Обнаружение болезней лилейника: простая и точная модель
Hemerocallis fulva, играющий важную роль в городских экосистемах и ландшафтном дизайне, сталкивается с проблемами при обнаружении болезней из-за ограниченности данных и снижения точности на неоднородном фоне. Для решения этих проблем представлены набор данных о болезнях листьев лилейника жёлто-красного (HFLD-Dataset), а также эффективная модель — Hemerocallis fulva Multi-Scale and Enhanced Network (HF-MSENet), которая предназначена для повышения точности обнаружения болезней в разных масштабах и снижения количества пропусков.
Аннотация
Модуль Channel–Spatial Multi-Scale Module (CSMSM) улучшает локализацию и захват ключевых признаков, преодолевая ограничения извлечения многоуровневых признаков, вызванные недостаточным вниманием к характеристикам заболевания. Модуль C3_EMSCP улучшает многоуровневое слияние признаков за счёт комбинации многоуровневых свёрточных ядер и групповой свёртки, повышая адаптивность слияния и взаимодействие между разными масштабами. Для устранения ошибок интерполяции и размытия границ при увеличении разрешения в модуле DySample используется механизм динамической корректировки позиций выборки на основе обучения смещению. Это в сочетании с методами переупорядочивания пикселей и сеточной выборки снижает ошибки интерполяции и сохраняет детали границ. Экспериментальные результаты показывают, что HF-MSENet достигает показателей mAP@50 и mAP%50–95 на уровне 94,9 % и 80,3 % соответственно, превосходя базовую модель на 1,8 % и 6,5 %. По сравнению с другими моделями HF-MSENet демонстрирует значительные преимущества в эффективности и надёжности, обеспечивая надёжную поддержку для точного обнаружения болезней Hemerocallis fulva.
1. Введение
Hemerocallis, многолетнее травянистое растение семейства Асфоделовые [1], распространен преимущественно в умеренных и субтропических регионах Азии [2]. Известный как «король многолетников», Hemerocallis играет ключевую роль в защите экологии благодаря своей хорошо развитой корневой системе, засухоустойчивости и способности укреплять почву и предотвращать эрозию песка [3]. Кроме того, его экстракты содержат флавоноидные соединения с седативным и антидепрессивным действием [4,5,6], и на фоне растущей озабоченности по поводу депрессии и бессонницы в постпандемическую эпоху эта проблема привлекла значительное внимание [7].
Hemerocallis fulva, ценимый за яркие цветы и адаптируемость к различным условиям окружающей среды, широко используется в ландшафтном дизайне и экологической реставрации [8]. Однако масштабное культивирование усилило проблемы с болезнями листьев, повреждая растения и угрожая другой растительности [9]. Это уменьшает его экологические функции, такие как стабилизация почвы и сохранение водных ресурсов, одновременно влияя на городское озеленение и связанные с ним отрасли [10]. Обмен научными знаниями, например, интеграция западной и китайской медицинских практик в Bencao Bu Педро де ла Пиньюэлы, показывает, как разнообразные системы знаний вносят вклад в современные исследования [11]. Эффективные методы исследований и обнаружения необходимы для защиты его экологической и экономической ценности и поддержки устойчивого развития.
Ранние исследования по обнаружению болезней листьев в основном фокусировались на комбинации извлечения признаков изображения с традиционными классификаторами, что привело к значительным достижениям в диагностике заболеваний [12,13]. Например, Махмуд и др. [14] предложили метод обнаружения мучнистой росы клубники с использованием текстурных признаков изображения вместе с классификаторами на основе метода опорных векторов (SVM) и метода k-ближайших соседей (kNN), достигнув точности до 98,33% при различных методах валидации. Се и Хе объединили гиперспектральные изображения с текстурными признаками, используя матрицу совместной встречаемости уровней серого (GLCM), применяя модели kNN и AdaBoost для ранней классификации болезни баклажанов (вертициллёзное увядание), достигнув точности 88,46% [15]. Нашруллах и др. [16] представили метод извлечения текстурных признаков на основе фильтров Габора с классификатором SVM, достигнув специфичности 98,83% и AUC 94,60%. Ахмад и др. [17] объединили текстурные признаки GLCM с классификацией SVM, достигнув точности 98,79% при перекрестной проверке. Ван и др. [18] предложили алгоритм на основе K-средних и цветового пространства Lab для обнаружения болезней листьев пшеницы, достигнув точности 90%. Ву и др. [19] применили гиперспектральную визуализацию, вегетационные индексы и текстурные признаки в сочетании с машинным обучением для раннего обнаружения серой гнили клубники. Сингх и Каур использовали многоклассовый классификатор SVM для обнаружения болезней листьев картофеля, достигнув точности 95,99% [20]. Чжао и др. [21] использовали гиперспектральную визуализацию и анализ главных компонентов (PCA) с классификатором SVM для диагностики черной пятнистости лимонника китайского, достигнув точности 92,77%. Суганья Деви и др. [22] предложили метод H2K, объединяющий детектор углов Харриса, признаки HOG и kNN, достигнув точности 97,67%. Цзиньлин Чжао и др. [23] использовали гиперспектральную визуализацию и SVM для идентификации ржавчины пшеницы, достигнув точности 93,33% после снижения размерности с помощью PCA.
Несмотря на прогресс в извлечении признаков и выборе классификаторов, ранние методы испытывали трудности со сложным фоном и малозаметными признаками болезней. Полагаясь на признаки, разработанные вручную, они часто упускали критические детали при перекрывающихся заболеваниях, что приводило к ложноположительным или ложноотрицательным результатам. Хотя эти методы были эффективны в более простых задачах, они нуждаются в улучшении устойчивости и точности для высокоточного обнаружения болезней.
Недавние достижения в технологиях глубокого обучения значительно продвинули методы обнаружения болезней листьев. По сравнению с традиционными подходами, модели глубокого обучения автоматически извлекают глубинные признаки из крупномасштабных размеченных данных, улучшая точность обнаружения и адаптируемость в различных средах. Махешваран и др. [24] использовали сверточные нейронные сети (CNN) для обнаружения болезней листьев риса, применяя исключение фона на основе значений оттенка для предварительной обработки и извлекая признаки болезней с помощью CNN, достигнув высокой точности классификации. В результате, обнаружение объектов на основе глубокого обучения стало основным направлением, при этом методы в основном делятся на два типа: двухэтапные и одноэтапные алгоритмы. По сравнению с двухэтапными моделями, одноэтапные алгоритмы, такие как SSD и YOLO, используют сквозное прямое предсказание, предлагая более высокую скорость и меньшую вычислительную сложность, что делает их более подходящими для задач обнаружения в реальном времени [25,26,27,28,29,30,31,32,33,34]. Например, Тянь и др. [35] предложили модель VMF-SSD, которая оптимизирует многомасштабное извлечение признаков для улучшения показателей обнаружения мелких пятнистых болезней, достигнув mAP 83,19% на тестовом наборе. Деари Сабри и др. [36] представили гибридную многоэтапную модель, объединяющую YOLO с улучшенной сетью Inception, оптимизирующую локализацию и захват болезней, достигнув точности обнаружения 96,67% на общедоступном наборе данных о болезнях листьев риса. Цзяньлун Ван и др. [37] предложили метод LCGSC-YOLO, включающий модуль GSConv для улучшения адаптивности и способности к взаимодействию при слиянии признаков, достигнув mAP 95,5% на смешанном наборе данных. Кумар В. [38] Сентил и др. представили модель Bi-FAPN, используя двунаправленную сеть внимания с пирамидой признаков (Bi-FAPN) для оптимизации многомасштабного извлечения признаков, достигнув mAP 82,8% на наборе данных RID. Юэлун Хэ и др. [39] представили модель KTD-YOLOv8, которая интегрирует механизм Triplet Attention для улучшения многомасштабного извлечения признаков, что привело к увеличению точности на 2,8% по сравнению с YOLOv8 и улучшению обнаружения болезней листьев клубники. Чжэдун Се и др. [40] предложили модель YOLOv5s-BiPCNeXt, представив многомасштабный механизм кросс-пространственного внимания (ElA) и операции CARAFE для улучшения многомасштабного извлечения признаков и захвата детальной информации. Чжу Шисун и др. [41] представили модель EADD-YOLO, которая оптимизирует извлечение и слияние признаков с помощью ShuffleNet и модуля координатного внимания, достигнув mAP 95,5% на наборе данных о болезнях листьев яблони. Янь Чуньмань и др. [42] предложили модель FSM-YOLO, объединяющую адаптивный модуль улучшения признаков (AFEl) и модуль внимания с учетом пространственного контекста (SCAA), улучшив mAP@50 на 2,7%. Акрам Абдула и др. [43] использовали фреймворк YOLOv8s для оптимизации извлечения признаков, достигнув mAP 92,5% и улучшив точность обнаружения болезней листьев томата. Сюй Вэйши и др. [44] представили модель ALAD-YOLO, включающую MobileNet-V3s и механизм координатного внимания, достигнув улучшения точности на 7,9% по сравнению с YOLOv5s для обнаружения болезней листьев яблони. Банди и др. [45] предложили метод обнаружения болезней листьев и классификации стадий с использованием YOLOv5 и Vision Transformer (ViT), достигнув F1-меры 0,908, одновременно улучшая захват деталей и точность реконструкции за счет удаления фона.
Несмотря на эти достижения, существующие методы по-прежнему сталкиваются с ограничениями в задачах обнаружения болезней на сложном фоне и многомасштабных задач. С одной стороны, большинство исследований были сосредоточены на обнаружении болезней основных культур, таких как яблоки и рис, при этом относительно немногочисленные исследования были проведены на садовых растениях, таких как Hemerocallis fulva. С другой стороны, устойчивость современных моделей к обработке сложного фона и шумовых помех остается недостаточной, особенно при обнаружении мелких поражений, где модели с трудом точно захватывают малозаметные признаки. Кроме того, хотя многомасштабное извлечение признаков и реконструкция детальной информации улучшились, точная локализация границ поражений и слияние признаков все еще требуют дальнейшей оптимизации.
После анализа предыдущих исследований YOLO зарекомендовал себя как эффективная модель для обнаружения болезней листьев. YOLOv8 выделяется своей скоростью и точностью, что делает его основным выбором в этой области. Вдохновленные его производительностью, мы предлагаем модель высокоточного обнаружения объектов для болезни листьев Hemerocallis fulva на сложном фоне, чтобы решить эти проблемы, со следующими вкладами:
- Чтобы решить проблему нехватки данных о болезнях листьев Hemerocallis fulva, был создан набор данных о болезнях листьев Hemerocallis fulva (HFLD-Dataset), охватывающий четыре категории болезней, собранные в центральной части равнины реки Янцзы в Южной Азии (апрель–август 2024 г.), предоставляя всеобъемлющие данные для валидации модели.
- Была разработана улучшенная модель обнаружения объектов — многомасштабная и улучшенная сеть Hemerocallis fulva (HF-MSENet), чтобы повысить точность обнаружения болезней при различных условиях освещения, углах и стадиях роста. Экспериментальные результаты подтверждают ее превосходство над традиционными методами.
- Представлен многомасштабный модуль канально-пространственного внимания (CSMSM) для улучшения способности модели фокусироваться на целевых областях и извлекать из них признаки. Используя двойной механизм канально-пространственного внимания и многомасштабное извлечение признаков, он значительно улучшает захват мелкозернистой информации и обнаружение целевых областей.
- Традиционные методы многомасштабного слияния признаков ограничены плохим взаимодействием информации, что делает их неэффективными при вариациях размера и формы целей. Этапы увеличения разрешения часто вносят ошибки интерполяции, снижая детализацию краев и точность обнаружения. Чтобы решить эти проблемы, модуль C3_EMSCP улучшает многомасштабное слияние признаков с помощью объединенных многомасштабных и групповых сверток. В паре с модулем DySample, который регулирует позиции выборки с использованием динамических смещений, этот подход улучшает реконструкцию деталей, уменьшает ошибки интерполяции и повышает четкость краев за счет переупорядочивания пикселей и сеточной выборки.
2. Материалы и методы
2.1. Построение набора данных и предварительная обработка
2.1.1. Описание района исследования и сбора данных
Набор данных о болезнях листьев Hemerocallis fulva был собран в среднем течении равнины реки Янцзы в Южной Азии, районе, характеризующемся субтропическим муссонным климатом. Этот район отличается теплым и влажным климатом, равнинной местностью и плодородной почвой, что делает его идеальным для роста Hemerocallis fulva. Обилие водных ресурсов и различные микроклиматы обеспечили оптимальные условия для разнообразия образцов болезней. Данные были собраны в трех местах провинции Хунань, Китай: плантация Центрального южного университета лесного хозяйства и технологий (28,132 с.ш., 112,994 в.д.) — 636 изображений; парк Бафанг (28,239 с.ш., 112,944 в.д.) — 1380 изображений; и провинциальный ботанический сад Хунани (28,103 с.ш., 113,032 в.д.) — 339 изображений, всего 2355 изображений. Сбор данных проводился с апреля по август 2024 года, в период быстрого роста Hemerocallis fulva, когда листья полностью распустились, а симптомы болезней были наиболее выражены. Этот период обеспечил репрезентативность данных и предоставил научную основу для профилактики и борьбы с болезнями. Географическое расположение и среда мест сбора набора данных показаны на Рисунке 1.
