Не просто срезать, а срывать правильно: метод глубокого обучения для бережного сбора элитного чая
Чай является важной товарной культурой, широко выращиваемой по всему миру. В настоящее время сбор чая преимущественно осуществляется вручную. Однако из-за старения населения и роста затрат на рабочую силу машинный сбор чая становится важным трендом в чайной отрасли. Определение положения срыва и позы сбора является критически важным предварительным условием для машинного сбора чайных листьев. Для повышения точности и эффективности машинного сбора в данной статье представлен метод определения точки срыва и позы сбора на основе сети глубокого обучения для сегментации экземпляров (instance segmentation).
Аннотация
В данном исследовании изображения чая в наборе данных сначала были размечены с помощью программного обеспечения Labelme (версия 4.5.13). Затем была предложена модель LDS-YOLOv8-seg для идентификации области чайной почки и зоны срыва. Точки срыва и центральные точки ограничивающих рамок (bounding box) чайных почек были рассчитаны и сопоставлены попарно с использованием предложенных в исследовании методов: метода ближайшей точки (Nearest Point Method, NPM) и метода точки в диапазоне (Point In Range Method, PIRM). Наконец, поза срыва была получена на основе результатов сопоставления характерных точек.
Результаты сопоставления на тестовом наборе данных показывают, что метод PIRM демонстрирует более высокую производительность с точностью сопоставления 99,229% и средним временем сопоставления 2,363 миллисекунды. Кроме того, в исследовании также были проанализированы случаи неудачного сопоставления характерных точек в процессе определения позы срыва. Результаты тестирования показывают, что предложенный метод определения положения и позы срыва пригоден для машинного сбора чая.
1. Введение
Чай занимает значительное место в жизни людей благодаря своей высокой потребительской и экономической ценности. Он широко культивируется в различных странах, включая Китай, Японию, Англию, Индию и др. [1]. Растущий спрос на чай привел к повышению требований к его производству и переработке. Существует четыре основных этапа обработки чая: сбор, фиксация (убийство зелени), скручивание и сушка. Из них сбор является первым процессом, и его качество оказывает важное влияние на последующую обработку. Сбор чая трудоемок и утомителен, а уровень механизации низок. Проблемы, связанные со сбором чая, становятся все более заметными в последние годы. С одной стороны, сбор чая — это тяжелая работа, но с развитием урбанизации сельское трудоспособное население сокращается, а затраты на рабочую силу быстро растут. С другой стороны, основными работниками в чайных садах в настоящее время являются пожилые мужчины или женщины, что неустойчиво в условиях старения населения [2]. Более того, сбор чая, особенно элитного, предъявляет высокие требования к опыту. Без обучения качество сбора не является единообразным.
Для решения вышеупомянутых проблем и повышения эффективности сбора чая была предложена механизированная уборка чая. Япония первой начала изучение механизации сбора чая и разработала различные типы чаесборочных машин, включая самоходные и навесные [3,4]. Механизация сбора чая также изучалась в Англии, Индии и Австралии соответственно [1]. Однако эти ранние чаесборочные машины в основном срезали верхушки чайных кустов без выбора на одной высоте или под одним углом, что неточно и может повредить листья. Это осуществимо для обычного чая, но не подходит для элитного. В последние годы некоторые ученые начали исследования и разработку прецизионного механизированного оборудования для сбора чайных почек для достижения точного сбора элитного чая [5,6,7].
Ранние чаесборочные машины срезали чайные листья без определения положения и позы листьев, что приводило к низкому качеству сбора. Идентификация чайных листьев является ключевым этапом сбора чая, и многие ученые провели обширные исследования по этой теме. Существует два основных этапа в изучении идентификации чая. На первом этапе использовались цветовые и геометрические признаки чая, при этом изображения чая обрабатывались с помощью различных преобразований с использованием методов обработки изображений для получения целевых признаков [8,9,10]. Тхангавел и Мурти предложили полуавтоматическую систему для сбора чайных листьев, которая идентифицировала различные сорта чайных листьев с использованием извлечения ключевых кадров, подсчета объектов, оптического потока и комбинации операторов Превитта и автоматического порогового разделения [11]. Чен и др. проанализировали цветовые свойства изображений чая с использованием модели яркости и цветоразности (модель YUV), а затем преобразовали изображения в градациях серого в бинарные изображения с использованием метода Оцу, устраняя шум из бинарного изображения для получения области чая [12]. Ву и др. предложили алгоритм идентификации чайных почек с использованием метода кластеризации K-средних на основе компонентов a и b цветовой модели Lab, и изображения, сделанные на трех разных расстояниях, были использованы для сравнения эффекта распознавания и эффективности метода Оцу и метода K-средних [13]. Карунасена и др. представили метод обнаружения чайных почек с использованием каскадного классификатора на основе метода, интегрированного с признаками гистограммы ориентированных градиентов (HOG) и классификацией методом опорных векторов (SVM), и четыре набора изображений образцов чайных листьев были сделаны для проведения теста идентификации чайных почек [14].
Хотя метод обработки изображений прост в работе при распознавании признаков изображения, его точность ограничена, а требования к изображениям высоки, что затрудняет удовлетворение реальных потребностей. В частности, для распознавания чайных почек цветовые и геометрические признаки переднего плана и фона очень близки друг к другу, поэтому результаты распознавания едва удовлетворительны [15]. В последние годы глубокое обучение продемонстрировало свою выдающуюся способность распознавать объекты в условиях сложного фона, предоставив новый метод для распознавания и локализации сельскохозяйственных культур. Многие эксперты изучали обнаружение и распознавание различных фруктов, таких как киви [16], яблоко [17,18], плоды камелии масличной [19], томат [20] и красника [21], с использованием глубокого обучения [22,23]. Поэтому второй этап исследований по распознаванию признаков чайных листьев в основном основан на методах глубокого обучения [24,25,26,27,28,29]. Сюй и др. предложили двухуровневую сеть слияния, которая сочетает возможности быстрого обнаружения YOLOv3 и высокоточные возможности классификации DenseNet201 для обнаружения чайных почек [30]. Они также исследовали влияние угла съемки камеры на эффект обнаружения. Результаты показывают, что обнаружение лучше для чайных почек, снятых сбоку, чем для снятых сверху. Ян и др. предложили улучшенный алгоритм сверточной нейронной сети глубокого обучения YOLOv3 для идентификации нежных побегов для высококачественного чая, который обеспечил сквозное обнаружение объектов с использованием пирамиды изображений и остаточной сети, а метод K-средних был использован для кластеризации размеров ограничивающих рамок [28].
Определение положения и позы срыва являются ключевыми шагами после идентификации чайной почки. Однако несколько ученых изучали метод определения точки срыва, и еще меньше изучали определение позы срыва. Ли и др. обнаружили области чайных побегов на RGB-изображениях с использованием сети YOLO и получили облака точек чайных побегов с использованием обработки евклидовой кластеризации и алгоритма извлечения целевого облака точек, а затем определили точку срыва путем задания минимального цилиндра с радиусом, охватывающим 3D-облако точек, и высотой, определенной характеристиками роста чая [7]. Чен и др. представили метод определения местоположения точки срыва путем комбинирования алгоритма YOLOv3, алгоритма семантической сегментации, извлечения скелета и минимального ограничивающего прямоугольника. Они сегментировали главные жилки из целевых областей с использованием алгоритмов Fast-SCNN и извлечения скелета и, наконец, определили конечную точку обхода как точку срыва [25]. Ян и др. идентифицировали области чайных побегов с улучшенной сетью YOLOv3, получили ограничивающую рамку цели. Положение контакта стебля чая и рамки идентификации было установлено как точка срыва. Однако этот метод предъявляет высокие требования к углу камеры [28]. Чен и др. обучили Faster R-CNN для обнаружения областей "один верхний лист и два листа" (OTTL regions), а затем использовали FCN для обнаружения точки срыва в областях OTTL [31].
На самом деле, в отличие от крупных фруктов, таких как яблоки и апельсины, чайные почки малы и нежны. Чайные почки механически срываются путем срезания стеблей чая в специальном месте. Если точка срыва достигается в неправильном направлении, произойдет неудача. Поэтому необходимо точно определить положение и позу срыва в соответствии с характеристиками его роста.
В этом исследовании мы были направлены на решение проблемы определения позы и положения срыва. Основные инновации и исследовательские идеи заключаются в следующем:
• Был предложен подход для определения позы и точки срыва чайных почек на основе сети глубокого обучения и метода обработки изображений. Эта методика может повысить точность реализации механизированного сбора чая, способствуя тем самым его успешному внедрению на практике.
• Были предложены два подхода сопоставления характерных точек, позволяющие точно выравнивать два набора характерных точек чайных почек и получать линию признака для позы сбора чая. Точность и эффективность этих двух методов были подробно проанализированы.
• Точное сопоставление характерных точек играет ключевую роль в определении позы срыва чайных почек. Поэтому также были проанализированы случаи неудачного сопоставления характерных точек. Дополнительно были представлены будущие исследовательские перспективы.
Остальная часть этой статьи организована следующим образом. В разделе 2 представлен метод обнаружения и сегментации чайных почек и зоны срыва, а также метод, использованный для определения позы и положения срыва. Оценка эффективности алгоритма и некоторые обсуждения представлены в разделе 3. Выводы приведены в разделе 4.
2. Материалы и методы
2.1. Построение набора данных
2.1.1. Получение изображений
Набор данных изображений был построен с использованием фотографий чайных почек, сделанных в Гуанчжоуском национальном парке сельскохозяйственных наук и технологий (113.449166 в.д., 23.394961 с.ш.) в провинции Гуандун, Китай, в июне. «Инхун № 9», который является одним из сортов элитного чая в Южном Китае, был использован в качестве объекта исследования. Чтобы повысить эффективность предложенного алгоритма в улучшении фактической точности и эффективности сбора, фотографии были сделаны за 3–5 дней до сбора чайных почек в различных погодных условиях, включая солнечную, пасмурную и дождливую погоду. Учитывая более высокую скорость распознавания и эффективный сбор, изображения были сделаны с углом съемки 60° и фотографическим расстоянием 0,5–1 м, как показано на Рисунке 1. Всего было сделано 4024 изображения с разрешением 4032 × 3024 и сохранено в формате JPEG.
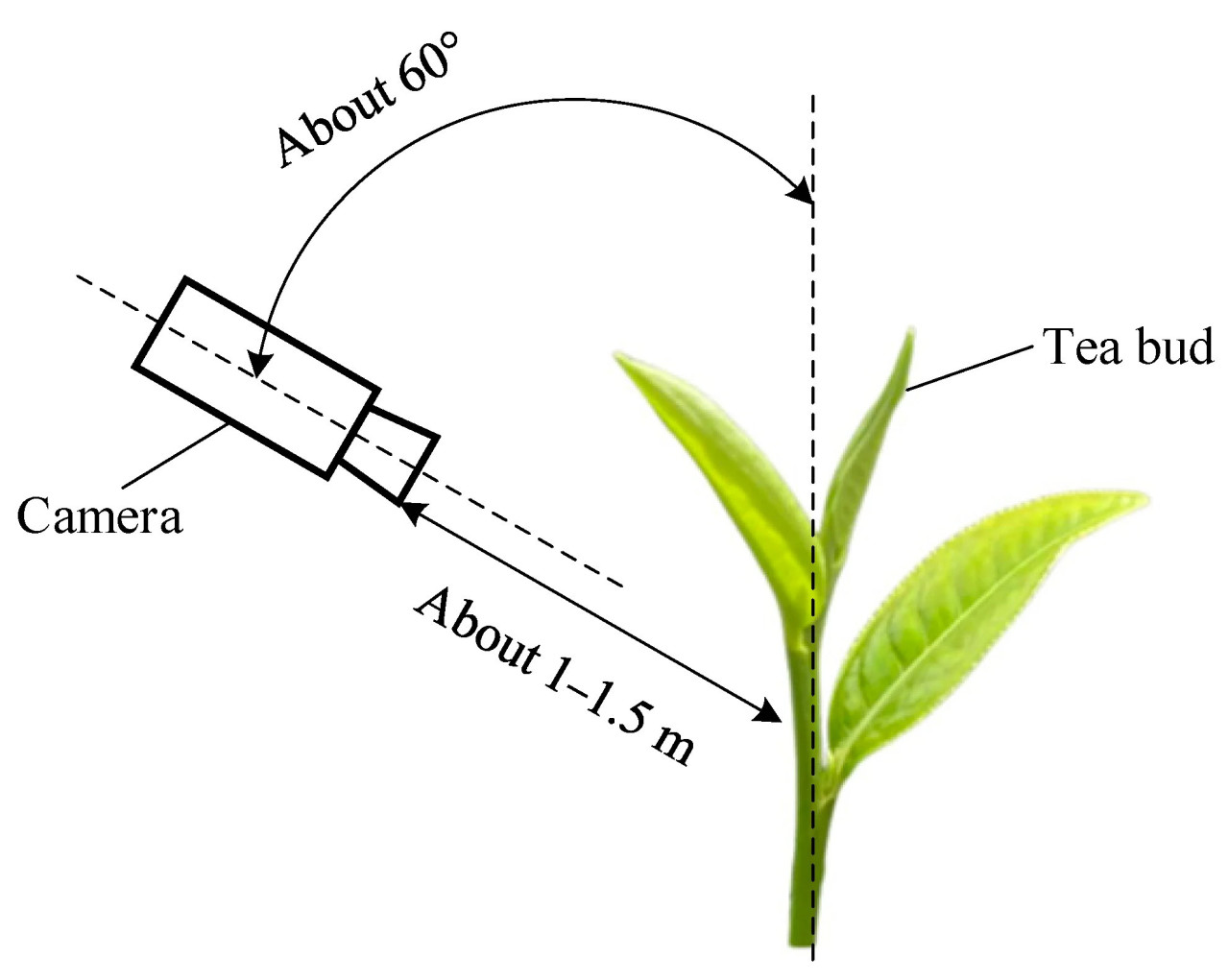
Рисунок 1. Ситуация получения изображений.
2.1.2. Обработка данных
После удаления недействительных изображений разрешение всех оставшихся изображений было уменьшено до 1008 × 756, чтобы сократить время обучения. Кроме того, для улучшения способности к обобщению результатов глубокого обучения изображения были дополнены с использованием горизонтального зеркального отражения. В итоге в наборе данных было 6450 изображений. Они были разделены на три подмножества: 80% (5000) изображений находились в обучающем наборе, и 20% (1250) изображений находились в проверочном наборе; кроме того, 200 изображений были использованы в качестве тестового набора для оценки производительности результатов.
Аннотирование изображений имеет ключевое значение для обработки наборов данных в глубоком обучении, что может создавать информацию о признаках для обучения сети глубокого обучения. Программное обеспечение для аннотирования изображений Labelme было использовано в качестве инструмента аннотирования в этом исследовании для создания регионов чайных почек и зоны срыва [32]. Один побег с одним листом (OBOL) обычно считается высококачественным чаем, поэтому области OBOL были аннотированы как чайные почки в наборе данных изображений чая. Между тем, чтобы локализовать точку срыва и позу чайной почки, зона срыва также была аннотирована. Зона срыва располагалась на стебле чая между первым и вторым листом и была аннотирована 4 линиями. Общий результат аннотирования показан на Рисунке 2.
