Тайный язык листьев: как ИИ находит скрытый дефицит питания у томатов
Эффективная диагностика легкого стресса от недостатка питательных веществ на протяжении всего цикла роста томатов защищенного грунта является сложной задачей. В данном исследовании предлагается глубокая обучающаяся структура на основе CNN + LSTM, использующая в качестве входных данных спектры ближнего инфракрасного диапазона (БИК) кроны томатов на различных стадиях роста, для диагностики легкого стресса от недостатка азота (N), калия (K) и кальция (Ca) на протяжении всего цикла роста томатов защищенного грунта.
Аннотация
В исследовании сравнивается диагностическая производительность моделей Random Forest (RF), Support Vector Machine (SVM), Partial Least Squares (PLS), Convolutional Neural Networks (CNN) и CNN + Long Short-Term Memory (LSTM) для обнаружения легкого стресса от недостатка питательных веществ у томатов защищенного грунта. Сначала был определен метод предварительной обработки спектральных характеристических полос в сочетании с Savitzky-Golay (SG) + Standard Normal Variate (SNV). Затем все данные образцов были разделены на шесть групп: дефицит N, дефицит K, дефицит Ca, избыток N, избыток K и избыток Ca. После этого для классификации и прогнозирования были использованы вышеупомянутые модели. Результаты показывают, что модели RF и CNN + LSTM продемонстрировали хорошую прогностическую производительность. В частности, RF достигла точности 70,14%, 90,81%, 88,59% и 85,37% в задачах классификации дефицита Ca, избытка N, избытка K и избытка Ca соответственно. Модель CNN + LSTM достигла точности 93,33%, 63,33%, 99,2%, 83,33% и 98,52% в задачах классификации дефицита K, дефицита Ca, избытка N, избытка K и избытка Ca соответственно. Наконец, при проверке с использованием метода Leave-One-Group-Out Validation (LOGOV) для оценки обобщающей способности модели RF показала лучшие результаты в задачах дефицита N, дефицита K и дефицита Ca, достигнув точности диагностики 80,19%, 81,43% и 77,02% соответственно. Модель CNN + LSTM показала точность диагностики 66,72% в задаче классификации избытка N. Исследование приходит к выводу, что при наличии полных обучающих данных модель CNN + LSTM может эффективно диагностировать легкий стресс от недостатка питательных веществ (N, K и Ca) у томатов защищенного грунта в большинстве сценариев.
1. Введение
Томат является важной экономической культурой, широко возделываемой по всему миру, чей рост, развитие и качество урожая в значительной степени зависят от поставки питательных веществ [1]. Однако антагонистические взаимодействия между элементами делают управление питанием томатов достаточно сложным [2]. Азот (N), калий (K) и кальций (Ca) — это три элемента, которые томаты требуют в наибольших количествах для роста. Высокие летние температуры могут ингибировать поглощение Ca томатами [3]; для восполнения Ca часто вносят азот N, что приводит к избытку азота; в свою очередь, избыток N подавляет поглощение как K, так и Ca томатами [4,5]. Поэтому быстрая и точная диагностика того, испытывает ли растение томата стресс от недостатка питательных веществ, имеет важнейшее значение для обеспечения качества урожая.
Традиционная диагностика стресса от недостатка питательных веществ основана на отборе образцов растительных тканей и анализе содержания в них питательных веществ с использованием лабораторных химических методов [6]. Однако этот подход не только требует много времени и трудоемок, но также может вмешиваться в нормальный рост и развитие растений [7]. В последние годы неразрушающие технологии обнаружения, такие как 2D/3D визуализация, гиперспектральная визуализация и спектроскопия ближнего инфракрасного диапазона, значительно улучшили эффективность и точность получения фенотипических данных растений [8,9], предоставив новые методы для диагностики стресса от недостатка питательных веществ у растений.
Современные основные методы неразрушающей диагностики стресса от недостатка питательных веществ у растений основаны на информации изображений растений. Многочисленные исследования показали, что использование глубоких обучающихся сетей для анализа изображений листьев томата позволяет достичь высокоточной диагностики стресса от недостатка питательных веществ [10,11,12]. Однако эти исследования в основном были сосредоточены на эффективной идентификации томатов с серьезным дефицитом питательных веществ. Когда томаты испытывают легкий дефицит питательных веществ (здесь мы даем определения легкого стресса от недостатка питательных веществ: мы определяем растения томата, которые проявляют определенную степень дефицита питательных веществ, но не показывают значительных симптомов дефицита (таких как пожелтение листьев, темно-зеленые листья, неразвернутые кончики новых листьев или высохшие кончики и края листьев. См. Рисунок S1 в дополнительных материалах) как легкий дефицит питательных веществ. Аналогично, растения томата, которые испытывают переудобрение, но не превышают двукратную стандартную норму внесения питательных веществ для любого элемента, определяются как легкий избыток питательных веществ), их листья не проявляют типичных симптомов, таких как ожог, пожелтение или хлороз. В результате исследований по диагностике легкого дефицита питательных веществ остается недостаточно. Более того, упомянутые выше исследования различали только случаи недостаточности питательных веществ, не учитывая ситуацию с их избытком. Причина этого заключается в том, что физиологическая информация растений, содержащаяся в изображениях растений, ограничена, предоставляя недостаточное основание для дискриминации, чтобы поддержать дальнейшие углубленные исследования.
Спектроскопия ближнего инфракрасного диапазона — это метод сбора и анализа спектральных характеристик объекта в ближнем инфракрасном диапазоне (700–2500 нм). Он обычно используется в сельском хозяйстве для оценки различных признаков и характеристик листьев, стеблей и плодов растений [13,14]. Спектры ближнего инфракрасного диапазона содержат избыток физиологической информации о растении, в то время как объем требуемых данных образцов относительно мал. Поэтому спектроскопия ближнего инфракрасного диапазона предлагает преимущества, такие как скорость, неразрушаемость и точность в анализе целевых компонентов [15].
Полная кривая спектра ближнего инфракрасного диапазона обычно содержит несколько сотен точек данных. Обычные методы анализа данных не показывают особенно хороших результатов при обработке образцов с большими объемами данных [16]. Для повышения эффективности обработки данных и точности прогнозирования исследователи часто выбирают определенные спектральные области или используют спектральные индексы для анализа. Фурланетто [17] сравнил производительность данных, обработанных с использованием алгоритмов выбора характеристических полос (таких как алгоритм последовательных проекций, конкурентный адаптивный взвешенный отбор проб, метод проекции на латентные структуры (PLS) и анализ главных компонент), и исходных спектральных данных в прогнозировании содержания K в листьях сои. Результаты показали, что точность прогнозирования спектральной регрессионной модели с выбранными полосами была примерно на 7,65% выше, чем у модели, использующей полный спектр. Эти исследования сосредоточены исключительно на одном элементе питания и не достигают цели одновременного прогнозирования нескольких питательных элементов. Фанг [18] использовал регрессию PLS и градиентный бустинг регрессионных деревьев для создания полосовой спектральной прогностической модели содержания Ca, K и бора (B) в мякоти и кожице плодов груши. Результаты показали, что прогностические модели для трех элементов имели значения R² больше 0,8 для наборов прогнозирования. Лю [19] использовал метод опорных векторов для регрессии для анализа спектральной отражательной способности листьев винограда, достигнув прогнозов с высокой точностью для содержания K и Ca в листьях со значениями R² 0,7 и 0,62 соответственно и значениями среднеквадратичной ошибки (RMSE) 0,0006 и 0,0011. Эти исследования достигли одновременных прогнозов для нескольких элементов питания, но они были сосредоточены на анализе содержания питательных веществ в тканях растений в определенные моменты времени отбора проб, без учета всего цикла роста растения. Они упустили из виду потенциальное влияние различий растений на различных стадиях роста на результаты эксперимента.
В настоящее время исследования томатов на основе спектроскопии ближнего инфракрасного диапазона в основном сосредоточены на диагностике заболеваний, анализе зрелости или анализе биомассы [20], с ограниченным количеством исследований по стрессу от недостатка питательных веществ. Более того, существующие исследования часто упускают важный факт: даже при постоянном внесении удобрений существуют значительные спектральные различия у одного и того же растения томата на разных стадиях роста [21]. Поэтому при моделировании с использованием данных спектрального отбора проб из одной точки времени могут возникать ошибки в диагностике стресса от недостатка питательных веществ. Например, спектральные вариации, вызванные стадией роста, могут быть ошибочно интерпретированы как сигналы стресса от недостатка питательных веществ, приводя к неточным диагностическим результатам.
Ввиду этого, в данном исследовании была разработана модель глубокой обучающейся сети на основе одномерных сверточных нейронных сетей (CNN) + долгой краткосрочной памяти (LSTM), использующая спектральные данные листьев томатов защищенного грунта в качестве входных данных для прогнозирования статуса стресса трех элементов питания: N, K и Ca. Классификационная производительность моделей PLS, метода опорных векторов (SVM), случайного леса (RF) и моделей с одиночной структурой CNN сравнивалась с производительностью предложенной модели, демонстрируя, что модель эффективно интегрирует спектральные различия, вызванные вариациями стадии роста у томатов защищенного грунта. Модель, представленная в этом исследовании, обеспечивает более точную основу для диагностики стресса от недостатка питательных веществ у томатов защищенного грунта и способствует лучшему управлению питанием для томатов защищенного грунта.
