Сегментация и анализ томатов: алгоритм ES-RBMO для 3D-фенотипирования
В связи с изменениями в структуре рассады томатов традиционные методы визуализации с трудом позволяют точно количественно оценить ключевые морфологические параметры, такие как площадь листа, длина междоузлий и взаимное затенение органов. Поэтому в данной работе предлагается структура сегментации стебля и листьев томата на основе облака точек, построенная с использованием алгоритма оптимизации ES-RBMO (Elite Strategy-based Improved Red-billed Blue Magpie).
Аннотация
Данная методология использует четырехслойную сверточную нейронную сеть (CNN) для сегментации стеблей и листьев, интегрируя улучшенный алгоритм роевого интеллекта, с точностью 0,965. Были извлечены четыре ключевых фенотипических параметра растения. Путем сравнения значений, полученных ручными измерениями, со значениями, извлеченными с помощью 3D-технологии облака точек, были проанализированы фенотипические параметры: высота растения, толщина стебля, площадь листа и угол наклона листа. Результаты показали, что коэффициенты детерминации (R²) для этих параметров составили 0,932, 0,741, 0,938 и 0,935 соответственно, что указывает на высокую корреляцию. Среднеквадратическая ошибка (RMSE) составила 0,511, 0,135, 0,989 и 3,628, что отражает уровень расхождения между измеренными и извлеченными значениями. Абсолютные процентные ошибки (APE) составили 1,970, 4,299, 4,365 и 5,531, что дополнительно количественно оценивает точность измерений. В данном исследовании был создан эффективный и адаптивный интеллектуальный оптимизационный каркас, способный оптимизировать стратегии обработки данных для достижения эффективной и точной обработки данных облака точек томата. Это исследование предоставляет новый технический инструмент для фенотипирования растений и способствует повышению уровня интеллектуального управления в сельскохозяйственном производстве.
1. Введение
В контексте современных исследований в области сельскохозяйственных наук, структурный анализ растений томата является ключевым компонентом для понимания их роста и привычек развития, оптимизации практик культивирования и управления, а также улучшения конечной урожайности культур [1]. Используя наборы данных в виде облака точек, полученные с помощью высокоточных камер глубины, мы можем достичь точной реконструкции трехмерной морфологии растений томата, которая включает детальное пространственное расположение компонентов, таких как стебли, листья и ветви, а также количественное описание их геометрических особенностей. Однако обработка данных облака точек не является безупречной и часто сталкивается с такими проблемами, как окклюзия данных, шумовое загрязнение и разреженность данных [2]. Эти неблагоприятные факторы могут привести к частичной потере информации и снижению точности сегментации. В условиях активного развития технологии глубокого обучения то, как добиться точной сегментации структуры стеблей и листьев растения томата на основе данных облака точек и эффективно извлечь геометрическую информацию, стало центром внимания и горячей темой исследований в этой области [3].
В настоящее время распространенную сегментацию стеблей и листьев в области растений можно разделить на три типа: обучение с учителем, обучение без учителя и обучение со слабым учителем. Обучение с учителем достигает эффективного извлечения признаков и точной сегментации данных облака точек структуры растения через модели глубокого обучения, которые полагаются на полностью размеченные данные для обучения. Исследователи добились автоматической идентификации ключевых признаков во входном облаке точек и выполнили точную сегментацию органов растения путем обучения глубоких нейронных сетей. В последние годы глубокие сети на основе семантической сегментации продемонстрировали отличную производительность в сельском хозяйстве, особенно в таких задачах, как сегментация видов культур и разметка площадей полей, с заметно улучшенной точностью. Тем временем, техники обнаружения объектов также добились прорывов в сельскохозяйственных приложениях, например, в задачах идентификации болезней и подсчета плодов, методы, такие как YOLO и Faster R-CNN, получили широкое распространение, демонстрируя чрезвычайно высокую эффективность и точность [4,5,6]. В дополнение, применение методов слияния мультимодальных данных, таких как комбинирование данных дистанционного зондирования, изображений с БПЛА и гиперспектральных данных [7], предоставляет более всестороннюю и богатую поддержку для классификации и сегментации в сельском хозяйстве. Эти методы предоставляют техническую основу для интеллектуализации сельского хозяйства [8]. Lou L и др. предложили новую систему со слабым учителем Eff-3DPSeg для 3D сегментации почек растений [9]. Этот метод комбинирует глубокое обучение и техники работы с облаками точек для решения задач 3D сегментации почек растений. Wang, Y и др. достигли эффективной сегментации стеблей и листьев растений томата, комбинируя извлечение скелета с методами кластеризации восходящих пикселей, что позволило добиться определенной точности сегментации [10]. Xusheng Zhong использовал Графовую Сверточную Нейронную Сеть (GCNN) в качестве базовой структуры для исследования сегментации облаков точек растений. В исследовании использовалось 864 набора данных облаков точек растений в качестве датасета и была проверена производительность модели [11]. Эти методы основаны на способности глубокого обучения к изучению признаков и оптимизации моделей для обработки сложных данных и повышения точности сегментации.
Обучение без учителя не использует никаких размеченных данных, а ищет закономерности в данных [12]. Предобученные модели или методы машинного обучения могут автономно извлекать признаки из крупномасштабных неразмеченных данных облака точек и обрабатывать и анализировать данные облака точек, используя алгоритмы, такие как кластеризация и снижение размерности [13,14,15,16]. Miao, T и др. предложили автоматизированный метод сегментации стеблей и листьев побегов кукурузы на основе 3D облака точек. Метод использовал информацию о скелете в качестве априорного знания для помощи в сегментации облака точек и реализовал автоматизированный процесс сегментации [17]. Обучение со слабым учителем использует частично размеченные данные для направления обучения модели, что подходит для тех сценариев, где ресурсы для разметки ограничены, но все еще необходима контролирующая информация [18]. Wu J и др. предложили метод семантической сегментации 3D облака точек со слабым учителем (WS3DSS), который направлен на разработку устойчивой модели, способной обучаться на ограниченных размеченных данных и эффективно использовать неразмеченные данные для повышения производительности сегментации [19]. Однако обучение без учителя не имеет информации о разметке, и обученная модель может быть неприменима напрямую к конкретным задачам классификации или регрессии с ограниченным повышением производительности и низкой точностью. Обучение со слабым учителем может быть недостаточным для эффективного направления обучения модели из-за неполной или неопределенной информации разметки, что влияет на точность и стабильность результатов сегментации [20,21,22].
Был направлен на решение проблем, с которыми сталкивается текущая сегментация, в данной статье предлагается алгоритм оптимизации ES-RBMO, который направлен на решение следующих проблем:
1. Модели глубокого обучения в целом имеют проблему большого размера параметров. Хотя потребность в вычислительных ресурсах может быть значительно снижена с помощью методов облегчения модели, этот процесс часто приводит к снижению производительности модели, то есть потере точности, что влияет на точность конечных результатов сегментации.
2. Точность сегментации некоторых моделей глубокого обучения показывает определенную степень нестабильности в сложных условиях, и эта нестабильность ограничивает применимость модели в практических сценариях применения, затрудняя удовлетворение потребности в высоконадежных результатах сегментации в сельскохозяйственном производстве.
Был направлен на текущие проблемы, данная статья направлена на предложение метода, который все еще может получать высокую точность сегментации при меньшем количестве сверточных слоев и меньшем числе параметров. Для достижения этой цели в данном исследовании приняты следующие стратегии:
1. Алгоритм RBMO оптимизируется с использованием элитной стратегии для улучшения стабильности и поисковой способности алгоритма. Элитная стратегия улучшает общую производительность алгоритма, сохраняя лучших особей в последовательных поколениях и направляя эволюцию алгоритма к лучшим решениям.
2. Оптимизированный алгоритм RBMO интегрирован с моделью сети глубокого обучения для оптимизации эффекта сегментации стеблей и листьев растений томата. Эта стратегия интеграции направлена на обеспечение устойчивости модели при работе со сложными данными облака точек, одновременно снижая зависимость от большого количества параметров.
3. Алгоритм инкапсулирует настроенные сверточные слои путем комбинирования геометрических признаков и признаков кривизны данных облака точек. Этот подход делает модель сети более адаптированной к характеристикам обработки пространственных 3D данных, тем самым повышая способность распознавания деталей структуры растений при сохранении облегченности модели.
2. Материалы и методы
2.1. Источники данных и сбор
В четвертой теплице Научно-исследовательского института овощей и цветов провинции Цзилинь в данном исследовании было установлено пять независимых растущих блоков с единообразными условиями культивирования во всех блоках. В каждом блоке было выращено девяносто шесть растений томата, а общий размер выборки составил 480 растений. Внутри этих блоков растения были расположены в два ряда с междурядьем 0,1 м, в то время как длина ряда составляла 2,4 м (Рисунок 1a). Внутри одного ряда расстояние между растениями составляло приблизительно 0,05 м. Для получения 3D структурных данных растений томата использовалось устройство 3DScanner-630w (погрешность измерения размера: 0.001~0.03 мм; максимальное разрешение объектива: 6.3 мегапикселя) для сбора данных облака точек (Рисунок 1b,c). Во время процесса сбора уделялось особое внимание избеганию влияния теней и отражений для обеспечения целостности данных. Предварительная обработка полученных данных изображения выполнялась с помощью программного обеспечения CloudCompare версии 2.14. С использованием масштабирования, шумоподавления и усиления деталей было окончательно получено 8640 файлов облака точек. Датасет разделен в соотношении 7:2:1. В конечном итоге, предварительно обработанные данные изображения были визуализированы и отображены в 3D с помощью языка программирования Python (Рисунок 1d).
