Метод прогнозирования цен на овощи, основанный на архитектуре «смесь экспертов» (VPF-MoE)
Точное прогнозирование цен на овощи имеет решающее значение для разработки политики, принятия рыночных решений и стабильности аграрного рынка. Традиционные модели временных рядов часто требуют ручной настройки параметров и плохо справляются со сложными нелинейными зависимостями в данных о ценах на овощи, что ограничивает точность прогнозов.
Аннотация
В данном исследовании проводится всесторонний анализ эффективности традиционных методов, подходов глубокого обучения и передовых больших языковых моделей (LLM) в прогнозировании цен на овощи с использованием множества метрик. Результаты экспериментов показывают, что большие языковые модели в целом превосходят другие методы, но не демонстрируют стабильной эффективности для всех видов овощей на различных временных горизонтах.
Вследствие этого мы предлагаем новый метод прогнозирования VPF-MoE, основанный на архитектуре «смесь экспертов» (Mixture of Experts). Он сочетает в себе преимущества больших языковых моделей и методов глубокого обучения. В отличие от традиционного подхода с единой моделью, VPF-MoE динамически адаптируется к характеристикам различных видов овощей, выбирая для каждого случая наилучший метод прогнозирования, что значительно повышает точность и устойчивость системы. Кроме того, мы оптимизировали применение больших языковых моделей для прогнозирования цен на овощи, предложив новое технологическое решение для этой задачи.
1. Введение
Овощеводство занимает значительное положение в современной аграрной и сельской экономике, являясь ключевым источником для ежедневного потребления населения [1]. Колебания цен на овощи существенно влияют на сельскохозяйственное производство, рыночное предложение и потребительское поведение при покупках. Однако цены на овощи часто подвержены заметной волатильности из-за влияния таких факторов, как стихийные бедствия, рыночная динамика спроса и предложения, а также макрополитическая среда. Эти ценовые колебания демонстрируют нерегулярные характеристики, включая нестационарность и нелинейность [2], что увеличивает риски для фермеров и усугубляет нестабильность на аграрных рынках. Следовательно, точное прогнозирование цен на овощи стало imperative для стабилизации аграрных рынков и руководства планированием и развитием производства.
Прогнозирование цен на овощи является ключевой областью исследований в сельском хозяйстве и важным аспектом прогнозирования данных временных рядов. Прогнозирование временных рядов анализирует исторические данные для выявления тенденций и закономерностей, предсказывая будущие значения и тренды [3]. Традиционные методы прогнозирования временных рядов, такие как интегрированная модель авторегрессии — скользящего среднего (ARIMA), обобщенная авторегрессионная условная гетероскедастичность (GARCH) и модели экспоненциального сглаживания, основаны на статистических рамках и широко применяются в таких областях, как финансы и энергетика [4,5]. Однако эти методы часто предполагают линейность и стационарность данных временных рядов, что ограничивает их способность обрабатывать сложные нелинейные закономерности в реальных наборах данных. Более того, традиционные подходы с трудом эффективно и точно обрабатывают данные крупного масштаба [6].
В последние годы глубокое обучение стало доминирующим подходом в прогнозировании временных рядов благодаря своим мощным возможностям моделирования и анализа данных. В частности, архитектура Transformer продемонстрировала значительные преимущества в анализе данных временных рядов с долгосрочными зависимостями. Несмотря на достижения в точности прогнозирования, обеспечиваемые глубоким обучением, остаются проблемы, включая масштабируемость и вычислительную эффективность.
С непрерывной оптимизацией архитектур нейронных сетей и развитием высокопроизводительных вычислений большие языковые модели (LLM), представленные такими технологиями, как GPT, произвели революцию в этой области. Появление ChatGPT еще больше усилило интерес к этим моделям. LLM превосходно обрабатывают сложные последовательности и выполняют логические выводы на основе данных, эффективно улавливая замысловатые долгосрочные зависимости в данных временных рядов и демонстрируя превосходство в задачах прогнозирования «с нуля» (zero-shot) [7], что открывает новые направления исследований и сценарии применения для прогнозирования временных рядов.
Большинство существующих исследований по прогнозированию цен на овощи сосредоточено на использовании подхода с единой моделью, который все еще имеет значительные ограничения в практических приложениях, особенно при работе с интеграцией данных различных масштабов. Мы оценили производительность этих методов в прогнозировании как краткосрочных, так и долгосрочных цен на овощи и обнаружили, что разные модели демонстрируют разную производительность для различных сортов овощей и разных временных масштабов. Поэтому единая модель часто не способна эффективно решать задачи прогнозирования цен для всех видов овощей. Техники ансамблей моделей, при которых оптимальная модель выбирается на основе характеристик каждого вида овощей, предоставляют хорошее решение этой проблемы. Архитектура «смесь экспертов» (MoE) служит отличным подходом к созданию ансамблей моделей для решения этой задачи. Особенно в практических приложениях, из-за различий в механизмах моделирования и отправных точках разных моделей, одна и та же задача прогнозирования часто может выявлять вариации цен на овощи через разные методы предсказания. Следовательно, более научная стратегия прогнозирования заключается в оптимизации комбинации нескольких методов прогнозирования для достижения взаимодополняющих преимуществ. Этот комбинированный подход к прогнозированию стал тенденцией развития в области исследований прогнозирования цен на сельскохозяйственную продукцию.
Основной вклад данной статьи заключается в предложении инновационного метода прогнозирования цен на овощи на основе MoE — VPP-MoE. Этот метод сочетает большую языковую модель (LLM), обученную на миллиардах точек данных, с методами глубокого обучения, эффективно повышая точность и масштабируемость прогнозирования цен на овощи. Для оценки производительности модели мы использовали метрики прогнозирования временных рядов, включая MAE, MSE, R2 и коэффициенты корреляции, и применили алгоритм голосования для выбора окончательной модели. MAE и MSE оценивают величину и распределение ошибки, R2 измеряет объясняющую способность, а корреляция оценивает связь между прогнозируемыми и фактическими значениями. Этот многомерный подход позволил более точно оценить прогностическую способность и пригодность модели. VPF-MoE эффективно интегрирует возможности захвата долгосрочных зависимостей и сложных взаимосвязей в данных временных рядов цен из разных методов для достижения точных ценовых прогнозов, заполняя пробел в существующих исследованиях по прогнозированию цен на овощи и предоставляя новое направление для будущего прогнозирования цен на овощи. Насколько нам известно, это первое исследование применения LLM для прогнозирования цен на овощи.
2. Обзор литературы
Многочисленные исследования показывают, что цены на сельскохозяйственную продукцию находятся под влиянием различных факторов, включая спрос и предложение, изменения погоды, политические вмешательства и рыночные риски. Исследования указывают, что спрос и предложение являются ключевыми факторами, определяющими цены на сельскохозяйственную продукцию, при этом производственная деятельность вызывает колебания цен через их влияние на соотношение спроса и предложения [8,9]. Кроме того, такие переменные, как затраты на рабочую силу, затраты на выращивание, а также климат, продолжительность солнечного света и эпидемии, оказывают значительное влияние на цены на сельскохозяйственную продукцию [10].
Однако взаимосвязь между ценами и различными влияющими факторами, как правило, нелинейна, динамична и неопределенна, что затрудняет точную количественную оценку с помощью простых математических моделей [11]. Многие ученые исследовали производительность одномерного прогнозирования временных рядов, анализируя волатильность ценовых временных рядов. Хотя этот одномерный подход к прогнозированию не может выявить динамические изменения в объемах производства или спроса, его результаты часто могут косвенно отражать влияние этих изменений на цены [12]. Поэтому данное исследование фокусируется на прогнозной производительности одномерных ценовых временных рядов.
Современные методы прогнозирования цен на сельскохозяйственную продукцию можно разделить на два основных типа: традиционное прогнозирование временных рядов на основе статистических моделей и интеллектуальные методы прогнозирования на основе машинного обучения и глубокого обучения.
Традиционные методы прогнозирования цен на овощи в основном опираются на статистические характеристики исторических данных, часто предполагая линейные корреляции в ценах на овощи [13]. Модель ARIMA является одним из наиболее широко используемых методов одномерного прогнозирования временных рядов. Например, Kumar Mahto и др. успешно применили ARIMA для краткосрочного прогнозирования цен на семена подсолнечника в Индии с 2011 по 2016 год [14]. Сезонная интегрированная модель авторегрессии — скользящего среднего (SARIMA) включает сезонные вариации в данные о ценах, чтобы лучше улавливать циклические ценовые колебания [15]. Zheng Xiuguo и др. проанализировали оптовые цены на овощи в Шанхае и разработали модель SARIMA, которая эффективно охарактеризовала локальную ценовую волатильность [16]. Однако эти традиционные методы с трудом учитывают нелинейные взаимосвязи, присущие ценам на овощи, что приводит к неоптимальной точности прогнозирования.
Алгоритмы машинного обучения и глубокого обучения достигли значительного прогресса в прогнозировании цен на овощи [17]. Подходы машинного обучения, такие как искусственные нейронные сети (ANN) и регрессия опорных векторов (SVR), известны своей простотой и высокой скоростью обучения [18]. Например, Babu и др. использовали модели, такие как случайный лес, метод опорных векторов и наивный байесовский классификатор, для прогнозирования цен на лук, продемонстрировав их эффективность [19]. Аналогично, Paul и др. применили четыре модели машинного обучения для прогнозирования ежедневных цен на баклажаны, достигнув лучшей точности, чем традиционные методы [20]. Однако модели машинного обучения часто требуют разработки признаков экспертами и ограничены в обработке сложных нелинейных данных временных рядов, что делает их склонными к переобучению и затрудняет обобщение для разных овощей [21].
Модели глубокого обучения предлагают превосходные возможности извлечения и представления признаков, позволяя им захватывать эффективные временные особенности из исходных последовательностей без опоры на разработку признаков. Они хорошо подходят для обработки нелинейных взаимосвязей в крупномасштабных периодических наборах данных, что делает их эффективным решением для прогнозирования цен на овощи [22]. Методы на основе глубокого обучения включают многослойные перцептроны (MLP), рекуррентные нейронные сети (RNN), сверточные нейронные сети (CNN), сети долгой краткосрочной памяти (LSTM) и модели Transformer [23]. Sari и др. продемонстрировали, что модели LSTM превосходят традиционные статистические и методы машинного обучения в прогнозировании сельскохозяйственных цен [24]. MLP изучают сложные нелинейные взаимосвязи в данных временных рядов через сложенные скрытые слои и были успешно применены к прогнозированию сельскохозяйственных цен [25]. Nayak и др. использовали модель N-BEATS для прогнозирования еженедельных цен на картофель, показав ее превосходную производительность по сравнению с CNN и LSTM [26]. Karthik и др. подчеркнули потенциал моделей прогнозирования временных рядов на основе MLP в значительном улучшении точности прогнозирования сельскохозяйственных цен [27]. Модели Transformer с их механизмом самовнимания (self-attention) [28] захватывают долгосрочные зависимости в сложных данных временных рядов, преодолевая ограничения традиционных моделей в отношении прогнозирования длинных последовательностей и параллельных вычислений. Многочисленные варианты Transformer продемонстрировали преимущества архитектуры в приложениях для прогнозирования цен. Несмотря на эти достижения, большинство методов адаптированы к конкретным сельскохозяйственным продуктам, имеют ограниченную масштабируемость и ограничения, накладываемые архитектурами моделей.
LLM решают эти проблемы, предлагая улучшенную масштабируемость и способность эффективно обрабатывать данные временных рядов крупного масштаба. Но существует мало исследований по прогнозированию цен на сельскохозяйственную продукцию с использованием LLM. Таким образом, мы исследуем применение LLM в прогнозировании цен на овощи, стремясь предоставить новую перспективу для этого. В зависимости от подхода к исследованию, модели прогнозирования временных рядов на основе LLM можно классифицировать на два типа [29]: прямое применение универсальных LLM к прогнозированию временных рядов путем кодирования данных временных рядов как представлений естественного языка для углубленного анализа [30] и разработка специализированных моделей временных рядов, адаптированных к характеристикам данных временных рядов. Эти модели преобразуют данные временных рядов в форматы, совместимые с LLM, используя такие методы, как квантование и выравнивание [31,32], конструируя предметно-ориентированные базовые модели для более точного решения задач прогнозирования временных рядов (Таблица 1).
