Умное зрение для робота-садовода: DCFA-YOLO — точное обнаружение гроздей помидоров черри
Чтобы лучше использовать мультимодальную информацию для сельскохозяйственных приложений, в данной статье предлагается сеть для обнаружения гроздей черри-помидоров, использующая двуканальное перекрестное слияние признаков. Она направлена на повышение эффективности обнаружения за счет использования взаимодополняющей информации цветных и глубинных изображений.
Аннотация
Используя существующую архитектуру YOLOv8_n в качестве базовой основы, сеть включает механизм двуканального перекрестного внимания для извлечения и слияния мультимодальных признаков. В магистральной сети используется блок ShuffleNetV2 для оптимизации эффективности начального извлечения признаков. На этапе слияния признаков вводятся два модуля, использующие репараметризацию, динамическое взвешивание и эффективную конкатенацию для усиления представления мультимодальной информации. Между тем, механизм CBAM интегрируется на различных этапах извлечения признаков в сочетании с улучшенным модулем SPPF_CBAM, что позволяет эффективно повысить фокусировку и репрезентативность ключевых признаков.
Результаты экспериментов с использованием набора данных, полученных в коммерческой теплице, демонстрируют, что DCFA-YOLO превосходно справляется с обнаружением гроздей черри-помидоров, достигая показателя mAP50 в 96.5%, что является значительным улучшением по сравнению с базовой моделью, при одновременном резком снижении вычислительной сложности. Кроме того, сравнения с другими современными моделями YOLO и иными моделями обнаружения объектов подтверждают ее эффективность. Данное решение обеспечивает эффективный подход к мультимодальному слиянию для обнаружения плодов в реальном времени в контексте роботизированного сбора урожая, работая со скоростью 52 кадра в секунду на обычном компьютере.
1. Введение
С учетом старения населения мира и растущей нехватки рабочей силы в сельском хозяйстве современное сельское хозяйство сталкивается с беспрецедентными вызовами [1]. На этом фоне быстрое развитие технологий интеллектуального сельского хозяйства становится важной движущей силой содействия аграрной трансформации. Как популярный фрукт, черри-помидоры играют важную роль в мировом сельскохозяйственном производстве благодаря своему приятному вкусу и богатству ликопином [2]. Однако из-за небольших размеров и неравномерного распределения их сбор сталкивается со значительными трудностями. Существующее механическое уборочное оборудование часто пропускает плоды или ошибочно срывает листья, поскольку ему трудно точно определить местоположение плода, что затрудняет эффективное повышение эффективности и качества роботизированного сбора. Таким образом, разработка эффективного и интеллектуального распознавания и определения положения черри-помидоров является ключом к повышению эффективности производства и качества плодов.
Обнаружение плодов — один из основных компонентов роботов для сбора урожая [3]. В последние годы глубокие нейронные сети (DNN) достигли значительного прогресса в обнаружении плодов. Эти алгоритмы больше не полагаются на ручное проектирование признаков и могут автоматически изучать сложные закономерности в изображениях, эффективно преодолевая ограничения традиционных методов обнаружения плодов при столкновении со сложным освещением и фоновыми помехами. Методы обнаружения объектов на основе глубокого обучения в основном делятся на одноэтапное обнаружение и двухэтапное обнаружение. Одноэтапное обнаружение напрямую регрессирует и предсказывает ограничивающую рамку цели. Его преимуществами являются высокая скорость обнаружения и высокая эффективность, и это один из наиболее широко используемых методов. Типичные методы одноэтапного обнаружения включают серию YOLO и сеть SSD [4,5,6]. Например, Lyu et al. [Лю и др.] улучшили магистральную сеть и функцию потерь YOLOv5 в YOLOv5-CS для обнаружения и подсчета зеленых цитрусовых в садовой среде [7]. Wang et al. [Ван и др.] использовали ShuffleNet v2 в качестве улучшенной магистральной сети и внедрили механизм внимания CBAM для повышения точности обнаружения и уменьшения размера модели [8]. Gai et al. [Гай и др.] улучшили YOLOv4, объединив его с DenseNet, для обнаружения спелости