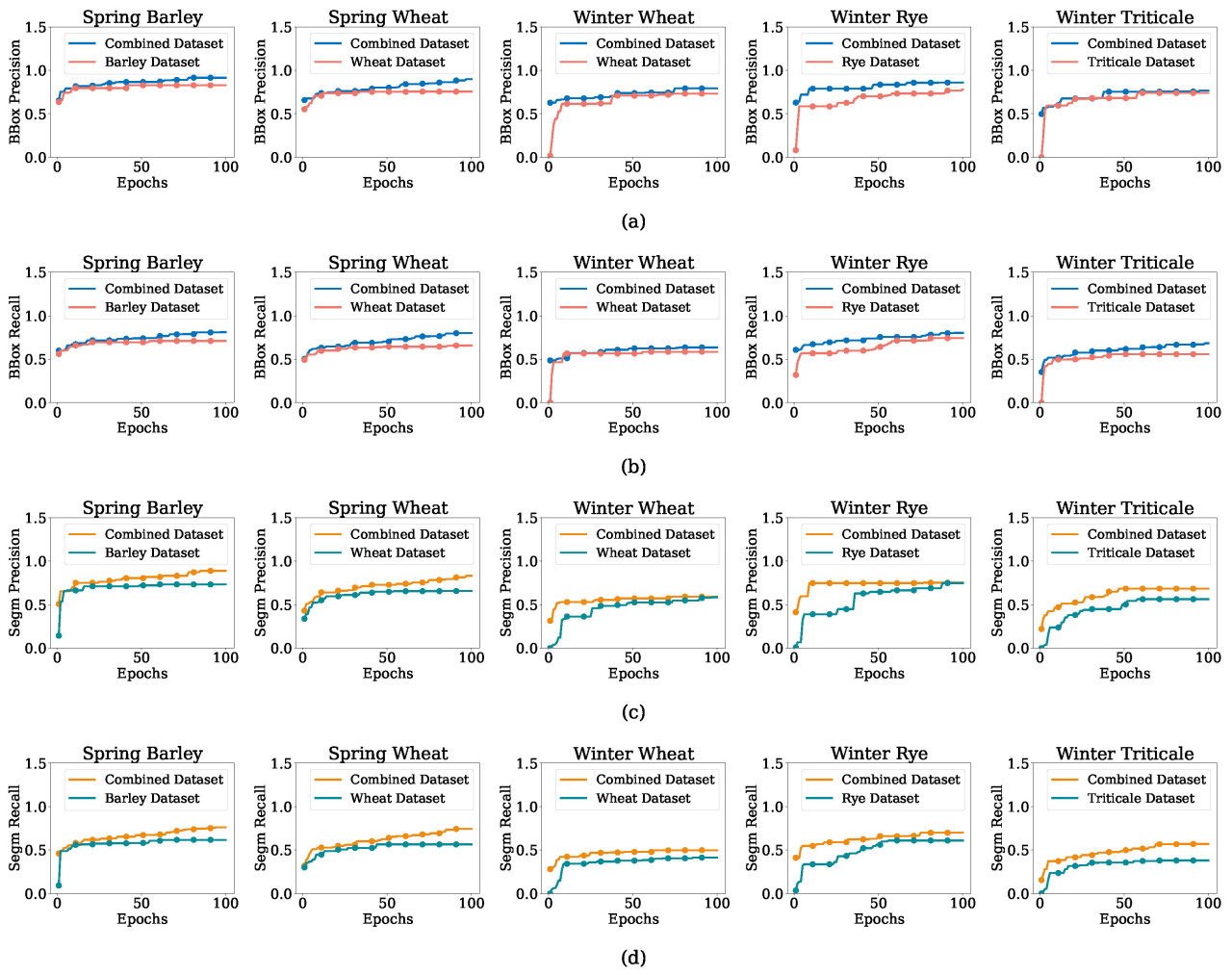
Рисунок 7. (a–d) Точность и полнота для ярового ячменя, яровой пшеницы, озимой пшеницы, озимой ржи и озимой тритикале в объединенных и отдельных наборах данных, показывающие точность и полноту для рамок и сегментации.
