Умный диагноз для урожая: новая модель обнаруживает опасную инфекцию на ранней стадии
Бактерия Xanthomonas campestris представляет серьёзную угрозу для мирового сельского хозяйства из-за своей способности поражать листья, плоды и стебли в различных климатических условиях. Её быстрое распространение на обширных посевных площадях приводит к экономическим потерям, снижает урожайность, увеличивает затраты на управление и угрожает продовольственной безопасности, особенно в условиях мелкотоварного сельскохозяйственного производства. Для решения этой проблемы в данном исследовании была разработана модель, сочетающая нечёткую логику и нейронные сети, оптимизированные с помощью интеллектуальных алгоритмов, для выявления симптомов этого листового заболевания у 15 основных сельскохозяйственных культур в различных условиях окружающей среды с использованием изображений.
Аннотация
С этой целью были применены системы нечёткого вывода типа Сугено и адаптивные нейро-нечёткие системы вывода (ANFIS), настроенные с помощью правил и методов кластеризации, разработанных для решения случаев, когда диагностическая неопределённость возникает из-за неточности различных сельскохозяйственных сценариев.
Модель достигла точности 93,81%, продемонстрировав устойчивость к изменениям освещения, наличию теней и углов съёмки, и доказала свою эффективность в выявлении паттернов, связанных с заболеванием, на ранних стадиях, что позволяет проводить быструю и надёжную диагностику. Этот прогресс представляет собой значительный вклад в автоматизированное выявление болезней растений, предоставляя доступный инструмент, который повышает сельскохозяйственную производительность и способствует внедрению устойчивых практик в уходе за культурами.
1. Введение
Потери урожая, вызванные болезнями листьев растений, представляют собой растущую проблему для глобальной продовольственной безопасности, особенно в условиях демографического роста, который увеличивает спрос на продовольствие [1]. Эта проблема подчеркивает настоятельную необходимость внедрения устойчивых сельскохозяйственных решений для смягчения последствий, особенно для мелких фермеров, которые зависят от здорового урожая и экономической стабильности, обеспечиваемой их рыночной продукцией [2,3].
В традиционном сельском хозяйстве обнаружение болезней осуществляется эмпирически путем прямого и постоянного наблюдения, а его лечение в значительной степени зависит от использования пестицидов [4]. Этот подход, помимо того, что он медленный, дорогой, ненадежный и субъективный [5], может снижать производственную способность до 50% из-за сложности этой задачи.
Напротив, своевременная и точная диагностика болезней растений является ключевым компонентом точного земледелия [6], где неразрушающие методы дистанционного зондирования широко используются для мониторинга культур в видимом и невидимом спектрах [7]. Эти методы предлагают новые сельскохозяйственные решения для улучшения и оптимизации урожайности, составляя непрерывно развивающуюся область исследований [8]. Не отвергая опыт человека в решении сложных задач, этот подход представляется перспективным для повышения продуктивности сельскохозяйственных культур и автоматической защиты окружающей среды [9], сокращая значительные усилия по мониторингу и позволяя обнаруживать симптомы болезней на ранних стадиях [10].
Благодаря достижениям в области приложений активного дистанционного зондирования и технической диагностики на основе обработки изображений для создания алгоритмов обнаружения с использованием машинного обучения [11], были разработаны, например, интегрированные методы для выявления болезней риса по изображениям, полученным со смартфона, с использованием предварительной обработки в цветовом пространстве Hue Saturation Brightness (HSB) для извлечения области интереса, выполнения сегментации изображения и выделения признаков, позволяющих обнаруживать стадии тяжести болезни увядания [12].
Аналогично, в работе [13] эффективно использовались информативные области изображения для построения множественных моделей классификации изображений с помощью трансферного обучения, что позволило обнаруживать 21 заболевание у 14 культур мелкого зерна с использованием сверточных нейронных сетей, оптимизированных методом стохастического градиентного спуска, достигнув точности 93,05%. Эти исследования демонстрируют эффективность методов глубокого обучения для ранней и надежной идентификации болезней на основе распознавания образов, например, для обнаружения болезней листьев персика, вызываемых Xanthomonas campestris, с использованием архитектур, подобных AlexNet, дообученных с помощью трансферного обучения, обеспечивая надежные сельскохозяйственные диагнозы [14].
Несколько исследований также изучили использование алгоритмов машинного обучения, среди которых применение таких алгоритмов, как метод опорных векторов (SVM) [15], метод k-ближайших соседей (KNN), случайный лес, наивный байесовский классификатор [16] и деревья решений [17], которые в некоторых случаях, с помощью архитектур, таких как гибридные интеллектуальные алгоритмы, и даже методов оптимизации, таких как оптимизация роем частиц, оптимизатор градиентного спуска и алгоритмы выбора признаков [18], достигли производительности от 54,1% до 99,7%.
Однако другие исследования показали, что фермеры могут повысить точность и эффективность обнаружения и управления болезнями, применяя методы нечеткой логики в точном земледелии, что приводит к более высокой урожайности, поскольку использование нечеткой логики использует гибкость и интерпретируемость логических систем для обработки неопределенностей и неточностей, присущих сельскохозяйственным данным [19]. В этом отношении, в работе [20] была представлена передовая модель для прогнозирования болезней листьев растений с использованием адаптивной нечеткой экспертной системы, оптимизированной алгоритмом кошачьего роя на основе ястребов Харриса (CSHH), и данных, собранных с помощью IoT. Метод обрабатывает изображения листьев и данные об окружающей среде, извлекая характеристики с использованием шаблонов для классификации болезней с оптимизированными правилами «если–то». Протестированная на наборах данных по кукурузе, винограду и томату, модель продемонстрировала точность 94,61%, значительно превзойдя традиционные подходы, такие как KNN и SVM.
Аналогично, работа [21] предоставила диагноз черной пятнистости яблони с использованием адаптивной нейро-нечеткой системы на основе изображений с цифровой камеры, достигнув точности 89%. Между тем, в работе [22] использовался гибридный метод нечеткой логики и метода k-ближайших соседей (KNN) для обнаружения болезней и проблем у растений риса. В этом подходе нечеткая логика определяет степень принадлежности к классу обнаружения болезни, а KNN идентифицирует ближайшее расстояние между оцениваемыми данными и его k ближайшими соседями в обучающих данных, достигнув точности 98,74% в тестах, проведенных на 200 случаях 13 болезней и вредителей.
В этом контексте настоящее исследование предлагает модель обнаружения листовой болезни, вызываемой Xanthomonas campestris, основанную на интеграции систем нечеткого вывода, оптимизированных алгоритмами машинного обучения; цель заключалась в разработке системы, которая не только точна в обнаружении болезни, но также интерпретируема и доступна для конечных пользователей, позволяя принимать обоснованные решения. Это особенно важно в сельском хозяйстве, где доверие к автоматизированным системам в значительной степени зависит от способности пользователей понимать и проверять результаты.
Для разработки данной статьи изначально были определены сбор данных, их обработка для оптимизации результатов и конфигурация четырех нечетких и нейро-нечетких систем, которые впоследствии сравнивались на этапах тестирования и обучения, что позволило определить модель, которая обеспечивает наиболее быстрый и надежный диагноз на основе статистических тестов с их соответствующими результатами.
2. Материалы и методы
2.1. Сбор данных
Метод обнаружения болезней растений по изображениям восходит к 1980-м годам, когда в США было проведено одно из первых заметных исследований, где ученые предложили решения для снижения потерь от увядания урожая с помощью цветной инфракрасной фотографии для обнаружения инфекций у соевых культур [23]. Ранние применения включали алгоритмы распознавания образов, которые сочетали дистанционное зондирование с диагностическими методами на основе симптомов, давая точные и надежные результаты [11].
Для разработки предложенной модели был составлен набор данных из 1471 изображения, охватывающих 15 видов растений, восприимчивых к инфекциям различных подвидов Xanthomonas campestris и широко возделываемых в больших масштабах. Эти виды включают банан (Musa x paradisiaca), редис (Raphanus sativus), грецкий орех (Juglans regia), томат (Solanum lycopersicum), сою (Glycine max), тыкву (Cucurbitaceae), сливу (Prunus domestica), перец (Capsicum annuum), персик (Prunus persica), манго (Mangifera indica), фундук (Corylus avellana), капусту (Brassica oleracea), брокколи (Brassica oleracea var. italica), цветную капусту (Brassica oleracea var. gemmifera) и фасоль (Phaseolus vulgaris).