мелких помидоров [9]. Zhao et al. [Чжао и др.] достигли точного обнаружения винограда и точек сбора, улучшив YOLOv4, где средняя точность обнаружения винограда достигла 93,27% [10]. Другим популярным методом одноэтапного обнаружения является модель SSD, предложенная Yuan et al. [Юань и др.] [11], которые проверили ее производительность на черри-помидорах, используя различные магистральные сети (VGG16, MobileNet, Inception V2). Кроме того, Fuentes-Peñailillo et al. [Фуэнтес-Пеньяильо и др.] предложили модель подсчета рассады, которая объединяет традиционную обработку изображений с MobileNet-SSD, достигнув максимальной точности 96% [12]. Напротив, двухэтапное обнаружение обрабатывает извлечение и классификацию областей-кандидатов в два этапа. Хотя скорость обнаружения ниже, оно показывает лучшие результаты по точности. Типичные методы двухэтапного обнаружения включают серию RCNN [13,14,15] и SPPNet [16]. Например, Hu et al. [Ху и др.] использовали Faster R-CNN в сочетании с преобразованием цветового пространства и методом нечетких множеств для реализации обнаружения ограничивающих рамок и сегментации помидоров [17]. Метод хорошо показал себя в случаях, когда края плодов были размыты или перекрывались. Song et al. [Сонг и др.] построили модель Faster R-CNN на основе VGG16 и достигли обнаружения киви при различных условиях освещения [18]. Средняя точность обнаружения достигла 87,61%. Gao et al. [Гао и др.] использовали Faster R-CNN для обнаружения и классификации яблок в четырех различных условиях роста, со средней точностью 87,9% [19].
Хотя обработка одномерных визуальных данных на основе глубокого обучения достигла значительного прогресса в обнаружении плодов, она все еще сталкивается со многими проблемами в сложных условиях. Во-первых, одномерные методы (например, обнаружение только на основе RGB) в значительной степени подвержены изменениям освещения, окклюзии и фоновому шуму, что приводит к недостаточной точности и надежности обнаружения. Например, в условиях низкой освещенности или когда плоды частично скрыты листьями, производительность этих методов значительно ухудшается. Во-вторых, большинство существующих моделей сильно зависят от крупномасштабных размеченных наборов данных, получение которых требует больших затрат труда и времени, особенно для мелких и плотно распределенных плодов, таких как черри-помидоры. В-третьих, хотя некоторые исследования пытались повысить точность обнаружения за счет увеличения сложности модели, это обычно достигается ценой повышенных вычислительных затрат, что делает их непригодными для приложений реального времени, таких как роботизированный сбор урожая. Чтобы решить эти проблемы, мультимодальная фузия постепенно стала важным перспективным направлением исследований для решения этих проблем. Особенно при сборе урожая роботы обычно оснащены несколькими датчиками, такими как цветные и глубинные камеры. Слияние информации из разных модальностей может не только повысить точность обнаружения плодов, но и улучшить способность системы адаптироваться к изменениям окружающей среды. В последние годы мультимодальные методы, объединяющие цветные (RGB) и глубинные изображения, широко используются при обнаружении плодов и достигли заметного прогресса. Tu et al. [Ту и др.] разработали модель обнаружения плодов и их спелости с использованием RGB-D изображений [20]. Их абляционный эксперимент показал, что введение глубины повысило точность обнаружения на 3,03%. Cui et al. [Цуй и др.] предложили метод обнаружения одиночных черри-помидоров, объединяющий RGB-D входные данные. RGB-изображение преобразуется в цветовое пространство LAB, а затем объединяется с картой глубины и картой нормалей, полученными из облака точек, в качестве входных данных для улучшенного YOLOv7 для обнаружения черри-помидоров [21,22]. Аналогично, Rong et al. [Жун и др.] оптимизировали YOLOv5 путем слияния RGB и глубинных изображений для улучшения обнаружения гроздей черри-помидоров [23]. Кроме того, Kaukab et al. [Каукаб и др.] использовали мультимодальные данные в качестве входных данных для YOLOv5 и эффективно снизили влияние шума глубинных изображений с помощью метода глубокой фузии с удалением нетагетного фона, достигнув точности 96,4% при обнаружении яблок [24].