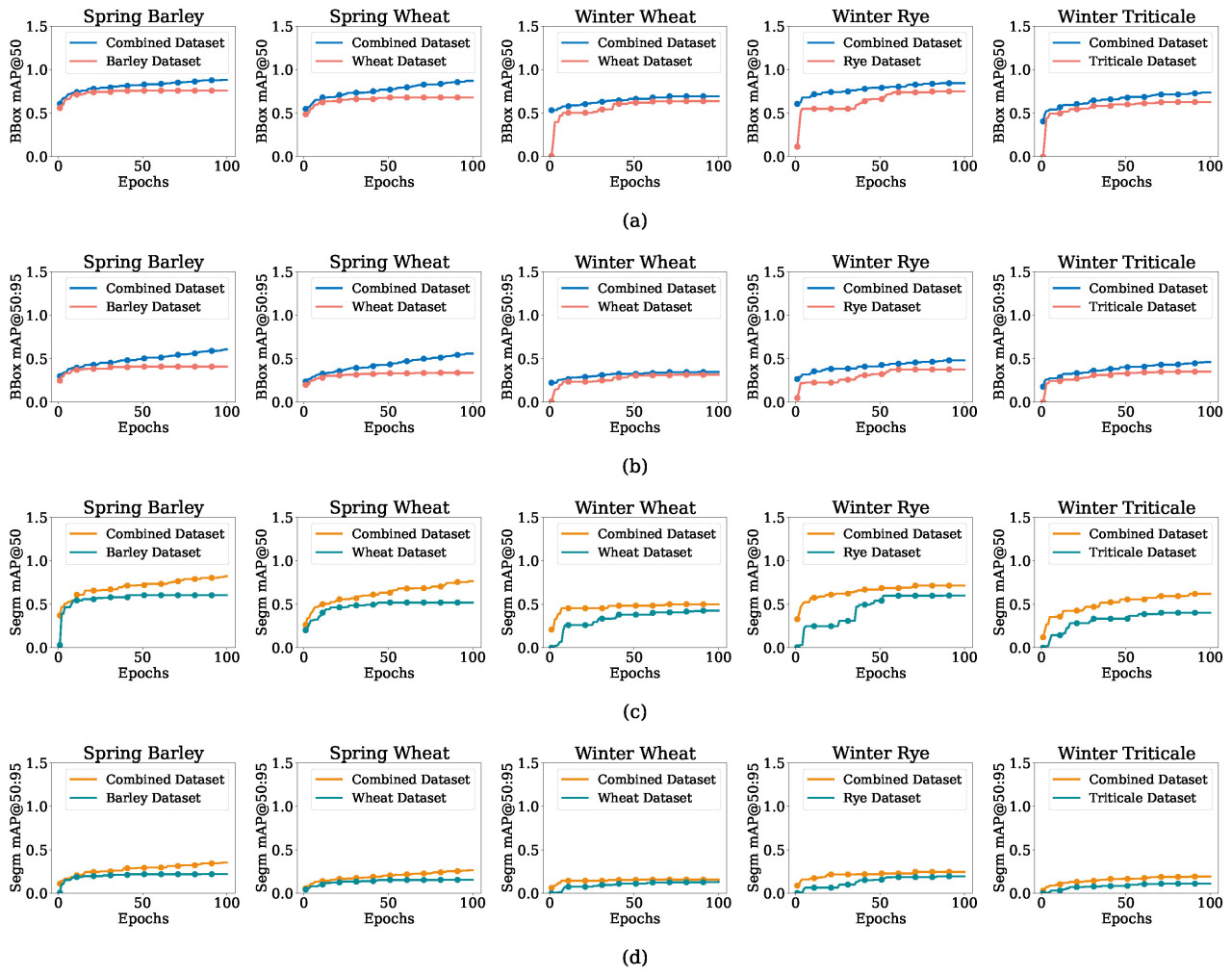
Рисунок 8. (a–d) Средняя Средняя Точность (mAP) для ярового ячменя, яровой пшеницы, озимой пшеницы, озимой ржи и озимой тритикале в объединенных и отдельных наборах данных, показывающая @mAP50 и @mAP50:95 для рамок и сегментации.

Рисунок 9. (a–e) Результаты предсказания для ярового ячменя, яровой пшеницы (изображения с робота), а также озимой пшеницы, ржи и тритикале (изображения с дрона 8 м), с обнаруженными культурами, выделенными цветными аннотациями.
