Точный прогноз для малых полей: как ИИ оценивает урожай риса по форме колоса
Интеллектуальная модель прогнозирования урожайности риса на малых площадях возделывания может обеспечить точные результаты прогнозирования для фермеров, рисоводческих предприятий и исследователей, что имеет большое значение для сельскохозяйственной отрасли и исследований в области растениеводства в малых регионах. Хотя машинное обучение способно решать сложные нелинейные задачи для повышения точности прогнозов, всё ещё необходимы дальнейшие улучшения моделей для точного прогнозирования урожайности риса на малых территориях, сталкивающихся со сложными условиями возделывания, тем самым повышая производительность моделей.
Аннотация
В данном исследовании используются четыре фенотипических признака риса, а именно угол наклона метёлки, длина метёлки, общая длина ветвей и количество зёрен, а также семь методов машинного обучения — множественная линейная регрессия, метод опорных векторов, MLP, случайный лес, GBR, XGBoost и LightGBM — для построения группы моделей прогнозирования урожайности. Впоследствии три лучшие модели с наивысшей производительностью в индивидуальных прогнозах интегрируются с использованием методов ансамблевого голосования и стекинга для получения оптимальной интеграционной модели. Наконец, исследуется влияние различных фенотипических признаков риса на производительность стекинг-ансамблевой модели. Результаты экспериментов показывают, что модель случайного леса демонстрирует наилучшие результаты после индивидуального моделирования методами машинного обучения, со значениями RMSE, R² и MAPE, равными 0,2777, 0,9062 и 17,04% соответственно. После интеграции моделей Stacking-3m демонстрирует наилучшую производительность со значениями RMSE, R² и MAPE, равными 0,2483, 0,9250 и 6,90% соответственно. По сравнению с результатами после моделирования случайным лесом, RMSE снизился на 10,58%, R² увеличился на 1,88%, а MAPE уменьшился на 0,76%, что указывает на улучшение производительности модели после стекинг-ансамбля. Модель Stacking-3m, показавшая наилучшие комплексные оценочные метрики, была выбрана для валидации, и результаты валидации оказались удовлетворительными, со значениями MAE, R² и MAPE, равными 8,3384, 0,9285 и 0,2689 соответственно. Приведённые выше результаты исследований демонстрируют, что данная интеграционная модель обладает высокой практической ценностью и заполняет пробел в точном прогнозировании урожайности для маломасштабного выращивания риса в регионе Юньнаньского нагорья.
1. Введение
Рис является одной из важнейших продовольственных культур в мире, играя ключевую роль в национальной продовольственной безопасности и средствах к существованию людей [1,2]. Согласно статистике, общий объем мирового производства риса в сезоне 2023/2024 года составляет приблизительно 517,34 млн тонн, что делает его одной из культур с самой большой площадью возделывания и самым высоким урожаем в мире. Китай является крупнейшим производителем риса в мире, его годовой объем производства составляет примерно 30% от мирового общего показателя [3]. Статистика показывает, что производство риса в Китае в сезоне 2023/2024 года составило приблизительно 144,62 млн тонн, что занимает первое место в мире. Однако при населении, превышающем 1,41 млрд человек (Китай является второй по численности населения страной в мире), и объеме импорта только в 2023 году в 2,63 млн тонн риса и рисовой крупы, Китай по-прежнему сталкивается с дилеммой нехватки продовольствия, несмотря на высокое производство риса. Следовательно, прогнозирование производства риса имеет большое значение для глобальной продовольственной безопасности.
Современные методы прогнозирования урожайности риса в основном основаны на традиционных измерительных методиках, моделях роста сельскохозяйственных культур и технологиях дистанционного зондирования, которые моделируются, а затем используются для прогнозирования. Среди них традиционные методы измерений предполагают отбор рисовых полей для выборки на основе принципов равной площади или среднего по группе. После созревания рис подвергается обмолоту, сушке, очистке и взвешиванию, затем с помощью влагомера измеряется его влажность. Окончательная урожайность риса рассчитывается на основе пропорций индика и японики, составляющих 13,5% и 14,5% соответственно [4]. Этот метод является громоздким, дорогостоящим, требует много времени и труда, а также подвержен значительным ошибкам. Модели роста сельскохозяйственных культур превосходят традиционные методы прогнозирования урожайности риса, поскольку они могут выводить соответствующие прогнозные результаты просто путем ввода соответствующих параметров. Модели, такие как WOFOST (World Food Studies), APSIM (Agricultural Production System Simulator) и DSSAT (Decision Support System for Agrotechnology Transfer), могут имитировать развитие и рост сельскохозяйственных культур [5]. Однако эти модели в значительной степени зависят от местных почвенных условий, методов управления культурой и обширных климатических данных [2], и они требуют значительных вычислительных затрат [6]. В последнее время AquaCrop, новая модель сельскохозяйственных культур, разработанная ФАО, широко используется в производственной практике благодаря своим преимуществам, таким как меньшее количество входных параметров и простой интерфейс. Однако модель сталкивается с проблемами нестабильности в точности моделирования, а калибровка и корректировка параметров модели являются требовательными, что ограничивает сферу ее применения конкретными регионами и типами сельскохозяйственных культур [7]. Технология дистанционного зондирования успешно применяется для прогнозирования урожайности сельскохозяйственных культур [8,9], например, для риса [10,11]. Различные наборы данных дистанционного зондирования могут быть получены с помощью наземного спектрального отражения, RGB/мультиспектральных/гиперспектральных изображений с дронов и спутниковых платформ. В последние годы спутники среднего и высокого разрешения, такие как MODIS, QuickBird, Landsat и SPOT, широко используются для прогнозирования урожайности зерна в больших масштабах [12,13]. Однако точность прогнозирования урожайности зерна с использованием спутниковых изображений зависит от временного, пространственного и спектрального разрешения [14], и такие факторы, как сложность рельефа, длительность цикла повторного обзора, низкое пространственное разрешение и размер площади сельскохозяйственных угодий, значительно влияют на прогнозирование урожайности сельскохозяйственных культур [10,15]. С углубленным развитием технологий больших данных, многопользовательские данные дистанционного зондирования, как продукт технологий больших данных, предоставляют новый метод мониторинга для оценки урожайности сельскохозяйственных культур. LCC оценивалась путем слияния спутниковых изображений или изображений с БПЛА [16], и производительность оценивалась с использованием независимых наборов данных [17,18]. Кроме того, слияние многопользовательских данных дистанционного зондирования эффективно повышает точность прогнозирования урожайности зерна [19,20]. Чтобы установить модель прогнозирования урожайности зерна, большинство исследований напрямую используют спектральную информацию и информацию RGB-изображений. Хотя эти прогностические модели могут точно прогнозировать урожай и легко интерпретируются, им часто не хватает механистических объяснений. Следовательно, сложно использовать информацию дистанционного зондирования для объяснения влияния физиологических процессов на урожай зерна и точности этих прогностических моделей [21].
Различие между машинным обучением и традиционными моделями роста сельскохозяйственных культур в прогнозировании урожайности заключается в том, что алгоритмы машинного обучения, будучи смоделированными, способны обрабатывать нелинейные отношения и демонстрируют адаптивность, возможности обобщения, а также способности к изучению и выбору признаков, тем самым повышая точность прогнозирования [22]. Следовательно, технология машинного обучения, как одна из наиболее ключевых и практичных технологий в области точного земледелия, широко применяется по всей цепочке создания стоимости в сельском хозяйстве, повышая производственную эффективность [23]. В частности, с постоянным совершенствованием алгоритмов машинного обучения, интеграция этих методов со знаниями из смежных областей сельского хозяйства привела к построению разнообразных моделей точного земледелия, дающих положительные результаты, что делает его одним из основных технологических средств для изучения сельского хозяйства будущего [24,25]. Это связано с тем, что машинное обучение хорошо справляется с нелинейными отношениями, обладает адаптивностью, возможностями обобщения, а также способностями к изучению и выбору признаков, что, в свою очередь, повышает точность и гибкость прогнозирования [22]. Одновременно, путем обучения на исторических данных, автоматического обучения и извлечения взаимосвязей между признаками строятся интеллектуальные модели, отображающие входные признаки на целевые переменные, а именно урожайность сельскохозяйственных культур [26,27]. Этот подход варьируется от базовых регрессионных моделей до сложных алгоритмов глубокого обучения (DL) [28]. Ямпарла и др. [29], на основе обширных исторических и экологических данных, использовали различные алгоритмы машинного обучения для построения модели прогнозирования урожайности сельскохозяйственных культур. Результаты исследования показали, что алгоритм случайного леса при применении для прогнозирования урожайности сельскохозяйственных культур в Индии достиг точности 95%. Паудел и др. [30] приняли улучшенный метод машинного обучения для построения модели прогнозирования урожайности сельскохозяйственных культур для европейского региона. Драммонд и др. [31] использовали множественную линейную регрессию (SMLR), проекционно-поисковую регрессию (PPR) и несколько типов нейронных сетей для построения модели прогнозирования урожайности зерна. Экспериментальные результаты показали, что производительность алгоритмов нейронных сетей после моделирования превзошла производительность SMLR и PPR. Хаки и Ванг [32] разработали модель остаточной нейронной сети для прогнозирования урожайности. Мупангва и др. [33] оценили производительность нескольких моделей машинного обучения (ML) в прогнозировании урожайности зерна кукурузы в условиях сохранного земледелия. Многочисленные исследователи построили модели прогнозирования урожайности сельскохозяйственных культур на основе методов машинного обучения, добившись заметных успехов. Однако эти исследователи в основном строили модели прогнозирования урожайности сельскохозяйственных культур на основе исторических и экологических данных конкретного региона. Эти модели в основном прогнозируют урожайность сельскохозяйственных культур в широких областях, в основном применяются для оценки урожайности в определенной области, подходят для прогнозирования урожайности сельскохозяйственных культур правительственными ведомствами, но недостаточны для прогнозирования урожайности сельскохозяйственных культур на конкретных посевных площадях. Однако с быстрым развитием технологий точного земледелия все больше предпринимателей погружаются в развитие сельскохозяйственной отрасли. Предприятия по выращиванию сельскохозяйственных культур, отдельные фермеры, исследователи и сборщики данных нуждаются в точных прогнозах для культур, выращиваемых на конкретных участках или нескольких участках. Одновременно, по мере того как технологии точного земледелия продолжают развиваться, единичная модель машинного обучения больше не может удовлетворять требованиям прогнозирования урожайности сельскохозяйственных культур на основе фенотипических характеристик в сложных условиях окружающей среды. Поэтому существует настоятельная необходимость в разработке нового метода точного прогнозирования урожайности риса.
Это исследование решает задачу точного прогнозирования урожайности риса в сложных условиях горных районов плато Юньнань, характеризующихся многочисленными горными районами, обширными террасными полями, небольшими площадями рисовых полей и низкой урожайностью. Вначале, фенотипические признаки зрелого риса были измерены с помощью сканера фенотипов риса TPS–BX–1 (China Zhejiang topu yunnong Technology Co., Ltd., Ханчжоу, Китай), служащих влияющими факторами для построения модели машинного обучения. Вес каждого рисового колоса был определен как соответствующий результат этих влияющих факторов, была создана база данных фенотипических ресурсов риса, состоящая из 2048 наборов данных. Это обеспечивает поддержку данных для построения точной модели прогнозирования урожайности риса, интегрирующей несколько интеллектуальных алгоритмов. Далее, путем сочетания точного прогнозирования урожайности риса на основе интеллектуальных алгоритмов с алгоритмами ансамбля, мы провели углубленное исследование сильных и слабых сторон различных алгоритмов машинного обучения при решении одной и той же проблемы. Это эффективно использует преимущества отдельных моделей, повышая производительность ансамблевой модели. Был предложен метод построения интегрированной модели для прогнозирования урожайности риса на основе фенотипических данных, направленный на построение интегрированной модели для прогнозирования урожайности риса в условиях мелкомасштабного возделывания. Это решает задачу точного прогнозирования урожайности риса для фермеров, баз (предприятий) по выращиванию сельскохозяйственных культур и исследователей.
2. Область исследования и обработка данных
2.1. Район исследования
Юньнаньский сельскохозяйственный университет расположен в районе Паньлун, Куньмин, провинция Юньнань, Китай. Среднегодовая температура составляет 14,9 °C, с абсолютным максимумом 31,5 °C и абсолютным минимумом –7,8 °C. Среднегодовое количество осадков составляет приблизительно 1000,5 мм, с максимальным месячным количеством осадков 208,3 мм и максимальным суточным количеством осадков 153,3 мм, преимущественно сконцентрированным с мая по сентябрь. Годовая продолжительность солнечного сияния составляет 2327,5 ч, а годовое испарение — 1856,4 мм. Максимальная скорость ветра — 40 м/с, преимущественно с юго-запада. Относительная влажность составляет 76%. Комплексная учебно-практическая база новых агрономических наук была создана и широко введена в эксплуатацию 1 августа 2023 года, в основном для исследований в области селекции, возделывания, точного земледелия и сельскохозяйственной инженерии. Основным типом почвы в регионе является краснозем, который широко распространен по краям озерных котловин плато и в низкогорных и среднегорных районах на высотах от 1500 до 2500 м на севере Юньнани на широтах от 24° до 26°. Этот тип почвы подходит для роста различных растений, включая зерновые и технические культуры, такие как рис, пшеница, бобы, кукуруза, картофель, рапс, табак, овощи и цветы.