2. Материалы и методы
2.1. Экспериментальные материалы
В этом исследовании разведение томатов было начато в помещении в накопительном резервуаре 19 февраля 2024 года, и рассада томатов была пересажена в минераловатные кубики (GRODAN, Рурмонд, Нидерланды, 100 × 100 × 100 мм) 15 марта 2024 года. Экспериментальный участок располагался на полевой ферме в районе Пукоу (118,6465° в.д., 32,1788° с.ш.), город Нанкин, Китай, в пленочной теплице (8 × 11 × 3 м), которая была закрыта в направлении восток-запад, проветривалась в направлении север-юг 24 часа в сутки и была покрыта затеняющей сеткой наверху теплицы в случае высоких температур. Всего было высажено 54 растения томата сорта «Чжэцзян Фен 202», место испытаний показано на рисунке 1. С даты пересадки все сеянцы обрабатывались стандартным питательным раствором для томатов Ямасаки (ЭС = 2,435 мСм см⁻¹) [22]. С 21 марта по 21 июня 2024 года был проведен градиентный эксперимент с компонентами питательного раствора для гидропонного выращивания томатов Ямасаки в контролируемом испытании с тремя повторениями в каждой группе. Субстратом для выращивания служили двойные минераловатные кубики (100 × 100 × 100 мм), помещенные в горшки одинакового размера (200 × 200 мм) с перлитом, посыпанным вокруг минераловатных кубиков. Ручной полив осуществлялся один раз в день в 9 утра и 5 вечера. Каждое орошение считалось завершенным, когда питательный раствор начинал просачиваться со дна минераловатных кубиков.

Рисунок 1. (а) Вид растений сверху; (b) общий вид экспериментального участка.
Формула питательного раствора для томатов Ямасаки была разработана в соответствии с потребностями растений в воде и удобрениях и считается стабильным питательным раствором. Питательный раствор, используемый в градиентном тесте, был составлен в соответствии с формулой питательного раствора для томатов Ямасаки, а дозировки питательных соединений с вариациями показаны в таблице 1. Дозировки питательных соединений без вариаций показаны в таблице 2, а микроэлементы были составлены по общей формуле.
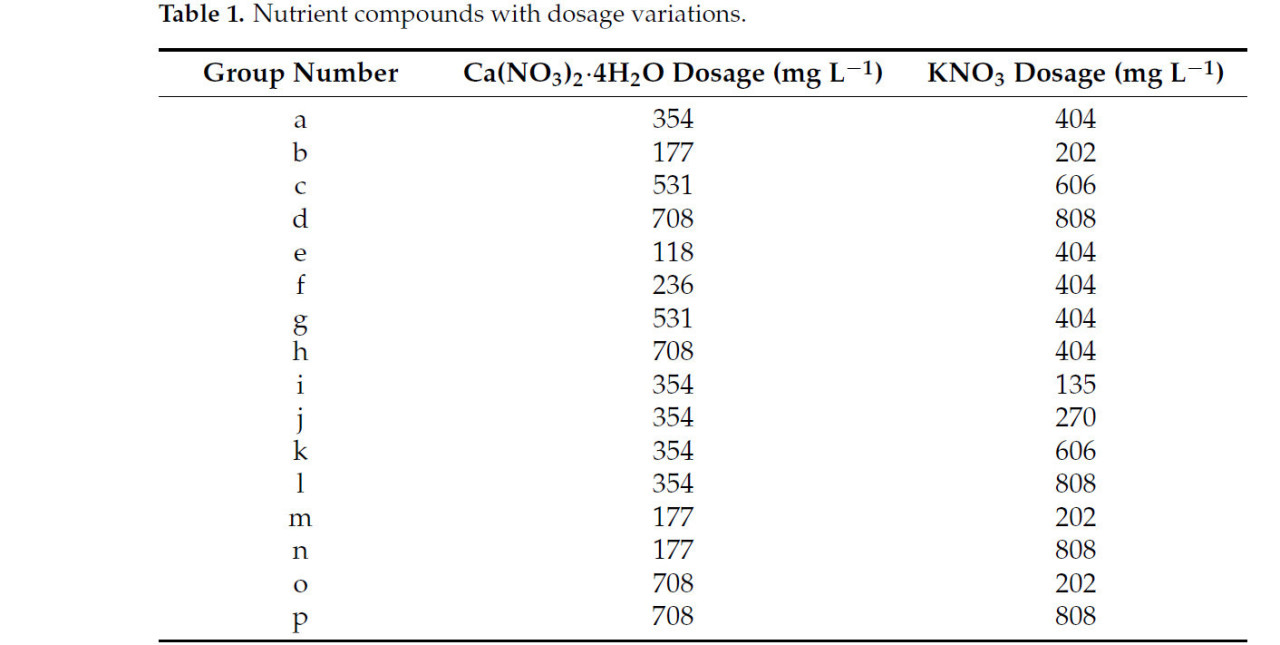
Таблица 1. Питательные соединения с вариациями дозировки.
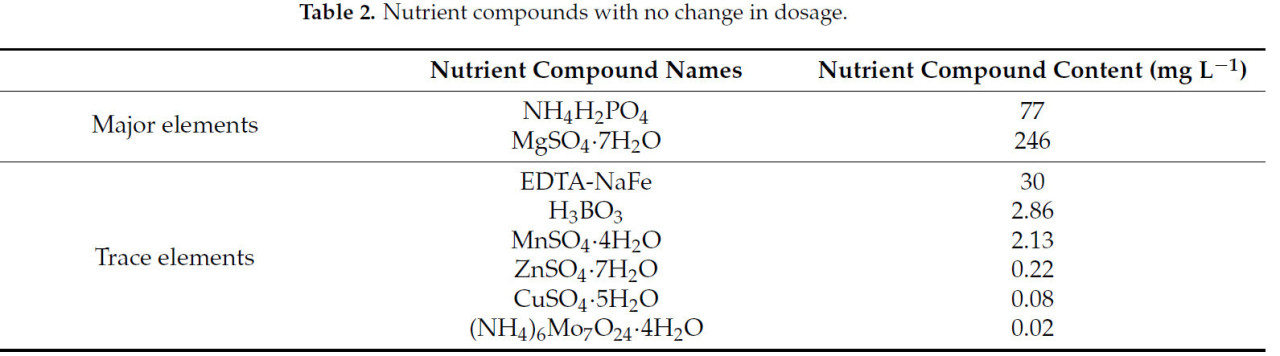
Таблица 2. Питательные соединения без изменения дозировки.
Группа а представляет стандартную дозировку состава питательного раствора для томатов Ямасаки (включая только питательные соединения с измененными дозировками). Группы b, c и d представляют все питательные соединения, масштабированные пропорционально на основе группы a, а группы e~p представляют только питательные соединения из таблицы корректировки дозировки.
2.2. Сбор и предварительная обработка спектральных данных NIR
Для сбора спектральных данных с верхнего слоя (вертикальное направление без затенения лезвием) листьев томата использовался портативный спектрометр ближнего инфракрасного диапазона (NIR-R210, PYNECT, Шэньчжэнь, Китай) [23]. Каждый целевой лист имел площадь не менее 50 мм², и спектральные данные собирались только один раз с каждого листа. Спектральный диапазон составлял 900–1700 нм, спектральное разрешение — 3,5 нм, а общее количество точек спектрального отбора проб — 228. Отбор проб проводился путем наложения передней стороны листьев кроны томата на окно отбора проб (5 × 10 мм), а задняя часть листьев прижималась акриловой пластиной чисто белого цвета для обеспечения плотного прилегания (подробная методология отбора проб приведена на рисунке S2 дополнительных материалов). Время отбора проб выбиралось после захода солнца, чтобы уменьшить влияние колебаний освещенности на сбор данных. В период с 21 марта по 21 июня 2024 года было проведено 11 раундов сбора данных, в результате чего получено в общей сложности 6548 спектральных образцов (более подробная информация об испытании доступна в дополнительных материалах «Экспериментальные детали»). Для всех спектральных данных было проведено скрининг характеристических полос, и 50 спектральных образцов были идентифицированы как характеристические полосы с помощью алгоритма последовательных проекций (SPA) (диапазоны характеристических длин волн: [903,5~938,5 нм] и [963~1096 нм]). Вся последующая обработка данных основывалась на указанных выше диапазонах длин волн.
2.3. Подход к моделированию
2.3.1. Общая модель
Спектральная поглощательная способность листа томата содержит множество физиологических и биохимических характеристик. Чтобы полностью извлечь детальные характеристики, встроенные в кривую спектральной поглощательной способности, в качестве модуля обработки входных данных используется CNN для извлечения признаков из предварительно обработанной кривой спектральной поглощательной способности. Учитывая существование временных признаков среди спектральных данных, собранных на протяжении всего экспериментального цикла, в качестве модуля постобработки используется сеть LSTM. Как показано на рисунке 2a, модель глубокого обучения принимает спектральный коэффициент поглощения кроны томата в качестве входных данных и статус стресса N, K и Ca в качестве выходных данных.