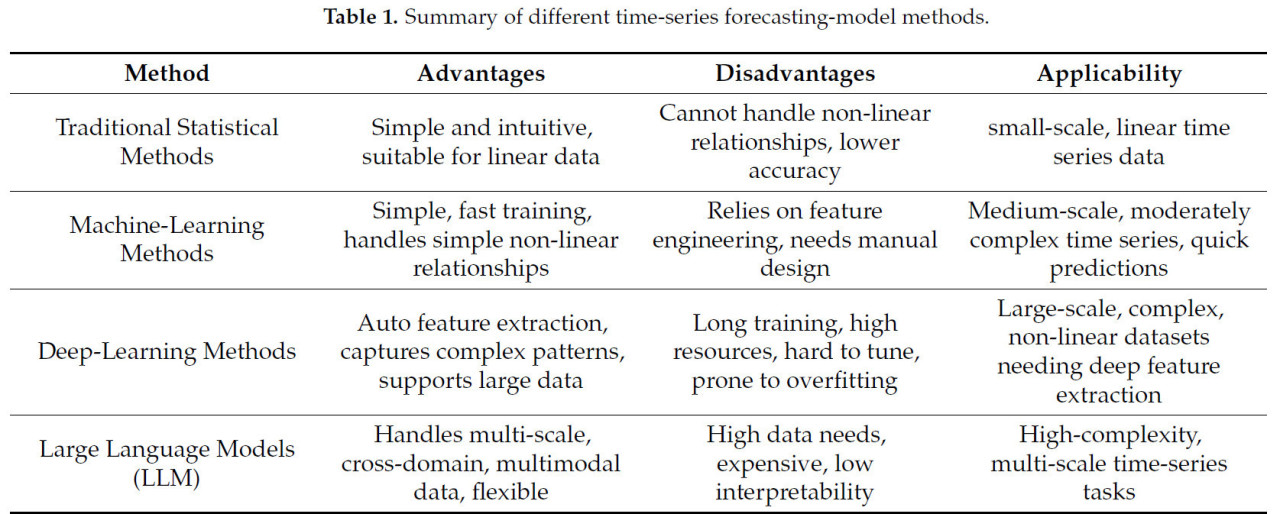

Таблица 1. Сводка различных методов моделей прогнозирования временных рядов.
3. Материалы и методы
3.1. Данные
3.1.1. Выбор данных
В данной статье используются данные о среднесуточных ценах на различные сорта овощей с 1 января 2014 года по 31 марта 2024 года, собранные на семи крупных оптовых рынках в Пекине, Китай (оптовые рынки Синьфади, Юэгэчжуан, Даянлу, Шимэнь, Балицяо, Шуйтунь и Цзиньсю Дади). Все данные были собраны авторитетными государственными органами, имеют обширный временной охват, что гарантирует надежность и точность данных, обеспечивая тем самым всесторонний обзор и анализ колебаний цен на овощи. Наборы данных включают корнишон (bur cucumber), вешенку (oyster mushroom), цветную капусту, кочанный салат (knotted lettuce) и баклажан. Эти пять сортов овощей были выбраны из четырех основных категорий — листовые овощи, пасленовые овощи, овощи длительного хранения и съедобные грибы. Из каждой категории было выбрано от одного до двух видов овощей, чтобы обеспечить репрезентативную выборку, отражающую разнообразные характеристики производства овощей и рыночных условий.
Для оценки производительности модели в прогнозировании цен на овощи на разных временных масштабах исходные ежедневные данные были передискретизированы для создания еженедельных и ежемесячных наборов данных о ценах на овощи.
Как показано на Рисунке 1, линейный график представляет общие ценовые колебания различных сортов овощей за последние десять лет. Анализ выявляет отчетливые закономерности ценовых вариаций среди типов овощей, однако все они демонстрируют заметные сезонные колебания. В частности, вешенка демонстрирует более высокую общую цену по сравнению с другими сортами, с отчетливо отличной тенденцией ценовых колебаний. Напротив, корнишон, цветная капуста, кочанный салат и баклажан показывают схожие общие уровни цен и демонстрируют относительно согласованные закономерности колебаний. Эти сорта обычно демонстрируют циклические и сезонные вариации, характеризующиеся более высокими ценами в зимние и весенние месяцы и более низкими ценами летом и осенью. От прогностических моделей требуются возможности подчеркивать сезонный характер цен на овощи и обеспечения базового понимания ценовой динамики.
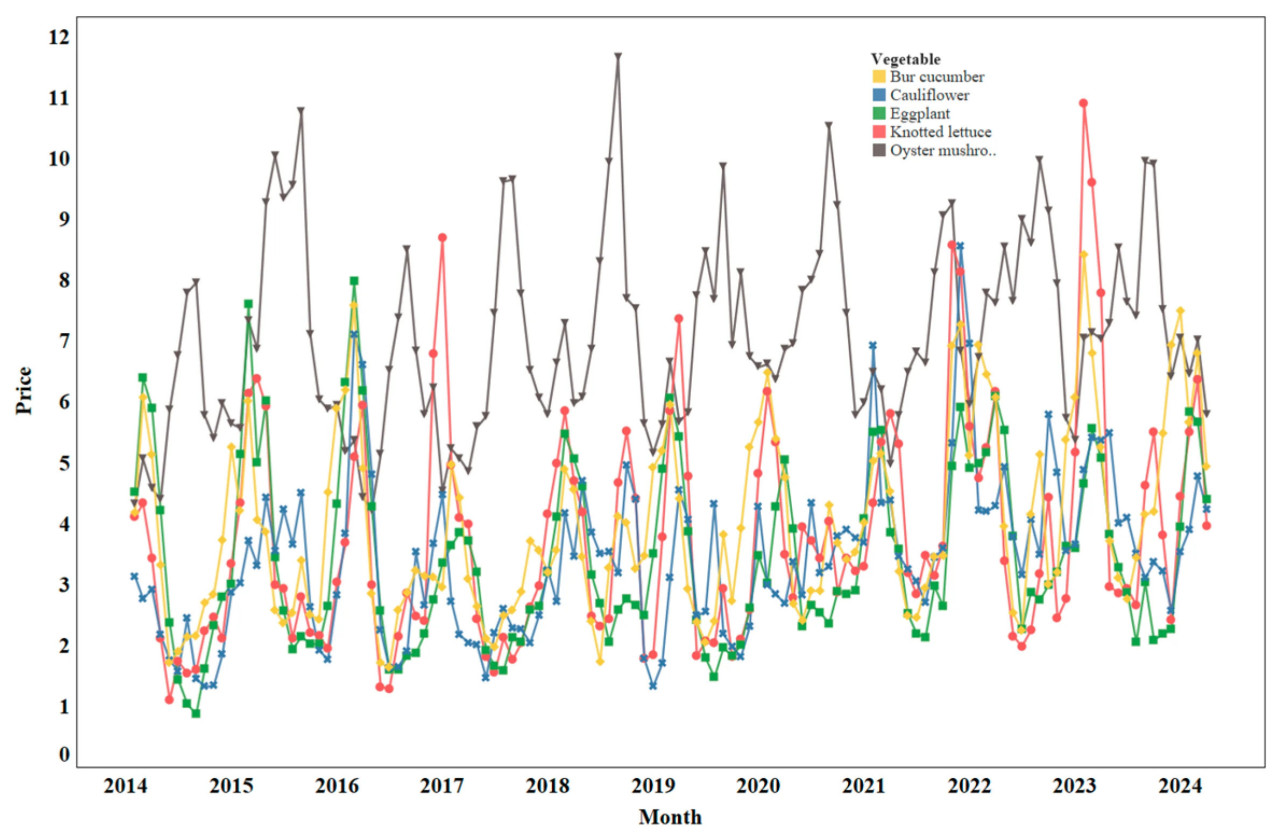
Рисунок 1. Анализ тенденции ценовых колебаний на овощи.
Дополнительные графики для каждого овоща, представленные в Приложении А Рисунок A1, предлагают более детальный анализ.
3.1.2. Дескриптивный анализ данных
Таблица 2 представляет сводку общей статистики данных о ценах, включая ключевые показатели колебаний цен для каждого сорта овощей, такие как среднее значение, максимум, минимум, стандартное отклонение и дисперсия. Набор данных включает 3743 наблюдения по пяти сортам овощей. Среди них цена на кочанный салат демонстрирует значительные колебания, что отражено в относительно высоком стандартном отклонении и дисперсии. Напротив, баклажан и цветная капуста показывают относительно стабильные ценовые закономерности, характеризующиеся более низкими уровнями дисперсии (Таблица 2).
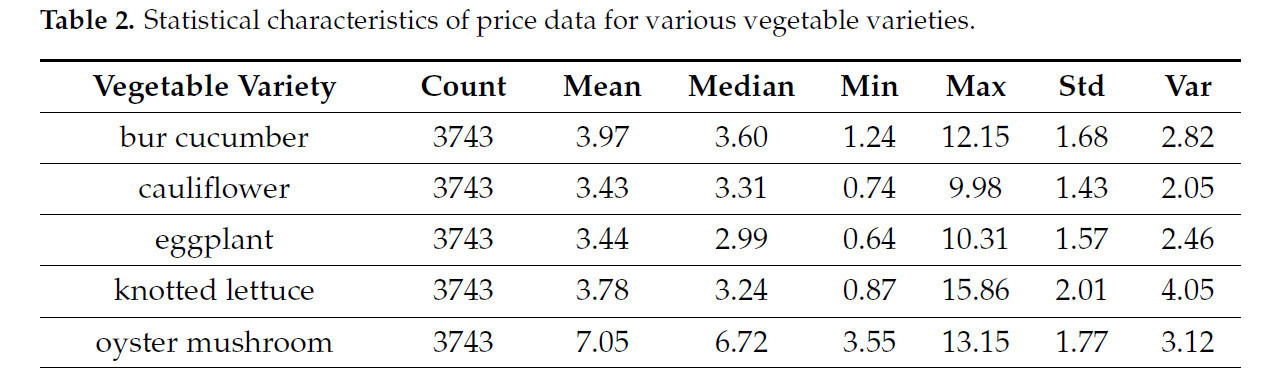
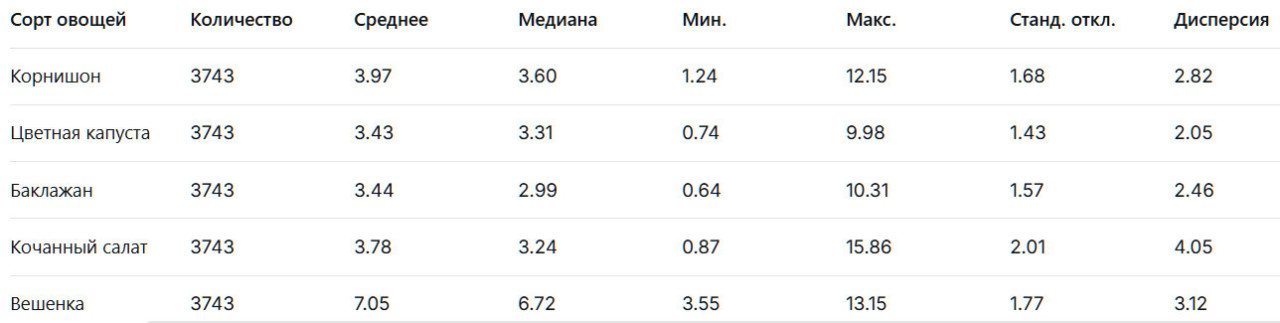
Таблица 2. Статистические характеристики данных о ценах для различных сортов овощей.