Зона 2–22 Комплексной учебно-практической базы новых агрономических наук при Юньнаньском сельскохозяйственном университете является одной из ведущих исследовательских и учебных баз для Ключевой лаборатории производства сельскохозяйственных культур и точного земледелия провинции Юньнань. Как показано на Рисунке 1, эта зона служит рисовым экспериментальным участком, в основном ответственным за построение моделей роста сельскохозяйственных культур для облегчения интеллектуального управления полем. Она собирает данные об окружающей среде, почвенные данные и фенотипические данные в процессе роста сельскохозяйственных культур с помощью метеостанций и датчиков влажности почвы, среди других устройств Интернета вещей. Основываясь на этом, в данном исследовании были построены несколько индивидуальных моделей прогнозирования урожайности риса с использованием различных алгоритмов машинного обучения на основе фенотипических данных и соответствующих данных об урожайности, собранных при возделывании риса на базе. Впоследствии, это исследование выбрало три наиболее точные модели среди этих индивидуальных моделей и использовало как метод голосования ансамбля, так и метод стекинга ансамбля для разработки модели интегрированного обучения, нацеленной на выявление наиболее подходящего подхода для прогнозирования урожайности риса. Этот подход позволяет точно прогнозировать урожайность риса в условиях мелкомасштабного возделывания, завершая разработку широко применимой и демонстрационной модели прогнозирования урожайности риса.
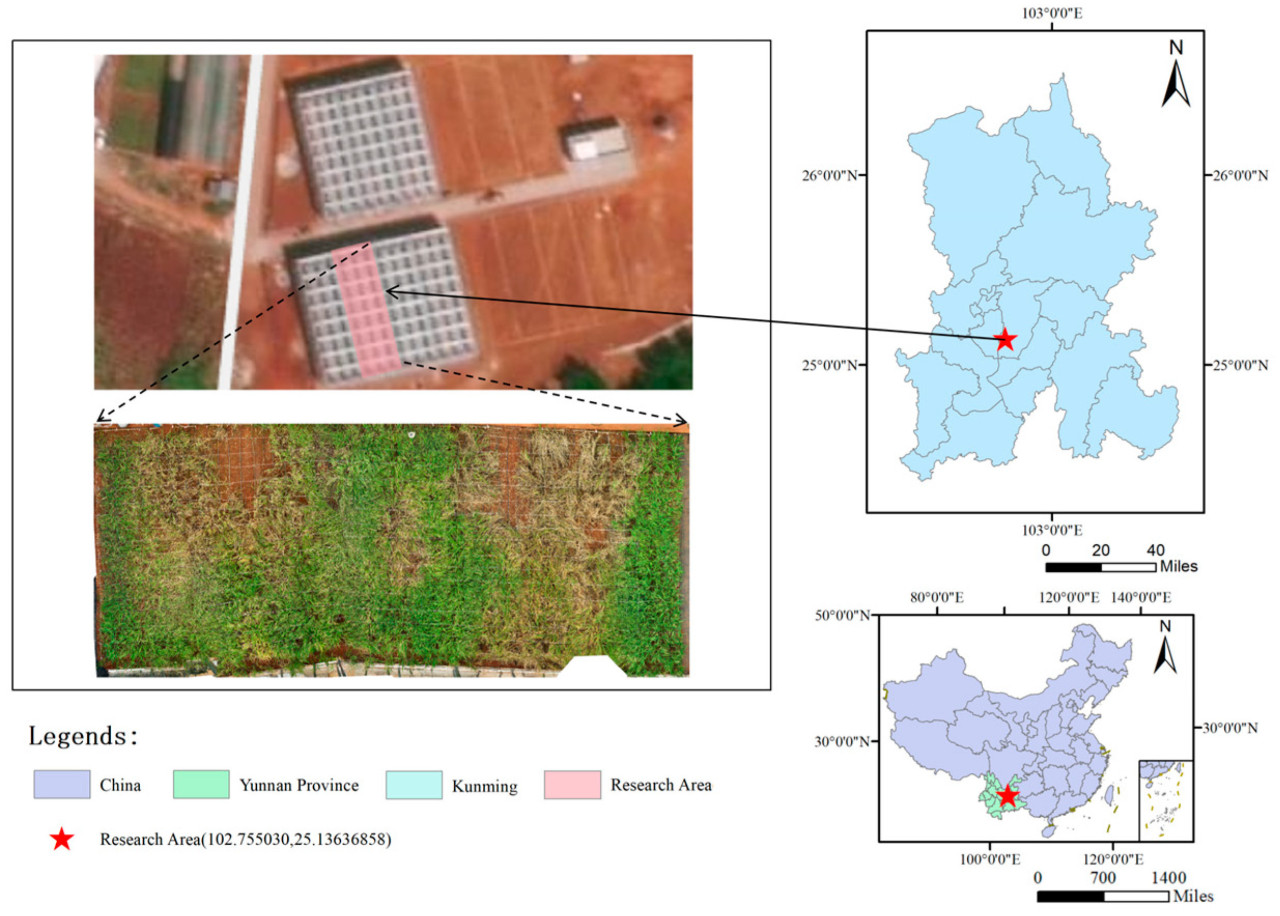
Рисунок 1. Карта района исследования.
2.2. Сбор и обработка данных
2.2.1. Набор данных
Это исследование проводилось 15 апреля 2024 года на Комплексной учебно-практической базе новых агрономических наук Юньнаньского сельскохозяйственного университета, в частности в зоне 2–22 — рисовой экспериментальной зоне. Сорт риса Dianhe 615 был высажен методом посева на суше, занимая площадь более 160 квадратных метров. Как только рис вступил в стадию прорастания, экспериментальное поле было разделено на пять секций, каждая с разной нормой полива, в основном путем регулировки капельного полива на 100%, 75%, 50%, 25% и 0% открытия. По мере созревания риса белой веревкой экспериментальное поле было разделено на 512 меньших посадочных секций, каждая из которых служила независимой единицей наблюдения. 25 сентября 2024 года, после того как рис достиг полной зрелости, для измерения ключевых фенотипических признаков и веса каждого колоса риса был использован детектор фенотипов риса TPS–BX–1 (включая приложение «Zhizhong»). Конкретные детали включают следующее.
Вначале, в каждой подобласти случайным образом отбирались четыре рисовых колоса в качестве образцов для измерения, в результате чего было получено в общей сложности 2048 наборов данных. Детектор фенотипов риса TPS–BX–1, включая приложение «Zhizhong», в основном использовался для измерения фенотипических признаков каждого колоса, включая угол, длину колоса, общую длину ветвей, количество зерен и вес зерна. Впоследствии, для проверки экспериментальных результатов и прогнозирования урожайности подобластей, данные из 12 случайно выбранных подобластей из 512 использовались в качестве проверочных образцов. Детектор фенотипов риса использовался для измерения количества колосьев в этих подобластях, в то время как электронные весы использовались для определения веса каждой подобласти. Конкретные методы сбора показаны на Рисунке 2.

Рисунок 2. Система обнаружения фенотипов риса.
Мы разделили задачу измерения фенотипических признаков риса на пять групп, каждая из которых состояла из пяти человек, всего 25 человек. Пять типов фенотипических признаков измерялись с помощью сканера фенотипов риса TPS–BX–1. Взяв одну группу в качестве примера, мы подробно опишем процесс сбора данных следующим образом. Во-первых, 12 малых участков были случайным образом выбраны в пределах рисовой экспериментальной зоны. Объект перекрестной калибровки в детекторе фенотипов риса TPS–BX–1 был размещен непосредственно над посаженным рисом. Впоследствии, функция «количество колосьев на му» приложения «Know–Seed» использовалась для фотомониторинга, в результате чего были получены подсчеты колосьев: 11, 15, 18, 28, 41, 14, 35, 42, 43, 40, 16 и 14 колосьев на этих 12 малых участках. Затем, путем ручного подсчета, было обнаружено, что только на одном малом участке не хватало одного колоса, остальные данные были верными. Наконец, устройство использовалось для измерения колосьев на 512 малых участках. После измерения количества рисовых колосьев из каждого малого участка случайным образом отбирались четыре колоса в качестве объектов измерения, всего 2048 рисовых колосьев. Угол риса, длина колоса, количество зерен на растение, вес зерна и вес колоса измерялись отдельно. Конкретный метод измерения показан на Рисунке 2: Во-первых, телефон был закреплен на держателе телефона измерителя угла, а ветви колоса были зафиксированы на прижимной пластине. Функция «угол культуры» приложения «Know–Seed» использовалась для фотографирования и анализа каждого случайно выбранного рисового колоса для получения значения угла. Четыре рисовых колоса были случайным образом выбраны из каждого малого участка для проведения измерительных экспериментов и размещены на фотопланшете для измерения морфологии рисового колоса, и функция «морфология рисового колоса» приложения «Know–Seed» использовалась для анализа от первой ветви до верхушки рисового колоса для получения длины колоса. Первичные и вторичные ветви каждого случайно выбранного образца помещались в соответствующие области на фотопланшете, и функция «полное обследование рисового колоса» приложения «Know–Seed» использовалась для фотографирования и анализа ветвей, записывая общую длину ветвей рисового колоса. Все зерна одного рисового колоса размещались на фоновом фотопланшете, и функция «подсчет семян» приложения «Know–Seed» использовалась для фотографирования и получения количества зерен. После завершения сбора данных по 2048 рисовым колосьям был сформирован исходный набор данных фенотипа одиночного колоса риса, как показано в Таблице 1, служащий базовой базой данных для построения интегрированной модели прогнозирования значений фенотипических характеристик риса и урожайности.
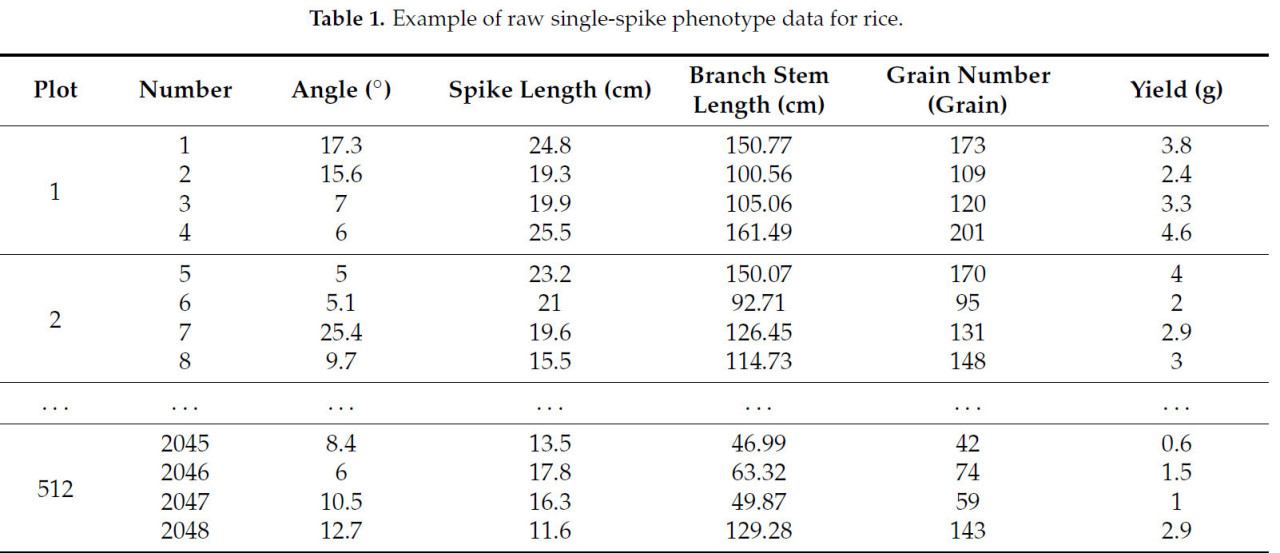
Таблица 1. Пример исходных данных фенотипа одиночного колоса риса.
2.2.2. Анализ и обработка данных
В этом эксперименте мы повысили обобщающую способность модели в нестабильных и неоднозначных условиях путем введения шума, следующего нормальному распределению, имитируя потенциальные колебания или ошибки, которые могут возникнуть в реальных данных. В частности, мы использовали метод `random.normal()` из numpy для генерации случайного массива с тем же количеством строк, что и исходные данные, где каждый элемент был взят из нормального распределения со средним значением 0 и стандартным отклонением 0,5. Это внесло определенную степень случайных вариаций в исходные данные. Этот подход обычно используется в обработке и анализе данных, обеспечивая реалистичное представление фактических условий данных. В ходе эксперимента мы собрали 2048 точек данных, охватывающих пять фенотипических признаков риса, включая угол, длину метелки, общую длину ветвей, количество зерен и вес зерна, все полученные из одного и того же рисового колоса. Как показано в Таблице 2, перед построением модели прогнозирования урожайности мы объединили первую и последнюю строки набора данных для расчета среднего значения, получив одну точку данных и вдвое сократив общий объем данных. Впоследствии, мы расширили набор данных на 1024 точки шумовых данных, установив стандартное отклонение шума равным 0,05. Окончательный выборочный набор данных состоял из 2048 точек данных, как показано в Таблице 3.
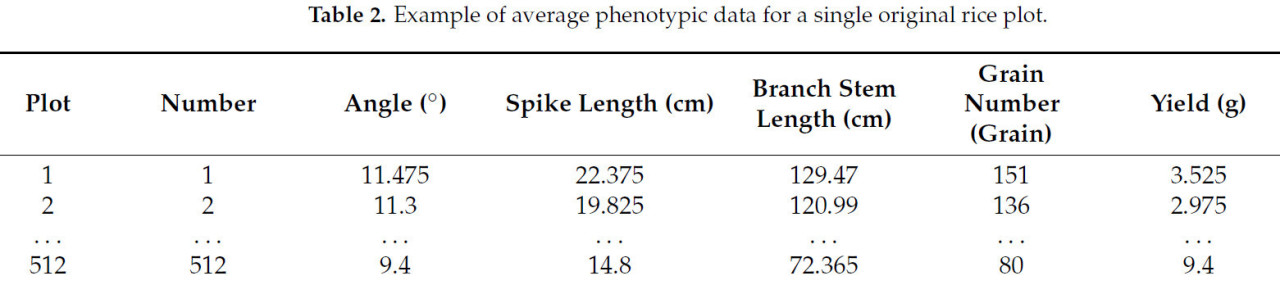
Таблица 2. Пример усредненных фенотипических данных для одного исходного участка риса.