Методы слияния мультимодальных изображений можно разделить на три типа: раннее слияние, среднее слияние и позднее слияние, в зависимости от того, на каком этапе обработки оно вводится. В методах раннего слияния изображения из разных модальностей непосредственно объединяются на уровне изображения перед подачей в сеть. Например, Liu et al. [Лю и др.] значительно повысили среднюю точность обнаружения киви до 90,7% путем наложения RGB и ближних инфракрасных изображений для формирования четырехмерного тензора в качестве входных данных для VGG16 [25]. Однако этот метод склонен к рассогласованию пикселей из-за смещения между изображениями разных модальностей. Напротив, позднее слияние линейно объединяет независимые прогнозы на этапе принятия решений. Sa et al. [Са и др.] объединили результаты обнаружения RGB и NIR изображений на последнем этапе сети совместного извлечения признаков Faster R-CNN и повысили точность обнаружения с 81,6% до 83,8% [26], что особенно эффективно для плодов со схожими цветами, таких как зеленый перец и дыни. Однако при позднем слиянии признаки разных модальностей не могут учиться друг у друга, что приводит к плохому взаимодействию между различными ветвями сети. Как метод слияния на уровне признаков, среднее слияние объединяет мультимодальные карты признаков и может эффективно сбалансировать глубину и эффективность интеграции признаков. Например, Wei et al. [Вэй и др.] разработали многопоточную магистральную сеть, которая включает входные цветные, инфракрасные и поляризационные изображения [27]. Используя такие операции, как соединение признаков, снижение размерности и активацию, они достигли более высокой точности распознавания целей в сложных условиях. Однако это также значительно снижает скорость вывода.
Несмотря на прогресс в области мультимодальной фузии, несколько проблем остаются нерешенными. Во-первых, методы раннего слияния часто страдают от рассогласования пикселей из-за пространственного смещения между RGB и глубинными изображениями, что приводит к неточному извлечению признаков. Во-вторых, методам позднего слияния не хватает эффективного взаимодействия между модальностями, поскольку они обрабатывают каждую модальность независимо до финального этапа принятия решений, что ограничивает их способность использовать взаимодополняющую информацию. В-третьих, методы среднего слияния, хотя и достигают лучшей интеграции признаков, часто вносят высокую вычислительную сложность, что делает их непригодными для приложений реального времени, таких как роботизированный сбор урожая. Кроме того, большинство существующих мультимодальных методов слияния не полностью используют потенциал механизмов внимания для повышения значимости ключевых признаков и подавления нерелевантной информации, что является ключевым для повышения точности обнаружения в сложных условиях. Эти ограничения подчеркивают необходимость в более эффективном и надежном подходе к мультимодальному слиянию, который может решить эти проблемы, сохраняя при этом производительность в реальном времени.
Для дальнейшей оптимизации производительности мультимодального слияния в последние годы исследователи начали внедрять механизмы внимания для выделения критической информации и уменьшения помех от нерелевантных признаков. Woo et al. [Ву и др.] внедрили самообучаемые весовые параметры в модуль CBAM, что эффективно увеличивает вес области интереса и подавляет неэффективные признаки [28]. Li et al. [Ли и др.] предложили решение, использующее DenseBlock в сочетании с механизмом внимания для достижения шумоподавления изображений при слиянии RGB и NIR изображений для задач мультимодальной сегментации [29]. Вдохновленная их работой, эта статья предлагает сеть DCFA-YOLO (Dual-Channel Cross-Fusion Attention YOLO) для удовлетворения потребностей точного и быстрого мультимодального обнаружения гроздей черри-помидоров. В частности, мы внедряем параллельный механизм внимания на этапе среднего слияния. Усиливая способность к обучению и значимость области интереса, он преодолевает помехи, вносимые смещением пикселей при раннем слиянии, и высокую независимость признаков каждой модальности при позднем слиянии. DCFA-YOLO интегрирует мультимодальные данные цветных и глубинных изображений и использует двуканальное перекрестное слияние и механизмы внимания для эффективного извлечения и слияния признаков различных модальностей. В то же время модель спроектирована с целью быть легковесной для приложений реального времени. Даже при использовании мультимодального слияния размер ее параметров остается аналогичным таковому для одномерного метода, что обеспечивает ее высокую эффективность и простоту развертывания. Дизайн этой модели не только расширяет возможности понимания и обработки мультимодальных данных, но также учитывает сохранение вычислительных ресурсов. Он предоставляет надежное и эффективное решение для точного земледелия и интеллектуального сбора плодов. Вклады этой статьи могут быть суммированы следующим образом:
1. Разработан новый метод слияния признаков для эффективного объединения признаков разных модальностей. Он интегрирует механизм внимания с двуканальным перекрестным слиянием в YOLO для сбалансированного улучшения слияния цветных и глубинных изображений, значительно повышая точность и надежность обнаружения плодов.