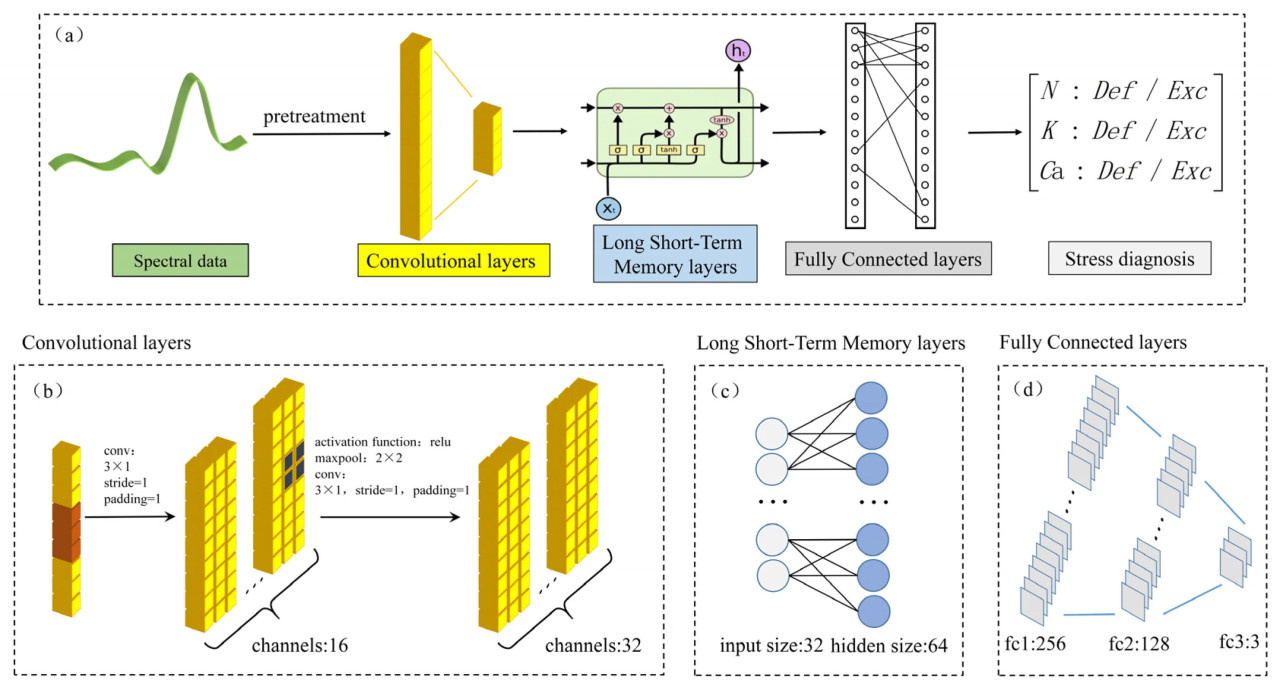
Рисунок 2. Структура модели. (а) Основная структура модели; (b) CNN; (c) LSTM; (d) полносвязные слои.
CNN широко используются в обработке изображений благодаря своей превосходной способности извлечения признаков [24]. Спектральные данные можно рассматривать как изображения с пикселями 1 × n, поэтому для извлечения спектральных признаков можно использовать одномерную CNN [25]. В этом исследовании используется двухслойная одномерная CNN, и конфигурация сети показана на рисунке 2b. Входные данные сначала пропускаются через сверточное ядро 1 × 3 с размером шага 1 для извлечения детальных признаков. После того как данные проходят через 16 каналов, применяется выпрямленная линейная единица (ReLU), за которой следует максимальное объединение 2 × 2. Дальнейшие признаки извлекаются с помощью сверточного ядра с размерами шага 1 и 1 × 3 и, наконец, выводятся через 32 канала.
Сеть LSTM — это архитектура рекуррентной нейронной сети, основным компонентом которой является блок LSTM, позволяющий избирательно сохранять или отбрасывать информацию в длинных последовательностях [26]. В этом исследовании используется сеть LSTM с одним скрытым слоем для извлечения временных связей между многомерными данными на протяжении всего цикла роста томата, подробности сети показаны на рисунке 2c. Сеть состоит из входного слоя с 32 единицами, скрытого слоя с 64 единицами и выходного слоя, непосредственно связанного с полносвязным слоем, содержащим 256 единиц. Полносвязный слой, как конечный выходной слой модели, имеет три слоя размерами 256, 128 и 3, чьи подробные параметры показаны на рисунке 2d.
Чтобы наглядно продемонстрировать производительность модели, в исследовании сравнивались результаты моделей RF, SVM, PLS и модели с одиночной CNN с результатами предложенной модели при выполнении задач диагностики стресса от недостатка питательных веществ.
2.3.2. Предварительная настройка параметров модели
Чтобы исключить ошибочные суждения, вызванные неподходящими начальными настройками параметров в моделях, это исследование сначала разработало задачу классификации для всех экспериментальных групп (a~p) (16-классовая классификация) и предварительно настроило параметры каждой модели. Матрицы ошибок для результатов классификации каждой модели показаны на рисунке 3. Модели SVM, CNN и CNN + LSTM продемонстрировали хорошую классификационную производительность с общей точностью 94,83%, 92,81% и 96,01% соответственно. Среди них модель CNN показала значительную ошибку классификации в группе g, где большинство тестовых образцов g были ошибочно классифицированы как группа h, что свидетельствует о возможном переобучении модели. Хотя модель RF имела общую точность всего 71,1%, неправильно классифицированные образцы были более рассеяны, без какой-либо концентрированной ошибки классификации. Кроме того, поскольку PLS почти полностью провалился в этой многоклассовой задаче, окончательная матрица ошибок для PLS не представлена. В качестве альтернативы параметры PLS были предварительно настроены на основе задач бинарной классификации для любых двух групп. Окончательные параметры для каждой модели показаны в таблице 3.
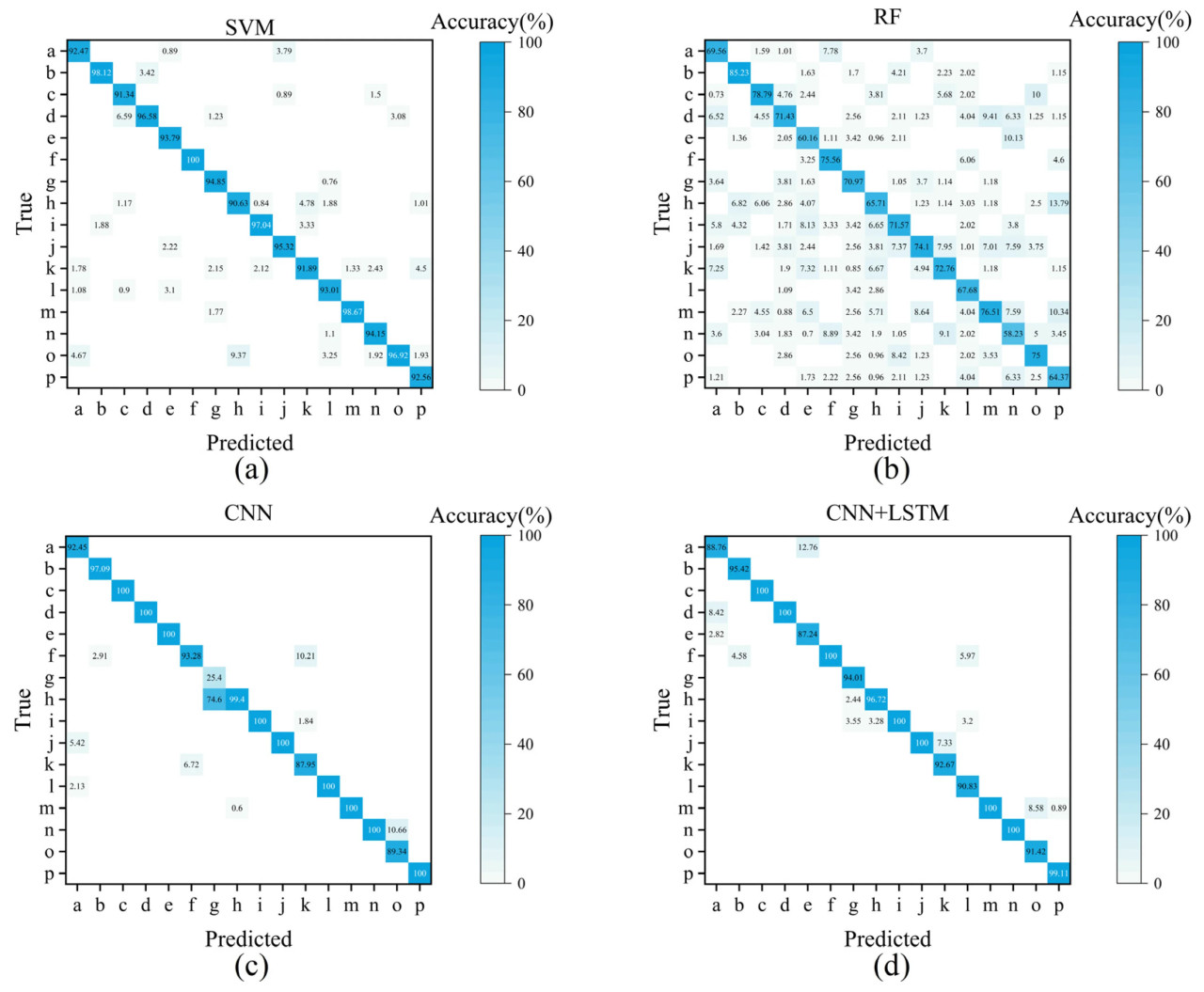
Рисунок 3. Матрица ошибок результатов классификации для каждой модели. (а) SVM; (b) RF; (c) CNN; (d) CNN + LSTM.