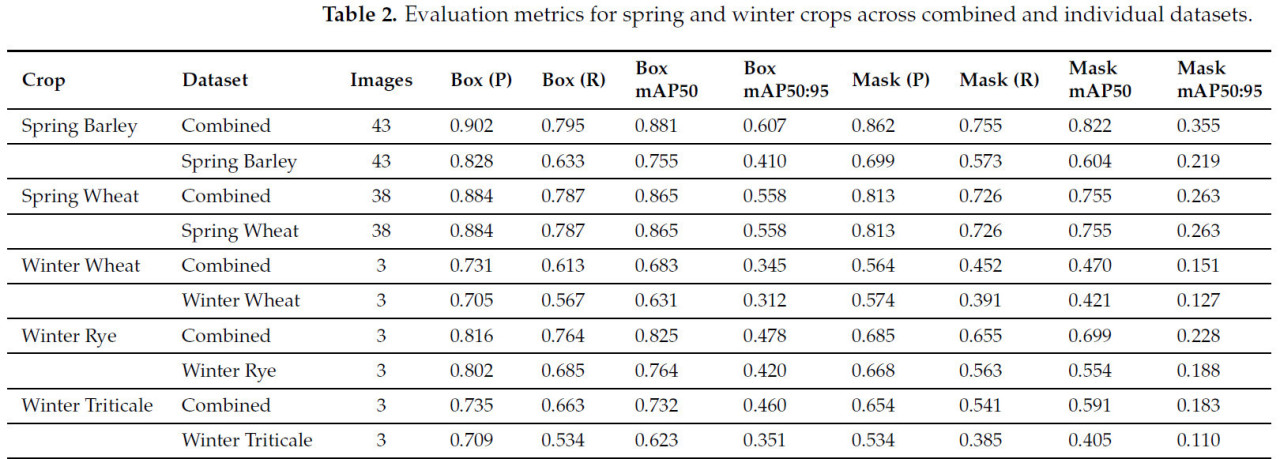
Таблица 2. Метрики оценки для яровых и озимых культур в объединенных и отдельных наборах данных.
5.1. Анализ потерь и сходимости
Рисунок 6 иллюстрирует кривые потерь при обучении и валидации для задач BBox и сегментации во всех типах культур. Модели, обученные на объединенном наборе данных, стабильно демонстрировали более низкие значения потерь во время обучения и валидации, в частности для яровых культур. Это отражает способность объединенного набора данных предоставлять более разнообразные и репрезентативные признаки, способствуя лучшему обобщению. В отличие от этого, модели, обученные на отдельных наборах данных, имели более высокие значения потерь, особенно для озимых культур, подчеркивая проблемы, вызванные ограниченными данными и повышенной изменчивостью.
5.2. Анализ точности и полноты
Рисунок 7 представляет кривые точности и полноты для задач BBox и сегментации. Модели, обученные на объединенном наборе данных, стабильно достигали более высоких значений точности и полноты как для яровых, так и для озимых культур, с более заметным преимуществом для задач ограничивающих рамок. Например, яровой ячмень и яровая пшеница достигли более 0,9 точности и полноты для задач BBox при использовании объединенного набора данных. Однако для задач сегментации разница между объединенными и отдельными наборами данных была меньше, в частности для озимых культур, где отдельные наборы данных иногда превосходили объединенный набор данных по полноте. Это указывает на то, что хотя объединенный набор данных улучшает обобщение, специфические нюансы отдельных культур могут все еще требовать специализированного обучения.
5.3. Анализ Средней Средней Точности (mAP)
Метрики mAP для задач BBox и сегментации, как показано на Рисунке 8, дополнительно выделяют превосходящую производительность объединенного набора данных. Для яровых культур значения mAP@50 как для BBox, так и для сегментации превышали 0,85, причем метрики сегментации немного отставали от метрик BBox. Для озимых культур объединенный набор данных все еще превосходил отдельные наборы данных в BBox mAP, достигая значений выше 0,7, в то время как mAP сегментации оставался ниже из-за присущих проблем меньшего количества образцов и более сложных условий съемки. Более высокие значения mAP объединенного набора данных указывают на его способность использовать сходства между культурами для надежного обнаружения.
5.4. Обзор метрик производительности
Количественные метрики, обобщенные в Таблице 2, подчеркивают преимущество объединенного набора данных в большинстве задач. Например, яровой ячмень достиг BBox mAP@50 0,881 и mAP@50 сегментации 0,822 при использовании объединенного набора данных, по сравнению с 0,755 и 0,604 соответственно для отдельного набора данных. Аналогично, для озимых культур, таких как озимая тритикале, объединенный набор данных достиг mAP@50 сегментации 0,591, превзойдя 0,405 отдельного набора данных. Эти результаты подчеркивают, что больший и более разнообразный набор данных значительно улучшил производительность модели, в частности для задач ограничивающих рамок, в то время как задачи сегментации оставались более чувствительными к изменчивости набора данных.