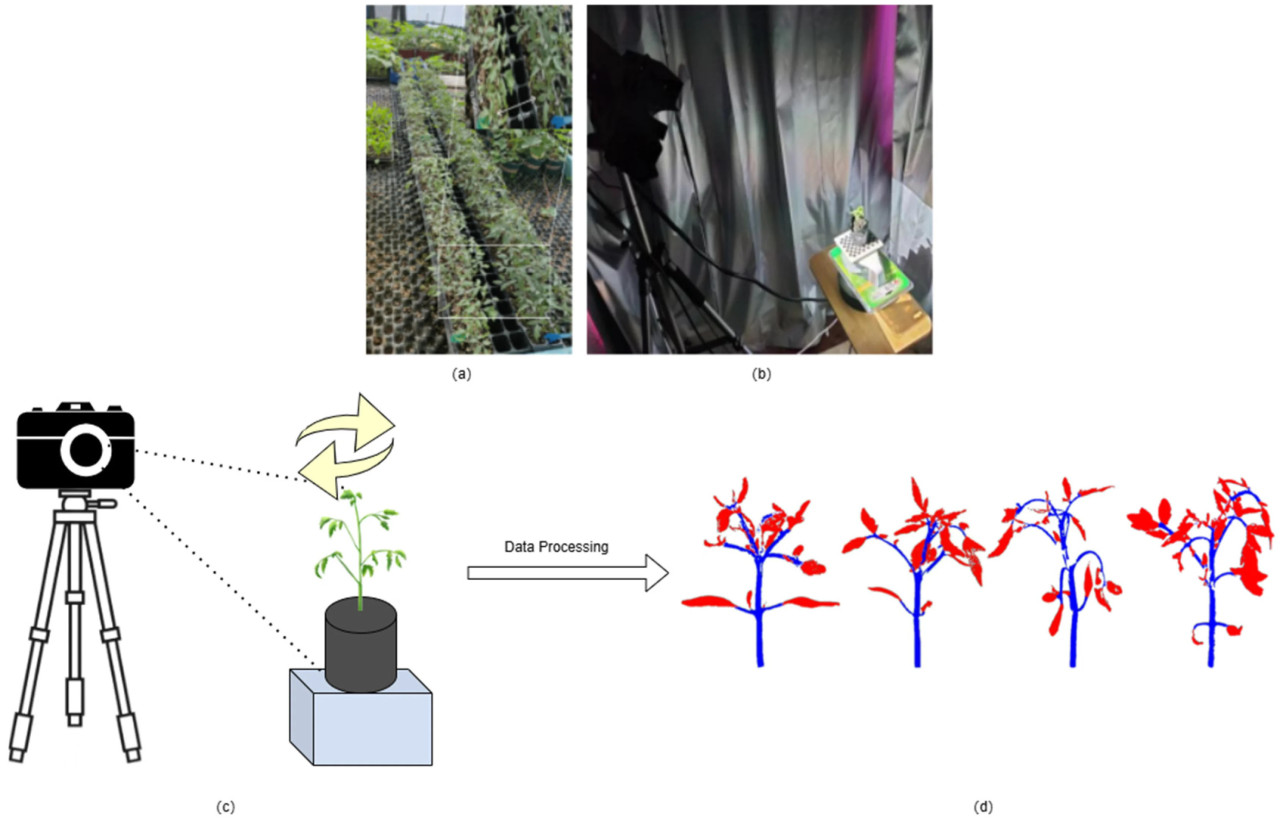
Рисунок 1. Метод получения изображений. (a) Образец растения томата. Получение данных облака точек; (b) Сцена получения данных облака точек; (c) Получение данных облака точек; (d) Визуализация предварительно обработанного изображения.
2.2. Методологии
2.2.1. Алгоритмические принципы алгоритма RBMO с оптимизацией элитной стратегией
Алгоритм оптимизации RBMO на основе элитной стратегии (ES-RBMO) оптимизирует красноклювую синюю сороку, моделируя ее поведение при поиске пищи в гиперпараметрическом пространстве сетей глубокого обучения [23,24,25]. Элитная стратегия эффективно избегает попадания в локальный оптимум, сохраняя текущее оптимальное решение и отдавая приоритет использованию его информации для последующих поисков.
Каждая особь (птица) представляет конфигурацию модели глубокого обучения. В данной статье размер популяции был установлен на 50. Предполагая, что модель глубокого обучения имеет несколько гиперпараметров, {θ1,θ2,…,θk}, положение каждой особи может быть представлено как:
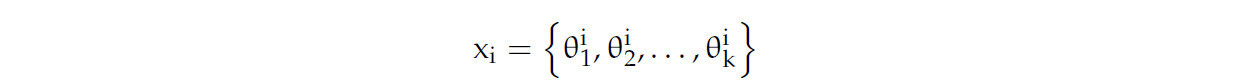
где θij обозначает значение измерения j i-й особи (решения) в гиперпараметрическом пространстве (например, скорость обучения, количество слоев сети и т.д.).
Фитнес-функция является количественной формой цели оптимизации, и мы вычисляем приспособленность особи на основе точности, полноты, точности позитивного прогноза, F1-меры и IoU. Пусть Fi обозначает значение приспособленности i-й особи, мы определяем взвешенную фитнес-функцию как:
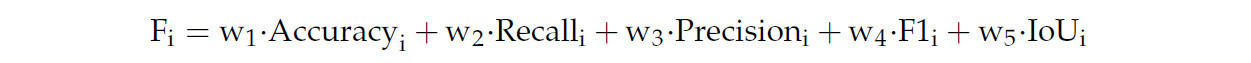
где, Accuracyi, Recalli, Precisioni, F1i, IoUi обозначает каждый показатель производительности модели, соответствующей i-й особи, соответственно. w1, w2, w3, w4, w5 — это вес каждого показателя, установка весового соотношения 1:1:1:1:1 обеспечивает равный вклад каждого показателя производительности в общую оценку, тем самым предоставляя объективный подход к оценке модели. Такая настройка весов является беспристрастной среди различных показателей и подходит для сценариев, в которых нет четкого предпочтения конкретному показателю. И она удовлетворяет условию w1+w2+w3+w4+w5=1.
Основой алгоритма оптимизации RBMO является поиск лучшего решения путем обновления особей с помощью следующих правил обновления:
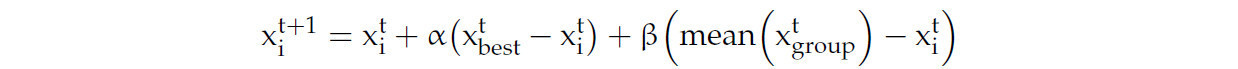
xt+1i указывает на i-ю особь в позиции t+1. xti указывает на i-ю особь в позиции t. xtbest — это элитная особь с наилучшей приспособленностью в текущей популяции. mean(xtgroup) — это среднее значение позиций всех особей в текущей популяции. α и β — это коэффициенты шага для глобального и локального поиска, соответственно.
Элитная стратегия путем выбора наиболее приспособленных Nelite особей сохраняет ее решение и передает его напрямую следующему поколению. Этот механизм помогает алгоритму удерживать поиск в окрестности оптимального решения и избегать попадания в локальные оптимумы.
В то время как локальный поиск выполняет тщательный поиск в окрестности текущего решения для оптимизации качества решения через незначительные корректировки, прыжковый поиск смело исследует большее пространство поиска путем случайной корректировки позиции особей с целью найти глобальные оптимальные решения, которые могли быть упущены [26,27]. С этой стратегией алгоритм RBMO не только способен точно выполнять локальную оптимизацию при обработке данных облака точек, но и сохраняет жизнеспособность глобального поиска, обеспечивая хорошую производительность алгоритма в таких сложных задачах, как выравнивание облаков точек, распознавание форм и другие [28]. Сохраняя элитные особи с наивысшей приспособленностью, алгоритм обеспечивает постоянное удержание оптимального решения в процессе итерации, что повышает общую эффективность поиска и качество решения [29].
Локальный поиск оптимизирует решение, внося небольшие корректировки на основе приспособленности текущей позиции особи. Например, исследуются лучшие решения внутри окрестности через операции мутации [30]:
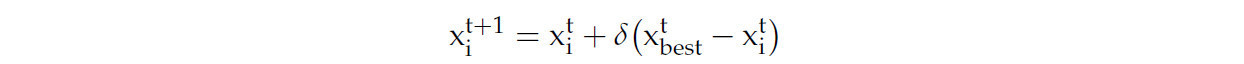
𝛿 — это небольшая константа, контролирующая шаг корректировки.