Таблица 3. Ключевые параметры каждой модели.
2.3.3. Оценка модели
Чтобы определить наиболее подходящий метод предварительной обработки спектров, было сравнено влияние различных методов предварительной обработки (Сэвицкого-Голея (SG), SG + производная первого порядка (FD), SG + производная второго порядка (SD), SG + стандартная нормальная вариация (SNV) и SG + мультипликативная коррекция рассеяния (MSC)) на производительность модели, и был определен унифицированный подход к предварительной обработке данных. Применялся метод 5-кратной перекрестной проверки [27], при котором спектральные данные из каждого раунда отбора проб (всего 11 раундов) случайным образом разделялись на обучающую и тестовую выборки в соотношении 7:3 (4583 образца в обучающей выборке и 1965 образцов в тестовой выборке). Для проверки обобщающей способности модели была разработана перекрестная проверка с исключением по группам (LOGOV). Этот метод аналогичен перекрестной проверке с исключением по одному (LOOCV) [28], с той разницей, что LOOCV оставляет для проверки только один образец, тогда как LOGOV рассматривает группу образцов, принадлежащих к одной категории, как единое целое, выполняя перекрестную проверку на групповой основе. В этом исследовании разработанный подход LOGOV рассматривает 16 групп (a–p), перечисленных в таблице 1, как 16 различных наборов, где все образцы внутри одного набора используются в качестве тестовой выборки, в то время как образцы из оставшихся 15 наборов используются для обучения. По сравнению с LOOCV, где каждый образец рассматривается как независимый, в LOGOV образцы по своей природе разделены на группы, и все образцы в одной группе соответствуют одной и той же цели прогнозирования.
Все модели в этом исследовании были реализованы с использованием Python 3.11 в программном обеспечении Pycharm® (версия 2023.2.5), а модель глубокого обучения выполнялась на видеокарте NVIDIA GTX 1650® в среде программного обеспечения Pytorch®.
3. Результаты
3.1. Спектральные характеристики
Спектральная поглощательная способность листьев кроны томата раскрывает богатые детали о состоянии роста. Как показано на рисунках 4a и 4b, были сравнены два набора кривых поглощения спектра (900–1700 нм) кроны томата, предварительно обработанные при различных практиках управления питанием. Как показано на рисунке 4a, кривые спектрального поглощения при половинной стандартной дозе питательных веществ и двойной стандартной дозе питательных веществ значительно различались в двух интервалах полос: 900–1300 нм и 1600–1700 нм. Томаты при половинном управлении питанием показали значительно большую спектральную поглощательную способность в этой полосе. Как показано на рисунке 4b, кривые спектрального поглощения при одной трети стандартной дозы CaNO₃ и двойной стандартной дозе CaNO₃ различались в интервале полос 1400–1550 нм, и томаты при управлении одной третью стандартной дозы CaNO₃ имели значительно более низкую спектральную поглощательную способность в этой полосе. Таким образом, хотя тенденции в спектральной поглощательной способности были схожи для всех листьев кроны томата, кривые спектрального поглощения при различных уровнях управления питанием все еще значительно различались, в частности, в подразделенных интервалах полос, что свидетельствует о возможности использования спектроскопии для диагностики стрессовых условий от недостатка питательных веществ у томатов.
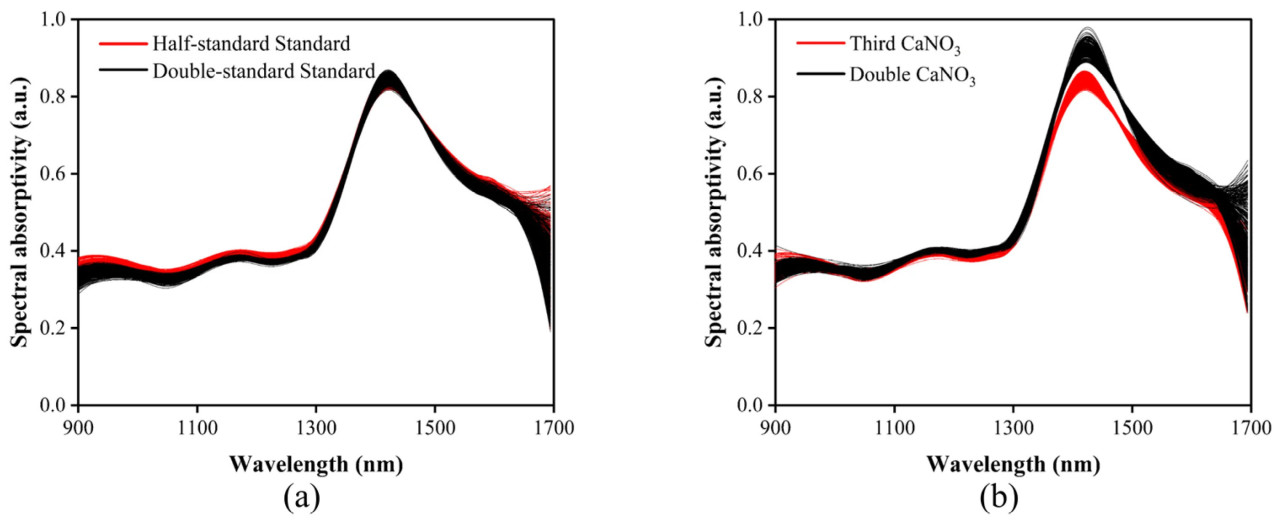
Рисунок 4. (а) Сравнение кривых спектрального поглощения после обработки питательным раствором половинной и двойной стандартной концентрации; (b) сравнение кривых спектрального поглощения после обработки одной третью или двойной концентрацией CaNO₃.
3.2. Сравнение общей точности прогнозирования при различных методах предварительной обработки данных
Как показано в таблице 1, все экспериментальные группы были разделены на категории: дефицит N, избыток N, дефицит K, избыток K, дефицит Ca и избыток Ca. Методы предварительной обработки SG, FD, SD, SNV и MSC были объединены для сравнения показателей точности прогнозирования каждой модели при различных стратегиях предварительной обработки данных, результаты представлены в таблице 4. Результаты показывают, что наивысший средний показатель точности для обучающей выборки был достигнут при комбинации SG + MSC, давшей среднюю точность 83,64%. Аналогично, наивысший средний показатель точности для тестовой выборки был достигнут при комбинации SG + SNV, со средней точностью 67,24%. Показатели точности для других трех методов предварительной обработки были сравнительно ниже. Однако кумулятивная разница в показателях точности между обучающей и тестовой выборками для комбинации SG + MSC была на 32,21% выше, чем для комбинации SG + SNV. Большое расхождение в точности между обучающей и тестовой выборками часто указывает на переобучение. Поэтому был выбран метод предварительной обработки спектров SG + SNV.
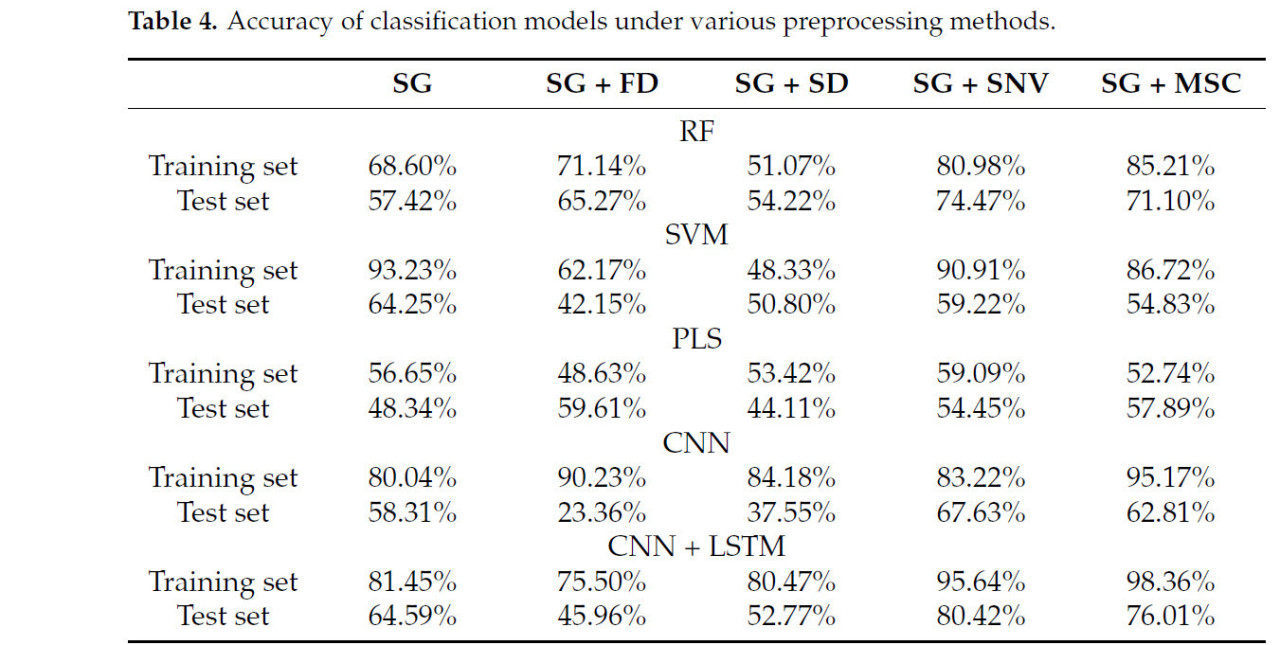
Таблица 4. Точность моделей классификации при различных методах предварительной обработки.
