Умное сельское хозяйство: быстрая диагностика болезней арахиса на периферийных устройствах
Интеллектуальная трансформация систем обнаружения болезней листьев сельскохозяйственных культур стимулировала применение алгоритмов глубоких нейронных сетей для разработки более точных моделей диагностики. В условиях ограниченных ресурсов развертывание таких моделей в облаке сопряжено с проблемами, включая задержки передачи данных и риски для конфиденциальности. Периферийные устройства с искусственным интеллектом (Edge AI) предлагают более низкую задержку связи и повышенную масштабируемость.
Аннотация
Для эффективного развертывания моделей обнаружения болезней листьев на периферийных устройствах был собран набор данных из 700 изображений, содержащих признаки пятнистости листьев арахиса, ожоговой пятнистости и ржавчины. С использованием сети YOLOX-Tiny были проведены эксперименты по развертыванию модели обнаружения болезней листьев арахиса на устройстве Jetson Nano B01. Эксперименты изначально были сосредоточены на трех аспектах оптимизации эффективного развертывания: слиянии операций выпрямленной линейной активации (ReLU) и свертки, интеграции модуля Efficient Non-Maximum Suppression для TensorRT (EfficientNMS_TRT) для ускорения постобработки внутри модели TensorRT, а также преобразовании форматов модели из NCHW (число образцов, каналы, высота, ширина) в NHWC (число образцов, высота, ширина, каналы) в модели TensorFlow Lite. Дополнительно проводились эксперименты по сравнению использования памяти, энергопотребления и задержки вывода между двумя фреймворками инференса, а также оценка производительности обнаружения в реальном времени с использованием DeepStream. Результаты демонстрируют, что слияние функций активации ReLU со сверточными операциями снизило задержку вывода на 55,5% по сравнению с использованием только активации SiLU. В модели TensorRT интеграция модуля EfficientNMS_TRT ускорила постобработку, что привело к снижению задержки вывода на 19,6% и увеличению количества кадров в секунду (FPS) на 20,4%. В модели TensorFlow Lite преобразование в формат NHWC уменьшило время конвертации модели на 88,7% и сократило задержку вывода на 32,3%. Эти три метода оптимизации эффективного развертывания позволили уменьшить задержку вывода и повысить эффективность инференса. Кроме того, сравнение двух фреймворков показало, что TensorFlow Lite обеспечивает снижение использования памяти на 15–20% и энергопотребления на 15–25% по сравнению с TensorRT. В то же время TensorRT достиг снижения задержки вывода на 53,2–55,2% относительно TensorFlow Lite. Следовательно, TensorRT подходит для задач, требующих высокой производительности в реальном времени и низкой задержки, тогда как TensorFlow Lite больше подходит для сценариев с ограниченными ресурсами памяти и энергопотребления. Кроме того, было обнаружено, что интеграция DeepStream и EfficientNMS_TRT оптимизирует использование памяти и энергии, тем самым повышая скорость обнаружения в реальном времени в видео. При разрешении 1280 × 720 была достигнута скорость обнаружения 28,7 кадра в секунду. Эти эксперименты подтверждают осуществимость и преимущества развертывания моделей обнаружения болезней листьев сельскохозяйственных культур на периферийных устройствах с искусственным интеллектом.
1. Введение
Арахис признан одной из основных масличных и экономических культур в мире [1]. Являясь крупнейшим производителем и потребителем арахиса в глобальном масштабе, Китай обеспечивает 40% мирового производства и потребления арахиса [2]. Урожайность и качество арахиса напрямую влияют на экономику сельского хозяйства и продовольственную безопасность. В период роста арахиса болезни листьев часто воздействуют как на урожайность, так и на качество. Следовательно, обнаружение болезней листьев арахиса имеет первостепенное значение. Традиционные методы ручного обнаружения требуют много времени и труда, что делает подходы к выявлению болезней на основе глубокого обучения весьма желательными [3,4]. Глубокое обучение генерирует значительные объемы данных, особенно в приложениях компьютерного зрения [5]. В суровых условиях сельскохозяйственных полей ограниченные вычислительные ресурсы препятствуют управлению такими огромными объемами данных. В то время как облачные вычисления перекладывают обработку обширных данных на серверы, возросшая задержка связи создает новые проблемы. Хотя появление периферийных устройств с ИИ позволяет снизить часть этого давления, такие факторы, как объем данных, требования к работе в реальном времени, энергопотребление, связь и хранение, создают дополнительные проблемы [6]. Кроме того, фреймворки инференса глубоких нейронных сетей могут служить вспомогательными инструментами для решения проблем, возникающих в различных сценариях инференса. Однако ограничения, связанные с вычислительными устройствами, глубокими нейронными сетями и фреймворками инференса, усложняют эффективное развертывание соответствующих приложений в сельскохозяйственных условиях.
В последние годы глубокие нейронные сети стали играть все более значительную роль в обнаружении болезней листьев сельскохозяйственных культур. Используя исходные изображения в качестве входных данных, эти сети автоматически извлекают соответствующие признаки, способствуя тем самым эффективному и точному обнаружению и диагностике болезней листьев сельскохозяйственных культур [7]. Внедрение глубоких нейронных сетей не только позволяет обойти проблемы, связанные с методами ручного проектирования признаков, но и повышает точность обнаружения и робастность [8]. Следовательно, растет количество исследований, направленных на использование глубоких нейронных сетей для обнаружения болезней листьев сельскохозяйственных культур, что приводит к заметным научным достижениям. Линь и др. [9] представили улучшенную сеть YOLOX-Tiny, которая включала иерархические блоки смешанного масштаба (HMU) в сеть neck для оптимизации признаков и интегрировала модуль внимания с сверточным блоком (CBAM) для улучшения обнаружения мелких поражений, что привело к превосходной производительности с точки зрения как точности, так и скорости обнаружения. Ли и др. [10] интегрировали легковесную структуру сверточной нейронной сети GhostNet в сеть YOLOv8s и ввели механизм тройного внимания. Кроме того, они использовали эффективную функцию полного пересечения над объединением (ECIoU_Loss) для замены исходной функции полного пересечения над объединением (CIoU_Loss), достигнув значительной оптимизации с точки зрения точности, размера модели и вычислительной сложности. Сангайя и др. [11] предложили сеть UAV T-yolo-Rice, которая включала слои обнаружения YOLO, пространственную пирамиду пулинга (SPP), CBAM и модуль извлечения признаков «песочные часы» (SCFEM), достигнув оптимальной производительности на созданном наборе данных по болезням листьев риса. Очевидно, что вышеупомянутые исследования достигли значительного прогресса в обнаружении болезней листьев сельскохозяйственных культур. Однако они не затронули проблему развертывания моделей обнаружения болезней листьев в условиях ограниченных ресурсов сельскохозяйственных полей.
Некоторые исследователи развернули модели обнаружения болезней листьев сельскохозяйственных культур на периферийных устройствах с ИИ для выявления болезней листьев в суровых условиях сельскохозяйственных полей. Ли и др. [12] модифицировали исходные части backbone и neck сети YOLOv4, включив в них разделяемую по глубине свертку и гибридный механизм внимания, а также спроектировали и оценили четыре новые сетевые архитектуры, причем модель с наилучшими показателями была названа DAC-YOLOv4. Эта модель была применена для обнаружения мучнистой росы клубники и достигла скорости обнаружения в реальном времени 43 FPS и 20 FPS на Jetson Xavier NX и Jetson Nano соответственно, что демонстрирует ее эффективность и практичность. Гаджара и др. [13] разработали новую архитектуру сверточной нейронной сети, способную идентифицировать и классифицировать 20 типов здоровых и больных листьев четырех видов растений. Развернутая на NVIDIA Jetson TX1, эта модель выполняла эффективное обнаружение множества листьев в реальном времени в полевых условиях и точно идентифицировала различные заболевания. Се и др. [14] предложили легковесную модель обнаружения YOLOv5s-BiPCNeXt для выявления болезней листьев баклажанов в естественных условиях. Эта модель использовала backbone MobileNeXt для уменьшения количества параметров и вычислительной сложности и интегрировала механизм многомасштабного кросс-пространственного внимания и оператор рекомбинации признаков с учетом контента в сети neck. В конечном итоге на устройстве Jetson Orin Nano была достигнута скорость обнаружения в реальном времени 26 FPS, что превзошло другие алгоритмы. Некоторые исследователи развернули модели обнаружения болезней листьев сельскохозяйственных культур на встраиваемых устройствах с ИИ; однако эффективное развертывание остается проблемой, и существует недостаток опыта в отношении их развертывания на встраиваемых устройствах с ИИ [15].
Данное исследование посвящено эффективному развертыванию моделей обнаружения болезней листьев сельскохозяйственных культур в условиях ограниченных ресурсов. Тематическое исследование было проведено с использованием сети YOLOX-Tiny на устройстве Jetson Nano B01, предоставляя опыт развертывания в отношении применения моделей обнаружения болезней листьев сельскохозяйственных культур в условиях сельскохозяйственных полей и продвигая вперед интеллектуальные сельскохозяйственные приложения в условиях ограниченности ресурсов. Эксперименты изначально были сосредоточены на трех аспектах оптимизации эффективного развертывания: слиянии операций ReLU и свертки, интеграции EfficientNMS_TRT для ускорения постобработки в модели TensorRT и преобразовании формата модели из NCHW в NHWC в модели TensorFlow Lite. Кроме того, сравнивались TensorRT и TensorFlow Lite с точки зрения использования памяти, энергопотребления и задержки вывода. Наконец, был проведен сравнительный эксперимент по обнаружению в реальном времени в видео путем объединения EfficientNMS_TRT с DeepStream. Это исследование предоставляет ценный опыт для эффективного развертывания моделей обнаружения болезней листьев сельскохозяйственных культур на периферийных устройствах в интеллектуальном сельском хозяйстве.
2. Материалы
2.1. Район исследования
Данные изображений болезней листьев арахиса, использованные в этом исследовании, были собраны на арахисовых полях базы Юаньян Хэнаньского сельскохозяйственного университета (35°6′45″ с.ш., 113°57′35″ в.д.). На рисунке 1 представлен обзор района исследования. Легенда на рисунке 1 отображает информацию о высоте над уровнем моря для района исследования. Зеленые области соответствуют более низким высотам, в то время как красные области соответствуют более высоким высотам, при этом значения высот варьируются от 66 м до 101 м.