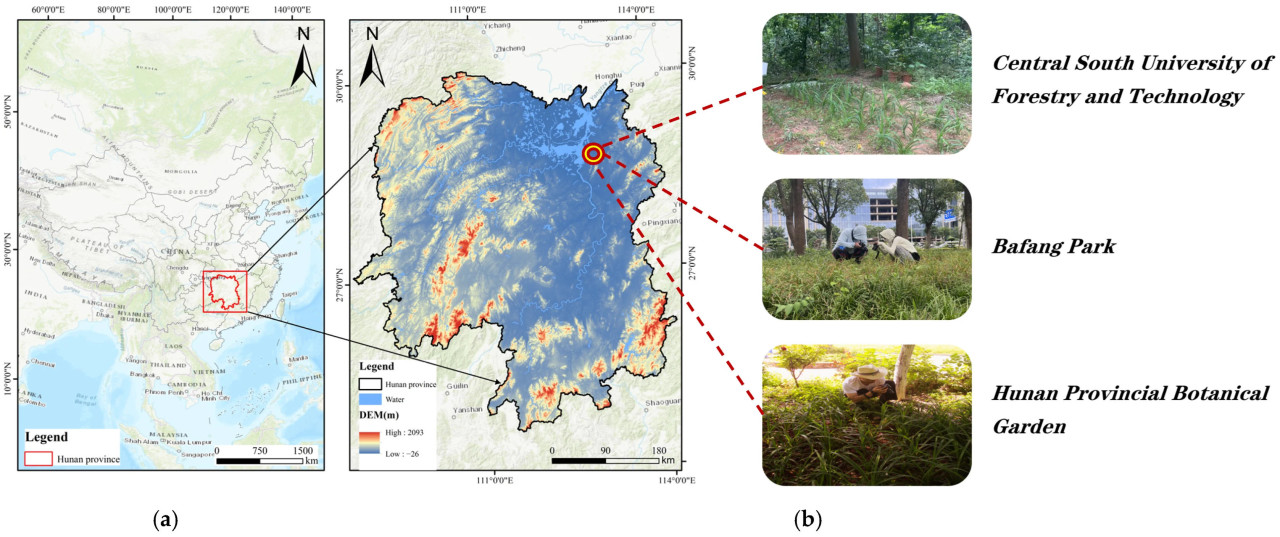
Рисунок 1. Места сбора данных о болезнях листьев Hemerocallis fulva следующие. (a) Карта Южной Азии; (b) среда места сбора в провинции Хунань, Китай.
Для улучшения разнообразия и репрезентативности набора данных для съемки изображений под различными углами использовались четыре смартфона и четыре камеры с расстояния 10–20 см от листьев. Этот подход обеспечил четкую видимость признаков болезней и охватил широкий диапазон качества изображений и сцен. Конкретные параметры пикселей устройств и количество изображений перечислены в Таблице 1.

Таблица 1. Оборудование для сбора и количество данных о болезнях листьев Hemerocallis fulva.
2.1.2. Аннотирование набора данных
Характеристики болезней листьев Hemerocallis fulva показаны на Рисунке 2, при этом все случаи болезней были точно аннотированы с помощью инструмента LabelImg 1.8.0. Данные аннотаций показывают, что количество случаев ржавчины, антракноза, листовой пятнистости и листовой гнили составляет 391, 332, 932 и 1050 соответственно. Среди них мелкие цели распределены наиболее плотно, за ними следуют средние и крупные цели. Это распределение отражает реальное возникновение целей болезней, подчеркивая важность улучшения извлечения мелкомасштабных признаков. Кроме того, распределение средних и крупных целей помогает сбалансировать вес целей различного масштаба в обучающем наборе данных, тем самым улучшая адаптируемость и обобщающую способность модели. Для обеспечения обобщения модели набор данных был разделен на обучающий, тестовый и валидационный наборы в соотношении 7:2:1 [46,47]. Организованный набор данных назван «HFLD-Dataset», а информация о размере ограничивающих рамок предоставлена на Рисунке 3.

Рисунок 2. Образцы набора данных о болезнях листьев Hemerocallis fulva (HFLD-Dataset). (a) Листовая гниль; (b) Антракноз; (c) Листовая пятнистость; (d) Ржавчина.
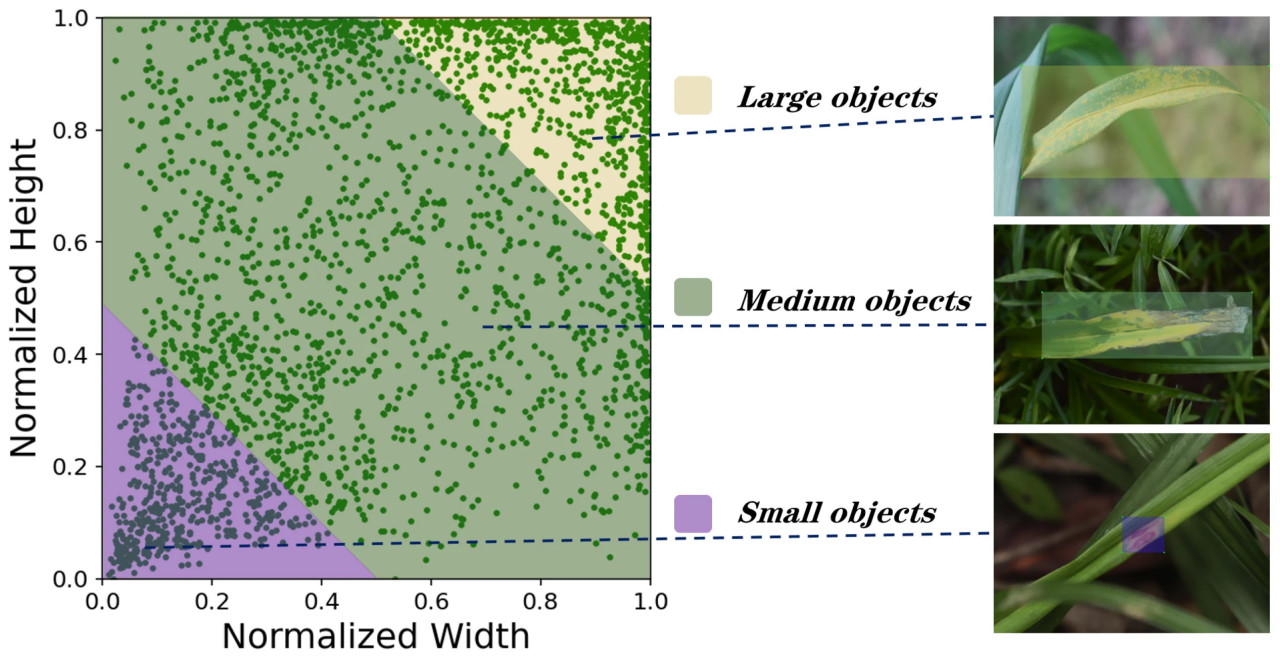
Рисунок 3. Визуализация распределения меток.
2.1.3. Улучшение изображений
Для повышения обобщающей способности модели и предотвращения переобучения были использованы различные стратегии аугментации данных для обогащения набора данных и решения проблемы нехватки образцов изображений в различных средах. Эти стратегии включают горизонтальное отражение для имитации изменений ориентации и угла листьев, преобразования перспективы для воспроизведения морфологических вариаций из-за изменений угла съемки или точки обзора, добавление шума для имитации влияния сенсорных или средовых помех, регулировку яркости для имитации работы при различных условиях освещения и преобразования вращения для имитации вариаций роста листьев или углов камеры. Каждое изображение было дополнено пять раз, при этом для каждого экземпляра применялся по крайней мере один метод улучшения, что гарантировало, что ни один метод не использовался более одного раза. Эффекты этих улучшений показаны на Рисунке 4.

Рисунок 4. Эффекты аугментации данных для болезни листьев Hemerocallis fulva. (a) Отражение; (b) преобразование перспективы; (c) регулировка яркости; (d) добавление шума; (e) вращение.
Аугментация данных улучшила разнообразие набора данных, обеспечив представление различных условий окружающей среды и вариаций во время обучения. Каждая аугментация расширила набор данных, сбалансировала распределение выборок, уменьшила переобучение и улучшила адаптируемость модели к сложным сценариям. Хотя распределение экземпляров болезней несколько несбалансировано из-за таких факторов, как климат, география, плотность растительности, частота применения пестицидов и наличие множества мелких целей болезней на одном изображении, общий масштаб и разнообразие набора данных соответствуют требованиям для обучения и валидации модели. Состав набора данных показан в Таблице 2.

Таблица 2. Таблица состава набора данных.
2.2. Модель HF-MSENet
Одноэтапные алгоритмы обнаружения объектов, такие как YOLO, напрямую предсказывают ограничивающие рамки и оценки классов, устраняя дополнительные накладные расходы двухэтапных моделей, что повышает эффективность обработки в реальном времени. YOLO превосходит SSD как по скорости, так и по точности, что делает его более подходящим для задач обнаружения в реальном времени. YOLOv8 благодаря непрерывной оптимизации дальнейше улучшает производительность, при этом YOLOv8n предлагает высокую точность, быстрое обнаружение и низкое использование памяти, что делает его идеальным для мобильного развертывания [48]. Его архитектура объединяет сеть C2f, SPPF и сверточные модули для извлечения признаков, в то время как PANet используется для слияния признаков. Благодаря своей эффективной конструкции YOLOv8n превосходит других по производительности и точности, предоставляя эффективное решение для обнаружения болезней в сельском хозяйстве.
Несмотря на сильные стороны YOLOv8n в быстром обнаружении и многометочной разметке, он имеет заметные ограничения в обнаружении болезней листьев Hemerocallis fulva. Во-первых, помехи от сложного фона часто скрывают признаки болезней, снижая способность модели фокусироваться на критических областях. Во-вторых, его способность к многомасштабному извлечению признаков ограничена, что делает его менее адаптируемым к значительным вариациям размера и формы областей болезней, в частности в обнаружении мелкомасштабных болезней. Кроме того, его способность реконструировать признаки и захватывать мелкие детали недостаточна для точного обнаружения малозаметных признаков болезней. Чтобы решить эти проблемы, в этом исследовании был сделан ряд ключевых улучшений, что привело к предложению улучшенной модели HF-MSENet. Архитектура модели HF-MSENet показана на Рисунке 5.
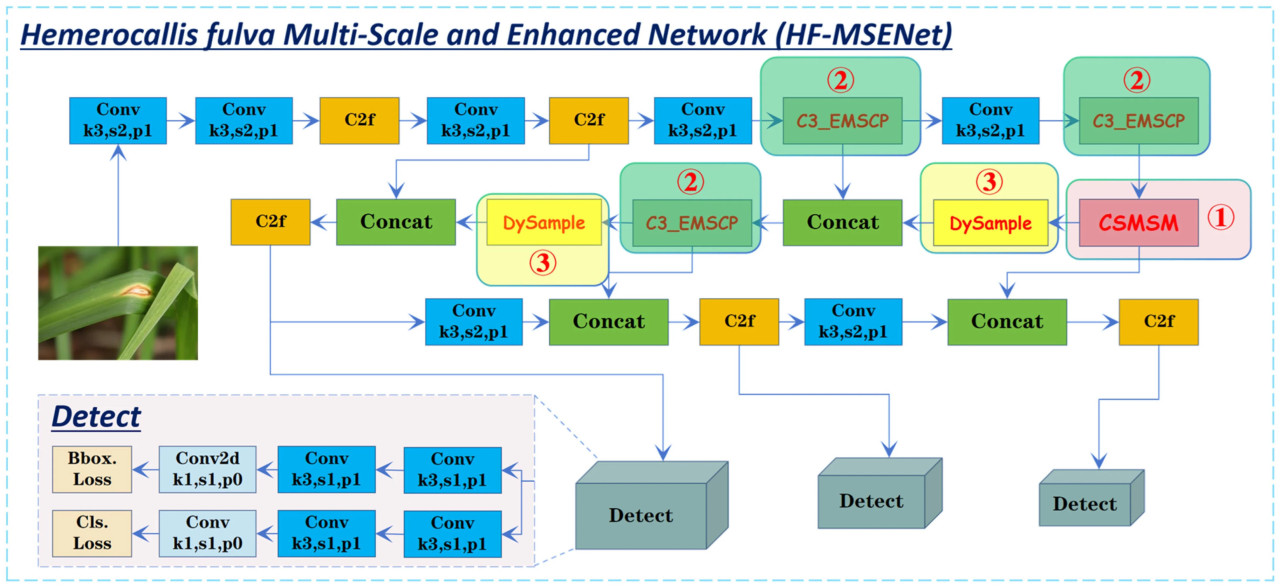
Рисунок 5. Структура модели (многомасштабная и улучшенная сеть Hemerocallis fulva) HF-MSENet.
- Чтобы улучшить способность модели фокусироваться на целевых областях и улучшить многомасштабное извлечение признаков, модуль CSMSM внедряется в тыловой части базовой сети в блоке ①. Этот модуль служит ключевым компонентом в конвейере обнаружения, оптимизируя способность модели расставлять приоритеты и извлекать признаки из ключевых областей, где симптомы болезней наиболее выражены. Этот модуль усиливает внимание модели к ключевым областям с помощью двойного механизма канально-пространственного внимания, в то время как включение стратегий многомасштабного извлечения признаков комплексно улучшает извлечение признаков областей болезней.
- Чтобы решить проблему низкой эффективности взаимодействия информации и недостаточного кросс-масштабного взаимодействия при многомасштабном слиянии признаков, модуль C3_EMSCP внедряется и оптимизируется в трех критических точках соединения между базовой сетью и сетевыми уровнями в блоке ②. Это стратегическое размещение позволяет модулю соединять различные слои признаков, улучшая способность модели объединять информацию из различных разрешений. Используя многомасштабные сверточные ядра, этот модуль эффективно адаптирует и уточняет признаки различных разрешений, в то время как интеграция структур групповой свертки дальнейше повышает вычислительную эффективность и глубину слияния признаков.
- Чтобы решить проблему потери деталей и размытия границ объектов, часто вызываемую традиционными методами увеличения разрешения, модуль DySample внедряется на этапе увеличения разрешения в блоке ③. Модуль DySample специально разработан для решения проблем, связанных с мелкозернистыми признаками и точностью границ при обнаружении болезней. Этот модуль использует механизм обучения динамическому смещению для адаптивной корректировки позиций выборки, избегая потери деталей из-за ошибок интерполяции. Кроме того, используя методы переупорядочивания пикселей и сеточной выборки, он оптимизирует сохранение деталей и улучшает четкость краев.
Совместная оптимизация извлечения признаков, многомасштабного слияния и реконструкции деталей значительно улучшает способность модели фокусироваться на целевых областях, взаимодействовать в различных масштабах и восстанавливать мелкие детали, предоставляя надежную поддержку для точного обнаружения болезней листьев Hemerocallis fulva.