Прыжковый поиск [31], по-видимому, более агрессивно применяется в алгоритме RBMO, который исследует области в пространстве решений, далекие от текущего местоположения популяции, путем увеличения размера шага поиска, таким образом потенциально обнаруживая лучшее решение [32]. В каждом поколении алгоритма мы обновляем позицию популяции на основе значения приспособленности каждой особи и генерируем новых особей. В этом процессе мы используем элитную стратегию, т.е. сохраняем особей с наилучшей приспособленностью как элиту, и эти элитные особи не будут исключаться, чтобы гарантировать, что алгоритм может поддерживать наследование оптимального решения в процессе итерации [33]. Применяя этот алгоритм RBMO, оптимизированный элитной стратегией, к обработке данных облака точек, можно более эффективно исследовать и использовать пространство решений, а также повысить эффективность и точность выравнивания облаков точек и оптимизации формы [34,35,36,37,38].
Условия завершения алгоритма включают следующие три аспекта: во-первых, когда алгоритм достигает предопределенного максимального числа итераций, процесс поиска автоматически останавливается; во-вторых, если изменение приспособленности оптимального решения меньше определенного установленного порога в течение нескольких последовательных поколений, это указывает на то, что алгоритм сошелся, и итерация также будет завершена в этот момент [39,40,41,42]; наконец, если значение приспособленности оптимального решения превышает предопределенный порог, это означает, что алгоритм нашел удовлетворительное решение и поэтому остановится досрочно [43,44]. С этой стратегией оптимизации мы применяем алгоритм RBMO к обработке данных облака точек для достижения более эффективного и точного поиска и сопоставления.
2.2.2. Алгоритмические принципы 3DCNN
3DCNN интегрирует геометрические свойства и свойства кривизны данных облака точек для построения четырехслойной архитектуры глубокого обучения путем инкапсуляции настроенных сверточных слоев [45]. Инкапсулируется сверточный слой CustomConv3D путем комбинирования признаков кривизны и геометрических признаков облака точек. Первый сверточный слой этой сети, conv1, использует сверточное ядро 3 × 3 × 3 для извлечения признаков из одноканальных входных данных, что обеспечивает отображение из исходных данных в 64-мерное пространство признаков и ускоряет сходимость и стабилизирует обучение через операцию пакетной нормализации в слое bn1 [46]. Conv2 со слоем bn2 расширяет размерность признаков до 128 измерений, что усиливает абстрактное представление признаков. Conv3 со слоями bn3 отображает признаки в 256 измерений для захвата структурной информации более высокого уровня. Дополнительные слои conv4 & bn4 обеспечивают более глубокое извлечение признаков, повышая 256-мерные признаки до 512 измерений, что заметно улучшает способность модели к моделированию и распознаванию сложных пространственных признаков [47], как показано на Рисунке 2. Этот метод эффективно извлекает и абстрагирует богатую геометрическую и структурную информацию из данных облака точек путем увеличения размерности признаков слой за слоем, что значительно улучшает способность модели к моделированию и распознаванию сложных 3D форм; одновременно, в сочетании с пакетной нормализацией, он оптимизирует процесс обучения, ускоряет скорость сходимости и повышает обобщающую способность модели.
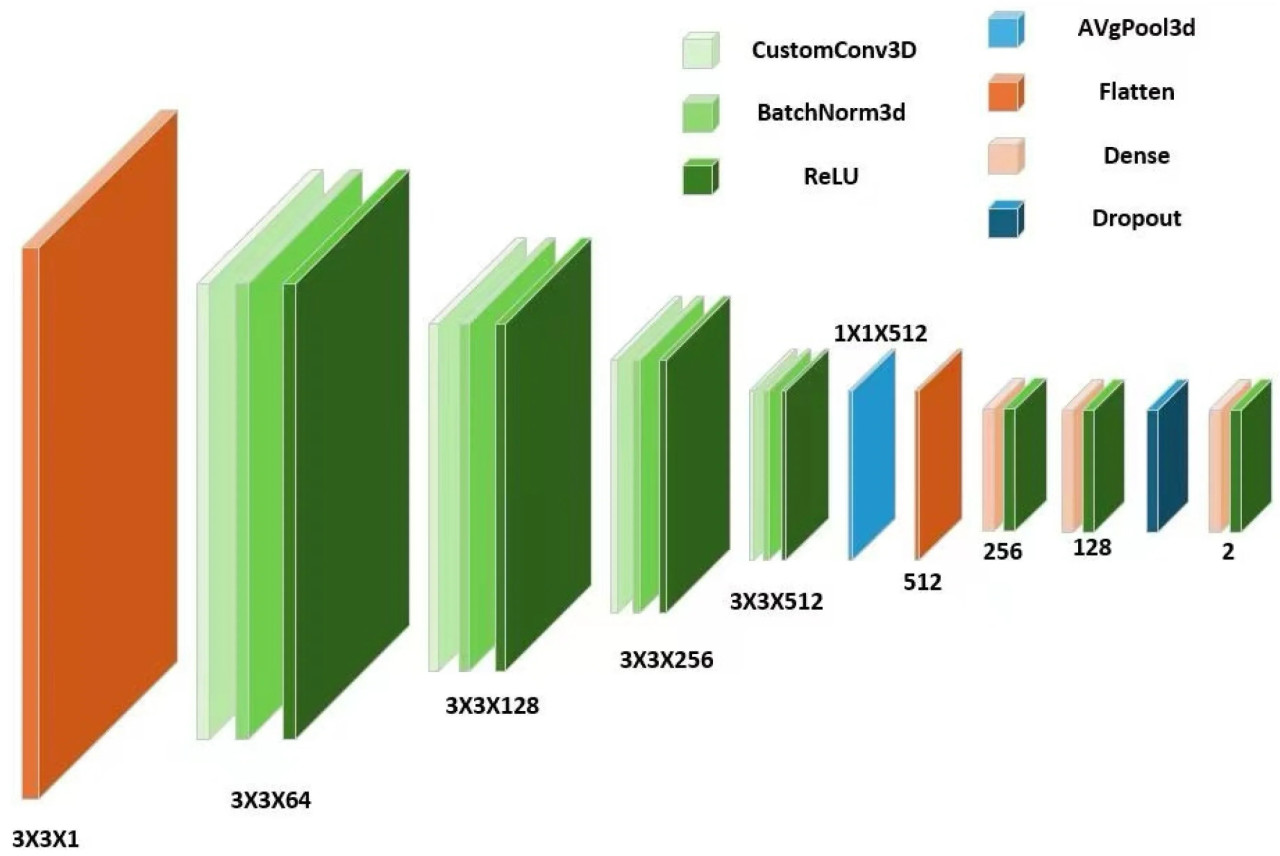
Рисунок 2. Блок-схема иерархии модели 3DCNN.
3. Результаты
3.1. Сравнительный эксперимент
Эксперимент использует точность (accuracy), полноту (recall), точность позитивного прогноза (precision), скорость потерь (loss rate), F1-меру (F1-Score) и индекс Жаккара (Intersection over Union, IoU) для оценки эффективности обучения модели. Формулы следующие.

TP означает Истинно Положительный (True Positive), что относится к правильной классификации положительных прогнозов; FP означает Ложно Положительный (False Positive), что означает ошибочную классификацию отрицательных прогнозов как положительные; FN означает Ложно Отрицательный (False Negative), что означает ошибочную классификацию положительных прогнозов как отрицательные; TN означает Истинно Отрицательный (True Negative), что относится к правильной классификации отрицательных прогнозов; A представляет фактическую область истинных значений; B представляет область, предсказанную моделью.
Алгоритм ES-RMBO, предложенный в данной статье, показывает заметное превосходство в задачах сегментации стеблей и листьев. В сравнении с другими основными алгоритмами, ES-RMBO достигает оптимального уровня в ключевых метриках производительности, таких как точность позитивного прогноза (0,965), полнота (0,965), F1-мера (0,965), IoU (0,965) и общая точность ACC (0,933), демонстрируя более высокую точность и стабильность сегментации (Таблица 1). В отличие от этого, хотя алгоритмы UNet [48], AC-UNet [49], PointNet++ [50], PCNN [51] и DeepLabV3 [52] также продемонстрировали хорошую производительность в задачах сегментации, они немного уступают RMBO с точки зрения точности (Рисунок 3a), полноты (Рисунок 3b), F1-меры (Рисунок 3c), IoU (Рисунок 3d) и ACC (Рисунок 3e). Растения томата проявляют уникальные характеристики роста, с прямостоячими и регулярными стеблями и густыми, разнообразными листьями с относительно сложной структурой. Алгоритм RMBO эффективно интегрирует геометрическую информацию данных облака точек, позволяя ему точно идентифицировать и различать эти сложные структурные признаки. Достигая лучшего баланса между точностью позитивного прогноза и полнотой, алгоритм RMBO значительно снижает количество ошибочных классификаций, тем самым повышая надежность и точность результатов сегментации.