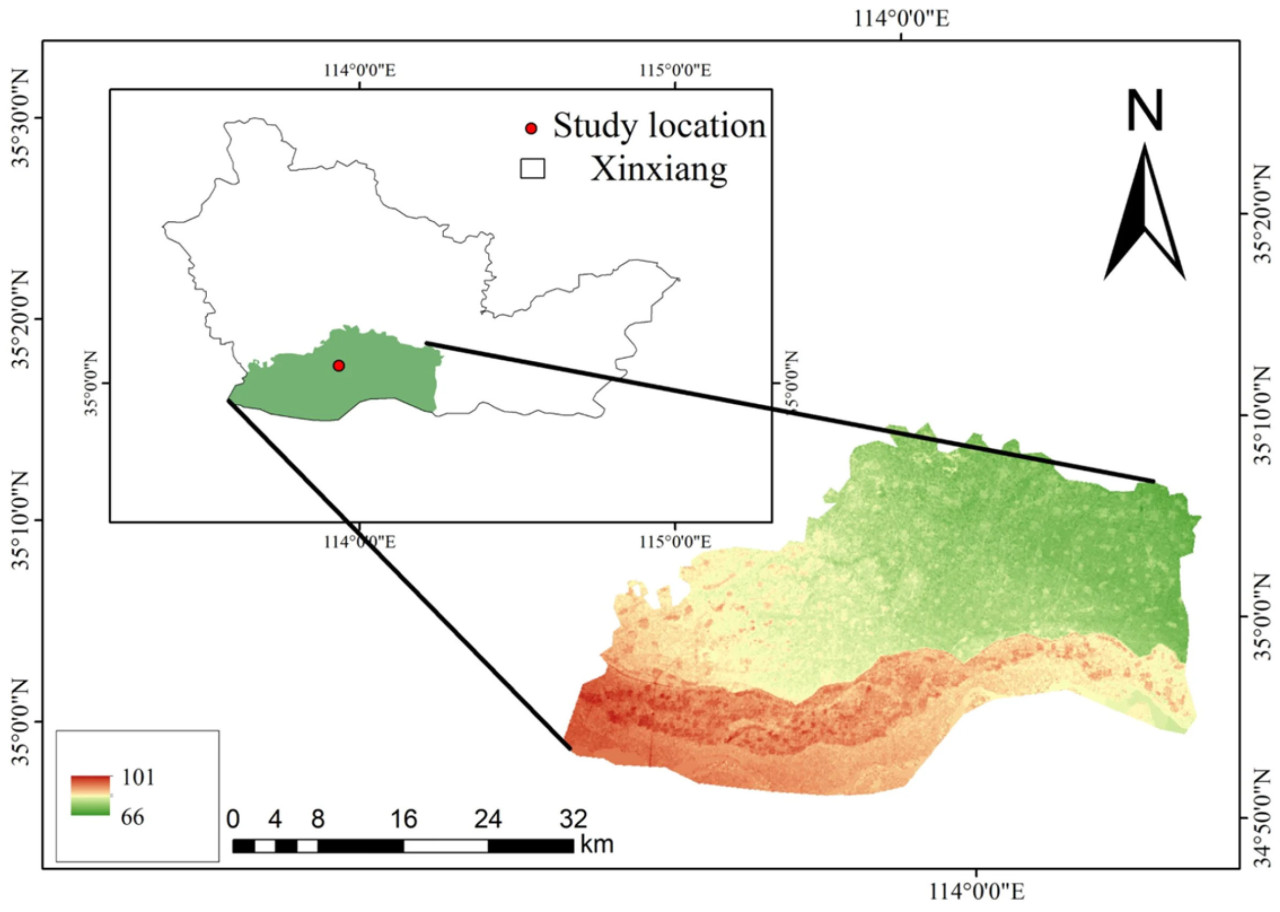
Рисунок 1. Обзор района исследования.
Район исследования характеризовался равнинным рельефом и легким механическим составом почвы, обеспечивающим отличные аэрацию и дренажные условия, что благоприятствует росту корней и плодов арахиса. Этот регион испытывает влияние умеренного муссонного климата с жарким и дождливым летом и холодной сухой зимой. Сочетание умеренного муссонного климата и благоприятных почвенных условий создает идеальную экологическую среду для культивирования арахиса, эффективно способствуя высокой урожайности и превосходному качеству. Оптимальный период посева арахиса в этом районе приходится на конец апреля – начало мая, когда температура почвы благоприятствует прорастанию семян и раннему росту всходов. Используется плотность посадки 135 000 растений/га, применяется рациональный метод посадки, который обеспечивает достаточное пространство для каждого растения, увеличивая урожайность с единицы площади. Основные болезни листьев арахиса, включая пятнистость, ожоговую пятнистость и ржавчину [16], в основном проявляются в средний и поздний периоды роста арахиса, с августа по октябрь. Эти заболевания значительно влияют на эффективность фотосинтеза и развитие плодов арахиса, представляя собой один из основных факторов, влияющих на высокую урожайность и качество арахиса в этом районе.
2.2. Сбор набора данных по болезням листьев арахиса
Для сбора изображений использовалась камера Fuji FinePix S4500, достигающая максимального разрешения 4608 × 3456 пикселей. Чтобы тщательно учесть вариации освещения и углов съемки, изображения были получены в пасмурные, солнечные и облачные погодные условия. Процесс сбора данных проводился с 1 по 3 сентября 2022 года, в основном в период с 10:00 до 12:00 и с 14:00 до 17:00. Из-за ограничений, связанных с временными рамками эксперимента и условиями окружающей среды, три заболевания находились на поздних стадиях развития. Следовательно, полученные изображения в основном представляли поздние стадии развития болезней. Чтобы максимально приблизиться к реальным условиям производства, никакой ручной обработки фона перед получением изображений болезней листьев арахиса не проводилось. После того как пятнистость, ожоговая пятнистость и ржавчина листьев арахиса были идентифицированы в поле экспертом по патологии арахиса, исследователи располагали камеру параллельно земле и получали вертикальные изображения пологов больных листьев арахиса с высоты 10–20 см. Местоположения пораженных участков на листьях были аннотированы вручную для облегчения последующей программной разметки. Всего было собрано 700 изображений, изображающих три типа болезней листьев арахиса, с соблюдением сбалансированной пропорции между категориями заболеваний. На рисунке 2 показаны пятнистость, ожоговая пятнистость и ржавчина листьев арахиса.

Рисунок 2. Болезни листьев арахиса: (a) пятнистость листьев, (b) ожоговая пятнистость, (c) ржавчина.
2.3. Обработка набора данных по болезням листьев арахиса
Для решения проблем редкого распределения болезней, затенения листьев и недостаточности данных изображений по болезням листьев арахиса были применены стандартные методы увеличения данных для предварительной обработки собранных изображений. Этот подход был направлен на увеличение объема данных и повышение их разнообразия, способствуя разработке более эффективной модели обнаружения болезней листьев арахиса и обеспечивая основу для ее эффективного развертывания на периферийных устройствах с ИИ. Первоначально было собрано 700 изображений, 70% из которых были назначены обучающим набором, 15% - тестовым набором и оставшиеся 15% - проверочным набором. Были применены методы увеличения данных, включая отражение, добавление гауссовского шума и масштабирование, причем каждый метод применялся для случайного увеличения 500 изображений. Этот процесс в конечном итоге расширил обучающий набор до 2990 изображений, в результате чего общий набор данных составил 3200 изображений. Увеличение данных изображения уменьшило переобучение, улучшило способность сетевой модели к обучению и повысило ее робастность. Исходные изображения были сначала аннотированы с использованием инструмента LabelImg, и аннотации были сохранены в формате COCO. Впоследствии к обучающему набору было применено увеличение данных. В таблице 1 представлено распределение обработанного набора данных. Исходные данные были разделены на обучающую, тестовую и проверочную выборки, чтобы гарантировать, что тестовая и проверочная выборки отражают производительность модели на невидимых данных. Увеличенные данные, однако, использовались исключительно в обучающем наборе, поскольку основная цель увеличения данных заключается в повышении разнообразия обучающих данных и улучшении способности модели к обобщению. Эти увеличенные образцы были сгенерированы из исходного обучающего набора и не включались в тестовую или проверочную выборки, чтобы предотвратить перекрытие в распределении данных.
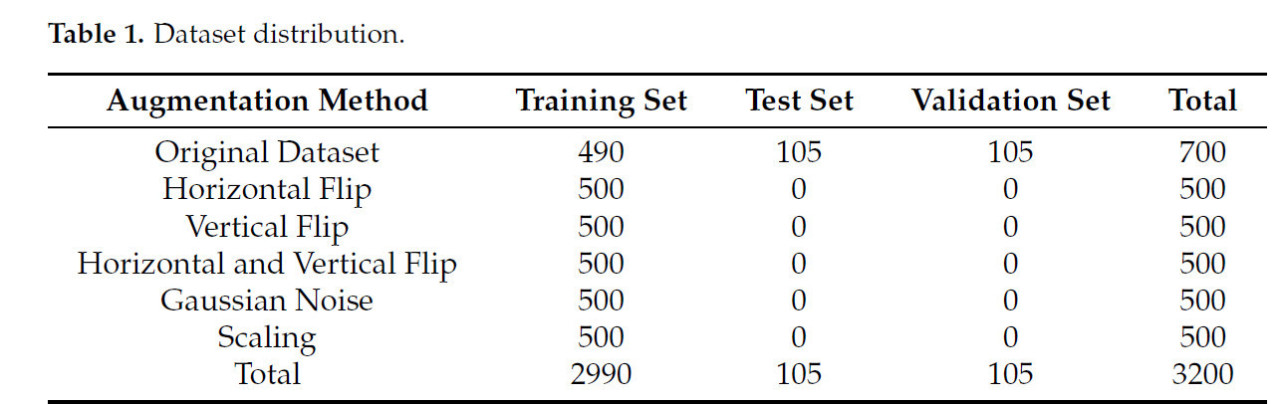
Таблица 1. Распределение набора данных.
3. Методы
3.1. YOLOX-Tiny
Детекторы объектов на основе глубокого обучения классифицируются на две категории: одноэтапные детекторы и двухэтапные детекторы [17]. В настоящее время основной детектор объектов, YOLO (You Only Look Once), является примером типичного одноэтапного детектора [18] и отличается своей высокой скоростью [19,20]. В этом исследовании использовался YOLOX [21], улучшенный алгоритм в серии YOLO, представленный компанией Megvii в 2021 году. Структуры backbone и neck сетевой модели YOLOX примечательно просты, избегая сложных операторов, которые вредят развертыванию. Его основные преимущества включают принятие разделенной головы, подхода без использования якорей и SimOTA для динамического назначения положительных образцов в части головы, тем самым улучшая производительность обнаружения сети [22]. Кроме того, YOLOX выигрывает от активного сообщества с открытым исходным кодом и подробных примеров развертывания, позволяя исследователям быстро изучать и развертывать модели, тем самым сокращая время разработки. Более того, процесс преобразования модели YOLOX является относительно зрелым. Кроме того, он демонстрирует хорошую совместимость с платформами встраиваемых устройств с ИИ, такими как Jetson Nano B01, облегчая исследователям эффективное развертывание.
В этом исследовании использовалась микросеть YOLOX-Tiny [23] для выполнения задач обнаружения болезней листьев арахиса, поддерживая высокую скорость инференса и обеспечивая при этом удовлетворительную точность обнаружения. На рисунке 3 показана сетевая архитектура YOLOX-Tiny. Вход сети состоял из изображений размером 416 × 416, созданных из исходных изображений путем предварительной обработки. Черный прямоугольник выделяет компоненты backbone, neck и предсказания сети, в то время как синие прямоугольники представляют подмодули внутри каждого компонента. Эти подмодули накладываются друг на друга, образуя окончательную структуру сети YOLOX-Tiny. Выход сети представляет собой изображение размером 416 × 416, созданное путем предсказания. Красный прямоугольник на изображении представляет обнаруженную пятнистость листьев. На этапе предварительной обработки сети исходные изображения с разрешением 4608 × 3456 были изменены до целевого входного размера 416 × 416, чтобы соответствовать входным требованиям сети YOLOX-Tiny. Сначала было вычислено минимальное соотношение масштабирования между целевым и исходным размером, в результате чего было получено измененное изображение размерами 416 × 312. Затем измененное изображение было дополнено 104 серыми пикселями по высоте для достижения окончательного размера 416 × 416, полностью соответствующего входным требованиям сети YOLOX-Tiny. В частности, как во время обучения, так и во время тестирования исходные изображения изменялись до размера 416 × 416 для соответствия входным требованиям сети YOLOX-Tiny. Аннотации, однако, основывались на исходном разрешении изображения 4608 × 3456 для обеспечения согласованности и точности. Внутри backbone YOLOX-Tiny структура Focus изначально использовалась для обработки входных данных изображений болезней листьев арахиса. Для повышения вычислительной эффективности и улучшения способности модели к представлению backbone в основном основан на структуре CSPDarknet [24]. Кроме того, интегрированы такие модули, как CSPNet и SPP, для обеспечения высоких возможностей извлечения признаков при низких вычислительных затратах. Neck использует структуру PAN-FPN, где FPN служит нисходящей пирамидой признаков [25], передавая и объединяя информацию о признаках высокого уровня через повышающую дискретизацию для улучшения семантического представления нижних слоев. Напротив, PAN объединяет преимущества PANet и FPN для более эффективного усиления передачи многомасштабной информации между слоями признаков. Часть heads включает стратегии оптимизации, включая разделенную голову, подход без использования якорей и SimOTA для динамического назначения положительных образцов [26]. Разделенная голова отвечает за разделение задач классификации и регрессии, избегая тем самым взаимного влияния двух задач и повышая эффективность обнаружения модели, что приводит к более эффективному процессу инференса. Традиционные методы обнаружения на основе якорей увеличивают сложность головы детектора и количество предсказаний на изображение. Учитывая ограниченные вычислительные ресурсы периферийных устройств с ИИ, традиционные методы на основе якорей могут стать узким местом с точки зрения задержки вывода. Подход без использования якорей исключает использование предопределенных якорей в обнаружении объектов, вместо этого предсказывая положение и размер целей непосредственно через центральные точки или ключевые точки, уменьшая вычислительную нагрузку по генерации и сопоставлению якорей и значительно повышая скорость инференса. SimOTA динамически выбирает положительные образцы для каждой цели, оптимизируя метод назначения меток и тем самым повышая эффективность обучения модели и улучшая точность обнаружения.