2. Предложен эффективный легковесный дизайн путем замены модуля C2f на блок ShuffleNetV2, оптимизирующий магистральную сеть для более быстрого и эффективного начального извлечения признаков при одновременном снижении вычислительной сложности.
3. Улучшен механизм внимания путем внедрения блока SPPF_CBAM на этап раннего извлечения признаков, что повышает способность модели фокусироваться на ключевых признаках с помощью динамического канального и пространственного внимания.
4. Предложенная DCFA-YOLO была оценена для обнаружения гроздей черри-помидоров с использованием набора данных, полученного в коммерческой теплице, достигнув mAP50 96,5%, что превосходит множество моделей YOLO, будучи при этом относительно легковесной.
Статья организована следующим образом: Раздел 1 предоставляет обзор связанных работ и существующих проблем в обнаружении плодов, а также в мультимодальном обнаружении объектов. Раздел 2 подробно описывает предложенный метод DCFA-YOLO. Раздел 3 экспериментально проверяет и анализирует эффективность DCFA-YOLO. Раздел 4 обсуждает результаты, их значение и возможные направления для будущих исследований, в то время как Раздел 5 заключает работу.
2. Предложенные методы
Предложенная DCFA-YOLO основана на модели YOLOv8_n [30]. Благодаря целенаправленным улучшениям в магистральной сети, механизме слияния признаков и механизме внимания, возможности извлечения и слияния признаков мультимодальных изображений были значительно улучшены. В то же время вычислительная сложность модели была эффективно снижена. Учитывая характерные особенности длинного хвоста распределения целей плодов в сложных условиях сбора урожая, была использована функция Distribution Focus Loss (DFL) для оптимизации способности модели фокусироваться на целях различных размеров. Это предоставило эффективное решение для задачи мультимодального обнаружения плодов. Общая структура DCFA-YOLO показана на Рисунке 1.
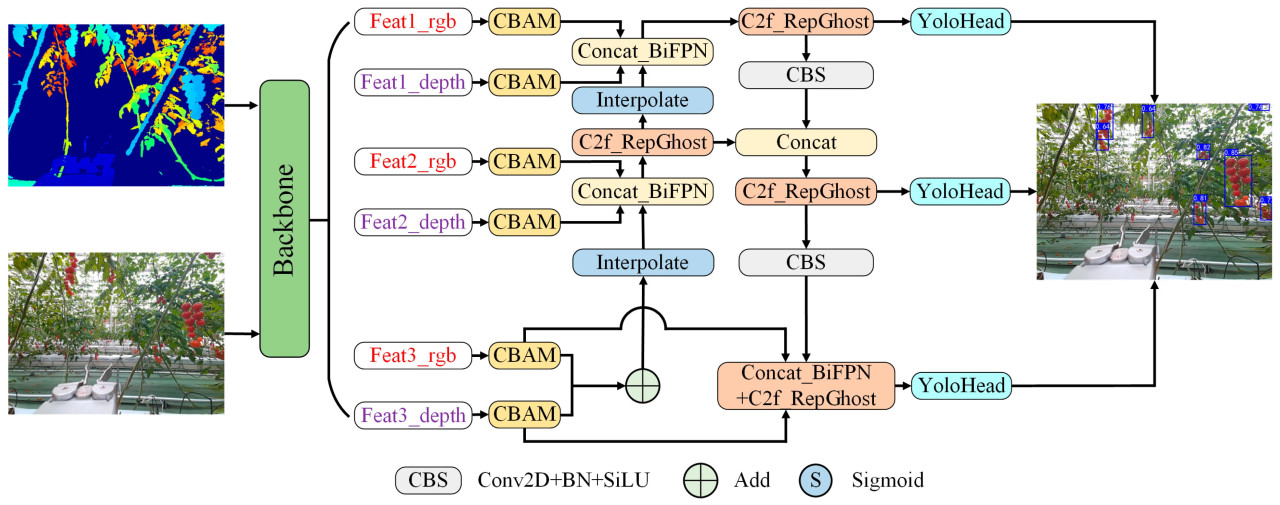
Рисунок 1. Общая архитектура предложенной DCFA-YOLO.