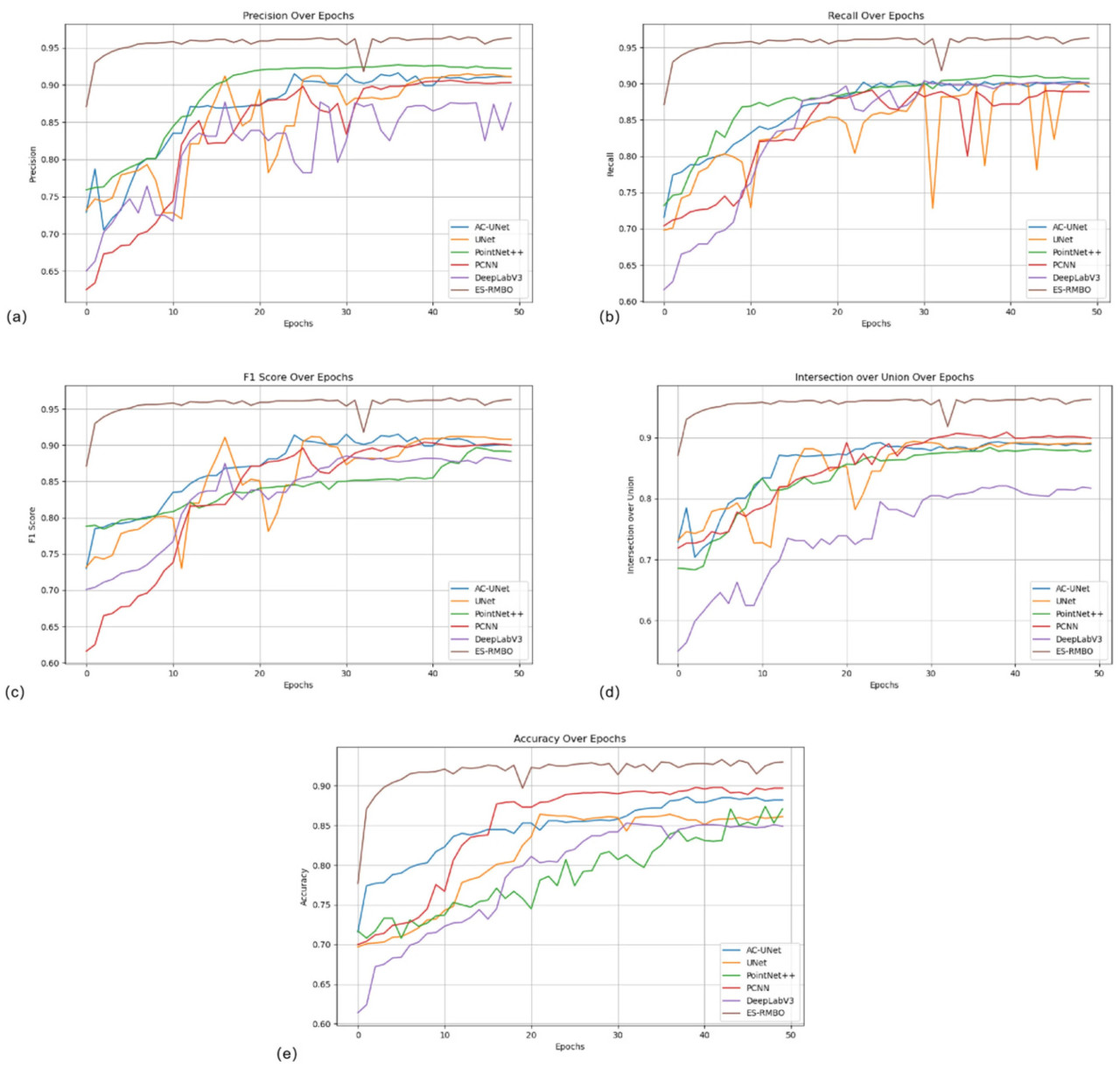
Рисунок 3. Сравнение различных данных сравнительного теста ES-RMBO. (a) Точность позитивного прогноза (Precision); (b) Полнота (Recall); (c) F1-мера; (d) IoU; (e) Общая точность (ACC).
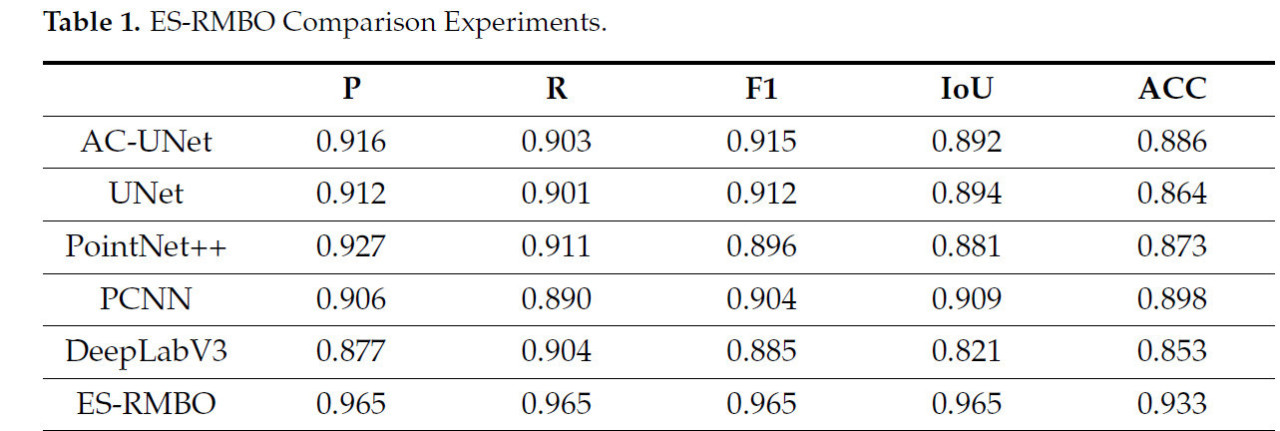
Таблица 1. Сравнительные эксперименты ES-RMBO.
Для всесторонней оценки вычислительной эффективности и использования ресурсов алгоритма ES-RBMO мы сравниваем его с моделями из Таблицы 1, и результаты, как показано в Таблице 2, показывают, что ES-RBMO имеет заметное преимущество по ряду метрик. Время обучения ES-RBMO составляет 13,1 ч, что примерно на 7% и 45% меньше, чем у UNet, PointNet++ и DeepLabV3, соответственно. Время обучения ES-RBMO составляет 13,1 ч, что примерно на 7%, 15% и 45% меньше, чем у UNet, PointNet++ и DeepLabV3, соответственно. Размер параметров модели составляет всего 5,8 миллиона, что составляет около 14% от DeepLabV3, и сегментационная точность (IoU 0,965) остается высокой при одновременном снижении вычислительной сложности. В дополнение, ES-RBMO потребляет 5,9 ГБ видеопамяти, что заметно ниже, чем 8,2 ГБ у PointNet++ и 10,4 ГБ у DeepLabV3, и более подходит для сценариев с ограниченными ресурсами. Вычислительная эффективность ES-RBMO составляет 17,04, что заметно выше, чем 9,56 у UNet, 10,29 у PointNet++ и 5,20 у DeepLabV3. Эти результаты полностью демонстрируют превосходство ES-RBMO с точки зрения времени выполнения, использования ресурсов и общей вычислительной эффективности.
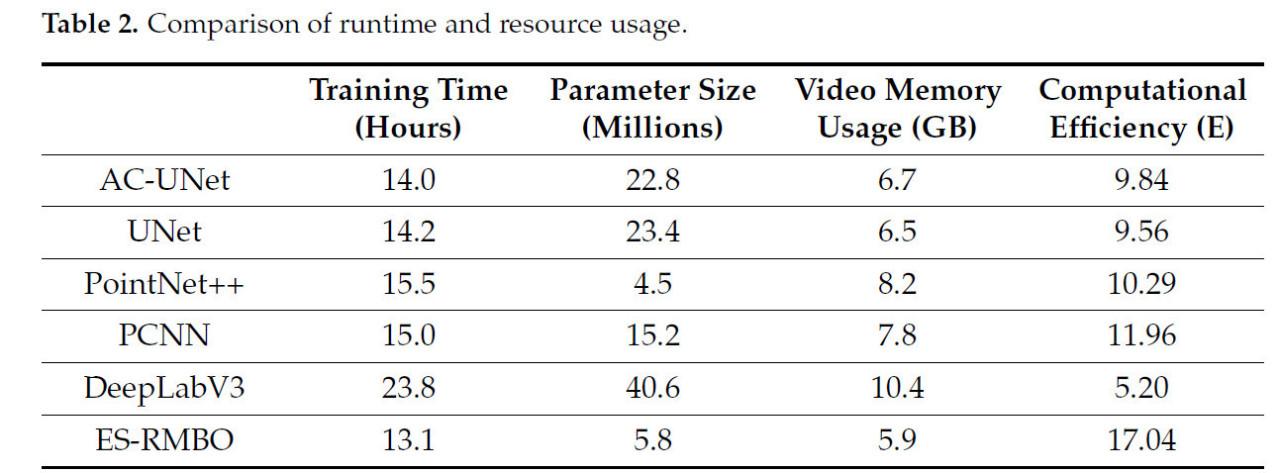
Таблица 2. Сравнение времени выполнения и использования ресурсов.