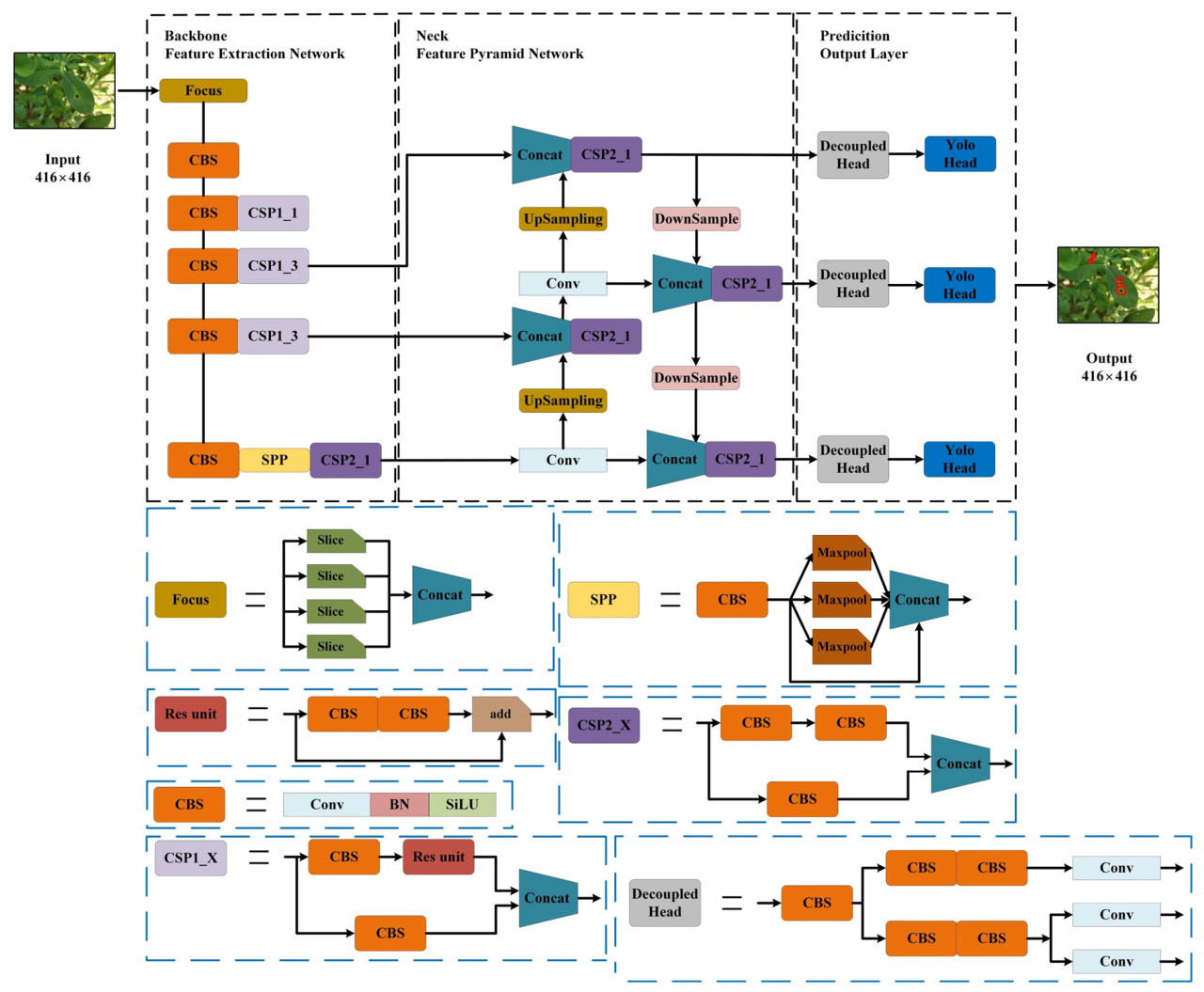
Рисунок 3. Диаграмма структуры модели YOLOX-Tiny.
3.2. Развертывание YOLOX-Tiny
3.2.1. Развертывание на периферии
Стратегии развертывания глубоких нейронных сетей в основном подразделяются на два типа: (1) облачное развертывание, которое перекладывает все вычислительные задачи на облако, используя обширные вычислительные ресурсы облака для выполнения сложных задач [27], и (2) периферийное развертывание, которое выполняет вычисления вблизи периферийных устройств, тем самым уменьшая задержки связи и риски для конфиденциальности [28]. Традиционные модели глубокого обучения, характеризующиеся большим количеством параметров и высокой вычислительной сложностью, обычно требуют развертывания моделей обнаружения болезней сельскохозяйственных культур на облачных серверах [29]. Однако по мере увеличения количества устройств и спроса облачные решения становятся неспособными удовлетворить требования к обработке и хранению. Кроме того, загрузка данных с периферийных устройств в облако создает такие проблемы, как задержки связи и утечка конфиденциальных данных [30]. Напротив, периферийное развертывание расширяет потенциал искусственного интеллекта за счет уменьшения использования полосы пропускания и задержки [31]. Более того, облачно-периферийный совместный инференс объединяет преимущества облачных и периферийных вычислений, требуя баланса между производительностью инференса и стоимостью. Благодаря рациональному распределению ресурсов можно оптимизировать эффективность и качество обслуживания [32]. В этом исследовании рассматривалось исключительно развертывание глубоких нейронных сетей на периферии. Причины выбора периферийного развертывания многочисленны. Во-первых, разнообразие и количество оконечных устройств растут экспоненциально, и решения для облачного развертывания из-за их ограниченной масштабируемости могут быть не в состоянии удовлетворить растущий спрос. Кроме того, развертывание в облаке обычно приводит к дополнительной задержке связи, что особенно заметно в суровых сельскохозяйственных условиях. Во-вторых, функциональность периферийных устройств значительно возросла, и примеры развертывания, связанные с периферийными устройствами, становятся все более многочисленными [33]. Периферийные устройства с ИИ серии Jetson от NVIDIA предлагают выдающуюся производительность и отличную энергоэффективность, и они постепенно заменяют ранее использовавшиеся периферийные устройства, такие как Raspberry Pi, которые были в первую очередь предназначены для приложений Интернета вещей.
3.2.2. Фреймворк развертывания
При периферийном развертывании распространенные фреймворки глубоких нейронных сетей, такие как TensorFlow и PyTorch, неадекватны для выполнения задач инференса на маломощных встраиваемых устройствах. Следовательно, такие компании, как Google и NVIDIA, разработали фреймворки инференса глубоких нейронных сетей, адаптированные для различных устройств и платформ. В настоящее время наиболее популярными являются TensorFlow Lite (TFLite) от Google и TensorRT от NVIDIA. TFLite был разработан в первую очередь для мобильных устройств, таких как iOS и Android, с упором на совместимость и кроссплатформенную адаптацию. С помощью таких методов, как сжатие модели и квантование, TFLite значительно уменьшает размер модели и вычислительные требования, обычно используя CPU для инференса [34]. Напротив, TensorRT специально оптимизирован для графических процессоров NVIDIA, применяя такие методы, как слияние операторов, оптимизация памяти и квантование, чтобы значительно повысить скорость и эффективность инференса глубоких нейронных сетей. TensorRT может быть реализован тремя способами: использование встроенного TRT-интерфейса фреймворка (TF-TRT), преобразование через промежуточный формат ONNX и построение сети с использованием собственного API TensorRT. Эти два фреймворка инференса оптимизируют модели с разных точек зрения, делая развертывание глубоких нейронных сетей более эффективным и гибким на различных устройствах и в различных сценариях.
Сеть YOLOX-Tiny изначально обучалась на хосте Ubuntu с использованием фреймворка PyTorch. По завершении обучения были сохранены веса с наилучшими показателями для дальнейшего использования. Сохраненные веса PyTorch были преобразованы в промежуточный формат ONNX во фреймворке PyTorch. Модель ONNX была затем перенесена на Jetson Nano B01, где она была отдельно преобразована в модели TensorRT и TFLite с использованием инструментов TensorRT и пользовательских скриптов. Для улучшения обеих моделей были применены три метода оптимизации эффективного развертывания. После оптимизации модели были оценены и сравнены с точки зрения использования памяти, энергопотребления и задержки вывода в обоих фреймворках. Наконец, оптимизированная модель TensorRT была интегрирована в конвейер DeepStream на Jetson Nano B01 для обеспечения ускоренного обнаружения в реальном времени в видео. Общий процесс развертывания YOLOX-Tiny показан на рисунке 4. На рисунке 4A YOLO-Tiny развертывается на Jetson Nano B01. Рисунок 4B иллюстрирует преобразование в два фреймворка инференса, TensorRT и TFLite, с использованием формата ONNX. На рисунке 4C представлены три метода оптимизации эффективного развертывания. Рисунок 4D сравнивает два фреймворка инференса с точки зрения использования памяти, энергопотребления и задержки вывода. Наконец, рисунок 4E иллюстрирует обнаружение в реальном времени в видео с использованием DeepStream.
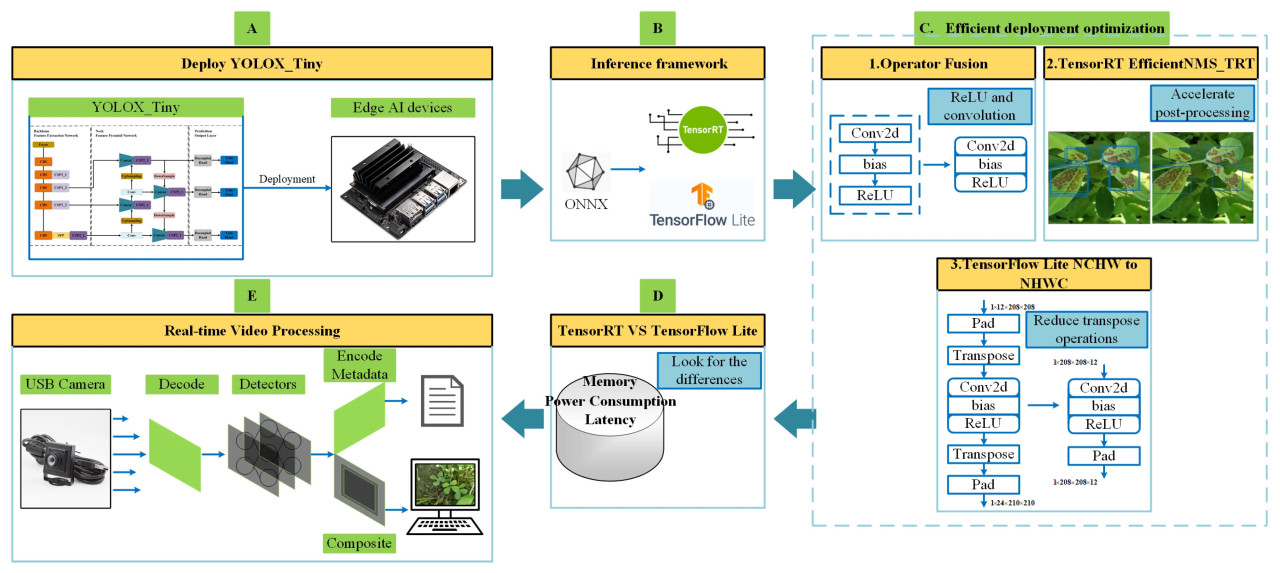
Рисунок 4. Общий процесс развертывания.