2.1. Механизм перекрестного слияния
Входные данные для механизма перекрестного слияния состояли из трех групп признаков, первоначально извлеченных магистральной сетью на различной глубине (Рисунок 2): две начальные модальные особенности (RGB и глубина) и одна дополнительная группа признаков, полученная сложением Feat3_rgb и Feat3_depth с последующим повышением дискретизации (апсемплингом). Эти три группы служили базовыми входами признаков для процесса перекрестного слияния. Чтобы улучшить семантическую информацию этих признаков, два базовых слоя признаков Feat3 были сначала сложены, затем подвергнуты апсемплингу и последовательно перекрестно слиты с двумя другими наборами слоев признаков. Поскольку относительно мелкие Feat1 и Feat2 содержали больше детальной информации, мы непосредственно слили независимые апсемплированные слои признаков RGB и глубины, используя модуль Concat_BiFPN.
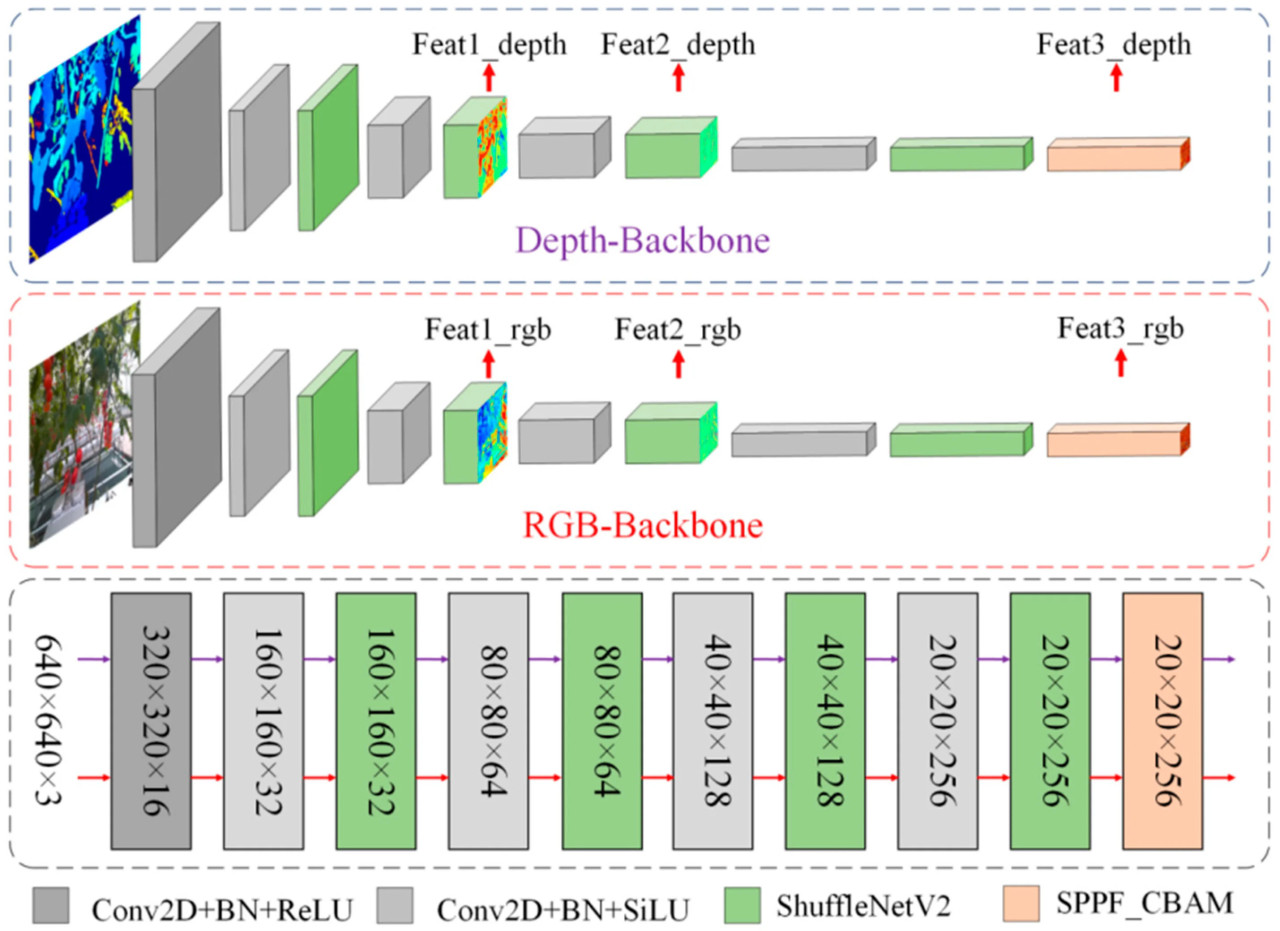
Рисунок 2. Структура магистральной сети.