5.5. Инсайты обнаружения из визуальных выходов
Рисунок 9 иллюстрирует визуальные результаты для всех типов культур. Модели, обученные на объединенном наборе данных, предоставляли более плотные и точные обнаружения, в частности для яровых культур, с минимальными ложными срабатываниями или пропущенными обнаружениями. Для озимых культур, хотя обнаружения в целом были менее плотными, объединенный набор данных все еще производил более надежные выходные данные в сложных областях с окклюзией или сложным фоном. Визуальные выходные данные согласуются с количественными метриками, выделяя эффективность использования разнообразных наборов данных для надежной производительности.
5.6. Обсуждение объединенного и индивидуального обучения
В целом, объединенный набор данных продемонстрировал превосходящую производительность в большинстве метрик, в частности для задач ограничивающих рамок, благодаря большему и более разнообразному обучающему пулу. Эта способность к обобщению ключевая для практических приложений, где аннотации, специфичные для культуры, могут быть ограничены. Однако для задач сегментации отдельные наборы данных иногда предоставляли лучшую полноту, указывая, что специфические для культуры признаки могут все еще выигрывать от целевого обучения. Этот компромисс выделяет важность балансирования разнообразия набора данных с точной настройкой под конкретную культуру для оптимизации производительности во всех задачах фенотипирования.
6. Обсуждение
Применение YOLOv11 для обнаружения и подсчета листьев в различных типах сельскохозяйственных культур выделяет преобразующий потенциал передовых методов глубокого обучения в автоматизированном фенотипировании растений. Используя архитектурные инновации и возможности обработки в реальном времени, YOLOv11 показала себя перспективной в решении проблем крупномасштабных сельскохозяйственных оценок, где ручные методы являются как трудоемкими, так и подверженными ошибкам. Способность модели обнаруживать и количественно оценивать листья в меняющихся условиях окружающей среды и съемки подчеркивает ее универсальность и практическую пользу.
Ключевое преимущество YOLOv11 заключается в ее архитектурных усовершенствованиях, таких как введение блока C3k2 и модуля C2PSA. Эти компоненты значительно улучшили извлечение признаков и пространственное внимание, позволяя модели эффективно обрабатывать сложные морфологии листьев и различные фоновые условия. Интеграция таких механизмов выделила YOLOv11 среди ее предшественников, позволив ей адаптироваться к различным сценариям съемки, включая высокое разрешение изображений с робота и данные, полученные с дрона на больших высотах. Дополнительно, возможности вывода в реальном времени YOLOv11 делают ее хорошо подходящей для полевого развертывания в точном земледелии, где быстрое принятие решений часто ключевое.
Однако определенные проблемы остаются, что выделяет необходимость дальнейшего совершенствования. Окклюзия, вызванная перекрывающимися структурами растений, продолжает препятствовать производительности обнаружения, в частности в густонаселенных или сильно вегетативных областях. Неспособность последовательно разделять перекрывающиеся листья ограничивает способность модели достигать идеальной точности в таких сценариях. Аналогично, экстремальные вариации освещения, от передержки при ярком солнечном свете до недодержки в затененных областях, могут вносить несоответствия в обнаружение. Эти факторы, присущие реальным сельскохозяйственным средам, представляют области, где надежность модели может быть улучшена.
PCA анализ, представленный на Рисунке 4, подчеркивает отчетливые различия между изображениями, полученными роботом и дроном, которые обусловлены факторами окружающей среды и условиями съемки. Изображения, полученные роботом, снятые ближе к земле, предоставляют более крупные и детализированные представления листьев в контролируемых условиях. Напротив, изображения, полученные с дрона, снятые с больших высот, отражают более мелкие и менее однородные признаки листьев, на которые влияют естественные полевые условия, такие как ветер и изменчивость освещения. Несмотря на эти различия, подход с объединенным набором данных, принятый в данном исследовании, позволил модели эффективно обобщать через меняющиеся условия окружающей среды. Это подтверждается стабильно высокими показателями mAP как для яровых культур (полученных роботом), так и для озимых культур (полученных дроном). Однако задачи сегментации для озимых культур, которые включают большую изменчивость окружающей среды, иногда показывали ограничения, подчеркивая необходимость дальнейшего расширения набора данных и точной настройки под конкретную область. Будущая работа будет сосредоточена на улучшении разнообразия набора данных и стратегий обучения для обеспечения надежного обобщения через неоднородные условия съемки.