3.3. Сравнение результатов диагностики стресса от недостатка питательных веществ у томатов с использованием перекрестной проверки
На основании результатов раздела 3.2 представлены показатели точности для диагностики стресса N, K и Ca при предварительной обработке SG + SNV для каждой модели, общие результаты показаны в таблице 5. Подробные диагностические результаты для каждой группы проиллюстрированы на рисунке 5. Среди них модель SVM не достигла точности выше 50% в диагностике дефицита питательных веществ для любого из трех элементов, в то время как точность диагностики избытка питательных веществ для всех трех элементов превысила 86%, что явно указывает на сильное переобучение. Модель PLS, за исключением диагностики избытка Ca, достигла показателей точности ниже 60% для других диагнозов стресса. Таким образом, SVM и PLS считаются практически полностью провалившимися. Модель CNN достигла точности выше 60% в диагностике стресса для N, K и Ca в пяти сценариях. Однако в четырех из этих сценариев точность не превысила 75%. Как показано на рисунке 5b, модель CNN также демонстрирует значительное переобучение в диагностике K. Учитывая, что это задача бинарной классификации, модель CNN также считается неэффективной. Модель RF показала диагностическую точность выше 70% в четырех сценариях, причем в трех из них превышающую 85%. Более того, как показано на рисунках 5a и 5b, модель RF достигла точности выше 50% в диагностике дефицита N и дефицита K, что свидетельствует о том, что ее более низкая производительность в этих двух категориях связана с внутренними сложностями задачи, а не с переобучением. Модель CNN + LSTM показала превосходные результаты в четырех сценариях с диагностической точностью выше 83%. Подобно модели RF, модель CNN + LSTM не показывает значительного переобучения.
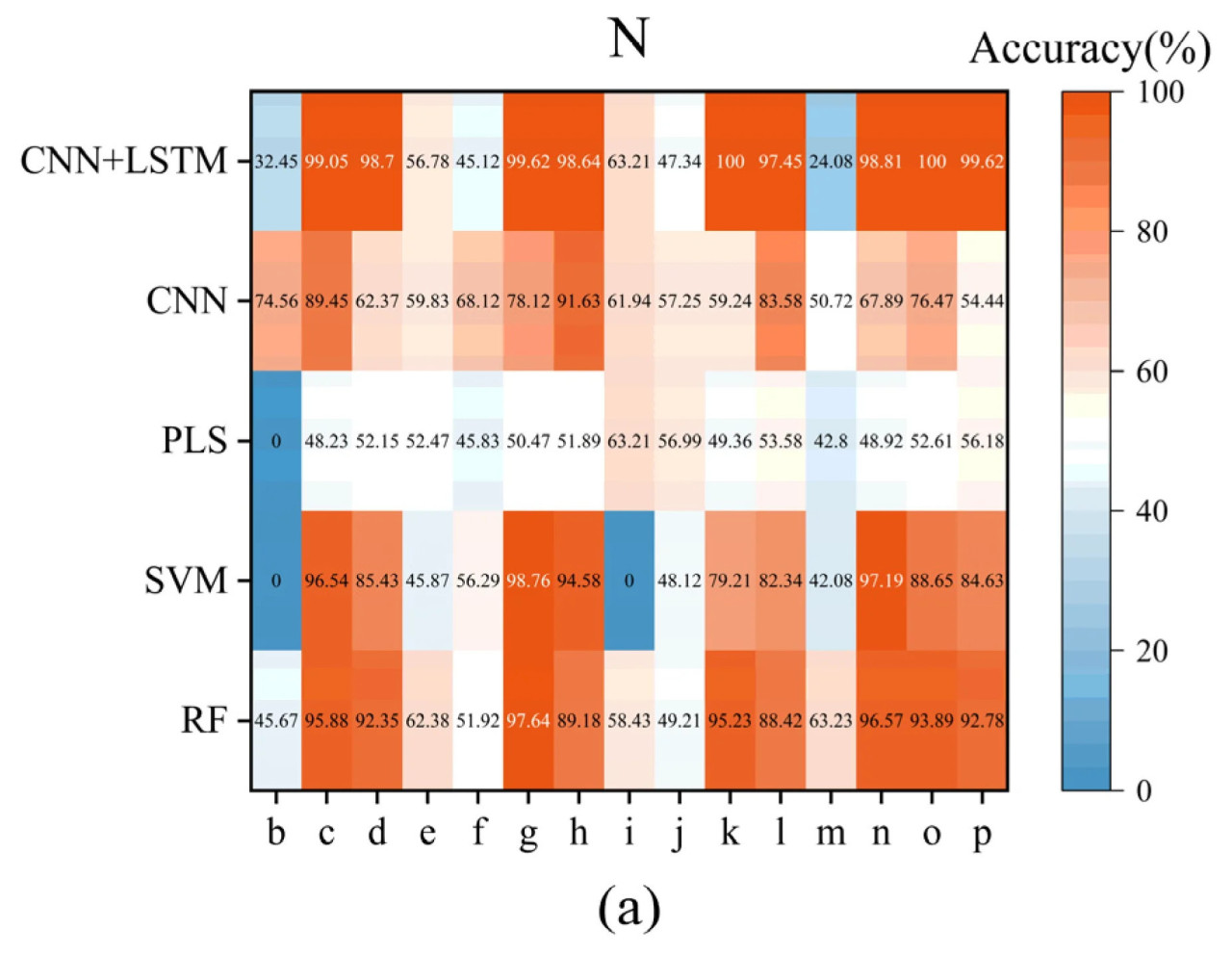
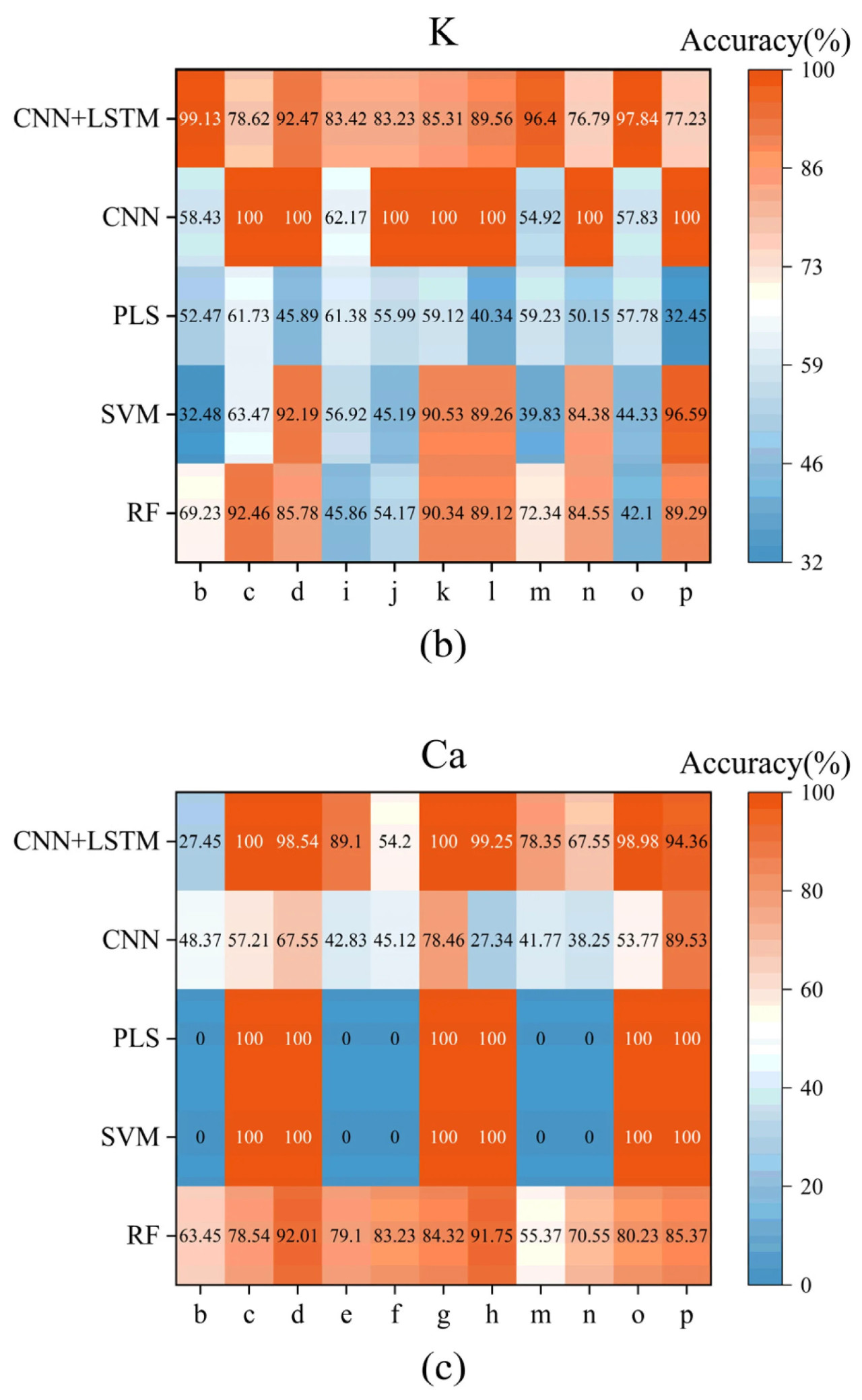
Рисунок 5. Подробные результаты диагностики стресса от недостатка питательных веществ N, K и Ca у томатов различными моделями. (а) N; (b) K; (c) Ca.