3.2. Абляционный эксперимент
Чтобы проверить эффективность алгоритма ES-RMBO в задаче сегментации стеблей и листьев томата, мы провели абляционные эксперименты для сравнения ES-RMBO с другими неоптимизированными алгоритмами, включая исходный 3DCNN и алгоритм с добавлением неоптимизированного RMBO. Таблица 3 демонстрирует сравнение производительности различных алгоритмов в задаче сегментации стеблей и листьев томата. Как видно из таблицы, алгоритм ES-RMBO достигает оптимальных результатов по всем ключевым метрикам производительности: точности позитивного прогноза (0,965), полноте (0,965), F1-мере (0,965), IoU (0,965) и общей точности ACC (0,933), что доказывает его превосходство в задаче сегментации стеблей и листьев томата. Результаты абляционных экспериментов показывают, что несколько значений точности позитивного прогноза (Рисунок 4a), полноты (Рисунок 4b), F1-меры (Рисунок 4c), IoU (Рисунок 4d) и ACC (Рисунок 4e) неоптимизированного алгоритма не так хороши, как у алгоритма ES-RMBO в задаче сегментации стеблей и листьев томата. Это предполагает, что алгоритм ES-RMBO способен эффективно обрабатывать данные облака точек томата, повышать точность и стабильность сегментации, предоставляя эффективное и точное решение для мониторинга роста томата, идентификации сортов и фенотипического анализа.
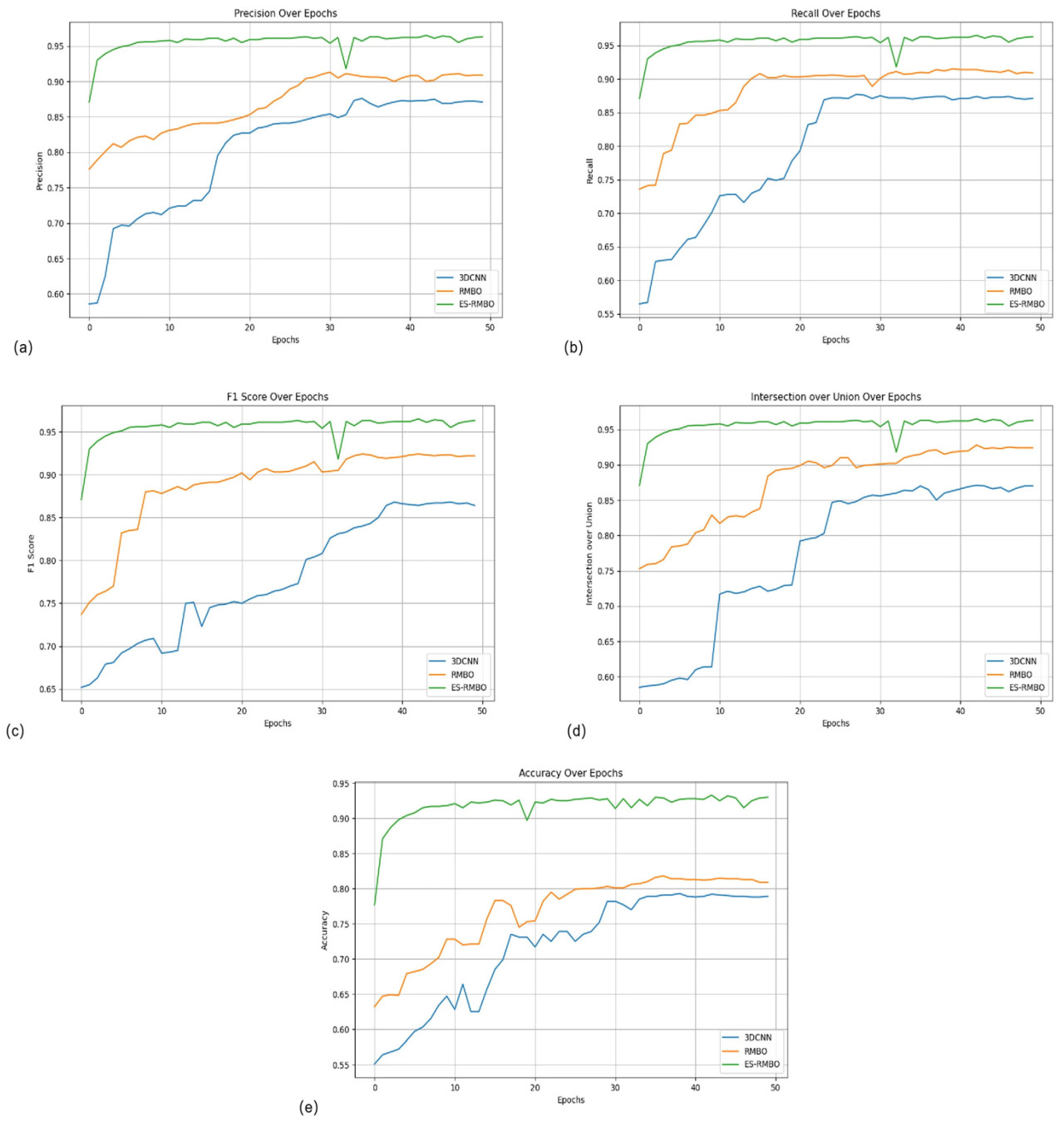
Рисунок 4. Сравнение различных данных абляционных экспериментов ES-RMBO. (a) Точность позитивного прогноза (Precision); (b) Полнота (Recall); (c) F1-мера; (d) IoU; (e) Общая точность (ACC).
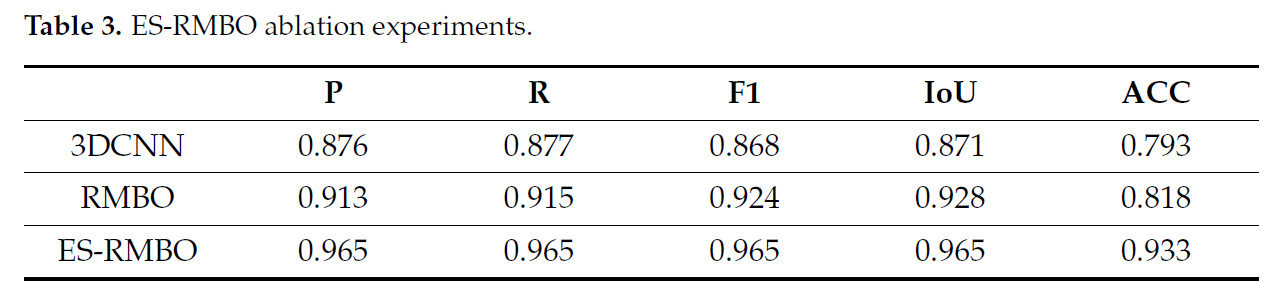
Таблица 3. Абляционные эксперименты ES-RMBO.
Из табличных данных видно, что каждая из трех моделей имеет свои особенности с точки зрения времени обучения, размера параметров, занимаемой видеопамяти и вычислительной эффективности. Как показано в Таблице 4, 3DCNN имеет размер параметров 10,8 миллиона, использование памяти 6,7 ГБ и вычислительную эффективность 9,37, что является более базовой производительностью. RMBO имеет время обучения 10,2 ч, использование памяти 6,5 ГБ, вычислительную эффективность 11,36 и размер параметров 11,4 миллиона, что немного больше, чем у 3DCNN, и показывает определенную степень улучшения производительности. ES-RMBO имеет наиболее выдающуюся производительность: несмотря на самое длительное время обучения (13,1 ч), он достигает наивысшей вычислительной эффективности (17,04) при наименьшем размере параметров (5,8 миллиона) и использовании видеопамяти (5,9 ГБ), что указывает на то, что он имеет заметное преимущество в балансе использования ресурсов и производительности и является моделью с наилучшей общей производительностью.
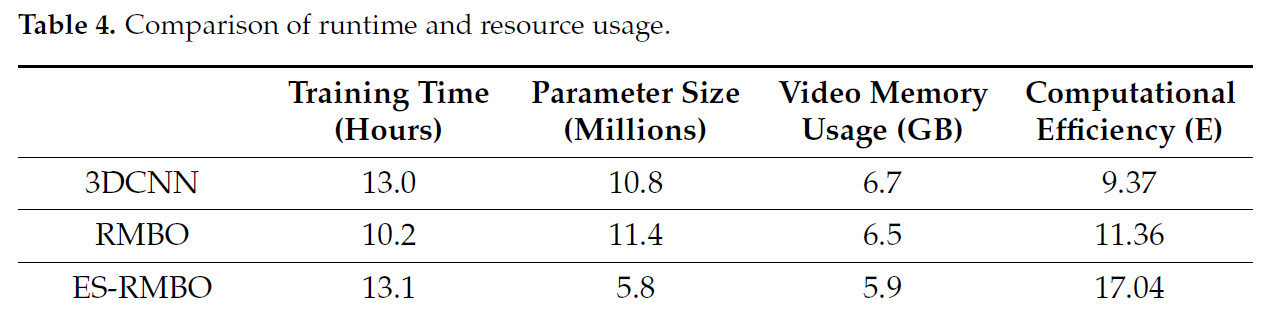
Таблица 4. Сравнение времени выполнения и использования ресурсов.