Изменчивость условий съемки в различных типах культур далее подчеркивает важность качества и разнообразия набора данных. Хотя YOLOv11 хорошо работает с большими, разнообразными наборами данных, такими как данные для яровых культур, меньшие наборы данных для озимых культур представляют значительную проблему. Ограниченная доступность данных снижает способность модели эффективно обобщать, в частности при столкновении со сложной текстурой почвы, разреженным распределением листьев или изображениями с дрона, полученными на различных высотах. Стратегии, такие как применение передовых методов аугментации данных, включая повороты, настройки яркости и генерацию синтетических данных с использованием Генеративных Состязательных Сетей (GAN) [19], могут помочь смягчить влияние дисбаланса набора данных. GAN могут создавать реалистичные синтетические изображения для недостаточно представленных озимых культур, обеспечивая более сбалансированное обучение. Дополнительно, диффузионные модели [20], известные своей способностью генерировать высокое качество и разнообразные синтетические данные, могут служить эффективной альтернативой GAN, лучше захватывая изменчивость и сложность реальных сельскохозяйственных наборов данных. Далее, интеграция Больших Языковых Моделей (LLM) [21] может упростить процесс аннотации, генерируя описательные метаданные и помогая в полуавтоматических конвейерах, делая подготовку данных более эффективной и масштабируемой.
Одним из наиболее ценных применений точной сегментации листьев является оценка индекса листовой поверхности (LAI), ключевого параметра для оценки структуры и здоровья растительного полога [6]. Оценка LAI в значительной степени зависит от точного обнаружения и сегментации листьев, в частности в условиях плотного полога, где перекрывающиеся листья и окклюзия представляют проблемы. Предоставляя выходные данные сегментации высокого разрешения, YOLOv11 может облегчить получение метрик LAI, которые являются инструментальными для понимания эффективности фотосинтеза, использования воды и перехвата света в сельскохозяйственных культурах. Это делает ее незаменимым инструментом в оптимизации управления сельскохозяйственными культурами и моделировании распределения ресурсов в реальных сельскохозяйственных условиях.
Одним значительным открытием данного исследования является то, что объединенный набор данных в целом приводил к улучшенной производительности, в частности для задач ограничивающих рамок, в основном благодаря его большему размеру и разнообразию. Однако это улучшение не было универсальным. Для задач сегментации отдельные модели иногда превосходили унифицированную модель для определенных культур, таких как озимая пшеница и озимая тритикале. Это предполагает, что хотя больший набор данных помогает обобщению, специфические нюансы и проблемы, связанные с определенными культурами, такие как уникальные морфологии листьев или условия окружающей среды, могут требовать специализированного обучения. Например, озимые культуры часто сталкиваются с большей окклюзией и изменчивостью в естественных полевых условиях, что может ограничивать преимущества обобщенной модели [22]. Полуавтоматические конвейеры аннотации с использованием предварительно обученных моделей YOLOv11 для псевдоразметки с последующей человеческой проверкой также могут ускорить создание набора данных для недостаточно представленных культур, сохраняя качество аннотации.
Одной из наиболее ключевых областей для будущих исследований является расширение аннотированных наборов данных для улучшения производительности и возможностей обобщения модели [23]. Увеличение объема и разнообразия аннотированных данных ключевое, в частности для культур с меньшими наборами данных, таких как озимая пшеница, озимая рожь и озимая тритикале. Большие наборы данных позволят модели лучше захватывать присущую изменчивость в морфологии листьев, стадиях роста и условиях окружающей среды, приводя к более надежному обнаружению во всех типах культур. Далее, увеличение разнообразия аннотированных данных путем включения образцов из нескольких географических регионов и сельскохозяйственных практик улучшит адаптивность модели. Захватывая изменчивость во внешнем виде сельскохозяйственных культур в различных климатах, типах почв и методах возделывания, расширенный набор данных предоставит модели более полное понимание характеристик листьев. Процесс аннотации должен быть сосредоточен на включении образцов из разнообразных полевых условий, включая вариации в освещении, текстурах почвы и плотности растений. Расширение диапазона аннотированных изображений для включения большего количества загороженных и перекрывающихся листьев позволит модели обучаться на сложных сценариях, тем самым улучшая ее способность справляться с реальными сложностями. Дополнительно, интеграция аннотированных изображений из различных модальностей датчиков, таких как мультиспектральные или гиперспектральные камеры, может предоставить более богатую информацию как для задач обнаружения, так и для сегментации.