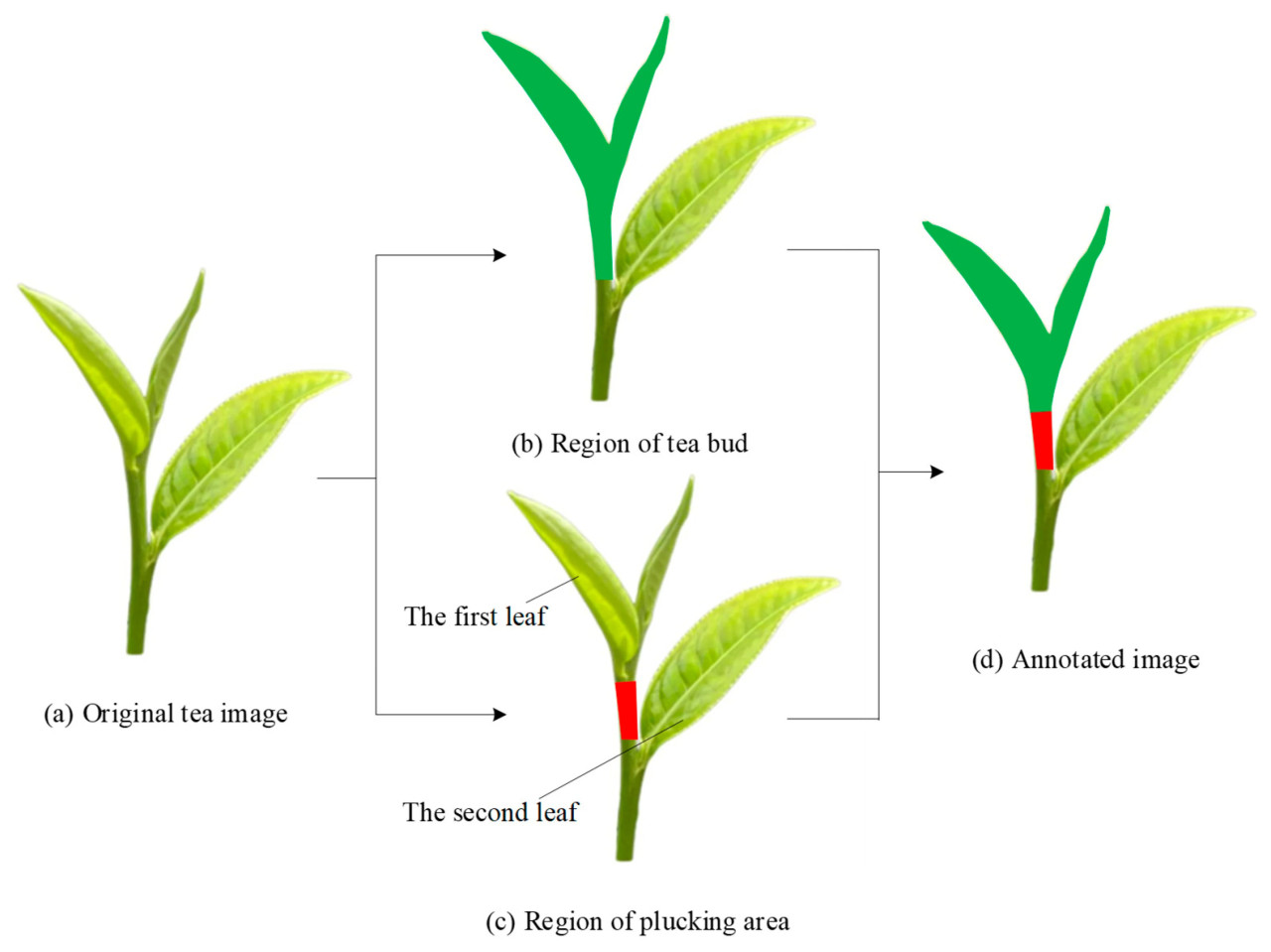
Рисунок 2. Аннотирование изображения чая: (a) исходное изображение; (b) область чайной почки; (c) область зоны срыва; (d) аннотированное изображение.
2.2. Сегментация экземпляров чайной почки и зоны срыва на основе улучшенного YOLOv8-Seg
YOLOv8 — это исключительная модель сети глубокого обучения, выпущенная Ultralytics в 2023 году, которая демонстрирует замечательные возможности в задачах классификации, обнаружения, сегментации и оценки позы. По сравнению с предыдущими версиями, YOLOv8 использует структуру без привязки (anchor-free); вместо предсказания смещения между целью и предопределенной привязкой, он напрямую предсказывает центр цели, тем самым повышая как эффективность, так и точность предсказаний [33]. Модель YOLOv8-seg включает ветви коэффициентов маски и прототипов, позволяя реализовать сегментацию экземпляров. Для размещения разнообразных задач YOLOv8-seg предлагает различные модели на основе масштабных коэффициентов глубины и ширины, а именно YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg и YOLOv8x-seg.
Сетевая структура YOLOv8-seg состоит из входного, основного (backbone), шеи (neck) и головного (head) модулей, как проиллюстрировано на Рисунке 3. Основной модуль состоит из модуля CBS, модуля C2f и модуля SPPF. Размер ядра первого сверточного слоя был изменен с исходного 6 × 6 на 3 × 3 на основе сети YOLOv5. Более того, все модули C3 были заменены модулями C2f, что привело к дальнейшему повышению вычислительной эффективности. Модуль шеи используется для слияния признаков на картах признаков, сгенерированных основной сетью. В головном компоненте используется развязанная структура, где несколько параллельных ветвей используются для извлечения признаков категории, позиционных признаков и признаков маски соответственно.
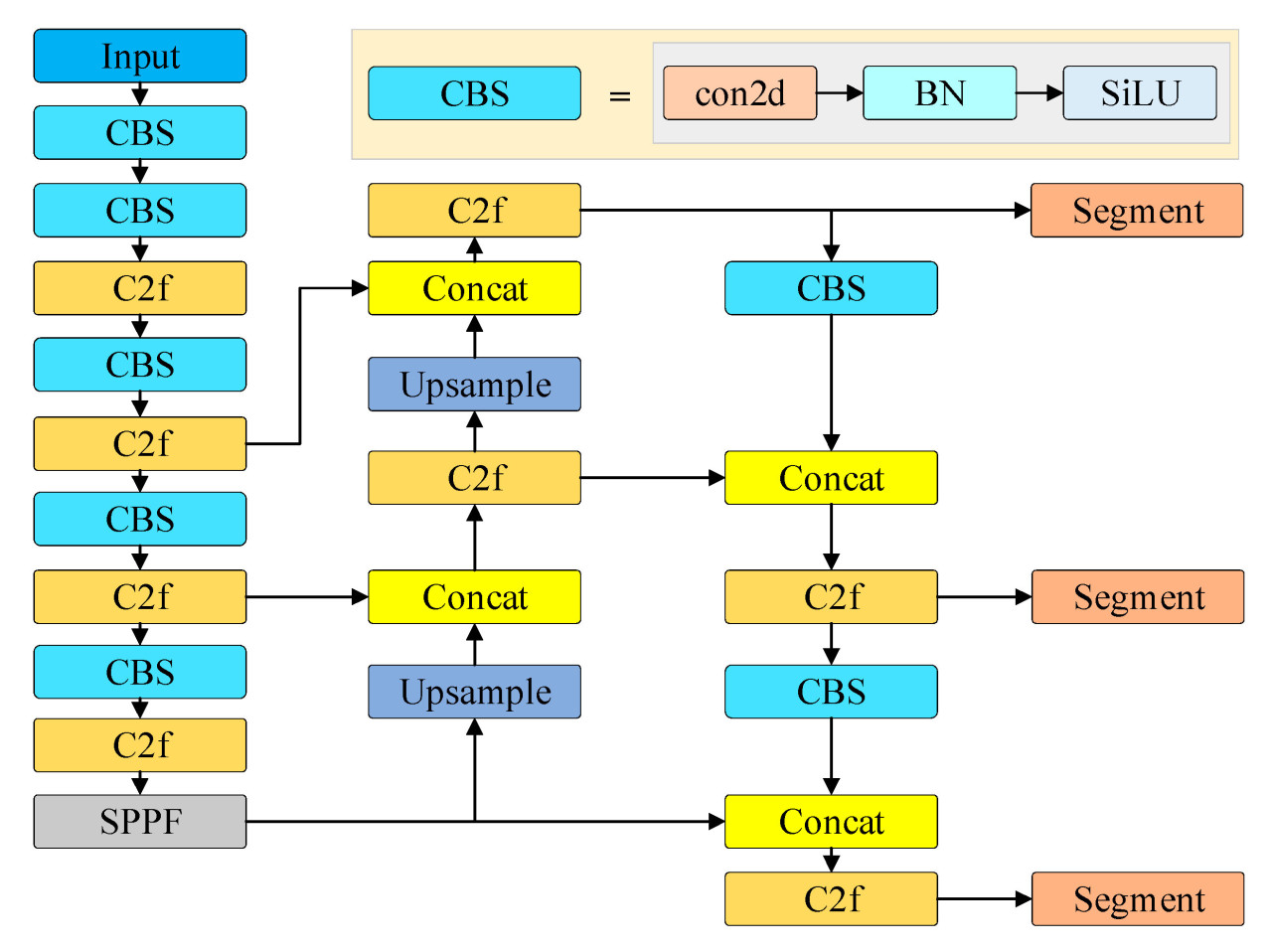
Рисунок 3. Структура оригинальной сети YOLOv8-seg.
Чтобы повысить эффективность и точность сегментации сети YOLOv8-seg и учесть изменчивые формы чайных почек и зон срыва в этом исследовании, в данной работе был предложен улучшенный алгоритм под названием LDS-YOLOv8-Seg. Во-первых, чтобы уменьшить чрезмерное количество параметров в головном модуле модели YOLOv8-seg, была использована общая свертка (shared convolution) для эффективного сокращения параметров и повышения эффективности сегментации. Дополнительно, чтобы компенсировать потенциальное снижение точности, возникающее из-за сокращения параметров, групповая нормализация (Group Normalization, GN) была принята в качестве замены пакетной нормализации (Batch Normalization, BN) для целей нормализации. Во-вторых, в модуль SPPF был добавлен механизм внимания для улучшения способности модели к извлечению признаков, что позволяет основному модулю уделять приоритетное внимание наиболее релевантным частям входа. Наконец, была введена деформируемая сверточная сеть версии 2 (Deformable Convolution network version 2, DCNv2) для эффективной адаптации к нерегулярным и изменчивым характеристикам формы сегментируемого объекта, тем самым получая более сложную пространственную информацию. Структура сети LDS-YOLOv8-Seg показана на Рисунке 4.
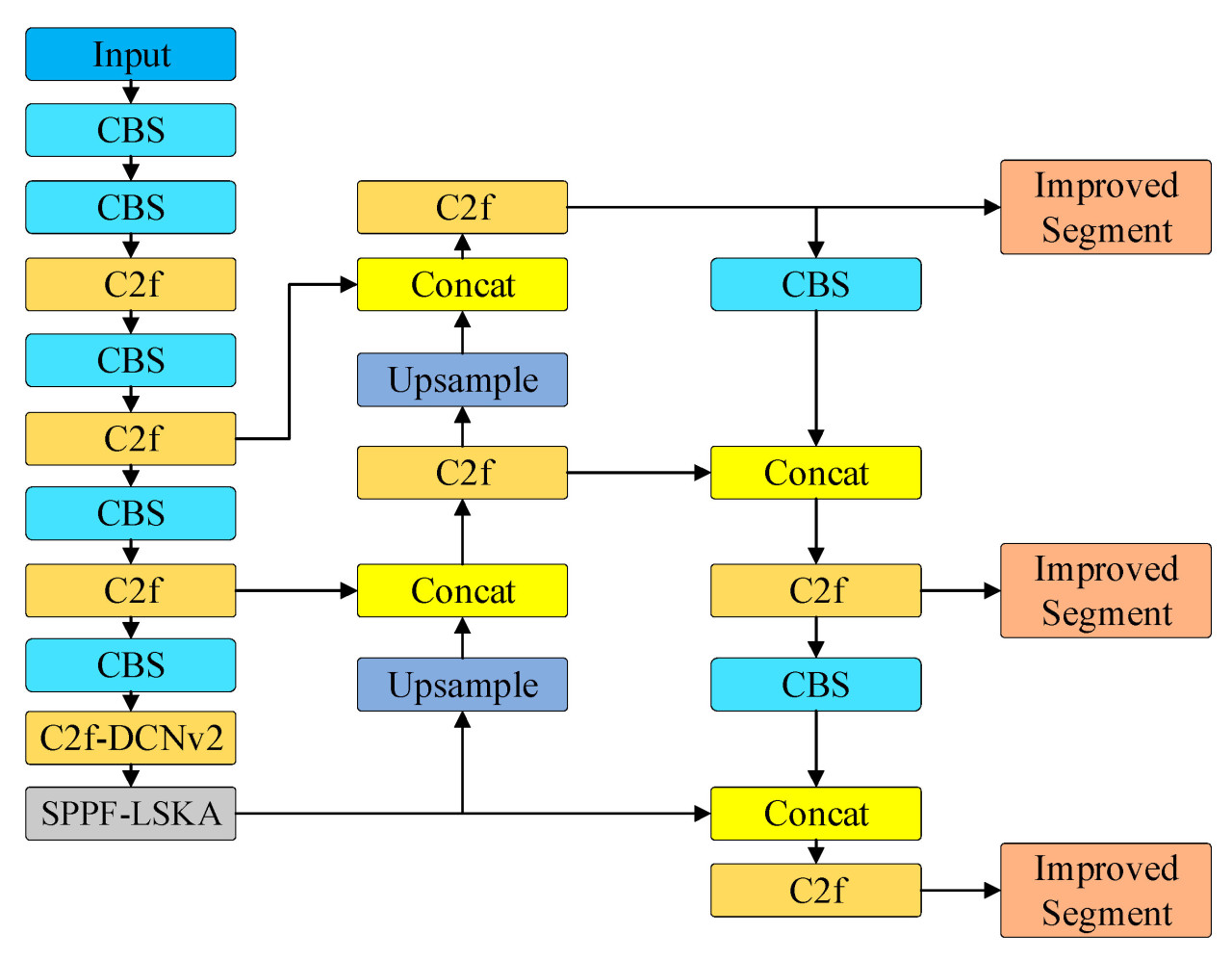
Рисунок 4. Структура сети LDS-YOLOv8-Seg.
2.2.1. Улучшенная сегментационная головка
Модуль головки является ключевым компонентом модели YOLOv8-seg, который отвечает за окончательное обнаружение объектов, классификацию и сегментацию. Он состоит из четырех типов ветвей, причем первая ветвь предназначена для предсказания прототипа и в основном состоит из слоя повышающей дискретизации (up-sampling). Кроме того, есть три ветви для карт признаков разных размеров: одна для предсказания регрессии ограничивающей рамки, другая для предсказания классификации и последняя ветвь для предсказания коэффициентов маски. Ветви предсказания регрессии и классификации обе состоят из двух модулей CBS и отдельного слоя conv2d, способствуя вычислению потерь регрессии и классификации соответственно. Модуль CBS включает слой conv2d, слой BatchNorm2d (BN) и функцию активации SiLU.
Оригинальная структура головки YOLOv8-seg, как показано на Рисунке 5, содержит большое количество параметров, что приводит к высоким вычислительным затратам. В этом исследовании модель была облегчена путем введения общей свертки и свертки 1 × 1 для уменьшения объема вычислений. Улучшенная структура головки YOLOv8-seg показана на Рисунке 6, где все белые модули используют общие свертки, включая модули CGS и модули Conv2d для классификации и регрессии. В ветвях регрессии и классификации выходные карты признаков компонента шеи сначала подвергаются сверточным операциям с использованием общих сверточных блоков 1 × 1 (CGS), а затем последующей обработке через два общих сверточных блока 3 × 3 (CGS) для классификации и обнаружения. Результаты регрессии ограничивающей рамки разных масштабов масштабируются с использованием масштабного коэффициента после вычисления регрессии, чтобы решить проблему несоответствия масштабов целей, обнаруженных разными ветвями регрессии, из-за общей свертки. Задача сегментации выполняется на уровне пикселей с акцентом на вычисление более уточненных пространственных признаков. Чтобы обеспечить точность сегментации, эта ветвь воздерживается от использования общих сверток. Модуль групповой нормализации (Group Normalization, GN), предложенный Ву и др., продемонстрировал улучшение точности вычислений в задачах обнаружения и сегментации по сравнению с пакетной нормализацией (Batch Normalization, BN) [34]. Использование общей свертки неизбежно приводит к некоторой степени снижения точности. Поэтому в этом исследовании групповая нормализация (GN) была использована в качестве замены пакетной нормализации (BN) внутри CBS, что привело к формированию модуля CGS для повышения точности окончательного вычисления. Более того, вычислительная нагрузка модели может быть дополнительно снижена за счет свертки 1 × 1.