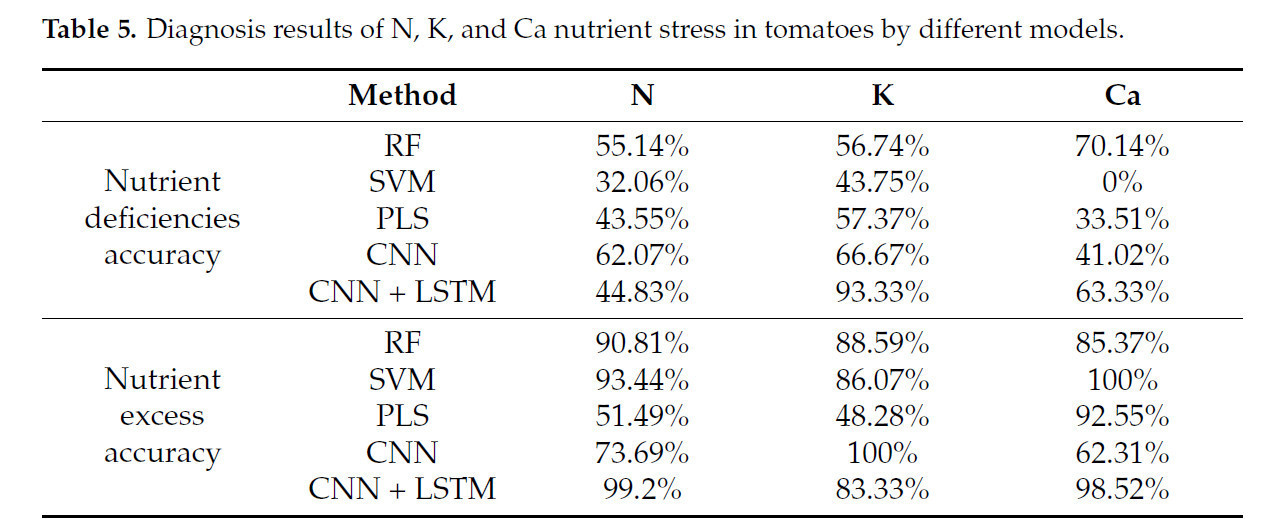
Таблица 5. Результаты диагностики стресса от недостатка питательных веществ N, K и Ca у томатов различными моделями.
3.4. Сравнение результатов диагностики стресса от недостатка питательных веществ у томатов с использованием LOGOV
Хотя это исследование оценивало диагностику стресса для 15 контролируемых экспериментальных групп, реальные условия выращивания гораздо сложнее экспериментальной установки. Чтобы сравнить обобщающую способность моделей, была разработана LOGOV. Основываясь на выводах из раздела 3.3, этот раздел фокусируется на сравнении моделей RF и CNN + LSTM и оценке их показателей точности для диагностики стресса N, K и Ca. Как показано на рисунке 6, показатели точности диагностики стресса от дефицита питательных веществ во всех подгруппах проиллюстрированы как для модели RF, так и для модели CNN + LSTM. Для диагностики стресса от дефицита питательных веществ модель RF достигла общей точности 58,62%, в то время как модель CNN + LSTM достигла 42,26%. Для диагностики стресса от избытка питательных веществ модель RF достигла общей точности 75,15% по сравнению с 57,77% для модели CNN + LSTM. В частности, для подгрупп модель RF показала хорошие результаты в диагностике дефицита Ca, избытка N и избытка K с показателями точности 80,19%, 81,43% и 77,02% соответственно. Модель CNN + LSTM, с другой стороны, достигла точности 66,72% в диагностике избытка N.
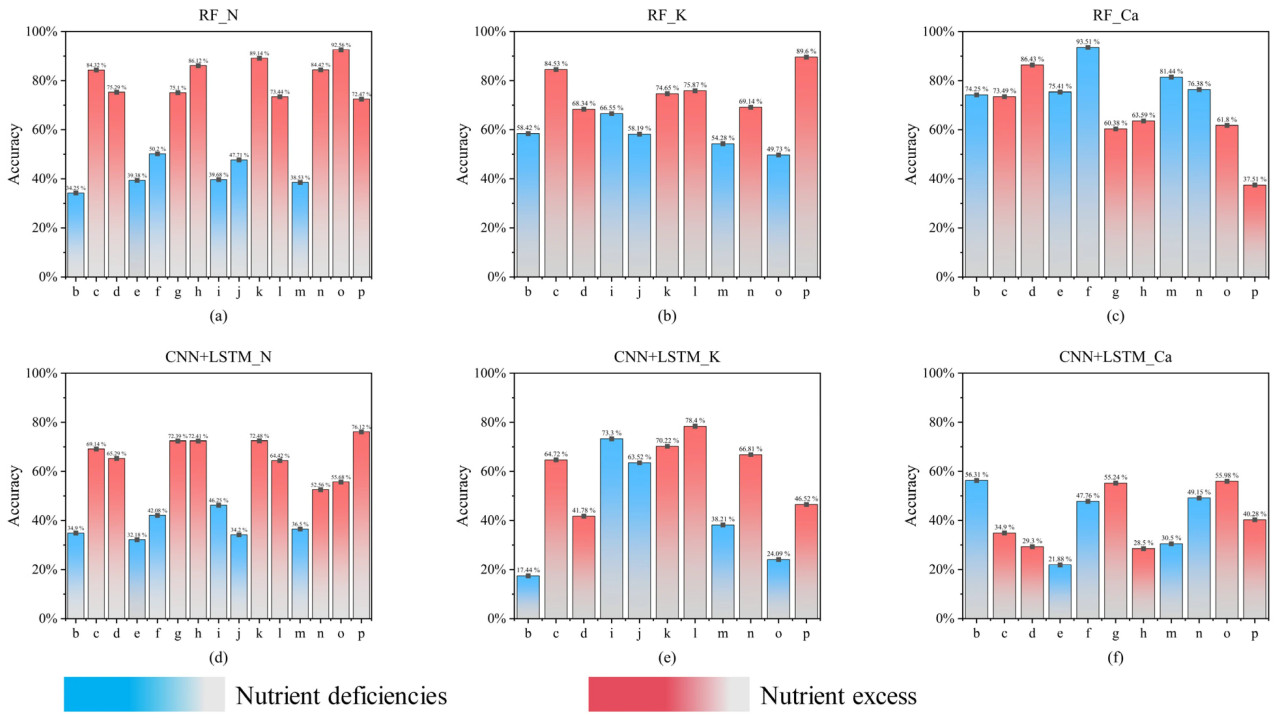
Рисунок 6. Результаты LOGOV для модели RF и CNN + LSTM. (а) RF_N; (b) RF_K; (c) RF_Ca; (d) CNN + LSTM_N; (e) CNN + LSTM_K; (f) CNN + LSTM_Ca.
4. Обсуждение
Идеальная модель управления питанием растений должна динамически корректироваться в соответствии с изменениями стадий роста растения [29]. Однако такой подход влечет высокие управленческие затраты и не подходит для крупномасштабного применения. Напротив, практическое производство показало, что использование питательного раствора с постоянным составом на протяжении всего жизненного цикла растения является осуществимым. Поэтому, хотя это исследование не корректировало динамически состав питательного раствора на основе стадий роста растения, оно все же представляет модель управления питанием, соответствующую реальным производственным практикам. Существующие исследования показали, что даже при постоянном количестве удобрений на протяжении всего цикла роста растения содержание питательных веществ в листьях растения колеблется [23]. Эти колебания неизбежно влияют на спектральное выражение [30], которое служит основой для текущих спектральных анализов содержания питательных веществ в тканях растений. Другими словами, модель управления питанием, подходящая для большинства производственных сценариев, по своей сути должна учитывать изменения спектрального отклика, вызванные вариациями стадии роста растения.
Значительное количество исследований было сосредоточено на прогнозировании содержания питательных веществ в тканях растений [31,32,33]. Однако даже при правильных практиках внесения удобрений содержание питательных веществ в тканях растений неизбежно колеблется на разных стадиях роста [23]. Такие исследования должны учитывать стадии роста и развития растения и стремиться установить комплексную систему корреляций, связывающую содержание питательных веществ с конкретными стадиями роста. Однако исследования в этой области остаются ограниченными. В отличие от этого, данное исследование переходит от прямой количественной оценки содержания питательных веществ в растении к приоритетной диагностике стресса от недостатка питательных веществ на всех стадиях. Этот подход предоставляет практичный и эффективный метод для идентификации стресса, соответствующий сложностям реальных производственных сценариев.