2.2.1. Модуль CSMSM
В задаче обнаружения болезней листьев Hemerocallis fulva признаки болезней часто появляются в различных масштабах и сопровождаются сложными фоновыми помехами. Существующие модели обнаружения объектов демонстрируют ограничения в фокусировке на ключевых областях и извлечении многомасштабных признаков. Чтобы решить эти проблемы, в этой статье предлагается CSMSM (многомасштабный канально-пространственный модуль), который объединяет двойной механизм канально-пространственного внимания со стратегией многомасштабного извлечения признаков. Этот подход эффективно подавляет фоновый шум и улучшает способность модели фокусироваться на ключевых областях болезней и извлекать из них признаки.
Дизайн CSMSM вдохновлен улучшениями в многоэтапных модулях и включает два основных компонента: канально-пространственное двойное внимание и стратегию многомасштабного слияния признаков. Модуль канально-пространственного двойного внимания, основанный на сотрудничестве механизмов канального и пространственного внимания (таких как CBAM и GAM) [49,50], дальнейше усиливает представление признаков в критических областях, одновременно эффективно подавляя фоновый шум. Стратегия многомасштабного слияния признаков объединяет идеи модулей SPPF и SPPFCSPC, в частности конструкцию кросс-этапной сети (CSP) [51,52]. Используя механизмы совместного использования и разделения признаков [53], она улучшает способность модели извлекать признаки на различных масштабах. Детальная конструкция показана на Рисунке 6.
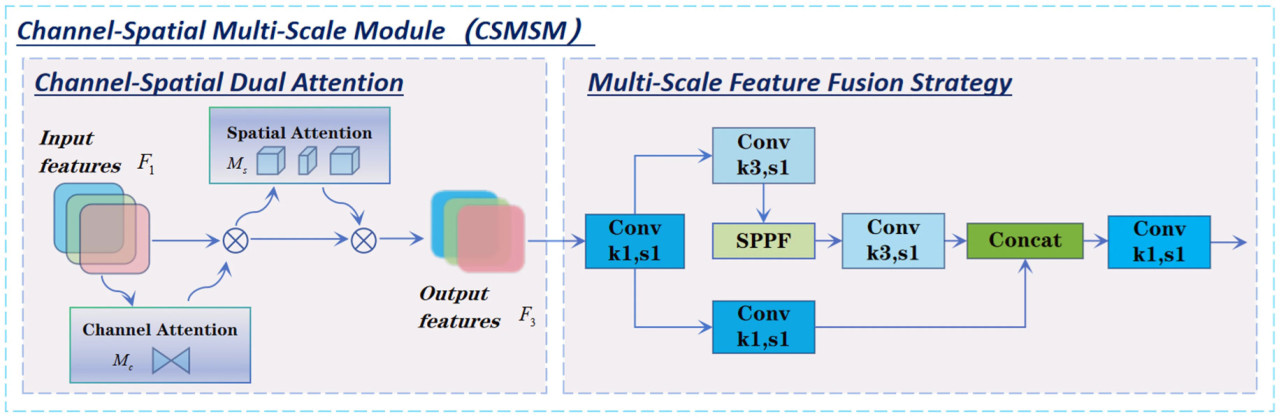
Рисунок 6. Структура модуля CSMSM.
Канально-пространственное двойное внимание
Одним из ключевых компонентов CSMSM является канально-пространственное двойное внимание, предназначенное для оптимизации представления признаков, улучшения фокуса модели на критических областях болезней и подавления фоновых шумовых помех. Структуры канального внимания и пространственного внимания показаны на Рисунке 7.
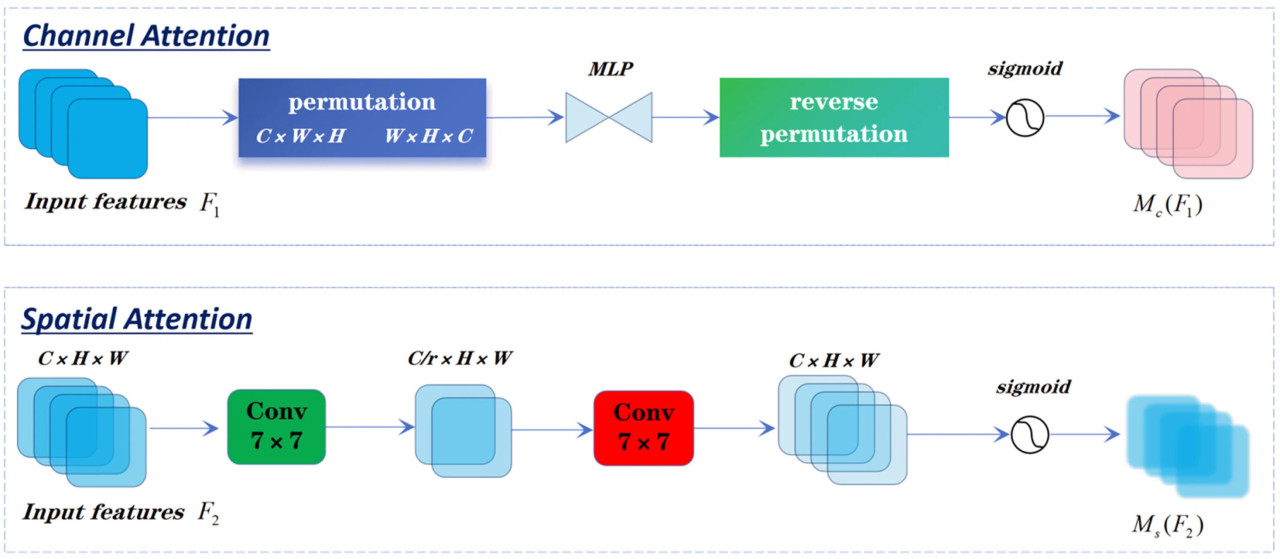
Рисунок 7. Структура канально-пространственного двойного внимания.
В частности, входная карта признаков сначала проходит через модуль канального внимания. Этот модуль направлен на оптимизацию распределения весов каналов входной карты признаков, выделяя признаки, связанные с болезнью, и одновременно подавляя нерелевантную информацию. Дизайн канального внимания вдохновлен динамическим распределением глобальной информации. Анализируя глобальные признаки каждого канала, генерируются адаптивные веса. В процессе реализации входная карта признаков сначала перестраивается вдоль измерения каналов. Затем два полностью связанных слоя (MLP) сжимают и восстанавливают размерности признаков, при этом функция активации ReLU применяется для нелинейного отображения. Впоследствии сгенерированные веса нормализуются с использованием функции Sigmoid, что гарантирует усиление весов каналов, связанных с болезнью, в то время как веса избыточных фоновых каналов подавляются. Оптимизированная карта признаков с канальными весами поэлементно умножается на исходную карту признаков для улучшения признаков вдоль измерения каналов.
Затем оптимизированная карта признаков передается в модуль пространственного внимания. Этот модуль фокусируется на двумерном пространственном распределении карты признаков для захвата локальной информации на уровне пикселей. При реализации пространственное внимание сначала использует ядро свертки 7×7 для извлечения локальных признаков, за которым следует оптимизация признаков с помощью пакетной нормализации (BatchNorm) и функции активации ReLU. Другой сверточный слой восстанавливает признаки до их исходных размерностей, и функция Sigmoid генерирует карту пространственных весов, которая значительно усиливает ключевые области болезней в пространственном измерении. Этот дизайн эффективно избегает потери информации, которая может возникнуть в результате традиционных операций пулинга, хорошо работая при обработке нерегулярных форм болезней и мелких поражений. Наконец, карта признаков, оптимизированная по каналам, поэлементно умножается на карту пространственных весов, что приводит к карте признаков, объединяющей как канальные, так и пространственные механизмы внимания.
На протяжении всего этого процесса канальное внимание динамически распределяет веса каналов, чтобы подчеркнуть признаки болезней, одновременно подавляя избыточную информацию. Пространственное внимание усиливает локальные детали в пространственном измерении, улучшая фокус на целевых областях болезней на сложном фоне. Конечная объединенная карта признаков демонстрирует улучшенную иерархическую структуру и выразительную способность.
Общий процесс вычислений описан в Уравнениях (1)–(3).
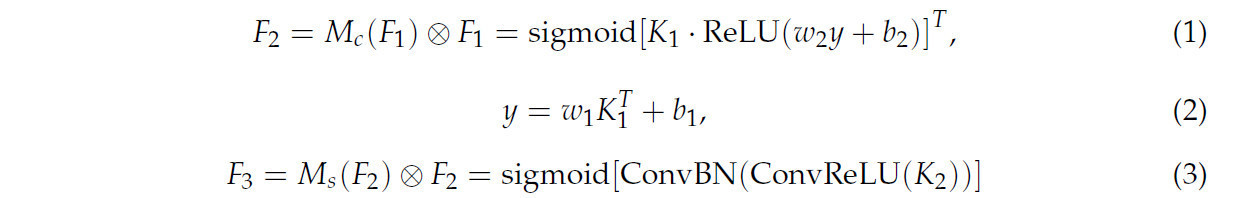
Здесь F1 представляет входную карту признаков, а F2 обозначает выходную карту признаков подмодуля канального внимания. w1 и w2, а также b1 и b2 представляют начальные веса и смещения многослойного перцептрона (MLP). MC относится к функции канального внимания, F3 — выходная карта признаков, а MS — функция пространственного внимания.
Стратегия многомасштабного слияния признаков
Стратегия многомасштабного слияния признаков является еще одной основной конструкцией CSMSM, направленной на дальнейшее улучшение способности модели захватывать многомасштабные признаки болезней после оптимизации внимания, сохраняя при этом эффективное извлечение признаков. Общая конструкция стратегии многомасштабного слияния признаков показана на Рисунке 8.
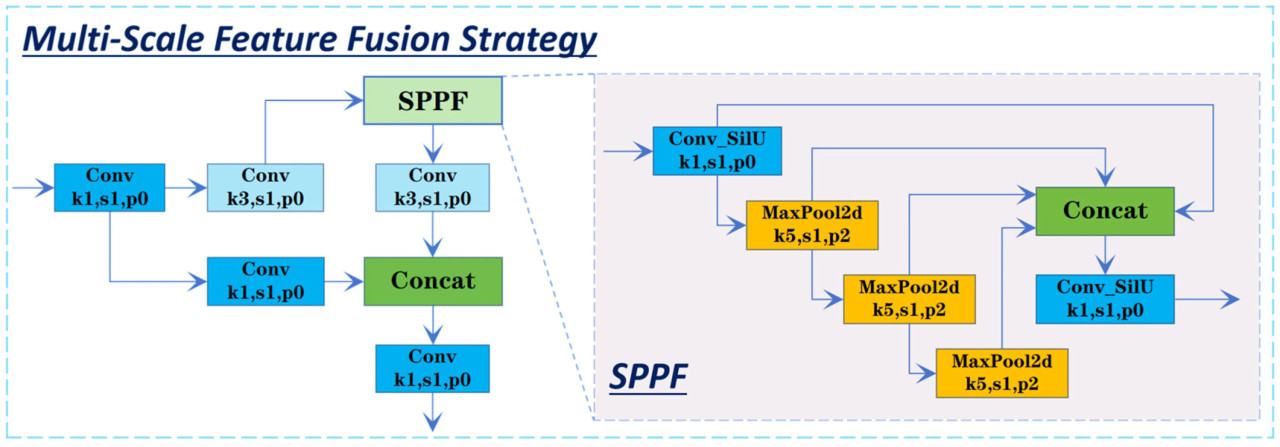
Рисунок 8. Структура стратегии многомасштабного слияния признаков.
В частности, входная карта признаков разделена на две ветви обработки: одна извлекает признаки с помощью традиционных сверточных операций, в то время как другая постепенно расширяет воспринимающее поле путем наложения ядер пулинга фиксированного размера (например, 5×5), имитируя эффект более крупных ядер пулинга (например, 9×9 и 13×13). Этот подход послойного наложения позволяет избежать избыточных вычислений, вызванных параллельным пулингом с несколькими ядрами, обеспечивая эффективное многомасштабное извлечение признаков. Затем карты признаков, полученные после пулинга, обрабатываются свертками 1×1 как для уменьшения, так и для расширения размерности, сохраняя детальную информацию и одновременно снижая вычислительную сложность. Кроме того, объединяя пулинг с остаточными связями, эта стратегия обеспечивает непрерывный и полный поток признаков. В конечном итоге, стратегия многомасштабного слияния признаков объединяет механизмы пулинга и остаточные связи для захвата признаков болезней в различных масштабах, сохраняя при этом эффективную вычислительную производительность.
Вычисления для части пулинга приведены в Уравнениях (4)–(7).
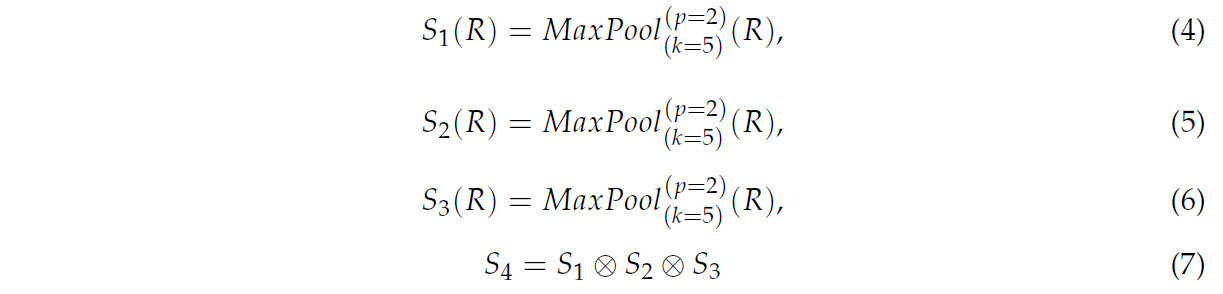
Здесь R представляет входной слой признаков, а S1, S2 и S3 обозначают результаты от малых, средних и больших ядер пулинга соответственно. S4 относится к конечному выходу, k указывает количество сверточных ядер, а p обозначает шаг свертки. Символ ⊗ представляет объединение тензоров.