Для эффективной генерации крупномасштабных аннотированных наборов данных следует исследовать полуавтоматические или автоматические конвейеры аннотации [24]. Использование предварительно обученных моделей для помощи в начальных аннотациях и уточнение их с использованием человеческой проверки может значительно сократить время и усилия, необходимые для подготовки данных. Этот подход был бы в частности полезен для культур с ограниченными наборами данных, позволяя исследователям масштабировать аннотации без чрезмерных ручных усилий [25].
Влияние размера и разнообразия набора данных невозможно переоценить, так как оно напрямую влияет на способность модели обобщать в различных типах культур и условиях окружающей среды. Однако результаты также указывают, что эффективность объединенного набора данных зависит от конкретной культуры и задачи, выделяя необходимость сбалансированного подхода, который объединяет преимущества разнообразных данных с точной настройкой под конкретную культуру. По мере роста аннотированного набора данных модели YOLOv11 будут становиться все более способными справляться с нюансами обнаружения и подсчета листьев, прокладывая путь для более надежных и масштабируемых приложений в точном земледелии.
7. Заключение
Данное исследование продемонстрировало эффективность YOLOv11 для автоматизированного обнаружения и подсчета листьев в яровых и озимых культурах. Использование изображений высокого разрешения с робота и данных, полученных с дрона, позволило провести надежные оценки, с высокой точностью, наблюдаемой для яровых культур. Однако такие проблемы, как окклюзия, изменчивость освещения и меньшие размеры наборов данных, влияли на производительность для озимых культур. Эти результаты подчеркивают важность больших и более разнообразных аннотированных наборов данных для улучшения надежности и обобщения модели. Расширение разнообразия набора данных и использование полуавтоматических инструментов аннотации может решить эти ограничения. В целом, YOLOv11 предоставляет масштабируемое и эффективное решение для обнаружения и сегментации листьев, продвигая автоматизированное фенотипирование растений в точном земледелии.
Ссылки
1. Furbank, R.T.; Tester, M. Phenomics-technologies to relieve the phenotyping bottleneck. Trends Plant Sci. 2011, 16, 635–644. [Google Scholar] [CrossRef] [PubMed]
2. Reynolds, M.; Atkin, O.K.; Bennett, M.; Cooper, M.; Dodd, I.C.; Foulkes, M.J.; Frohberg, C.; Hammer, G.; Henderson, I.R.; Huang, B.; et al. Addressing research bottlenecks to crop productivity. Trends Plant Sci. 2021, 26, 607–630. [Google Scholar] [CrossRef]
3. Yang, W.; Feng, H.; Zhang, X.; Zhang, J.; Doonan, J.H.; Batchelor, W.D.; Xiong, L.; Yan, J. Crop phenomics and high-throughput phenotyping: Past decades, current challenges, and future perspectives. Mol. Plant 2020, 13, 187–214. [Google Scholar] [CrossRef] [PubMed]
4. Chawade, A.; van Ham, J.; Blomquist, H.; Bagge, O.; Alexandersson, E.; Ortiz, R. High-throughput field-phenotyping tools for plant breeding and precision agriculture. Agronomy 2019, 9, 258. [Google Scholar] [CrossRef]
5. Ronse De Craene, L.P. Are petals sterile stamens or bracts? The origin and evolution of petals in the core eudicots. Ann. Bot. 2007, 100, 621–630. [Google Scholar] [CrossRef]
6. Das, P.; Rahimzadeh-Bajgiran, P.; Livingston, W.; McIntire, C.D.; Bergdahl, A. Modeling forest canopy structure and developing a stand health index using satellite remote sensing. Ecol. Inform. 2024, 84, 102864. [Google Scholar] [CrossRef]
7. Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
8. Rose, J.C.; Paulus, S.; Kuhlmann, H. Accuracy analysis of a multi-view stereo approach for phenotyping of tomato plants at the organ level. Sensors 2015, 15, 9651–9665. [Google Scholar] [CrossRef] [PubMed]