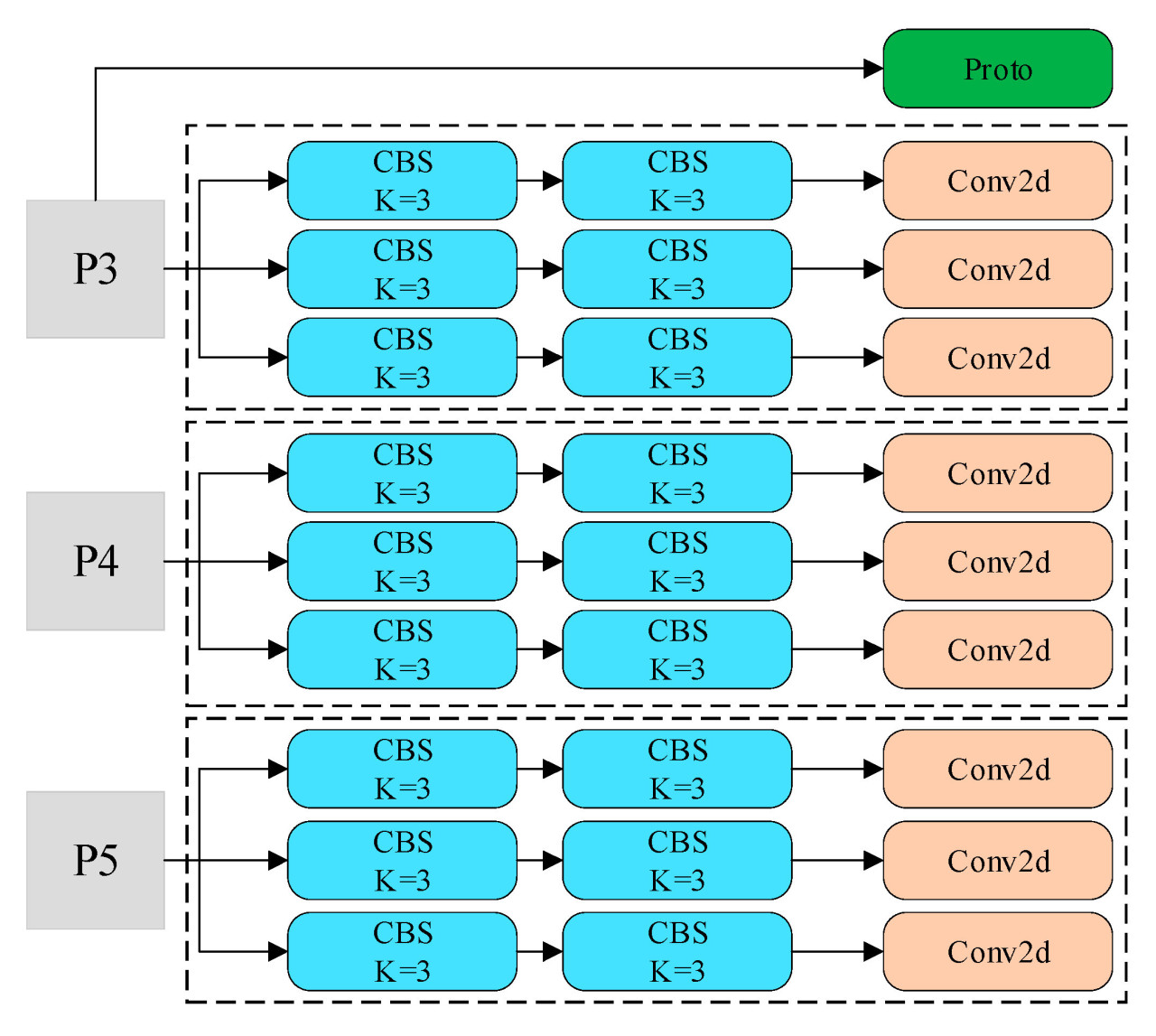
Рисунок 5. Оригинальная структура головки YOLOv8-seg.
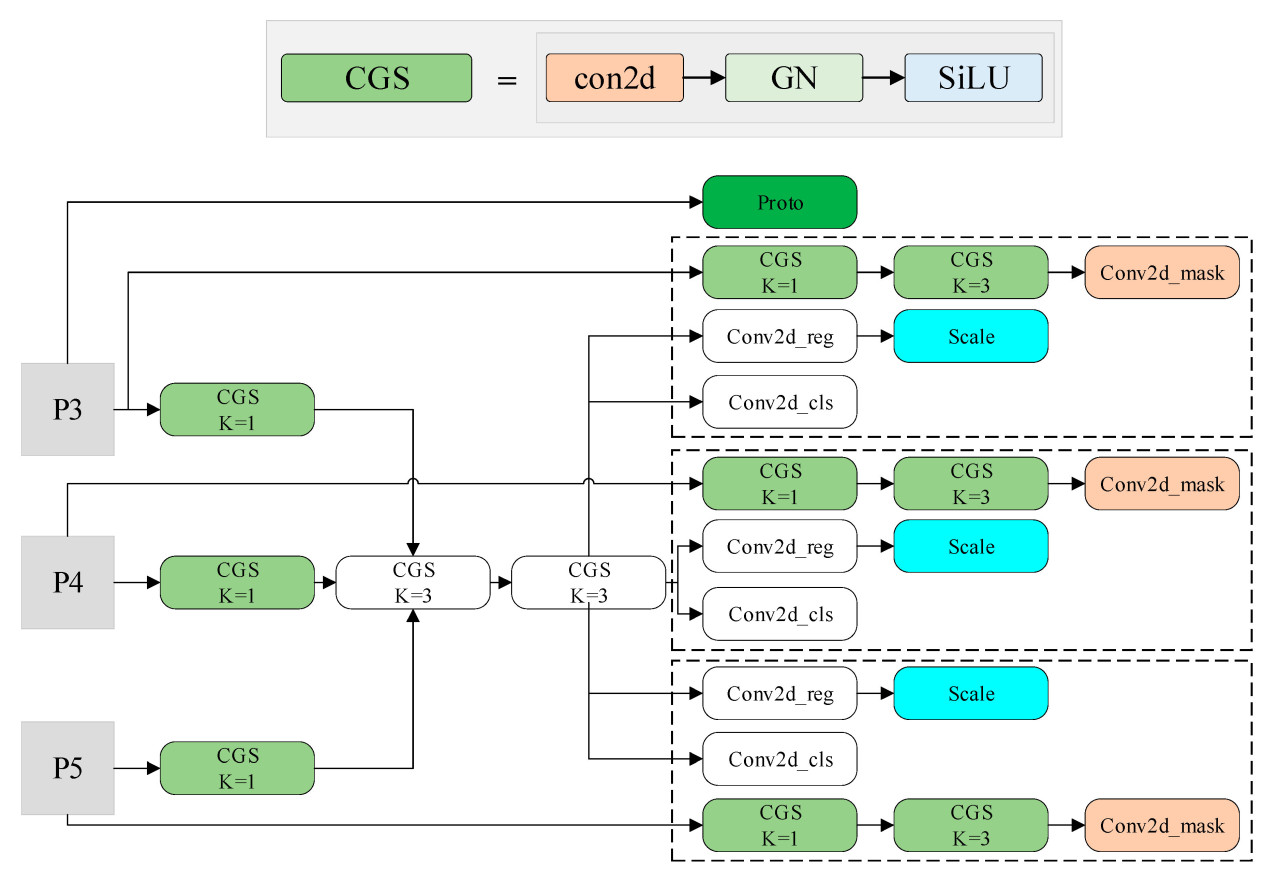
Рисунок 6. Улучшенная структура головки YOLOv8-seg.
2.2.2. Модуль SPPF-LSKA
Механизм внимания имитирует когнитивный процесс человека в распределении внимания при обработке информации. Назначая различные веса каждому элементу входных данных, он позволяет модели сосредоточиться на наиболее релевантных признаках, тем самым повышая выразительность и способность к обобщению модели, одновременно уменьшая ненужные вычисления. Большое разделяемое ядро внимания (large separable kernel attention, LSKA) — это механизм пространственного внимания, улучшенный на основе большого ядра внимания (large kernel attention, LKA). Структуры LKA и LSKA показаны на Рисунке 7, где ⊗ представляет произведение Адамара; модуль LKSA получается путем разложения двумерных сверточных ядер глубинной свертки и глубокой расширенной свертки в модуле LKA на два каскадных горизонтальных и вертикальных одномерных разделяемых сверточных ядра, тем самым еще больше уменьшая как использование памяти, так и вычислительную сложность. LSKA демонстрирует устойчивую длинную зависимость в изображении, пространственную и канальную адаптируемость, а также исключительную масштабируемость чрезвычайно большого ядра.
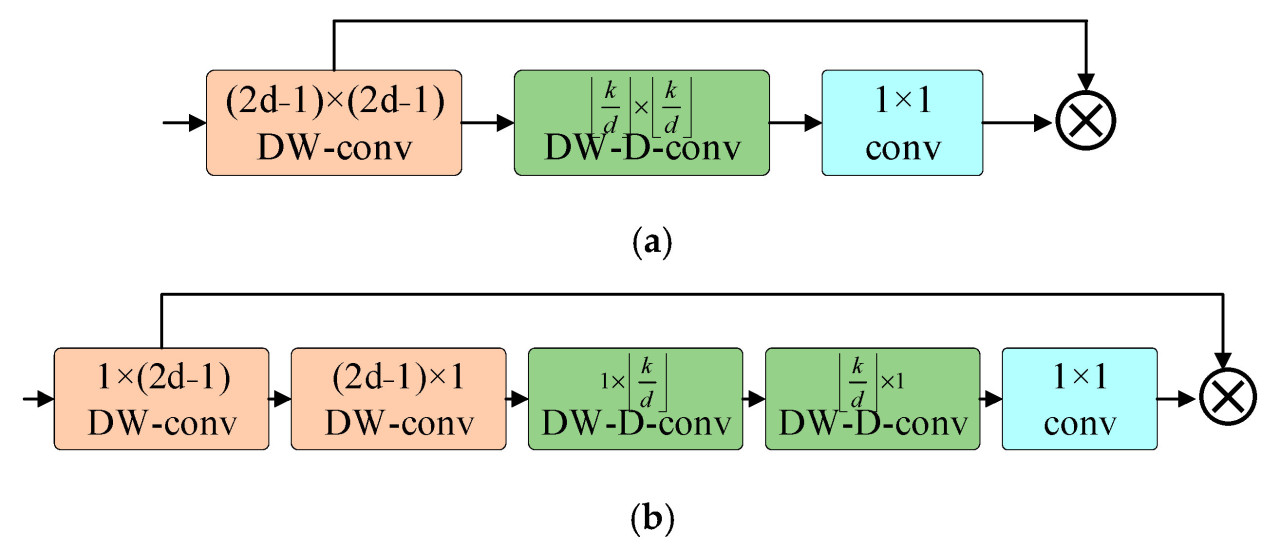
Рисунок 7. Структура модуля LKA и модуля LSKA: (a) модуль LKA; (b) модуль LSKA.
LSKA изначально использует свертку для извлечения горизонтальных и вертикальных признаков из входной карты признаков. Впоследствии расширенные свертки с разными коэффициентами расширения используются для дальнейшего улучшения извлечения признаков, что позволяет охватывать более широкое рецептивное поле и получать дополнительную информацию о признаках без дополнительных вычислительных затрат. Полученные признаки в конечном итоге объединяются через слой свертки 1 × 1 для создания окончательной карты внимания, которая затем подвергается произведению Адамара с исходной входной картой признаков.
Модуль LSKA был включен после слоя Concat модуля SPPF в этом исследовании. Более того, слой BN был заменен слоем GN в модуле CBS для создания модуля CGS. Модуль SPPF-LSKA был сформирован посредством этих вышеупомянутых улучшений. Улучшенная структура показана на Рисунке 8. Способность к слиянию признаков модуля SPPF может быть улучшена с помощью этих улучшений, уменьшая влияние признаков фона на обнаружение чайных почек и зоны срыва и повышая точность модели в сложных условиях.
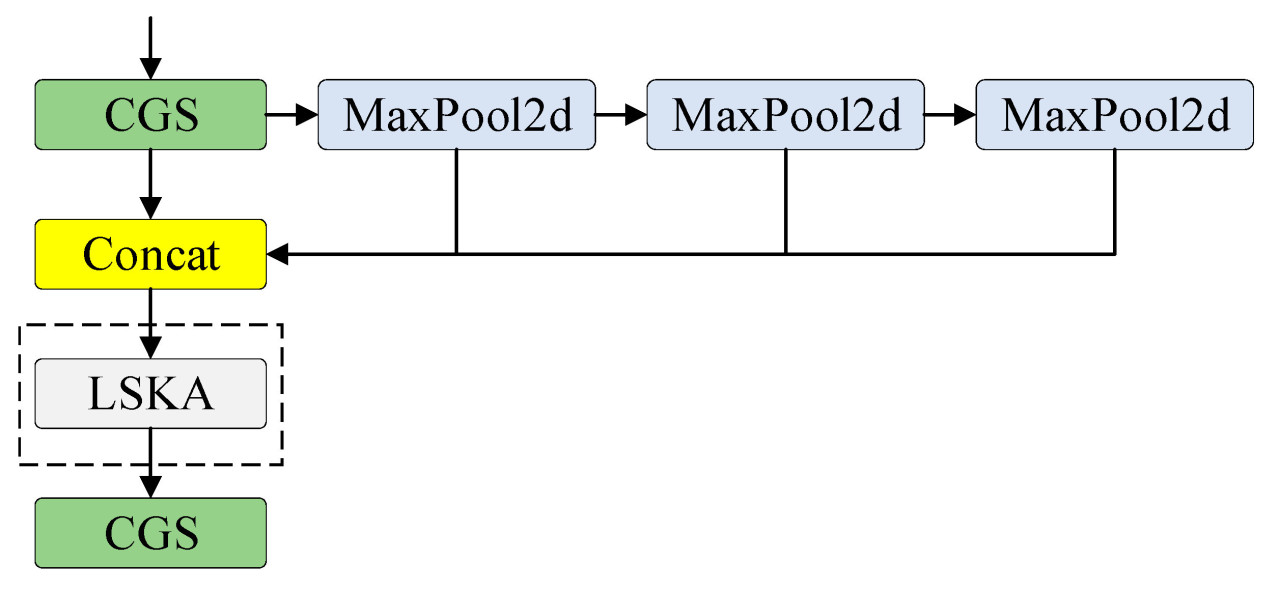
Рисунок 8. Структура модуля SPPF-LSKA.
2.2.3. Модуль C2f-DCNv2
Традиционная свертка хорошо справляется с обработкой статических или регулярных целей; однако она может столкнуться с трудностями при работе с нерегулярными и изменчивыми формами чайных почек, а также значительными различиями в размере. По сравнению с традиционными сверточными сетями, деформируемая сверточная сеть (deformable convolution network, DCN) демонстрирует лучшие возможности распознавания для разнообразных форм и размеров чайных почек за счет динамической адаптации пространственных и структурных характеристик цели. Деформируемая сверточная сеть версии 1 (DCNv1) вводит обучаемые смещения для адаптации к деформации объектов на изображении; однако новое положение точки выборки после смещения может выйти за пределы идеального диапазона смещения. Чтобы устранить это ограничение, в DCNv2 каждая выборка не только изучает смещение, как в DCNv1, но и модулирует его с использованием изученных параметров модуляции. Если конкретно, DCNv2 вводит скаляр модуляции Δ𝑚𝑘 в процесс свертки, который представляет изменение амплитуды признака на k-й позиции. Это позволяет сети уделять приоритетное внимание ключевым признакам, уменьшать помехи от нерелевантной информации и, как следствие, повышать производительность модели. Структура DCNv2 показана на Рисунке 9.
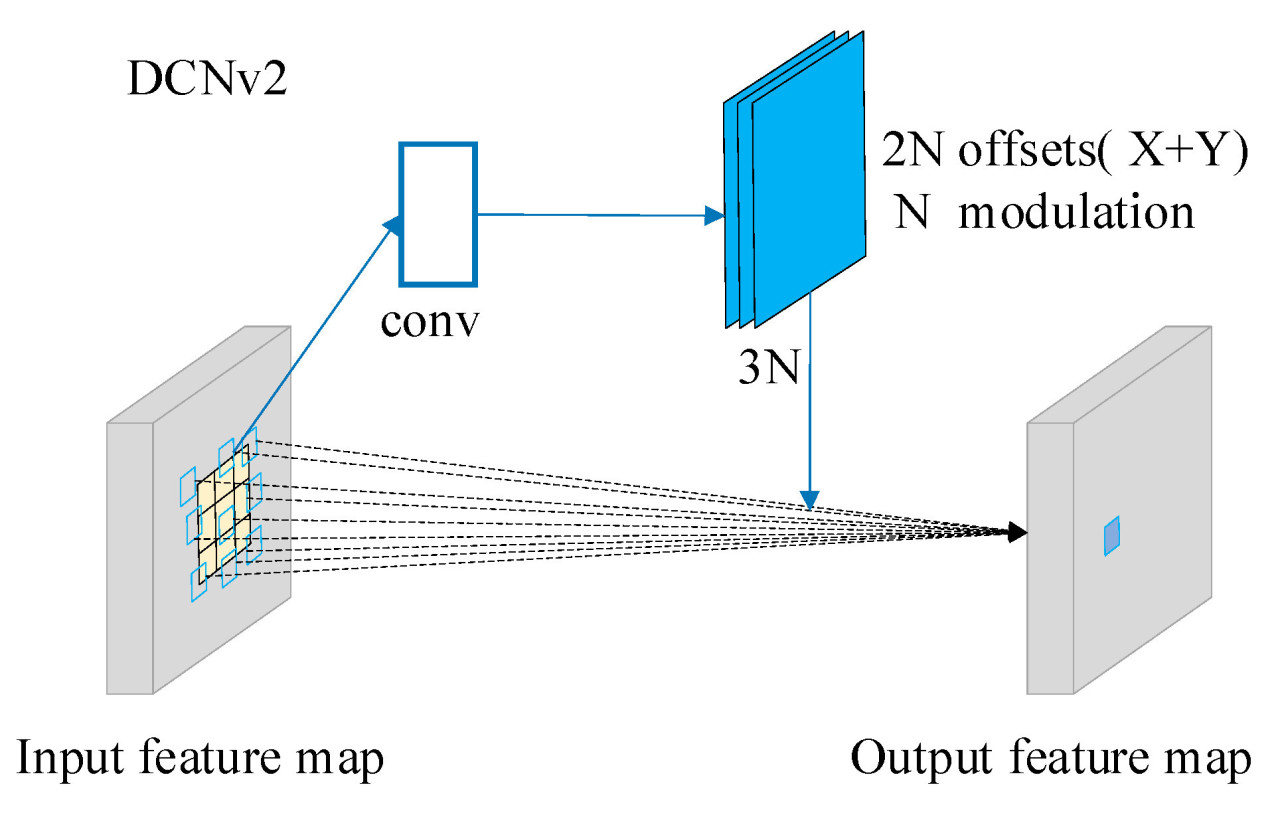
Рисунок 9. Структура модуля DCNv2.