Рисунок 2 представляет анализ ящика с усами (box plot) ежедневных цен пяти сортов овощей в 2023 году, наглядно иллюстрирующий характеристики ценовых колебаний каждого овоща. Как видно из рисунка, существуют значительные различия в распределении цен среди различных сортов овощей. Данные о ценах на корнишон, цветную капусту, баклажан и вешенку демонстрируют меньше выбросов, причем некоторые категории не показывают выбросов вообще. Напротив, цена на кочанный салат показывает значительное количество выбросов вокруг периода Лунного Нового года, отражая существенные колебания рыночных цен в это время.
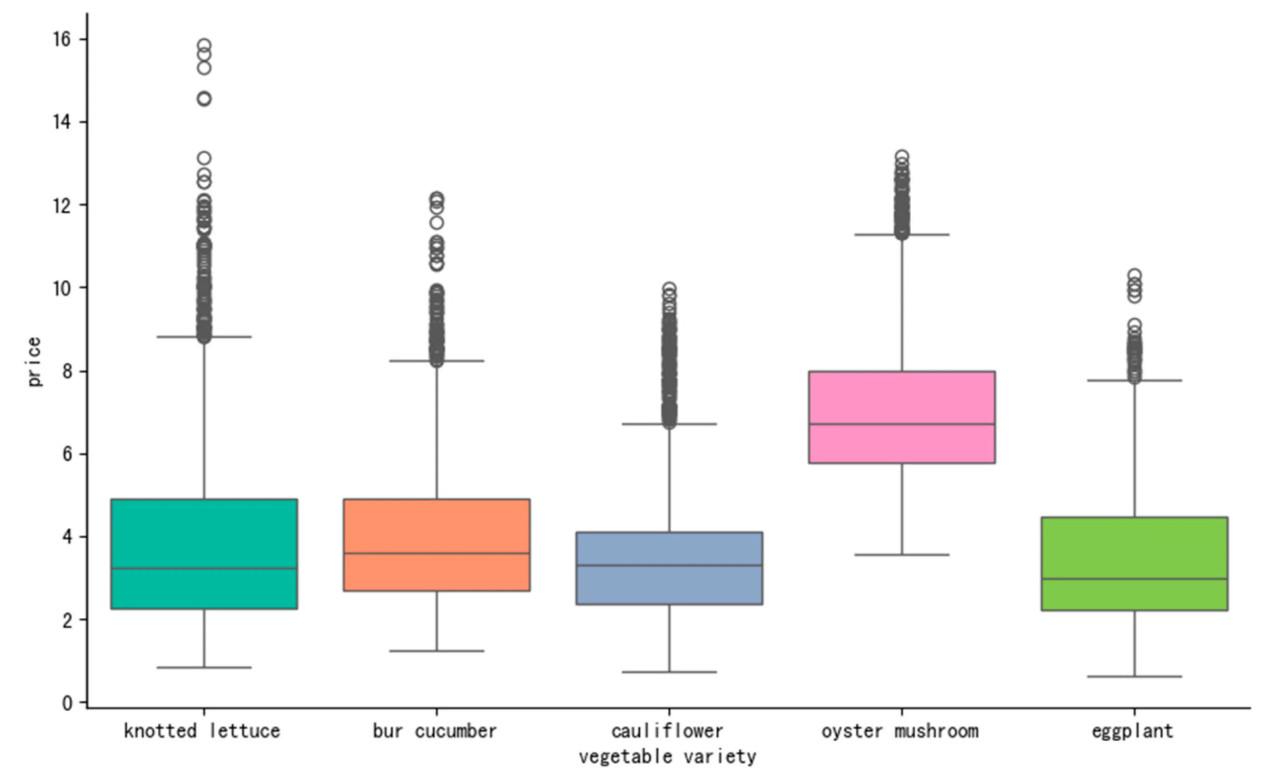
Рисунок 2. Ящик с усами ежедневных цен для пяти сортов овощей.
3.2. VPF-MoE
Мы предлагаем новый подход к прогнозированию цен на овощи, VPF-MoE, использующий MoE для интеграции передовых больших языковых моделей и методов глубокого обучения, доказавших свою эффективность в прогнозировании временных рядов. Архитектура VPF-MoE проиллюстрирована на Рисунке 3. Процесс обучения и процесс применения показаны как Рисунок 3A и Рисунок 3B соответственно.
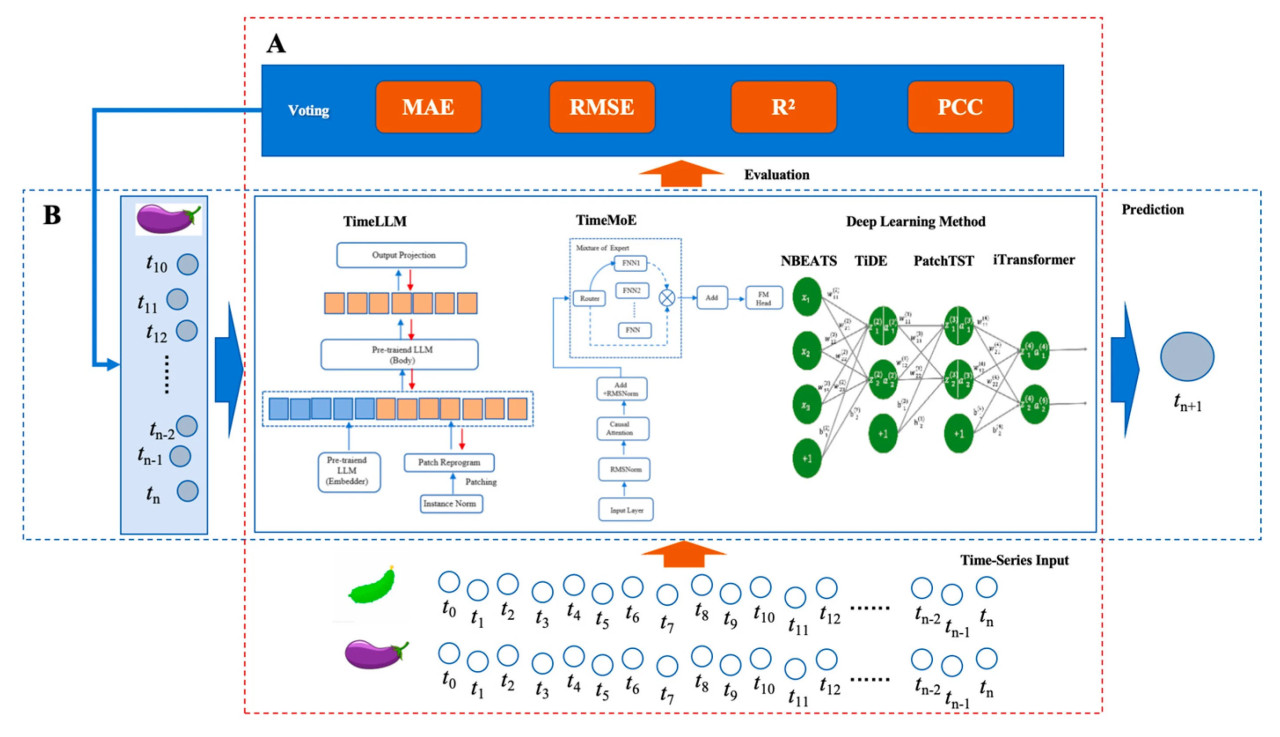
Рисунок 3. Иллюстрация алгоритмических фреймворков, используемых в VPF-MoE: (A) процесс обучения; (B) процесс применения.
Конвейер обучения VPF-MoE включает следующие шаги:
1. Выбор модели: Определение современных моделей с высокой производительностью в прогнозировании временных рядов, включая большие языковые модели, такие как TimeMoE и Time-LLM, и подходы глубокого обучения, такие как N-BEATS, TiDE, PatchTST и iTransformer.
2. Обучение и оценка: Обучение всех выбранных моделей на разнообразных наборах данных о ценах на овощи. Вычисление метрик производительности, включая среднюю абсолютную ошибку (MAE), среднеквадратическую ошибку (RMSE), коэффициент детерминации (R2) и коэффициент корреляции Пирсона (PCC), для оценки.
3. Механизм голосования: Использование алгоритма голосования для определения лучшей модели для каждого овоща на основе вычисленных метрик. Выбранная модель вместе с ее оптимальными параметрами должна быть записана в список сопоставления овощей, моделей и параметров для последующего использования.
Для данной статьи мы сравнили производительность традиционных методов прогнозирования временных рядов, методов глубокого обучения и больших языковых моделей на данных временных рядов цен пяти овощей. Традиционные методы включали SARIMA, в то время как подходы глубокого обучения состояли из N-BEATS, TiDE, PatchTST и iTransformer. Большие языковые модели включали Time-LLM и TimeMoE. Набор данных был разделен на обучающий набор (80% данных) и тестовый набор (оставшиеся 20%).
1. Традиционная модель прогнозирования временных рядов
Модель SARIMA расширяет классическую модель ARIMA, включая сезонные вариации. Она сочетает как сезонные, так и несезонные операции авторегрессии (AR), дифференцирования (I) и скользящего среднего (MA), эффективно удаляя долгосрочные тренды и сезонные колебания из данных, делая тем самым временной ряд стационарным. В частности, сезонное дифференцирование (SI) используется для устранения влияния сезонных трендов, в то время как несезонное дифференцирование удаляет долгосрочные тренды. Кроме того, компоненты авторегрессии и скользящего среднего позволяют модели захватывать краткосрочные зависимости и случайные колебания. Представленная как SARIMA(p, q, d)(P, Q, D)[s], параметры включают следующее:
• p, q, d обозначают несезонный порядок авторегрессии, порядок скользящего среднего и порядок дифференцирования соответственно;
• P, Q, D обозначают сезонный порядок авторегрессии, скользящего среднего и дифференцирования соответственно;
• s обозначает сезонный период.
Процесс моделирования SARIMA включает три основных этапа: стационаризация данных, определение параметров и установление модели. Информационный критерий Акаике (AIC) использовался для выбора оптимальной комбинации параметров, а тест Льюнга – Бокса применялся для проверки адекватности модели. В Таблице 3 приведены оптимальные параметры SARIMA, определенные для каждого сорта овощей.
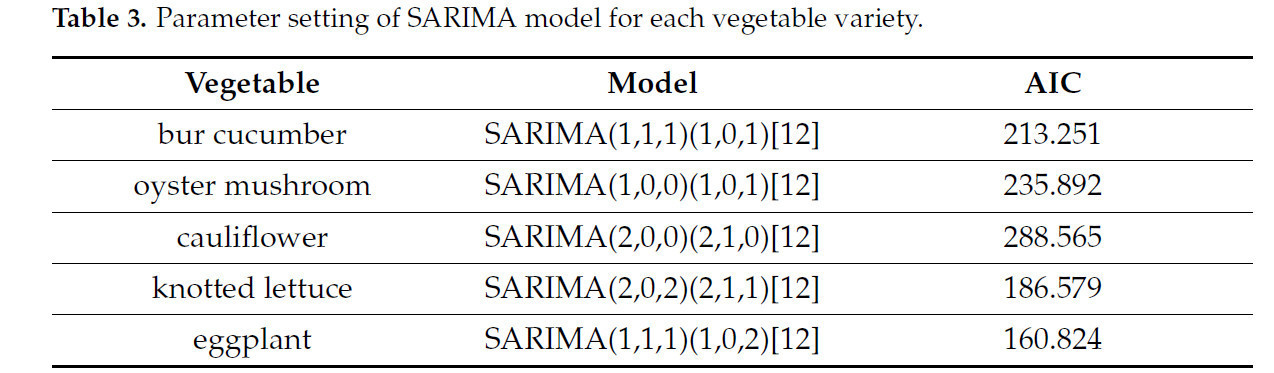
Таблица 3. Установка параметров модели SARIMA для каждого сорта овощей.