3.3. Оптимизация эффективного развертывания
3.3.1. Слияние операторов
Операторы, служащие наименьшими единицами планирования в глубоких нейронных сетях, обычно существуют как слои в сетевой архитектуре. Чтобы уменьшить вычислительные затраты, снизить требования к пропускной способности памяти, уменьшить хранение промежуточных данных и повысить эффективность инференса [35], исследователи объединили несколько операторов в единую операцию. Это позволяет выполнять их в течение одного цикла чтения-записи памяти, избегая тем самым ненужных промежуточных вычислений и обмена данными с памятью [36]. Являясь основным фреймворком инференса для мобильных и маломощных встраиваемых устройств, TFLite в первую очередь фокусируется на слиянии операторов между базовыми операторами [37], демонстрируя более низкую сложность слияния по сравнению с TensorRT. Напротив, TensorRT не только объединяет базовые слои, но также использует многочисленные дополнительные параметры и опции внутренне, объединяя несколько слоев в один эффективный исполнительный блок на основе характеристик базового оборудования [38].
ReLU является чрезвычайно простой нелинейной функцией активации, и ее вычисление является простым, требующим только пороговой операции над входными данными. Функция ReLU представлена уравнением (1). SiLU, также известная как функция активации Swish, включает в себя значительно более сложные вычисления по сравнению с ReLU. Учитывая сложность слияния и выгоды, получаемые от такой интеграции, в этом исследовании не выполнялось слияние операторов SiLU со сверткой. SiLU преобразует входные данные, используя сигмоидную функцию σ(x), как показано в уравнении (2), и затем умножает результат на сами входные данные. Из-за необходимости вычисления сигмоидной функции и выполнения операций умножения SiLU влечет за собой дополнительные вычислительные шаги и сложность. Функция SiLU представлена уравнением (2). Графики SiLU и ReLU показаны на рисунке 5. Горизонтальная ось на рисунке 5 представляет входные значения x для уравнений (1) и (2) в диапазоне от отрицательных до положительных. Вертикальная ось представляет соответствующие выходные значения y уравнений (1) и (2) для заданных входных данных.
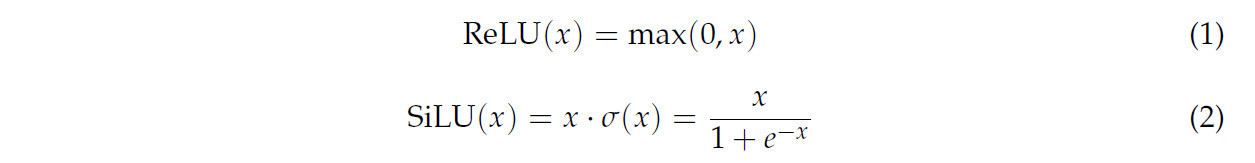
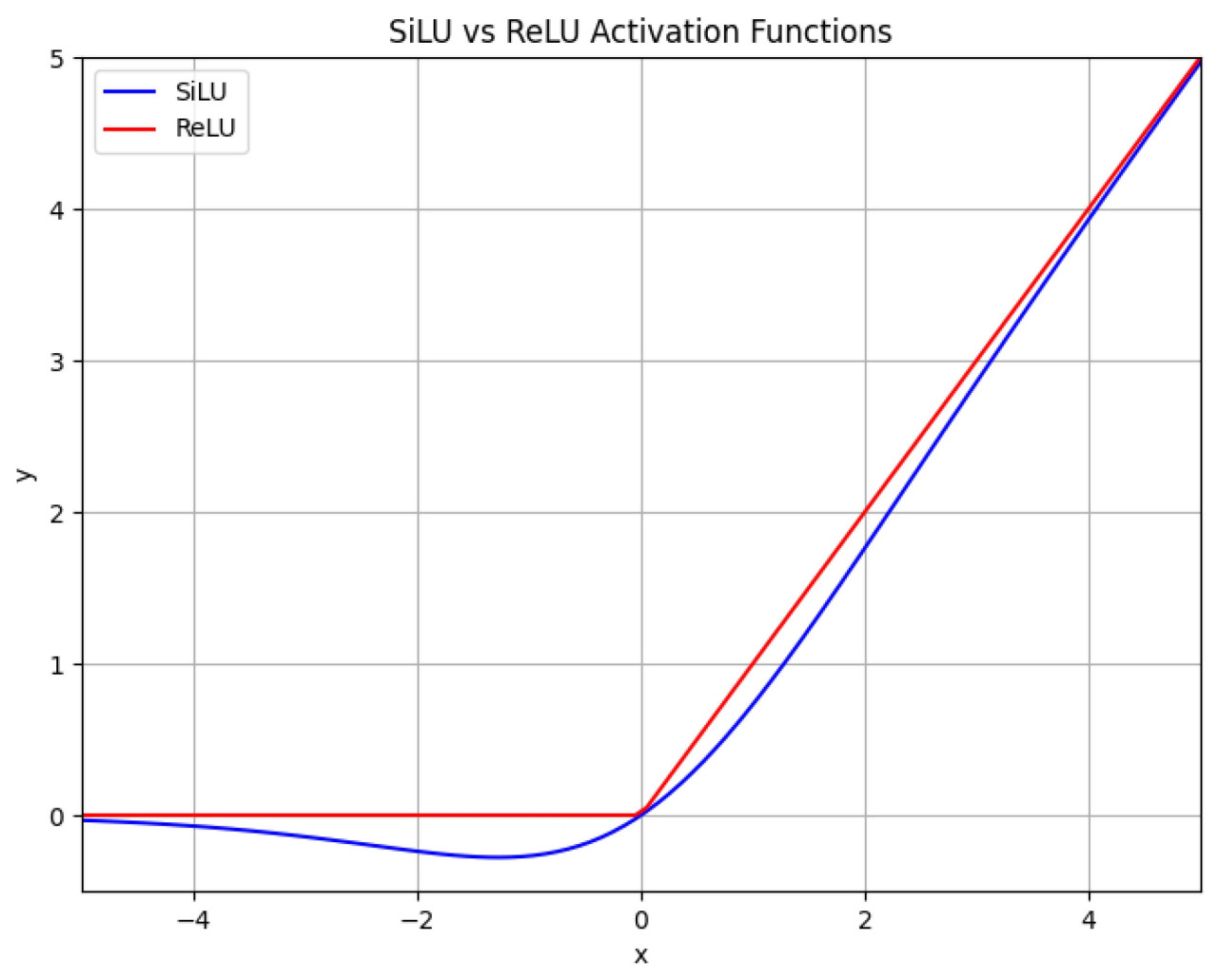
Рисунок 5. SiLU и ReLU.
Благодаря характеристикам функции активации ReLU многие фреймворки инференса глубоких нейронных сетей, включая TensorRT и TFLite, могут легко объединять ReLU со сверточными операциями. Выход свертки представлен уравнением (3), где сумматор обозначает сумму произведений между входной картой признаков и ядром свертки. Bias[j] относится к члену смещения, добавляемому после свертки, обычно добавляемому после сверточного слоя. Выход свертки затем обрабатывается через функцию активации с помощью уравнения (4), где activation_fn представляет функцию активации, которой в данном контексте является ReLU. До слияния операторов уравнения (3) и (4) указывают на то, что сверточные операции и функции активации разделены. После слияния операторов получается уравнение (5).

Накопленные результаты и смещение от свертки немедленно обрабатываются через функцию активации, непосредственно давая окончательный выход. Это уменьшает доступ к памяти, выполняя свертку и активацию в рамках одной и той же операции, тем самым сокращая время вычислений и доступ к данным, связанные с промежуточными этапами. На рисунке 4C(1) показано слияние операций ReLU и свертки.
3.3.2. EfficientNMS_TRT
Для достижения более быстрого и точного обнаружения болезней листьев арахиса во фреймворке TensorRT в модель ONNX был вставлен оператор EfficientNMS_TRT [39], который эффективно обрабатывает операции немаксимального подавления (NMS), и впоследствии он был успешно скомпилирован с помощью TensorRT. Open Neural Network Exchange (ONNX), инициированный в результате сотрудничества между Microsoft и Facebook в 2017 году, представляет собой стандартизированный открытый формат для описания глубоких нейронных сетей. Он упрощает переносимость глубоких нейронных сетей между различными фреймворками и аппаратными платформами [40]. Являясь статическим вычислительным графом, ONNX включает информацию, такую как веса модели и операторы. Операторы являются основными компонентами, которые выполняют конкретные вычисления. Хотя ONNX изначально поддерживает несколько стандартизированных операторов, он также позволяет создавать пользовательские операторы, адаптированные для конкретных задач. NMS - это метод, используемый в обработке изображений. Являясь важнейшим этапом в алгоритмах обнаружения объектов, цель NMS заключается в выборе оптимальных ограничивающих рамок-кандидатов из множества предложенных обнаружений [41]. Операция NMS включает ранжирование рамок обнаружения на основе оценок достоверности и отбрасывание любой рамки, перекрытие которой с сохраненной рамкой превышает определенный порог. Этот процесс не только удаляет избыточные рамки обнаружения, но также обеспечивает точность обнаружения [42]. Обычно NMS выполняется отдельно на CPU на этапе постобработки; однако этот подход неэффективен на периферийных устройствах с ИИ с ограниченными вычислительными ресурсами. Интегрируя NMS в сеть, снижается сложность, связанная с ручным добавлением кода постобработки, и может быть достигнута ускоренная обработка во время инференса с использованием TensorRT.
EfficientNMS_TRT - это операция немаксимального подавления, оптимизированная для графических процессоров, предназначенная для ускорения критического этапа в задачах обнаружения объектов. В зависимости от типа входных данных, EfficientNMS_TRT работает в двух режимах. Первый - это стандартный режим NMS. В этом режиме входными данными являются координаты ограничивающих рамок и оценки классификации. Этот режим функционирует аналогично традиционному NMS, обрабатывая декодированные ограничивающие рамки и оценки достоверности, что требует выполнения этапа декодирования перед выполнением. Второй - это режим декодирования объединенных рамок. Здесь входные данные состоят из сырых предсказаний локализации, оценок классификации и координат якорей по умолчанию. Этот режим объединяет декодирование рамок с NMS, предназначаясь для моделей обнаружения объектов на основе якорей [43]. Однако, поскольку YOLOX-Tiny реализована без использования якорей, в этом исследовании был принят первый режим работы. В этом исследовании NMS была непосредственно интегрирована в глубокую нейронную сеть, используя ядра CUDA и распараллеливание на GPU для значительного сокращения времени вычислений, связанных с операциями NMS. Кроме того, выполнение NMS непосредственно на GPU минимизирует передачу данных между GPU и CPU, тем самым избегая множественного копирования данных и ненужных операций с памятью, что снижает накладные расходы на доступ к памяти. Кроме того, получение непосредственно используемых окончательных результатов обнаружения может упростить рабочий процесс развертывания глубоких нейронных сетей. Вход для этого модуля состоит из координат каждой обнаруженной ограничивающей рамки и оценок достоверности для каждой ограничивающей рамки по различным категориям. Выходные данные следующие: (1) detection_classes - метки обнаруженных классов; (2) detection_scores - оценки достоверности обнаружения; (3) detection_boxes - координаты окончательных ограничивающих рамок; (4) num_detections - общее количество зарегистрированных обнаружений. На рисунке 4C(2) показана вставка модуля EfficientNMS_TRT в модель TensorRT.
3.3.3. Преобразование NCHW в NHWC
Во фреймворке TFLite формат ввода модели может быть скорректирован в соответствии с желаемым форматом фреймворка инференса. NCHW (число образцов, каналы, высота, ширина) и NHWC (число образцов, высота, ширина, каналы) являются двумя распространенными форматами тензорных данных, и их производительность и эффективность могут варьироваться в зависимости от конкретного оборудования, операций и архитектуры глубокой нейронной сети. В формате NCHW размерность канала является второй размерностью. Этот макет памяти хранит данные для каждого канала последовательно, позволяя GPU одновременно обрабатывать несколько каналов благодаря своим мощным возможностям параллельных вычислений. В настоящее время фреймворк PyTorch в основном использует формат NCHW. И наоборот, в формате NHWC размерность канала является последней размерностью. Его макет памяти хранит каждую строку пикселей изображения последовательно [44], позволяя CPU более эффективно обращаться к непрерывным блокам памяти, тем самым снижая частоту промахов кэша и повышая вычислительную эффективность. Поскольку TensorFlow и TFLite изначально были разработаны для CPU и мобильных устройств соответственно, формат NHWC обычно используется в обоих. Стоит отметить, что в TFLite ускорение GPU может быть использовано через делегаты GPU. Однако, основываясь на наших экспериментах и опыте развертывания других исследователей, этот метод работает на Jetson Nano B01 хуже по сравнению с использованием только CPU и не поддерживает некоторые стандартные операторы [45].