Эти виды были выбраны, потому что они являются важнейшими культурами в мировом сельском хозяйстве, поскольку многие из них играют ключевую роль в продовольственной безопасности благодаря своей высокой продуктивности, питательной ценности и адаптивности к различным регионам и климатическим условиям. Следовательно, использованные изображения представляли как здоровые, так и больные листья в различных условиях окружающей среды, включая вариации освещения, углов, теней и уровней яркости, моделируя реальные сельскохозяйственные сценарии.
В здоровом состоянии листья этих видов преимущественно зеленые, что облегчает раннее обнаружение симптомов болезни при условии, что пораженная листовая площадь имеет от 10% до 15% видимых симптомов. Более того, разнообразие формы, размера и текстуры листьев позволяет модели идентифицировать специфические паттерны, связанные с инфекцией, повышая ее точность и надежность при анализе широкого спектра листовых морфологий в различных сельскохозяйственных контекстах.
Используемый набор данных включает изображения как здоровых, так и больных листьев (см. Рисунок 1), сделанные цифровой камерой в контролируемых условиях, различающиеся с точки зрения освещения, углов, теней и яркости. Дополнительно были включены изображения из общедоступного набора данных PlantVillage , которые оказались особенно ценными благодаря своим уникальным характеристикам, таким как стандартизированный фон, постоянные условия резкости и широкая репрезентативность особенностей культур [24]. Эти атрибуты не только укрепляют качество набора данных, но и улучшают обобщающую способность модели, включая различные сценарии. Кроме того, PlantVillage является общедоступным ресурсом, широко используемым в сельскохозяйственных исследованиях, что облегчает разработку исследований на основе передовых методов обработки изображений [25].

Рисунок 1. Набор изображений листьев различных культур в разных климатических и географических условиях: листья (a) больных и (b) здоровых растений.
2.2. Предварительная обработка
Распознавание образов было сосредоточено на регионах с определенными симптомами, включая мелкие пятна неправильной формы (диаметром 1–5 мм) с черными прожилками и некротическими центрами на листьях и стеблях. Дополнительные симптомы, задокументированные в [26], включают желтые ореолы и коричневые поражения, видимые с ранних стадий инфекции.
Во время сбора изображений специфические сегменты вырезались в различных размерах (см. Рисунок 2), чтобы гарантировать, что каждый вход для модели исключает фоны, которые могли бы запутать или перегрузить ее ненужной информацией, тем самым оптимизируя процесс обучения. Изображения сохранялись в цветовой модели RGB для сохранения вариаций освещения, контраста, угла и тени, позволяя модели распознавать разные характеристики листьев в разное время суток. Этот подход позволяет модели оценивать цветовой спектр, связанный с симптомами болезни на инфицированных листьях, оценивая каждый пиксель и идентифицируя цвета, соответствующие естественному проявлению болезни.
Рисунок 2. Распознавание образов на основе пикселей в соответствии со связанной цветовой шкалой у больного растения.
Исследования, такие как [27], предположили, что предварительная обработка изображений, используемых для обучения моделей машинного обучения, может значительно улучшить визуальное качество входных изображений, оптимизируя цветовой анализ симптомов болезни и, следовательно, повышая точность диагностики. Таким образом, после получения и обрезки изображений было выполнено цветовое преобразование каждого изображения, конвертировав из модели RGB в нормализованную модель HSB. Это изменение было необходимо, потому что значения RGB высоко чувствительны к вариациям условий освещения, контраста и теней, что может вносить значительный шум и затруднять точную идентификацию паттернов, связанных с болезнью [4]. Модель HSB, в отличие от RGB, решает эти ограничения, разлагая цвет на более интерпретируемые компоненты: тон, который определяет хроматическую природу (например, красный, желтый или коричневый); насыщенность, которая позволяет дифференцировать продвинутые симптомы (интенсивные цвета) и начальные симптомы (менее насыщенные цвета); и яркость, которая отражает светлоту цвета. Этот подход повышает надежность модели, смягчая влияние меняющихся условий освещения за счет установления пороговых значений, как показано на Рисунке 3, где присвоение цветовой шкалы на основе желтых, красных и коричневых тонов позволило идентифицировать симптомы болезни у различных оцениваемых видов.

Рисунок 3. Цветовое преобразование в модель HSB: листья с (a) больными и (b) здоровыми частями.
После обработки входная модель улучшает анализ признаков для обучения, используя различные цветовые пространства и параметры. Этот подход позволяет системе различать растения без характерных пятен болезни и чей цвет попадает в диапазон, отведенный для здоровых листьев. Кроме того, он улучшает способность модели распознавать паттерны, связанные с болезнью, способствуя более точному принятию решений при идентификации здоровых и больных листьев.
2.3. Конфигурация модели
Модели машинного обучения широко используются для извлечения важнейших параметров сельскохозяйственных культур для прогнозирования. Например, в работе [28] была разработана нейронная сеть, состоящая из входного слоя, слоя функций принадлежности, слоя правил и выходного слоя, которая может прогнозировать урожайность культур устойчивым образом. При конфигурации предложенной модели целостно применяются и характеризуются точностью и интерпретируемостью две системы.
Эти системы решают неточные проблемы, для которых решения часто сложны или даже невозможны [29]. Первая система — это система вывода типа Сугено для классификации. Вторая — адаптивная нейро-нечеткая система вывода (ANFIS), выполняемая на обучающих данных для повышения точности и обобщающей способности модели. Дополнительно интегрируется интеллектуальный гибридный механизм оптимизации и алгоритм внутренней точки для улучшения способности решения проблем и общей производительности модели, эффективно сочетая преимущества нечеткой логики с машинным обучением.
2.3.1. Конфигурация нечеткой системы Сугено
Нечеткая система Сугено решает задачи классификации с помощью нечетких правил с выходными функциями, которые обычно являются линейными или постоянными, обеспечивая взаимодействие и оптимальные результаты в приложениях [30]. В предложенной модели была разработана первоначальная система Сугено для обнаружения на уровне пикселей в шкале HSB специфических признаков, связанных с цветовым тоном болезни Xanthomonas campestris. Этот выход позволяет второй системе с аналогичными характеристиками принимать решения относительно состояния листа на основе совокупных результатов изображения.
Конфигурация этой первой системы основана на трех нечетких множествах для входа, каждое структурировано с тремя функциями принадлежности, представляющими низкие, средние и высокие значения в шкале HSB (где H соответствует тону, S — насыщенности, а B — яркости). Линейная функция по умолчанию определена для выхода, облегчая моделирование взаимосвязи между входными значениями и откликом системы. Эта оптимизация улучшает процесс вывода и повышает точность принятия решений на основе анализируемых визуальных характеристик.
Чтобы сравнить точность систем, конфигурации тестировались как с кластеризацией, так и без нее. Кластеризация идентифицирует группы со схожими характеристиками внутри набора данных, помогая в сегментации и анализе, как продемонстрировал [31]. В системах, использующих нечеткую кластеризацию, правила определяются автоматически, и выполняются три правила нечеткой кластеризации, гарантируя, что каждый вход равномерно связан с выходами, с максимумом 27 правил. Для системы, реализованной без нечеткой кластеризации, был проведен разведочный анализ различных значений HSB и их значимости для идентификации здоровых или больных пикселей на основе следующих правил:
- Если значение H низкое, S низкое и B низкое, то оно здоровое;
- Если значение H низкое, S среднее и B низкое, то оно здоровое;
- Если значение H низкое, S среднее и B среднее, то оно здоровое;
- Если значение H низкое, S среднее и B высокое, то оно больное;
- Если значение H среднее, S среднее и B высокое, то оно больное;
- Если значение H низкое, S высокое и B высокое, то оно больное;
- Если значение H среднее, S высокое и B высокое, то оно больное.
Таблица 1 описывает настройки, сделанные для систем нечеткого вывода Сугено без кластеризации. В ней перечислены значения, заданные для каждой из них в функции MATLAB sugfis, с использованием версии MATLAB R2023b.
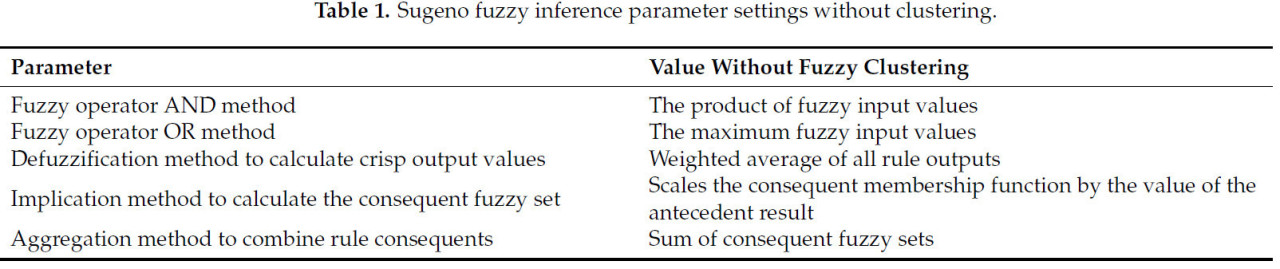
Таблица 1. Настройки параметров нечеткого вывода Сугено без кластеризации.