2. Методы глубокого обучения для прогнозирования временных рядов
• N-BEATS [33]: Нейронный анализ базисного разложения для модели прогнозирования временных рядов, построенный на фреймворке многослойного перцептрона (MLP). Он складывает прогностические модули, состоящие из полносвязных слоев, и включает две остаточные ветви для анализа исторических данных и прогнозирования будущих цен;
• TiDE [34]: Эта модель представляет собой плотный энкодер временных рядов, основанный на архитектуре энкодер–декодер. Энкодер захватывает внутренние закономерности данных, в то время как декодер предсказывает будущие временные шаги на основе закодированных представлений временных рядов;
• PatchTST [35]: Эта модель на основе Transformer, которая вводит техники сегментации на патчи (patch segmentation) и независимых каналов для эффективного извлечения локальной информации из данных временных рядов. Она поддерживает более быстрое обучение и более длинные входные окна;
• iTransformer [36]: Это инвертированная модель Transformer, в которой функциональность механизма внимания и прямых нейронных сетей обращена. Прямая нейронная сеть фокусируется на кодировании последовательностей и изучении признаков, в то время как модуль внимания захватывает корреляции между переменными.
Процесс обучения использовал среднеквадратическую ошибку (MSE) в качестве функции потерь и использовал фреймворк Ray Tune для оптимизации гиперпараметров. Ray Tune выполняет интеллектуальный поиск в пределах определенного пользователем пространства гиперпараметров с использованием байесовской оптимизации [37]. Количество испытаний сэмплирования было установлено равным 10. Гиперпараметры, настраиваемые в процессе оптимизации, включали размер пакета (batch size), скорость обучения и количество шагов обучения. Конкретно, `batch_size` относится к количеству образцов данных, используемых в каждой итерации обучения, при этом меньшие размеры пакетов потенциально могут ускорить процесс обучения. Скорость обучения контролирует размер шага обновления параметров в алгоритме оптимизации; если скорость обучения слишком велика, модель может не сойтись во время обучения. Установка соответствующего диапазона поиска для скорости обучения может удовлетворить различные потребности обучения. `max_steps` определяет количество итераций для обучения модели. Кроме того, существуют специфические для модели параметры, такие как параметр `patch_len` в PatchTST, который позволяет модели захватывать сегменты временных рядов разной длины. Параметры `num_encoder_layers` и `decoder_output_dim` определяют количество слоев энкодера и размерность выхода декодера соответственно. Эти параметры значительно влияют на производительность и выразительную способность модели (Таблица 4).

Таблица 4. Типы гиперпараметров и их пространства поиска.
3. Большие языковые модели для прогнозирования временных рядов
• Time-LLM [38]: Эта модель представляет собой фреймворк перепрограммирования для кросс-модального выравнивания между временными рядами на входе и текстовыми языковыми моделями. Добавляя описания наборов данных в качестве промптов к представлениям временных рядов, модель адаптируется к разнообразным задачам прогнозирования без необходимости модификации самой большой языковой модели;
• TimeMoE [39]: Это базовая модель прогнозирования временных рядов, основанная на архитектуре только энкодера, использующая передовые большие языковые модели для достижения превосходной производительности в захвате сложных нелинейных взаимосвязей и долгосрочных зависимостей в данных о ценах на овощи. Она использует дизайн слоя «смеси экспертов» с разреженной активацией (sparse-activated MoE), который активирует только подмножество узлов сети во время задач прогнозирования для повышения вычислительной эффективности. TimeMoE состоит из трех ключевых компонентов: встраивание входных токенов, MoE-модули и прогнозирование с множественным разрешением. Она построена на фреймворке Transformer только с декодером, используя RMSNorm для нормализации входных данных каждого подслоя, в то время как применяются ротационные позиционные кодировки вместо абсолютных позиционных кодировок. Во время обучения модель оптимизирует головы прогнозирования с множественным разрешением для улучшения обобщающей способности. Поскольку доказано, что техника дообучения (fine-tuning) способна оптимизировать производительность TimeMoE, мы использовали эту технологию для создания модели TimeMoE-tf, которая использовалась в последующих экспериментах.
При использовании больших моделей для прогнозирования цен на овощи обычно нормализуют данные временных рядов, чтобы уменьшить влияние разницы в масштабах. Мы применили метод нормализации среднего и стандартного отклонения, преобразовав данные временных рядов в форму с нулевым средним и единичным стандартным отклонением. Кроме того, для модели Time-LLM мы разработали префикс промпта, подходящий для набора данных о ценах на овощи. Конкретное содержание промпта: «Набор данных содержит данные о ежемесячных/еженедельных/ежедневных ценах на сельскохозяйственную продукцию. Наблюдается годовая сезонность». Этот промпт был предназначен для предоставления модели фоновой информации о данных на разных временных масштабах, помогая ей лучше обрабатывать и выводить временные закономерности в данных временных рядов.
3.3. Метрики оценки
Четыре метрики оценки использовались для оценки производительности модели: средняя абсолютная ошибка (MAE) [40], среднеквадратическая ошибка (RMSE) [41], R2 и коэффициент корреляции Пирсона (PCC). Метрики вычислялись следующим образом:
MAE отражает среднее абсолютное отклонение между прогнозами и фактическими значениями, обеспечивая надежную оценку ошибки, менее чувствительную к выбросам. n относится к общему количеству временных точек, а yi и ŷi обозначают наблюдаемое и прогнозируемое значение для i-го образца соответственно.
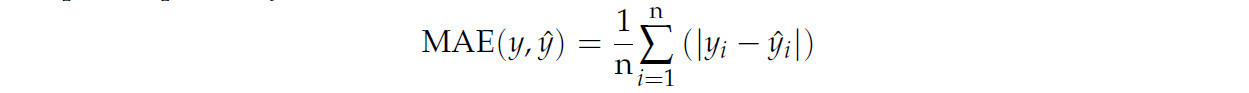
RMSE — это квадратный корень из MSE, широко используемая метрика для измерения средней квадратичной разницы между прогнозируемыми и фактическими значениями. Она присваивает большие веса большим ошибкам и фокусируется на стабильности прогнозирования, где более низкое значение RMSE соответствует более высокой точности. n относится к общему количеству временных точек, yi обозначает прогнозируемую цену для i-й временной точки, а ŷi представляет наблюдаемую цену для i-й временной точки.
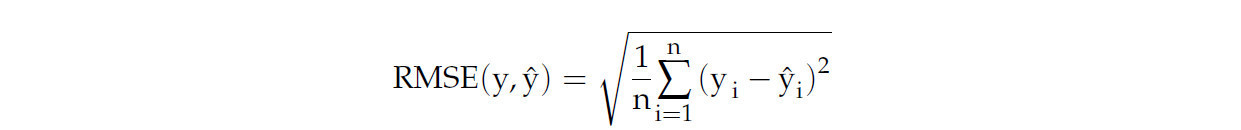
R2 измеряет долю дисперсии зависимой переменной, предсказуемую из независимых переменных в регрессионной модели. Она показывает, насколько хорошо модель объясняет изменчивость цен на овощи с течением времени. Более высокое значение R2 указывает, что модель захватывает больше ценовых трендов и сезонности, делая ее надежным инструментом для прогнозирования и принятия решений на сельскохозяйственных рынках. yi и ŷi обозначают наблюдаемое и прогнозируемое значение для i-го образца соответственно, а ȳ представляет среднее наблюдаемых значений.
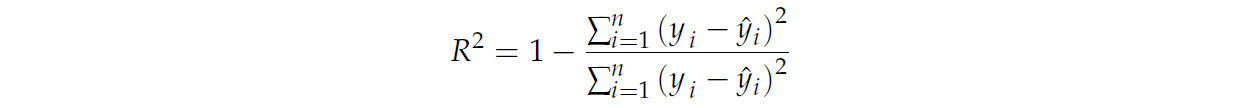
Коэффициент корреляции Пирсона количественно определяет силу и направление линейной связи между прогнозируемыми и фактическими значениями. Он находится в диапазоне от -1 до 1, где более высокое значение соответствует более высокой точности. Эта метрика обычно используется для оценки прогностической точности модели регрессионного прогноза. n относится к общему количеству временных точек, yi и ŷi обозначают наблюдаемое и прогнозируемое значение для i-го образца соответственно, а ȳ и ŷ̅ представляют среднее наблюдаемых и прогнозируемых значений соответственно.
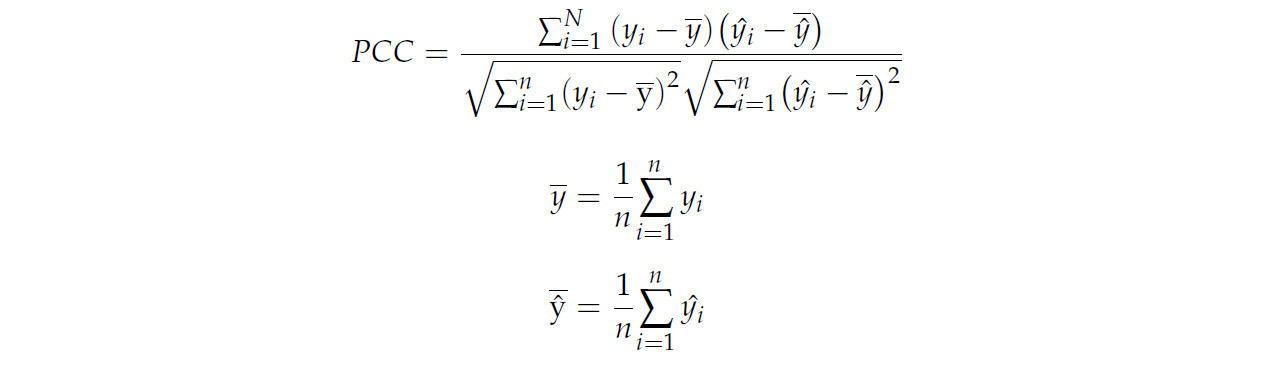
4. Результаты
4.1. Сравнение существующих методов в прогнозировании ежемесячных цен на овощи
В этом разделе представлен сравнительный анализ методов прогнозирования ежемесячных цен на овощи, исследующий их производительность для различных типов овощей. Оценка охватывает традиционные статистические модели, такие как SARIMA, передовые методы глубокого обучения и большие языковые модели (LLM). Результаты освещают сильные и слабые стороны каждого подхода с акцентом на ключевые метрики, такие как средняя абсолютная ошибка (MAE) и среднеквадратическая ошибка (RMSE).
Из Рисунка 4A видно, что прогностическая производительность различных методов варьируется в зависимости от типа овощей. Общая производительность SARIMA относительно низкая, особенно для овощей с высокой ценовой волатильностью, таких как корнишон и цветная капуста, где она демонстрирует более высокие ошибки. Что касается методов глубокого обучения, модели, такие как N-BEATS и TiDE, обычно превосходят SARIMA для большинства типов овощей. Однако они демонстрируют более высокие ошибки в некоторых случаях, например, для кочанного салата. Для LLM, TimeMoE-ft демонстрирует наилучшую производительность для нескольких типов овощей, особенно для корнишона и баклажана, достигая среднего сокращения приблизительно на 14% в MAE по сравнению с традиционными методами. Это указывает на его сильную способность захватывать сложные нелинейные взаимосвязи. Time-LLM показывает немного худшие результаты, чем TimeMoE-ft, в некоторых случаях, например, для цветной капусты.