Благодаря пошаговой оптимизации и поэлементному умножению канального внимания и пространственного внимания, CSMSM улучшает представление информации, связанной с ключевыми областями болезней, одновременно подавляя фоновый шум, тем самым повышая заметность областей болезней. В сочетании со стратегией многомасштабного слияния признаков, обеспечивающей эффективное совместное использование и разделение признаков, иерархическое выражение признаков постепенно оптимизируется, обеспечивая эффективное извлечение информации в различных масштабах. В целом, CSMSM значительно улучшает глубину и широту представления признаков, предоставляя высококачественную поддержку признаков для обнаружения болезней листьев Hemerocallis fulva на сложном фоне.
2.2.2. Модуль C3_EMSCP
В задаче обнаружения болезней листьев Hemerocallis fulva разнообразие и нерегулярность областей болезней создают значительные проблемы для способности модели объединять и взаимодействовать с многомасштабными признаками. Традиционный модуль C2f, как легковесная единица извлечения признаков, выражает признаки через стековые подмодули Bottleneck и улучшает вычислительную эффективность с помощью операций разбиения на блоки. Однако модуль C2f ограничен в своей способности взаимодействовать и объединять многомасштабную информацию, что затрудняет полную координацию информационных потоков между признаками различного масштаба. Это ограничение сужает общее понимание модели и ее адаптируемость к сложным областям болезней. Структура модуля C2f показана на Рисунке 9.
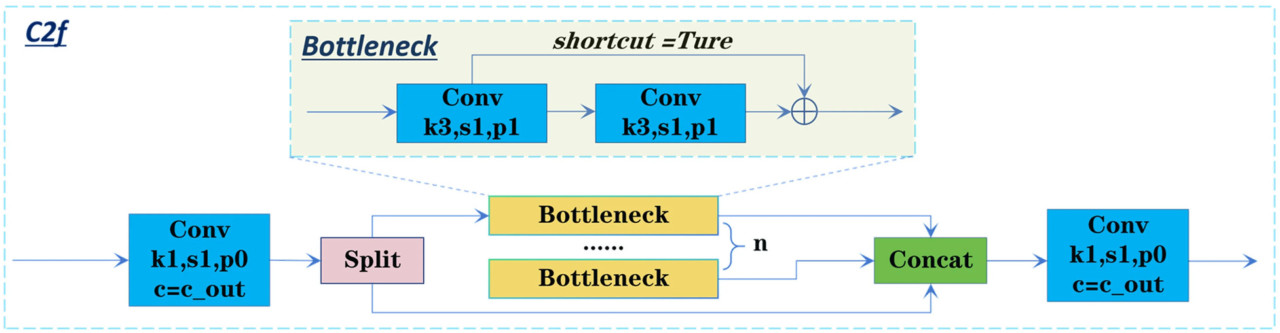
Рисунок 9. Структура модуля C2f.
Модуль C3_EMSCP внедряется и оптимизируется для улучшения многомасштабного взаимодействия и слияния информации. Объединяя многомасштабные сверточные ядра с методами групповой свертки, он улучшает поток признаков [54,55]. Структура модуля C3_EMSCP показана на Рисунке 10.
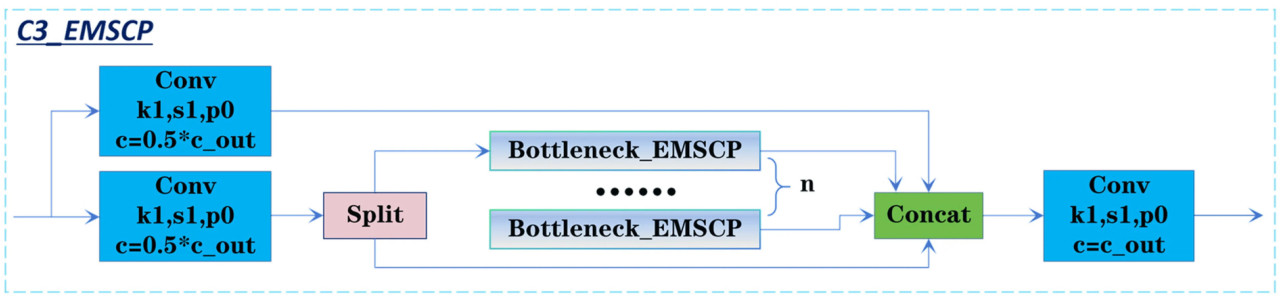
Рисунок 10. Структура модуля C3_EMSCP.
В частности, модуль C3_EMSCP использует двухпутевую конструкцию с мелкими и глубокими ветвями для сохранения локальных деталей и извлечения глубинных признаков:
- Мелкая ветвь: свертка 1×1 быстро сжимает входные признаки и извлекает ключевую информацию, сохраняя целостность детальных признаков и закладывая основу для последующего слияния признаков.
- Глубокая ветвь, используя стековую структуру Bottleneck_EMSCP, улучшает глубину слияния признаков и многомасштабное взаимодействие информации. В Bottleneck_EMSCP свертки 1×1 уменьшают количество каналов и объединяют информацию. Слой EMSConvP применяет многомасштабные сверточные ядра (1×1, 3×3, 5×5 и 7×7) и групповые свертки, облегчая поэтапную свертку сгруппированной входной карты признаков. Это обеспечивает глубокое взаимодействие между кросс-масштабными признаками, минимизируя при этом вычислительную избыточность. Структура Bottleneck_EMSCP показана на Рисунке 11.
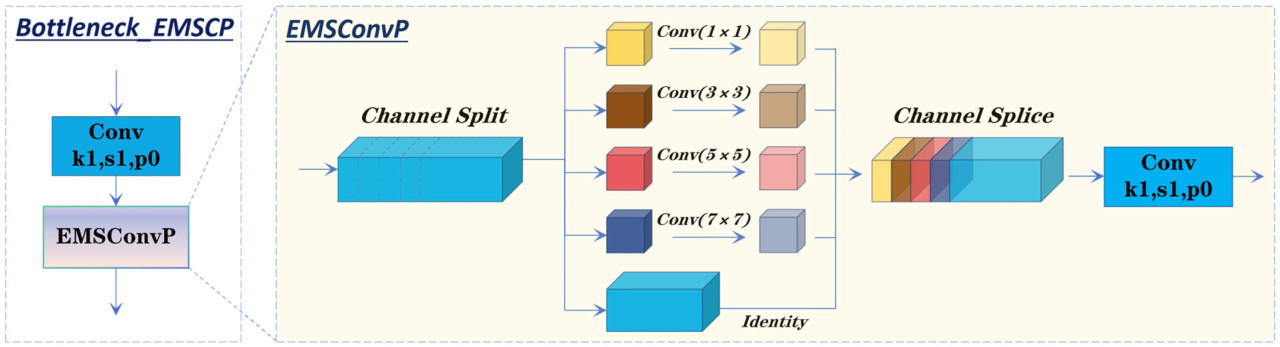
Рисунок 11. Структура модуля Bottleneck_EMSCP.
С точки зрения механизма слияния, модуль C3_EMSCP улучшает взаимодействие и интеграцию мелких и глубоких признаков благодаря совместной конструкции многомасштабных сверточных ядер и методов групповой свертки. Мелкая ветвь фокусируется на сохранении локальной детальной информации из входных признаков, в то время как глубокая ветвь захватывает глобальные признаки из областей болезней различного масштаба, используя многомасштабные сверточные ядра и групповые свертки. В конечном итоге, карты признаков из обеих ветвей объединяются вдоль измерения каналов и дальше оптимизируются с помощью сверток 1×1, значительно улучшая комплексное выражение как локальной, так и глобальной информации.
Основная инновация модуля C3_EMSCP заключается в синергетической конструкции многомасштабных сверточных ядер и групповых сверток. Этот дизайн эффективно решает недостатки традиционных модулей в извлечении многомасштабных признаков болезней, улучшая многомасштабную адаптируемость и взаимодействие информации признаков. Он не только улучшает способность модели к всестороннему пониманию областей болезней в различных масштабах, но и эффективно балансирует вычислительную эффективность и показатели обнаружения, предоставляя эффективную и стабильную поддержку признаков для точного обнаружения сложных областей болезней.
2.2.3. Модуль DySample
В задаче обнаружения болезней листьев Hemerocallis fulva, чтобы решить проблемы потери деталей и размытия границ во время реконструкции признаков, в модель HF-MSENet был внедрен и оптимизирован модуль динамического увеличения разрешения DySample. Основой DySample является динамическая генерация позиций выборки на основе содержимого входной карты признаков, что обеспечивает более точное восстановление деталей высокого разрешения и структурной информации [56]. Генерируя значения смещения с помощью сверточных слоев, модуль динамически регулирует диапазон выборки для каждого пикселя, эффективно оптимизируя пространственное распределение карты признаков. Этот механизм значительно улучшает способность модели захватывать малозаметные признаки болезней, в частности на сложном фоне, тем самым повышая точность обнаружения и устойчивость.
По сравнению с традиционными методами увеличения разрешения, DySample не только использует точечную выборку для уменьшения ошибок интерполяции, но также включает переупорядочивание пикселей и сеточную выборку для предотвращения размытия границ. Этот подход генерирует результаты увеличения разрешения с учетом содержимого без необходимости в дополнительных входных признаках высокого разрешения, тем самым снижая сложность модели и вычислительные затраты при сохранении высокой производительности. Процесс выборки показан на Рисунке 12.
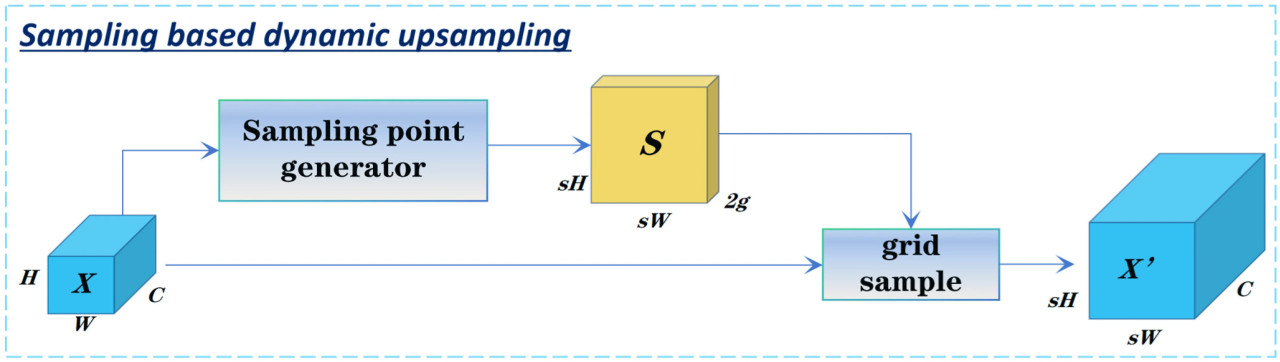
Рисунок 12. Динамическое увеличение разрешения на основе выборки.
В частности, для заданной входной карты признаков X (размером C × H × W) и набора точечной выборки S (размером 2g × sH × sW, где 2g представляет координаты x и y), функция Grid Sample повторно дискретизирует X в позициях, указанных S, для получения карты признаков X′ с увеличенным разрешением. Формула вычисления показана в Уравнении (8).
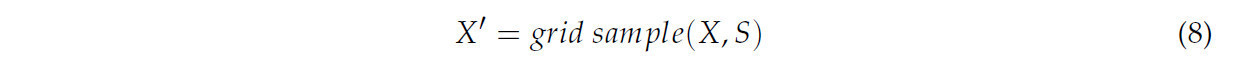
Диапазон смещения набора выборки может определяться динамическим и статическим факторами масштаба соответственно. Процессы выборки для обоих показаны на Рисунке 13.
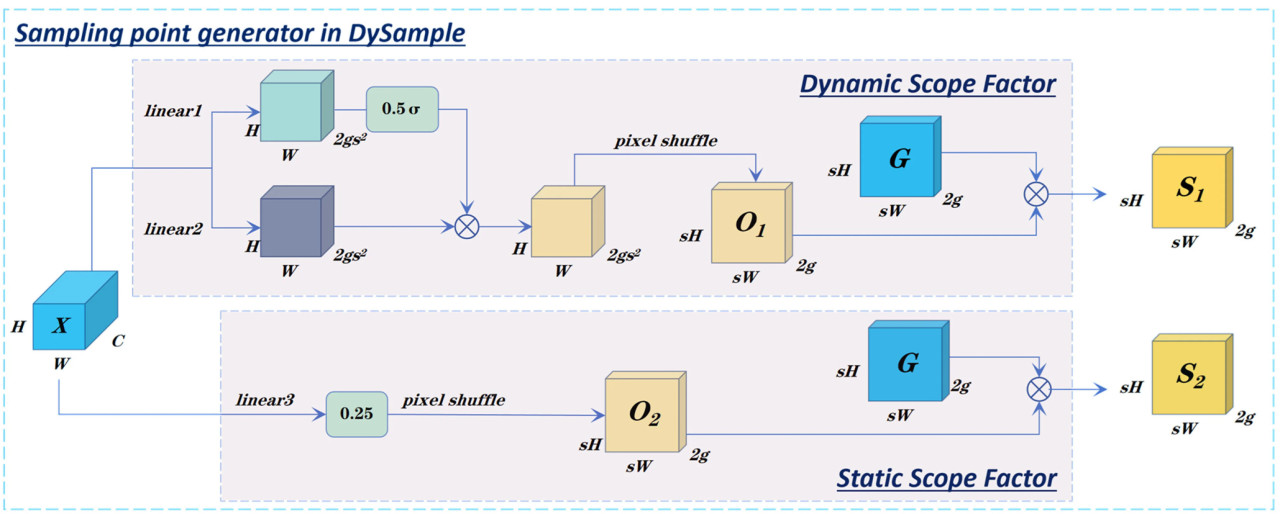
Рисунок 13. Генератор точек выборки в DySample.
Динамический фактор масштаба
Чтобы улучшить качество увеличения разрешения, DySample динамически регулирует позиции выборки на основе содержимого и контекста входной карты признаков. Используя обучаемые смещения, DySample обеспечивает мелкозернистую выборку в различных пространственных масштабах, преодолевая ограничения традиционных методов интерполяции. Механизм обучения смещению позволяет более эффективно захватывать детальную информацию, улучшая производительность при реконструкции изображений высокого разрешения и задачах обнаружения многомасштабных объектов. При обнаружении болезней листьев Hemerocallis fulva точный механизм увеличения разрешения модуля эффективно захватывает признаки поражений в различных масштабах, тем самым улучшая общую производительность модели. Вычислительные формулы представлены в Уравнениях (9) и (10).