Деформационные характеристики цели в глубоких слоях более сложны в сетях глубокого обучения. Поэтому в этом исследовании сверточная операция в последнем слое, C2f, основной сети была заменена на DCNv2, и был предложен модуль C2f-DCNv2. Если конкретно, свертка в структуре узкого места (bottleneck) C2f была специально заменена на DCNv2, что позволяет более гибко выбирать входные карты признаков и лучше изучать масштаб и деформации цели. После сверточного слоя было использовано остаточное соединение (residual connection) для слияния выходной карты признаков с входной картой признаков. Структура улучшенного C2f-DCNv2 показана на Рисунке 10, где ⊕ представляет остаточное соединение.
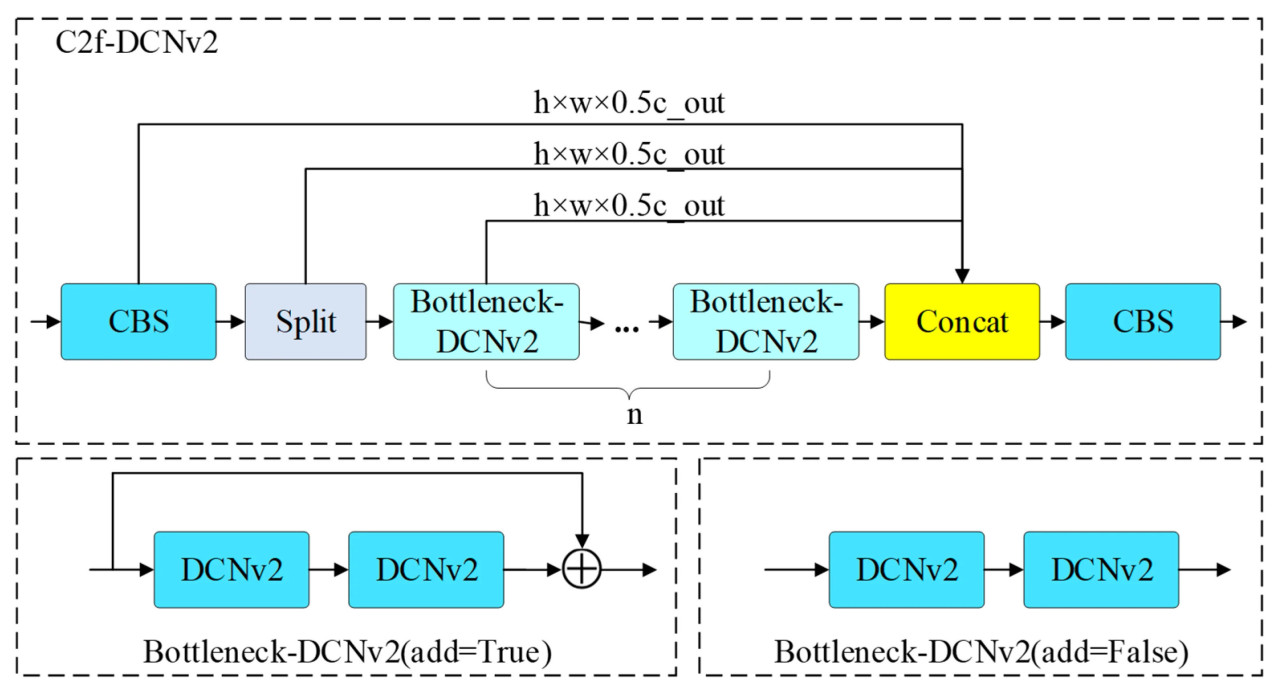
Рисунок 10. Структура улучшенного модуля C2f-DCNv2.
2.3. Сопоставление чайной почки с ее точкой срыва
После сегментации экземпляров чайных изображений были получены маска чайной почки и маска зоны срыва. Но каждая маска чайной почки и маска зоны срыва, полученные от сегментации экземпляров, были одиночными масками; они не были связаны друг с другом. Точка срыва и поза чайной почки — это то, что мы хотели получить в деятельности по сбору чая. Чтобы получить эту информацию, сначала необходимо сопоставить зону срыва и чайную почку на одном чайном растении. Точное сопоставление зоны срыва и чайной почки является ключевым предварительным условием для получения оптимальной позы срыва. Повышение точности сопоставления не только улучшает общую эффективность сопоставления, но и существенно способствует точным расчетам позы срыва чайной почки. Более того, это способствует фактическому высокоточному механизированному сбору чайных почек. Были предложены два алгоритма для выполнения сопоставления, включая метод сопоставления ближайшей точки и метод сопоставления точки в диапазоне.
2.3.1. Локализация точки срыва
Чтобы достичь сопоставления зоны срыва и чайной почки, сначала должна быть вычислена точка срыва. Маски зоны срыва, которые мы получили от сегментации экземпляров, представляли собой ряд матриц масок. Каждый элемент матрицы был вероятностью того, что позиция исходного изображения принадлежит зоне срыва. Что касается зоны срыва, координаты точки срыва могли быть получены путем вычисления центроида матрицы маски зоны срыва. Центроиды матрицы маски могут быть вычислены по уравнениям (1) и (2).
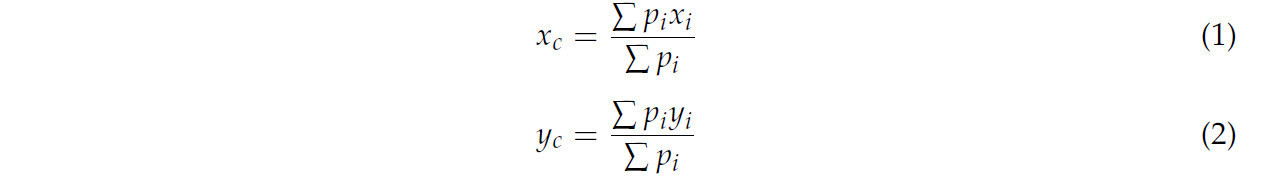
где 𝑥𝑐 и 𝑦𝑐 представляют координаты ширины и высоты центроида, 𝑥𝑖 и 𝑦𝑖 представляют координаты ширины и высоты каждого элемента в матрице маски, а 𝑝𝑖 представляет вероятность того, что позиция элемента принадлежит зоне срыва.
Точка срыва могла быть получена из вышеуказанного вычисления, и она определенно расположена в зоне срыва. Чтобы сопоставить зону срыва с чайной почкой, также должна быть вычислена характерная точка области чайной почки. Ради удобства центральная точка ограничивающей рамки чайной почки была выбрана в качестве характерной точки, которая может быть вычислена по уравнениям (3) и (4).
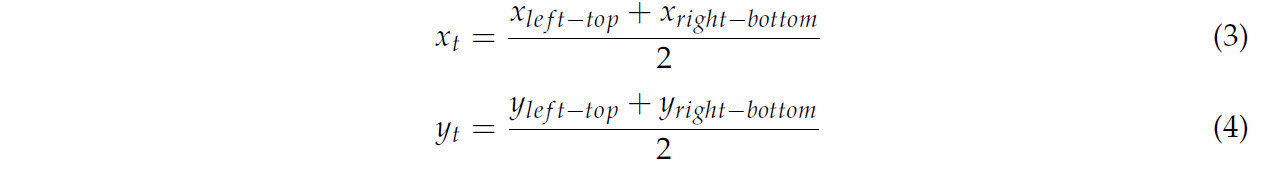
где 𝑥𝑙𝑒𝑓𝑡−𝑡𝑜𝑝 и 𝑦𝑙𝑒𝑓𝑡−𝑡𝑜𝑝 представляют координаты ширины и высоты левой верхней точки ограничивающей рамки чайной почки, 𝑥𝑟𝑖𝑔ℎ𝑡−𝑏𝑜𝑡𝑡𝑜𝑚 и 𝑦𝑟𝑖𝑔ℎ𝑡−𝑏𝑜𝑡𝑡𝑜𝑚 представляют координаты ширины и высоты правой нижней точки ограничивающей рамки чайной почки.
Центральная точка ограничивающей рамки чайной почки и центроид зоны срыва показаны на Рисунке 11.
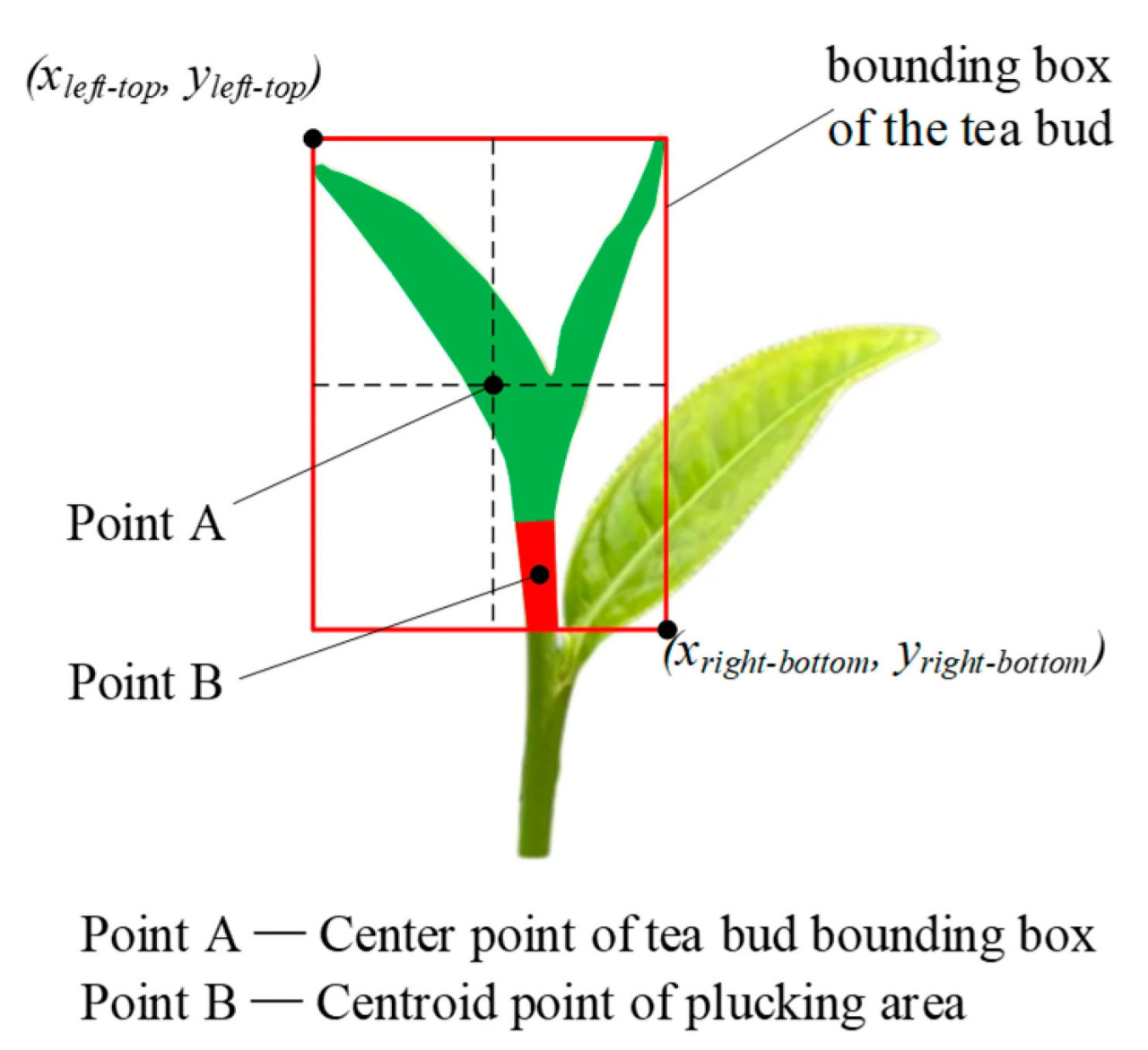
Рисунок 11. Схематическая диаграмма определения характерных точек.
2.3.2. Метод сопоставления ближайшей точки
Метод сопоставления ближайшей точки (nearest point matching method, NPM) был предложен для реализации сопоставления точки срыва и чайной почки в этом исследовании. Два набора точек были получены с помощью вышеуказанных вычислений. Набор точек A представлял собой набор точек срыва чайной почки. Набор точек B представлял собой набор центральных точек ограничивающих рамок чайных почек. Как показано на Рисунке 12, синие точки принадлежат набору точек A, а красные точки принадлежат набору точек B. Согласно анализу на наборе данных изображений чая, точка срыва чайной почки ближе к центральной точке своей ограничивающей рамки, чем к ограничивающей рамке другой чайной почки. Поэтому основная идея метода сопоставления ближайшей точки заключается в том, чтобы сопоставить каждый член набора точек A с ближайшим членом набора точек B. Более подробные процедуры для метода сопоставления ближайшей точки можно увидеть в Алгоритме 1.
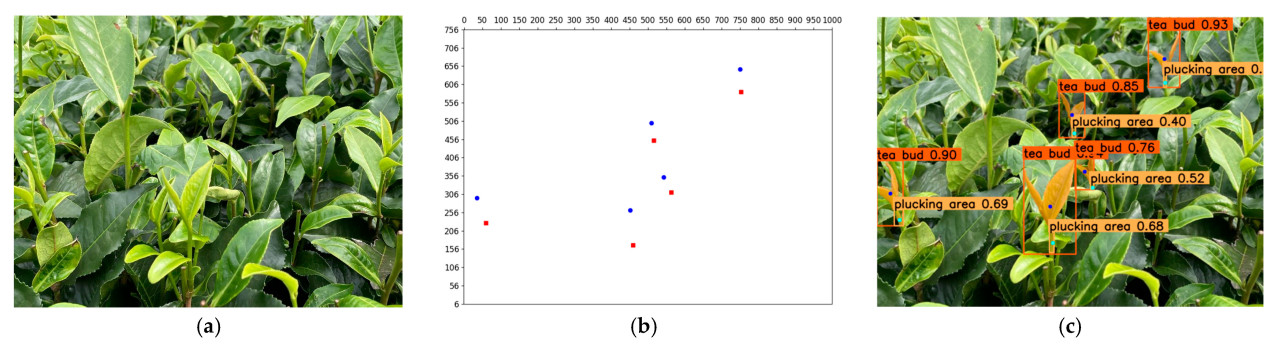
Рисунок 12. Метод сопоставления ближайшей точки (NPM): (a) исходное изображение; (b) два набора характерных точек; (c) сопоставленные наборы точек изображения.

2.3.3. Метод сопоставления точки в диапазоне
Вообще говоря, центроид зоны срыва расположен внутри ограничивающей рамки чайной почки, потому что зона срыва является частью чайной почки. Поэтому метод сопоставления точки в диапазоне (point in range matching method, PIRM) может быть использован для сопоставления точки срыва с центральной точкой ограничивающей рамки чайной почки. Как показано на Рисунке 3, координата ширины x точки срыва была расположена между левой и правой границами чайной почки. Аналогично, координата высоты y точки срыва была расположена между верхней и нижней границами чайной почки. Основная идея PIRM заключается в поиске того, какая ограничивающая рамка чайной почки удовлетворяет условиям уравнений (5) и (6).