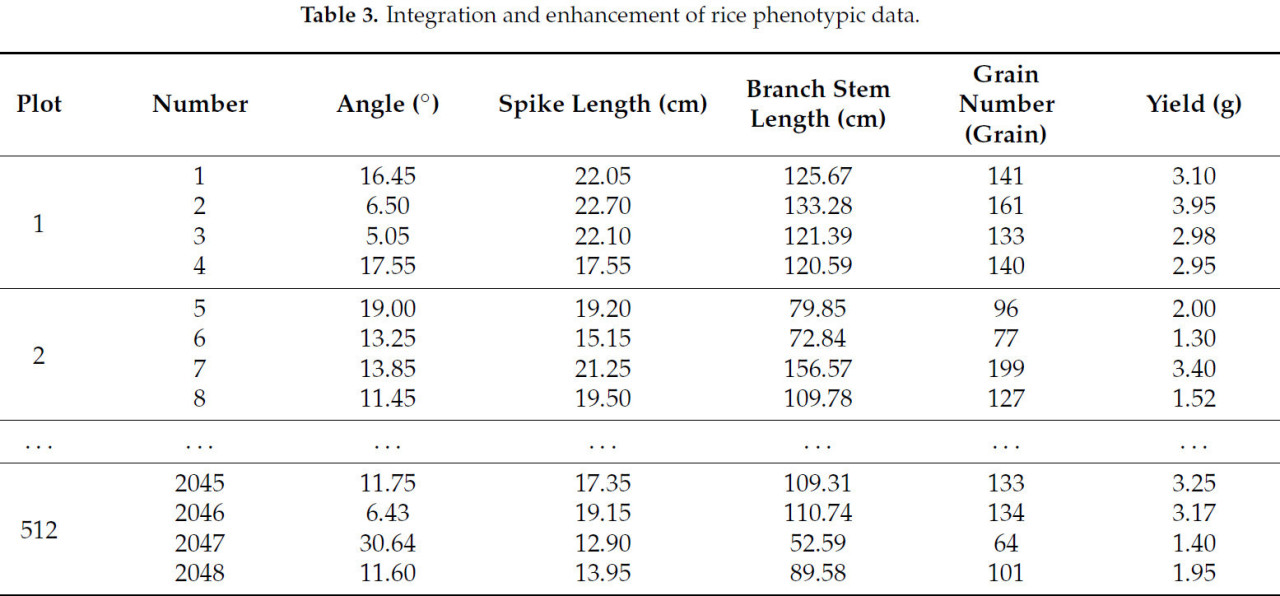
Таблица 3. Интеграция и расширение фенотипических данных риса.
Рисунок 3, показывающий взаимосвязь между фенотипическими характеристиками и урожайностью при возделывании риса, иллюстрирует взаимосвязь между четырьмя фенотипическими признаками риса и урожайностью с помощью диаграмм рассеяния. Очевидно, что распределение взаимосвязи между углом риса и урожайностью относительно равномерно, что указывает на отсутствие определенной линейной тенденции между двумя переменными. Напротив, взаимосвязи между такими признаками риса, как длина метелки, длина ветвей и количество зерен, и урожайностью демонстрируют линейное распределение, что предполагает значительную положительную корреляцию между этими тремя признаками и урожайностью. Кроме того, во взаимосвязях между длиной метелки и количеством зерен и урожайностью заметно, что из-за ошибок измерения, ошибок ввода данных и других факторов в выборке присутствуют отдельные выбросы. Поэтому необходимо устранить эти аномалии в ходе последующей обработки данных.
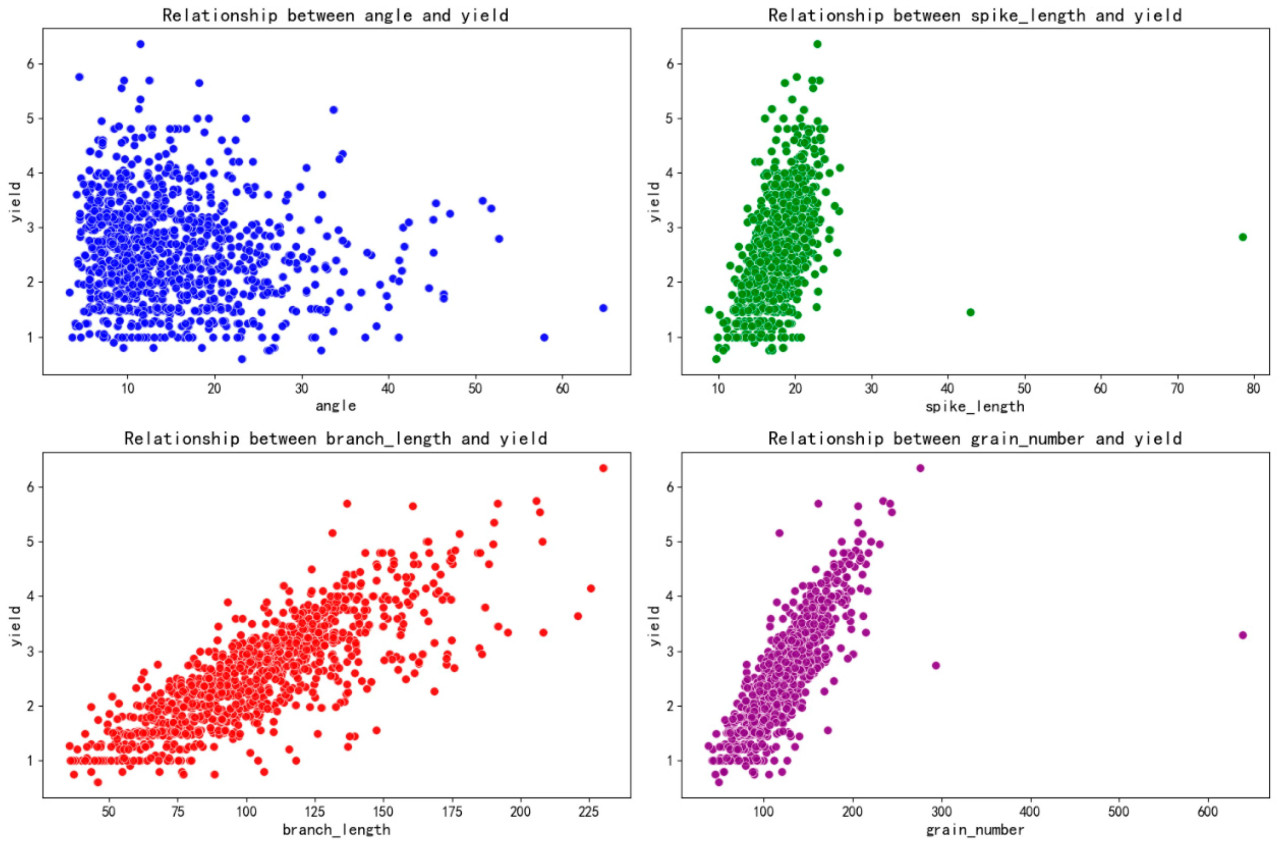
Рисунок 3. Взаимосвязь между фенотипическими характеристиками и урожайностью при возделывании риса.
3. Методология
Это исследование в основном включает планирование эксперимента, возделывание риса, сбор фенотипических данных риса и анализ данных для создания базы данных фенотипических признаков риса. Было выбрано семь различных алгоритмов машинного обучения для построения группы моделей прогнозирования урожайности на основе фенотипических данных риса. После анализа результатов прогнозирования каждой модели были выбраны три модели с высокой точностью и различиями между моделями. Методы ансамбля голосования и стекинга были использованы для интеграции этих моделей, тем самым создавая интегрированную модель для прогнозирования урожайности риса на основе фенотипических данных. Детальный план эксперимента иллюстрируется на Рисунке 4:
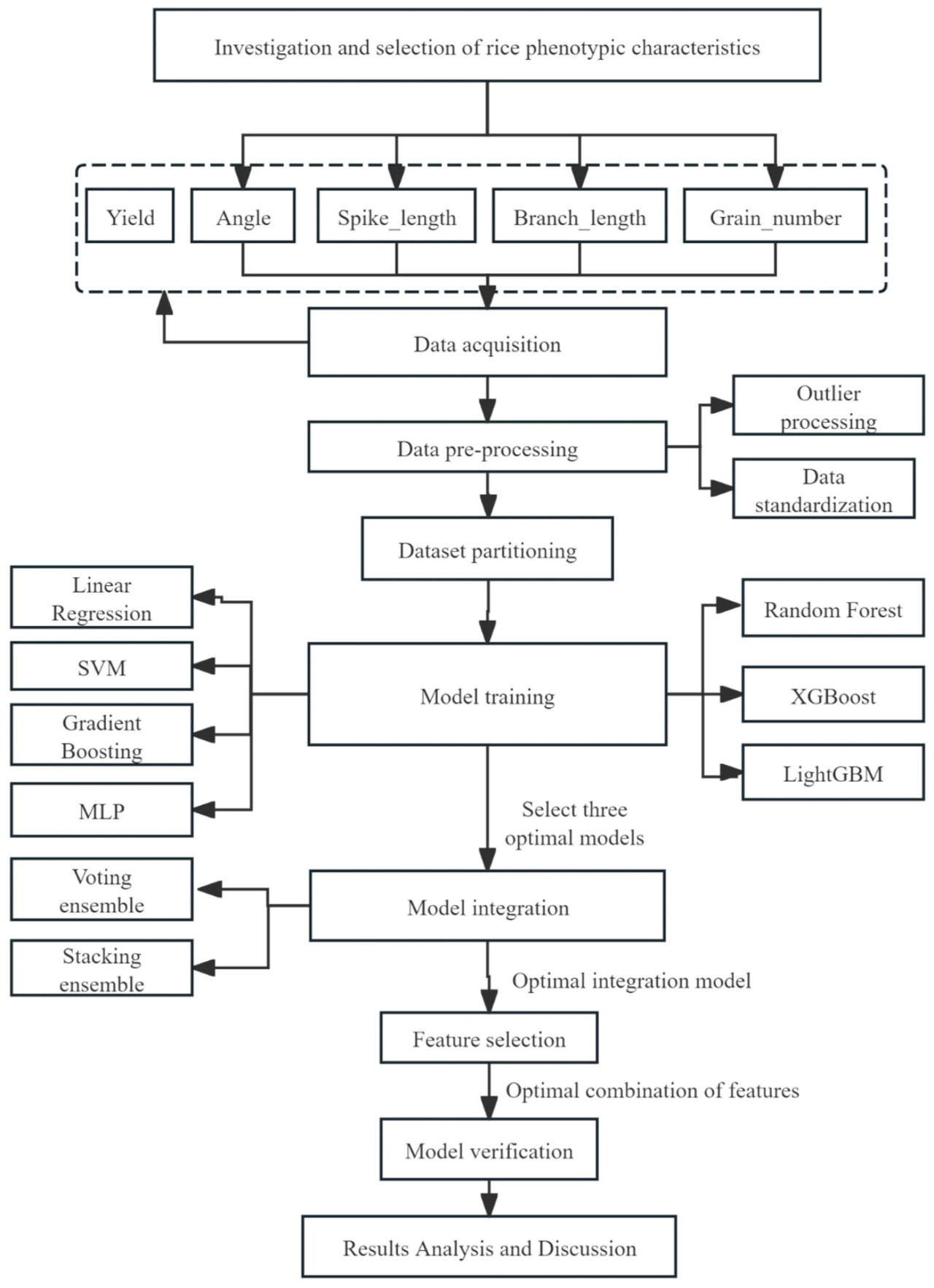
Рисунок 4. Дорожная карта технологии интегрированной модели прогнозирования урожайности на основе фенотипических данных риса.
3.1. Обработка аномальных данных
Метод межквартильного размаха (IQR) способен выявлять выбросы в данных путем расчета нижней и верхней границ. Любые точки данных, которые находятся ниже нижней границы или превышают верхнюю границу, считаются выбросами и могут быть удалены или заменены. Следовательно, данные для этого исследования следовали нормальному распределению. С помощью этого метода были выбраны точки данных между нижней и верхней границами, и окончательный набор данных был получен после удаления оставшихся пропущенных значений.
3.2. Выбор алгоритма
В этом исследовании были интегрированы алгоритмы машинного обучения для построения точных моделей прогнозирования урожайности на основе фенотипических признаков риса с использованием алгоритмов множественной линейной регрессии, метода опорных векторов, MLP, случайных лесов, GBR, XGBoost и LightGBM. Конкретные алгоритмы были следующими:
1. Множественная линейная регрессия (LR)
Многомерная линейная регрессия — это статистический метод, используемый для прогнозирования взаимосвязи между непрерывной зависимой переменной и двумя или более независимыми переменными [34]. Этот метод основан на нескольких ключевых допущениях, включая линейность, независимость наблюдений, нормальное распределение ошибок и гомогенность дисперсии [35]. Его основная форма может быть выражена как в Уравнении (1):
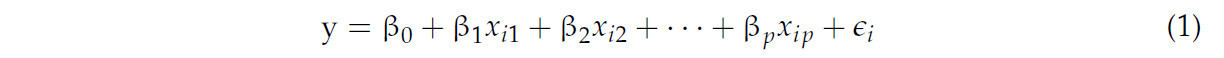
В этом контексте 𝑦ᵢ представляет зависимую переменную, в то время как xᵢ₁, xᵢ₂, …, xᵢₚ обозначают независимые переменные. β₀, β₁, …, βₚ — это параметры, подлежащие оценке, а 𝜖ᵢ означает член ошибки [36].
2. Метод опорных векторов (SVM)
SVM разделяет данные, находя гиперплоскость, которая максимизирует расстояние между выборками разных категорий и этой гиперплоскостью [37]. Для линейно разделимых данных, когда данные не являются линейно разделимыми, SVM отображает исходное пространство признаков в пространство более высокой размерности с помощью ядерной функции, где может быть найдена подходящая гиперплоскость.
3. Многослойный перцептрон (MLP)
MLP — это модель искусственной нейронной сети прямого распространения, состоящая из нескольких слоев, включая входной слой, скрытые слои и выходной слой. Каждый узел преобразует сигналы с помощью нелинейной функции активации, обычно используемые функции активации включают сигмоиду, ReLU (Rectified Linear Unit), гиперболический тангенс и т.д. [38]. Процесс обучения MLP обычно использует алгоритм обратного распространения ошибки для корректировки весов, вычисляя разницу между выходом и истинной меткой для изменения весов внутри сети, тем самым уменьшая потери [39].