9. Velusamy, P.; Rajendran, S.; Mahendran, R.K.; Naseer, S.; Shafiq, M.; Choi, J.G. Unmanned Aerial Vehicles (UAV) in precision agriculture: Applications and challenges. Energies 2021, 15, 217. [Google Scholar] [CrossRef]
10. Singh, A.; Jones, S.; Ganapathysubramanian, B.; Sarkar, S.; Mueller, D.; Sandhu, K.; Nagasubramanian, K. Challenges and opportunities in machine-augmented plant stress phenotyping. Trends Plant Sci. 2021, 26, 53–69. [Google Scholar] [CrossRef] [PubMed]
11. Johannsen, L.C.; Khan, A.T.; Jensen, S.M.; Kruppa-Scheetz, J. Innovative Leaf Disease Mapping: Unsupervised Anomaly Detection for Precise Area Estimation. Int. J. Mach. Learn. Cybern. 2024, preprint. [Google Scholar]
12. Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution RGB imagery using deep learning technique. Agric. For. Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
13. Khan, A.T.; Jensen, S.M.; Khan, A.R.; Li, S. Plant disease detection model for edge computing devices. Front. Plant Sci. 2023, 14, 1308528. [Google Scholar] [CrossRef]
14. Maes, W.H.; Steppe, K. Perspectives for remote sensing with unmanned aerial vehicles in precision agriculture. Trends Plant Sci. 2019, 24, 152–164. [Google Scholar] [CrossRef]
15. d’Andrimont, R.; Yordanov, M.; Martinez-Sanchez, L.; Van der Velde, M. Monitoring crop phenology with street-level imagery using computer vision. Comput. Electron. Agric. 2022, 196, 106866. [Google Scholar] [CrossRef]
16. Junior, L.C.M.; Ulson, J.A.C. Real time weed detection using computer vision and deep learning. In Proceedings of the 2021 14th IEEE International Conference on Industry Applications (INDUSCON), Sao Paulo, Brazil, 15–18 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1131–1137. [Google Scholar]
17. Abbaspour-Gilandeh, Y.; Aghabara, A.; Davari, M.; Maja, J.M. Feasibility of using computer vision and artificial intelligence techniques in detection of some apple pests and diseases. Appl. Sci. 2022, 12, 906. [Google Scholar] [CrossRef]
18. Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer vision technology in agricultural automation—A review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
19. Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Advances in Neural Information Processing Systems, Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; Volume 29, p. 29. [Google Scholar]
20. Trabucco, B.; Doherty, K.; Gurinas, M.; Salakhutdinov, R. Effective data augmentation with diffusion models. arXiv 2023, arXiv:2302.07944. [Google Scholar]
21. Bonifacio, L.; Abonizio, H.; Fadaee, M.; Nogueira, R. Inpars: Data augmentation for information retrieval using large language models. arXiv 2022, arXiv:2202.05144. [Google Scholar]
22. Hamuda, E.; Mc Ginley, B.; Glavin, M.; Jones, E. Automatic crop detection under field conditions using the HSV colour space and morphological operations. Comput. Electron. Agric. 2017, 133, 97–107. [Google Scholar] [CrossRef]
23. Amin, S.U.; Hussain, A.; Kim, B.; Seo, S. Deep learning based active learning technique for data annotation and improve the overall performance of classification models. Expert Syst. Appl. 2023, 228, 120391. [Google Scholar] [CrossRef]
24. Pangakis, N.; Wolken, S. Keeping Humans in the Loop: Human-Centered Automated Annotation with Generative AI. arXiv 2024, arXiv:2409.09467. [Google Scholar]
25. Wang, Y.; Stevens, D.; Shah, P.; Jiang, W.; Liu, M.; Chen, X.; Kuo, R.; Li, N.; Gong, B.; Lee, D.; et al. Model-in-the-Loop (MILO): Accelerating Multimodal AI Data Annotation with LLMs. arXiv 2024, arXiv:2409.10702. [Google Scholar]

Khan AT, Jensen SM. LEAF-Net: A Unified Framework for Leaf Extraction and Analysis in Multi-Crop Phenotyping Using YOLOv11. Agriculture. 2025; 15(2):196. https://doi.org/10.3390/agriculture15020196
Перевод статьи «LEAF-Net: A Unified Framework for Leaf Extraction and Analysis in Multi-Crop Phenotyping Using YOLOv11» авторов Khan AT, Jensen SM., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)