В этом исследовании обучение изначально проводилось с использованием фреймворка PyTorch, и полученная модель была впоследствии преобразована в модель ONNX, которая сохранила формат NCHW. Обычно при преобразовании модели ONNX в формат TFLite формат NCHW сохраняется. Однако этот формат не является предпочтительным форматом ввода для TFLite, что приводит к большому количеству операций транспонирования внутри модели TFLite. Во время фазы инференса вычислительные компоненты глубоких нейронных сетей составляют значительную часть времени обработки, в то время как быстрая передача данных остается критически важной. Хотя вычислительные затраты операций транспонирования минимальны, частое изменение порядка данных вызывает дополнительные затраты на доступ к памяти и передачу данных, тем самым снижая скорость инференса. Следовательно, это исследование также включало преобразование формата модели TFLite в NHWC. Рисунок 4C(3) демонстрирует преобразование модели TFLite из формата NCHW в NHWC, тем самым уменьшая количество избыточных операций транспонирования.
3.4. Экспериментальная платформа
Экспериментальная среда и оборудование, использованные для обучения нейронной сети YOLOX-Tiny, включали Ubuntu 18.04, Python 3.8, PyTorch 1.8.1, CUDA 11.1 и GPU RTX 3090. Технические характеристики устройства Jetson Nano B01 подробно описаны в таблице 2. Использовались версии TensorRT и TensorFlow Lite 8.2.1 и 2.3.1 соответственно, а также версия DeepStream 6.0. Для обнаружения в реальном времени в видео использовалась USB-камера Jie Rui Wei Tong DF100, работающая с разрешением 1280 × 720 и частотой кадров 30 кадров в секунду.

Таблица 2. Характеристики Jetson Nano B01.
4. Результаты
4.1. Сравнительные эксперименты по слиянию операторов
Наша текущая работа была сосредоточена исключительно на изображениях, представляющих поздние стадии прогрессирования пятнистости, ожоговой пятнистости и ржавчины листьев арахиса. Эксперименты изначально проводились с использованием двух функций активации, SiLU и ReLU, в течение 300 эпох обучения, что привело к получению кривых mAP@0.5 и mAP@0.5:0.95, как показано на рисунке 6. Независимо от используемой функции активации, кривые mAP@0.5 демонстрировали восходящий тренд примерно в течение первых 100 эпох. После 100-й эпохи кривые постепенно стабилизировались; однако при использовании функции активации SiLU наблюдалось увеличение mAP@0.5 примерно на 3% в течение последних 50 эпох. Кроме того, тренды кривых mAP@0.5:0.95 были схожи для обеих функций активации, причем различия в значениях оставались в пределах примерно 2% на протяжении всего процесса обучения. По завершении 300 эпох окончательные значения mAP@0.5 и mAP@0.5:0.95 достигли 93,93% и 85,44% соответственно при использовании функции активации SiLU, по сравнению с 90,90% и 87,00% при использовании функции активации ReLU. Слияние операций ReLU и свертки может уменьшить количество вызовов ядер, тем самым повышая скорость инференса. Напротив, относительно сложная функция активации SiLU не поддерживает автоматическое слияние в большинстве текущих фреймворков инференса, поскольку требует балансировки сложности слияния и выгод, получаемых от такой интеграции. Впоследствии модели YOLOX-Tiny, использующие обе функции активации, были развернуты во фреймворках TFLite и TensorRT; функция активации ReLU была объединена со сверточными операциями, тогда как слияние операторов для SiLU не выполнялось. В таблице 3 представлены результаты mAP@0.5 и mAP@0.5:0.95 для пятнистости, ожоговой пятнистости и ржавчины листьев в тестовом наборе при использовании функций активации SiLU и ReLU. Относительно низкие значения mAP для пятнистости и ожоговой пятнистости могут быть связаны с малым размером поражений и их менее выраженными признаками. Напротив, болезнь ржавчина обычно образует заметные ржаво-коричневые пятна на листьях, обладая более различимыми характеристиками, что облегчает ее идентификацию.
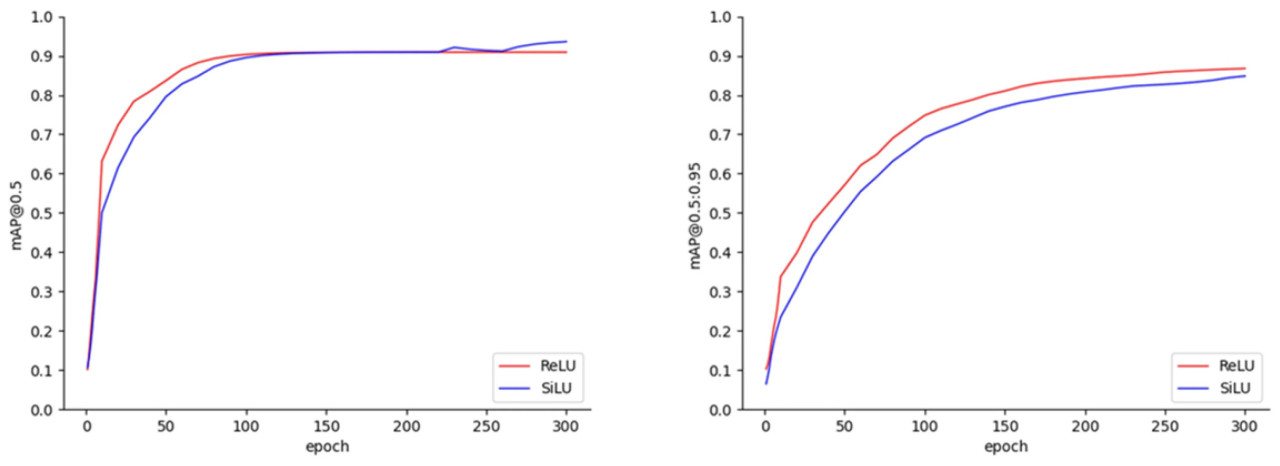
Рисунок 6. Результаты mAP@0.5 и mAP@0.5:0.95.
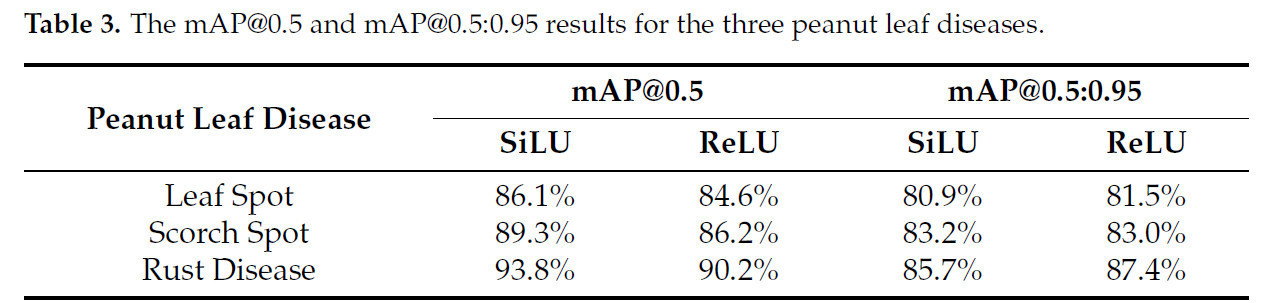
Таблица 3. Результаты mAP@0.5 и mAP@0.5:0.95 для трех болезней листьев арахиса.
В таблице 4 представлена задержка вывода SiLU и ReLU в различных фреймворках. Во фреймворке TFLite с размером пакета, установленным на 1, инференс одного изображения выполнялся 30 раз с использованием SiLU и ReLU, что привело к средней задержке вывода 563,4 мс и 427,6 мс соответственно. Задержка вывода с ReLU была уменьшена на 24,1% по сравнению с SiLU. Во фреймворке TensorRT также с размером пакета 1 задержка вывода при использовании ReLU была уменьшена на 26,7% по сравнению с SiLU. Однако эту разницу нельзя приписывать исключительно слиянию ReLU со сверточными операциями, поскольку она также может проистекать из внутренних различий между функциями активации. Поэтому, чтобы подтвердить, что слияние операций ReLU и свертки ускоряет скорость инференса, для пакетной обработки во фреймворке TensorRT был использован размер пакета 64. Аналогично, основываясь на средней задержке вывода от 30 последовательных инференсов, функция SiLU привела к средней задержке 97,0 мс, тогда как ReLU достиг средней задержки 43,1 мс, что представляет собой снижение на 55,5%. Учитывая результаты mAP@0.5 и mAP@0.5:0.95, показанные на рисунке 6, выбор функций активации должен основываться на конкретном сценарии применения для достижения баланса между точностью и задержкой вывода. Экспериментальными результатами было подтверждено, что интеграция ReLU и сверточных операций действительно может снизить задержку вывода модели, служа эффективным подходом к оптимизации развертывания.
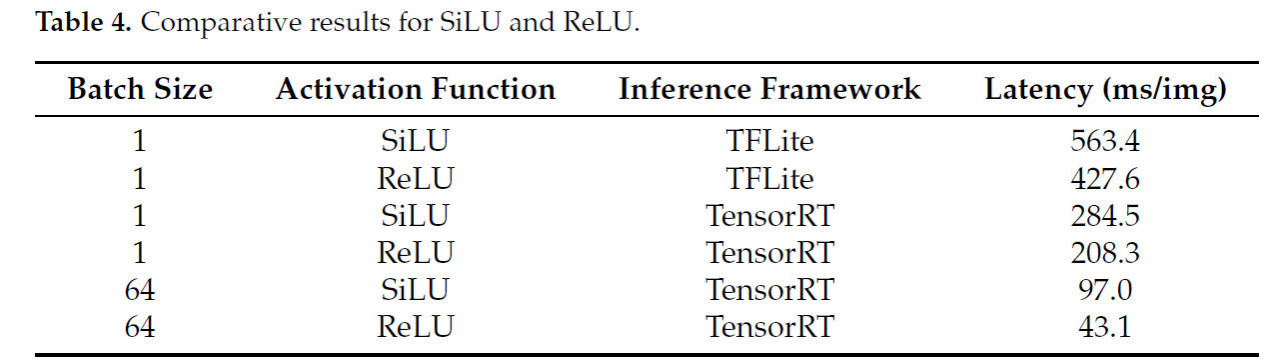
Таблица 4. Сравнительные результаты для SiLU и ReLU.
4.2. Сравнительные эксперименты по EfficientNMS_TRT
EfficientNMS_TRT, который является оператором NMS, оптимизированным для GPU, был интегрирован в модель ONNX и успешно скомпилирован с использованием TensorRT. Для экспериментов по инференсу было установлено семь различных размеров пакета. Когда был сконфигурирован размер пакета 128, 4 ГБ памяти Jetson Nano B01 предотвратили нормальный инференс. В каждом сценарии было проведено 30 инференсов, рассчитана средняя задержка вывода с последующим вычислением FPS. Кроме того, инференсы выполнялись с использованием точности как FP32, так и FP16. В этом эксперименте использовалось квантование после обучения (PTQ). Этот подход включает квантование модели после обучения, что является одновременно удобным и эффективным. Поэтому он был принят в этом исследовании для оптимизации производительности модели при одновременном упрощении процесса развертывания. В таблице 5 показано сравнительное влияние EfficientNMS_TRT на производительность инференса для разных размеров пакета. В этом исследовании символы ✓ и × использовались для указания, использовался ли конкретный модуль или инструмент. В частности, ✓ обозначает, что модуль или инструмент использовался, тогда как × указывает, что он не использовался. Для обеспечения робастности данных операции постобработки включались во время инференса, когда EfficientNMS_TRT не был интегрирован. При инференсе с точностью FP32 задержка вывода на изображение была уменьшена примерно на 3,9% - 14,7%, а FPS увеличился примерно на 4,1% - 17,3%. При инференсе с точностью FP16 задержка вывода на изображение была уменьшена примерно на 4,5% - 19,6%, а FPS увеличился примерно на 4,8% - 20,4%. Таблица 5 демонстрирует, что включение EfficientNMS_TRT в сеть и использование распараллеленных на GPU операций постобработки является эффективным методом для развертывания глубоких нейронных сетей. Этот подход не только ускоряет процесс инференса, но и упрощает рабочий процесс развертывания.