4. Случайный лес (RF)
Случайный лес — это метод ансамблевого обучения, который строит несколько деревьев решений для прогнозирования и интегрирует их результаты для получения конечного результата. Каждое дерево строится на основе подмножества набора данных. В процессе построения каждого дерева случайным образом выбирается подмножество признаков для увеличения разнообразия среди деревьев. Используя методы бутстрэп-выборки для генерации различных обучающих наборов, можно оценить степень влияния каждого входного признака на конечный результат прогнозирования [40].
5. Градиентный бустинг для регрессии (GBR)
Градиентный бустинг — это итеративный подход, при котором на каждой итерации создается новая модель, пытающаяся исправить ошибки существующего ансамбля моделей. Градиентный бустинг для регрессии (GBR) постепенно оптимизирует модель путем минимизации функции потерь, обычно включающей среднеквадратическую ошибку [41]. Степень обновления параметров модели на каждой итерации контролируется, при этом меньшая скорость обучения обычно требует большего количества итераций, но может привести к лучшей обобщающей способности [42]. Переобучение можно предотвратить путем корректировки параметров, таких как максимальная глубина и минимальное количество листовых узлов.
6. XGBoost
XGBoost — это оптимизированный фреймворк градиентного бустинга, который включает регуляризацию для смягчения переобучения и демонстрирует повышенную вычислительную эффективность [43]. Он способен обрабатывать крупномасштабные наборы данных и поддерживает множество функций потерь.
7. LightGBM
LightGBM — это фреймворк на основе градиентного бустинга, разработанный Microsoft, характеризующийся быстрой скоростью и минимальным использованием памяти. LightGBM использует методы, известные как GOSS (Gradient-based One–Side Sampling) и EFB (Exclusive Feature Bundling), чтобы ускорить процесс обучения [44].
3.3. Разделение набора данных
Перед применением моделирования машинного обучения мы разделили обучающий и тестовый наборы данных в трех разных соотношениях: 7:3, 8:2 и 9:1. После построения моделей мы сравнили метрики оценки R², RMSE и MAPE различных моделей и выбрали соотношение, соответствующее модели с наилучшей производительностью, в качестве соотношения разделения набора данных для экспериментального моделирования. Как показано на Рисунке 5, соотношение 9:1 продемонстрировало наилучшую комплексную производительность среди нескольких моделей, включая MLPR, SFR, XGBR и LGBMR. На основе данных этого эксперимента оптимальное соотношение разделения набора данных для этого эксперимента составляет 9:1.
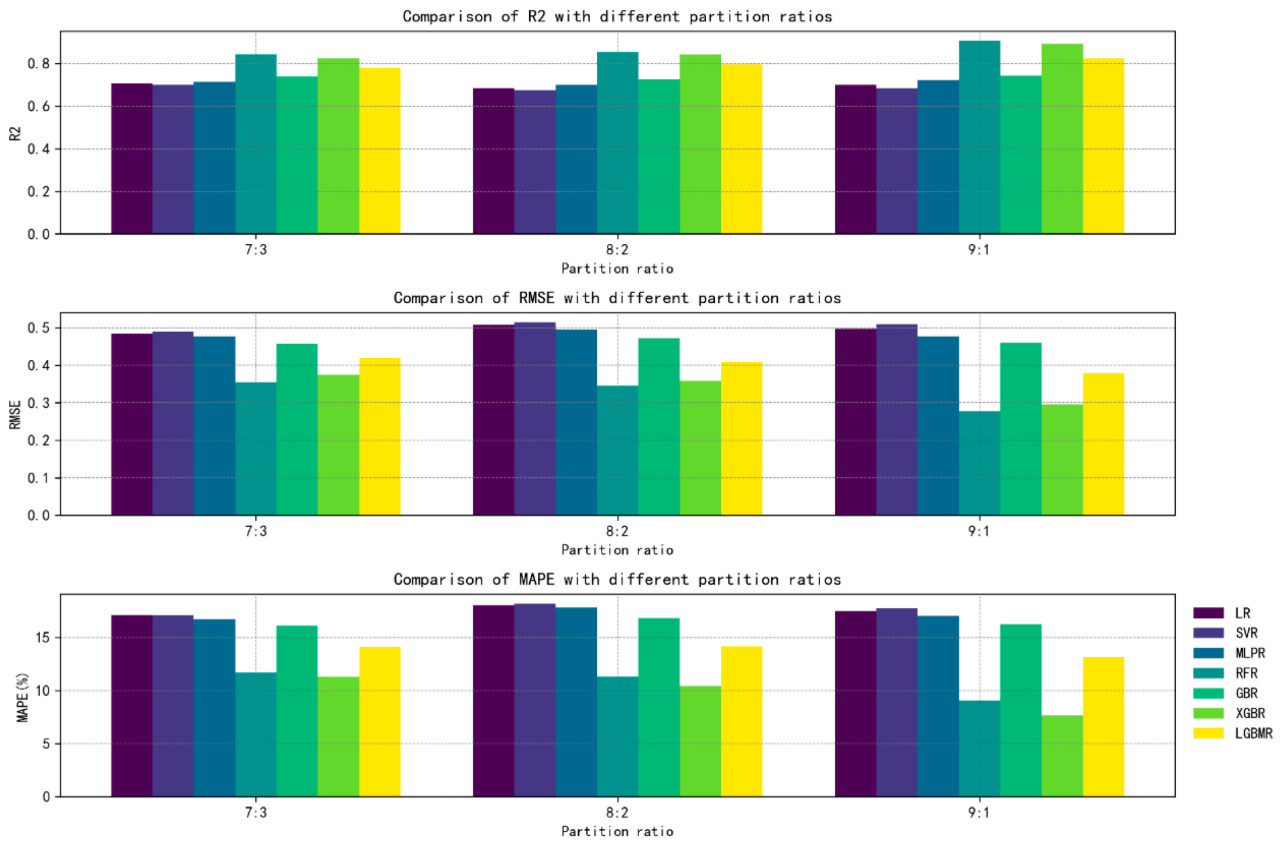
Рисунок 5. Сравнение производительности моделей машинного обучения с разными соотношениями разделения наборов данных.
3.4. Построение группы моделей прогнозирования урожайности риса на малых площадях на основе интеграции нескольких методов машинного обучения
На основе набора фенотипических данных риса, собранного в этом исследовании, с использованием различных моделей машинного обучения (линейная регрессия, метод опорных векторов, многослойный перцептрон, случайный лес, градиентный бустинг, LightGBM, XGBoost) была построена группа моделей прогнозирования урожайности на основе фенотипических данных риса. В процессе сбора фенотипических данных риса такие проблемы, как человеческий фактор и неисправности оборудования, могли привести к пропущенным или аномальным данным. Для повышения качества данных и точности прогнозирования модели вначале была проведена предварительная обработка данных, включая удаление потенциально пропущенных и дублирующихся строк, а затем удаление выбросов с помощью метода верхнего и нижнего усечения. Используя угол (°), длину метелки (см), общую длину ветвей (см) и общее количество зерен (зерен) в качестве признаков, а урожай (г) в качестве метки, набор признаков был стандартизирован, и данные были разделены в соотношении 9:1 на обучающую и тестовую выборки. Используя библиотеки Python 3.9, такие как scikit–learn 1.5, xgboost 2.0.3 и lightgbm 4.3.0, были построены различные регрессионные модели машинного обучения, и для оценки производительности моделей использовались три метрики оценки: среднеквадратическая ошибка (RMSE), коэффициент детерминации (R-квадрат, R²) и средняя абсолютная процентная ошибка (MAPE).
3.5. Модель прогнозирования урожайности риса на основе стекинг-ансамблевого обучения
Единичная модель машинного обучения проявляет недостатки с точки зрения точности и обобщающей способности. Чтобы решить эту проблему, в этом исследовании был использован подход ансамблевого обучения для интеграции нескольких моделей машинного обучения с целью повышения точности прогнозирования урожайности. При выборе базовых моделей для ансамблевого обучения необходимо достичь умеренного разнообразия. Вначале были выбраны три модели с наивысшей точностью среди индивидуальных моделей, обеспечивая умеренную разницу в точности при сохранении структурного разнообразия между моделями. Модели ансамблевого обучения были построены с использованием как метода голосования ансамбля, так и метода стекинга ансамбля, чтобы определить наиболее подходящий ансамблевый подход для задачи прогнозирования урожайности риса. Метод голосования ансамбля включает голосование на основе выходных данных трех базовых моделей для получения результатов прогнозирования, в то время как метод стекинга ансамбля выбирает три базовые модели и мета-модель. Мета-модель использует алгоритм линейной регрессии для объединения выходных данных трех базовых моделей для получения результатов прогнозирования. Метрики оценки для методов ансамблевого обучения также включали среднеквадратическую ошибку, коэффициент детерминации и среднюю абсолютную процентную ошибку.
3.6. Установление метрик оценки
В этом исследовании использовались среднеквадратическая ошибка (RMSE), коэффициент детерминации (R-квадрат) и средняя абсолютная процентная ошибка (MAPE) в качестве метрик оценки для модели прогнозирования урожайности риса. Характеристики этих метрик следующие:
1. Среднеквадратическая ошибка (RMSE)
Среднеквадратическая ошибка (RMSE) — это метрика, используемая для оценки точности прогностических моделей на непрерывных данных. Она представляет собой среднее отклонение между прогнозируемыми и фактическими значениями путем вычисления квадратного корня из среднего квадрата разности между ними. Формула представлена в Уравнении (2).
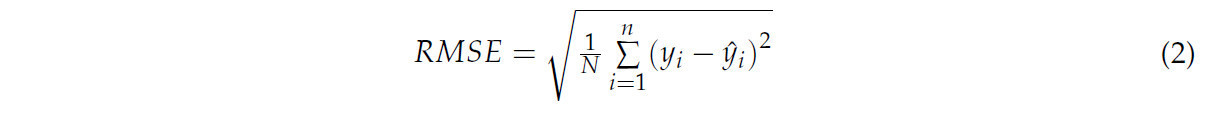
В этом контексте yᵢ обозначает истинное значение, а ŷᵢ представляет прогнозируемое значение.
2. Коэффициент детерминации (R-квадрат)
Коэффициент детерминации (R-квадрат), также известный как R², — это метрика оценки, используемая для оценки точности линейной модели. Его значение находится в диапазоне от 0 до 1. По мере того как значение приближается к 1, это указывает на лучшую производительность модели, тогда как значение, близкое к 0, означает худшую производительность модели. Формула для R-квадрата представлена в Уравнениях (3)–(5):
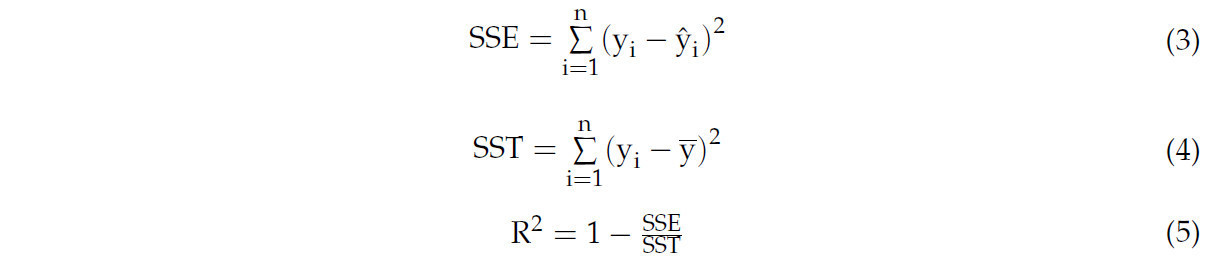
В этом контексте SSE обозначает сумму квадратов ошибок, SST означает общую сумму квадратов, yᵢ представляет истинное значение, ŷᵢ указывает прогнозируемое значение, а ȳ представляет среднее значение.
3. Средняя абсолютная процентная ошибка (MAPE)
Средняя абсолютная процентная ошибка (MAPE) измеряет точность прогнозов модели путем вычисления абсолютной разницы между прогнозируемым и фактическим значениями, деления этой разницы на фактическое значение, а затем усреднения этих значений. Эта формула дает процентную интерпретацию точности прогнозирования модели. Формула представлена в Уравнении (6).
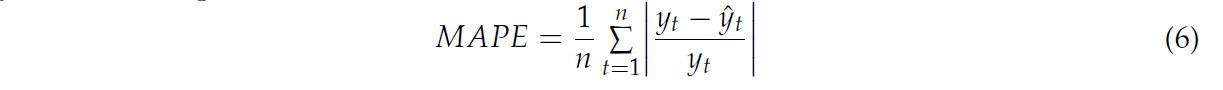
В этом контексте yₜ обозначает истинное значение, а ŷₜ представляет прогнозируемое значение.
4. Результаты
Аппаратная конфигурация этого исследования включает процессор 12-го поколения Intel(R) Core(TM) i9–12900H и 32 ГБ памяти, все эксперименты проводились в среде CPU. Что касается программного обеспечения, в качестве среды разработки использовался PyCharm 2022.4, в качестве языка программирования — Python 3.9, а библиотеки машинного обучения включали scikit–learn 1.5, xgboost 2.0.3 и lightgbm 4.3.0. Для построения графиков использовались matplotlib 3.9.4 и seaborn 0.13.2.
4.1. Анализ результатов, полученных путем построения модели прогнозирования урожайности риса с использованием различных алгоритмов машинного обучения
Семь алгоритмов машинного обучения, а именно линейная регрессия, метод опорных векторов, многослойный перцептрон, случайный лес, градиентный бустинг, LightGBM и XGBoost, были использованы для построения моделей прогнозирования урожайности риса и подвергнуты сравнительному анализу.