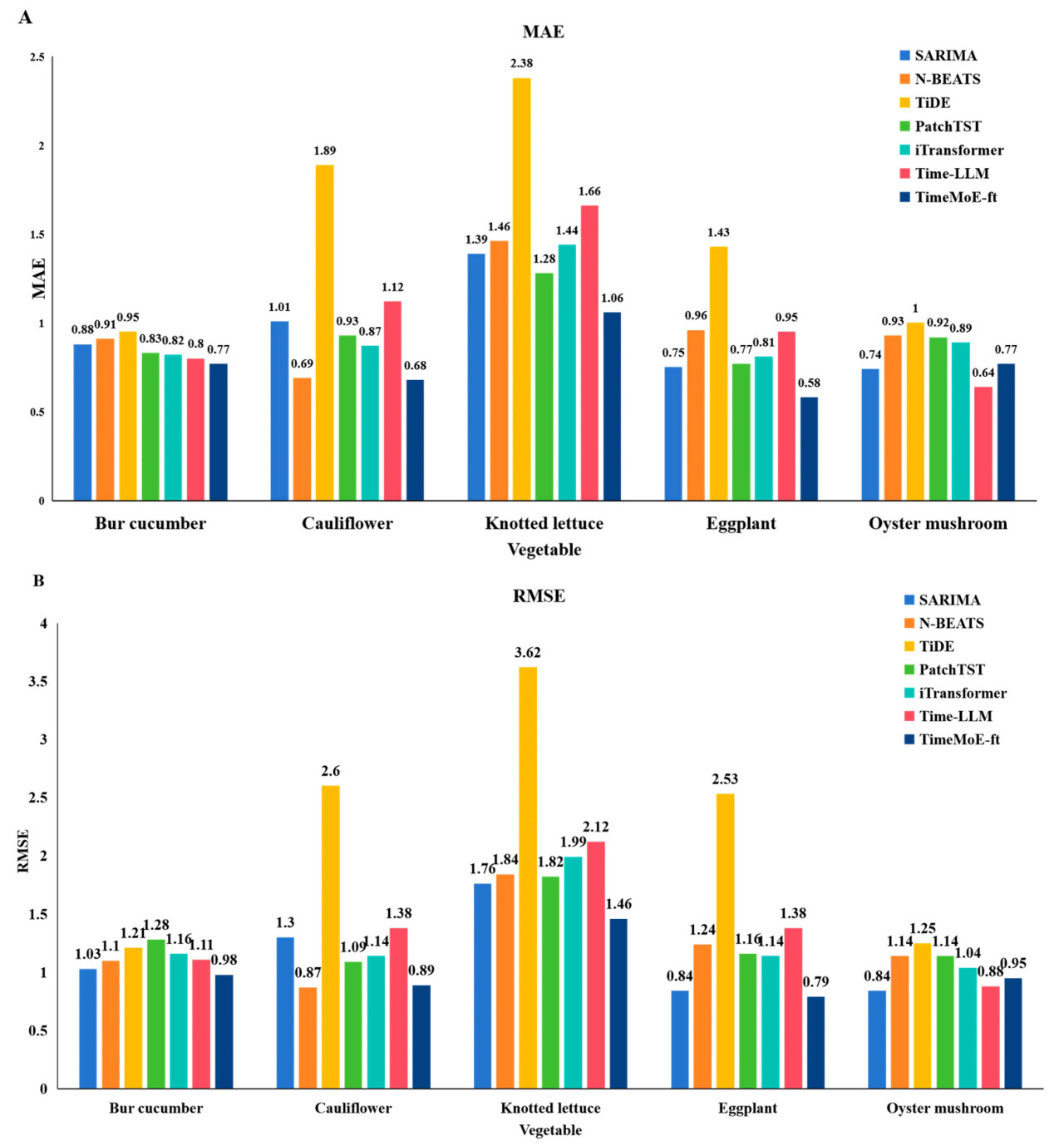
Рисунок 4. Сравнение существующих методов в прогнозировании ежемесячных цен на овощи с использованием MAE и RMSE в качестве метрик: (A) MAE; (B) RMSE.
Из Рисунка 4B можно сделать следующие наблюдения. SARIMA демонстрирует самые высокие значения RMSE для всех типов овощей, что указывает на низкую производительность, когда большие веса присваиваются большим ошибкам прогнозирования. Методы глубокого обучения, такие как PatchTST и iTransformer, хорошо справляются с прогнозированием цен на цветную капусту и кочанный салат. Однако их производительность менее удовлетворительна для некоторых типов, таких как баклажан. TimeMoE-ft продолжает превосходить по метрике RMSE, особенно для корнишона и баклажана. Хотя стабильность Time-LLM немного ниже, она все же превосходит традиционные методы и некоторые методы глубокого обучения в целом.
Из Рисунка 5 видно, что прогностическая производительность различных методов значительно варьируется в зависимости от типа овощей. Традиционный метод SARIMA демонстрирует низкие значения R2 для большинства типов овощей и даже отрицательные значения для некоторых (например, корнишона и цветной капусты), что указывает на плохую подгонку (fitting). Это подчеркивает их ограничения в моделировании сложных ценовых колебаний и нелинейных трендов. Методы глубокого обучения, такие как PatchTST, N-BEATS и iTransformer демонстрируют более высокие значения R2 для большинства овощей, таких как кочанный салат и цветная капуста, указывая на сильные возможности подгонки. Однако их производительность колеблется для некоторых овощей, таких как корнишон и баклажан. В частности, PatchTST и TiDE показывают нестабильность в некоторых случаях. Среди всех методов TimeMoE-ft показывает наилучшую общую производительность. Он достигает значительно более высоких значений R2, особенно для корнишона и баклажана, демонстрируя свое превосходство в способности захватывать сложные нелинейные взаимосвязи. Time-LLM работает немного хуже, чем TimeMoE-ft, но все же превосходит традиционные методы и некоторые модели глубокого обучения для некоторых овощей, таких как цветная капуста.
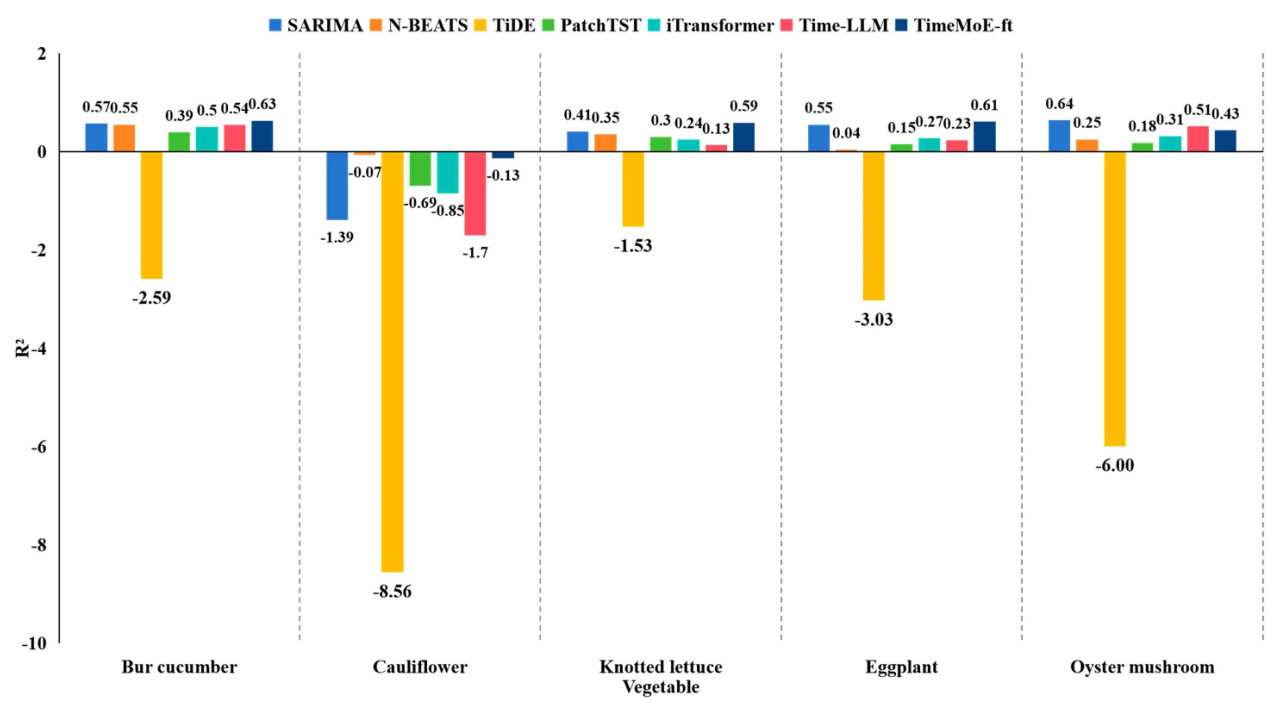
Рисунок 5. Сравнение существующих методов в прогнозировании ежемесячных цен на овощи с использованием R2 в качестве метрики.
Как показано на Рисунке 6, значения PCC метода глубокого обучения TiDE относительно низки для большинства сортов овощей. Традиционный метод SARIMA демонстрирует отличную производительность в прогнозировании кочанного салата и вешенки. В то же время большая языковая модель TimeMoE-ft достигает наилучшей общей производительности, но уступает SARIMA для вешенки.
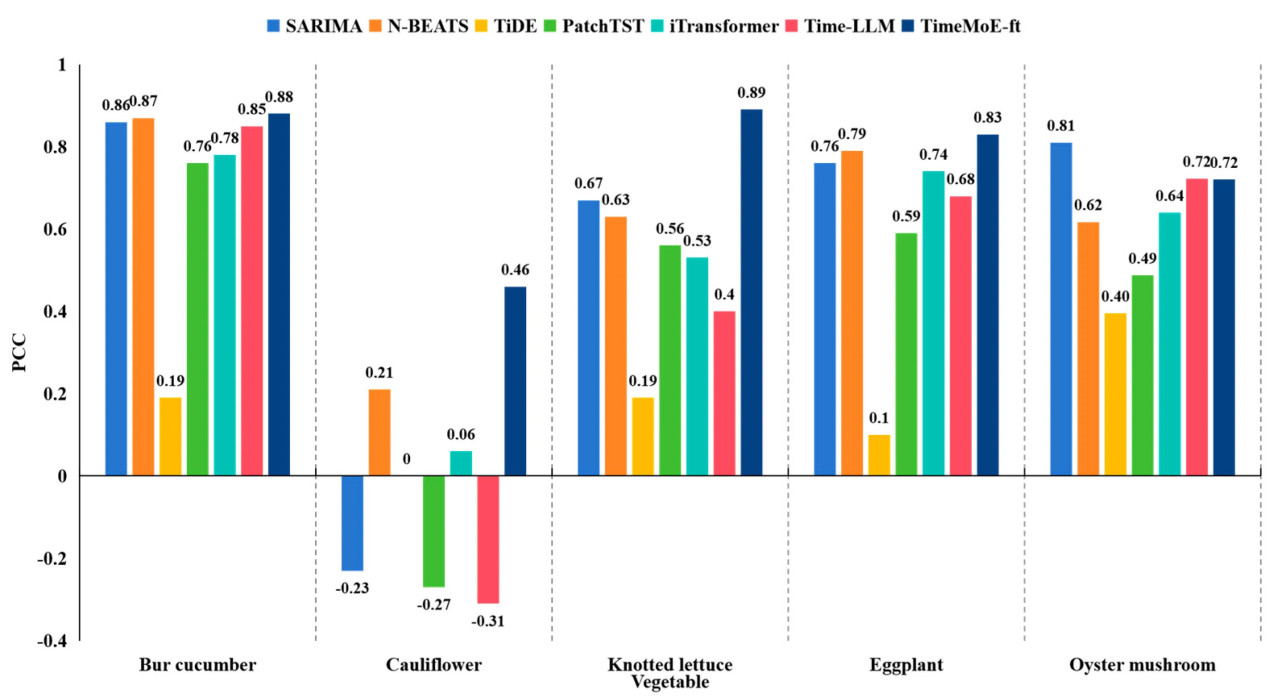
Рисунок 6. Сравнение существующих методов в прогнозировании ежемесячных цен на овощи с использованием коэффициента корреляции Пирсона в качестве метрики.
Из приведенного выше анализа можно сделать вывод, что прогностическая производительность различных методов варьируется в зависимости от типа овощей. Например, SARIMA показывает достаточно хорошие результаты для овощей с относительно стабильными ценовыми трендами, таких как кочанный салат, но испытывает трудности с более сложными закономерностями. Напротив, методы глубокого обучения и большие языковые модели демонстрируют значительные преимущества в захвате замысловатых закономерностей, однако их производительность может колебаться для определенных типов овощей.