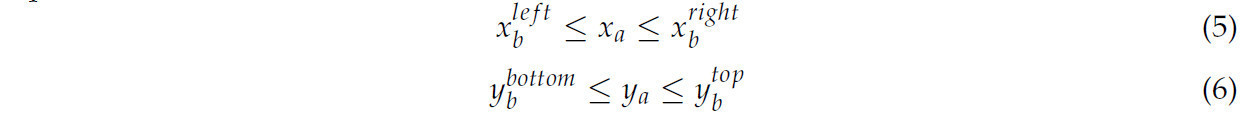
где 𝑥𝑎 и 𝑦𝑎 обозначают координаты ширины и высоты точки срыва, 𝑥𝑙𝑒𝑓𝑡𝑏 и 𝑥𝑟𝑖𝑔ℎ𝑡𝑏 обозначают левые и правые координаты ограничивающей рамки, а 𝑦𝑏𝑜𝑡𝑡𝑜𝑚𝑏 и 𝑦𝑡𝑜𝑝𝑏 обозначают нижние и верхние координаты ограничивающей рамки. Более подробные процедуры для PIRM можно увидеть в Алгоритме 2.

2.4. Определение позы срыва
Как правило, чайные почки растут вверх из-за характеристик апикального доминирования и гелиотропизма. Во многих исследованиях механизированный сбор чайных листьев осуществлялся путем вертикального опускания концевого эффектора сбора для достижения заданного положения срыва [35,36,37]. На практике, однако, направление роста чайных почек не является полностью прямым вверх из-за влияния положения посадки на чайном кусте, ситуации роста стебля, на котором находится чайная почка, и так далее. Чайные почки, расположенные на краях чайных кустов, особенно, могут расти даже горизонтально. Поэтому, если манипулятор сбора просто движется прямо вниз к точке срыва, чтобы сорвать чайную почку, это может привести к неудаче или даже повреждению чайного растения.
Ввиду вышеуказанных проблем был предложен метод для определения направления срыва чайной почки. Направление срыва противоположно направлению роста чайной почки. Следовательно, манипулятор сбора может двигаться вдоль направления срыва, полученного в этом исследовании, чтобы достичь лучшего срыва, избегая ошибок или даже неудач, вызванных прямым движением вниз.
Учитывая вышеуказанные исследования, как только точка срыва сопоставлена с центральной точкой ограничивающей рамки чайной почки, направление срыва чайной почки может быть определено.
2.4.1. Определение двумерной позы срыва
Сначала было определено двумерное направление срыва, то есть направление срыва на изображении чайной почки. Как показано на Рисунке 13, направление от точки срыва к центральной точке ограничивающей рамки чайной почки является направлением роста. Обратно, направление от центральной точки ограничивающей рамки чайной почки к точке срыва является направлением срыва. Рисунок 13b представляет собой частично увеличенную деталь рамки на Рисунке 13a. Уравнение (7) показывает расчетную формулу направления роста.
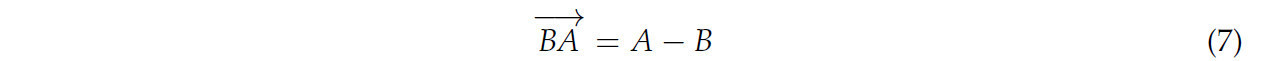
где A — координата центральной точки ограничивающей рамки чайной почки, а B — координата точки срыва.
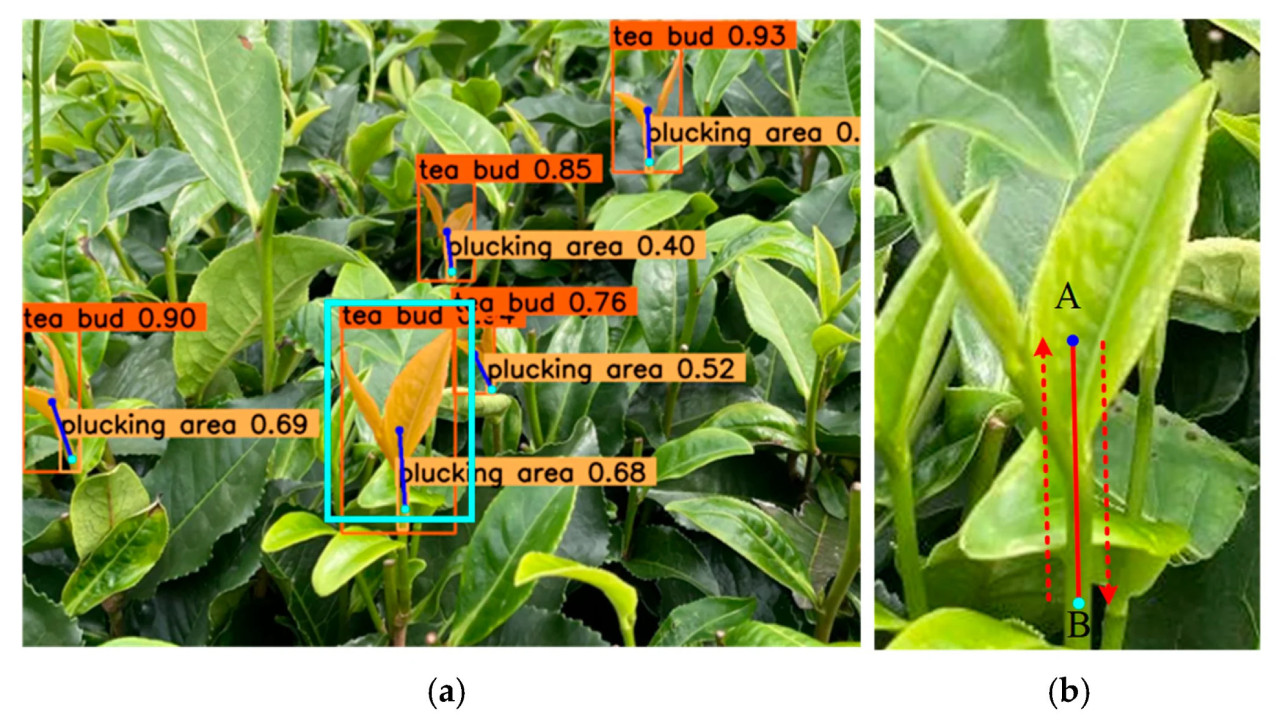
Рисунок 13. Определение двумерной позы срыва: (a) поза срыва; (b) направление роста и направление срыва.
2.4.2. Определение трехмерной позы срыва
Двумерное направление срыва не может быть использовано непосредственно в операции срыва чайной почки. Необходимо вычислить трехмерное направление срыва на основе двумерного направления, полученного из вышеуказанного исследования. Камера глубины (например, Intel Realsense, Microsoft Kinect и так далее) может быть использована для получения информации о глубине каждой точки на чайной почке, что может помочь нам определить трехмерное местоположение каждой чайной почки. Трехмерное направление срыва может быть получено, когда двумерная линия направления сопоставлена с пространственными координатами соответствующих точек.
Как показано на Рисунке 14, центральная точка ограничивающей рамки чайной почки не обязательно расположена на области чайной почки, и пространственные координаты точек на областях чайных почек значительно различаются. Но точка срыва определенно расположена в зоне срыва, потому что она является центроидом этой области, а зоны срыва обычно приближаются к прямоугольникам. Между тем, двумерная линия направления срыва чайной почки определенно проходит через зону срыва. Поэтому сначала вычисляются точки пересечения двумерной линии направления срыва и зоны срыва, а затем аппроксимированная прямая линия этих точек может быть использована в качестве трехмерной линии направления срыва.
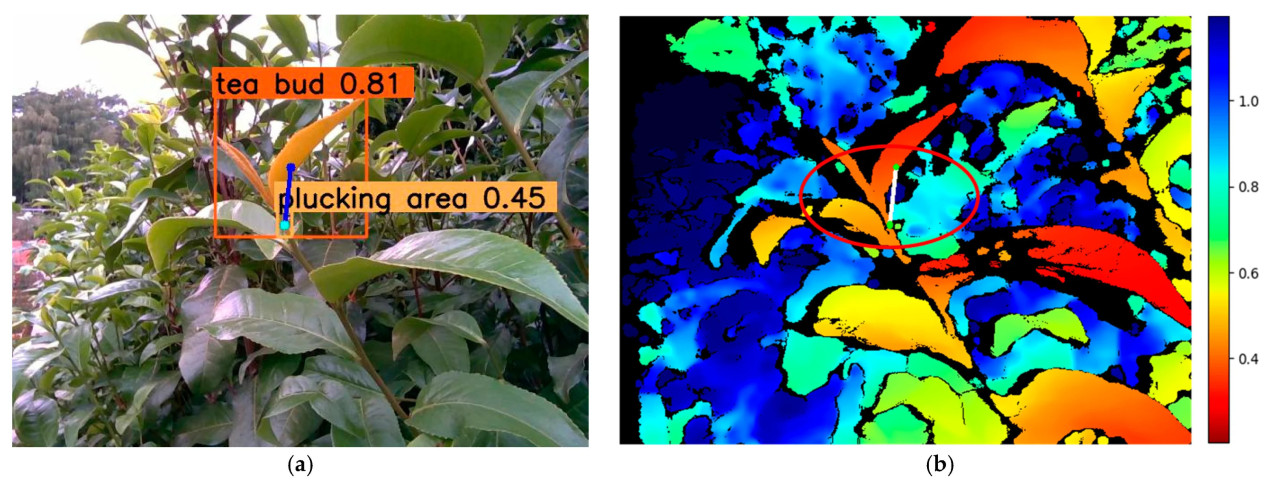
Рисунок 14. Характерные точки целевых областей. (a) Результат двумерного изображения. (b) Результат изображения глубины (метры).
Уравнение (8) представляет трехмерную линию направления срыва; его уравнение преобразования можно увидеть как уравнения (9) и (10).
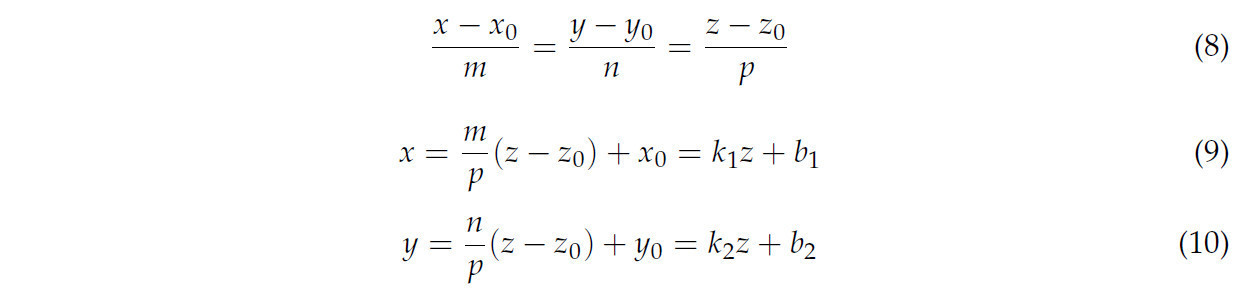
где параметры k1, b1, k2 и b2 были преобразованы с использованием уравнений (11)–(14).
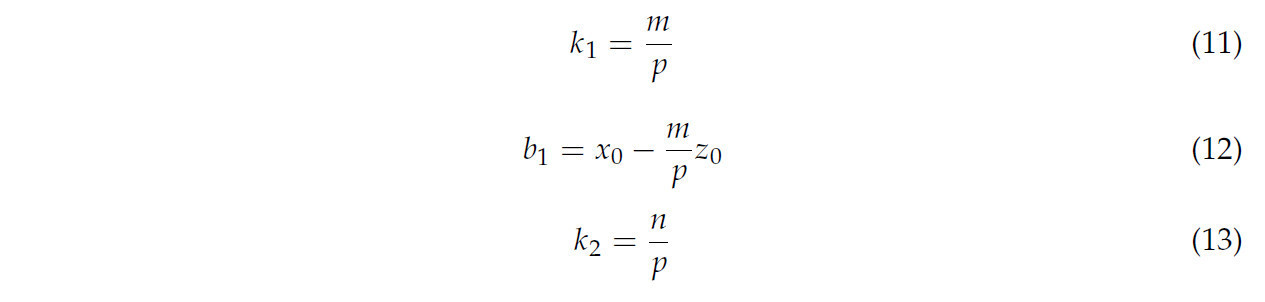
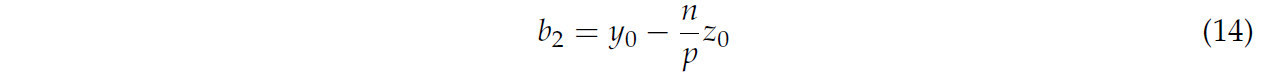
Следовательно, пространственную линию можно рассматривать как пересечение двух плоскостей в уравнениях (9) и (10). Метод наименьших квадратов был использован для аппроксимации пространственной линии, и когда сначала был завершен остаточный анализ, сумма квадратов остатков была рассчитана, как в уравнениях (15) и (16).
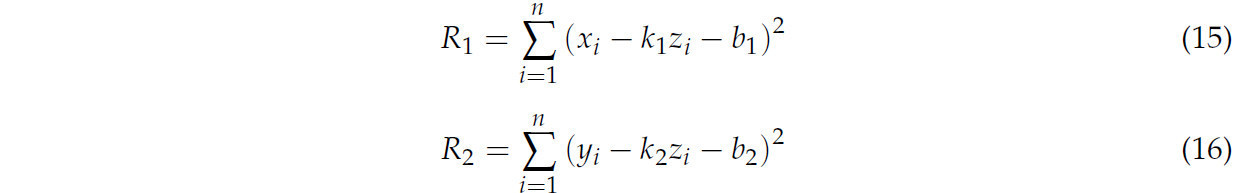
где n представляет количество точек. Чтобы получить минимальный остаток, частные производные уравнений (15) и (16) были рассчитаны, как в уравнениях (17)–(20).
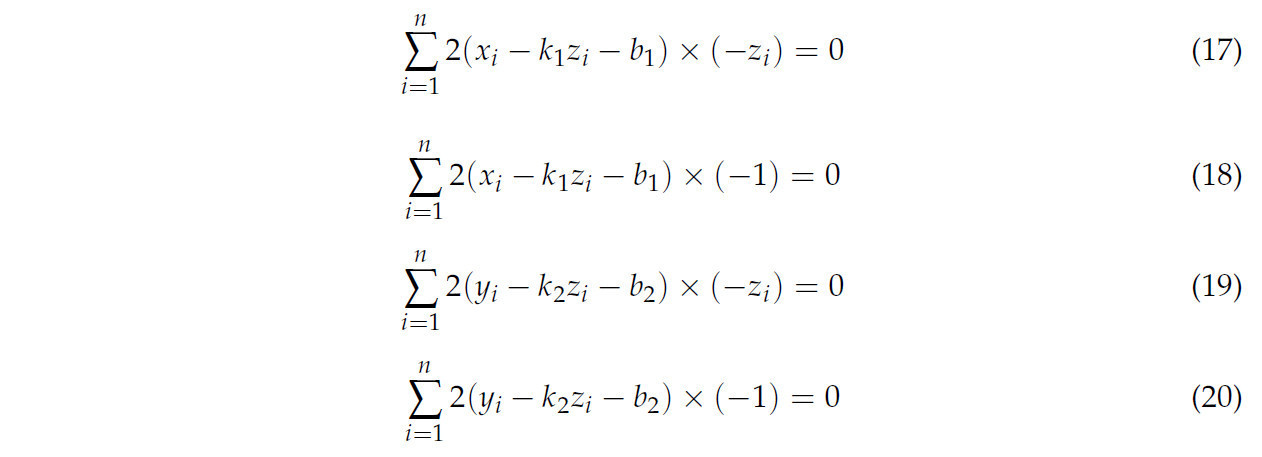
Из уравнений (17)–(20) аппроксимированное значение k1, b1, k2 и b2 может быть рассчитано, как в уравнениях (21)–(24).