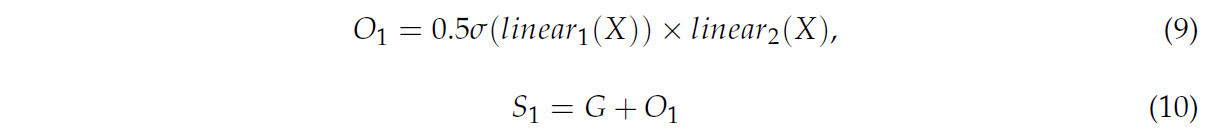
Статический фактор масштаба
Входная карта признаков X (размером C × H × W) сначала пропускается через линейный слой (входной канал C; выходной канал 2gs²), и результирующий тензор реорганизуется с использованием метода переупорядочивания пикселей для получения тензора смещения O₂ (размером 2g × sH × sW). Смещение O₂ затем добавляется к исходной сетке выборки G для генерации набора выборки S₂. Процесс вычисления определяется Уравнениями (11) и (12).
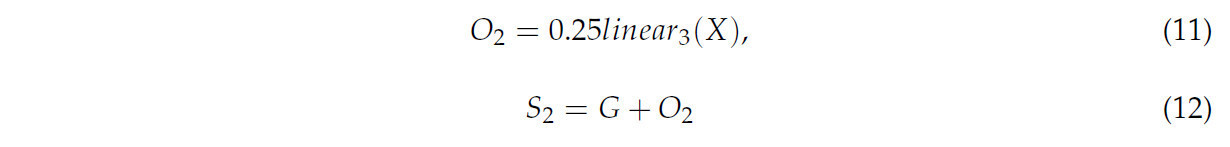
Механизм динамического увеличения разрешения модуля DySample улучшает способность модели восстанавливать детали и захватывать многомасштабные признаки, сохраняя при этом вычислительную эффективность. Он значительно улучшает точность обнаружения и устойчивость. При реконструкции признаков высокого разрешения и задачах обнаружения многомасштабных объектов конструкция DySample позволяет HF-MSENet работать исключительно хорошо на сложном фоне.
2.3. Среда обучения и настройки параметров
Аппаратные характеристики эксперимента, среда выполнения, конфигурации CUDA и cuDNN, а также соответствующие библиотеки, используемые при построении предложенной модели HF-MSENet для обнаружения болезней листьев Hemerocallis fulva, подробно описаны в следующих разделах, как обобщено в Таблице 3.

Таблица 3. Параметры экспериментальной среды.
Базовая модель определяется как архитектура YOLOv8n, которая работает без каких-либо дополнительных модулей или модификаций, обеспечивая стандартную структуру. Конкретные параметры обучения и конфигурации всесторонне перечислены в Таблице 4.

Таблица 4. Параметры обучения.
2.4. Показатели оценки производительности
Модель обнаружения болезней листьев Hemerocallis fulva была оценена с использованием ключевых показателей: точности (P), полноты (R), F1-меры (F1), mAP@50 и mAP@50–95.
- P измеряет точность предсказания, акцентируя внимание на уменьшении ложноположительных результатов.
- R количественно определяет обнаружение целей, акцентируя внимание на минимизации ложноотрицательных результатов.
- F1 является средним гармоническим P и R, балансируя точность обнаружения и чувствительность, особенно при несбалансированных классах.
- AP оценивает показатели обнаружения модели для одной категории, отражая среднюю точность для этого конкретного класса.
- mAP@50 измеряет среднюю точность обнаружения при пороге IoU 0,5, предоставляя общую оценку модели.
- mAP@50–95 вычисляет среднюю точность при порогах IoU от 0,5 до 0,95, оценивая устойчивость модели при различных условиях перекрытия.
Формулы для этих показателей приведены в Уравнениях (13)–(18).
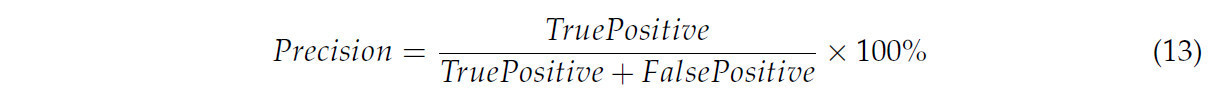

3. Результаты
3.1. Экспериментальные результаты и обсуждение
3.1.1. Абляционный эксперимент
Для всесторонней оценки вклада отдельных модулей в оптимизацию производительности HF-MSENet, в частности для обнаружения болезней на сложном фоне, была проведена серия абляционных экспериментов. Модули последовательно добавлялись или удалялись для оценки их независимого и синергетического влияния на извлечение, слияние и реконструкцию признаков. Эксперименты, разделенные на восемь групп, включали базовую модель и различные комбинации улучшенных модулей. Результаты предоставляют теоретическую поддержку для дизайна HF-MSENet. Результаты абляционного исследования обобщены в Таблице 5.
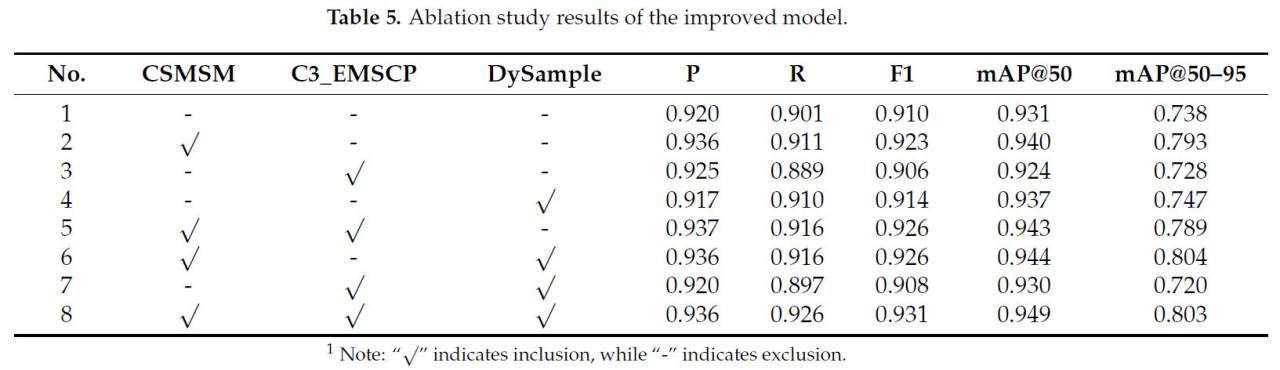
Таблица 5. Результаты абляционного исследования улучшенной модели.
Экспериментальные результаты демонстрируют, что базовая модель показала низкую производительность по всем показателям, с особенно низким mAP@50–95, равным 0,738, что указывает на ее ограниченную способность обнаруживать болезни на сложном фоне. Внедрение только модуля CSMSM улучшило P с 0,920 до 0,936 и mAP@50–95 до 0,793, что свидетельствует о том, что этот модуль эффективно улучшил представление целевых признаков и подавил фоновые помехи, тем самым улучшив общую производительность обнаружения. Когда был внедрен модуль C3_EMSCP, показатели P и F1 немного улучшились, но R и mAP@50–95 показали ограниченный рост, выделяя его основную роль в многомасштабном слиянии признаков с меньшим влиянием на оптимизацию мелких деталей. И наоборот, включение модуля DySample значительно улучшило R и mAP@50–95, подтверждая его эффективность в восстановлении мелкозернистых деталей и оптимизации границ целей.
Комбинация модулей CSMSM и DySample привела к синергетическим улучшениям, достигнув самого высокого mAP@50–95, выделяя их взаимодополняющие сильные стороны в извлечении признаков и восстановлении деталей. Интеграция всех модулей дальнейше улучшила производительность, при этом mAP@50 и mAP@50–95 достигли 0,949 и 0,803 соответственно, подтверждая независимый и синергетический вклад каждого модуля.
3.1.2. Обсуждение абляционного эксперимента
Визуализации тепловых карт были использованы для иллюстрации влияния каждого модуля на производительность модели. Тепловые карты выделяют точность обнаружения и внимание модели к областям болезней, при этом более темные цвета указывают на более высокое внимание. Рисунок 14 показывает постепенные изменения по мере последовательного внедрения CSMSM, C3_EMSCP и DySample.

Рисунок 14. Визуализация тепловых карт результатов обнаружения с различными комбинациями модулей. (a) Базовая модель; (b) Базовая модель + CSMSM; (c) Базовая модель + C3_EMSCP; (d) Базовая модель + DySample; (e) Базовая модель + CSMSM + C3_EMSCP; (f) Базовая модель + CSMSM + DySample; (g) Базовая модель + C3_EMSCP + DySample; (h) HF-MSENet.
- Базовая модель (Рисунок 14a) показывает нечеткую локализацию болезней и пропускает малозаметные признаки из-за общих методов извлечения, что приводит к высокому фоновому шуму и пропущенным обнаружениям. Необходимы улучшения для повышения производительности.
- Модуль CSMSM (Рисунок 14b) улучшает фокус на ключевых областях болезней с помощью двойного механизма канально-пространственного внимания, который расставляет приоритеты для признаков, связанных с болезнью. Однако ограниченное извлечение признаков может привести к пропуску мелких деталей и незначительным сдвигам границ обнаружения, поскольку модель акцентирует внимание на больших областях.
- Модуль C3_EMSCP (Рисунок 14c) улучшает многомасштабное слияние признаков, позволяя модели захватывать признаки в различных разрешениях. Однако из-за неполного извлечения мелкозернистых признаков мелкие поражения болезней могут быть неточно локализованы, вызывая незначительные сдвиги в позициях обнаружения.
- Модуль DySample (Рисунок 14d) улучшает восстановление деталей и уменьшает размытие границ во время увеличения разрешения. Динамически регулируя позиции выборки, он уточняет обнаружение мелкозернистых признаков. Тем не менее, ложные обнаружения могут все еще происходить на сложном фоне, вызывая незначительные сдвиги в местах обнаружения, в частности в областях с перекрывающимися или малозаметными симптомами болезней.
- Комбинация CSMSM и C3_EMSCP (Рисунок 14e) улучшает внимание к признакам и многомасштабное слияние, улучшая охват областей болезней и фокус на критических областях. Однако мелкие цели могут все еще пропускаться, поскольку модель отдает приоритет более крупным признакам, вызывая вариации в местах обнаружения для небольших поражений.
- Комбинация CSMSM и DySample (Рисунок 14f) улучшает фокусировку на областях и восстановление деталей, повышая точность обнаружения в различных размерах целей. Хотя фоновый шум уменьшен, а четкость границ улучшена, незначительные сдвиги в местах обнаружения могут все еще происходить из-за небольших ошибочных обнаружений на сложном фоне.
- Интеграция C3_EMSCP и DySample (Рисунок 14g) демонстрирует сильное многомасштабное слияние и оптимизацию границ. Однако сложность фонового шума немного снижает точность обнаружения, приводя к незначительным сдвигам в местах обнаружения, особенно для мелких или неправильной формы поражений болезней.
- Наконец, интеграция CSMSM, C3_EMSCP и DySample в HF-MSENet (Рисунок 14h) достигает оптимальной локализации областей болезней. Этот подход улучшает точность обнаружения в различных масштабах, значительно сокращая количество ложных и пропущенных обнаружений. Синергетический эффект этих модулей повышает точность обнаружения и обеспечивает последовательную локализацию, как продемонстрировано на Рисунке 14h.
Как показано на Рисунке 15 и в Таблице 6, модель HF-MSENet превосходит базовые модели по всем категориям болезней, демонстрируя синергетические эффекты оптимизации своих трех модулей. Для листовой гнили mAP@50 увеличился с 0,964 до 0,972, в первую очередь благодаря улучшенному фокусу модуля CSMSM на признаках ключевых областей, что повысило точность обнаружения. Для антракноза mAP@50 улучшился с 0,912 до 0,934, при этом HF-MSENet генерирует ограничивающие рамки, которые более точно соответствуют фактическим областям болезней, предоставляя более четкие границы и более точное покрытие. Это улучшение отражает улучшенное извлечение признаков модулем CSMSM и роль модуля DySample в оптимизации границ и восстановлении деталей. Для листовой пятнистости mAP@50 вырос с 0,918 до 0,929, отражая улучшенное обнаружение мелких поражений благодаря многомасштабному слиянию и взаимодействию признаков модуля C3_EMSCP, повышающему адаптируемость к разнообразным областям болезней. Для ржавчины mAP@50 увеличился с 0,931 до 0,962, при этом ограничивающие рамки тесно соответствуют истинным областям болезней и подавляют фоновый шум. Это демонстрирует преимущество модели в локализации ключевых областей и подтверждает многомасштабную адаптацию модуля C3_EMSCP и эффективность модуля DySample в реконструкции деталей. В целом, mAP@50 для HF-MSENet увеличился с 0,931 до 0,949, а mAP@50–95 улучшился с 0,738 до 0,803, отражая прирост на 1,8% и 6,5% соответственно. Эти результаты выделяют синергетические эффекты модулей CSMSM, C3_EMSCP и DySample в извлечении признаков, слиянии и восстановлении деталей, повышая точность и устойчивость обнаружения болезней листьев Hemerocallis fulva.

Рисунок 15. Сравнение показателей обнаружения четырех типичных образцов болезней. (a) Листовая гниль; (b) Антракноз; (c) Листовая пятнистость; (d) Ржавчина.

Таблица 6. Сравнение точности обнаружения в различных моделях для различных болезней.
Для дальнейшей проверки производительности HF-MSENet были сравнены кривые обучения по различным показателям. Рисунок 16 отображает кривые обучения модели, при этом панели (a–d) показывают кривые исходной модели для F1 Confidence, P Confidence, P-R и R Confidence, а панели (e–h) представляют соответствующие кривые для HF-MSENet. Кривая F1-Confidence показывает, что HF-MSENet достигает F1-меры 0,93 при пороге достоверности 0,261, превосходя показатель исходной модели 0,91 при 0,268, что указывает на лучший баланс между P и R. На кривой Precision–Confidence HF-MSENet достигает значения точности 1,00 при достоверности 0,921, в то время как исходная модель достигает того же значения при более низкой достоверности 0,905, выделяя преимущество HF-MSENet в снижении ложноположительных результатов. Кривая Precision–Recall дальше демонстрирует, что HF-MSENet сохраняет более высокую точность при различных значениях полноты. На кривой R-Confidence HF-MSENet демонстрирует более высокую полноту в области низкой достоверности, достигая полноты 0,96 при достоверности 0,000, по сравнению с полнотой исходной модели 0,95. Эти результаты подтверждают устойчивость и превосходную производительность HF-MSENet на сложном фоне и при обнаружении множественных болезней.