3.3. Результаты измерений фенотипических параметров и анализ
Прогнозирование фенотипических параметров на сегментированных данных облака точек проводится с использованием классических алгоритмов, включая ключевые параметры, такие как высота растения, диаметр стебля, площадь листа и угол наклона листа. Конкретные методы включают использование алгоритма RANSAC для линейной аппроксимации главного стебля для измерения высоты растения и диаметра стебля, применение алгоритма регионарного роста для оценки площади листа и угла наклона листа, а также дальнейшую оптимизацию расчета фенотипических параметров через алгоритм триангуляции жадной проекции. Результаты измерений и анализ были взяты от 100 растений томата, сравнивая ручные измерения с извлеченными значениями параметров 3D облака точек, включая высоту растения R² = 0,932, RMSE = 0,511, MAPE = 1,970 (Рисунок 5a); толщину стебля R² = 0,741, RMSE = 0,135, MAPE = 4,299 (Рисунок 5b); площадь листа R² = 0,938, RMSE = 0,989, MAPE = 4,365 (Рисунок 5c); угол наклона листа R² = 0,935, RMSE = 3,628, MAPE = 5,531 (Рисунок 5d). Экспериментальные данные показали, что результаты указывают на высокую корреляцию между измеренными результатами и реальными данными для измеренных данных листьев. Низкий R² для прогноза толщины стебля проистекает из неспособности модели извлекать признаки, связанные с толщиной стебля. В дополнение, шум измерений является одним из влияющих факторов. Высокий RMSE для угла наклона листа отражает сложность для модели в захвате сложности изменений угла листа, особенно перед лицом высокой изменчивости данных.
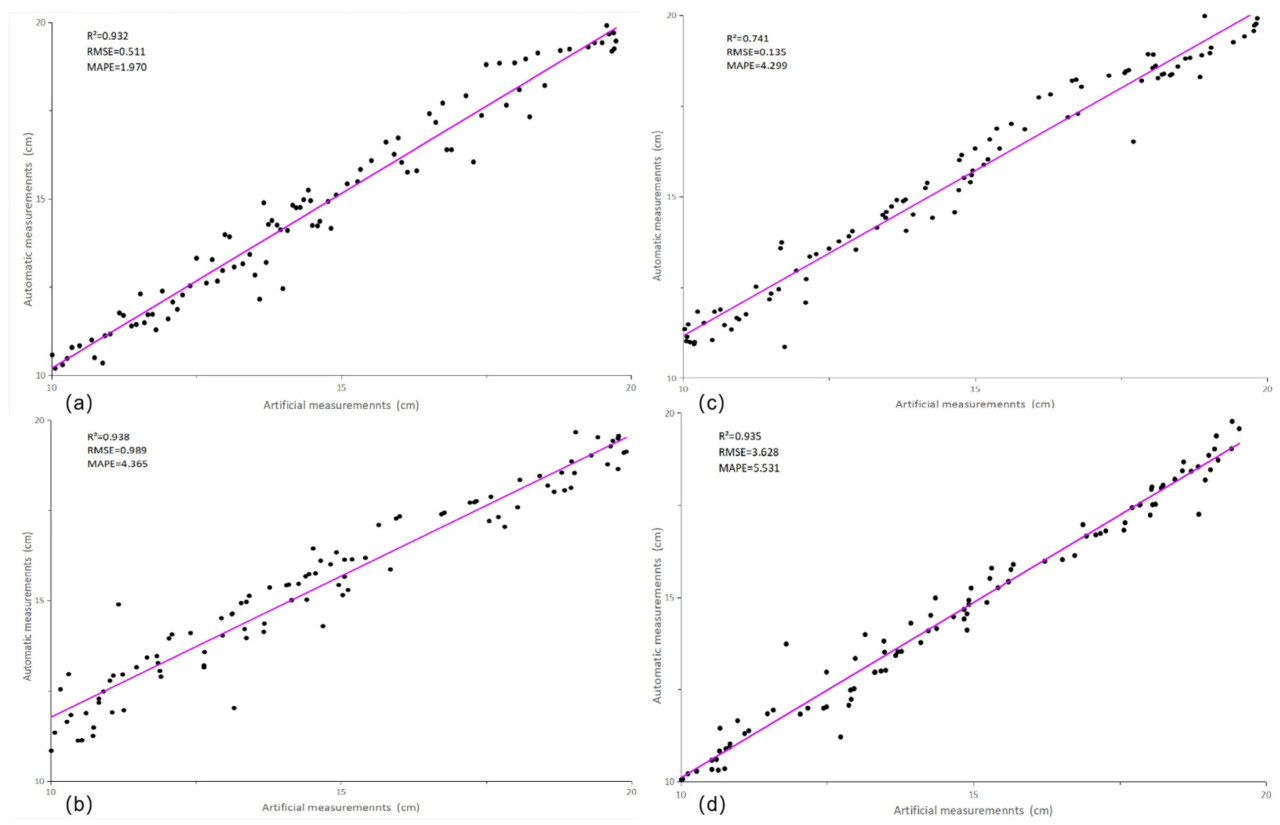
Рисунок 5. Измерения фенотипических параметров. (a) Высота растения; (b) Толщина стебля; (c) Площадь листа; (d) Угол наклона листа.
4. Обсуждение
Алгоритм ES-RBMO, предложенный в данной статье, демонстрирует отличную адаптивность и устойчивость к характеристикам облака точек, проявляемым растениями томата на разных стадиях роста и развития и в различных условиях окружающей среды. Извлекая геометрические признаки и признаки кривизны облака точек иерархическим образом, алгоритм ускоряет скорость сходимости и качество решения, а также повышает точность и стабильность сегментации. Экспериментальные результаты показывают, что алгоритм может эффективно выполнять сегментацию стеблей и листьев при обработке данных облака точек томата и достигает оптимального уровня ключевых метрик производительности, таких как точность позитивного прогноза, полнота, F1-мера, IoU и общая точность ACC, демонстрируя более высокую точность и стабильность сегментации (Рисунок 6a).
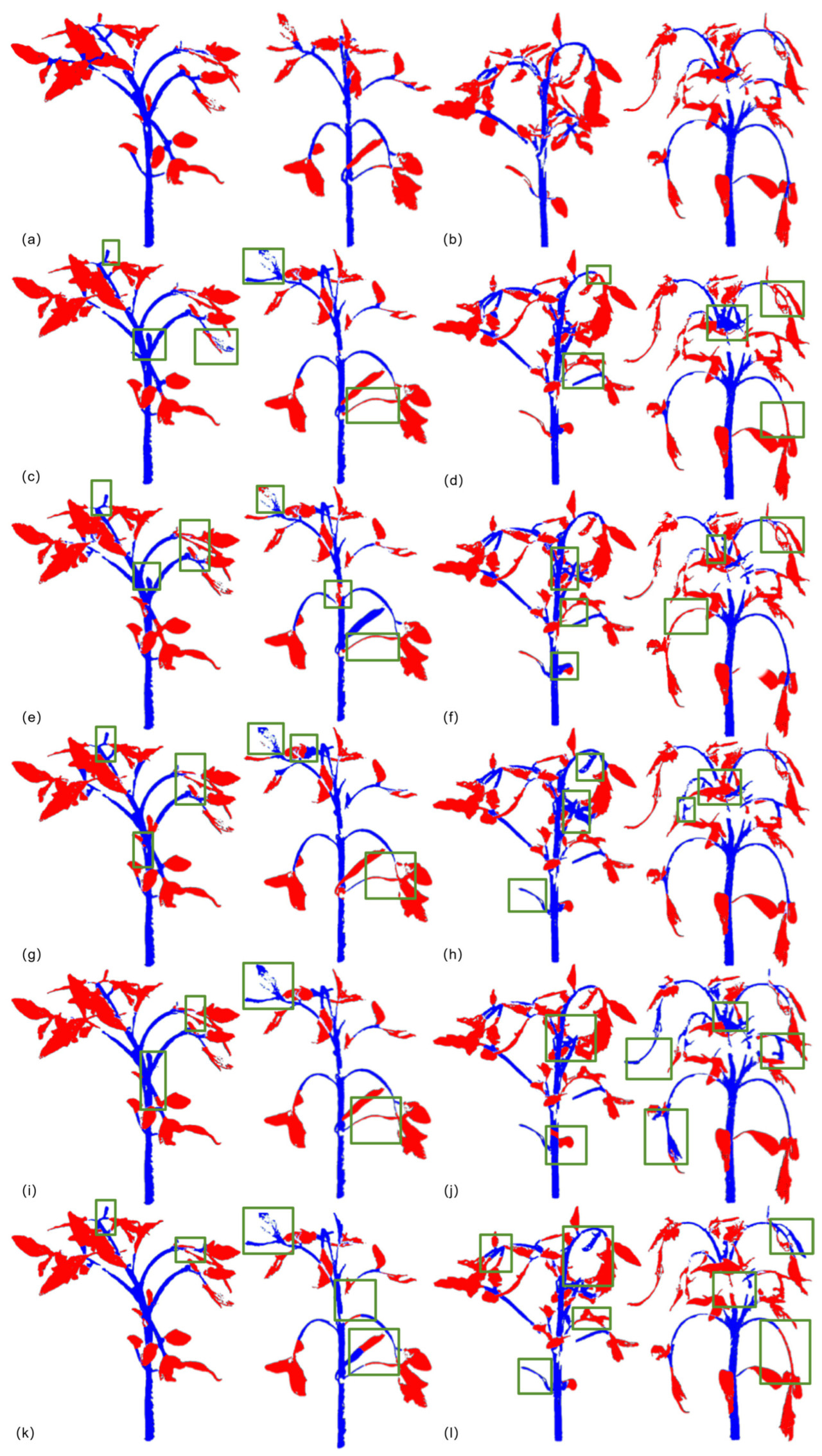
Рисунок 6. Результаты облака точек растений томата с разными условиями роста. Зеленые рамки на рисунке указывают на необнаруженные участки других моделей по сравнению с ES-RMBO. (a) Нормальные растения томата, идентифицированные ES-RMBO; (b) Более сложные растения томата, идентифицированные ES-RMBO; (c) Нормальные растения томата, идентифицированные AC-UNet; (d) Более сложные растения томата, идентифицированные AC-UNet; (e) Нормальные растения томата, идентифицированные UNet; (f) Более сложные растения томата, идентифицированные UNet; (g) Нормальные растения томата, идентифицированные PointNet++; (h) Более сложные растения томата, идентифицированные PointNet++; (i) Нормальные растения томата, идентифицированные PCNN; (j) Более сложные растения томата, идентифицированные PCNN; (k) Нормальные растения томата, идентифицированные DeepLabV3; (l) Более сложные растения томата, идентифицированные DeepLabV3.