Для повышения общей точности прогнозирования цен на овощи введение ансамблевой модели VPF-MoE является необходимым. Интегрируя несколько методов и динамически выбирая оптимальную модель для каждой задачи прогнозирования, VPF-MoE может лучше адаптироваться к уникальным характеристикам различных наборов данных о ценах на овощи. В конечном итоге этот подход обеспечивает более точные и надежные ценовые прогнозы.
4.2. Сравнение VPF-MoE с TimeMoE-ft в прогнозировании цен на овощи с разными временными масштабами
Поскольку TimeMoE-ft показывает наилучшие результаты в прогнозировании ежемесячных цен на овощи, была проанализирована его производительность на разных временных масштабах прогнозирования. Рисунок 7 иллюстрирует производительность модели TimeMoE-ft на разных овощах на трех временных масштабах прогнозирования (день, неделя и месяц) с использованием MAE в качестве метрики оценки. TimeMoE-ft достигает наилучшей производительности для прогнозирования ежемесячных цен на овощи, что указывается самыми низкими значениями MAE в большинстве случаев. Например, ежемесячные значения MAE для цветной капусты и кочанного салата (0.31 и 0.54 соответственно) значительно ниже, чем для ежедневных и еженедельных прогнозов, подчеркивая способность модели эффективно захватывать долгосрочные тренды. Еженедельные прогнозы демонстрируют умеренную производительность, со значениями MAE, как правило, ниже, чем для ежедневных прогнозов, но выше, чем для ежемесячных. Например, ежемесячные значения MAE для корнишона и вешенки составляют 0.77 и 0.68 соответственно. Напротив, TimeMoE-ft демонстрирует самые высокие значения MAE в ежедневных прогнозах цен, указывая на более низкую точность в захвате краткосрочных колебаний. Например, MAE для ежедневных прогнозов составляет 1.28 для корнишона и 1.18 для вешенки. Эти результаты предполагают, что TimeMoE-ft преуспевает в моделировании долгосрочных зависимостей и трендов, но испытывает трудности с нерегулярной и волатильной природой краткосрочных ценовых колебаний. Это подчеркивает необходимость потенциальных улучшений или гибридных подходов для повышения точности краткосрочного прогнозирования.
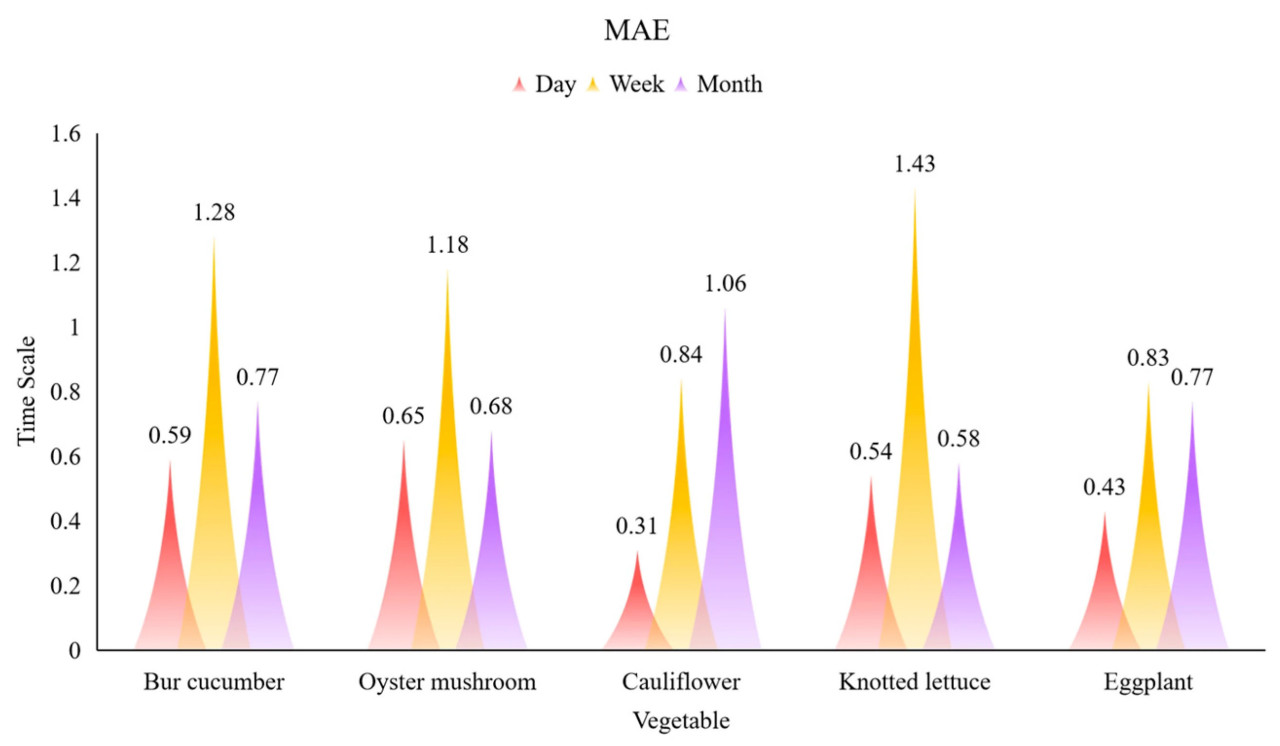
Рисунок 7. Сравнение TimeMoE-ft в прогнозировании цен на овощи с разными временными масштабами с использованием MAE в качестве метрики.
4.3. Сравнение VPF-MoE с TimeMoE и TimeMoE-ft в прогнозировании ежемесячных цен на овощи
В данном исследовании был проведен поисковый анализ влияния техник дообучения (fine-tuning) на модель TimeMoE. В экспериментах использовался оптимизатор Adam с размером пакета 64 и начальной скоростью обучения 5 × 10⁻⁵. Планировщик косинусного затухания (cosine annealing scheduler) использовался для динамической настройки скорости обучения, оптимизируя тем самым весь процесс обучения. Прогностические результаты представлены на Рисунке 8.
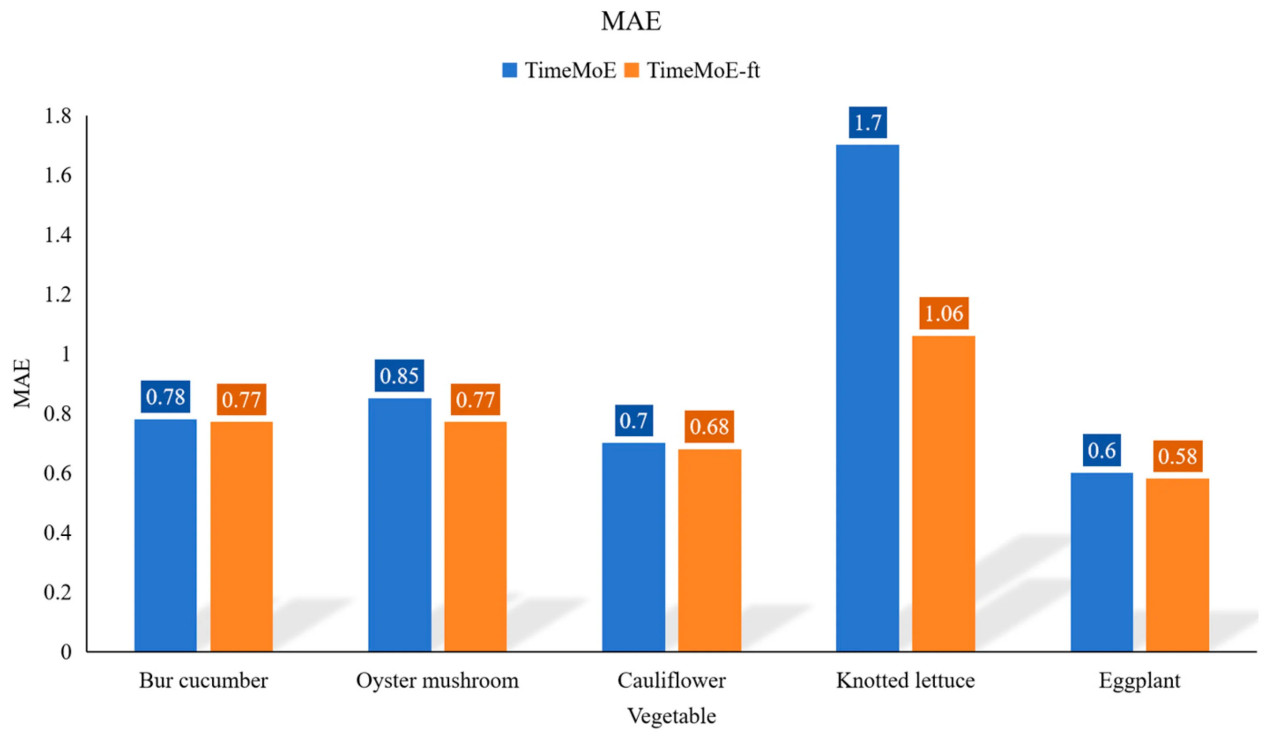
Рисунок 8. Сравнение VPF-MoE с TimeMoE и TimeMoE-ft в прогнозировании ежемесячных цен на овощи с использованием MAE в качестве метрики.
Сравнение показывает, что модель TimeMoE после дообучения на небольшом наборе образцов продемонстрировала улучшенную прогностическую производительность для всех сортов овощей. Наиболее значительное улучшение наблюдалось для кочанного салата, где значение MAE существенно упало с 1.70 до 1.06. Это показало, что дообучение значительно улучшило способность TimeMoE точно прогнозировать цены на овощи, подчеркивая оптимизирующий эффект дообучения на TimeMoE.
4.4. Методы, используемые в VPF-MoE для прогнозирования цен на овощи с разными временными масштабами
Мы провели статистический анализ оптимальных методов, используемых VPF-MoE для разных овощей на ежедневных, еженедельных и ежемесячных масштабах прогнозирования, как показано на Рисунке 9. На рисунке показано распределение выбранных методов для каждого масштаба прогнозирования, причем темные квадраты представляют модели, которые были выбраны на основе критериев оценки VPF-MoE как лучшие исполнители для конкретных задач прогнозирования овощей. Это иллюстрирует адаптивность выбранных моделей к различным распределениям данных и сценариям прогнозирования. Рисунок демонстрирует, что для ежедневного прогнозирования цен на овощи часто выбирается метод глубокого обучения PatchTST, в то время как большая языковая модель TimeMoE-ft чаще выбирается для ежемесячного прогнозирования цен на овощи. Для еженедельного прогнозирования цен на овощи используемые методы более разнообразны. Это дополнительно иллюстрирует, что разные методы демонстрируют различные характеристики производительности при прогнозировании цен на овощи, подчеркивая необходимость подхода VPF-MoE.