Для систем, реализованных с использованием нечеткой кластеризации, применялась следующая конфигурация, представленная в Таблице 2. Эти параметры, в свою очередь, были введены в функцию MATLAB genfis.
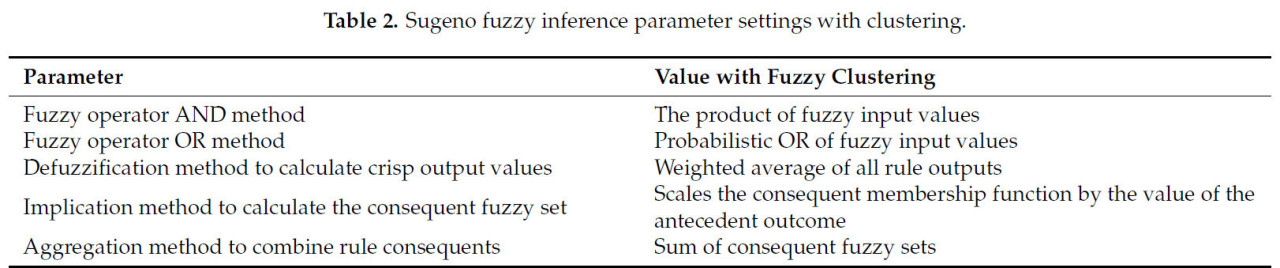
Таблица 2. Настройки параметров нечеткого вывода Сугено с кластеризацией.
Для завершения конфигурации этой первой системы были использованы три нейро-нечетких множества для входа, соответствующих различным значениям на уровне пикселей в цветовой шкале HSB. Каждое множество включает три функции принадлежности, согласующиеся с конфигурацией, определенной в кластерах, и выходное множество, которое определяет состояние пикселя (здоровый или больной) на основе его структуры, как показано на Рисунке 4. Слой правил, представленный синими кругами, интегрирует входные функции принадлежности, используя логические операции (например, И, ИЛИ), для оценки нечетких правил и генерации соответствующих выходов. Черные круги символизируют четкие (точные) значения как для входов, так и для конечного выхода, в то время как белые круги представляют промежуточные нечеткие значения, такие как степени принадлежности для входов и выходов. Эта структура улучшает интерпретацию и классификацию данных, облегчая идентификацию паттернов, указывающих на здоровье культуры, и обеспечивая эффективную реакцию на вариации цветовых значений.
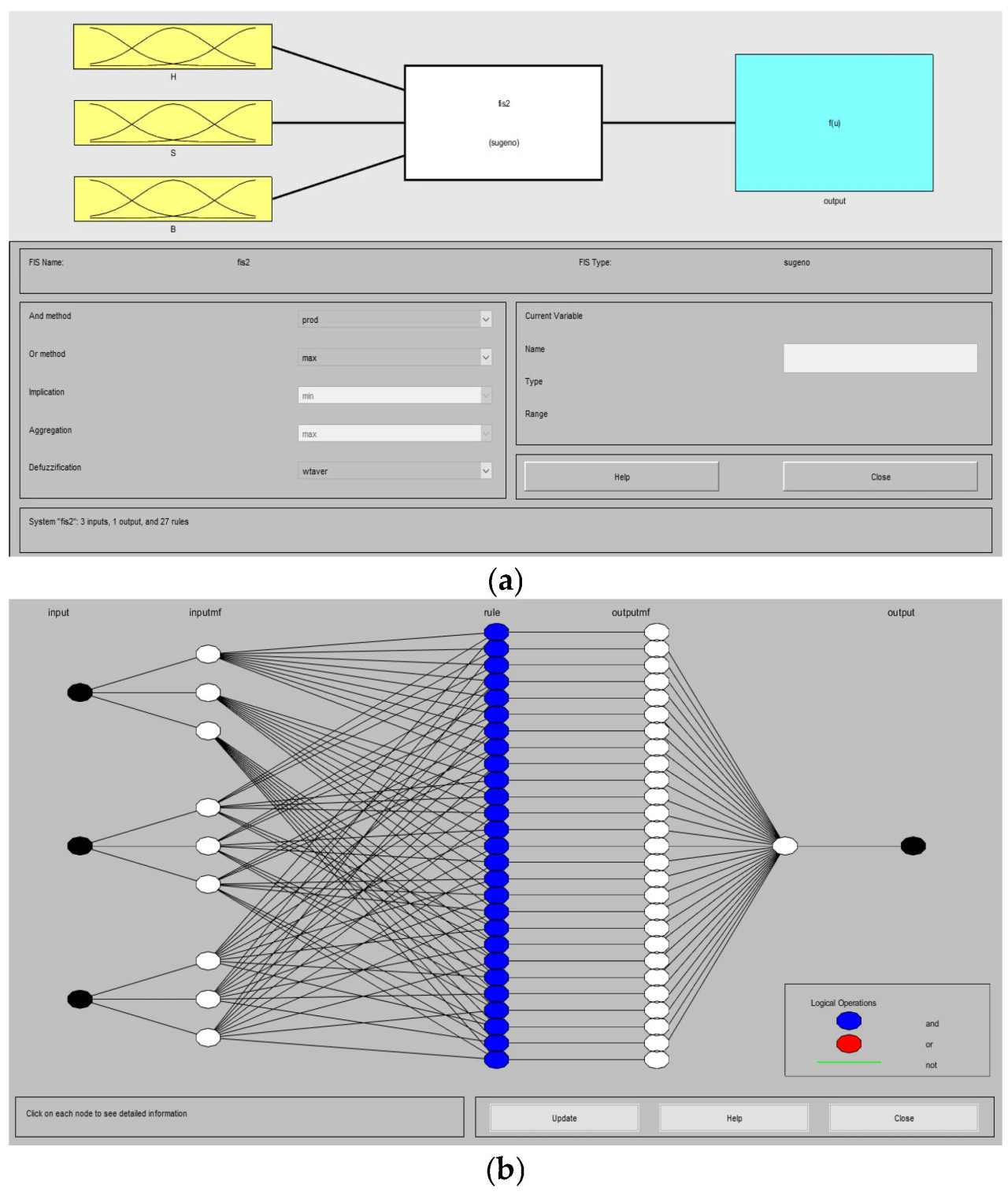
Рисунок 4. Структура нейро-нечеткой сети ANFIS для первой системы: (a) общая конфигурация нейро-нечетких множеств и их функций принадлежности; (b) архитектура нейро-нечеткой сети ANFIS для классификации.
Рисунок 5 представляет правила и их соответствие функциям принадлежности. Это представление иллюстрирует, как правила устанавливают взаимосвязь между входами и выходами, отражая результаты через линейную функцию на основе различных значений, которые могут принимать входные функции принадлежности (значения HSB). Дополнительно визуализируется выходная нейро-нечеткая поверхность, изображающая на трехмерном графике, как вариации входов — индивидуально или в комбинации — влияют на выход системы. На этом графике оси представляют входные переменные, в то время как вертикальная ось показывает соответствующее выходное значение, обеспечивая четкое понимание поведения системы в пределах пространства выборки.
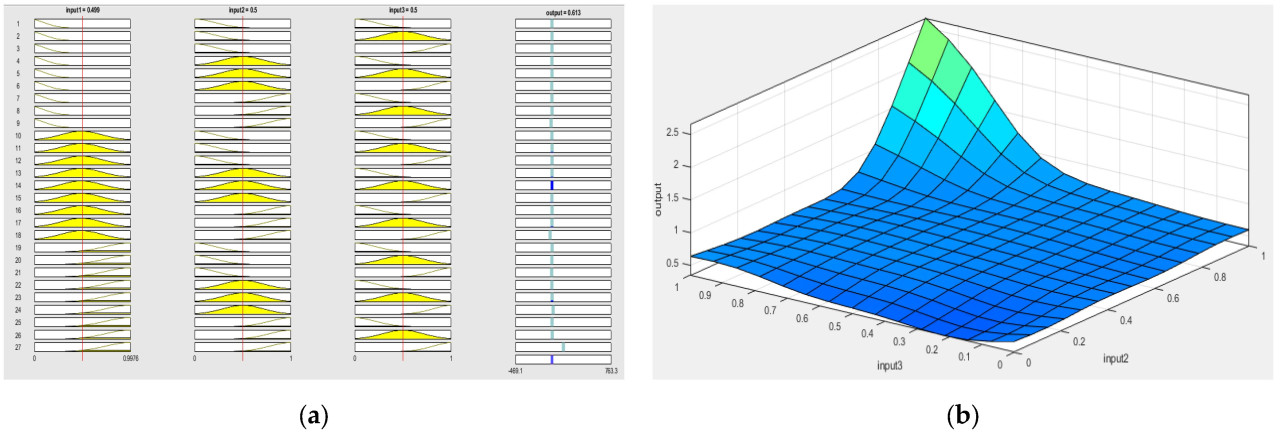
Рисунок 5. Компоненты для первой нейро-нечеткой системы вывода: (a) набор правил; (b) выходная нейро-нечеткая поверхность.