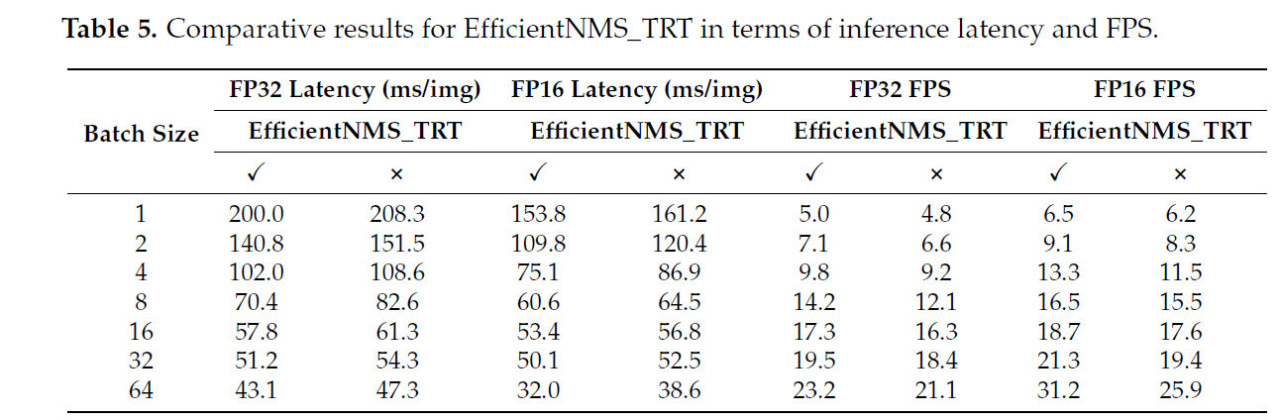
Таблица 5. Сравнительные результаты для EfficientNMS_TRT с точки зрения задержки вывода и FPS.
4.3. Сравнительные эксперименты по формату модели
Сеть YOLOX-Tiny сначала обучалась на хосте Ubuntu с использованием фреймворка PyTorch. После обучения были сохранены веса с наилучшими показателями. Эти веса были впоследствии преобразованы в промежуточный формат ONNX во фреймворке PyTorch. Модель ONNX была затем перенесена на Jetson Nano B01, где она была преобразована в модели TFLite с помощью пользовательских скриптов. При преобразовании модели ONNX в формат TFLite процесс преобразования по умолчанию обычно не учитывает формат ввода модели. В результате формат NCHW был изменен на NHWC в процессе преобразования. Эта мера не только соответствовала преимущественно CPU-инференсу TFLite, но и значительно сократила количество ненужных операций транспонирования. Хотя такие операции не являются вычислительно интенсивными, они влекут за собой дополнительные затраты на доступ к памяти и передачу данных, тем самым замедляя скорость инференса.
После получения двух различных моделей TFLite с помощью разных методов преобразования было зарегистрировано время их преобразования. Впоследствии была выполнена задача инференса изображения болезни листьев арахиса с размером пакета 1, и для сравнения была измерена средняя задержка за 30 запусков. Результаты, касающиеся времени преобразования и задержки вывода, представлены на рисунке 7. Преобразование с использованием формата NCHW потребовало 12,68 секунды, тогда как преобразование формата NHWC заняло всего 1,43 секунды, что составляет сокращение примерно на 88,7%. С одной стороны, средняя задержка вывода модели на основе NCHW достигла 631,9 мс. С другой стороны, модель, преобразованная методом NHWC, дала среднюю задержку вывода 427,6 мс, уменьшившись примерно на 32,3%. Из вышеизложенных результатов можно сделать вывод, что более быстрое преобразование модели и более низкая задержка вывода достижимы на Jetson Nano B01 при использовании формата NHWC в TFLite, что делает эту стратегию эффективной для оптимизации развертывания.
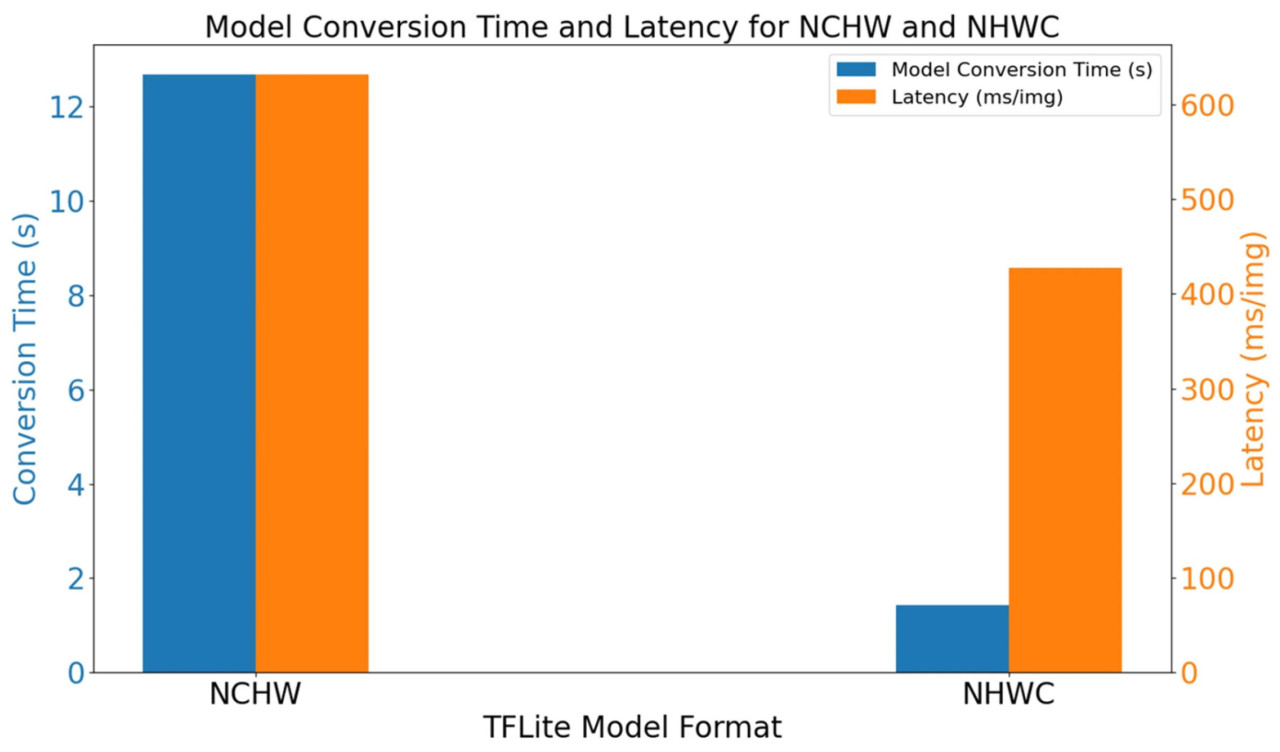
Рисунок 7. Время преобразования модели и задержка вывода.
4.4. Сравнительные эксперименты по фреймворку развертывания
Вышеупомянутые методы оптимизации эффективного развертывания были применены для выполнения задачи идентификации болезней листьев арахиса в обоих фреймворках инференса глубоких нейронных сетей: TensorRT и TFLite. Эти фреймворки были оценены на Jetson Nano B01 с точки зрения использования памяти, энергопотребления и задержки вывода. Благодаря своей оптимизации для параллельных вычислений, GPU способен одновременно обрабатывать несколько точек данных, тогда как CPU предназначен для задач общего назначения и не имеет аппаратного ускорения, необходимого для задач глубокого обучения. В результате производительность пакетной обработки на основе CPU в TFLite значительно ниже, чем у обработки на основе GPU на Jetson Nano B01. Во всех экспериментах использовался размер пакета, равный единице. Для сбора достаточного количества данных каждый фреймворк использовался для выполнения инференса одного и того же изображения 30 раз. Использование памяти и энергопотребление регистрировались каждую секунду, и на ящичковой диаграмме на рисунке 8 показаны эти измерения.
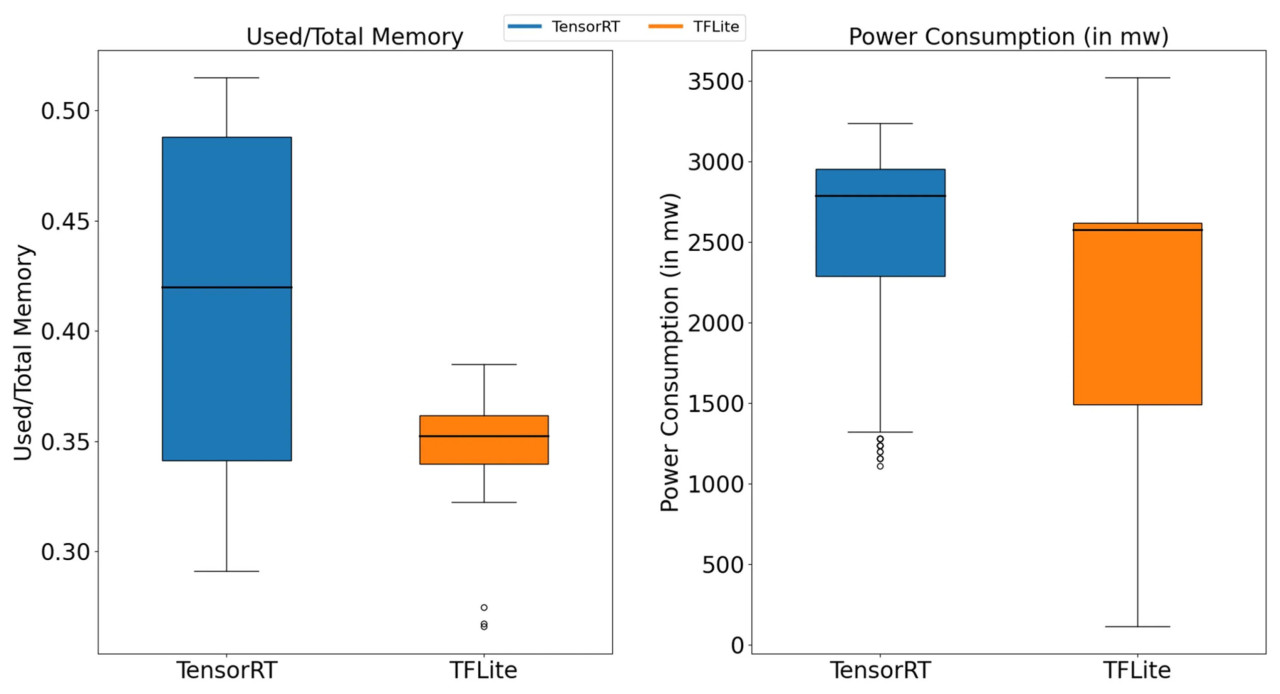
Рисунок 8. Использование памяти и энергопотребление.
Результаты показали, что при выполнении задачи инференса болезней листьев арахиса с размером пакета, равным единице, TFLite демонстрировал относительно стабильное использование памяти, тогда как TensorRT показал большую вариабельность в потреблении памяти. Кроме того, общее использование памяти TFLite было примерно на 15-20% ниже, чем у TensorRT. Хотя энергопотребление TFLite колебалось более значительно, оно оставалось примерно на 15-25% ниже, чем у TensorRT. После измерения использования памяти и энергопотребления для TensorRT и TFLite, их задержки вывода при точности FP32 и FP16 с размером пакета, равным единице, были зафиксированы в таблице 6. Изучая рисунок 8, можно заметить, что TFLite сохранял преимущества с точки зрения использования памяти и энергопотребления при выполнении инференса одного изображения листа арахиса на Jetson Nano B01. Однако TensorRT достиг снижения задержки вывода на 53,2% - 55,2% по сравнению с TFLite. Это расхождение в использовании памяти и энергопотреблении в значительной степени объясняется дизайном TFLite, который нацелен на маломощные встраиваемые и мобильные устройства, оптимизируя эти два фактора. Напротив, более высокое использование памяти и энергопотребление TensorRT способствовало более быстрому инференсу, что соответствует его ориентации на высокопроизводительный инференс.