Используя полный обучающий набор, модель CNN + LSTM продемонстрировала превосходную прогностическую производительность в четырех сценариях классификации: избыток N, дефицит K, избыток K и избыток Ca. Она также показала адекватные результаты в сценарии дефицита Ca, но не справилась со сценарием дефицита N. Однако при LOGOV модель показала хорошие результаты только в большинстве сценариев избытка N и избытка K и в некоторых сценариях дефицита K, в то время как она провалилась во всех других сценариях. Этот результат соответствует внутренним характеристикам сетей глубокого обучения. Для достижения надежной производительности модели глубокого обучения требуют комплексного и качественного набора обучающих данных [34]. Хотя это исследование включало 15 контрольных групп для представления дефицита и избытка питательных веществ, объем выборки остается недостаточным по сравнению со сложностью реальных условий. Следовательно, в итоговом тесте на обобщающую способность модель глубокого обучения не смогла превзойти традиционные модели машинного обучения.
При LOGOV модель RF значительно превзошла модель CNN + LSTM по общей прогностической производительности. Следующий анализ, основанный на характеристиках каждой модели [35,36], дает понимание этих результатов: RF по своей природе превосходно справляется со сложными нелинейными отношениями и демонстрирует низкую чувствительность к зашумленным данным. Учитывая, что решение проблемы влияния спектрального шума на разных стадиях роста было ключевой целью этого исследования, RF достиг превосходных результатов при LOGOV. Модель CNN + LSTM, хотя теоретически способна использовать временные и пространственные признаки, была ограничена небольшим размером и неполнотой набора данных. В результате она не смогла полностью раскрыть потенциальные преимущества сетей глубокого обучения, что привело лишь к средней производительности при LOGOV.
Другая не пренебрежимая деталь — это потребление вычислительных ресурсов каждой моделью. При фиксированных параметрах модели модели машинного обучения, как правило, занимают меньше вычислительных ресурсов и требуют меньше времени на обучение. Конечно, учитывая практические сценарии применения, фаза обучения модели может быть завершена на внешних устройствах, в то время как фаза тестирования более актуальна для потребления аппаратных ресурсов локальных устройств. Учитывая, что будущий сценарий применения этой модели, вероятно, будет небольшими встроенными устройствами с ограниченными вычислительными ресурсами, сложность модели значительно повлияет на производительность проверки в реальном времени. Здесь мы сравниваем время, затраченное каждой обученной моделью на проверку тестового набора на персональном компьютере: время проверки для моделей машинного обучения обычно составляет менее 0,1 с; модель с одиночной CNN занимает 0,56 с; а модель CNN + LSTM занимает 2,03 с.
Широко признано, что увеличение сложности моделей глубокого обучения и увеличение количества эпох обучения может улучшить прогностическую производительность модели [37]. Однако такие стратегии часто приводят к переобучению, и в некоторых случаях может потребоваться упрощение архитектуры модели для адаптации к конкретным характеристикам набора данных. Признавая эту проблему, данное исследование использовало относительно простые архитектуры сетей при первоначальном проектировании модели: 4-слойную CNN и 2-слойную CNN в сочетании с 1-слойной LSTM. Для смягчения переобучения были включены методы оптимизации, такие как L2-регуляризация, dropout и динамические скорости обучения (подробный процесс оптимизации переобучения предоставлен в дополнительных материалах, рисунки S3–S5). Тем не менее, как модель с одиночной CNN, так и модель CNN + LSTM показали признаки переобучения. Поэтому необходимо проектировать архитектуру сети глубокого обучения в соответствии с текущей задачей.
5. Выводы
Это исследование показало, что модель глубокого обучения CNN + LSTM, при наличии достаточно полного набора обучающих данных, может диагностировать большинство случаев легкого стресса от недостатка питательных веществ у томатов защищенного грунта на протяжении всего их жизненного цикла. В частности, модель достигла показателей точности 93,33%, 63,33%, 99,2%, 83,33% и 98,52% для задач классификации дефицита K, дефицита Ca, избытка N, избытка K и избытка Ca соответственно.
Это исследование фокусируется на наиболее распространенных сценариях роста томатов защищенного грунта на практике и разрабатывает диагностическую модель для выявления легкого стресса от недостатка питательных веществ на протяжении всего цикла роста томатов. Хотя исследование дало некоторые заслуживающие внимания выводы, оно все еще недостаточно. Модель глубокого обучения, разработанная в этом исследовании, может только качественно описывать статус стресса томатов, но не может предоставить пользователям точные, количественные ориентиры степени стресса от недостатка питательных веществ. Фактически, авторы пытались заставить модель выводить матрицу 1 × 3, которая точно количественно определяет текущий уровень стресса от недостатка питательных веществ у томатов для каждой контрольной экспериментальной группы. При полных обучающих данных модель показала перспективную прогностическую производительность. Однако в последующих тестах LOGOV, независимо от модели или корректировки ее параметров, окончательные прогнозы были стабильно плохими. Например, при обучении на группах a–o и тестировании на группе p результаты для p имели тенденцию совпадать с одной из групп a–o, а не соответствовать ожидаемым значениям для p. Авторы связывают неспособность модели правильно аппроксимировать данные в первую очередь с ограниченным количеством контрольных групп. Следовательно, авторы в конечном итоге отказались от идеи количественного описания степени стресса от недостатка питательных веществ у томатов.
Это исследование сосредоточено исключительно на поставке питательных веществ как переменной для изучения конкретного спектрального выражения кроны томата. Однако факторы окружающей среды также могут влиять на спектральные характеристики. Поэтому в экспериментальных деталях подчеркивается, что все сборы спектральных данных проводились после захода солнца, чтобы избежать влияния различий в окружающем освещении между солнечными и дождливыми дневными условиями на спектральное выражение. Конечно, для более углубленных исследований в будущем необходимо будет включить факторы окружающей среды в рассмотрение.
Основываясь на обсуждении, предложенная модель CNN + LSTM в этом исследовании может быть дополнительно оптимизирована в следующих двух основных направлениях: Во-первых, проектирование более комплексных контролируемых экспериментов для предоставления более богатого и детального набора обучающих данных. Во-вторых, поиск путей для приоритетного улучшения обобщающей способности модели, даже если это повлечет за собой некоторую потерю общей точности, чтобы лучше адаптировать модель к практическим сценариям применения.
Дополнительные материалы
Следующая вспомогательная информация может быть загружена по адресу: https://www.mdpi.com/article/10.3390/agriculture15030307/s1, Рисунок S1: Реальные фотографии томатов на средних и поздних стадиях роста; Рисунок S2: Метод сбора спектральных данных; Рисунок S3: Кривая точности прогнозирования неоптимизированной модели; Рисунок S4: Кривая точности прогнозирования модели после оптимизации динамической скорости обучения; Рисунок S5: Кривая точности прогнозирования модели после оптимизации L2-регуляризацией.