2.3.2. Конфигурация адаптивной нейро-нечеткой системы вывода (ANFIS)
Основываясь на средних (avg) результатах, полученных на уровне пикселей от первой системы, конфигурация второй системы учитывает способность модели определять, присутствует ли болезнь Xanthomonas campestris на всем изображении. Эта система состоит из пяти функций принадлежности, представляющих низкие, средне-низкие, средние, средне-высокие и высокие значения. Аналогично первой системе, линейная функция назначена по умолчанию для выхода.
В этом случае также были выполнены конфигурации с кластеризацией и без нее. Для систем, использующих нечеткую кластеризацию, правила определяются как в первой системе; однако выполняются пять правил нечеткой кластеризации. Для системы, реализованной без нечеткой кластеризации, был проведен разведочный анализ различных значений HSB и их значимости в идентификации здоровых или больных пикселей на основе следующих правил:
- Если значение avg высокое, то оно здоровое;
- Если значение avg средне-высокое, то оно здоровое;
- Если значение avg среднее, то оно здоровое;
- Если значение avg средне-низкое, то оно больное;
- Если значение avg низкое, то оно больное.
Нейро-нечеткие системы вывода создаются после разработки систем нечеткого вывода, которые объединяют искусственные нейронные сети и нечеткую логику для облегчения принятия решений на основе неточной или неопределенной информации. Эта способность проистекает из их чувствительности к определению функций принадлежности [32]. Кроме того, эта система использует гибридную процедуру обучения, которая строит карту «вход-выход» на основе человеческих знаний, эффективно описывая, как значения могут принадлежать к разным категориям, тем самым значительно сокращая время моделирования [33].
Для ее конфигурации был установлен максимальный предел в 600 этапов обучения, и, аналогично системе нечеткого вывода, конфигурации с кластеризацией и без нее были выполнены с теми же параметрами. Эта система использовала метод оптимизации обратного распространения ошибки для входа, в то время как метод наименьших квадратов применялся для выхода. Валидация проводилась с различными входными и ожидаемыми выходными тестовыми значениями, что помогло избежать переобучения в каждом случае.
Наконец, нейро-нечеткая конфигурация второй системы основана на входном множестве, которое представляет среднее значение результатов, полученных от изображения, предварительно оцененного первой системой. Структура этой системы использует одно входное множество с пятью функциями принадлежности, связывая входные данные с выходом, как показано на Рисунке 6. Черные точки представляют четкие (точные) значения для входа и выхода, в то время как белые точки соответствуют промежуточным нечетким значениям, таким как степени принадлежности входных данных и состояние выхода. Эта конфигурация обеспечивает быстрый и точный диагноз состояния листа относительно присутствия Xanthomonas campestris, облегчая раннюю идентификацию болезни и способствуя более эффективному управлению культурами.
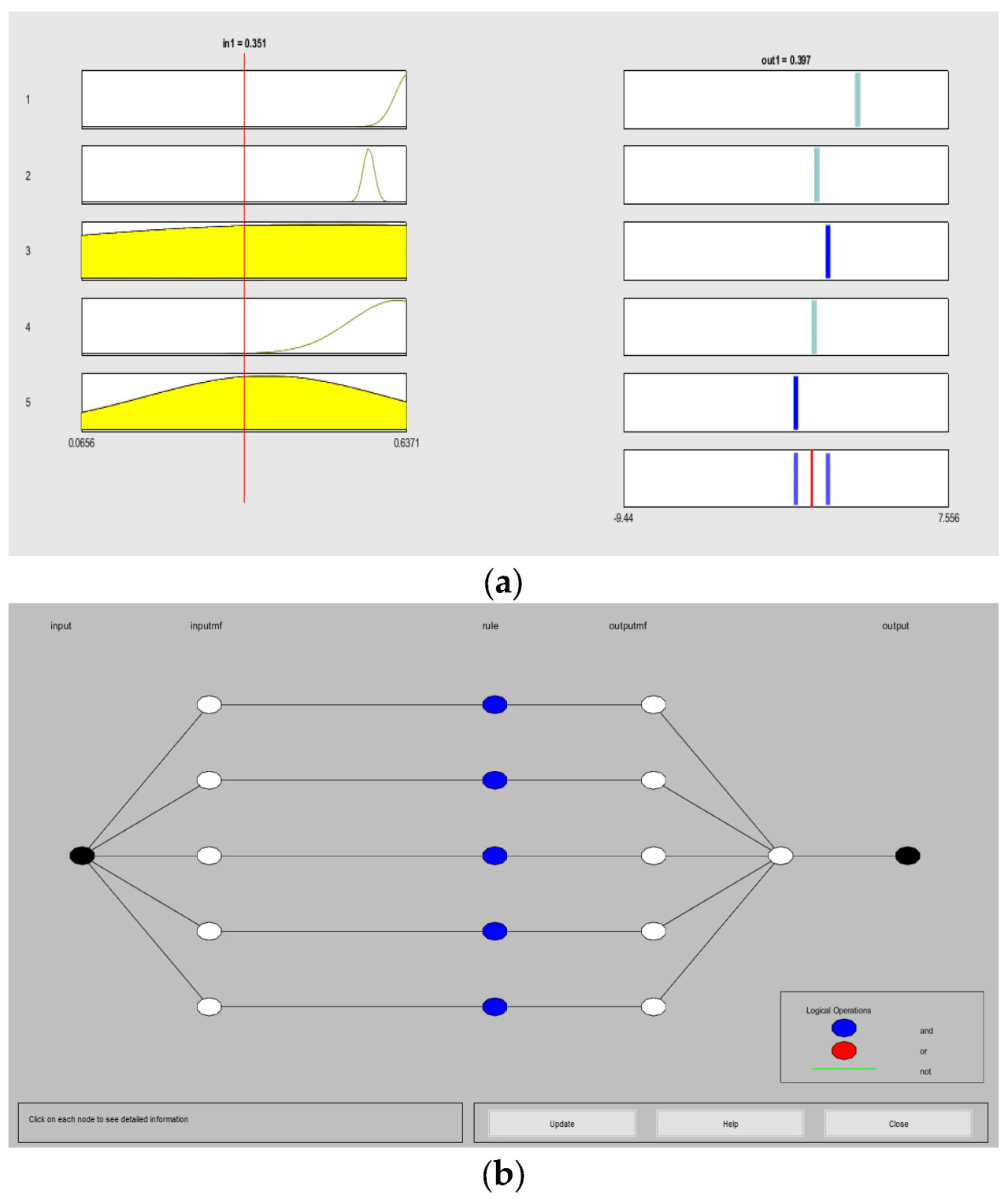
Рисунок 6. Конфигурация второй нейро-нечеткой системы вывода: (a) набор правил; (b) архитектура нейро-нечеткой сети ANFIS для диагностики.
2.4. Оптимизация
Чтобы минимизировать потерю информации на изображениях и обеспечить наиболее точные результаты при быстрой диагностике, модель была оптимизирована путем реализации гибридного алгоритма. Параметры этого алгоритма указаны в Таблице 3 и были установлены, чтобы позволить модели идентифицировать точки-кандидаты из здоровых пикселей. Это было достигнуто путем двукратного расширения точек-кандидатов без использования пикселей, полученных от алгоритма внутренней точки после выполнения генетического алгоритма.

Таблица 3. Параметры для реализации генетического алгоритма.
3. Результаты
После определения процесса выбора переменных и конфигурации нейро-нечетких систем были разработаны четыре модели: две для системы, которая оценивает состояние изображения на основе входных данных на уровне пикселей в шкале HSB, используя либо нечеткую кластеризацию в одном случае, либо определенные правила в другом. Оставшиеся две модели определяют диагноз листа на основе среднего значения всех пикселей изображения, обработанного первой системой, с установленными диапазонами для больного (0.3884 до 0.54) и здорового (0.55 до 0.70) состояний.