AC-UNet и UNet, как классические модели сверточных нейронных сетей, имеют лучшую точность сегментации и вычислительную эффективность, но склонны к путанице признаков или размытию границ при обработке сложных сцен (например, плотные цели и сильная окклюзия) (Рисунок 6c–f). PointNet++ и PCNN обладают сильной способностью захватывать пространственно-геометрические признаки с введением механизмов обработки облака точек и иерархического извлечения признаков (Рисунок 6g–j). Геометрические признаки, но все еще недостаточны в различении мелкозернистых признаков в окклюзированных областях (Рисунок 6g–j). DeepLabV3 преуспевает в захвате глобальной контекстуальной информации с помощью атрных сверток и многоуровневого извлечения признаков, но его большой размер параметров и высокие требования к памяти ограничивают его применение в средах с ограниченными ресурсами (Рисунок 6k,l). В отличие от этого, ES-RMBO сочетает эффективную архитектуру глубокого обучения и стратегию оптимизации, что предлагает заметные преимущества с точки зрения размера параметров, занимаемой видеопамяти и вычислительной эффективности, одновременно эффективно решая проблемы плотного роста и окклюзии. Однако ES-RMBO все еще может страдать от недостаточного захвата деталей в сценах с экстремальными окклюзиями и сложной геометрией. Эта плотная и переплетенная модель роста приводит к тому, что традиционные алгоритмы обнаружения краев с трудом точно распознают края листьев, таким образом влияя на точность результатов сегментации (Рисунок 6b).
5. Выводы
В данной статье мы предлагаем метод сегментации стеблей и листьев на основе улучшенного алгоритма оптимизации ES-RBMO и проверяем его отличную производительность и устойчивость в данных облака точек различной плотности. Метод заметно повышает точность и стабильность сегментации стеблей и листьев путем интеграции геометрических признаков, информации о пространственном распределении и модели глубокого обучения данных облака точек. Через динамическое сжатие объема усиливается агрегация облака точек, что эффективно повышает точность процесса извлечения признаков. Для разных плотностей облака точек алгоритм способен точно захватывать признаки стеблей и листьев, оптимизировать локальные детали и значительно снижать количество ошибочных классификаций. В процессе обработки растений томата ES-RMBO демонстрирует сильную стабильность и надежность и способен точно различать стебли и листья. Через иерархическую обработку и вычисление геометрических признаков метод успешно справляется с уникальной иерархической структурой растений томата, дополнительно усиливая эффект сегментации. Алгоритм достигает оптимальных результатов в ключевых метриках производительности, таких как точность позитивного прогноза, полнота, F1-мера, IoU и общая точность ACC, что проверяет его высокую адаптивность на стадиях роста растений. Алгоритм, предложенный в данной статье, может эффективно справляться со сложными структурами растений и предоставляет прочную техническую поддержку для мониторинга роста растений и задач автоматизированной сегментации в точном земледелии. Его применимость к широкому спектру видов растений и сельскохозяйственных сценариев применения может быть расширена в будущем путем дальнейшей оптимизации обобщающей способности алгоритма.
Ссылки
1. Boogaard, F.; Henten, E.; Kootstra, G. The added value of 3D point clouds for digital plant phenotyping—A case study on internode length measurements in cucumber. Biosyst. Eng. 2023, 234, 1–12. [Google Scholar] [CrossRef]
2. Alighaleh, P.; Mesri Gundoshmian, T.; Alighaleh, S.; Rohani, A. Feasibility and reliability of agricultural crop height measurement using the laser sensor array. Inf. Process. Agric. 2024, 11, 228–236. [Google Scholar] [CrossRef]
3. Anshori, M.F.; Dirpan, A.; Sitaresmi, T.; Rossi, R.; Farid, M.; Hairmansis, A.; Purwoko, B.; Suwarno, W.B.; Nugraha, Y. An overview of image-based phenotyping as an adaptive 4. 0 technology for studying plant abiotic stress: A bibliometric and literature review. Heliyon 2023, 9, e21650. [Google Scholar] [CrossRef] [PubMed]
4. Dong, Q.; Sun, L.; Han, T.; Cai, M.; Gao, C. PestLite: A Novel YOLO-Based Deep Learning Technique for Crop Pest Detection. Agriculture 2024, 14, 228. [Google Scholar] [CrossRef]
5. Li, R.; Li, Y.; Qin, W.; Abbas, A.; Li, S.; Ji, R.; Wu, Y.; He, Y.; Yang, J. Lightweight Network for Corn Leaf Disease Identification Based on Improved YOLO v8s. Agriculture 2024, 14, 220. [Google Scholar] [CrossRef]
6. Wang, Y.; Wu, M.; Shen, Y. Identifying the Growth Status of Hydroponic Lettuce Based on YOLO-EfficientNet. Plants 2024, 13, 372. [Google Scholar] [CrossRef] [PubMed]
7. Zhao, L.; Zhao, Y.; Liu, T.; Deng, H. A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels. Sensors 2023, 23, 9846. [Google Scholar] [CrossRef] [PubMed]
8. Sun, Y.; Guo, X.; Yang, H. Win-Former: Window-Based Transformer for Maize Plant Point Cloud Semantic Segmentation. Agronomy 2023, 13, 2723. [Google Scholar] [CrossRef]
9. Luo, L.; Jiang, X.; Yang, Y.; Samy, E.R.; Lefsrud, M.; Hoyos-Villegas, V.; Sun, S. Eff-3DPSeg: 3D organ-level plant shoot segmentation using annotation-efficient point clouds. arXiv 2022, arXiv:2212.10263. [Google Scholar]
10. Wang, Y.; Liu, Q.; Yang, J.; Ren, G.; Wang, W.; Zhang, W.; Li, F. A Method for Tomato Plant Stem and Leaf Segmentation and Phenotypic Extraction Based on Skeleton Extraction and Supervoxel Clustering. Agronomy 2024, 14, 198. [Google Scholar] [CrossRef]
11. Morteza, G.; Kevin, W.; Corke, F.M.; Tiddeman, B.; Liu, Y.; Doonan, J.H. Deep Segmentation of Point Clouds of Wheat. Front. Plant Sci. 2021, 12, 608732. [Google Scholar]
12. Yonatan, L.; Ofri, R.; Merav, A. Dissecting the roles of supervised and unsupervised learning in perceptual discrimination judgments. J. Neurosci. 2020, 41, 757–765. [Google Scholar]
13. Yao, D.; Chuanchuan, Y.; Hao, C.; Yan, W.; Li, H. Low-complexity point cloud denoising for LiDAR by PCA-based dimension reduction. Opt. Commun. 2021, 482, 126567. [Google Scholar]
14. Alkadri, F.M.; Yuliana, Y.; Agung, C.R.M.; Rahman, M.A.; Hein, C. Enhancing preservation: Addressing humidity challenges in Indonesian heritage buildings through advanced detection methods point cloud data. Results Eng. 2024, 24, 103292. [Google Scholar] [CrossRef]
15. Jing, R.; Shao, Y.; Zeng, Q.; Liu, Y.; Wei, W.; Gan, B.; Duan, X. Multimodal feature integration network for lithology identification from point cloud data. Comput. Geosci. 2025, 194, 105775. [Google Scholar] [CrossRef]
16. Chen, T.; Ying, X. FPSMix: Data augmentation strategy for point cloud classification. Front. Comput. Sci. 2024, 19, 192701. [Google Scholar] [CrossRef]
17. Miao, T.; Zhu, C.; Xu, T.; Yang, T.; Li, N.; Zhou, Y.; Deng, H. Automatic stem-leaf segmentation of maize shoots using three-dimensional point cloud. Comput. Electron. Agric. 2021, 187, 106310. [Google Scholar] [CrossRef]
18. Shen, F.; Lu, Z.-M.; Lu, Z.; Wang, Z. Dual semantic-guided model for weakly-supervised zero-shot semantic segmentation. Multimed. Tools Appl. 2021, 81, 5443–5458. [Google Scholar] [CrossRef]