Для достижения оптимальных результатов для каждой модели мы настроили параметры скрытого слоя алгоритма многослойного перцептрона на (100, 50, 25), установили параметр регуляризации alpha равным 0,01 и приняли параметры по умолчанию для всех остальных моделей. Кроме того, мы установили случайное начальное число random_state равным 42 для облегчения воспроизводимости экспериментальных результатов.
Согласно Таблице 4, для единичной модели машинного обучения случайный лес, LightGBM и XGBoost способны повысить производительность путем построения нескольких базовых алгоритмов, достигая похвальных результатов на тестовом наборе. Среди них модель случайного леса, благодаря своей устойчивости к переобучению и сильной обобщающей способности, демонстрирует лучшие результаты с точки зрения коэффициента детерминации и среднеквадратической ошибки. Напротив, XGBoost превосходит по метрике средней абсолютной процентной ошибки. Это указывает на то, что различные модели машинного обучения обладают своими соответствующими преимуществами, и сложно оценить превосходство среди индивидуальных моделей при использовании единичной модели в качестве модели прогнозирования урожайности риса.
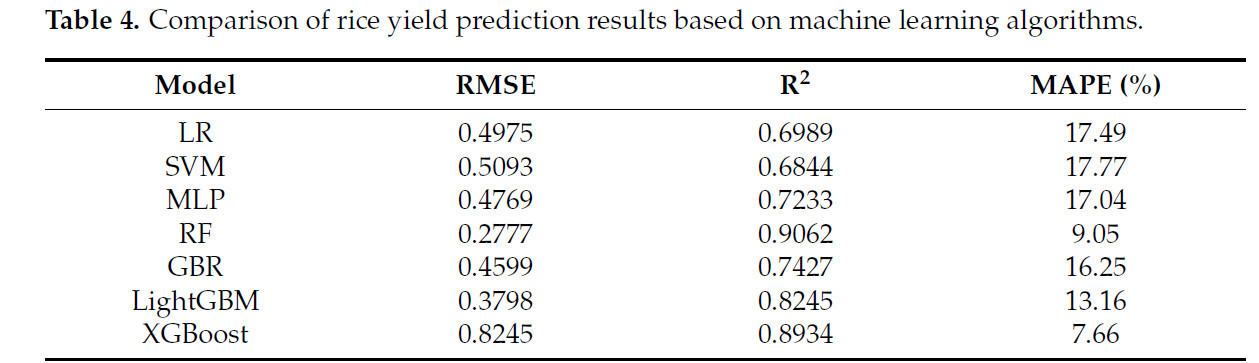
Таблица 4. Сравнение результатов прогнозирования урожайности риса на основе алгоритмов машинного обучения.
4.2. Анализ производительности модели прогнозирования урожайности риса на основе ансамблевого обучения на малой площади
Чтобы полностью использовать преимущества различных моделей машинного обучения, в этом исследовании были приняты два метода ансамбля: голосование и стекинг. Три модели машинного обучения с наивысшей точностью прогнозирования (коэффициент детерминации) (случайный лес, LightGBM, XGBoost) нацелены на получение комплексной модели с наивысшей точностью прогнозирования и наименьшей ошибкой. Для дальнейшей оптимизации эффекта интеграции, эксперимент также сравнил эффект интеграции при выборе только двух моделей с наивысшей точностью прогнозирования и выборе трех моделей, чтобы оценить влияние различных стратегий интеграции на конечную производительность модели. Результаты эксперимента показаны в Таблице 5.
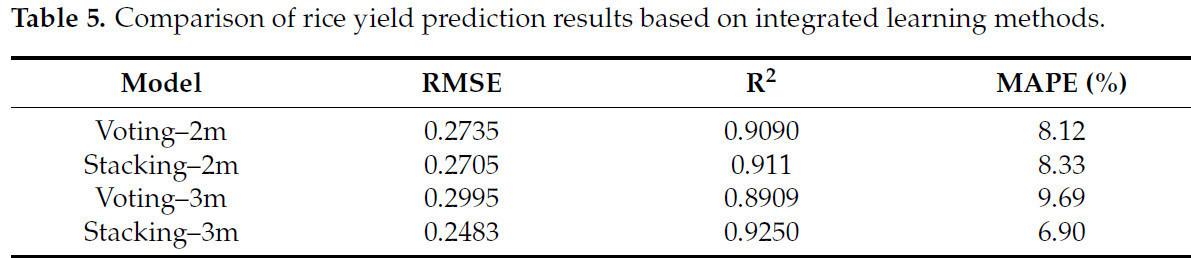
Таблица 5. Сравнение результатов прогнозирования урожайности риса на основе методов интегрированного обучения.
В Таблице 5 «2m» означает выбор первых двух моделей с наивысшей точностью, а «3m» означает выбор трех лучших моделей. Три модели, используемые для ансамбля, в порядке убывания точности: случайный лес, XGBoost и LightGBM. Среди них метод голосования после выбора двух лучших моделей с наивысшей точностью улучшил свою производительность по различным метрикам. Это связано с тем, что метод голосования получает результаты прогнозирования путем усреднения и интеграции нескольких моделей. Для метода стекинга производительность является оптимальной при выборе трех моделей, т.е. RMSE, R² и MAPE модели Stacking–3m достигли 0,2483, 0,9250 и 6,90% соответственно. По сравнению с оптимальными результатами метрик оценки в единичной модели машинного обучения, среднеквадратическая ошибка уменьшилась на 10,58%, коэффициент детерминации увеличился на 1,88%, а средняя абсолютная процентная ошибка уменьшилась на 0,76%. Модель после интеграции стекингом дальнейшим образом улучшилась на основе единичной модели. В целом, выбор подходящей модели и метода ансамбля обеспечивает лучшую точность и применимость по сравнению с единичной моделью.
4.3. Сравнительный анализ моделей прогнозирования урожайности риса на основе методов ансамблевого обучения в сравнении с подходами без ансамбля
Рисунок 6 иллюстрирует сравнение между прогнозируемыми значениями и фактическими значениями модели случайного леса и модели стекинг-ансамбля, которые демонстрируют наилучшую производительность среди единичных моделей машинного обучения, на тестовом наборе. На этом рисунке каждая точка представляет образец из тестового набора, с абсциссой, указывающей фактическое значение образца, и ординатой, указывающей прогнозируемое значение. Черная пунктирная линия представляет сценарий идеального прогнозирования, где прогнозируемые значения совпадают с фактическими значениями. При наблюдении за распределением диаграммы рассеяния становится очевидным, что, за исключением нескольких образцов с чрезмерно высокими значениями урожайности, распределение прогнозируемых точек для модели стекинг-ансамбля более сконцентрировано, чем у модели случайного леса, что указывает на то, что первая модель демонстрирует превосходную производительность в прогнозировании урожайности.
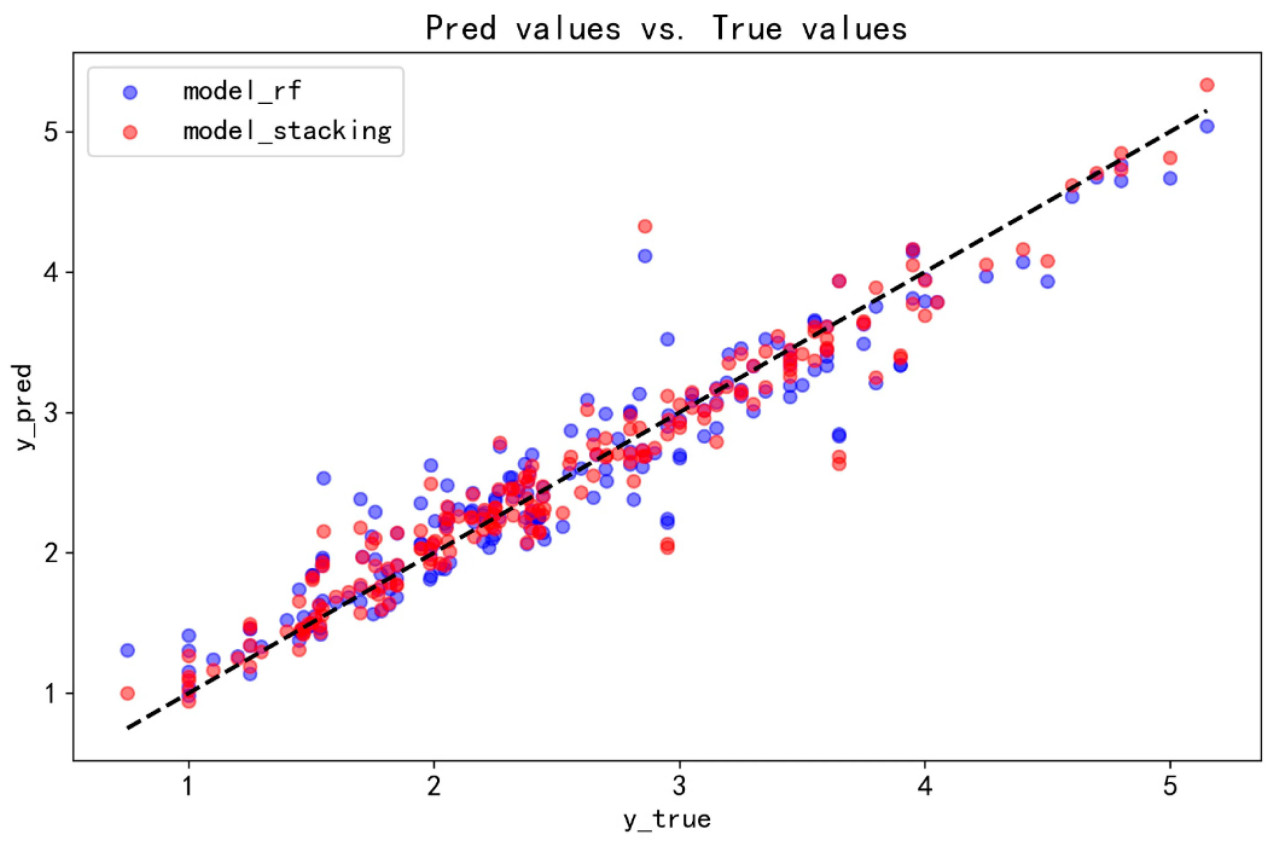
Рисунок 6. Сравнительная диаграмма результатов, полученных с моделями случайного леса и стекинг-ансамбля на тестовом наборе.
4.4. Влияние важных фенотипических характеристик на производительность интегрированных моделей
Чтобы исследовать влияние различных фенотипических признаков риса на производительность модели стекинга, в этом разделе были проведены эксперименты от единичного признака до четырех признаков. Учитывая, что выбор признаков является одним из ключевых факторов, влияющих на производительность моделей машинного обучения, этот эксперимент был направлен на оценку влияния различного количества признаков на точность прогнозирования модели, а также на определение, существует ли оптимальное подмножество признаков, которое дает наилучшую прогностическую производительность для модели. Результаты эксперимента подробно описаны на Рисунке 7.
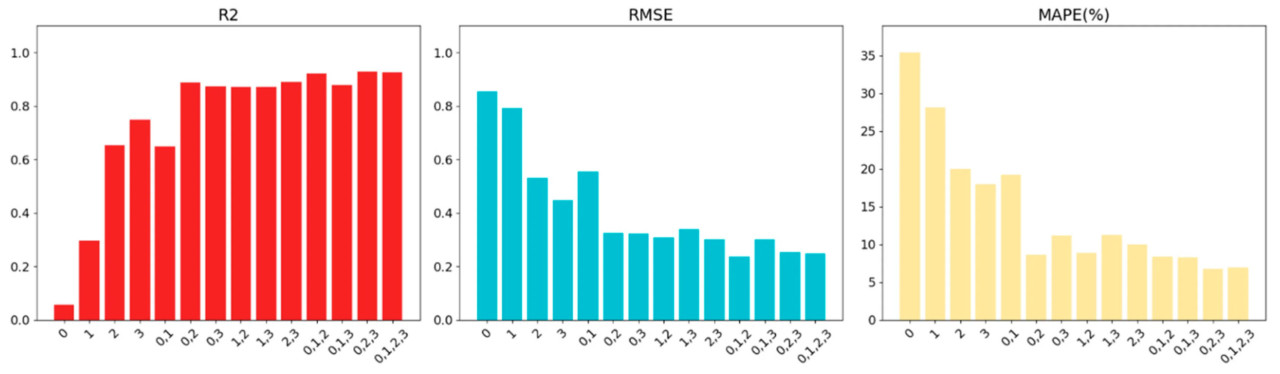
Рисунок 7. Влияние различных методов отбора признаков на результаты прогнозирования урожайности риса.
На Рисунке 7 метки «0», «1», «2» и «3» на оси x представляют четыре влияющих фактора — угол, длина колоса, общая длина ветвей и общее количество зерен — которые являются четырьмя характеристическими значениями, влияющими на урожайность. Согласно результатам эксперимента, в модели стекинга от одного признака до четырех признаков, модели с различными комбинациями признаков демонстрируют определенные различия в производительности. Когда модель включает три признака: угол (0), длина колоса (1) и общая длина ветвей (2), RMSE достигает минимального значения 0,2364; когда модель включает три признака: угол (0), общая длина ветвей (2) и общее количество зерен (3), R² достигает максимального значения 0,9291, а MAPE достигает минимального значения 6,74%. Это указывает на то, что выбор соответствующего подмножества признаков влияет на прогностическую производительность модели. По мере увеличения количества признаков метрики производительности модели не всегда монотонно возрастают. Хотя модель не продемонстрировала наилучшую производительность при включении всех четырех признаков, по сравнению с двумя другими трехпризнаковыми моделями, которые показали оптимальную производительность по определенным метрикам оценки, модель со всеми признаками показала лучший баланс по различным метрикам оценки. Это предполагает, что хотя определенные комбинации признаков могут улучшить производительность по конкретным метрикам, выбор всех признаков помогает поддерживать сбалансированную производительность модели по различным метрикам оценки.