Модуль Concat_BiFPN имеет много преимуществ по сравнению с традиционными BiFPN_Add и простой конкатенацией Concat [31]. Во-первых, в отличие от BiFPN_Add, Concat_BiFPN не только реализует динамическое взвешивание признаков с помощью обучаемых весовых параметров, но также сохраняет независимость каждого входного признака. BiFPN_Add непосредственно суммирует входные признаки после взвешивания, что может привести к потере деталей модальных признаков, несмотря на тесное слияние. Concat_BiFPN, с другой стороны, объединяет признаки вдоль заданного измерения с помощью взвешивания, что может не только интегрировать мультимодальную информацию, но и сохранять различия исходных признаков. Это предоставляет более богатое и полное выражение признаков для последующей обработки. Во-вторых, по сравнению с простой операцией Concat, Concat_BiFPN вводит механизм динамического взвешивания, который позволяет адаптивно регулировать вклад признаков каждой модальности в соответствии с требованиями задачи. Это преодолевает проблему дисбаланса признаков при простой конкатенации. В-третьих, Concat_BiFPN поддерживает гибкую настройку размерности и количества входных признаков, что делает его более адаптируемым.
Формула для модуля Concat_BiFPN:
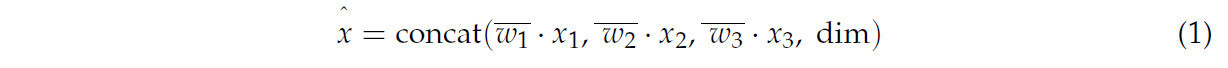
где x1, x2 и x3 — входные карты признаков из различных модальностей; (w_1 ) ̅, (w_2 ) ̅ и (w_3 ) ̅ — изученные веса, используемые для регулировки вклада признаков различных модальностей; а dim — размерность конкатенации, которая обычно может быть выбрана как канальная размерность карты признаков.
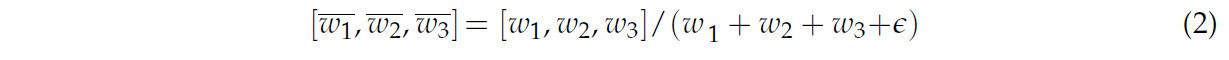
где w = [w1, w2, w3] — вектор весов, ϵ — маленькая константа, используемая для избежания деления на ноль, а значение 3 относится к трем входным модальностям (RGB, глубина и слитый признак), которые объединяются в модуле Concat_BiFPN. Нормализация гарантирует, что их вклад соответствующим образом регулируется во время слияния.
Стоит отметить, что мы использовали билинейную интерполяцию при апсемплинге для перекрестного слияния признаков. Это позволило получить более гладкое увеличение карты признаков с сохранением большего объема информации.
2.2. Упрощения модели
По сравнению с сетями, использующими одномерный вход, DCFA-YOLO использует мультимодальное перекрестное слияние и двуканальное извлечение признаков, что приводит к значительному увеличению объема вычислений. Чтобы эффективно снизить вычислительную сложность и размер параметров, сохраняя при этом высокую точность обнаружения, мы предлагаем целенаправленные оптимизации. В частности, мы заменили модуль C2f в магистрали на блок ShuffleNetV2, а модуль C2f при перекрестном слиянии признаков был заменен на C2f_RepGhost. Эти модификации были направлены на то, чтобы сбалансировать вычислительную эффективность с высококачественным извлечением признаков, учитывая различные роли этапов магистрали и слияния признаков.
Как показано на Рисунке 2, магистраль отвечает за предварительное извлечение признаков. Ее цель — извлечь глобальные признаки из входных мультимодальных данных. Чтобы снизить вычислительную сложность на этом этапе, C2f был заменен блоком ShuffleNetV2, как показано на Рисунке 3a. ShuffleNetV2 — это легковесная сверточная нейронная сеть, которая значительно снижает объем вычислений и количество параметров с помощью таких эффективных методов, как разделение каналов (Channel Split), групповые свертки и многоуровневое слияние признаков. Кроме того, перетасовка каналов (Channel Shuffle) помогла улучшить представление признаков, разрушая информационную изоляцию в групповых свертках, что приводит к более эффективному извлечению признаков с уменьшенными вычислительными затратами. Эти оптимизации позволили ShuffleNetV2 значительно снизить GFLOPs и размер параметров, сохраняя при этом относительно эффективное извлечение признаков.