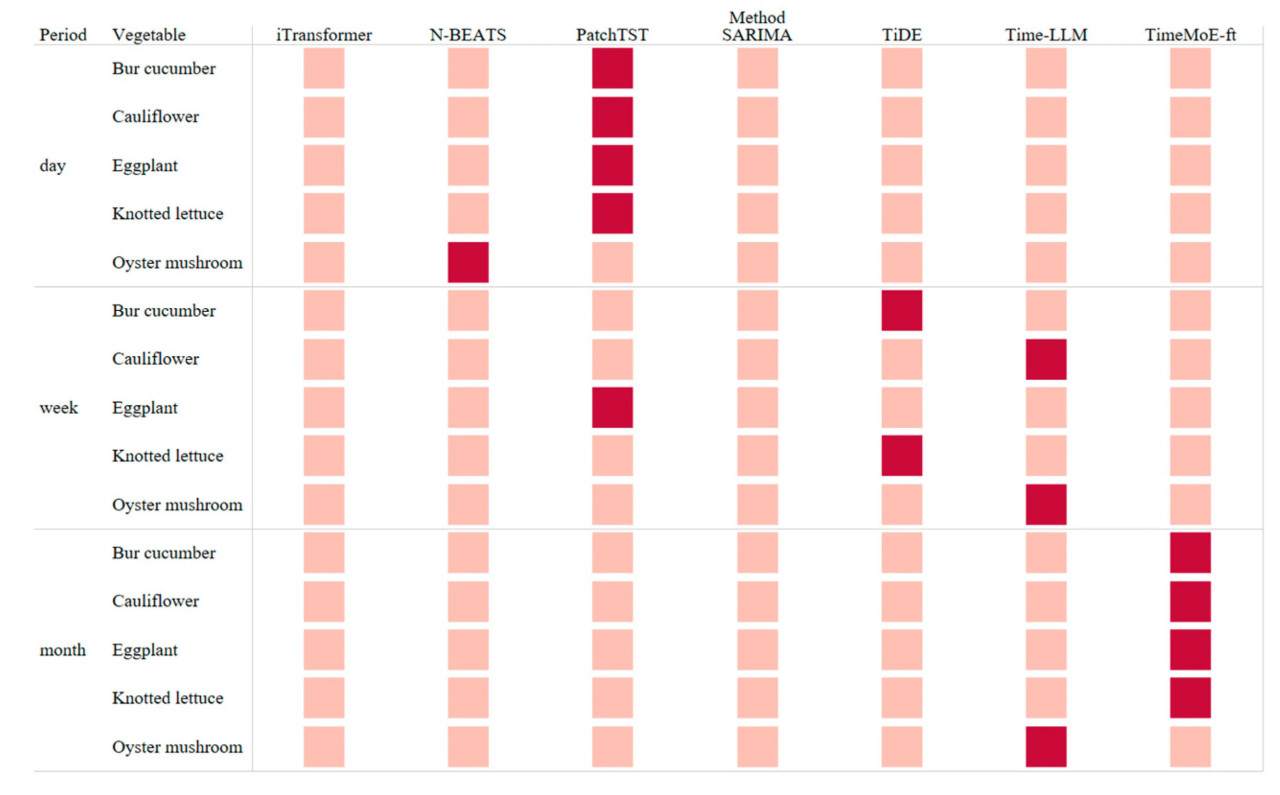
Рисунок 9. Методы, используемые в VPF-MoE для прогнозирования цен на овощи разных периодов.
4.5. Анализ соответствия VPF-MoE различным методам прогнозирования
Рисунок 10A–E представляет сравнение фактических цен и прогнозируемых цен с помощью оптимальной модели, выбранной с использованием VPF-MoE, на тестовом наборе для пяти различных сортов овощей. Каждый подграфик представляет один тип овощей, при этом серая линия представляет фактические данные о ценах, а красная линия представляет прогнозируемые данные о ценах. Из рисунка видно, что прогнозируемые ценовые тенденции для пяти сортов овощей близко соответствуют фактическим рыночным тенденциям. Модель эффективно захватывает ценовые колебания; однако в месяцы с более значительной ценовой волатильностью наблюдаются некоторые отклонения прогноза. В большинстве прогнозов по овощам метод большой языковой модели TimeMoE-ft показывает хорошие результаты, но в случае с вешенкой его производительность относительно средняя. Для дальнейшего анализа мы изучили точность прогнозирования всех методов по отношению к фактическим ценам, как показано на Рисунке 10E. Результаты выявляют значительное расхождение между прогнозируемыми и фактическими ценами, указывая, что текущие модели еще не полностью захватили закономерности и тенденции, присущие кривой цен на вешенку. Кроме того, в прогнозировании цен на кочанный салат мы сравнили соответствие прогноза TimeMoE до и после дообучения и обнаружили, что дообучение значительно улучшило способность TimeMoE лучше соответствовать фактической ценовой кривой, подчеркивая оптимизирующий эффект дообучения на TimeMoE.
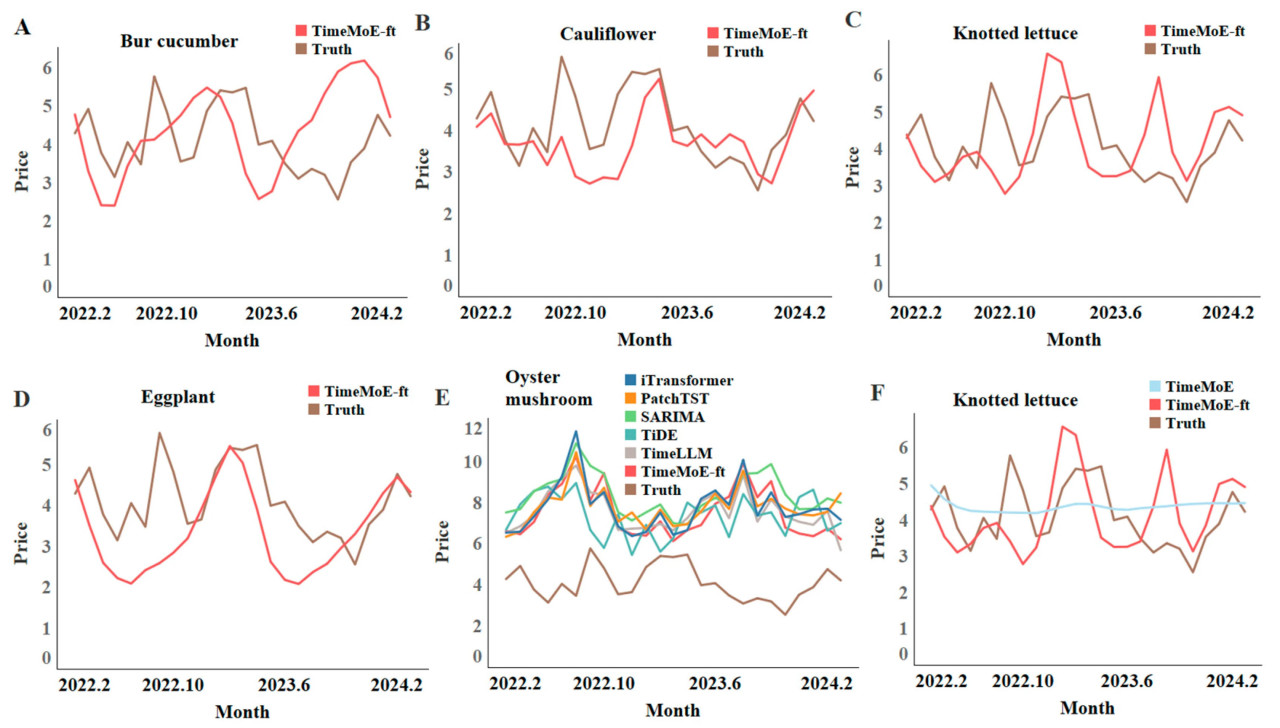
Рисунок 10. Анализ соответствия VPF-MoE для разных овощей: (A) корнишон; (B) цветная капуста; (C) кочанный салат; (D) баклажан; (E) вешенка; (F) кочанный салат.
5. Обсуждение
В данном исследовании мы выполнили ежедневные, еженедельные и ежемесячные прогнозы цен для пяти различных сортов овощей. Предыдущие исследования показали, что традиционные методы прогнозирования временных рядов, такие как ARIMA и SARIMA, часто демонстрируют плохую производительность при работе с длинными временными рядами [42,43]. Эти модели, полагающиеся на линейные предположения и фиксированные сезонные закономерности, как правило, имеют более высокие значения ошибок при столкновении со значительными нелинейными колебаниями и сложными закономерностями. Данное исследование дополнительно подтверждает это наблюдение. Например, подгонка SARIMA значительно хуже для корнишона и цветной капусты, где ценовая волатильность более выражена. Напротив, методы глубокого обучения, со своей способностью моделировать нелинейность и эффективно обрабатывать данные различных масштабов, значительно улучшают прогнозирование сложных ценовых колебаний овощей. Однако производительность этих методов может колебаться из-за характеристик данных и различий в сценариях, в то время как их высокая сложность может привести к более высоким вычислительным затратам и рискам переобучения. Кроме того, мы исследовали применение больших языковых моделей (LLM) в прогнозировании временных рядов, где они показали особые перспективы в прогнозировании долгосрочных трендов.
На этом фоне метод VPF-MoE, предложенный в данном исследовании, интегрирует преимущества различных моделей прогнозирования путем динамического выбора оптимальной модели для обработки данных о ценах разных типов овощей. Существующие исследования предполагают, что единые модели часто сталкиваются с ограничениями при решении разнообразных сценариев данных. Более того, предыдущие ансамблевые методы в основном основаны на фреймворках анализа временных рядов, что затрудняет полное использование сложных характеристик данных. В отличие от этого, данное исследование оптимизирует результаты ансамблевого прогнозирования с точки зрения глубокого обучения [44,45,46]. Сравнительные результаты демонстрируют, что VPF-MoE показывает наилучшую общую производительность по ежедневным, еженедельным и ежемесячным временным масштабам, эффективно балансируя точность прогнозирования и вычислительную эффективность.
Прогнозирование цен на овощи на разных временных масштабах имеет значительную практическую ценность и может предоставить ключевые идеи для различных этапов посадки, сбора урожая и рыночного предложения. Ежемесячные прогнозы цен помогают фермерам рационально планировать графики посадки и выбирать оптимальное время посадки, тем самым повышая производственную эффективность и максимизируя экономическую выгоду. Более детальные ежедневные и еженедельные прогнозы предоставляют точную поддержку для определения лучшего времени сбора урожая и разработки стратегий рыночного предложения, способствуя улучшению управления цепочками поставок и принятия решений. По мере того как ресурсы данных продолжают расширяться и аналитические технологии развиваются, прогнозирование цен на овощи представит еще большие перспективы применения. Внедрение наборов данных большего масштаба и многомерных данных повысит точность и надежность прогнозов.
6. Выводы
В данной статье исследуется применение технологии LLM в прогнозировании цен на овощи путем анализа данных временных рядов цен для нескольких сортов овощей и оцениваются различия в прогностической производительности по сравнению с традиционными методами и методами глубокого обучения на примере пяти сортов овощей, таких как корнишон и баклажан. Результаты указывают, что подходы на основе LLM превосходят по нескольким метрикам в большинстве случаев, подтверждая их широкую применимость и потенциал в областях прогнозирования цен на овощи. Однако прогностическая производительность больших моделей временных рядов все еще имеет потенциал для улучшения, что может быть решено путем оптимизации архитектуры модели и методов обучения в будущем. Это будет в центре нашего текущего исследования.
Затем, на основе этого анализа, мы предлагаем метод прогнозирования овощей VPF-MoE на основе MoE, сочетая способность эффективно захватывать сложные нелинейные взаимосвязи и долгосрочные зависимости в данных временных рядов LLM и методов глубокого обучения. Предложенный метод преуспевает, когда данные демонстрируют четкие сезонные закономерности, показывая преимущество перед традиционными моделями в прогнозировании в условиях стабильной рыночной конъюнктуры. Однако его производительность имеет тенденцию к снижению в ситуациях сильных ценовых колебаний, таких как вызванные экстремальными погодными явлениями или внезапными изменениями политики.
Это исследование не только предоставляет новую перспективу для прогнозирования цен на овощи, но также предлагает надежный инструмент для лиц, принимающих решения в сельском хозяйстве, чтобы лучше управлять рыночными колебаниями, оптимизировать распределение ресурсов и повышать общую экономическую эффективность. Надеемся, что эта работа вдохновит на дальнейшие успехи в применении больших языковых моделей к прогнозированию сельскохозяйственных цен и послужит ценным справочным материалом для исследователей и практиков в этой области.
Данное исследование также имеет определенные ограничения. Из-за ограничений данных метод VPF-MoE в настоящее время сосредоточен исключительно на одномерном прогнозировании ценовых временных рядов и не учитывает внешние факторы, которые могут влиять на изменения цен, такие как неопределенности сельскохозяйственного производства, шоки спроса и предложения и другие. Будущие исследования могли бы улучшить этот метод путем включения внешних переменных, таких как погодные условия, уровни производства или изменения цепочки поставок. Другое возможное направление улучшения — расширение существующей модели путем моделирования и анализа событий рыночных шоков, чтобы лучше адаптироваться к атипичным ценовым колебаниям. Постоянный прогресс в этих областях, как ожидается, даст более точные и адаптируемые модели прогнозирования, в конечном итоге принося пользу участникам рынка и политикам и способствуя лучшему принятию решений в сельскохозяйственном секторе.