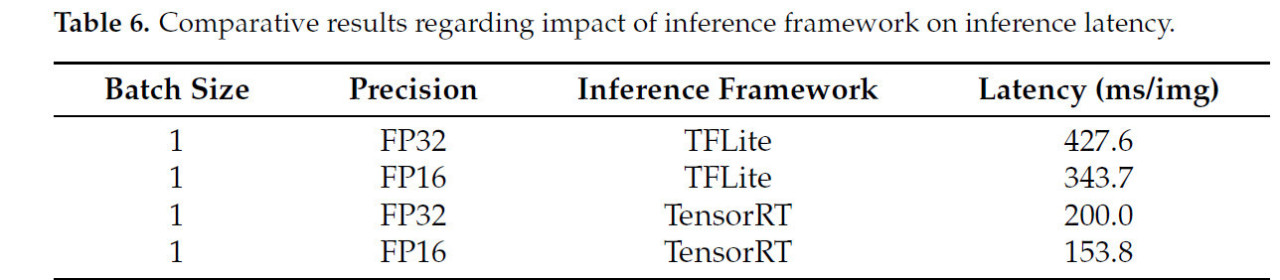
Таблица 6. Сравнительные результаты относительно влияния фреймворка инференса на задержку вывода.
4.5. Эксперимент по обнаружению в реальном времени в видео
Для проверки производительности обнаружения в реальном времени сети YOLOX-Tiny на реальных арахисовых полях, 30-секундное видео было записано с использованием USB-камеры Jie Rui Wei Tong DF100 для тестирования модели, с разрешением 1280 × 720 и частотой кадров 30 кадров/с. Поскольку TFLite сравнительно слабее TensorRT в обнаружении в реальном времени в видео, эксперименты проводились с использованием TensorRT. DeepStream, выпущенный NVIDIA и разработанный на основе фреймворка Gstreamer, представляет собой комплексный набор инструментов для анализа потоков, предназначенный для обработки видео и изображений в реальном времени. Передача видео и управление памятью были оптимизированы для GPU NVIDIA в DeepStream, тем самым снижая нагрузку на передачу данных между CPU и GPU [46]. Кроме того, DeepStream был специально оптимизирован для периферийных устройств с ИИ, чтобы обеспечить более эффективный инференс.
На этом этапе были проведены четыре сравнительных эксперимента с точностью FP16: (1) прямой инференс с использованием модели TensorRT; (2) прямой инференс с использованием модели TensorRT с плагином EfficientNMS_TRT; (3) инференс путем интеграции модели TensorRT в конвейер DeepStream; (4) инференс путем интеграции модели TensorRT с плагином EfficientNMS_TRT в конвейер DeepStream. Согласно таблице 7, соответствующие средние частоты кадров составили 13,2 FPS, 15,4 FPS, 24,1 FPS и 28,7 FPS. Соответствующие значения использования памяти и энергопотребления, представленные в таблице 6 как средние, показывают, что при самой высокой частоте кадров использование памяти и энергопотребление достигли 55,4% и 2826,1 мВт соответственно. Эти результаты указывают на то, что вставка EfficientNMS_TRT в модель TensorRT и ее интеграция в конвейер DeepStream, хотя и влечет за собой более высокие затраты памяти и энергии, значительно улучшает пропускную способность обнаружения в реальном времени в видео.
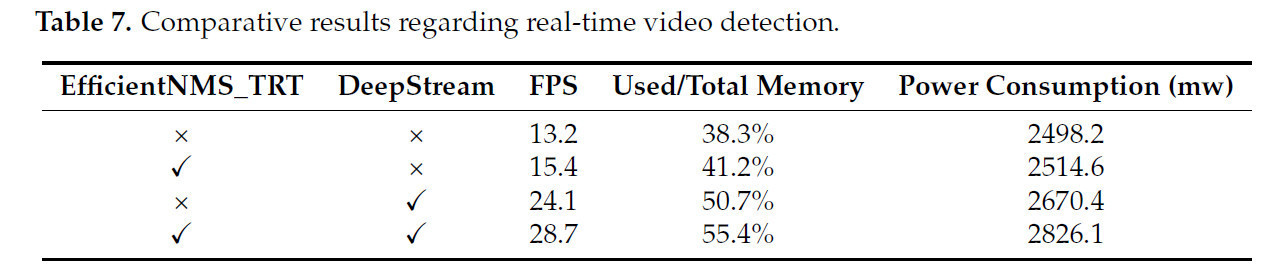
Таблица 7. Сравнительные результаты по обнаружению в реальном времени в видео.
На рисунке 9 показаны четыре примера кадров, выбранных из четвертого набора экспериментов. В этом исследовании YOLOX-Tiny использовалась для обнаружения в реальном времени болезней листьев арахиса в видеопотоках, и процесс был ускорен с помощью DeepStream для достижения более высокой производительности и точности в реальном времени. Этот подход предоставляет практические знания для эффективного развертывания моделей обнаружения болезней листьев сельскохозяйственных культур и может способствовать продвижению современного сельского хозяйства к большей интеллектуализации и точности.

Рисунок 9. Обнаружение в реальном времени в видео.
5. Обсуждение
Многие предыдущие исследования были направлены на улучшение архитектур глубоких нейронных сетей для повышения точности распознавания болезней листьев сельскохозяйственных культур. Различные сети обнаружения объектов были приняты для разных задач обнаружения. Линь и др. [47] представили улучшенную модель YOLOv8n, которая интегрировала FasterNeXt, разделяемую по глубине свертку и функцию обобщенного пересечения над объединением (GIoU_Loss) для достижения обнаружения болезней листьев арахиса в реальном времени при сохранении высокой точности. Чэнь и др. [48] предложили модель CACPNET, которая объединила модуль эффективного канального внимания (ECA) с канальным прореживанием, что делает ее пригодной для распознавания распространенных болезней растений. С другой стороны, Го и др. [49] построили модель прогнозирования пятнистости листьев арахиса, подавая карты признаков, полученные из CNN, улучшенной с помощью модуля сжатия-возбуждения (SE), в сеть долгой краткосрочной памяти (LSTM), используя многолетние метеорологические данные и записи о возникновении пятнистости листьев арахиса.
Вышеупомянутые исследователи внесли значительный вклад в задачи обнаружения болезней листьев арахиса. Учитывая, что их работа была в основном сосредоточена на этапе исследования алгоритмов, настоящее исследование в первую очередь включало развертывание сетей обнаружения объектов, предоставляя тем самым другим исследователям понимание эффективного развертывания таких сетей. Следовательно, YOLOX-Tiny была изначально выбрана для развертывания на Jetson Nano B01 в качестве примера для обнаружения болезней листьев арахиса. Впоследствии были проанализированы три метода оптимизации эффективного развертывания. Во-первых, влияние функции активации ReLU на задержку вывода было изучено с точки зрения слияния операторов. Кроме того, оптимизации в моделях TensorRT и TFLite были изучены отдельно. Первая была оптимизирована путем вставки EfficientNMS_TRT для ускорения части постобработки модели, в то время как вторая включала преобразование формата модели NCHW в формат NHWC, который более подходит для моделей TFLite. Кроме того, задачи инференса на изображениях болезней листьев арахиса выполнялись с размером пакета, равным единице, и различия в производительности сети YOLOX-Tiny во фреймворках инференса TensorRT и TFLite были сравнены с точки зрения использования памяти, энергопотребления и задержки вывода. Наконец, во фреймворке TensorRT более эффективное обнаружение болезней листьев арахиса в реальном времени в видео было достигнуто за счет использования EfficientNMS_TRT и DeepStream.
В наших экспериментах оставалось несколько ограничений. Во-первых, сеть YOLOX-Tiny была изначально выбрана из-за ее структурной простоты и зрелых стратегий развертывания. Однако, что касается возможностей обнаружения модели, текущая используемая сеть YOLOX-Tiny демонстрирует некоторые трудности в точном обнаружении болезней листьев арахиса. Поскольку целевые области болезней на листьях арахиса, как правило, малы, существует необходимость в улучшении способности модели обнаруживать мелкие объекты. Во-вторых, с точки зрения фреймворков инференса, TensorRT и TFLite были использованы для достижения эффективного инференса сети обнаружения объектов. Тем не менее, этот подход вводит определенные ограничения. Например, на оборудовании, отличном от NVIDIA, реализация не может быть полностью воспроизведена, что требует корректировки модели. Кроме того, это исследование было разработано с использованием Python, тогда как C++ больше подходит для задач высокопроизводительного инференса.
Следовательно, проведение будущих работ остается весьма значимым. С одной стороны, структура сетей обнаружения объектов может быть оптимизирована путем включения легковесных модулей, таких как CBAM или разделяемая по глубине свертка. Эти модули улучшают возможности извлечения признаков без существенного увеличения сложности модели; однако на этапе развертывания все еще требуется специализированная оптимизация. Кроме того, необходимо принять более совершенные сети обнаружения объектов для решения сложностей и проблем, присущих обнаружению болезней листьев арахиса. Таким образом, сети обнаружения объектов могут быть индивидуально оптимизированы для периферийных устройств с ИИ, тем самым улучшая точность модели и производительность в реальном времени и дополнительно способствуя широкому применению технологии обнаружения болезней листьев арахиса в сельском хозяйстве. С другой стороны, чтобы преодолеть ограничения, связанные с зависимостью от конкретных фреймворков инференса, будущие работы должны изучить методы сжатия моделей, такие как прореживание, дистилляция и квантование. Прореживание удаляет избыточные или незначимые веса и нейроны из модели, тем самым уменьшая ее размер. Дистилляция передает знания от моделей с превосходными способностями распознавания к тем, которые требуют оптимизации, поддерживая высокую точность распознавания болезней листьев арахиса. В этом исследовании использовалось PTQ, которое непосредственно квантует веса и значения активации после обучения модели. И наоборот, квантование с учетом обучения (QAT) имитирует операции квантования во время обучения, достигая более высокой точности. Эти методы могут значительно снизить сложность модели и повысить эффективность инференса, способствуя более эффективному развертыванию на периферийных устройствах с ИИ. Это, в свою очередь, может улучшить эффективность и точность обнаружения болезней листьев в сельском хозяйстве, дополнительно продвигая применение и развитие глубоких нейронных сетей в современном сельском хозяйстве и обеспечивая техническую поддержку для точного земледелия и устойчивого развития.
6. Выводы
В этом исследовании было разработано оптимизированное решение для эффективного развертывания модели обнаружения болезней листьев арахиса YOLOX-Tiny на устройстве Jetson Nano B01 в условиях ограниченных ресурсов сельскохозяйственной среды.
Выводы этого исследования следующие.
· Слияние функции активации ReLU со сверточными операциями снизило задержку вывода на 55,5% по сравнению с использованием только SiLU. В модели TensorRT вставка модуля EfficientNMS_TRT ускорила постобработку модели, что привело к снижению задержки вывода на 19,6% и увеличению FPS на 20,4%. В модели TensorFlow Lite преобразование в формат NHWC уменьшило время преобразования модели на 88,7% и задержку вывода на 32,3%. Эти три метода оптимизации эффективного развертывания позволили снизить задержку вывода и повысить эффективность инференса.
· Сравнение двух фреймворков показало, что TensorFlow Lite демонстрирует на 15–20% более низкое использование памяти и на 15–25% более низкое энергопотребление по сравнению с TensorRT. Однако TensorRT достиг снижения задержки вывода на 53,2–55,2% относительно TFLite. Таким образом, TensorRT подходит для задач, требующих высокой производительности в реальном времени и низкой задержки, тогда как TFLite больше подходит для сценариев с ограничениями по памяти и энергопотреблению.