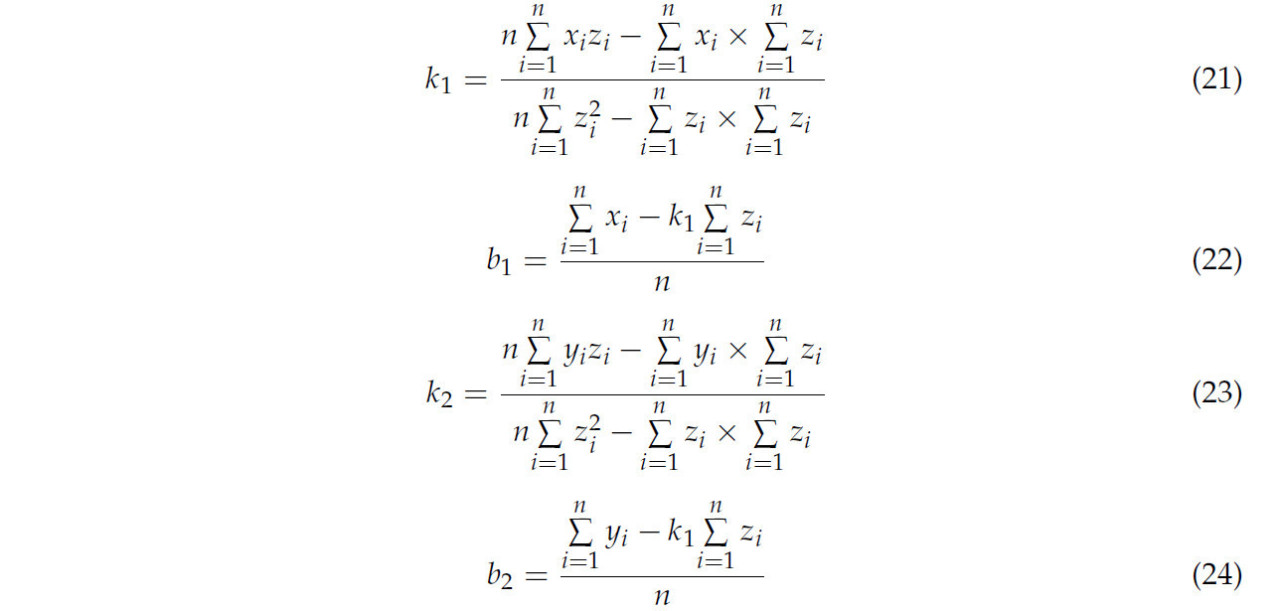
Из вышеуказанных уравнений может быть получена аппроксимированная линия трехмерного направления срыва.
Как только трехмерное направление срыва получено, направление движения манипулятора сбора может быть рассчитано с использованием преобразования координат. Манипулятор может быть направлен для движения к точке срыва вдоль направления срыва, чтобы сорвать чайную почку.
2.5. Общее резюме метода
Подводя итог, данное исследование сосредоточено на определении точки срыва и позы срыва чайной почки, которые являются ключевыми аспектами реализации механизированного сбора чая. Рабочий процесс предложенного метода показан на Рисунке 15. Во-первых, был создан набор данных изображений чайных почек путем фотографирования в чайном саду и проведения процедур предварительной обработки. На этом этапе особое внимание уделяется совместному аннотированию как чайной почки, так и зоны срыва. Во-вторых, улучшенная сеть YOLOv8-seg была использована для точной сегментации чайной почки и зоны срыва. Однако важно отметить, что хотя достижение точного распознавания и сегментации чайной почки и зоны срыва желательно, это не является основной целью данного исследования. Вместо этого, основная цель на этом шаге заключалась в извлечении характерных точек и точек срыва через ряд операций с изображениями. Наконец, несопоставленные наборы точек, полученные на предыдущем шаге, были спарены с использованием NPM или PIRM, предложенных в этом исследовании. Соединительные линии этих пар представляют двумерные направления срыва чайных почек. Впоследствии аппроксимированная линия точек пересечения двумерного направления срыва и зоны срыва была рассчитана как трехмерное направление срыва.
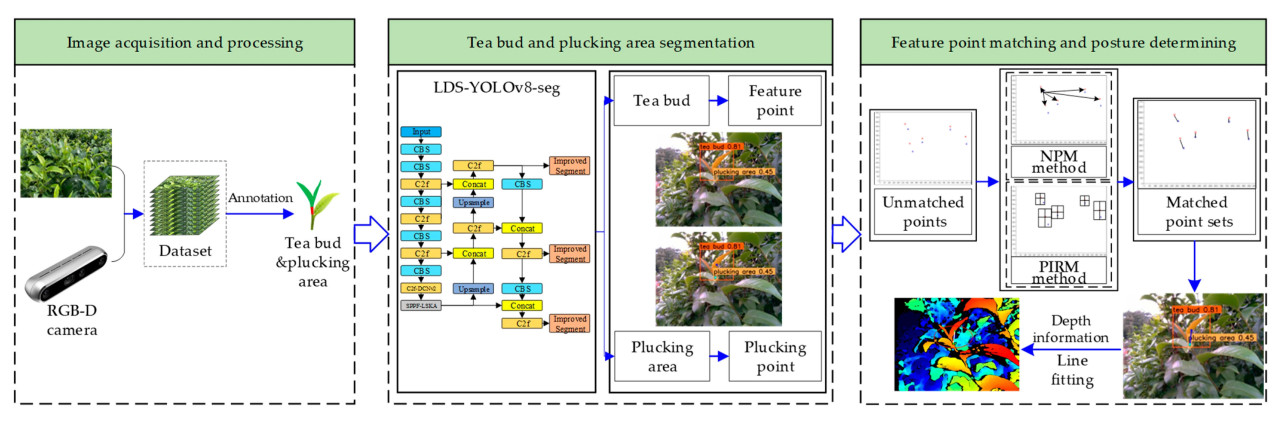
Рисунок 15. Блок-схема метода определения точки срыва и позы срыва чайной почки.
3. Результаты и обсуждение
3.1. Метрики оценки
В это исследование были включены два аспекта оценки производительности: один — оценка обнаружения и сегментации чайных почек и зоны срыва, а другой — оценка сопоставления характерных точек.
Оценка обнаружения и сегментации в основном проводилась путем оценки результатов использования сети YOLO в этом исследовании. Точность (precision), полнота (recall), оценка F1 и GFLOPs были включены в метрики оценки. Точность, рассчитываемая по формуле (25), представляет собой отношение фактически истинных выборок ко всем выборкам, предсказанным как истинные, что представляет точность предсказания истинных выборок. Полнота — это отношение выборок, предсказанных как истинные, в фактически истинных выборках, что может быть рассчитано по формуле (26). Оценка F1, рассчитываемая по формуле (27), является балансирующим показателем точности и полноты.

где TP — количество фактически истинных выборок, которые были предсказаны как истинные выборки, FP — количество ложных выборок, которые были предсказаны как истинные выборки, а FN — количество фактически истинных выборок, которые были предсказаны как ложные выборки.
GFLOPs представляют общее количество операций с плавающей запятой, выполняемых моделью во время вывода или обучения, служа метрикой сложности модели. Более высокое значение GFLOP обычно указывает на то, что модель обладает большей вычислительной сложностью и требует больше дополнительных вычислительных ресурсов для обработки.
Точность и влияние сопоставления характерных точек на эффективность сбора были основными факторами, рассматриваемыми при оценке сопоставления характерных точек. Поэтому точность сопоставления и время сопоставления были предложены в качестве метрик оценки, которые были все получены с использованием статистического анализа данных тестирования сопоставления.
3.2. Обучение модели LDS-YOLOv8
Сеть глубокого обучения LDS-YOLOv8 была построена на основе фреймворка pytorch, и ОС Win 10 с 128 ГБ ОЗУ, процессором Intel(R) Xeon(R) E5-2680 v4 @ 2.40 ГГц и графическим процессором NVIDIA RTX A6000 48 ГБ была использована в качестве платформы обучения в этом исследовании. Программное обеспечение, использованное в процессах обучения и тестирования, включало python3.8, CUDA11.4, cuDNN8.2.2 и т.д. Учитывая баланс между производительностью компьютера и эффективностью обучения, размер пакета (batch size) был установлен равным 24. Начальная скорость обучения и конечная скорость обучения были обе установлены на 0.01.
3.3. Оценка распознавания чайных почек и обнаружения зоны срыва
3.3.1. Результаты обнаружения и сегментации с использованием улучшенной модели YOLOv8
Сетевая архитектура YOLOv8 предоставляет пять моделей сетей разных размеров. По мере увеличения размера модели наблюдается соответствующее улучшение точности обнаружения и сегментации. Однако это улучшение происходит за счет увеличения времени вычислений. Для сбора чая время вычисления моделей разных размеров может удовлетворять их фактическим потребностям; поэтому улучшения и тесты в этом исследовании были все проведены на основе модели YOLOv8x-seg для наилучшей точности. Были проанализированы общие ситуации процесса обучения оригинальной и улучшенной модели YOLOv8-seg, и Рисунок 16 показывает тенденцию изменения значения потерь во время обучения, включая потери ограничивающей рамки (box loss), потери классификации (classification loss), фокальные потери распределения (distribution focal loss) и потери сегментации (segmentation loss). Видно, что как оригинальная, так и улучшенная модели показали быстрое снижение значения потерь с увеличением эпохи, и значение потерь в конечном итоге стало стабильным, что указывало на то, что обучение проходило хорошо и что результаты были сходящимися. Дополнительно, улучшенная модель достигла сходимости раньше, чем оригинальная модель, что продемонстрировало улучшенную эффективность ее процесса обучения.
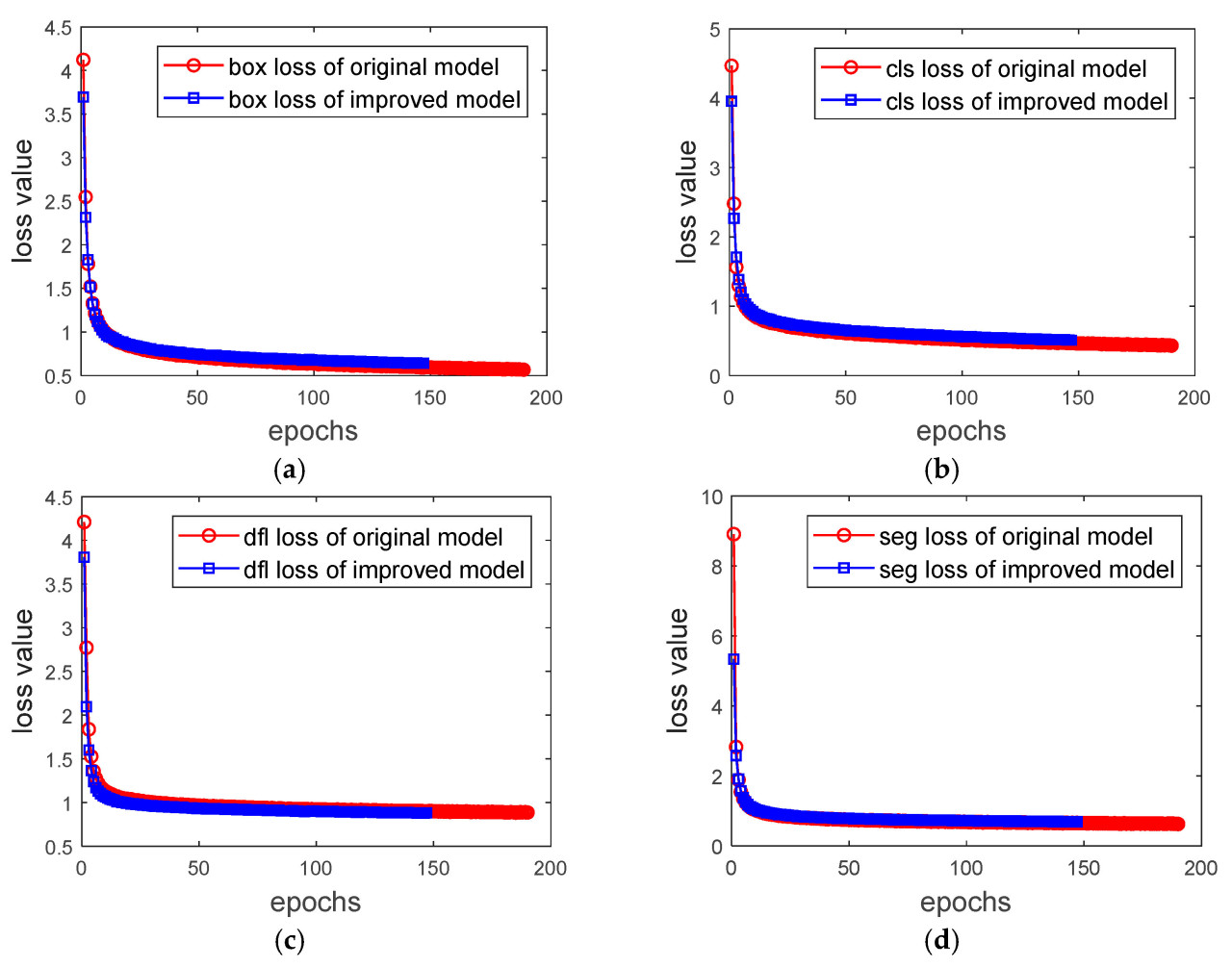
Рисунок 16. Кривые изменения значения потерь для оригинальных и улучшенных моделей: (a) потери ограничивающей рамки; (b) потери классификации; (c) фокальные потери распределения; (d) потери сегментации.
Таблица 1, Таблица 2, Таблица 3 представляют результаты обнаружения объектов и сегментации экземпляров, полученные с использованием моделей YOLOv8x-seg и LDS-YOLOv8x-seg для чайных почек, зоны срыва и общей ситуации соответственно. Как показано в Таблице 1, точность (precision) и mAP модели LDS-YOLOv8x-seg превзошли таковые у модели YOLOv8x-seg с точки зрения обнаружения чайных почек. Как видно из Таблицы 2, точность, полнота (recall) и mAP модели LDS-YOLOv8x-seg все превзошли таковые у модели YOLOv8x-seg с точки зрения обнаружения зоны срыва. С комплексной точки зрения, как показано в Таблице 3, точность, полнота и mAP обнаружения объектов, достигнутые с использованием модели LDS-YOLOv8x-seg, превзошли таковые у модели YOLOv8x-seg. В отношении сегментации экземпляров чайных почек, как показано в Таблице 1, как точность, так и mAP модели LDS-YOLOv8x-seg превзошли таковые у модели YOLOv8x-seg, с увеличением точности на 3,6%. Что касается сегментации экземпляров зоны срыва, как видно из Таблицы 2, точность модели LDS-YOLOv8x-seg была немного ниже, чем у оригинальной модели YOLOv8x-seg; однако как полнота, так и mAP претерпели значительные улучшения. Комплексно, как показано в Таблице 3, с точки зрения сегментации экземпляров, модель LDS-YOLOv8x-seg проявила заметные улучшения как в точности, так и в mAP, сохраняя при этом практически неизменную полноту по сравнению с оригинальной YOLOv8x-seg. Приведенные выше результаты демонстрируют, что улучшенная модель данной статьи показала превосходящую производительность в обнаружении и сегментации чайных почек и зоны срыва по сравнению с оригинальной моделью.

Таблица 1. Производительность обнаружения и сегментации чайных почек.

Таблица 2. Производительность обнаружения и сегментации зоны срыва.

Таблица 3. Производительность общей ситуации обнаружения и сегментации.
Также можно видеть из Таблиц 1 и 2, что как оригинальные, так и улучшенные модели работали лучше при обнаружении и сегментации чайной почки, чем при обнаружении и сегментации зоны срыва, с точностью, полнотой и mAP обнаружения и сегментации чайной почки, превосходящими таковые для зоны срыва. Анализируя причину этого, возможно, что геометрические характеристики чайной почки были хорошо определены, в то время как зона срыва меньше чайной почки, а цвет и форма менее отличительны от окружающей области. Более того, несомненно, что чайная почка и зона срыва каждого чайного растения были размечены вместе во время маркировки изображений, что полезно для обнаружения зоны срыва.
Кроме того, результаты точности, полноты и mAP обнаружения и сегментации чайных почек показали меньшую дисперсию; однако для обнаружения и сегментации зоны срыва результаты были заметно разными. Анализируя причину этого, зона срыва мала, что затрудняет ее обнаружение и сегментацию. Между тем, даже небольшая ошибка может привести к большому отклонению масштабирования из-за ее малого размера.
3.3.2. Сравнение производительности различных сетей
Чтобы дополнительно проиллюстрировать эффективность данного исследования, улучшенный алгоритм в этой статье был сравнен с другими алгоритмами. По сравнению с существующими исследованиями по распознаванию целей чайных почек, существует дефицит исследований, сосредоточенных на сегментации экземпляров как чайных почек, так и зоны срыва. Этот аспект имеет значительную важность, поскольку служит ключевым предварительным условием для определения оптимальной позы срыва и идентификации точных точек срыва.