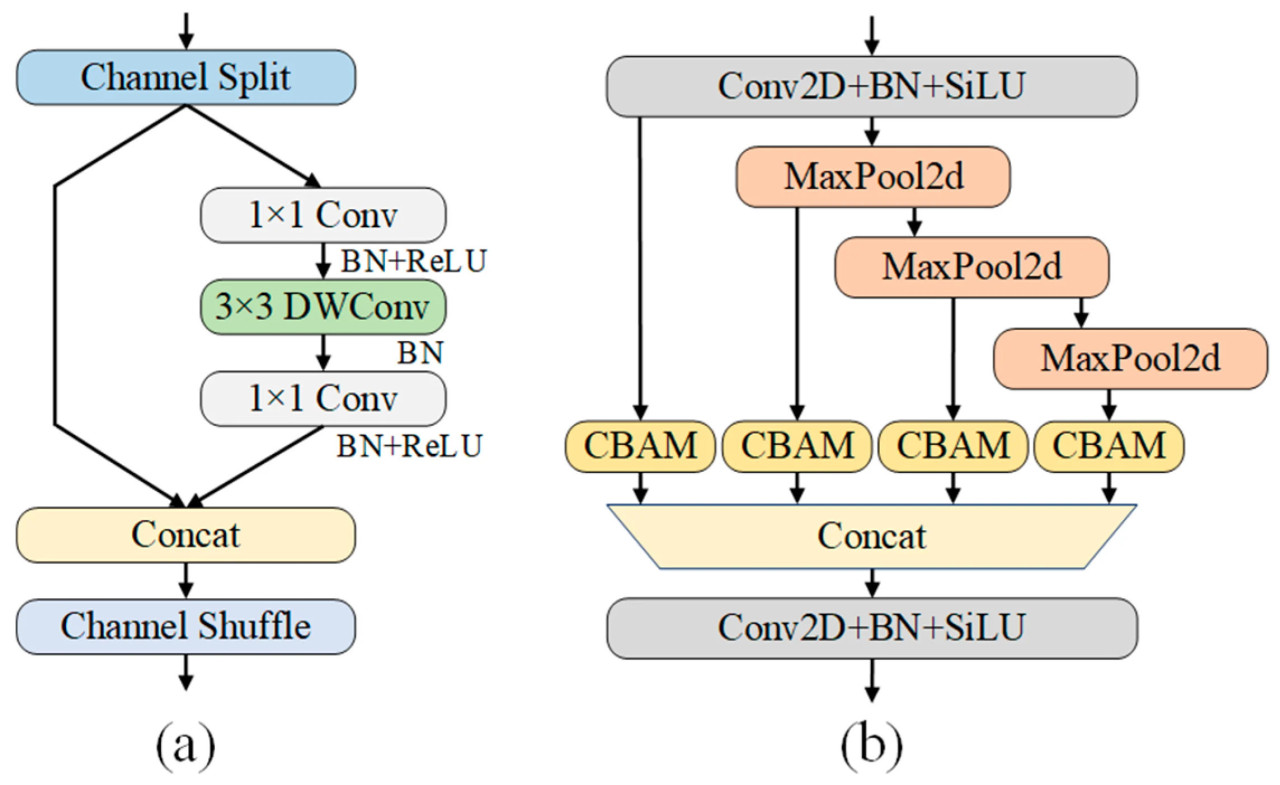
Рисунок 3. (a) Структура блока ShuffleNetV2; (b) структура блока SPPF_CBAM.
Этап перекрестного слияния признаков служит шеей сети, ключевым компонентом для улучшения извлечения признаков и повышения производительности модели. Как показано на Рисунке 4, модуль C2f был заменен модулем C2f_RepGhost на этапе перекрестного слияния признаков для достижения эффективного извлечения признаков. Он объединяет разделяемую по глубине свертку (DWConv) для пространственного извлечения признаков и поточечную свертку (PWConv) для канального взаимодействия, улучшая возможности выражения признаков при одновременном снижении вычислений. Кроме того, модуль вводит shortcut-соединения для достижения остаточного обучения, смягчая исчезновение градиента во время обучения и способствуя повторному использованию признаков. Более того, методы репараметризации во время фазы вывода объединяют сложные структуры модуля в эффективные конфигурации вывода, дополнительно снижая вычислительную сложность для вывода. Благодаря этим разработкам модуль C2f_RepGhost расширяет возможности выражения глубинных признаков, обеспечивая при этом вычислительную эффективность.