Каждая модель была запущена 50 раз, используя 70% набора данных для обучения и оставшиеся 30% для тестирования. В первой валидации результаты сравнивались с точки зрения максимальной, минимальной, средней квадратичной ошибки (MSE), среднеквадратической ошибки (RMSE) и средней абсолютной ошибки (MAE) для обучающих и валидационных наборов данных. Эти результаты обобщены в Таблицах 4 и 5, выделяя выполнения с наименьшей квадратичной ошибкой и идентифицируя наилучшее выполнение в каждом случае. Важно отметить, что некоторые модели могут сходиться к локальным минимумам, а не достигать глобального минимума.
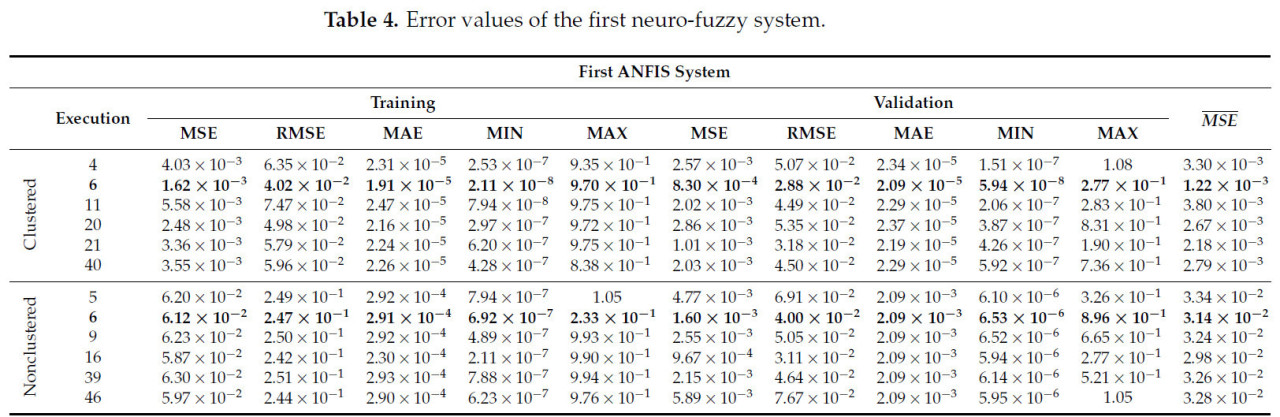
Таблица 4. Значения ошибок первой нейро-нечеткой системы.
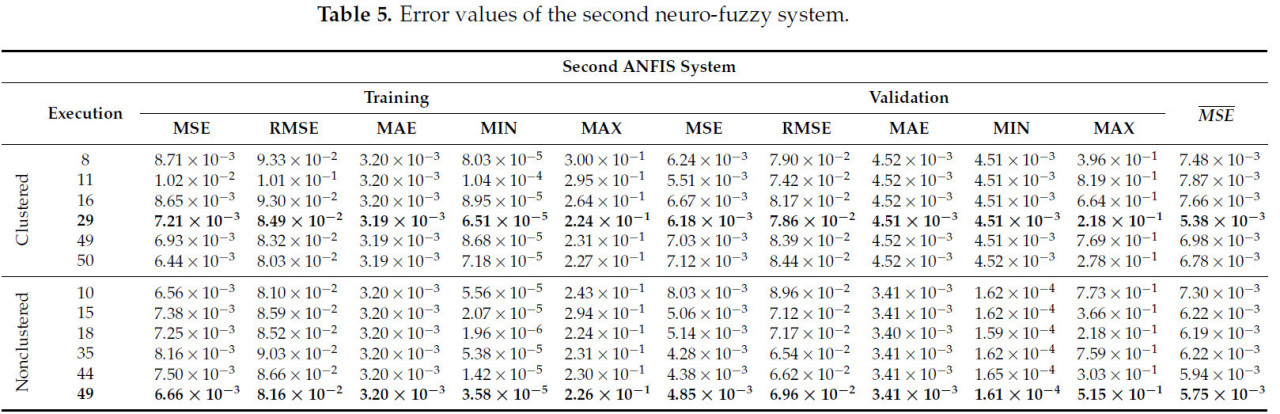
Таблица 5. Значения ошибок второй нейро-нечеткой системы.
Чтобы определить систему с наилучшей точностью и производительностью, особенно при использовании кластеров, результаты оценивались с точки зрения максимальной и минимальной ошибок, средней квадратичной ошибки (MSE), среднеквадратической ошибки (RMSE) и средней абсолютной ошибки (MAE) в обучающих и валидационных наборах данных. Дополнительно был проведен тест Краскела-Уоллиса для сравнения медиан групп данных и оценки, происходят ли выборки из одной и той же совокупности. Наконец, для лучшей модели была использована матрица ошибок для количественной оценки ее производительности, помогая идентифицировать ошибки через все прогнозы.
3.1. Обучение
Во время обучения были выбраны изображения, демонстрирующие наиболее узнаваемые паттерны болезни, чтобы избежать избыточности и путаницы, которые могли бы негативно повлиять на конечный диагноз. Этот подход гарантировал, что процесс обучения основан на репрезентативных и разнообразных примерах. Впоследствии было проведено 50 запусков двух систем, давших результаты, обобщенные в Таблице 6, которая представляет статистические значения и выделяет запуск, достигший наилучшего результата.
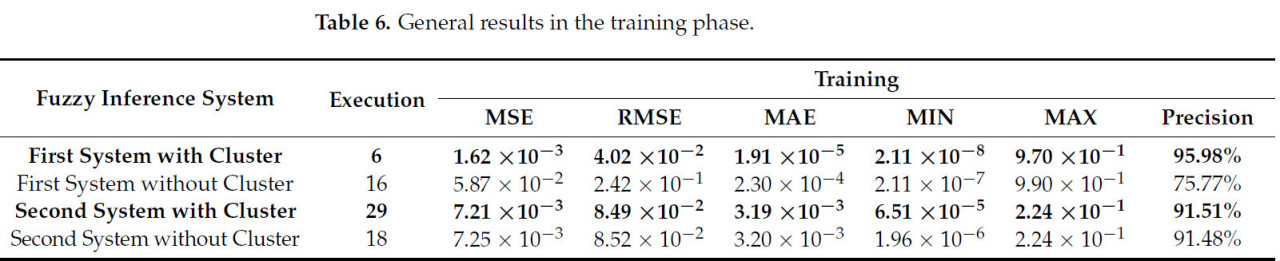
Таблица 6. Общие результаты на фазе обучения.
Чтобы определить точность, с которой системы на основе кластеризации делают прогнозы по отношению к фактическим результатам, и оценить производительность их конфигураций, их результаты были проанализированы с учетом смоделированных и реальных значений. Этот анализ позволил идентифицировать потенциальные паттерны ошибок, точки путаницы в классификациях и оценить эффективность модели, выделяя области для улучшения и корректировок во время обучения для оптимизации производительности и обеспечения надежной диагностики.
В случае первой системы, во время фазы обучения, ожидаемые данные для здорового пикселя показывали значение, близкое к 0,62, в то время как смоделированные значения для больных пикселей приближались к 0,3884. Основываясь на этом, зарегистрированная средняя квадратичная ошибка (MSE) составила 1,62 × 10−3, указывая на минимальные различия между симуляцией и ожидаемыми значениями. Это свидетельствует о том, что численно такие метрики ошибок, как MAE и RMSE, будучи низкими, являются явными индикаторами хорошо откалиброванной прогностической модели. Хотя определенные итерации могут давать результаты, значительно отличающиеся от реальных значений, они, по-видимому, являются спорадическими и не оказывают значительного влияния на общую стабильность модели.
С другой стороны, производительность второй системы во время фазы обучения оценивалась путем сравнения среднего значений, сгенерированных первой системой, и определения ошибки на основе прогноза состояния растения. В этом случае была зарегистрирована MSE 7,21 × 10−3, указывающая на отсутствие крупных повторяющихся ошибок, и большинство смоделированных значений остаются близкими к фактическим. Это предполагает, что модель не только эффективно следует трендам, но также демонстрирует низкую дисперсию ошибок, поддерживая низкий средний уровень ошибок и устойчивость к аномалиям.
3.2. Тест
Для фазы тестирования изображения были случайным образом выбраны из здоровых образцов и инфицированных Xanthomonas campestris, которые не использовались при обучении модели. Этот подход был принят, чтобы более точно проверить способность модели распознавать ранее невиданные паттерны. Как и на фазе обучения, было проведено 50 запусков, в результате чего получена сводка статистических данных, представленная в Таблице 7, и обеспечена аппроксимация реальной точности систем.