Список сокращений
N — Азот
K — Калий
Ca — Кальций
B — Бор
CNN — Сверточная нейронная сеть
LSTM — Долгая краткосрочная память
PLS — Метод проекции на латентные структуры
SVM — Метод опорных векторов
RF — Случайный лес
FD — Производная первого порядка
SD — Производная второго порядка
SNV — Стандартная нормальная вариация
MSC — Мультипликативная коррекция рассеяния
SG — Фильтр Сэвицкого-Голея
SPA — Алгоритм последовательных проекций
NIR — Ближний инфракрасный диапазон
RMSE — Среднеквадратическая ошибка
LOGOV — Перекрёстная проверка с исключением по группам
LOOCV — Перекрёстная проверка с исключением по одному
Ссылки
1. Hou, S.; Dang, H.; Huang, T.; Huang, Q.; Li, C.; Li, X.; Sun, Y.; Chu, H.; Qiu, W.; Liu, J.; et al. Targeting High Nutrient Efficiency to Reduce Fertilizer Input in Wheat Production of China. Field Crops Res. 2023, 292, 108809. [Google Scholar] [CrossRef]
2. Gunes, A.; Alpaslan, M.; Inal, A. Critical Nutrient Concentrations and Antagonistic and Synergistic Relationships among the Nutrients of NFT-grown Young Tomato Plants. J. Plant Nutr. 1998, 21, 2035–2047. [Google Scholar] [CrossRef]
3. Olle, M.; Bender, I. Causes and Control of Calcium Deficiency Disorders in Vegetables: A Review. J. Hortic. Sci. Biotechnol. 2009, 84, 577–584. [Google Scholar] [CrossRef]
4. Zhang, F.; Niu, J.; Zhang, W.; Chen, X.; Li, C.; Yuan, L.; Xie, J. Potassium Nutrition of Crops under Varied Regimes of Nitrogen Supply. Plant Soil 2010, 335, 21–34. [Google Scholar] [CrossRef]
5. Bonomelli, C.; de Freitas, S.T.; Aguilera, C.; Palma, C.; Garay, R.; Dides, M.; Brossard, N.; O’Brien, J.A. Ammonium Excess Leads to Ca Restrictions, Morphological Changes, and Nutritional Imbalances in Tomato Plants, Which Can Be Monitored by the N/Ca Ratio. Agronomy 2021, 11, 1437. [Google Scholar] [CrossRef]
6. Asadnia, M.; Kottapalli, A.G.P.; Miao, J.M.; Randles, A.B.; Sabbagh, A.; Kropelnicki, P.; Tsai, J.M. High Temperature Characterization of PZT(0.52/0.48) Thin-Film Pressure Sensors. J. Micromech. Microeng. 2014, 24, 015017. [Google Scholar] [CrossRef]
7. Bian, L.; Zhang, H.; Ge, Y.; Čepl, J.; Stejskal, J.; EL-Kassaby, Y.A. Closing the Gap between Phenotyping and Genotyping: Review of Advanced, Image-Based Phenotyping Technologies in Forestry. Ann. Sci. 2022, 79, 22. [Google Scholar] [CrossRef]
8. Gao, X.; Li, S.; He, Y.; Yang, Y.; Tian, Y. Spectrum Imaging for Phenotypic Detection of Greenhouse Vegetables: A Review. Comput. Electron. Agric. 2024, 225, 109346. [Google Scholar] [CrossRef]
9. Zhang, Q.; Luan, R.; Wang, M.; Zhang, J.; Yu, F.; Ping, Y.; Qiu, L. Research Progress of Spectral Imaging Techniques in Plant Phenotype Studies. Plants 2024, 13, 3088. [Google Scholar] [CrossRef]
10. Cevallos, C.; Ponce, H.; Moya-Albor, E.; Brieva, J. Vision-Based Analysis on Leaves of Tomato Crops for Classifying Nutrient Deficiency Using Convolutional Neural Networks. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
11. Tran, T.-T.; Choi, J.-W.; Le, T.-T.; Kim, J.-W. A Comparative Study of Deep CNN in Forecasting and Classifying the Macronutrient Deficiencies on Development of Tomato Plant. Appl. Sci. 2019, 9, 1601. [Google Scholar] [CrossRef]
12. Ponce, H.; Cevallos, C.; Espinosa, R.; Gutiérrez, S. Estimation of Low Nutrients in Tomato Crops Through the Analysis of Leaf Images Using Machine Learning. J. Artif. Intell. Technol. 2021, 1, 131–137. [Google Scholar] [CrossRef]
13. Minas, I.S.; Blanco-Cipollone, F.; Sterle, D. Accurate Non-Destructive Prediction of Peach Fruit Internal Quality and Physiological Maturity with a Single Scan Using near Infrared Spectroscopy. Food Chem. 2021, 335, 127626. [Google Scholar] [CrossRef] [PubMed]
14. Li, L.; Hu, D.-Y.; Tang, T.-Y.; Tang, Y.-L. Non-Destructive Detection of the Quality Attributes of Fruits by Visible-near Infrared Spectroscopy. J. Food Meas. Charact. 2023, 17, 1526–1534. [Google Scholar] [CrossRef]
15. Zahir, S.A.D.M.; Omar, A.F.; Jamlos, M.F.; Azmi, M.A.M.; Muncan, J. A Review of Visible and Near-Infrared (Vis-NIR) Spectroscopy Application in Plant Stress Detection. Sens. Actuators A Phys. 2022, 338, 113468. [Google Scholar] [CrossRef]
16. Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the Most Common Pre-Processing Techniques for near-Infrared Spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
17. Furlanetto, R.H.; Crusiol, L.G.T.; Gonçalves, J.V.F.; Nanni, M.R.; de Oliveira Junior, A.; de Oliveira, F.A.; Sibaldelli, R.N.R. Machine Learning as a Tool to Predict Potassium Concentration in Soybean Leaf Using Hyperspectral Data. Precis. Agric. 2023, 24, 2264–2292. [Google Scholar] [CrossRef]
18. Fang, J.; Jin, X.; Wu, L.; Zhang, Y.; Jia, B.; Ye, Z.; Heng, W.; Liu, L. Prediction Models for the Content of Calcium, Boron and Potassium in the Fruit of ‘Huangguan’ Pears Established by Using Near-Infrared Spectroscopy. Foods 2022, 11, 3642. [Google Scholar] [CrossRef]
19. Lyu, H.; Grafton, M.; Ramilan, T.; Irwin, M.; Sandoval, E. Assessing the Leaf Blade Nutrient Status of Pinot Noir Using Hyperspectral Reflectance and Machine Learning Models. Remote Sens. 2023, 15, 1497. [Google Scholar] [CrossRef]
20. de Brito, A.A.; Campos, F.; dos Nascimento, A.R.; de Corrêa, G.C.; da Silva, F.A.; de Teixeira, G.H.A.; Cunha Júnior, L.C. Determination of Soluble Solid Content in Market Tomatoes Using Near-Infrared Spectroscopy. Food Control 2021, 126, 108068. [Google Scholar] [CrossRef]
21. Song, J.; He, D.; Wang, J.; Mao, H. How to Diagnose Potassium Abundance and Deficiency in Tomato Leaves at the Early Cultivation Stage. Horticulturae 2023, 9, 1225. [Google Scholar] [CrossRef]
22. Ali Lakhiar, I.; Liu, X.; Wang, G.; Gao, J. Experimental Study of Ultrasonic Atomizer Effects on Values of EC and PH of Nutrient Solution. Int. J. Agric. Biol. Eng. 2018, 11, 59–64. [Google Scholar] [CrossRef]
23. Handheld Reflection Near Infrared Spectrometer R210/Near Infrared Spectrometer/Product Center. Available online: https://www.pynect.com/pageProduct/detailR210.html (accessed on 17 January 2025).
24. Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
25. Malek, S.; Melgani, F.; Bazi, Y. One-dimensional Convolutional Neural Networks for Spectroscopic Signal Regression. J. Chemom. 2018, 32, e2977. [Google Scholar] [CrossRef]
26. Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
27. Wong, T.-T.; Yang, N.-Y. Dependency Analysis of Accuracy Estimates in K-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2417–2427. [Google Scholar] [CrossRef]
28. Osco, L.P.; Ramos, A.P.M.; Faita Pinheiro, M.M.; Moriya, É.A.S.; Imai, N.N.; Estrabis, N.; Ianczyk, F.; de Araújo, F.F.; Liesenberg, V.; de Jorge, L.A.C.; et al. A Machine Learning Framework to Predict Nutrient Content in Valencia-Orange Leaf Hyperspectral Measurements. Remote Sens. 2020, 12, 906. [Google Scholar] [CrossRef]
29. Dunn, R.J.; Nattrass, M. Response of Hydroponic Tomato Yield and Yield-Correlated Morphological Characteristics to Constant or Growth Stage-Based Nutrient Management Strategies. HortScience 2024, 59, 1534–1542. [Google Scholar] [CrossRef]
30. van Maarschalkerweerd, M.; Husted, S. Recent Developments in Fast Spectroscopy for Plant Mineral Analysis. Front. Plant Sci. 2015, 6, 169. [Google Scholar] [CrossRef]
31. Prananto, J.A.; Minasny, B.; Weaver, T. Near Infrared (NIR) Spectroscopy as a Rapid and Cost-Effective Method for Nutrient Analysis of Plant Leaf Tissues. Adv. Agron. 2020, 164, 1–49. [Google Scholar] [CrossRef]
32. Azadnia, R.; Rajabipour, A.; Jamshidi, B.; Omid, M. New Approach for Rapid Estimation of Leaf Nitrogen, Phosphorus, and Potassium Contents in Apple-Trees Using Vis/NIR Spectroscopy Based on Wavelength Selection Coupled with Machine Learning. Comput. Electron. Agric. 2023, 207, 107746. [Google Scholar] [CrossRef]
33. Pandey, P.; Veazie, P.; Whipker, B.; Young, S. Predicting Foliar Nutrient Concentrations and Nutrient Deficiencies of Hydroponic Lettuce Using Hyperspectral Imaging. Biosyst. Eng. 2023, 230, 458–469. [Google Scholar] [CrossRef]
34. Whang, S.E.; Roh, Y.; Song, H.; Lee, J.-G. Data Collection and Quality Challenges in Deep Learning: A Data-Centric AI Perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
35. Čehovin, L.; Bosnić, Z. Empirical Evaluation of Feature Selection Methods in Classification. Intell. Data Anal. 2010, 14, 265–281. [Google Scholar] [CrossRef]
36. Ragusa, E.; Cambria, E.; Zunino, R.; Gastaldo, P. A Survey on Deep Learning in Image Polarity Detection: Balancing Generalization Performances and Computational Costs. Electronics 2019, 8, 783. [Google Scholar] [CrossRef]
37. Hu, X.; Chu, L.; Pei, J.; Liu, W.; Bian, J. Model Complexity of Deep Learning: A Survey. Knowl. Inf. Syst. 2021, 63, 2585–2619. [Google Scholar] [CrossRef]

Yuan Y, Sun G, Chen G, Zhang Q, Liang L. A Model for Diagnosing Mild Nutrient Stress in Facility-Grown Tomatoes Throughout the Entire Growth Cycle. Agriculture. 2025; 15(3):307. https://doi.org/10.3390/agriculture15030307
Перевод статьи «A Model for Diagnosing Mild Nutrient Stress in Facility-Grown Tomatoes Throughout the Entire Growth Cycle» авторов Yuan Y, Sun G, Chen G, Zhang Q, Liang L., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik















































































































Комментарии (0)