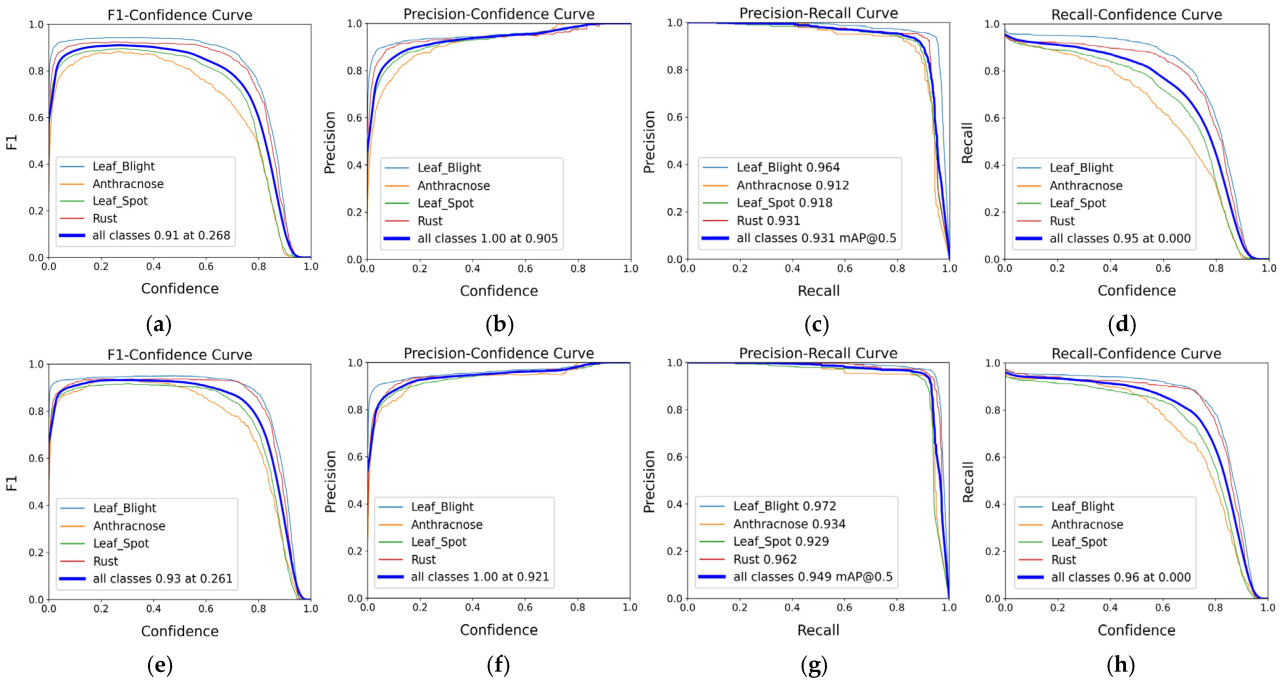
Рисунок 16. Сравнение результатов обнаружения в различных моделях и по различным показателям. (a) Кривая F1 confidence исходной модели; (b) Кривая P confidence исходной модели; (c) Кривая P - R исходной модели; (d) Кривая R confidence исходной модели; (e) Кривая F1 confidence HF-MSENet; (f) Кривая P confidence HF-MSENet; (g) Кривая P - R HF-MSENet; (h) Кривая R confidence HF-MSENet.
Рисунок 17a иллюстрирует изменения точности различных моделей в зависимости от эпох обучения. Базовая модель показывает медленные улучшения точности с более низкими значениями на каждой эпохе. Напротив, модели, интегрирующие улучшенные модули, демонстрируют различные уровни улучшения. Модуль CSMSM приводит к быстрому росту на ранних этапах, улучшая фокус на ключевых областях и извлечение признаков. Модуль C3_EMSCP улучшает производительность на средних и поздних этапах, оптимизируя многомасштабное слияние признаков. Модуль DySample ускоряет рост на поздних этапах, уменьшая потерю деталей. При комбинировании модулей наблюдается быстрый рост на ранних этапах и более высокая конечная точность, что предполагает синергетические улучшения. HF-MSENet, интегрирующая все модули, достигает самой высокой точности при стабилизации. Рисунок 17b представляет сравнение значений mAP@50 в различных моделях. Аналогично, значения увеличиваются с эпохами обучения, показывая быстрый ранний рост, за которым следует более медленное увеличение. Базовая модель имеет более низкие значения mAP@50 с более медленным ростом, в то время как модели, включающие CSMSM, повышают точность обнаружения целей. C3_EMSCP улучшает рост на средних и поздних этапах, оптимизируя многомасштабное слияние признаков, в то время как DySample ускоряет рост на поздних этапах, улучшая обработку границ и деталей. Комбинации двух модулей приводят к значительным улучшениям производительности, при этом HF-MSENet, интегрирующая все преимущества модулей, достигает самого высокого значения mAP@50 при стабилизации. Оба рисунка демонстрируют, что внедрение конкретных модулей и их комбинаций улучшает производительность модели, при этом HF-MSENet показывает явное общее преимущество.
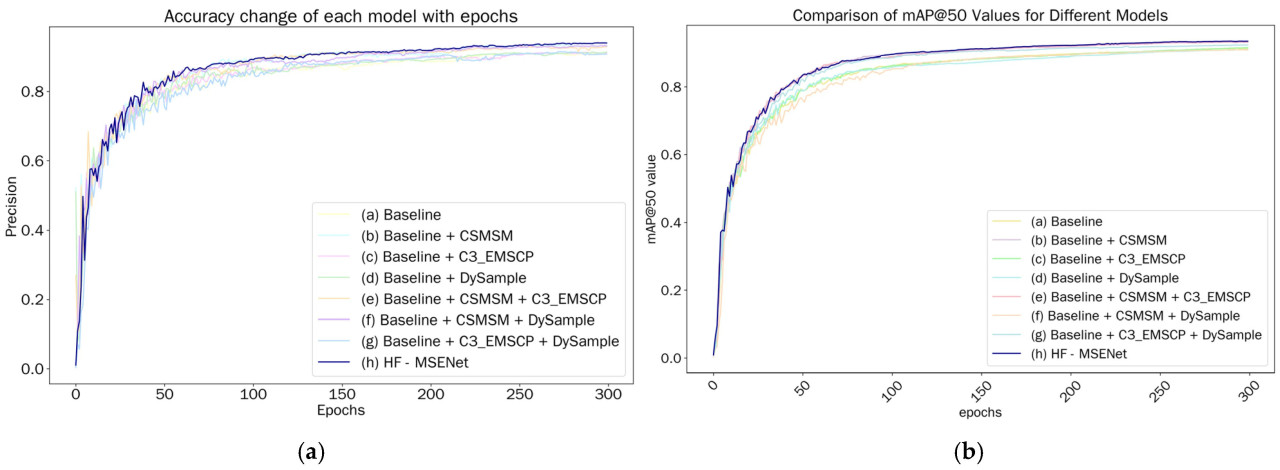
Рисунок 17. Сравнение показателей точности и mAP@50 в различных моделях. (a) Изменение точности каждой модели с эпохами; (b) Сравнение значения mAP@50 каждой модели с эпохами.
Сравнение матриц ошибок показывает, что HF-MSENet значительно превосходит базовую модель в классификации болезней. Доля ложноположительных результатов для Leaf_Blight снизилась, а точность обнаружения Anthracnose и Leaf_Spot улучшилась с 0,87 и 0,89 до 0,93 и 0,92 соответственно. Доля ложноположительных результатов на фоне заметно снизилась. Кроме того, точность обнаружения Rust увеличилась с 0,93 до 0,94, при этом доля ложноположительных результатов на фоне осталась стабильной. Эти результаты демонстрируют, что оптимизация с помощью модулей CSMSM, C3_EMSCP и DySample повысила устойчивость модели, уменьшила фоновый шум и усилила классификацию болезней и их локализацию на сложном фоне. Сравнение матриц ошибок обучения показано на Рисунке 18.
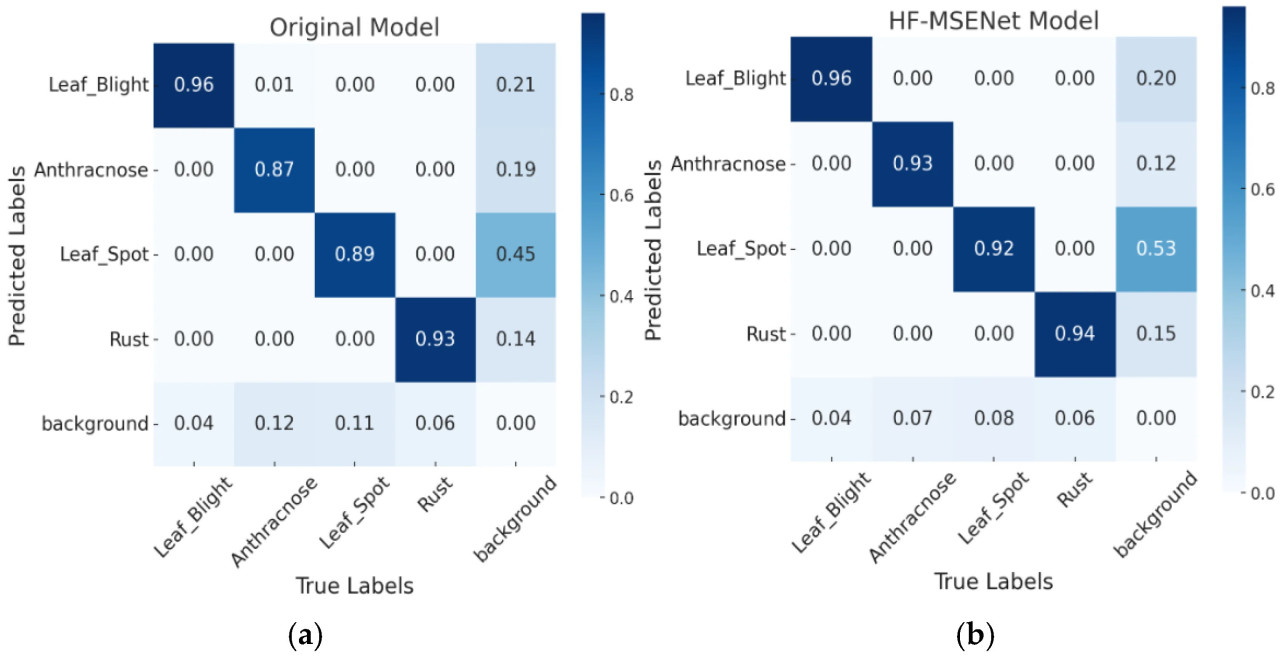
Рисунок 18. Сравнение матриц ошибок в различных моделях. (a) Матрица ошибок исходной модели; (b) Матрица ошибок модели HF-MSENet.
Таким образом, HF-MSENet демонстрирует исключительную производительность по множеству оценочных показателей. Абляционные исследования подтвердили критическую роль модулей CSMSM, C3_EMSCP и DySample в извлечении, слиянии и реконструкции признаков. Визуализации тепловых карт проиллюстрировали точный фокус модели на областях болезней и ее способность подавлять фоновые помехи. Анализ точности обнаружения и кривых показателей выделил ее отличную эффективность обучения и высокую точность обнаружения. Кроме того, матрица ошибок подтвердила устойчивость модели и низкую долю ложноположительных результатов в задачах классификации и локализации. В целом, HF-MSENet превосходит все аспекты обнаружения болезней, полностью подтверждая свою эффективность и практичность.
3.1.3. Сравнительный эксперимент
Для всесторонней оценки производительности модели HF-MSENet при обнаружении болезней листьев Hemerocallis fulva было выбрано несколько широко валидированных моделей обнаружения объектов для сравнения. Эти модели служили эталонными ориентирами, предоставляя надежную основу для оценки производительности HF-MSENet и выделяя ее преимущества на сложном фоне и при многомасштабном обнаружении болезней. Результаты обнаружения для каждой модели на валидационном наборе показаны в Таблице 7.
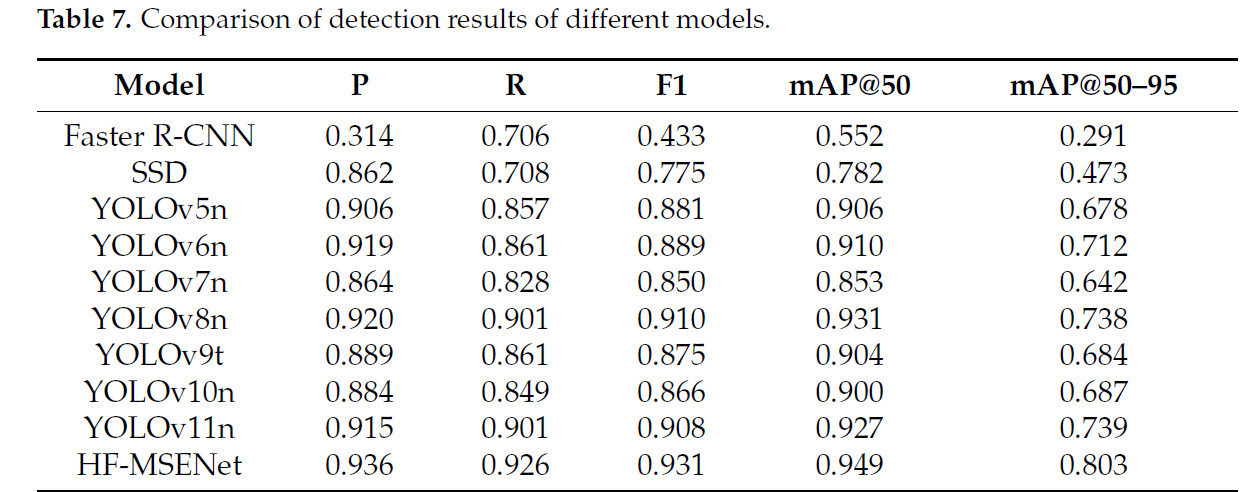
Таблица 7. Сравнение результатов обнаружения различных моделей.