Кроме того, результаты эксперимента показывают, что комбинация признаков, включающая угол и общую длину ветвей, продемонстрировала превосходную производительность по нескольким метрикам производительности, независимо от того, использовалась ли она отдельно или в сочетании с другими признаками. При вычислении значимости различных признаков для урожайности с использованием алгоритма случайного леса, как иллюстрировано на Рисунке 8, очевидно, что количество зерен оказывает наибольшее влияние на урожайность риса, достигая значения 0,8. Напротив, угол, длина метелки и общая длина ветвей оказывают меньшее влияние на урожайность риса, со значениями 0,063, 0,058 и 0,079 соответственно. Результаты указывают на то, что взаимодействие признаков угла и общей длины ветвей значительно влияет на прогнозирование урожайности риса. Сочетание наиболее и наименее значимых признаков может дать лучшие результаты прогнозирования.
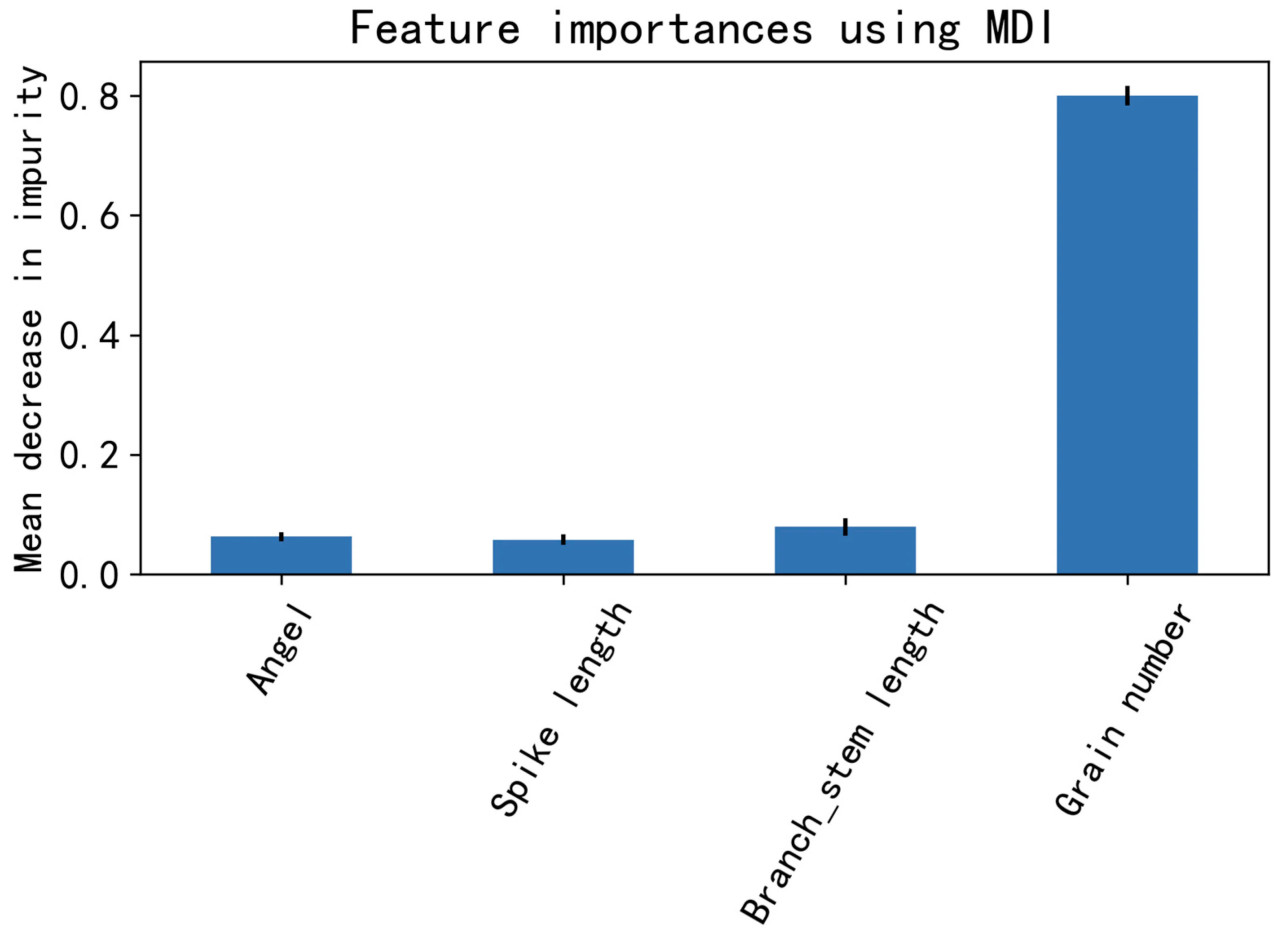
Рисунок 8. Важность признаков, рассчитанная на основе алгоритма случайного леса.
4.5. Валидация модели прогнозирования урожайности на основе фенотипических характеристик риса, выращиваемого на малых плантациях
В эксперименте по проверке урожайности на малой площади мы выбрали модель Stacking–3m, которая продемонстрировала наилучшие комплексные метрики оценки, для валидации. Вначале, после экспорта модели Stacking–3m, мы спрогнозировали значения урожайности одиночного колоса для 12 случайно выбранных образцов. Впоследствии, мы рассчитали урожайность для малой площади, умножив прогнозируемую урожайность одиночного колоса на соответствующее количество колосьев. Как иллюстрировано на Рисунке 8, метрики оценки MAE, R² и MAPE в прогнозе составили 8,3384, 0,9285 и 0,2689 соответственно. Наконец, мы сравнили прогнозируемые урожайности на малых площадях с фактическими измерениями продукции на малых площадях, как показано на Рисунке 9. Прогнозируемые значения и фактические значения были сгруппированы вокруг диагональной линии «Прогнозируемое значение = Фактическое значение». Это указывает на то, что выбранная модель Stacking–3m может достигать удовлетворительных результатов в прогнозировании урожайностей на малых площадях.
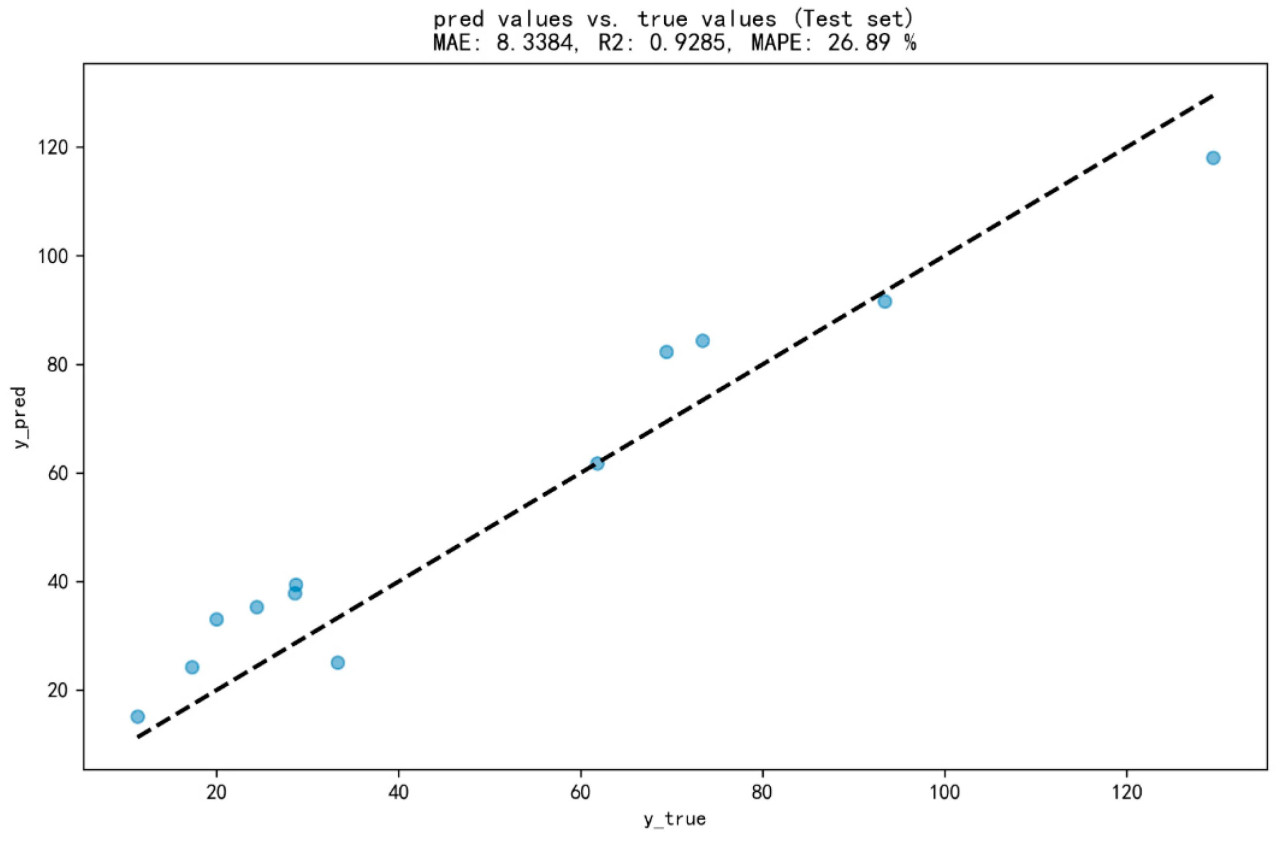
Рисунок 9. Диаграмма результатов проверки прогнозирования урожайности в малом регионе.
5. Обсуждение
5.1. Сравнительный анализ производительности различных алгоритмов машинного обучения
Результаты эксперимента, как показано на Рисунке 10, показывают, что производительность семи алгоритмов машинного обучения в построении модели прогнозирования урожайности риса значительно различается. Среди них производительность моделей случайного леса, LightGBM и XGBoost превосходит производительность моделей линейной регрессии, метода опорных векторов, многослойного перцептрона (MLP) и градиентного бустинга. Это может быть в основном связано с превосходной точностью прогнозирования ансамблевых алгоритмов на основе Bagging и Boosting, таких как случайный лес, LightGBM и XGBoost. Эти алгоритмы повышают общую прогностическую производительность путем объединения результатов прогнозирования нескольких деревьев решений с помощью различных методов, тем самым снижая риск переобучения и повышая обобщающую способность модели. Кроме того, XGBoost демонстрирует наилучшую производительность с точки зрения MAPE, возможно, из-за наличия в наборе данных определенных значений урожайности, которые встречаются чаще, чем другие. XGBoost хорошо справляется с несбалансированными наборами данных, обеспечивая точные прогнозы урожайности риса. Среди четырех других алгоритмов, используемых для построения моделей прогнозирования урожайности риса, точность моделей MLP и градиентного бустинга превосходит точность моделей линейной регрессии и метода опорных векторов. Это может быть связано с тем, что MLP способен выполнять высокоуровневую абстракцию и классификацию входных данных с помощью нескольких слоев нелинейных преобразований, что приводит к превосходной производительности модели по сравнению с обычными алгоритмами нейронных сетей. Градиентный бустинг хорошо справляется с обработкой различных типов наборов данных и особенно хорошо справляется с выбросами и шумом. Однако время вычислений модели относительно велико и склонно к переобучению. Производительность моделей линейной регрессии и метода опорных векторов относительно низкая. Это может быть связано с тем, что линейная регрессия не может хорошо аппроксимировать нелинейные данные, а производительность метода опорных векторов значительно зависит от таких параметров, как ядерная функция и штрафной коэффициент. Неподходящие значения параметров могут привести к снижению производительности модели.
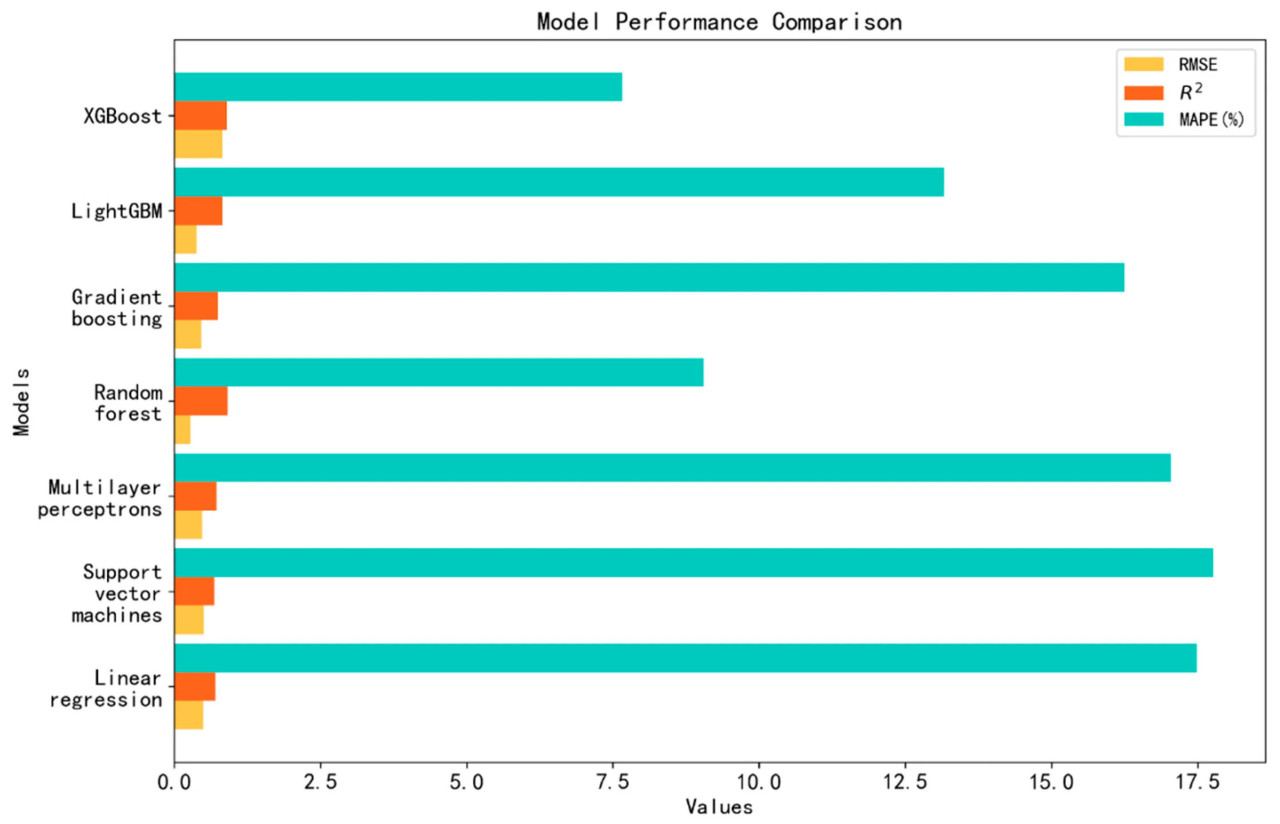
Рисунок 10. Сравнительная аналитическая диаграмма производительностей различных алгоритмов машинного обучения.