· Сочетание DeepStream и EfficientNMS_TRT максимизировало использование памяти и энергии, тем самым повышая скорость обнаружения в реальном времени в видео. При разрешении 1280 × 720 была достигнута частота кадров 28,7 FPS.
Ссылки
1. Chen, T.; Yang, W.; Zhang, H.; Zhu, B.; Zeng, R.; Wang, X.; Wang, S.; Wang, L.; Qi, H.; Lan, Y.; et al. Early detection of bacterial wilt in peanut plants through leaf-level hyperspectral and unmanned aerial vehicle data. Comput. Electron. Agric. 2020, 177, 105708. [Google Scholar] [CrossRef]
2. Yu, B.; Jiang, H.; Pandey, M.K.; Huang, L.; Huai, D.; Zhou, X.; Kang, Y.; Varshney, R.K.; Sudini, H.K.; Ren, X.; et al. Identification of two novel peanut genotypes resistant to aflatoxin production and their SNP markers associated with resistance. Toxins 2020, 12, 156. [Google Scholar] [CrossRef]
3. Akkem, Y.; Biswas, S.K.; Varanasi, A. Smart farming using artificial intelligence: A review. Eng. Appl. Artif. Intell. 2023, 120, 105899. [Google Scholar] [CrossRef]
4. Attri, I.; Awasthi, L.K.; Sharma, T.P.; Rathee, P. A review of deep learning techniques used in agriculture. Ecol. Inform. 2023, 77, 102217. [Google Scholar] [CrossRef]
5. Liu, J.; Xiang, J.; Jin, Y.; Liu, R.; Yan, J.; Wang, L. Boost precision agriculture with unmanned aerial vehicle remote sensing and edge intelligence: A survey. Remote Sens. 2021, 13, 4387. [Google Scholar] [CrossRef]
6. Koubaa, A.; Ammar, A.; Kanhouch, A.; AlHabashi, Y. Cloud versus edge deployment strategies of real-time face recognition inference. IEEE Trans. Netw. Sci. Eng. 2021, 9, 143–160. [Google Scholar] [CrossRef]
7. Ranjana, P.; Reddy, J.P.K.; Manoj, J.B.; Sathvika, K. Plant Leaf Disease Detection Using Mask R-CNN. In Ambient Communications and Computer Systems: Proceedings of RACCCS 2021; Springer: Singapore, 2022; pp. 303–314. [Google Scholar]
8. Sun, H.; Xu, H.; Liu, B.; He, D.; He, J.; Zhang, H.; Geng, N. MEAN-SSD: A novel real-time detector for apple leaf diseases using improved light-weight convolutional neural networks. Comput. Electron. Agric. 2021, 189, 106379. [Google Scholar] [CrossRef]
9. Lin, J.; Yu, D.; Pan, R.; Cai, J.; Liu, J.; Zhang, L.; Wen, X.; Peng, X.; Cernava, T.; Oufensou, S.; et al. Improved YOLOX-Tiny network for detection of tobacco brown spot disease. Front. Plant Sci. 2023, 14, 1135105. [Google Scholar] [CrossRef]
10. Li, R.; Li, Y.; Qin, W.; Abbas, A.; Li, S.; Ji, R.; Wu, Y.; He, Y.; Yang, J. Lightweight Network for Corn Leaf Disease Identification Based on Improved YOLO v8s. Agriculture 2024, 14, 220. [Google Scholar] [CrossRef]
11. Sangaiah, A.K.; Yu, F.N.; Lin, Y.B.; Shen, W.C.; Sharma, A. UAV T-YOLO-Rice: An Enhanced Tiny Yolo Networks for Rice Leaves Diseases Detection in Paddy Agronomy. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5201–5216. [Google Scholar] [CrossRef]
12. Li, Y.; Wang, J.; Wu, H.; Yu, Y.; Sun, H.; Zhang, H. Detection of powdery mildew on strawberry leaves based on DAC-YOLOv4 model. Comput. Electron. Agric. 2022, 202, 107418. [Google Scholar] [CrossRef]
13. Gajjar, R.; Gajjar, N.; Thakor, V.J.; Patel, N.P.; Ruparelia, S. Real-time detection and identification of plant leaf diseases using convolutional neural networks on an embedded platform. Vis. Comput. 2022, 38, 2923–2938. [Google Scholar] [CrossRef]
14. Xie, Z.; Li, C.; Yang, Z.; Zhang, Z.; Jiang, J.; Guo, H. YOLOv5s-BiPCNeXt, a Lightweight Model for Detecting Disease in Eggplant Leaves. Plants 2024, 13, 2303. [Google Scholar] [CrossRef]
15. Stäcker, L.; Fei, J.; Heidenreich, P.; Bonarens, F.; Rambach, J.; Stricker, D.; Stiller, C. Deployment of deep neural networks for object detection on edge ai devices with runtime optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 1015–1022. [Google Scholar]
16. Xu, L.; Cao, B.; Ning, S.; Zhang, W.; Zhao, F. Peanut leaf disease identification with deep learning algorithms. Mol. Breed. 2023, 43, 25. [Google Scholar] [CrossRef]
17. Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
18. Han, X.; Chang, J.; Wang, K. You only look once: Unified, real-time object detection. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar] [CrossRef]
19. Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
20. Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
21. Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
22. Han, J.; Yang, G.; Wei, H.; Gong, W.; Qian, Y. ST-YOLOX: A lightweight and accurate object detection network based on Swin Transformer. J. Supercomput. 2024, 80, 8038–8059. [Google Scholar] [CrossRef]
23. Ru, C.; Zhang, S.; Qu, C.; Zhang, Z. The high-precision detection method for insulators’ self-explosion defect based on the unmanned aerial vehicle with improved lightweight ECA-YOLOX-Tiny model. Appl. Sci. 2022, 12, 9314. [Google Scholar] [CrossRef]
24. Zhang, D.; Hao, X.; Liang, L.; Liu, W.; Qin, C. A novel deep convolutional neural network algorithm for surface defect detection. J. Comput. Des. Eng. 2022, 9, 1616–1632. [Google Scholar] [CrossRef]
25. Aubard, M.; Antal, L.; Madureira, A.; Ábrahám, E. Knowledge Distillation in YOLOX-ViT for Side-Scan Sonar Object Detection. arXiv 2024, arXiv:2403.09313. [Google Scholar]
26. Zhao, Y.; Yang, Y.; Chen, S. An Active Semi-Supervised Learning for Object Detection. In Proceedings of the 2023 International Conference on Culture-Oriented Science and Technology (CoST), Xi’an, China, 11–14 October 2023; pp. 257–261. [Google Scholar]
27. Shevlane, T. Structured access: An emerging paradigm for safe AI deployment. arXiv 2022, arXiv:2201.05159. [Google Scholar]
28. Islam, J.; Kumar, T.; Kovacevic, I.; Harjula, E. Resource-aware dynamic service deployment for local iot edge computing: Healthcare use case. IEEE Access 2021, 9, 115868–115884. [Google Scholar] [CrossRef]
29. Yu, X.; Yang, M.; Zhang, H.; Li, D.; Tang, Y.; Yu, X. Research and Application of Crop Diseases Detection Method Based on Transfer Learning. Trans. Chin. Soc. Agric. Mach. 2020, 51, 252–258. [Google Scholar]
30. Gu, R.; Niu, C.; Wu, F.; Chen, G.; Hu, C.; Lyu, C.; Wu, Z. From server-based to client-based machine learning: A comprehensive survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
31. Ma, F.; Wang, B.; Dong, X.; Wang, H.; Luo, P.; Zhou, Y. Power vision edge intelligence: Power depth vision acceleration technology driven by edge computing. Power Syst. Technol. 2020, 44, 2020–2029. [Google Scholar]
32. Rui, W.; Jianpeng, Q.; Liang, C.; Long, Y. Survey of Collaborative Inference for Edge Intelligence. J. Comput. Res. Dev. 2023, 60, 398–414. [Google Scholar]
33. Shuvo, M.M.H.; Islam, S.K.; Cheng, J.; Morshed, B.I. Efficient acceleration of deep learning inference on resource-constrained edge devices: A review. Proc. IEEE 2022, 111, 42–91. [Google Scholar] [CrossRef]
34. Nair, S.; Abbasi, S.; Wong, A.; Shafiee, M.J. Maple-edge: A runtime latency predictor for edge devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3660–3668. [Google Scholar]
35. Niu, W.; Guan, J.; Wang, Y.; Agrawal, G.; Ren, B. Dnnfusion: Accelerating deep neural networks execution with advanced operator fusion. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual, 20–25 June 2021; pp. 883–898. [Google Scholar]
36. Cai, X.; Wang, Y.; Zhang, L. Optimus: An operator fusion framework for deep neural networks. ACM Trans. Embed. Comput. Syst. 2022, 22, 1–26. [Google Scholar] [CrossRef]
37. TensorFlow Lite. Available online: https://www.tensorflow.org/lite/guide (accessed on 24 December 2024).
38. TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 24 December 2024).
39. Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 16965–16974. [Google Scholar]
40. Shin, D.J.; Kim, J.J. A deep learning framework performance evaluation to use YOLO in Nvidia Jetson platform. Appl. Sci. 2022, 12, 3734. [Google Scholar] [CrossRef]
41. Gong, M.; Wang, D.; Zhao, X.; Guo, H.; Luo, D.; Song, M. A review of non-maximum suppression algorithms for deep learning target detection. In Proceedings of the Seventh Symposium on Novel Photoelectronic Detection Technology and Applications. SPIE, Kunming, China, 5–7 November 2021; Volume 11763, pp. 821–828. [Google Scholar]
42. Symeonidis, C.; Mademlis, I.; Pitas, I.; Nikolaidis, N. Neural attention-driven non-maximum suppression for person detection. IEEE Trans. Image Process. 2023, 32, 2454–2467. [Google Scholar] [CrossRef] [PubMed]
43. EfficientNMSPlugin. Available online: https://github.com/NVIDIA/TensorRT/tree/main/plugin/efficientNMSPlugin (accessed on 24 December 2024).
44. Fu, X.; Zhang, X.; Ma, J.; Zhao, P.; Lu, S.; Liu, X.T. High Performance Im2win and Direct Convolutions using Three Tensor Layouts on SIMD Architectures. arXiv 2024, arXiv:2408.00278. [Google Scholar]
45. qengineering. Available online: https://qengineering.eu/install-tensorflow-2-lite-on-jetson-nano.html (accessed on 24 December 2024).
46. NVIDIADeepStreamSDK. Available online: https://developer.nvidia.com/deepstream-sdk (accessed on 24 December 2024).
47. Lin, Y.; Wang, L.; Chen, T.; Liu, Y.; Zhang, L. Monitoring system for peanut leaf disease based on a lightweight deep learning model. Comput. Electron. Agric. 2024, 222, 109055. [Google Scholar] [CrossRef]
48. Chen, R.; Qi, H.; Liang, Y.; Yang, M. Identification of plant leaf diseases by deep learning based on channel attention and channel pruning. Front. Plant Sci. 2022, 13, 1023515. [Google Scholar] [CrossRef] [PubMed]
49. Guo, Z.; Chen, X.; Li, M.; Chi, Y.; Shi, D. Construction and validation of peanut leaf spot disease prediction model based on long time series data and deep learning. Agronomy 2024, 14, 294. [Google Scholar] [CrossRef]
Lv Z, Yang S, Ma S, Wang Q, Sun J, Du L, Han J, Guo Y, Zhang H. Efficient Deployment of Peanut Leaf Disease Detection Models on Edge AI Devices. Agriculture. 2025; 15(3):332. https://doi.org/10.3390/agriculture15030332
Перевод статьи «Efficient Deployment of Peanut Leaf Disease Detection Models on Edge AI Devices» авторов Lv Z, Yang S, Ma S, Wang Q, Sun J, Du L, Han J, Guo Y, Zhang H., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык




















































































































Комментарии (0)