Был проведен сравнительный анализ алгоритма в соответствующем исследовании и типичной сегментации экземпляров Mask R-CNN. Чен и др. [31] достигли обнаружения и сегментации чайных почек с использованием комбинации моделей Faster-RCNN и FCN-16s. Они использовали двухэтапную сеть обнаружения целей Faster-RCNN для распознавания чайных почек, а затем применение обученной сети FCN-16s для выполнения точной сегментации чайных почек. Сеть Mask R-CNN с различными базовыми архитектурами (backbones) также была рассчитана в этом сравнении. Как представлено в Таблице 4, сравнивая эти методы с методом, представленным в этой статье, наблюдается, что точность обнаружения чайных почек, достигнутая с использованием нашего метода, заметно превосходит их.
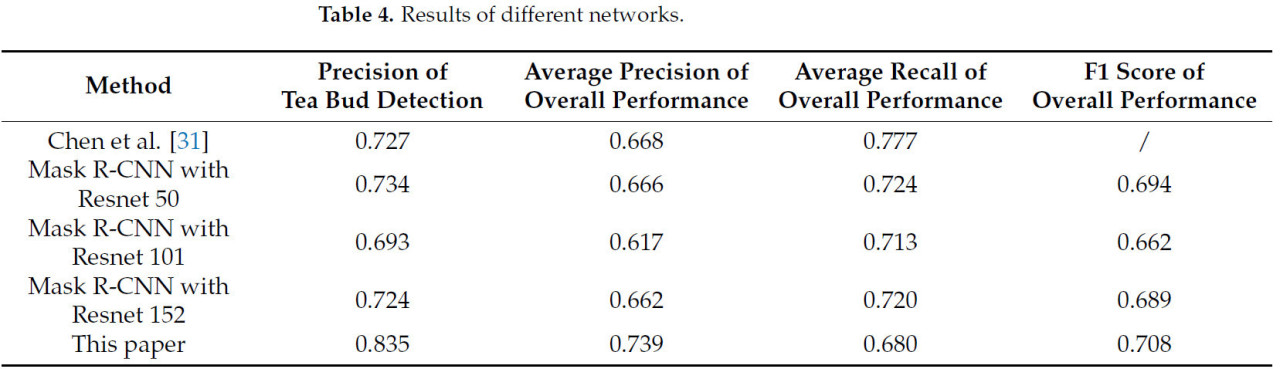
Таблица 4. Результаты различных сетей.
С точки зрения общего эффекта распознавания и сегментации, средняя точность метода, предложенного в этой статье, также была заметно выше, чем у других. Средняя полнота этого исследования не превзошла таковую у других; однако в фактической механизированной операции сбора чайных почек точность имеет большее значение, чем полнота, из-за того, что механизированные операции сбора имеют тенденцию повторяться в циклических поездках.
Метод в этой статье одновременно сегментирует чайную почку и зону срыва, в то время как их метод сегментирует только зону срыва с точки зрения сегментации экземпляров [31]. В дополнение, одноэтапный алгоритм YOLO демонстрирует заметное преимущество в эффективности по сравнению с двухэтапным алгоритмом сегментации экземпляров Mask RCNN.
3.3.3. Абляционные эксперименты
Чтобы исследовать влияние каждой стратегии улучшения, включая улучшенную головку, SPPF-LSKA и C2f-DCNv2, на улучшение производительности обнаружения объектов и сегментации экземпляров модели, в этом исследовании были проведены абляционные эксперименты с использованием проверочного набора данных. Результаты представлены в Таблице 5. Очевидно из таблицы, что по сравнению с оригинальной моделью YOLOv8-seg улучшенная модель демонстрирует значительно улучшенный эффект производительности. Анализ трех отдельных улучшений указывает, что сеть, включающая улучшенный модуль головки, показала превосходящую производительность как в задачах обнаружения объектов, так и в задачах сегментации экземпляров. В частности, при обнаружении объектов точность улучшилась на 1,3%, полнота увеличилась на 1,2%, а mAP улучшилась на 1,6% относительно оригинальной модели сети. С точки зрения сегментации экземпляров, как точность, так и mAP показали значительные улучшения, в то время как вычислительная стоимость модели была заметно снижена, достигнув уменьшения на 12,54% по сравнению с оригинальной YOLOv8-seg. Это дополнительно продемонстрировало существенное влияние улучшенного модуля головки на облегчение модели. Для улучшенной модели с модулем SPPF-LSKA можно видеть, что модуль имеет значительное улучшение в производительности обнаружения и сегментации экземпляров; все показатели в таблице были увеличены по сравнению с оригинальной моделью. Сеть, улучшенная с C2f-DCNv2, также показала превосходящую производительность как в сегментации экземпляров, так и в обнаружении объектов, с полнотой и mAP, увеличившимися на 1,2% и 0,8% соответственно при обнаружении, и всеми показателями, улучшившимися во время сегментации экземпляров.
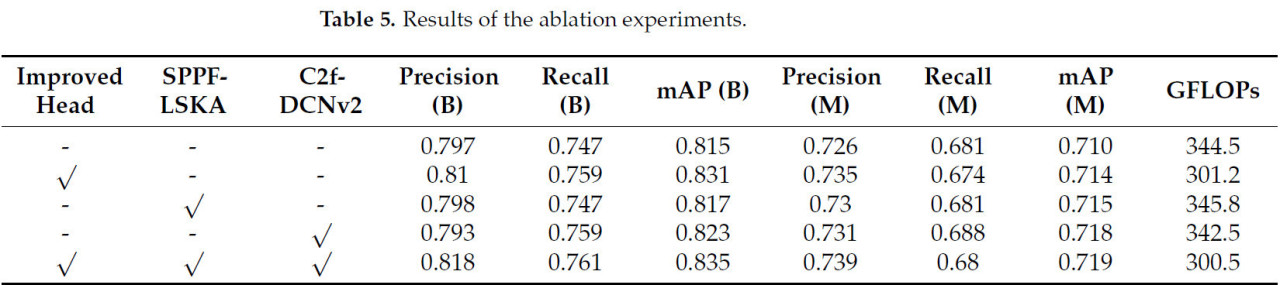
Таблица 5. Результаты абляционных экспериментов.
Наконец, улучшенная модель, включающая все три модуля улучшения, показала значительно превосходящий эффект улучшения по сравнению с оригинальной моделью и улучшенной моделью с соответствующим модулем. Среди семи оценочных показателей, показанных в таблице, улучшенная модель, включающая все три модуля улучшения, превзошла другие в шести из них. Общая производительность обнаружения и сегментации улучшенной модели для чайных почек и зоны срыва была эффективно повышена, с точностью обнаружения и сегментации, улучшившейся на 2,1% и 1,3% соответственно. Более того, вычислительная стоимость всей модели снизилась на 12,77% по сравнению с оригинальной моделью.
Вышеупомянутые выводы демонстрируют эффективность улучшений модели YOLOv8-seg, дополнительно доказывая, что модель LDS-YOLOv8-seg лучше подходит для обнаружения и сегментации чайных почек и зоны срыва.
Рисунок 17 показывает результаты обнаружения и сегментации чайных почек и зон срыва, достигнутые с использованием оригинальной и улучшенной модели YOLOv8-seg. Рисунок демонстрирует, что улучшенный метод показал превосходящие возможности распознавания и сегментации.

Рисунок 17. Результаты обнаружения и сегментации чайной почки и зоны срыва: (a) исходное изображение; (b) результат YOLOv8-seg; (c) результат LDS-YOLOv8-seg.
3.4. Оценка сопоставления и определения позы срыва
Точность сопоставления и время сопоставления являются ключевыми факторами, влияющими на успех и эффективность сбора чайных почек. Сопоставление центральных точек ограничивающих рамок чайных почек и центроидов зон срыва с использованием NPM и PIRM было проведено соответственно на 200 изображениях тестового набора данных с использованием модели LDS-YOLOv8-seg в этом исследовании. Точность сопоставления была рассчитана путем подсчета количества идентифицированных характерных точек и количества правильно сопоставленных точек. Результаты точности сопоставления и времени сопоставления перечислены в Таблице 6. Используя статистический анализ, всего 788 пар характерных точек было сопоставлено с использованием NPM, из которых 712 пар были правильно сопоставлены с точностью 90,355%, в то время как всего 779 пар характерных точек было сопоставлено с использованием PIRM, из которых 773 пары были правильно сопоставлены с точностью 99,229%. NPM достиг большего количества пар сопоставленных характерных точек; однако было больше ложных сопоставлений. С точки зрения времени сопоставления, среднее затраченное время и стандартное отклонение для каждого изображения с NPM составили 0,175 мс и 0,380 мс соответственно, в то время как результаты PIRM составили 2,363 мс и 0,995 мс.
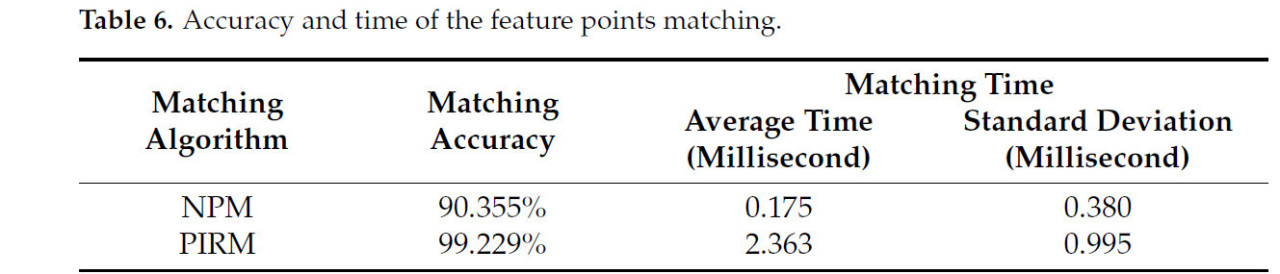
Таблица 6. Точность и время сопоставления характерных точек.
Как видно из вышеуказанных результатов, среднее время сопоставления с использованием NPM короче, чем при использовании PIRM, но его точность сопоставления ниже. На самом деле, относительно времени движения срыва аппарата сбора чайных почек, среднее время сопоставления обоих методов полностью удовлетворяет требованиям для сбора чая. С комплексной точки зрения, PIRM имеет лучший эффект на сопоставление чайных почек и зоны срыва.
Рисунок 18 показывает результаты сопоставления чайных почек и зоны срыва.
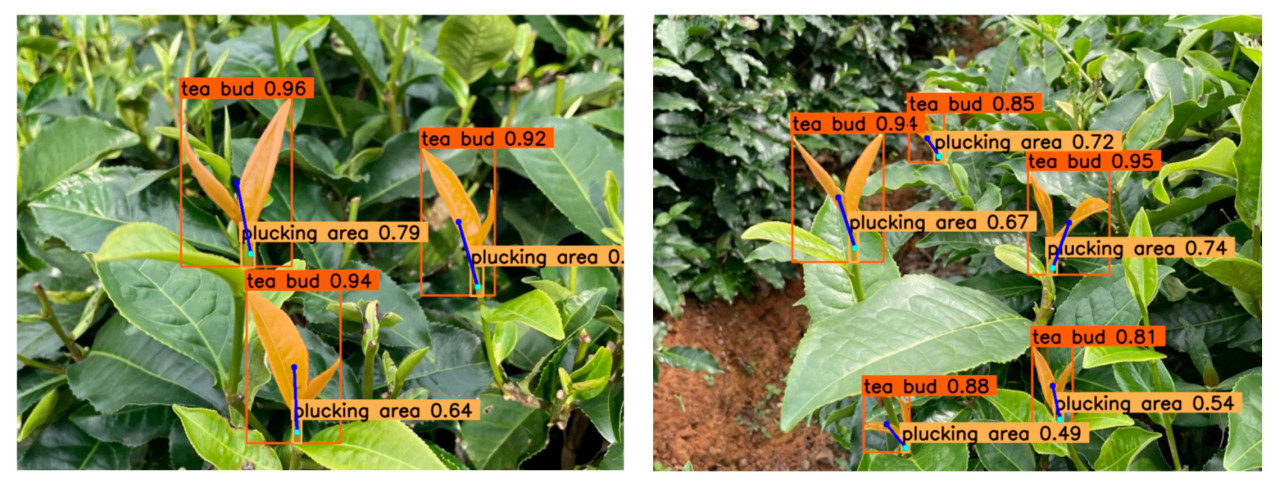
Рисунок 18. Результаты сопоставления чайной почки и зоны срыва.
3.5. Анализ случаев неудач
Случаи неудач были встречены в сегментации экземпляров и сопоставлении характерных точек. Сложность обнаружения малых целей является основной причиной неудачи идентификации чайной почки и зоны срыва. В дополнение, точность распознавания сетевой модели также подвержена влиянию большого различия между размером чайных почек и зоны срыва. Согласно статистике площадей пикселей чайных почек и зоны срыва на изображениях обучающего набора данных, использованного в этом исследовании, как показано в Таблице 7, существует большой разрыв между двумя видами площадей пикселей.

Таблица 7. Сравнение площади пикселей чайной почки и зоны срыва.
Анализ причин неудачи в процессе сопоставления характерных точек был основной работой в этом исследовании. В случаях неудач PIRM мы узнали, что основной причиной было то, что центроид зоны срыва и центральная точка ограничивающей рамки чайной почки располагались вместе или отдельно в ограничивающей рамке другой чайной почки. Как показано на Рисунке 19, точка срыва чайной почки №1 была расположена в ограничивающей рамке чайной почки №2 и была ближе к центральной точке ограничивающей рамки чайной почки №2. В случаях неудач NPM основной причиной было то, что точка срыва другого чайного растения действительно была ближе к центральной точке ограничивающей рамки этого чайного растения, чем ограничивающая рамка того чайного растения. Это можно видеть на Рисунке 20a, где точка срыва чайной почки №1 была ближе к центральной точке ограничивающей рамки чайной почки №2, чем к чайной почке №1.
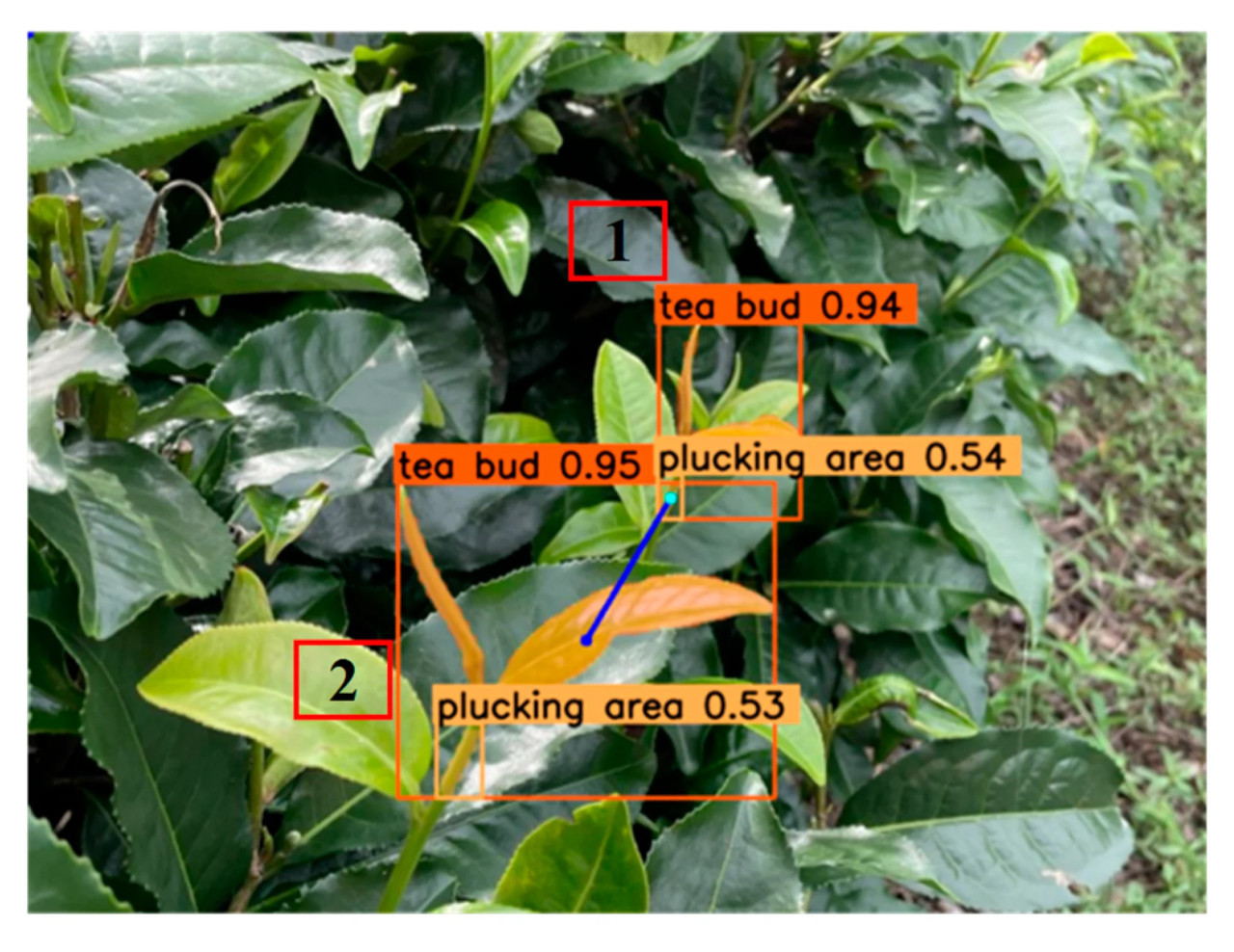
Рисунок 19. Случай неудачи метода сопоставления точки в диапазоне.