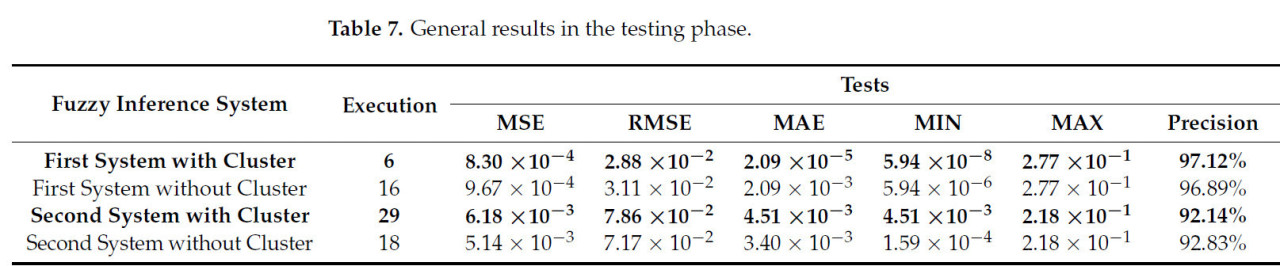
Таблица 7. Общие результаты на фазе тестирования.
Как и на фазе обучения, фаза тестирования также оценивала точность прогнозов систем на основе кластеризации по отношению к результатам. Чтобы оценить производительность их конфигураций, их результаты были проанализированы с учетом смоделированных и фактических значений.
Для первой системы ожидаемое значение для данных здорового пикселя оставалось неизменным, близким к 0,62. Между тем, поведение, полученное в результате сравнения смоделированных и ожидаемых значений для пикселей, представляющих больные состояния, приближалось к 0,3884. На этой фазе график средней квадратичной ошибки (MSE) указывает на значение 8,30 × 10−4, показывая лучшую производительность по сравнению с фазой обучения. Однако смоделированные данные демонстрировали значительную изменчивость, представляя потенциальное обнаружение необычных событий. Эта изменчивость предполагает чувствительность модели к факторам, влияющим на производительность, демонстрируя потенциал для корректировки и улучшения точности в будущих итерациях.
Наконец, производительность второй системы оценивалась путем сравнения смоделированных результатов с фактическими значениями. В этом случае MSE, равная 6,18 × 10−3, указывает, что хотя были некоторые значительные различия между фактическими и смоделированными значениями в определенных точках, среднее квадратов разностей оставалось относительно небольшим. Это означает, что смоделированные значения недалеки от фактических, несмотря на некоторые вариации, консолидируя достаточно хорошую модель. Кроме того, низкая MAE предполагает, что в абсолютном выражении средние различия между смоделированными и фактическими значениями малы. Хотя модель не всегда точно предсказывает конкретные точки, отклонения, как правило, незначительны и находятся в пределах приемлемого диапазона, что является положительным аспектом модели.
В целом, система на фазе тестирования хорошо справилась с захватом общей тенденции фактических данных. Средняя ошибка была мала, что означает, что хотя система не может идеально следовать резким изменениям или исключительным событиям, она не делает чрезвычайно больших ошибок. Эти результаты подчеркивают надежность модели и ее способность к обобщению, что является ключевым для ее применения в реальных сельскохозяйственных диагностических сценариях.
3.3. Валидация лучшей модели
Основываясь на полученных результатах, первая и вторая нейро-нечеткие системы с кластеризацией были идентифицированы как модели с наилучшей производительностью. Для валидации этого вывода был проведен тест Краскела-Уоллиса. Этот тест, который не требует, чтобы данные следовали нормальному распределению, обеспечивает большую универсальность для различных типов данных, сравнивая медианы групп данных, чтобы определить, происходят ли выборки из одной и той же совокупности, проверяя эквидистрибуцию. Другими словами, он оценивает, принадлежат ли после применения алгоритмов оптимизации результаты модели для обучающих данных и их ожидаемые значения одной и той же популяции.
Тест был проведен на уровне значимости 0,05 и дал p-значение 0,646. Поскольку это значение выше порога, мы заключаем, что выборки эквидистрибутивны и принадлежат одному распределению. Таким образом, нулевая гипотеза не может быть отвергнута, что предполагает, что модель, использующая нечеткую кластеризацию, дает последовательные и надежные результаты.
3.4. Общая производительность модели
После достижения оптимальных результатов с нейро-нечеткой моделью вывода с кластеризацией, улучшенной гибридным интеллектуальным алгоритмом, конфигурация модели была оценена с использованием матрицы ошибок, примененной ко всему набору данных, как показано на Рисунке 7. Эта матрица демонстрирует, что модель достигла общей точности 92,34%, чувствительности 95,28%, специфичности 92,40% и точности 93,81%. Эти метрики подчеркивают эффективность модели в обнаружении болезни с высокой степенью надежности ее прогнозов. Высокая чувствительность указывает на силу модели в точной идентификации положительных случаев, в то время как специфичность выделяет ее компетентность в правильной классификации отрицательных случаев.
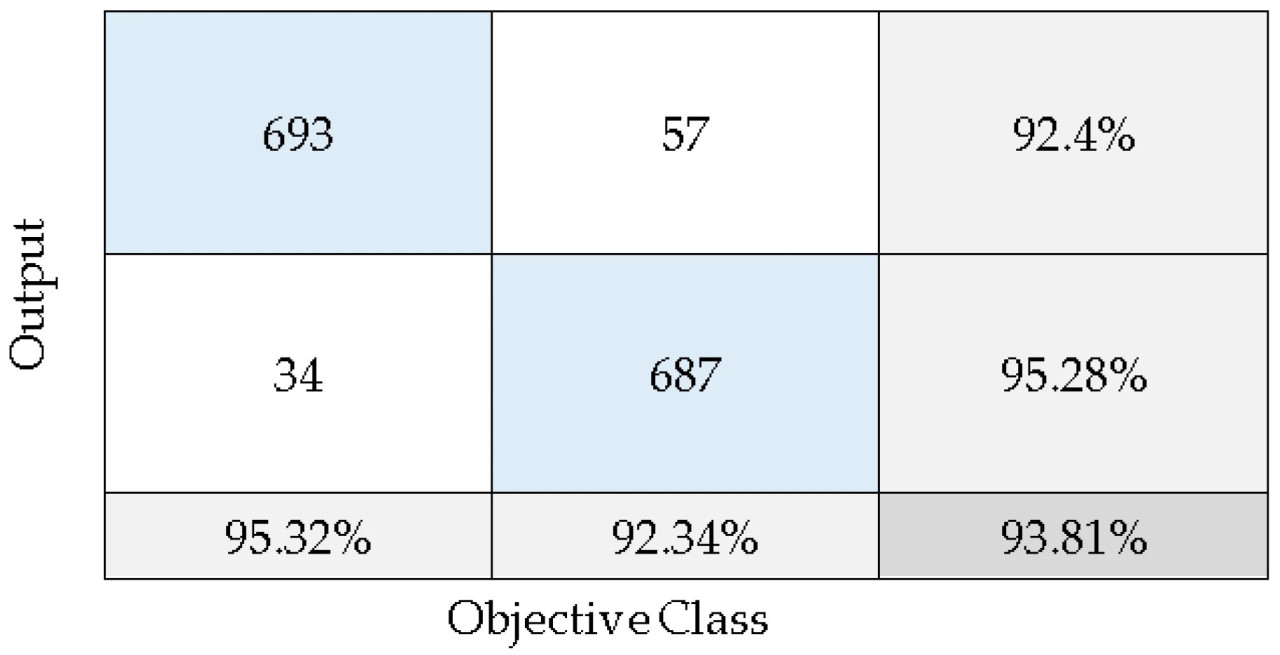
Рисунок 7. Матрица ошибок модели с наилучшей производительностью.
4. Обсуждение
В последние годы исследования, сосредоточенные на искусственном зрении и распознавании образов, сместились в сторону автоматизации процесса обнаружения болезней в сельскохозяйственных культурах [34], что привело к разработке систем, способных идентифицировать болезни листьев с меньшим ручным вмешательством [35] и способных точно и быстро диагностировать разнообразие болезней сельскохозяйственных культур, обеспечивая надежные и быстрые результаты с помощью компьютеризированных обнаружений [36]. Этот прогресс особенно ценен для культур, восприимчивых к листовым болезням, таким как фитофтороз, которые могут быстро распространяться, вызывая гибель растений и значительно снижая сельскохозяйственную продуктивность [37].
Результаты, полученные в этом исследовании, подчеркивают потенциал сочетания нечеткой логики с нейронными сетями, демонстрируя, что их использование не только эффективно для моделирования сложных систем с неопределенностью, но и для адаптации к различным сельскохозяйственным сценариям. Эта адаптивность обусловлена их способностью интегрировать факторы окружающей среды, такие как вариации света, что облегчает раннее обнаружение болезней, таких как Xanthomonas campestris, даже на начальных стадиях. Кроме того, конфигурируемость модели ANFIS позволяет ее применение как для специфических болезней культур, так и для различных видов, показывая последовательные результаты через различные сценарии.