19. Wu, J.; Sun, M.; Xu, H.; Jiang, C.; Ma, W.; Zhang, Q. Class agnostic and specific consistency learning for weakly-supervised point cloud semantic segmentation. Pattern Recognit. 2025, 158, 111067. [Google Scholar] [CrossRef]
20. Samoaa, P.; Aronsson, L.; Longa, A.; Leitner, P.; Chehreghani, M.H. A unified active learning framework for annotating graph data for regression task. Eng. Appl. Artif. Intell. 2024, 138, 109383. [Google Scholar] [CrossRef]
21. Bicheng, S.; Peng, Z.; Liang, D.; Li, X. Active deep image clustering. Knowl.-Based Syst. 2022, 252, 109346. [Google Scholar]
22. Sun, R.; Guo, S.; Guo, J.; Li, W.; Zhang, X.; Guo, X.; Pan, Z. GraphMoCo: A graph momentum contrast model for large-scale binary function representation learning. Neurocomputing 2024, 575, 127273. [Google Scholar] [CrossRef]
23. Shengwei, F.; Ke, L.; Haisong, H.; Ma, C.; Fan, Q.; Zhu, Y. Red-billed blue magpie optimizer: A novel metaheuristic algorithm for 2D/3D UAV path planning and engineering design problems. Artif. Intell. Rev. 2024, 57, 134. [Google Scholar]
24. Hassen, L.; Ali, L.; Slim, B.; Kariri, E. Joint filter and channel pruning of convolutional neural networks as a bi-level optimization problem. Memetic Comput. 2024, 16, 71–90. [Google Scholar]
25. Baljon, M. A Framework for Agriculture Plant Disease Prediction using Deep Learning Classifier. Int. J. Adv. Comput. Sci. Appl. IJACSA 2023, 14, 1098–1111. [Google Scholar] [CrossRef]
26. Xiaodan, L.; Zijian, Z. A Whale Optimization Algorithm with Convergence and Exploitability Enhancement and Its Application. Math. Probl. Eng. 2022, 2022, 2904625. [Google Scholar]
27. Anderson, J.P.; Stephens, D.W.; Dunbar, S.R. Saltatory search: A theoretical analysis. Behav. Ecol. 1997, 8, 307–317. [Google Scholar] [CrossRef]
28. Fergany EA, A.; Agwa, M.A. Red-Billed Blue Magpie Optimizer for Electrical Characterization of Fuel Cells with Prioritizing Estimated Parameters. Technologies 2024, 12, 156. [Google Scholar] [CrossRef]
29. Wang, P.; Liu, Z.; Wang, Z.; Zhao, Z.; Yang, D.; Yan, W. Graph generative adversarial networks with evolutionary algorithm. Appl. Soft Comput. 2024, 164, 111981. [Google Scholar] [CrossRef]
30. Zhang, M.; Wang, H.; Cui, Z.; Chen, J. Hybrid multi-objective cuckoo search with dynamical local search. Memetic Comput. 2018, 10, 199–208. [Google Scholar] [CrossRef]
31. Li, C.; Priemer, R.; Cheng, K.H. Optimization by random search with jumps. Int. J. Numer. Methods Eng. 2004, 60, 1301–1315. [Google Scholar] [CrossRef]
32. Shan, D.; Zhang, X.; Shi, W.; Li, L. Neural Architecture Search for a Highly Efficient Network with Random Skip Connections. Appl. Sci. 2020, 10, 3712. [Google Scholar] [CrossRef]
33. Gan, W.; Li, H.; Hao, P. Many-objective optimization algorithm based on the similarity principle and multi-mechanism collaborative search. J. Supercomput. 2024, 81, 124. [Google Scholar] [CrossRef]
34. Fang, G.; Weibin, Z.; Guofu, L.; Zhang, X.; Luo, L.; Wu, Y.; Guo, P. A point cloud registration method based on multiple-local-feature matching. Optik 2023, 295, 171511. [Google Scholar]
35. Jingtao, W.; Changcai, Y.; Lifang, W.; Chen, R. CSCE-Net: Channel-Spatial Contextual Enhancement Network for Robust Point Cloud Registration. Remote Sens. 2022, 14, 5751. [Google Scholar] [CrossRef]
36. Wang, L. High-precision point cloud registration method based on volume image correlation. Meas. Sci. Technol. 2024, 35, 035024. [Google Scholar] [CrossRef]
37. Chuang, T.Y.; Jaw, J.J. Multi-feature registration of point clouds. Remote Sens. 2017, 9, 281. [Google Scholar] [CrossRef]
38. Yu, F.; Chen, Z.; Cao, J.; Jiang, M. Redundant same sequence point cloud registration. Vis. Comput. 2023, 40, 7719–7730. [Google Scholar] [CrossRef]
39. Xu, S. An Introduction to Scientific Computing with Matlab and Python Tutorials; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
40. Garcia, H.A.; Zhu, W. Building an Accessible and Flexible Multi-User Robotic Simulation Framework with Unity-MATLAB Bridge. Computers 2024, 13, 282. [Google Scholar] [CrossRef]
41. Gasmi, K.; Hasnaoui, S. Dataflow-based automatic parallelization of MATLAB/Simulink models for fitting modern multicore architectures. Clust. Comput. 2024, 27, 6579–6590. [Google Scholar] [CrossRef]
42. Yang, D. An improved particle swarm optimization algorithm for parameter optimization. Comput. Informatiz. Mech. Syst. 2022, 5, 35–38. [Google Scholar]
43. Mohan, B.G.; Kumar, P.R.; Elakkiya, R. Enhancing pre-trained models for text summarization: A multi-objective genetic algorithm optimization approach. Multimed. Tools Appl. 2024, 1–17. [Google Scholar] [CrossRef]
44. Chaudhury, A. Multilevel Optimization for Registration of Deformable Point Clouds. IEEE Trans. Image Process. 2020, 29, 8735–8746. [Google Scholar] [CrossRef]
45. Tianyuan, L.; Jiacheng, W.; Xiaodi, H.; Lu, Y.; Bao, J. 3DSMDA-Net: An improved 3DCNN with separable structure and multi-dimensional attention for welding status recognition. J. Manuf. Syst. 2021, 62, 811–822. [Google Scholar]
46. Peyman, A.; Keyhan, G.; Atieh, A.; Deb, P.; Moradkhani, H. Bayesian Multi-modeling of Deep Neural Nets for Probabilistic Crop Yield Prediction. Agric. For. Meteorol. 2022, 314, 108773. [Google Scholar]
47. Zhu, G.; Zhang, L.; Shen, P.; Song, J.; Shah, S.A.; Bennamoun, M. Continuous Gesture Segmentation and Recognition Using 3DCNN and Convolutional LSTM. IEEE Trans. Multimed. 2019, 21, 1011–1021. [Google Scholar] [CrossRef]
48. Zhihua, D.; Peiliang, G.; Baohua, Z.; Zhang, D.; Yan, J.; He, Z.; Zhao, S.; Zhao, C. Maize crop row recognition algorithm based on improved UNet network. Comput. Electron. Agric. 2023, 210, 107940. [Google Scholar]
49. Yi, X.; Wang, J.; Wu, P.; Wang, G.; Mo, L.; Lou, X.; Liang, H.; Huang, H.; Lin, E.; Maponde, B.T. AC-UNet: An improved UNet-based method for stem and leaf segmentation in Betula luminifera. Front. Plant Sci. 2023, 14, 1268098. [Google Scholar] [CrossRef] [PubMed]
50. Liu, B.; Chen, S.; Huang, H.; Tian, X. Tree Species Classification of Backpack Laser Scanning Data Using the PointNet++ Point Cloud Deep Learning Method. Remote Sens. 2022, 14, 3809. [Google Scholar] [CrossRef]
51. Xiang, R. Image segmentation for whole tomato plant recognition at night. Comput. Electron. Agric. 2018, 154, 434–442. [Google Scholar] [CrossRef]
52. Zeng, W.; He, M. Rice disease segmentation method based on CBAM-CARAFE-DeepLabv3+. Crop Prot. 2024, 180, 106665. [Google Scholar] [CrossRef]

Zhang L, Huang Z, Yang Z, Yang B, Yu S, Zhao S, Zhang X, Li X, Yang H, Lin Y, et al. Tomato Stem and Leaf Segmentation and Phenotype Parameter Extraction Based on Improved Red Billed Blue Magpie Optimization Algorithm. Agriculture. 2025; 15(2):180. https://doi.org/10.3390/agriculture15020180
Перевод статьи «Tomato Stem and Leaf Segmentation and Phenotype Parameter Extraction Based on Improved Red Billed Blue Magpie Optimization Algorithm» авторов Zhang L, Huang Z, Yang Z, Yang B, Yu S, Zhao S, Zhang X, Li X, Yang H, Lin Y, et al., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik

















































































































Комментарии (0)