Экспериментальные результаты показывают, что Faster R-CNN демонстрировала относительно низкую производительность обнаружения, в первую очередь из-за помех фонового шума во время извлечения признаков и генерации областей-кандидатов. Это ограничивало ее эффективность при обнаружении малозаметных болезней и выполнении многомасштабных задач. Модель SSD показала приемлемую производительность с точки зрения точности и mAP@50, но ее mAP@50–95 составил всего 0,473, выделяя ее ограничения в обнаружении малозаметных болезней и достижении высокой точности. Среди серии YOLO, YOLOv5n и YOLOv6n обеспечили лучший баланс между точностью и полнотой. Однако YOLOv7n показала снижение точности с mAP@50 всего 0,853, что указывает на трудности в обнаружении областей болезней. YOLOv8n показала наилучшую производительность с mAP@50 0,931, но ее mAP@50–95 составил всего 0,738, что показывает ограничения в реконструкции малозаметных признаков болезней. YOLOv9t, YOLOv10n и YOLOv11n продемонстрировали ограниченные улучшения в высокоточном обнаружении, с лишь незначительным увеличением mAP@50–95, сохраняя умеренную общую производительность. Напротив, предложенная HF-MSENet превзошла все модели по ключевым показателям, достигнув самой высокой производительности со значением P 0,936, F1-мерой 0,931, mAP@50 0,949 и прорывным mAP@50–95 0,803. Эти результаты ясно демонстрируют значительную синергетическую оптимизацию модулей HF-MSENet, подтверждая ее превосходную производительность при обнаружении болезней листьев Hemerocallis fulva.
3.1.4. Обсуждение сравнительного эксперимента
Для оценки производительности модели во время обучения были построены кривые изменения mAP@50 с интервалами в 10 эпох, чтобы выделить скорость сходимости и конечную точность (Рисунок 19). Также были построены радиолокационные диаграммы на основе P, R, F1-меры, mAP@50 и mAP@50–95 для иллюстрации общего распределения производительности (Рисунок 19).
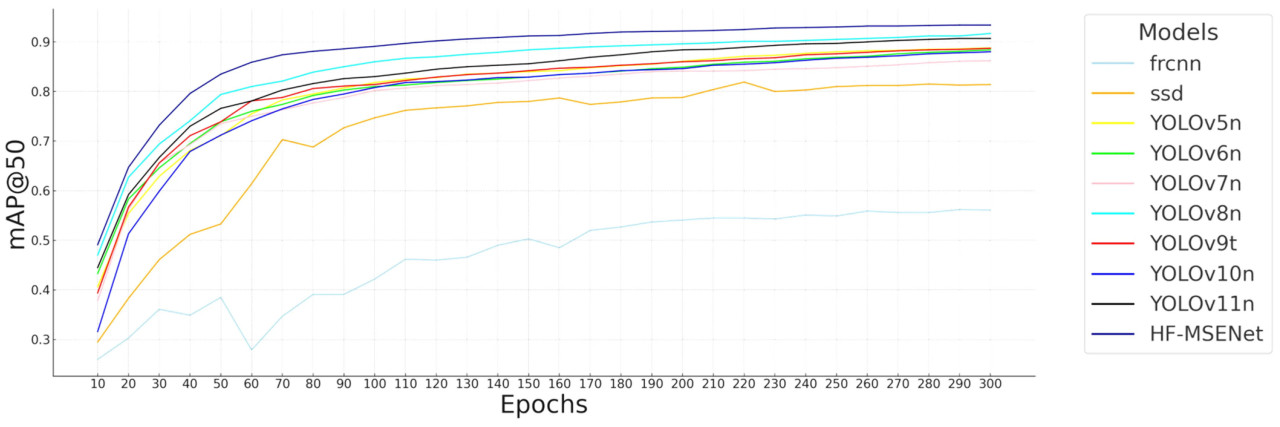
Рисунок 19. Сравнение изменения mAP@50 с эпохами обучения для различных моделей.
Рисунок 18 показывает, что HF-MSENet стабильно превосходит все сравниваемые модели. На ранних и средних этапах обучения (эпохи с 10 по 150) ее кривая mAP@50 быстро растет, демонстрируя высокую эффективность обучения и эффективное извлечение признаков для болезней листьев Hemerocallis fulva. К 50-й эпохе HF-MSENet достигает mAP@50 0,835, превосходя YOLOv8n (0,794), YOLOv5n (0,711) и YOLOv6n (0,739), выделяя эффективность модулей CSMSM и C3_EMSCP в извлечении признаков и многомасштабном слиянии. Напротив, Faster R-CNN показывает самую слабую начальную производительность с mAP@50 всего 0,260 на 10-й эпохе и значительными колебаниями во время раннего обучения, что указывает на более медленную сходимость и ограниченную способность к обучению. Хотя SSD немного превосходит Faster R-CNN, его общая производительность остается ниже, чем у моделей YOLO, в частности наблюдается стагнация на среднем этапе обучения (эпохи с 50 по 150). YOLOv8n достигает более высокого начального mAP@50 0,470 на 10-й эпохе, но ее рост замедляется, достигая 0,917 на 300-й эпохе, что все еще отстает от HF-MSENet. YOLOv5n и YOLOv6n показывают схожие тенденции с конечными значениями mAP@50 0,888 и 0,884 соответственно, оба ниже, чем у HF-MSENet.
На протяжении всего обучения HF-MSENet не только сходится быстрее, но и достигает большей стабильности на поздних этапах (после 150 эпох). К 300-й эпохе ее mAP@50 достигает 0,934, значительно превосходя все другие модели, что подчеркивает ее устойчивость и превосходную производительность в сложных условиях.
Как показано на радиолокационной диаграмме на Рисунке 20, HF-MSENet занимает наибольшую площадь, образуя высоко сбалансированную пятиугольную структуру. Это указывает на выдающуюся производительность по всем показателям, в частности по mAP@50 и mAP@50–95, где она достигает 0,949 и 0,803 соответственно, значительно превосходя другие модели. Это демонстрирует ее высокую способность к обнаружению болезней и устойчивость.
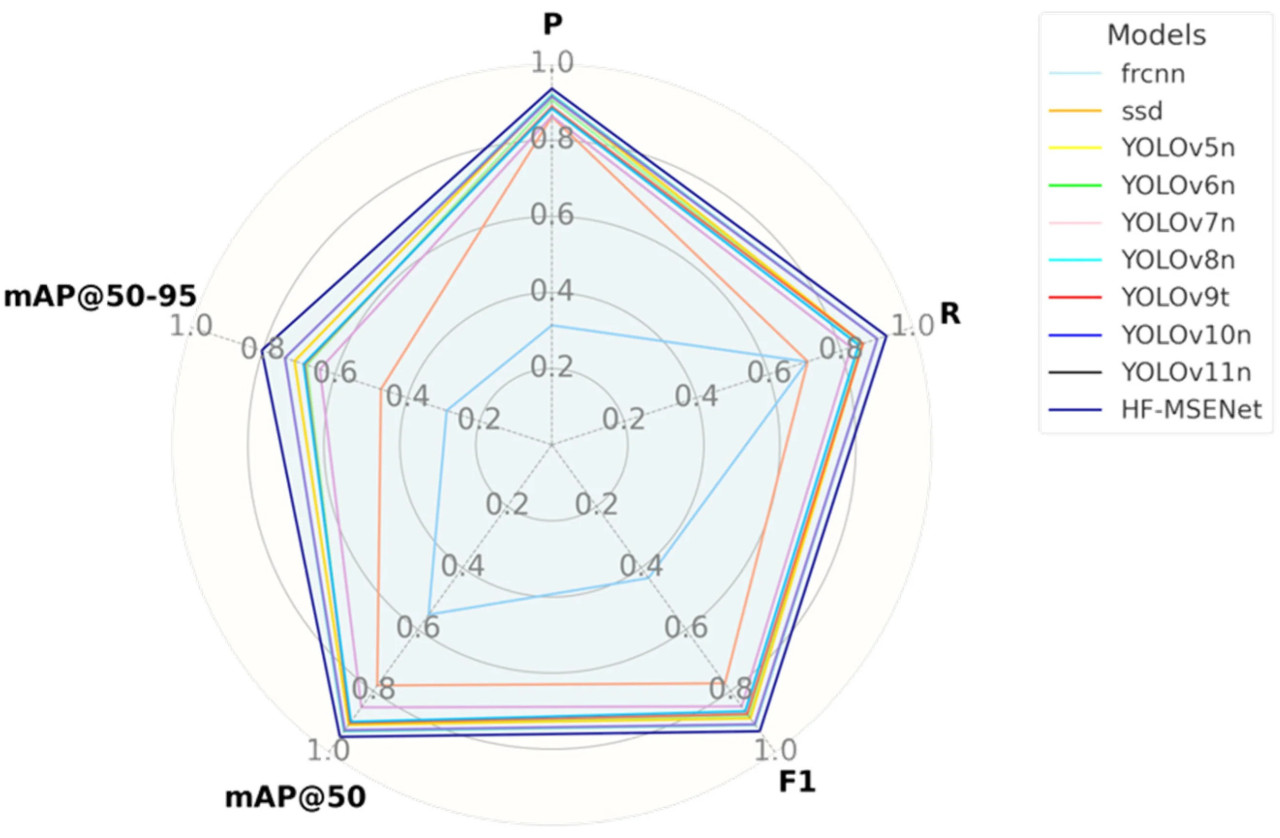
Рисунок 20. Сравнение радиолокационных диаграмм результатов обнаружения в различных моделях и по различным показателям.
Напротив, радиолокационная диаграмма для Faster R-CNN показывает явную асимметрию с относительно низкими значениями P и F1, составляющими 0,314 и 0,433 соответственно. Это отражает ее уязвимость к шумовым помехам на сложном фоне, что затрудняет точное обнаружение областей болезней. Радиолокационная диаграмма SSD демонстрирует структуру «одностороннего сдвига», где значение P достигает 0,862, но ее mAP@50–95 составляет всего 0,473, что показывает ее ограничения в высокоточных задачах.
Среди моделей серии YOLO радиолокационные диаграммы YOLOv5n, YOLOv6n и YOLOv8n относительно близки по форме к HF-MSENet, с высокими значениями P, R и mAP@50. Например, YOLOv8n достигает mAP@50 0,931, что близко к HF-MSENet, но ее mAP@50–95 составляет всего 0,738, что указывает на то, что ее производительность в высокоточных задачах остается немного ниже. Более поздние версии, такие как YOLOv9t, YOLOv10n и YOLOv11n, показывают улучшения по некоторым показателям, но демонстрируют заметные колебания в общей форме радиолокационной диаграммы, не превосходя HF-MSENet.
Радиолокационная диаграмма HF-MSENet высоко сбалансирована без значительного сжатия. Она достигает самых высоких значений P, R и F1, достигая 0,936, 0,926 и 0,931 соответственно. Это дальше подтверждает ее исключительную производительность в точной локализации и высокой точности обнаружения. Значительное преимущество в mAP@50 и mAP@50–95 выделяет способность модели к извлечению признаков и многомасштабному слиянию на сложном фоне. В целом, сбалансированная радиолокационная диаграмма и лидирующие показатели подтверждают практическую ценность HF-MSENet при обнаружении сложных болезней.
3.2. Обсуждение ограничений и будущих направлений
Несмотря на значительный успех модели HF-MSENet в обнаружении болезней листьев Hemerocallis fulva, остается несколько ограничений. Во-первых, текущий набор данных HFLD-Dataset не полностью охватывает все вариации болезней листьев Hemerocallis fulva, что ограничивает обобщающую способность модели, в частности в новых сценариях с неизвестными образцами болезней или новыми вариациями болезней. Во-вторых, хотя модель работает отлично, ее сложная сетевая архитектура увеличивает вычислительные требования, ограничивая ее развертывание и применение в реальном времени на мобильных и встраиваемых устройствах.
По сравнению с другими связанными исследованиями, большинство существующих исследований в основном фокусировались на основных культурах, таких как яблоки и рис, в то время как наше исследование направлено на садовые растения, такие как Hemerocallis fulva. Отсутствует прямое сравнение с точки зрения производительности модели на различных типах культур. Например, при обнаружении болезней пшеницы, кукурузы и соевых бобов другие модели могут иметь различные уровни производительности и сталкиваться с различными проблемами. Это указывает на то, что существует необходимость в дальнейшем изучении применимости нашей модели к более широкому кругу культур.
Будущие исследования должны изучить следующие направления. Во-первых, расширение набора данных с точки зрения размера и разнообразия для включения образцов из различных климатических условий, регионов и новых вариаций болезней улучшит адаптируемость и точность модели в различных средах. Во-вторых, исследование методов оптимизации моделей, таких как pruning и дистилляция знаний, могло бы улучшить эффективность обнаружения и обеспечить применение в реальном времени. Кроме того, было бы ценно протестировать модель HF-MSENet на других важных культурах, таких как пшеница, кукуруза и соевые бобы, чтобы оценить ее производительность и потенциал для обобщения. Это предоставило бы более полное понимание возможностей модели и ее потенциала для вклада в область автоматизированного распознавания болезней различных сельскохозяйственных растений.
В заключение, HF-MSENet демонстрирует явные преимущества в фокусировке на областях болезней, слиянии признаков и точности обнаружения, предоставляя эффективное решение для обнаружения болезней Hemerocallis fulva. Ожидается, что будущие усилия по расширению набора данных, внедрению легковесных конструкций и включению многомодального слияния обеспечат ее более широкое развертывание в практических приложениях, предоставляя ценную техническую поддержку для управления здоровьем Hemerocallis fulva и развития интеллектуального сельского хозяйства.