По сравнению с другими передовыми архитектурами, такими как DenseNet (средняя точность 97%) [38] и продвинутые многозадачные сети, такие как VGG16 (точность до 98,75%) [39], модель ANFIS предлагает более интерпретируемую и адаптируемую альтернативу. Это преимущество особенно актуально для культур с ограниченными историческими данными, где методы глубокого обучения требуют обширного переобучения, тем самым увеличивая как затраты, так и время реализации.
Этот подход особенно актуален для мелкотоварного сельского хозяйства, где доступ к передовым технологиям и диагностическим экспертам ограничен, в то время как ANFIS обеспечивает более доступное и устойчивое решение, которое может интегрироваться с недорогими технологиями, такими как базовые дистанционные датчики, представляя значительный прогресс в автоматизации мониторинга сельскохозяйственных культур. Кроме того, использование изображений в качестве входа облегчает его внедрение в системах мониторинга в реальном времени, так как модель продемонстрировала диагностическую точность 93,8%, значительно увеличивая надежность мониторинга сельскохозяйственных культур и обеспечивая фермеров доступным инструментом для быстрого вмешательства, существенно сокращая их потери.
Этот прогресс особенно выгоден эмпирическим фермерам, поскольку снижает их зависимость от экспертов по уходу за культурами и мониторингу, оптимизируя принятие решений и способствуя более эффективному управлению ресурсами, что может улучшить сельскохозяйственную продуктивность.
Однако важно отметить, что, хотя модель показала высокую производительность при оцененных условиях, ее эффективность может зависеть от таких факторов, как качество изображения и экстремальные вариации условий окружающей среды. Кроме того, хотя в наборе данных использовалось 15 различных видов, было бы полезно расширить разнообразие видов, чтобы исследовать производительность модели в более широком диапазоне сельскохозяйственных культур.
Наконец, важно подчеркнуть, что методы, основанные на машинном обучении, имеют значительный потенциал для двойного использования: увеличения урожайности сельскохозяйственных культур и сокращения использования пестицидов, особенно по мере продолжения роста глобального населения. Поэтому является ключевым продолжать работать над различными направлениями исследований, которые решают эти проблемы. Будущие исследования могут быть сосредоточены на интеграции этой модели в мобильные платформы или дроны для полевого использования, что позволит фермерам более эффективно и точно контролировать посевы. Также может быть возможно исследовать интеграцию этого подхода с другими системами мониторинга на основе датчиков, такими как влажность или температура, чтобы обеспечить более полный и точный диагноз состояния сельскохозяйственных культур.
5. Выводы
Это исследование продемонстрировало эффективность моделей нейро-нечеткого вывода с кластеризацией для обнаружения болезни, вызываемой Xanthomonas campestris в сельскохозяйственных культурах. Путем интеграции нечеткой кластеризации были реализованы две оптимизированные нейро-нечеткие системы, идентифицированные как лучшие модели, и модель показала сильную способность генерировать точные и надежные прогнозы.
Эта модель в целом основана на распознавании образов и обработке цифровых изображений, захватывая данные из различных источников, включая специализированные и RGB-изображения, при случайных условиях освещения, яркости и контраста. Путем последующего применения цветовой модели HSB и обрезки изображений на специфические разделы она обеспечивает диагноз листьев, достигая точности 93,81%, точности 92,34%, чувствительности 95,28% и специфичности 92,40%. Эта производительность позволяет пользователям получить доступ к надежной модели, способной оптимизировать процесс ухода и повышать продуктивность 15 видов сельскохозяйственных культур.
Помимо точности, интерпретируемость модели является ключевой особенностью этого исследования. В отличие от других подходов с глубокими нейронными сетями, система нечеткого вывода позволяет пользователям понять процессы принятия решений внутри модели. Эта прозрачность важна для укрепления доверия фермеров к технологии и облегчения ее внедрения.
Исследование подчеркивает адаптивность модели через различные виды сельскохозяйственных культур и ее способность работать в различных условиях окружающей среды. Эта особенность предполагает потенциал для интеграции в инструменты точного земледелия, такие как дроны и устройства IoT, позволяя осуществлять мониторинг болезней в реальном времени и значительно сокращая ручное вмешательство.
Обеспечивая интерпретируемую и доступную диагностическую модель, данный подход расширяет возможности фермеров для принятия обоснованных решений. Это приводит к более эффективному управлению ресурсами, включая оптимизированное применение пестицидов, способствуя устойчивым сельскохозяйственным практикам и снижению воздействия на окружающую среду.
Однако исследование также выявило определенные ограничения, которые следует решить в будущей работе. Например, зависимость модели от высококачественных изображений и необходимость обширной предварительной обработки могут ограничивать ее применимость в условиях, где эти ресурсы нелегко доступны. Поэтому, чтобы максимизировать ее влияние, следует разрабатывать решения, которые могут интегрироваться с другими передовыми сельскохозяйственными технологиями, такими как дроны и датчики реального времени, чтобы обеспечить фермеров более целостными и эффективными ответами.
Ссылки
1. Metre, V.A.; Sawarkar, S.D. Reviewing Important Aspects of Plant Leaf Disease Detection and Classification. In Proceedings of the 2022 International Conference for Advancement in Technology (ICONAT), Goa, India, 21–22 January 2022; pp. 1–8. [Google Scholar]
2. Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.Z.; Brohi, S.N. Performance of Deep Learning vs Machine Learning in Plant Leaf Disease Detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
3. Yadav, R.; Kumar, Y.; Nagpal, S. Plant Leaf Disease Detection and Classification Using Particle Swarm Optimization; Springer Nature: Cham, Switzerland, 2019; pp. 294–306. [Google Scholar] [CrossRef]
4. Sharma, P.; Berwal, Y.P.S.; Ghai, W. Performance Analysis of Deep Learning CNN Models for Disease Detection in Plants Using Image Segmentation. Inf. Process. Agric. 2020, 7, 566–574. [Google Scholar] [CrossRef]
5. Rashid, J.; Khan, I.; Ali, G.; Almotiri, S.H.; AlGhamdi, M.A.; Masood, K. Multi-Level Deep Learning Model for Potato Leaf Disease Recognition. Electronics 2021, 10, 2064. [Google Scholar] [CrossRef]
6. Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A Review of Deep Learning in Multiscale Agricultural Sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
7. Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intell. Neurosci. 2016, 2016, 3289801. [Google Scholar] [CrossRef]
8. Kerkech, M.; Hafiane, A.; Canals, R. VddNet: Vine Disease Detection Network Based on Multispectral Images and Depth Map. Remote Sens. 2020, 12, 3305. [Google Scholar] [CrossRef]
9. Kocian, A.; Incrocci, L. Learning from Data to Optimize Control in Precision Farming. Stats 2020, 3, 239–245. [Google Scholar] [CrossRef]
10. Jackulin, C.; Murugavalli, S. A Comprehensive Review on Detection of Plant Disease Using Machine Learning and Deep Learning Approaches. Meas. Sens. 2022, 24, 100441. [Google Scholar] [CrossRef]
11. Shin, J.; Chang, Y.K.; Heung, B.; Nguyen-Quang, T.; Price, G.W.; Al-Mallahi, A. Effect of Directional Augmentation Using Supervised Machine Learning Technologies: A Case Study of Strawberry Powdery Mildew Detection. Biosyst. Eng. 2020, 194, 49–60. [Google Scholar] [CrossRef]