5.2. Предложен метод построения точной прогностической модели урожайности риса на основе различных влияющих факторов
В прогнозировании урожайности идеально, чтобы модель демонстрировала устойчивость и сохраняла точность прогнозирования, минимально подверженную влиянию различных факторов, особенно при прогнозировании урожайности сельскохозяйственных культур с неизвестными конкретными сортами [45,46]. Это исследование в основном рассматривает фенотипические признаки риса в качестве основных факторов, влияющих на урожайность риса, обходя влияние различных сортов риса. Конкретный подход построения включает использование собранных четырех значений фенотипических признаков в качестве влияющих факторов для интегрированной модели прогнозирования урожайности на основе значений фенотипических признаков риса. Путем выбора алгоритмов машинного обучения, построения модели, интеграции модели и сравнительного анализа мы разработали интегрированную модель Stacking–3m. Хотя производительность этой модели была относительно хорошей, не было доказано, что она является оптимальной моделью на протяжении всего эксперимента. Это в основном отражалось в невозможности определить, были ли эти четыре влияющих фактора оптимальными. Поэтому это исследование приняло метод постепенного сокращения количества влияющих факторов для корректировки различных комбинаций между ними (путем маркировки четырех влияющих факторов как «0», «1», «2» и «3»), формируя 14 различных комбинаций влияющих факторов, включая «0», «1», «2», «3», «0, 1», «0, 2», «0, 3», «1, 2», «1, 3», «2, 3», «0, 1, 2», «0, 1, 3», «0, 2, 3» и «0, 1, 2, 3». Используя эти 14 различных комбинаций в качестве влияющих факторов, мы использовали группу интегрированных моделей Stacking–3m и сравнили и проанализировали производительность этих моделей. Результаты реализации показывают, что этот метод может обойти явление влияния неразумных комбинаций влияющих факторов на производительность модели. Во время эксперимента также было обнаружено, что увеличение количества признаков не всегда улучшает производительность модели, что может быть связано с тем, что увеличение количества моделей может привести к более сложным моделям, и некоторые признаки могут оказывать негативное влияние на прогнозы модели, приводя к переобучению. Поэтому выбор подходящих значений признаков оказывает значительное влияние на улучшение прогностической производительности модели. Кроме того, комбинация значений фенотипических признаков риса, включая угол и общую длину ветвей, продемонстрировала превосходную производительность по нескольким показателям производительности. Это явление может быть связано с прямой корреляцией между этими двумя признаками и условиями роста риса и урожайностью. Величина угла значительно влияет на эффективность фотосинтеза риса, в то время как общая длина ветвей тесно связана с количеством и структурой колосьев, и то и другое играет решающую роль в конечной урожайности риса. Следовательно, их можно рассматривать как ключевые справочные показатели для прогнозирования урожайности риса.
5.3. Был предложен низкозатратный и высокоэффективный метод прогнозирования урожайности риса
Современные методы прогнозирования урожайности риса в основном основаны на прогностических моделях, построенных на основе климатических данных, мультиспектральных данных и данных со спутников. Исследователи, такие как Сынтэк Джонг [47], интегрировали глубокое обучение и технологии дистанционного зондирования, чтобы предложить модель прогнозирования урожайности риса, которая точно прогнозирует урожайность риса в регионе Корейского полуострова. Хонгкуй Чжоу и его коллеги [48] построили модель CNN–M2D для прогнозирования урожайности риса, основанную на мультиспектральных изображениях дистанционного зондирования с дронов в сочетании с алгоритмами машинного обучения и глубокого обучения. Результаты прогнозирования были следующими: RRMSE = 8,13% и R² = 0,73. Джаван Де Клерк и его коллеги [49] использовали 20-летние климатические, спутниковые данные и данные об урожайности риса из 247 рисоводческих регионов Индии, применяя 19 моделей машинного обучения для построения модели прогнозирования урожайности риса для раннего прогнозирования урожайности риса. Кроме того, Чу и Цзюн и др. [50] использовали рекуррентные нейронные сети для прогнозирования урожайности риса в 81 уезде на юге Китая. Вэйго и его коллеги [51] провели прогнозирование урожайности риса на уровне поля и уезда на основе радиолокационных данных с синтезированной апертурой (SAR), оптических и метеорологических данных. Эти исследователи в основном сосредоточились на прогнозировании урожайности риса в регионах выше уровня уезда. Модель Stacking–3m, построенная в этом исследовании, служит моделью прогнозирования урожайности риса, способной точно обнаруживать урожайность риса в пределах малой площади. Это согласуется с литературой, подчеркивающей, что моделирование машинного обучения может повысить производительность модели и превзойти стандартные модели имитации сельскохозяйственных культур [52,53,54,55]. Следовательно, это исследование заполняет пробел в построении моделей прогнозирования урожайности с использованием фенотипических данных сельскохозяйственных культур и моделирования сельскохозяйственных культур, интегрируя ансамблевые алгоритмы для построения модели Stacking–3m, решая ограничения традиционных моделей сельскохозяйственных культур с низкой производительностью из-за необходимости интеграции данных дистанционного зондирования [56,57,58]. Одновременно, многие исследования приняли методы сквозного обучения на основе эмпирических моделей для прогнозирования урожайности сельскохозяйственных культур [59,60]. Однако эти эмпирические модели часто не способны улавливать сложные процессы, влияющие на урожайность сельскохозяйственных культур [47]. Необходимо самостоятельно анализировать и тщательно записывать ключевые характеристики сельскохозяйственных культур в течение их критических стадий роста. Это исследование требовало только ввода значений фенотипических признаков риса для точного прогнозирования его урожайности. Этот подход устраняет традиционные этапы измерений, такие как обмолот, сушка, очистка и взвешивание. Кроме того, модель демонстрирует сильную практичность; чем больше объем входных данных, тем выше точность модели. После ввода различных сортов риса она может достигать точных прогнозов для урожаев различных типов риса. Наконец, масштабируемость модели является надежной, позволяя применять ее к прогнозам урожайности различных зерновых культур. Следовательно, модель Stacking–3m не только снижает затраты, связанные с традиционными методами измерения урожайности риса, но и расширяет ее применение до различных зерновых культур, эффективно решая проблемы громоздких операционных процедур, высоких затрат, длительных временных рамок, значительной рабочей нагрузки и существенных ошибок, присущих традиционным процессам прогнозирования урожайности сельскохозяйственных культур.
5.4. Ограничения и направления будущих исследований интегрированной модели прогнозирования урожайности на основе фенотипических характеристик риса
Хотя интегрированная модель Stacking–3m, построенная в этом исследовании, теоретически демонстрирует высокую точность прогнозирования, существуют определенные проблемы и затраты, связанные с получением, обработкой и анализом данных. Кроме того, данные в этом исследовании в основном происходили из сорта риса Юньнань Dianhe 615, и проверочные эксперименты также проводились с использованием этого сорта риса, посаженного нами. Для других регионов или различных сортов риса могут потребоваться целевые корректировки и оптимизации. Поэтому для следующего этапа нашего исследования мы планируем собирать значения фенотипических признаков рисовых колосьев на стадии полной зрелости из различных регионов, таких как город Чусюн и уезд Цзяньшуй, и сортов, чтобы повысить точность и практическую сферу применения модели. Далее, в процессе валидации модели мы включим фенотипические данные рисовых колосьев из различных регионов, таких как город Чусюн, и сортов, чтобы увеличить разнообразие и масштаб данных валидации, тем самым более точно оценивая производительность модели.
Кроме того, новый подход, который мы предлагаем, включает интеграцию алгоритма машинного обучения с фенотипическими данными риса для построения интеллектуальной модели. Недавние исследования поддерживают нашу точку зрения на подход к моделированию для прогнозирования урожайности риса. Например, интеграция машинного обучения с данными роста сельскохозяйственных культур повысила производительность модели, достигнув масштабируемости для разнообразных культур и сред [61,62].
Модель Stacking–3m, построенная в этом исследовании, служит оптимальной моделью для интегрированной модели на основе фенотипических характеристик риса, выращиваемого на малых площадях, для прогнозирования урожайности. Помимо демонстрации удовлетворительной производительности в прогнозировании урожайности риса, эта модель также применима к прогнозированию урожайности зерновых культур, таких как пшеница и рожь. Взяв прогнозирование урожайности пшеницы в качестве примера, мы исследуем применение модели Stacking–3m в этой области. Вначале, как только пшеница вступает в стадию зрелости, основные фенотипические характеристики (длина зерна, масса тысячи зерен, количество колосков, высота растения и т.д.), измеренные с помощью детектора фенотипов TPS–BX–1 (включая приложение «ZhiZhong»), а также вес каждого колоса, используются в качестве набора данных для моделирования. Путем включения шума из нормального распределения обобщающая способность модели в нестабильных и неоднозначных условиях улучшается, имитируя потенциальные колебания или ошибки в фактических данных для формирования тестового и проверочного наборов для моделирования. Вышеупомянутые данные вводятся в Stacking–3m для обучения, непосредственно выводя данные прогнозирования урожайности пшеницы, тем самым достигая прогнозирования урожайности пшеницы. Следовательно, модель Stacking–3m может быть широко применена к прогнозированию урожайности зерновых культур, предоставляя практичную и высоко применимую модель для фермеров и предприятий по выращиванию сельскохозяйственных культур.
Благодаря способности систем сельскохозяйственного Интернета вещей облегчать мониторинг в реальном времени, интеллектуальный контроль, удаленное управление и раннее предупреждение об аномалиях для выращиваемых культур, в сочетании со способностью анализировать и обрабатывать собранные данные для предоставления точной поддержки данных для построения интеллектуальных прогностических моделей, интеграция модели Stacking–3m, разработанной в этом исследовании, с системами сельскохозяйственного Интернета вещей может расширить практичность модели. Вначале, системы сельскохозяйственного Интернета вещей способны собирать фенотипические данные для зерновых культур, таких как пшеница и рожь, в реальном времени, позволяя осуществлять мониторинг в реальном времени за процессами роста сельскохозяйственных культур путем захвата таких параметров, как температура, влажность, влажность почвы и интенсивность света. Затем данные передаются в центр данных через беспроводные коммуникационные сети. Следовательно, мы можем дальнейшим образом увеличить параметры модели Stacking–3m, постоянно совершенствуя ее производительность. Одновременно, при построении новых моделей прогнозирования урожайности сельскохозяйственных культур мы можем напрямую строить модели с использованием наборов данных из центра данных, точно прогнозируя урожайность зерновых культур, таких как пшеница, рис и рожь.
6. Выводы
1. Производительность интегрированной модели Stacking–3m превосходит производительность индивидуальных моделей. В эксперименте с ансамблевым обучением оптимальные результаты были достигнуты при выборе трех моделей с наивысшими коэффициентами детерминации на основе метода стекинга. RMSE, R² и MAPE лучшей интегрированной модели, Stacking–3m, достигли 0,2483, 0,9250 и 6,90% соответственно. По сравнению с индивидуальными моделями, среднеквадратическая ошибка уменьшилась на 10,58%, коэффициент детерминации увеличился на 1,88%, а средняя абсолютная процентная ошибка уменьшилась на 0,76%, что указывает на значительное улучшение производительности модели. Это предполагает, что метод стекинга может эффективно сочетать сильные стороны различных моделей и дальнейшим образом улучшать прогностическую производительность с помощью мета-моделей линейной регрессии.
2. Различные влияющие факторы оказывают значительное влияние на производительность модели. В этом исследовании мы использовали метод постепенного сокращения количества влияющих факторов для корректировки различных комбинаций между ними, в конечном итоге формируя 14 различных комбинаций. На основе этих 14 различных комбинаций, когда влияющие факторы были выбраны как «1,0,2,3», RMSE, R² и MAPE достигли 0,2483, 0,9250 и 6,90% соответственно, представляя модель с оптимальной производительностью; когда влияющий фактор был выбран как «0», RMSE, R² и MAPE составили 0,8546, 0,0576 и 35,41% соответственно, что указывает на модель с наихудшей производительностью; когда влияющие факторы были выбраны как «0,2,3», значение R² достигло 0,9291, представляя оптимальное значение. Вышеупомянутые экспериментальные данные привели к следующим выводам: при построении интегрированной модели для прогнозирования урожайности риса на основе фенотипических признаков выбор различных влияющих факторов для моделирования приводит к значительным вариациям в производительности модели. Поэтому выбор подходящих влияющих факторов становится одним из наиболее ключевых аспектов в построении прогностических моделей с использованием машинного обучения.
3. Был разработан метод точного прогнозирования урожайности риса в пределах маломасштабной посадочной площади. Это исследование решает задачу точного прогнозирования урожайности риса в пределах маломасштабной посадочной площади в уникальных географических условиях плато Юньнань. Вначале, на основе семи алгоритмов машинного обучения, были построены несколько моделей прогнозирования урожайности риса с использованием интеллектуальных алгоритмов. Были выбраны три модели с наилучшей производительностью, и два метода ансамбля, а именно голосование и стекинг, были использованы для построения группы интегрированных моделей прогнозирования урожайности риса. После сравнительного анализа была определена оптимальная интегрированная модель, Stacking–3m. Впоследствии, путем корректировки различных влияющих факторов, была построена новая интегрированная модель прогнозирования урожайности риса и сравнена с Stacking–3m. Полученная модель, основанная на фенотипических признаках риса в пределах маломасштабной посадочной площади, обозначена как Stacking–3m.