4. Выводы
Чтобы решить проблемы обнаружения болезней листьев Hemerocallis fulva на сложном фоне и в многомасштабных сценариях, в этом исследовании была предложена HF-MSENet — высокоточная модель обнаружения объектов. Используя высококачественный набор данных HFLD-Dataset и инновационные модули (CSMSM, C3_EMSCP и DySample), модель улучшает внимание к критическим областям, многомасштабное слияние признаков и реконструкцию деталей, что значительно повышает точность и устойчивость.
Экспериментальные результаты показывают, что HF-MSENet достигла точности, полноты и значения mAP@50 на уровне 93,6%, 92,6% и 94,9% на HFLD-Dataset, превзойдя базовую модель на 1,6%, 2,5% и 1,8% соответственно. Модель превзошла других по mAP@50–95, достигнув 80,3%, что на 6,5% выше. Визуализации тепловых карт подтвердили фокус модуля CSMSM на ключевых областях болезней, эффективность модуля C3_EMSCP в многомасштабном слиянии признаков и улучшение модулем DySample реконструкции мелкозернистых признаков. Кроме того, модель улучшила локализацию болезней и точность обнаружения, сократив ложноположительные и ложноотрицательные результаты по всем типам болезней.
По сравнению с основными моделями обнаружения объектов, такими как YOLOv8n и Faster R-CNN, HF-MSENet достигла превосходной производительности с точки зрения точности обнаружения, полноты и показателей при высоких порогах IoU, демонстрируя свою эффективность и применимость.
В целом, HF-MSENet поддерживает высокую точность обнаружения, одновременно оптимизируя вычислительную эффективность благодаря модульной конструкции, что делает ее высокоприменимой. Эта модель предоставляет надежное решение для точного обнаружения и классификации болезней листьев Hemerocallis fulva и показывает большой потенциал для систем реального мониторинга болезней и защиты растений, способствуя прогрессу в управлении здоровьем садовых культур и интеллектуальных сельскохозяйственных технологиях.
Ссылка
1. Hirota, S.K.; Yasumoto, A.A.; Nitta, K.; Tagane, M.; Miki, N.; Suyama, Y.; Yahara, T. Evolutionary history of Hemerocallis in Japan inferred from chloroplast and nuclear phylogenies and levels of interspecific gene flow. Mol. Phylogenetics Evol. 2021, 164, 107264. [Google Scholar] [CrossRef] [PubMed]
2. Li, S.; Ji, F.; Hou, F.; Shi, Q.; Xing, G.; Chen, H.; Weng, Y.; Kang, X. Morphological, palynological and molecular assessment of Hemerocallis core collection. Sci. Hortic. 2021, 285, 110181. [Google Scholar] [CrossRef]
3. Bortolini, L.; Zanin, G. Hydrological behaviour of rain gardens and plant suitability: A study in the Veneto plain (north-eastern Italy) conditions. Urban For. Urban Green. 2018, 34, 121–133. [Google Scholar] [CrossRef]
4. Szewczyk, K.; Kalemba, D.; Miazga-Karska, M.; Krzemińska, B.; Dąbrowska, A.; Nowak, R. The essential oil composition of selected Hemerocallis cultivars and their biological activity. Open Chem. 2019, 17, 1412–1422. [Google Scholar] [CrossRef]
5. Liang, Y.; Huang, R.; Chen, Y.; Zhong, J.; Deng, J.; Wang, Z.; Wu, Z.; Li, M.; Wang, H.; Sun, Y. Study on the sleep-improvement effects of Hemerocallis citrina Baroni in Drosophila melanogaster and targeted screening to identify its active components and mechanism. Foods 2021, 10, 883. [Google Scholar] [CrossRef]
6. Li, X.; Jiang, S.; Cui, J.; Qin, X.; Zhang, G. Progress of genus Hemerocallis in traditional uses, phytochemistry, and pharmacology. J. Hortic. Sci. Biotechnol. 2022, 97, 298–314. [Google Scholar] [CrossRef]
7. Sandri, E.; Werner, L.U.; Bernalte Martí, V. Lifestyle Habits and Nutritional Profile of the Spanish Population: A Comparison Between the Period During and After the COVID-19 Pandemic. Foods 2024, 13, 3962. [Google Scholar] [CrossRef] [PubMed]
8. Li, L.; Qu, Y.-t.; Han, H.; Tang, H.-w.; Chen, F.; Xiong, Y. Effects of Plant Growth Regulators on Adventitious Bud Induction and Proliferation of Hemerocallis fulva; Northeast Forestry University: Harbin, China, 2021. [Google Scholar]
9. Yu, Y.; Hu, J.; Wa, J.; Zhang, Z. The control effect of combination of fertilizer and medicine on daylily leaf streak of Hemerocallis fulva. J. Technol. 2023, 23, 177–181. [Google Scholar]
10. Zhao, T.-R.; Xu, Z.-H.; Zhang, C.-H.; Wang, J.-J.; Guo, F.-Q.; Ye, Q.-M. Evaluation on Waterlogging Tolerance of Hemerocallis Fulva in Field; Jiangxi Academy of Agricultural Sciences: Nanchang, China, 2021. [Google Scholar]
11. Ye, J. Pedro de la Piñuela’s Bencao Bu and the Cultural Exchanges between China and the West. Religions 2024, 15, 343. [Google Scholar] [CrossRef]
12. Dhingra, G.; Kumar, V.; Joshi, H. Study of digital image processing techniques for leaf disease detection and classification. Multimed. Tools Appl. 2018, 77, 19951–20000. [Google Scholar] [CrossRef]
13. Keivani, M.; Mazloum, J.; Sedaghatfar, E.; Tavakoli, M. Automated analysis of leaf shape, texture, and color features for plant classification. Trait. Du Signal 2020, 37, 17–28. [Google Scholar] [CrossRef]
14. Mahmud, M.S.; Chang, Y.K.; Zaman, Q.U.; Esau, T.J. Detection of strawberry powdery mildew disease in leaf using image texture and supervised classifiers. In Proceedings of the CSBE/SCGAB 2018 Annual Conference, Guelph, ON, USA, 22–25 July 2018; pp. 22–25. [Google Scholar]
15. Xie, C.; He, Y. Spectrum and image texture features analysis for early blight disease detection on eggplant leaves. Sensors 2016, 16, 676. [Google Scholar] [CrossRef]
16. Nashrullah, F.H.; Suryani, E.; Salamah, U.; Prakisya, N.P.; Setyawan, S. Texture-Based Feature Extraction Using Gabor Filters to Detect Diseases of Tomato Leaves. Rev. D’intelligence Artif. 2021, 35, 331. [Google Scholar]
17. Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf image-based plant disease identification using color and texture features. Wirel. Pers. Commun. 2021, 121, 1139–1168. [Google Scholar] [CrossRef]
18. Wang, M.; Guo, S.; Niu, X. surveys. Detect. Wheat Leaf Disease. Appl. Int. J. Res. 2015, 6, 1669–1675. [Google Scholar]
19. Gangshan, W.; Yinlong, F.; Qiyou, J.; Ming, C.; Na, L.; Yunmeng, O.; Zhihua, D.; Baohua, Z. Early identification of strawberry leaves disease utilizing hyperspectral imaging combing with spectral features, multiple vegetation indices and textural features. Comput. Electron. Agric. 2023, 204, 107553. [Google Scholar]
20. Aditi, S.; Harjeet, K. Potato Plant Leaves Disease Detection and Classification using Machine Learning Methodologies. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1022, 012121. [Google Scholar]
21. Sen, Z.; Yun, F.; Jiang-nan, C.; Ye, L.; Xu-dong, D.; Yong-liang, L. Application of hyperspectral imaging in the diagnosis of acanthopanax senticosus black spot disease. Spectrosc. Spectr. Anal. 2021, 41, 1898–1904. [Google Scholar]
22. Devi, K.S.; Srinivasan, P.; Bandhopadhyay, S. H2K–A robust and optimum approach for detection and classification of groundnut leaf diseases. Comput. Electron. Agric. 2020, 178, 105749. [Google Scholar] [CrossRef]
23. Zhao, J.; Fang, Y.; Chu, G.; Yan, H.; Hu, L.; Huang, L. Identification of leaf-scale wheat powdery mildew (Blumeria graminis f. sp. Tritici) combining hyperspectral imaging and an SVM classifier. Plants 2020, 9, 936. [Google Scholar] [CrossRef] [PubMed]
24. Maheswaran, S.; Sathesh, S.; Rithika, P.; Shafiq, I.M.; Nandita, S.; Gomathi, R. Detection and classification of paddy leaf diseases using deep learning (cnn). In Proceedings of the International Conference on Computer, Communication, and Signal Processing, Chennai, India, 24–25 February 2022; pp. 60–74. [Google Scholar]
25. Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
26. Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
27. Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
28. Farhadi, A.; Redmon, J. Yolov3: An Incremental Improvement; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
29. Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
30. Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
31. Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
32. Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–21. [Google Scholar]
33. Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
34. Khanam, R.; Hussain, M.J. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
35. Tian, L.; Zhang, H.; Liu, B.; Zhang, J.; Duan, N.; Yuan, A.; Huo, Y. Bioinformatics. VMF-SSD: A Novel v-space based multi-scale feature fusion SSD for apple leaf disease detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 20, 2016–2028. [Google Scholar]
36. Deari, S.; Ulukaya, S. Engineering. A hybrid multistage model based on YOLO and modified inception network for rice leaf disease analysis. Arab. J. Sci. Eng. 2024, 49, 6715–6723. [Google Scholar] [CrossRef]
37. Wang, J.; Qin, C.; Hou, B.; Yuan, Y.; Zhang, Y.; Feng, W. LCGSC-YOLO: A lightweight apple leaf diseases detection method based on LCNet and GSConv module under YOLO framework. Front. Plant Sci. 2024, 15, 1398277. [Google Scholar] [CrossRef] [PubMed]
38. Kumar, V.S.; Jaganathan, M.; Viswanathan, A.; Umamaheswari, M.; Vignesh, J.J. Rice leaf disease detection based on bidirectional feature attention pyramid network with YOLO v5 model. Environ. Res. Commun. 2023, 5, 065014. [Google Scholar] [CrossRef]
39. He, Y.; Peng, Y.; Wei, C.; Zheng, Y.; Yang, C.; Zou, T. Automatic Disease Detection from Strawberry Leaf Based on Improved YOLOv8. Plants 2024, 13, 2556. [Google Scholar] [CrossRef]
40. Xie, Z.; Li, C.; Yang, Z.; Zhang, Z.; Jiang, J.; Guo, H. YOLOv5s-BiPCNeXt, a Lightweight Model for Detecting Disease in Eggplant Leaves. Plants 2024, 13, 2303. [Google Scholar] [CrossRef]
41. Zhu, S.; Ma, W.; Wang, J.; Yang, M.; Wang, Y.; Wang, C. EADD-YOLO: An efficient and accurate disease detector for apple leaf using improved lightweight YOLOv5. Front. Plant Sci. 2023, 14, 1120724. [Google Scholar] [CrossRef] [PubMed]
42. Yan, C.; Yang, K. FSM-YOLO: Apple leaf disease detection network based on adaptive feature capture and spatial context awareness. Digit. Signal Process. 2024, 155, 104770. [Google Scholar] [CrossRef]
43. Abdullah, A.; Amran, G.A.; Tahmid, S.A.; Alabrah, A.; AL-Bakhrani, A.A.; Ali, A. A deep-learning-based model for the detection of diseased tomato leaves. Agronomy 2024, 14, 1593. [Google Scholar] [CrossRef]
44. Xu, W.; Wang, R. ALAD-YOLO: An lightweight and accurate detector for apple leaf diseases. Front. Plant Sci. 2023, 14, 1204569. [Google Scholar]
45. Bandi, R.; Swamy, S.; Arvind, C.S. Leaf disease severity classification with explainable artificial intelligence using transformer networks. Int. J. Adv. Technol. Eng. Explor. 2023, 10, 278. [Google Scholar]
46. Brownlee, J. Deep Learning for Computer Vision: Image Classification, Object Detection, and Face Recognition in Python; Machine Learning Mastery: Melbourne, Australia, 2019. [Google Scholar]
47. Wang, R.; Wang, Z.; Xu, Z.; Wang, C.; Li, Q.; Zhang, Y.; Li, H. A Real-Time Object Detector for Autonomous Vehicles Based on YOLOv4. Comput. Intell. Neurosci. 2021, 2021, 9218137. [Google Scholar] [CrossRef] [PubMed]
48. Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; pp. 529–545. [Google Scholar]
49. Wang, S.-H.; Fernandes, S.L.; Zhu, Z.; Zhang, Y.-D. Attention-based VGG-style network for COVID-19 diagnosis by CBAM. IEEE Sens. J. 2021, 22, 17431–17438. [Google Scholar] [CrossRef] [PubMed]
50. Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
51. Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
52. Wang, C.-Y.; Liao, H.; Wu, Y.-H.; Chen, P.-Y.; Yeh, I. A New Backbone that can Enhance Learning Capability of CNN. 2020 IEEE. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: New York, NY, USA; pp. 390–391. [Google Scholar]
53. Li, X.; Song, D.; Dong, Y. Hierarchical feature fusion network for salient object detection. IEEE Trans. Image Process. 2020, 29, 9165–9175. [Google Scholar] [CrossRef]
54. Yan, C.; Xu, E. ECM-YOLO: A real-time detection method of steel surface defects based on multiscale convolution. J. Opt. Soc. Am. A 2024, 41, 1905–1914. [Google Scholar] [CrossRef]
55. Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
56. Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 6027–6037. [Google Scholar]

Wang T, Xia H, Xie J, Li J, Liu J. A Multi-Scale Feature Focus and Dynamic Sampling-Based Model for Hemerocallis fulva Leaf Disease Detection. Agriculture. 2025; 15(3):262. https://doi.org/10.3390/agriculture15030262
Перевод статьи «A Multi-Scale Feature Focus and Dynamic Sampling-Based Model forHemerocallis fulvaLeaf Disease Detection» авторов Wang T, Xia H, Xie J, Li J, Liu J., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik

















































































































Комментарии (0)