12. Abu Bakar, M.N.; Abdullah, A.H.; Abdul Rahim, N.; Yazid, H.; Misman, S.N.; Masnan, M.J. Rice Leaf Blast Disease Detection Using Multi-Level Colour Image Thresholding. J. Telecommun. Electron. Comput. Eng. (JTEC) 2018, 10, 1–6. [Google Scholar]
13. Yang, G.; He, Y.; Yang, Y.; Xu, B. Fine-Grained Image Classification for Crop Disease Based on Attention Mechanism. Front. Plant Sci. 2020, 11, 600854. [Google Scholar] [CrossRef] [PubMed]
14. Zhang, K.; Xu, Z.; Dong, S.; Cen, C.; Wu, Q. Identification of Peach Leaf Disease Infected by Xanthomonas campestris with Deep Learning. Eng. Agric. Environ. Food 2019, 12, 388–396. [Google Scholar] [CrossRef]
15. Van De Vijver, R.; Mertens, K.; Heungens, K.; Somers, B.; Nuyttens, D.; Borra-Serrano, I.; Lootens, P.; Roldán-Ruiz, I.; Vangeyte, J.; Saeys, W. In-Field Detection of Alternaria Solani in Potato Crops Using Hyperspectral Imaging. Comput. Electron. Agric. 2020, 168, 105106. [Google Scholar] [CrossRef]
16. Kasinathan, T.; Singaraju, D.; Uyyala, S.R. Insect Classification and Detection in Field Crops Using Modern Machine Learning Techniques. Inf. Process. Agric. 2021, 8, 446–457. [Google Scholar] [CrossRef]
17. Poblete, T.; Camino, C.; Beck, P.S.A.; Hornero, A.; Kattenborn, T.; Saponari, M.; Boscia, D.; Navas-Cortes, J.A.; Zarco-Tejada, P.J. Detection of Xylella fastidiosa Infection Symptoms with Airborne Multispectral and Thermal Imagery: Assessing Bandset Reduction Performance from Hyperspectral Analysis. ISPRS J. Photogramm. Remote Sens. 2020, 162, 27–40. [Google Scholar] [CrossRef]
18. Cruz, A.; Ampatzidis, Y.; Pierro, R.; Materazzi, A.; Panattoni, A.; De Bellis, L.; Luvisi, A. Detection of Grapevine Yellows Symptoms in Vitis vinifera L. with Artificial Intelligence. Comput. Electron. Agric. 2019, 157, 63–76. [Google Scholar] [CrossRef]
19. Sinha, M.; Tiwary, R. Utilizing Fuzzy Logic in Precision Agriculture: Techniques for Disease Detection and Management. J. Stat. Math. Eng. 2024, 10, 35–40. [Google Scholar] [CrossRef]
20. Karande, M.U.; Satarkar, S.L. Optimized Adaptive Fuzzy Expert System-Based Plant Leaf Disease Prediction Model Using Data Through Internet of Things. Migr. Lett. 2024, 21, 339–361. [Google Scholar]
21. Omrani, E.; Khoshnevisan, B.; Shamshirband, S.; Saboohi, H.; Anuar, N.B.; Nasir, M.H.N.M. Potential of Radial Basis Function-Based Support Vector Regression for Apple Disease Detection. Measurement 2014, 55, 512–519. [Google Scholar] [CrossRef]
22. Anamisa, D.R.; Satoto, B.D.; Yusuf, M.; Sophan, M.K.; Alamsyah, N.; Muntasa, A. Web-Based Rice Pest and Diseases Detection Using Hybrid Fuzzy and K-Nearest Neighbor Methods. In Proceedings of the 2022 6th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 28–29 September 2022; pp. 54–59. [Google Scholar]
23. Kerkech, M.; Hafiane, A.; Canals, R. Vine Disease Detection in UAV Multispectral Images Using Optimized Image Registration and Deep Learning Segmentation Approach. Comput. Electron. Agric. 2020, 174, 105446. [Google Scholar] [CrossRef]
24. Xiong, Y.; Liang, L.; Wang, L.; She, J.; Wu, M. Identification of Cash Crop Diseases Using Automatic Image Segmentation Algorithm and Deep Learning with Expanded Dataset. Comput. Electron. Agric. 2020, 177, 105712. [Google Scholar] [CrossRef]
25. Hernández, S.; López, J.L. Uncertainty Quantification for Plant Disease Detection Using Bayesian Deep Learning. Appl. Soft Comput. J. 2020, 96, 106597. [Google Scholar] [CrossRef]
26. Matsunaga, T.M.; Ogawa, D.; Taguchi-Shiobara, F.; Ishimoto, M.; Matsunaga, S.; Habu, Y. Direct Quantitative Evaluation of Disease Symptoms on Living Plant Leaves Growing under Natural Light. Breed. Sci. 2017, 67, 316–319. [Google Scholar] [CrossRef] [PubMed]
27. Gargade, A.; Khandekar, S. Custard Apple Leaf Parameter Analysis, Leaf Diseases, and Nutritional Deficiencies Detection Using Machine Learning. In Advances in Signal and Data Processing: Select Proceedings of ICSDP 2019; Springer: Singapore, 2021; pp. 57–74. [Google Scholar]
28. Elavarasan, D.; Durai Raj Vincent, P.M. Fuzzy Deep Learning-Based Crop Yield Prediction Model for Sustainable Agronomical Frameworks. Neural Comput. Appl. 2021, 33, 13205–13224. [Google Scholar] [CrossRef]
29. Esmaili, M.; Aliniaeifard, S.; Mashal, M.; Vakilian, K.A.; Ghorbanzadeh, P.; Azadegan, B.; Seif, M.; Didaran, F. Assessment of Adaptive Neuro-Fuzzy Inference System (ANFIS) to Predict Production and Water Productivity of Lettuce in Response to Different Light Intensities and CO2 Concentrations. Agric. Water Manag. 2021, 258, 107201. [Google Scholar] [CrossRef]
30. Wieczynski, J.; Lucca, G.; Borges, E.; Urio-Larrea, A.; Molina, C.L.; Bustince, H.; Dimuro, G. Application of the Sugeno Integral in Fuzzy Rule-Based Classification. Appl. Soft Comput. 2024, 167, 112265. [Google Scholar] [CrossRef]
31. Zhang, S.; You, Z.; Wu, X. Plant Disease Leaf Image Segmentation Based on Superpixel Clustering and EM Algorithm. Neural Comput. Appl. 2019, 31, 1225–1232. [Google Scholar] [CrossRef]
32. Sarlaki, E.; Sharif Paghaleh, A.; Kianmehr, M.H.; Asefpour Vakilian, K. Valorization of Lignite Wastes into Humic Acids: Process Optimization, Energy Efficiency and Structural Features Analysis. Renew. Energy 2021, 163, 105–122. [Google Scholar] [CrossRef]
33. Yang, J.; Chen, T.; Chen, L.; Zhao, J. Towards A Clustering Guided Rule Interpolation for ANFIS Construction. In Proceedings of the 2024 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Yokohama, Japan, 30 June–5 July 2024; pp. 1–6. [Google Scholar]
34. Munjal, D.; Singh, L.; Pandey, M.; Lakra, S. A Systematic Review on the Detection and Classification of Plant Diseases Using Machine Learning. Int. J. Softw. Innov. (IJSI) 2023, 11, 1–25. [Google Scholar] [CrossRef]
35. Nagi, R.; Tripathy, S.S. Plant Disease Identification Using Fuzzy Feature Extraction and PNN. Signal Image Video Process 2023, 17, 2809–2815. [Google Scholar] [CrossRef]
36. Ayoub Shaikh, T.; Rasool, T.; Rasheed Lone, F. Towards Leveraging the Role of Machine Learning and Artificial Intelligence in Precision Agriculture and Smart Farming. Comput. Electron. Agric. 2022, 198, 107119. [Google Scholar] [CrossRef]
37. V, S.; Bhagwat, A.; Laxmi, V.; Shrivastava, S. A Custom Backbone UNet Framework with DCGAN Augmentation for Efficient Segmentation of Leaf Spot Diseases in Jasmine Plant. J. Comput. Netw. Commun. 2024, 2024, 5057538. [Google Scholar] [CrossRef]
38. Jiang, M.; Feng, C.; Fang, X.; Huang, Q.; Zhang, C.; Shi, X. Rice Disease Identification Method Based on Attention Mechanism and Deep Dense Network. Electronics 2023, 12, 508. [Google Scholar] [CrossRef]
39. Jiang, Z.; Dong, Z.; Jiang, W.; Yang, Y. Recognition of Rice Leaf Diseases and Wheat Leaf Diseases Based on Multi-Task Deep Transfer Learning. Comput. Electron. Agric. 2021, 186, 106184. [Google Scholar] [CrossRef]

Leal-Lara D-D, Barón-Velandia J, Molina-Parra L-M, Cabrera-Blandón A-C. A Model for Detecting Xanthomonas campestris Using Machine Learning Techniques Enhanced by Optimization Algorithms. Agriculture. 2025; 15(3):223. https://doi.org/10.3390/agriculture15030223
Перевод статьи «A Model for DetectingXanthomonas campestrisUsing Machine Learning Techniques Enhanced by Optimization Algorithms» авторов Leal-Lara D-D, Barón-Velandia J, Molina-Parra L-M, Cabrera-Blandón A-C., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik
















































































































Комментарии (0)