Ссылки
1. Son, N.; Chen, C.; Chen, C.; Minh, V.; Trung, N. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
2. Wang, L.; Tian, Y.; Yao, X.; Zhu, Y.; Cao, W. Predicting grain yield and protein content in wheat by fusing multi-sensor and multi-temporal remote-sensing images. Field Crop. Res. 2014, 164, 178–188. [Google Scholar] [CrossRef]
3. Chou, J.; Dong, W.; Xu, G.; Tu, G. New Ideas for Research on the Impact of Climate Change on China’s Food Security. Clim. Environ. Res. 2022, 27, 206–216. (In Chinese) [Google Scholar]
4. Li, P.; Chang, T.; Chang, S.; Ouyang, X.; Qu, M.; Song, Q.; Xiao, L.; Xia, S.; Deng, Q.; Zhu, X.G. Systems model-guided rice yield improvements based on genes controlling source, sink, and flow. J. Integr. Plant Biol. 2018, 60, 1154–1180. [Google Scholar] [CrossRef] [PubMed]
5. Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating multi-source data for rice yield prediction across China using machine learning and deep learning approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
6. Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
7. Sun, S.; Zhang, L.; Chen, Z.; Sun, J. Advances in AquaCrop Model Research and Application. Sci. Agric. Sin. 2017, 50, 3286–3299. [Google Scholar]
8. Noureldin, N.; Aboelghar, M.; Saudy, H.; Ali, A. Rice yield forecasting models using satellite imagery in Egypt. Egypt J. Remote Sens. Space Sci. 2013, 16, 125–131. [Google Scholar] [CrossRef]
9. Peng, D.; Huang, J.; Li, C.; Liu, L.; Huang, W.; Wang, F.; Yang, X. Modelling paddy rice yield using MODIS data. Agric. For. Meteorol. 2014, 184, 107–116. [Google Scholar] [CrossRef]
10. Wang, F.; Yi, Q.; Hu, J.; Xie, L.; Yao, X.; Xu, T.; Zheng, J. Combining spectral and textural information in UAV hyperspectral images to estimate rice grain yield. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102397. [Google Scholar] [CrossRef]
11. Zhou, X.; Zheng, H.; Xu, X.; He, J.; Ge, X.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Predicting grain yield in rice using multi-temporal vegetation indices from UAV-based multispectral and digital imagery. ISPRS J. Photogramm. Remote Sens. 2017, 130, 246–255. [Google Scholar] [CrossRef]
12. Ji, Z.; Pan, Y.; Zhu, X.; Zhang, D.; Wang, J. A generalized model to predict large-scale crop yields integrating satellite-based vegetation index time series and phenology metrics. Ecol. Indic. 2022, 137, 108759. [Google Scholar] [CrossRef]
13. Meng, L.; Liu, H.; Zhang, X.; Ren, C.; Ustin, S.; Qiu, Z.; Xu, M.; Guo, D. Assessment of the effectiveness of spatiotemporal fusion of multi-source satellite images for cotton yield estimation. Comput. Electron. Agric. 2019, 162, 44–52. [Google Scholar] [CrossRef]
14. Wu, G.; De Leeuw, J.; Skidmore, A.K.; Prins, H.H.; Liu, Y. Exploring the Possibility of Estimating the Aboveground Biomass of Vallisneria spiralis L. In Using Landsat TM Image in Dahuchi, Jiangxi Province, China, Proceedings of the MIPPR 2005: Geospatial Information, Data Mining, and Applications, Wuhan, China, 2 December 2005; SPIE: Bellingham, WA, USA, 2005; pp. 800–810. [Google Scholar]
15. Wang, Z.; Ma, Y.; Chen, P.; Yang, Y.; Fu, H.; Yang, F.; Raza, M.A.; Guo, C.; Shu, C.; Sun, Y. Estimation of rice aboveground biomass by combining canopy spectral reflectance and unmanned aerial vehicle-based red green blue imagery data. Front. Plant Sci. 2022, 13, 903643. [Google Scholar] [CrossRef] [PubMed]
16. Hosoi, F.; Umeyama, S.; Kuo, K. Estimating 3D chlorophyll content distribution of trees using an image fusion method between 2D camera and 3D portable scanning lidar. Remote Sens. 2019, 11, 2134. [Google Scholar] [CrossRef]
17. Su, W.; Sun, Z.; Chen, W.-h.; Zhang, X.; Yao, C.; Wu, J.; Huang, J.; Zhu, D. Joint retrieval of growing season corn canopy LAI and leaf chlorophyll content by fusing Sentinel–2 and MODIS images. Remote Sens. 2019, 11, 2409. [Google Scholar] [CrossRef]
18. Zhang, H.; Ge, Y.; Xie, X.; Atefi, A.; Wijewardane, N.K.; Thapa, S. High throughput analysis of leaf chlorophyll content in sorghum using RGB, hyperspectral, and fluorescence imaging and sensor fusion. Plant Methods 2022, 18, 60. [Google Scholar] [CrossRef]
19. Wan, L.; Cen, H.; Zhu, J.; Zhang, J.; Zhu, Y.; Sun, D.; Du, X.; Zhai, L.; Weng, H.; Li, Y. Grain yield prediction of rice using multi-temporal UAV-based RGB and multispectral images and model transfer—A case study of small farmlands in the South of China. Agric. For. Meteorol. 2020, 291, 108096. [Google Scholar] [CrossRef]
20. Wang, J.; He, P.; Liu, Z.; Jing, Y.; Bi, R. Yield estimation of summer maize based on multi-source remote-sensing data. Agron. J. 2022, 114, 3389–3406. [Google Scholar] [CrossRef]
21. Wang, Z.; Chen, J.; Zhang, J.; Fan, Y.; Cheng, Y.; Wang, B.; Wu, X.; Tan, X.; Tan, T.; Li, S. Predicting grain yield and protein content using canopy reflectance in maize grown under different water and nitrogen levels. Field Crop. Res. 2021, 260, 107988. [Google Scholar] [CrossRef]
22. Cao, J.; Wang, H.; Li, J.; Tian, Q.; Niyogi, D. Improving the forecasting of winter wheat yields in Northern China with machine learning-dynamical hybrid subseasonal-to-seasonal ensemble prediction. Remote Sens. 2022, 14, 1707. [Google Scholar] [CrossRef]
23. Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine learning applications for precision agriculture: A comprehensive review. IEEE Access 2020, 9, 4843–4873. [Google Scholar] [CrossRef]
24. Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
25. Zhang, S.; Zhang, C.; Park, D.S.; Yoon, S. Machine Learning and Artificial Intelligence for Smart Agriculture; Frontiers Media SA: Lausanne, Switzerland, 2023; Volume 14, p. 1166209. [Google Scholar]
26. González Sánchez, A.; Frausto Solís, J.; Ojeda Bustamante, W. Predictive ability of machine learning methods for massive crop yield prediction. Span. J. Agric. Res. 2014, 12, 313–328. [Google Scholar] [CrossRef]
27. Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
28. Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
29. Yamparla, R.; Shaik, H.S.; Guntaka, N.S.P.; Marri, P.; Nallamothu, S. Crop Yield Prediction Using Random Forest Algorithm. In Proceedings of the 2022 7th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 22–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 1538–1543. [Google Scholar]
30. Paudel, D.; Boogaard, H.; de Wit, A.; van der Velde, M.; Claverie, M.; Nisini, L.; Janssen, S.; Osinga, S.; Athanasiadis, I.N. Machine learning for regional crop yield forecasting in Europe. Field Crop. Res. 2022, 276, 108377. [Google Scholar] [CrossRef]
31. Drummond, S.T.; Sudduth, K.A.; Joshi, A.; Birrell, S.J.; Kitchen, N.R. Statistical and neural methods for site-specific yield prediction. Trans. ASAE 2003, 46, 5. [Google Scholar] [CrossRef]
32. Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef]
33. Mupangwa, W.; Chipindu, L.; Nyagumbo, I.; Mkuhlani, S.; Sisito, G. Evaluating machine learning algorithms for predicting maize yield under conservation agriculture in Eastern and Southern Africa. SN Appl. Sci. 2020, 2, 952. [Google Scholar] [CrossRef]
34. Uyanık, G.K.; Güler, N. A study on multiple linear regression analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef]
35. Tranmer, M.; Elliot, M. Multiple linear regression. Cathie Marsh Cent. Census Surv. Res. (CCSR) 2008, 5, 1–5. [Google Scholar]
36. Jobson, J.; Jobson, J. Multiple linear regression. In Applied Multivariate Data Analysis: Regression and Experimental Design; Springer: New York, NY, USA, 1991; pp. 219–398. [Google Scholar]
37. Suthaharan, S.; Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
38. Popescu, M.-C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
39. Delashmit, W.H.; Manry, M.T. Recent developments in multilayer perceptron neural networks. In Proceedings of the Seventh Annual Memphis Area Engineering and Science Conference, MAESC, Memphis, TN, USA, 11 May 2005; p. 33. [Google Scholar]
40. Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
41. Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
42. Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
43. Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
44. Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; p. 30. [Google Scholar]
45. Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
46. Vasit, S.; Maitiniyazi, M.; Sourav, B.; Matthew, M.; Brown, D.R.; Paheding, S.; Fritschi, F.B. Field-scale crop yield prediction using multi-temporal WorldView–3 and PlanetScope satellite data and deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 174, 265–281. [Google Scholar]
47. Jeong, S.; Ko, J.; Ban, J.-o.; Shin, T.; Yeom, J.-m. Deep learning-enhanced remote sensing-integrated crop modeling for rice yield prediction. Ecol. Inform. 2024, 84, 102886. [Google Scholar] [CrossRef]
48. Zhou, H.; Huang, F.; Lou, W.; Gu, Q.; Ye, Z.; Hu, H.; Zhang, X. Yield prediction through UAV-based multispectral imaging and deep learning in rice breeding trials. Agric. Syst. 2025, 223, 104214. [Google Scholar] [CrossRef]
49. Clercq, D.D.; Mahdi, A. Feasibility of machine learning-based rice yield prediction in India at the district level using climate reanalysis and remote sensing data. Agric. Syst. 2024, 220, 104099. [Google Scholar] [CrossRef]
50. Rußwurm, M.; Courty, N.; Emonet, R.; Lefèvre, S.; Tuia, D.; Tavenard, R. End-to-end learned early classification of time series for in-season crop type mapping. ISPRS J. Photogramm. Remote Sens. 2023, 196, 445–456. [Google Scholar] [CrossRef]
51. Weiguo, Y.; Gaoxiang, Y.; Dong, L.; Hengbiao, Z.; Xia, Y.; Yan, Z.; Weixing, C.; Lin, Q.; Tao, C. Improved prediction of rice yield at field and county levels by synergistic use of SAR, optical and meteorological data. Agric. For. Meteorol. 2023, 342, 109729. [Google Scholar]
52. Nishu, B.; Anshu, S. Deep Learning Based Wheat Crop Yield Prediction Model in Punjab Region of North India. Appl. Artif. Intell. 2021, 35, 1304–1328. [Google Scholar]
53. Debaditya, G.; Nihal, G.; Siddhartha, S.; Sudip, M. Role of existing and emerging technologies in advancing climate-smart agriculture through modeling: A review. Ecol. Inform. 2022, 71, 101805. [Google Scholar]
54. Jeong, S.; Ko, J.; Yeom, J.-M. Predicting rice yield at pixel scale through synthetic use of crop and deep learning models with satellite data in South and North Korea. Sci. Total Environ. 2022, 802, 149726. [Google Scholar] [CrossRef]
55. Yang, S.; Li, L.; Fei, S.; Yang, M.; Tao, Z.; Meng, Y.; Xiao, Y. Wheat Yield Prediction Using Machine Learning Method Based on UAV Remote Sensing Data. Drones 2024, 8, 284. [Google Scholar] [CrossRef]
56. Seungtaek, J.; Jonghan, K.; Taehwan, S.; Min, Y.J. Incorporation of machine learning and deep neural network approaches into a remote sensing-integrated crop model for the simulation of rice growth. Sci. Rep. 2022, 12, 9030. [Google Scholar]
57. Joshi, A.; Pradhan, B.; Gite, S.; Chakraborty, S. Remote-sensing data and deep-learning techniques in crop mapping and yield prediction: A systematic review. Remote Sens. 2023, 15, 2014. [Google Scholar] [CrossRef]
58. Shafi, U.; Mumtaz, R.; Anwar, Z.; Ajmal, M.M.; Khan, M.A.; Mahmood, Z.; Qamar, M.; Jhanzab, H.M. Tackling food insecurity using remote sensing and machine learning based crop yield prediction. IEEE Access 2023, 11, 108640–108657. [Google Scholar] [CrossRef]
59. Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A review of the challenges of using deep learning algorithms to support decision-making in agricultural activities. Remote Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
60. Pandya, P.; Gontia, N.K. Early crop yield prediction for agricultural drought monitoring using drought indices, remote sensing, and machine learning techniques. J. Water Clim. Chang. 2023, 14, 4729–4746. [Google Scholar] [CrossRef]
61. Sunitha, D.B.; Sandhya, N.; Shahu, C.K. Hybrid deep WaveNet–LSTM architecture for crop yield prediction. Multimed. Tools Appl. 2023, 83, 19161–19179. [Google Scholar]
62. Alexandros, O.; Cagatay, C.; Ayalew, K. Hybrid Deep Learning-based Models for Crop Yield Prediction. Appl. Artif. Intell. 2022, 36, 2031822. [Google Scholar]

Sun J, Tian P, Li Z, Wang X, Zhang H, Chen J, Qian Y. Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations. Agriculture. 2025; 15(2):181. https://doi.org/10.3390/agriculture15020181
Перевод статьи «Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations» авторов Sun J, Tian P, Li Z, Wang X, Zhang H, Chen J, Qian Y., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)