Ссылки
1. Li, X.Y. Analysis and prediction of vegetable price fluctuation factors under the background of Lixinyi rural revitalization. Technol. Ind. 2023, 23, 126–130. [Google Scholar]
2. Cao, Y.; Mohiuddin, M. Sustainable Emerging Country Agro-Food Supply Chains: Fresh Vegetable Price Formation Mechanisms in Rural China. Sustainability 2019, 11, 2814. [Google Scholar] [CrossRef]
3. Meng, X.F.; Shi, H.Y. Review of time series data prediction methods based on Transformer model. Comput. Sci. Explor. 2025, 19, 45–64. [Google Scholar]
4. Wang, Y.; Liang, Z. Financial time series forecasting based on iTransformer model. Ind. Innov. Res. 2024, 24, 122–124. [Google Scholar]
5. Anh, N.T.N.; Anh, N.N.; Thang, T.N.; Solanki, V.K.; Crespo, R.G.; Dat, N.Q. Online SARIMA Applied for Short-Term Electricity Load Forecasting. Appl. Intell. 2024, 54, 1003–1019. [Google Scholar] [CrossRef]
6. Wang, Y.; Wu, H.; Dong, J.; Liu, Y.; Long, M.; Wang, J. Deep Time Series Models: A Comprehensive Survey and Benchmark. arXiv 2024, arXiv:2407.13278. [Google Scholar]
7. Jin, M.; Zhang, Y.; Chen, W.; Zhang, K.; Liang, Y.; Yang, B.; Wang, J.; Pan, S.; Wen, Q. Position: What Can Large Language Models Tell Us about Time Series Analysis. arXiv 2024, arXiv:2402.02713. [Google Scholar]
8. Xiao, X.Y.; Li, C.G. Chinese vegetable price characteristics, problems and countermeasures. Res. Agric. Mod. 2016, 37, 948–955. [Google Scholar] [CrossRef]
9. Beckert, J. Where Do Prices Come from? Sociological Approaches to Price Formation. Socio-Econ. Rev. 2011, 9, 757–786. [Google Scholar] [CrossRef]
10. Gu, Z.; Zhang, Y. Research on factors influencing agricultural prices based on machine learning—Taking oil as an example. Price Theory Pract. 2023, 43, 122–126. [Google Scholar] [CrossRef]
11. Sun, F.; Meng, X.; Zhang, Y.; Wang, Y.; Jiang, H.; Liu, P. Agricultural Product Price Forecasting Methods: A Review. Agriculture 2023, 13, 1671. [Google Scholar] [CrossRef]
12. Agricultural Products Price Prediction Based on Improved RBF Neural Network Model. Available online: https://www.tandfonline.com/doi/full/10.1080/08839514.2023.2204600 (accessed on 23 December 2024).
13. Yang, H.M.; Pan, Z.S.; Bai, W. Review of time series forecasting methods. Comput. Sci. 2019, 46, 21–28. [Google Scholar]
14. KumarMahto, A.; Biswas, R.; Alam, M.A. Short Term Forecasting of Agriculture Commodity Price by Using ARIMA: Based on Indian Market. In Advances in Computing and Data Sciences, Proceedings of the Third International Conference, ICACDS 2019, Ghaziabad, India, 12–13 April 2019; Revised Selected Papers, Part I 3; Springer: Berlin/Heidelberg, Germany, 2019; pp. 452–461. [Google Scholar]
15. Luo, C.S.; Zhou, L.Y.; Wei, Q.F. Application of SARIMA Model in Cucumber Price Forecast. Appl. Mech. Mater. 2013, 373, 1686–1690. [Google Scholar] [CrossRef]
16. Zheng, X.G.; Yang, J.; Qian, T.T.; Xu, Y.Y. SARIMA analysis and forecast of vegetable prices in Shanghai in recent ten years. Shanghai J. Agric. Sci. 2020, 36, 138–141. [Google Scholar] [CrossRef]
17. Chen, Q.; Yu, Z.; Zheng, K. The Price Prediction of Vegetables by Using Machine Learning. Highlights Sci. Eng. Technol. 2024, 85, 1127–1134. [Google Scholar] [CrossRef]
18. Chaitra, B.; Meena, K. Forecasting Crop Price Using Various Approaches of Machine Learning. In Proceedings of the 2023 International Conference on Innovations in Engineering and Technology (ICIET), Muvattupuzha, India, 13–14 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
19. Babu, K.S.; Mallikharjuna Rao, K. Onion Price Prediction Using Machine Learning Approaches. In Proceedings of the International Conference on Computational Intelligence and Data Engineering: ICCIDE 2021, Vijayawada, India, 13–14 August 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 175–189. [Google Scholar]
20. Paul, R.K.; Yeasin, M.; Kumar, P.; Kumar, P.; Balasubramanian, M.; Roy, H.S.; Paul, A.K.; Gupta, A. Machine Learning Techniques for Forecasting Agricultural Prices: A Case of Brinjal in Odisha, India. PLoS ONE 2022, 17, e0270553. [Google Scholar] [CrossRef]
21. Jaiswal, R.; Jha, G.K.; Kumar, R.R.; Choudhary, K. Deep Long Short-Term Memory Based Model for Agricultural Price Forecasting. Neural Comput. Appl. 2022, 34, 4661–4676. [Google Scholar] [CrossRef]
22. Weng, Y.; Wang, X.; Hua, J.; Wang, H.; Kang, M.; Wang, F.-Y. Forecasting Horticultural Products Price Using ARIMA Model and Neural Network Based on a Large-Scale Data Set Collected by Web Crawler. IEEE Trans. Comput. Soc. Syst. 2019, 6, 547–553. [Google Scholar] [CrossRef]
23. Liang, Y.; Wen, H.; Nie, Y.; Jiang, Y.; Jin, M.; Song, D.; Pan, S.; Wen, Q. Foundation Models for Time Series Analysis: A Tutorial and Survey. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25 August 2024; pp. 6555–6565. [Google Scholar]
24. Sari, M.; Duran, S.; Kutlu, H.; Guloglu, B.; Atik, Z. Various Optimized Machine Learning Techniques to Predict Agricultural Commodity Prices. Neural Comput. Appl. 2024, 36, 11439–11459. [Google Scholar] [CrossRef]
25. Rosenblatt, F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
26. Nayak, G.H.; Alam, M.W.; Avinash, G.; Singh, K.N.; Ray, M.; Kumar, R.R. N-BEATS Deep Learning Architecture for Agricultural Commodity Price Forecasting. Potato Res. 2024, 1–21. [Google Scholar] [CrossRef]
27. Karthik, V.C.; Naik, B.S.; Manjunatha, B.; Sujith, A.S.B.; Halesha, P.; Harish Nayak, G.H. Advanced Potato Price Prediction through N-BEATS Deep Learning Architecture. J. Exp. Agric. Int. 2024, 46, 362–375. [Google Scholar] [CrossRef]
28. Vaswani, A. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
29. Jiang, Y.; Pan, Z.; Zhang, X.; Garg, S.; Schneider, A.; Nevmyvaka, Y.; Song, D. Empowering Time Series Analysis with Large Language Models: A Survey. arXiv 2024, arXiv:2402.03182. [Google Scholar]
30. Xue, H.; Salim, F.D. PromptCast: A New Prompt-Based Learning Paradigm for Time Series Forecasting. IEEE Trans. Knowl. Data Eng. 2024, 36, 6851–6864. [Google Scholar] [CrossRef]
31. Rabanser, S.; Januschowski, T.; Flunkert, V.; Salinas, D.; Gasthaus, J. The Effectiveness of Discretization in Forecasting: An Empirical Study on Neural Time Series Models. arXiv 2020, arXiv:2005.10111. [Google Scholar]
32. Wang, Z.; Ji, H. Open Vocabulary Electroencephalography-to-Text Decoding and Zero-Shot Sentiment Classification. Proc. AAAI Conf. Artif. Intell. 2022, 36, 5350–5358. [Google Scholar] [CrossRef]
33. Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural Basis Expansion Analysis for Interpretable Time Series Forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
34. Das, A.; Kong, W.; Leach, A.; Mathur, S.; Sen, R.; Yu, R. Long-Term Forecasting with Tide: Time-Series Dense Encoder. arXiv 2023, arXiv:2304.08424. [Google Scholar]
35. Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series Is Worth 64 Words: Long-Term Forecasting with Transformers. arXiv 2022, arXiv:2211.14730. [Google Scholar]
36. Liu, Y.; Hu, T.; Zhang, H.; Wu, H.; Wang, S.; Ma, L.; Long, M. Itransformer: Inverted Transformers Are Effective for Time Series Forecasting. arXiv 2023, arXiv:2310.06625. [Google Scholar]
37. Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I. Ray: A Distributed Framework for Emerging {AI} Applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 561–577. [Google Scholar]
38. Jin, M.; Wang, S.; Ma, L.; Chu, Z.; Zhang, J.Y.; Shi, X.; Chen, P.-Y.; Liang, Y.; Li, Y.-F.; Pan, S.; et al. Time-Llm: Time Series Forecasting by Reprogramming Large Language Models. arXiv 2024, arXiv:2310.01728. [Google Scholar]
39. Shi, X.; Wang, S.; Nie, Y.; Li, D.; Ye, Z.; Wen, Q.; Jin, M. Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts. arXiv 2024, arXiv:2409.16040. [Google Scholar]
40. De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean Absolute Percentage Error for Regression Models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef]
41. Hodson, T.O. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE): When to Use Them or Not. Geosci. Model Dev. Discuss. 2022, 2022, 1–10. [Google Scholar] [CrossRef]
42. Jadhav, V.; Chinnappa Reddy, B.V.; Gaddi, G.M. Application of ARIMA Model for Forecasting Agricultural Prices. J. Agric. Sci. Technol. 2017, 19, 981–992. [Google Scholar]
43. Yu, R.; Wang, X.; Xu, X.; Zhang, Z. Research on Forecasting Sales of Pure Electric Vehicles in China Based on the Seasonal Autoregressive Integrated Moving Average–Gray Relational Analysis–Support Vector Regression Model. Systems 2024, 12, 486. [Google Scholar] [CrossRef]
44. Lun, R.; Luo, Q.; Gao, M.; Yang, Y. Analysis of China’s potato price forecast based on a combination model. Chin. J. Agric. Resour. Reg. Plan. 2021, 42, 97–108. [Google Scholar]
45. Cao, S.; He, Y. Wavelet decomposition-based SVM-ARIMA price forecasting model for agricultural products. Stat. Decis. 2015, 92–95. Available online: https://link.cnki.net/doi/10.13546/j.cnki.tjyjc.2015.13.025 (accessed on 5 January 2025).
46. Wang, B.; Liu, P.; Chao, Z.; Junmei, W.; Chen, W.; Cao, N.; O’Hare, G.M.; Wen, F. Research on Hybrid Model of Garlic Short-term Price Forecasting based on Big Data. Comput. Mater. Contin. 2018, 57, 283–296. [Google Scholar] [CrossRef]

Zhao C, Wang X, Zhao A, Cui Y, Wang T, Liu J, Hou Y, Wang M, Chen L, Li H, et al. A Vegetable-Price Forecasting Method Based on Mixture of Experts. Agriculture. 2025; 15(2):162. https://doi.org/10.3390/agriculture15020162
Перевод статьи «A Vegetable-Price Forecasting Method Based on Mixture of Experts» авторов Zhao C, Wang X, Zhao A, Cui Y, Wang T, Liu J, Hou Y, Wang M, Chen L, Li H, et al.., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык

















































































































Комментарии (0)