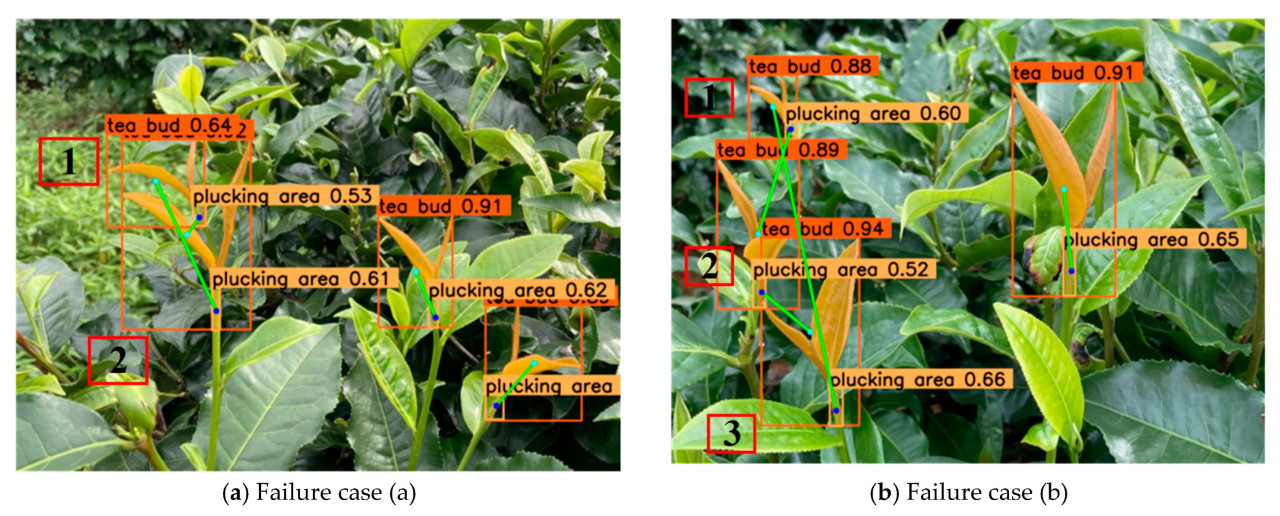
Рисунок 20. Случай неудачи метода сопоставления ближайшей точки.
В общем, причина ошибки в сопоставлении характерных точек заключалась в том, что чайные почки, которые нужно было сорвать, росли слишком близко друг к другу. Кроме того, после того как пара точек была успешно сопоставлена в алгоритме, они были удалены из своего набора точек, поэтому, как только одна пара точек была сопоставлена неправильно, возникала вторая ошибка сопоставления, как показано на Рисунке 20a, или даже если три или более пар точек были сопоставлены неправильно одновременно, как показано на Рисунке 20b. В дополнение, последовательность сопоставления также влияет на результат сопоставления. Как показано на Рисунке 20a, если бы сопоставление начиналось с центральной точки ограничивающей рамки чайной почки №1, ошибки бы не было; в противном случае, если бы сопоставление начиналось с центральной точки ограничивающей рамки чайной почки №2, оба сопоставления были бы неправильными. В частности, как показано на Рисунке 20b, все три сопоставления были неправильными, потому что сопоставление начиналось с центральной точки ограничивающей рамки чайной почки №3. Однако из-за случайного положения чайных почек на одном изображении определенная последовательность сопоставления не могла быть установлена заранее.
4. Выводы
(1) Улучшенная модель YOLOv8-seg была предложена для обнаружения и сегментации экземпляров чайных почек и их зоны срыва, направленная на автоматический сбор чайных почек. Включая улучшенные модули головки, SPPF-LSKA и C2f-DCNv2, модель LDS-YOLOv8-seg продемонстрировала превосходящую производительность в обнаружении и сегментации чайных почек и зоны срыва со значениями точности обнаружения, полноты и mAP, равными 0,818, 0,761 и 0,835, а также значениями точности сегментации, полноты и mAP, равными 0,739, 0,68 и 0,719. Более того, вычислительная стоимость уменьшилась на 12,77% по сравнению с оригинальной моделью.
(2) Локализация точки срыва чая является ключевым предварительным условием для автоматического сбора. Центроид зоны срыва был вычислен путем отображения вероятности каждого пикселя в маске изображения на координаты его соответствующего пикселя в исходном изображении. Предложенный метод является более точным и универсальным по сравнению с традиционными методами локализации точки срыва.
(3) Чтобы проводить автоматический сбор чая более точно, в этом исследовании был разработан метод определения позы срыва. Сначала были идентифицированы точка срыва и центральная точка ограничивающей рамки чайной почки, а затем сопоставление этих точек было достигнуто с использованием либо PIRM, либо NPM, предложенных в этом исследовании. Двумерная поза срыва может быть определена с использованием сопоставленных точек. В сочетании с трехмерной информацией может быть получена трехмерная поза срыва. Эффекты сопоставления PIRM и NPM также были сравнены, и показано, что PIRM работает лучше, с точностью сопоставления 99,229% и средним затраченным временем 2,363 миллисекунды.
(4) Случаи неудач в процессе сопоставления характерных точек были проанализированы в этом исследовании. Основной причиной несоответствия было то, что чайные почки, которые необходимо было сорвать, росли слишком близко друг к другу. Кроме того, порядок сопоставления различных пар точек на одном изображении также влиял на точность сопоставления.
Как обсуждалось ранее, для чайных листьев, которые растут близко друг к другу, метод, предложенный в этой статье, подвержен неправильному сопоставлению, что, следовательно, препятствует точному определению позы срыва чайной почки. Поэтому наши будущие исследования будут изучать более уточненный алгоритм, который интегрирует цветовые и геометрические признаки для сопоставления характерных точек чайной почки, направленный на решение проблемы неудач в сопоставлении характерных точек, вызванных последовательностью сопоставлений. Другой важной исследовательской задачей является исследование интеграции метода определения позы срыва чая, предложенного в этой статье, в аппарат сбора чайных почек для полевых экспериментов.
Ссылки
1. Han, Y.; Xiao, H.; Qin, G.; Song, Z.; Ding, W.; Mei, S. Developing Situations of Tea Plucking Machine. Engineering 2014, 6, 268–273. [Google Scholar] [CrossRef]
2. Motokura, K.; Takahashi, M.; Ewerton, M.; Peters, J. Plucking Motions for Tea Harvesting Robots Using Probabilistic Movement Primitives. IEEE Robot. Autom. Lett. 2020, 5, 3275–3282. [Google Scholar] [CrossRef]
3. Han, Y.; Xiao, H.; Song, Y.; Ding, Q. Design and Evaluation of Tea-Plucking Machine for Improving Quality of Tea. Appl. Eng. Agric. 2019, 35, 979–986. [Google Scholar] [CrossRef]
4. Wang, X.; Han, C.; Wu, W.; Xu, J.; Zhang, Q.; Chen, M.; Hu, Z.; Zheng, Z. Fundamental Understanding of Tea Growth and Modeling of Precise Tea Shoot Picking Based on 3-D Coordinate Instrument. Processes 2021, 9, 1059. [Google Scholar] [CrossRef]
5. Li, Y.; Wu, S.; He, L.; Tong, J.; Zhao, R.; Jia, J.; Chen, J.; Wu, C. Development and field evaluation of a robotic harvesting system for plucking high-quality tea. Comput. Electron. Agric. 2023, 206, 107659. [Google Scholar] [CrossRef]
6. Zhu, Y.; Wu, C.; Tong, J.; Chen, J.; He, L.; Wang, R.; Jia, J. Deviation Tolerance Performance Evaluation and Experiment of Picking End Effector for Famous Tea. Agriculture 2021, 11, 128. [Google Scholar] [CrossRef]
7. Li, Y.; He, L.; Jia, J.; Lv, J.; Chen, J.; Qiao, X.; Wu, C. In-field tea shoot detection and 3D localization using an RGB-D camera. Comput. Electron. Agric. 2021, 185, 106149. [Google Scholar] [CrossRef]
8. Liu, Z.; Zhou, Z. Research progress of tea image feature extraction and its application. J. Green Sci. Technol. 2021, 23, 207–209. [Google Scholar] [CrossRef]
9. Tian, J.; Zhu, H.; Liang, W.; Chen, J.; Wen, F.; Long, Z. Research on the Application of Machine Vision in Tea Autonomous Picking. J. Phys. Conf. Ser. 2021, 1952, 022063. [Google Scholar] [CrossRef]
10. Wei, B. Research on tea leaf recognition based on the color and shape features. Fujian Tea 2016, 38, 16–17. [Google Scholar] [CrossRef]
11. Thangavel, S.K.; Murthi, M. A semi automated system for smart harvesting of tea leaves. In Proceedings of the 2017 4th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 January 2017; pp. 1–10. [Google Scholar]
12. Chen, J.; Chen, Y.; Jin, X.; Che, J.; Gao, F.; Li, N. Research on a Parallel Robot for Tea Flushes Plucking. In Proceedings of the Proceedings of the 2015 International Conference on Education, Management, Information and Medicine, Shenyang, China, 24–26 April 2015; pp. 22–26. [Google Scholar]
13. Wu, X.; Tang, X.; Zhang, F.; Gu, J. Tea buds image identification based on lab color model and K-means clustering. J. Chin. Agric. Mech. 2015, 36, 161–164, 179. [Google Scholar] [CrossRef]
14. Karunasena, G.M.K.B.; Priyankara, H. Tea Bud Leaf Identification by Using Machine Learning and Image Processing Techniques. Int. J. Sci. Eng. Res. 2020, 11, 624–628. [Google Scholar] [CrossRef]
15. Wang, C.; Tang, Y.; Zou, X.; Luo, L.; Chen, X. Recognition and Matching of Clustered Mature Litchi Fruits Using Binocular Charge-Coupled Device (CCD) Color Cameras. Sensors 2017, 17, 2564. [Google Scholar] [CrossRef] [PubMed]
16. Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
17. Gené-Mola, J.; Vilaplana, V.; Rosell-Polo, J.R.; Morros, J.-R.; Ruiz-Hidalgo, J.; Gregorio, E. Multi-modal deep learning for Fuji apple detection using RGB-D cameras and their radiometric capabilities. Comput. Electron. Agric. 2019, 162, 689–698. [Google Scholar] [CrossRef]
18. Mirbod, O.; Choi, D.; Heinemann, P.H.; Marini, R.P.; He, L. On-tree apple fruit size estimation using stereo vision with deep learning-based occlusion handling. Biosyst. Eng. 2023, 226, 27–42. [Google Scholar] [CrossRef]
19. Tang, Y.; Zhou, H.; Wang, H.; Zhang, Y. Fruit detection and positioning technology for a Camellia oleifera C. Abel orchard based on improved YOLOv4-tiny model and binocular stereo vision. Expert Syst. Appl. 2023, 211, 118573. [Google Scholar] [CrossRef]
20. Rong, J.; Wang, P.; Wang, T.; Hu, L.; Yuan, T. Fruit pose recognition and directional orderly grasping strategies for tomato harvesting robots. Comput. Electron. Agric. 2022, 202, 107430. [Google Scholar] [CrossRef]
21. Wang, Y.; Lv, J.; Xu, L.; Gu, Y.; Zou, L.; Ma, Z. A segmentation method for waxberry image under orchard environment. Sci. Hortic. 2020, 266, 109309. [Google Scholar] [CrossRef]
22. Tang, Y.; Qiu, J.; Zhang, Y.; Wu, D.; Cao, Y.; Zhao, K.; Zhu, L. Optimization strategies of fruit detection to overcome the challenge of unstructured background in field orchard environment: A review. Precis. Agric. 2023, 24, 1183–1219. [Google Scholar] [CrossRef]
23. Li, X.; Liu, B.; Shi, Y.; Xiong, M.; Ren, D.; Wu, L.; Zou, X. Efficient three-dimensional reconstruction and skeleton extraction for intelligent pruning of fruit trees. Comput. Electron. Agric. 2024, 227, 109554. [Google Scholar] [CrossRef]
24. Chen, B.; Yan, J.; Wang, K. Fresh Tea Sprouts Detection via Image Enhancement and Fusion SSD. J. Control Sci. Eng. 2021, 2021, 6614672. [Google Scholar] [CrossRef]
25. Chen, C.; Lu, J.; Zhou, M.; Yi, J.; Liao, M.; Gao, Z. A YOLOv3-based computer vision system for identification of tea buds and the picking point. Comput. Electron. Agric. 2022, 198, 107116. [Google Scholar] [CrossRef]
26. Gui, Z.; Chen, J.; Li, Y.; Chen, Z.; Wu, C.; Dong, C. A lightweight tea bud detection model based on Yolov5. Comput. Electron. Agric. 2023, 205, 107636. [Google Scholar] [CrossRef]
27. Wang, T.; Zhang, K.; Zhang, W.; Wang, R.; Wan, S.; Rao, Y.; Jiang, Z.; Gu, L. Tea picking point detection and location based on Mask-RCNN. Inf. Process. Agric. 2021, 10, 267–275. [Google Scholar] [CrossRef]
28. Yang, H.; Chen, L.; Chen, M.; Ma, z.; Deng, F.; Li, M.; Li, X. Tender Tea Shoots Recognition and Positioning for Picking Robot Using Improved YOLO-V3 Model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
29. Yang, H.; Chen, L.; Ma, Z.; Chen, M.; Zhong, Y.; Deng, F.; Li, M. Computer vision-based high-quality tea automatic plucking robot using Delta parallel manipulator. Comput. Electron. Agric. 2021, 181, 105946. [Google Scholar] [CrossRef]
30. Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
31. Chen, Y.-T.; Chen, S.-F. Localizing plucking points of tea leaves using deep convolutional neural networks. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
32. Torralba, A.; Russell, B.C.; Yuen, J. LabelMe: Online Image Annotation and Applications. Proc. IEEE 2010, 98, 1467–1484. [Google Scholar] [CrossRef]
33. Sapkota, R.; Ahmed, D.; Karkee, M. Comparing YOLOv8 and Mask R-CNN for instance segmentation in complex orchard environments. Artif. Intell. Agric. 2024, 13, 84–99. [Google Scholar] [CrossRef]
34. Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2020, 128, 742–755. [Google Scholar] [CrossRef]
35. Lin, G.; Chen, D.; Chen, J.; Zhong, K.; Cai, L.; Lin, F.; Zheng, X.; Li, W. Design and testing of a Cutting-collecting integrated end-effector for tea picking. Mech. Electr. Eng. Technol. 2023, 52, 42–45+172. [Google Scholar] [CrossRef]
36. Zhang, Z.; Zhu, L.; Lin, G.; Zhang, S.; Guan, J. Research progress on key technologies of the famous tea picking end effectors. Mordem Agric. Equip. 2022, 43, 7–12. [Google Scholar] [CrossRef]
37. Chen, G.; Mao, b.; Zhang, Y. Research on key technologies of famous tea picking robot. J. Chin. Agric. Mech. 2023, 44, 174–179. [Google Scholar] [CrossRef]

Dong C, Wu W, Han C, Zeng Z, Tang T, Liu W. Plucking Point and Posture Determination of Tea Buds Based on Deep Learning. Agriculture. 2025; 15(2):144. https://doi.org/10.3390/agriculture15020144
Перевод статьи «Plucking Point and Posture Determination of Tea Buds Based on Deep Learning» авторов Dong C, Wu W, Han C, Zeng Z, Tang T, Liu W., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik

















































































































Комментарии (0)