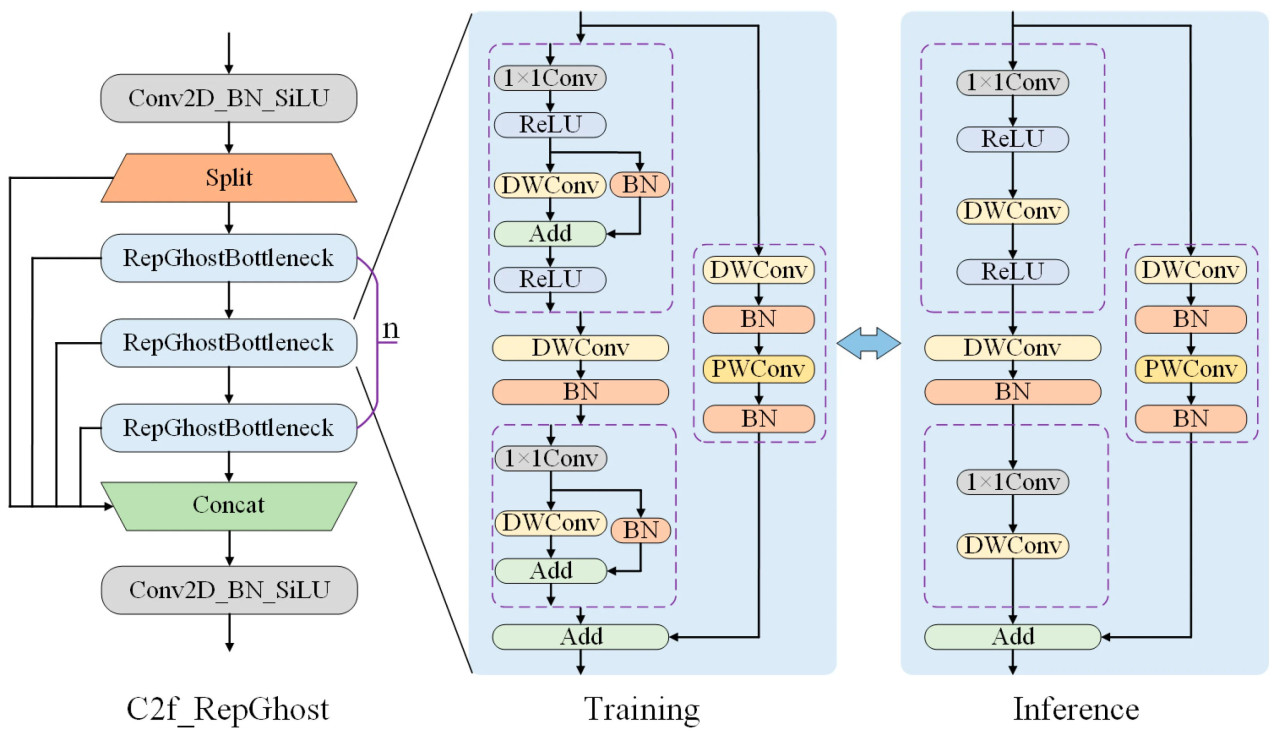
Рисунок 4. Структура модуля C2f_RepGhost. Модуль добавляет skip-соединения на этапе обучения по сравнению с этапом вывода.
Эти целенаправленные стратегии легковесного улучшения учитывают характеристики каждого этапа, чтобы максимизировать соответствующие функции магистрали и слияния признаков. Это не только удовлетворяет требованиям легкости для предварительного извлечения признаков, но и соответствует высоким требованиям к производительности для улучшенного слияния признаков.
2.3. Механизм внимания
Чтобы дальнейше повысить способность модели извлекать и сливать мультимодальные признаки, в магистральную сеть был введен механизм внимания. Улучшения отразились в оптимизации модуля SPPF и усиленном внимании на слое раннего извлечения признаков. На последнем слое магистрали исходный модуль SPPF был заменен на SPPF_CBAM, как показано на Рисунке 3b. Детали модуля CBAM показаны на Рисунке 5. Благодаря параллельным канальному и пространственному модулям внимания веса различных каналов и пространственных положений в карте признаков могут быть адаптивно скорректированы. Это усиливает ключевые признаки и подавляет избыточную информацию, улучшая способность модели выражать признаки.
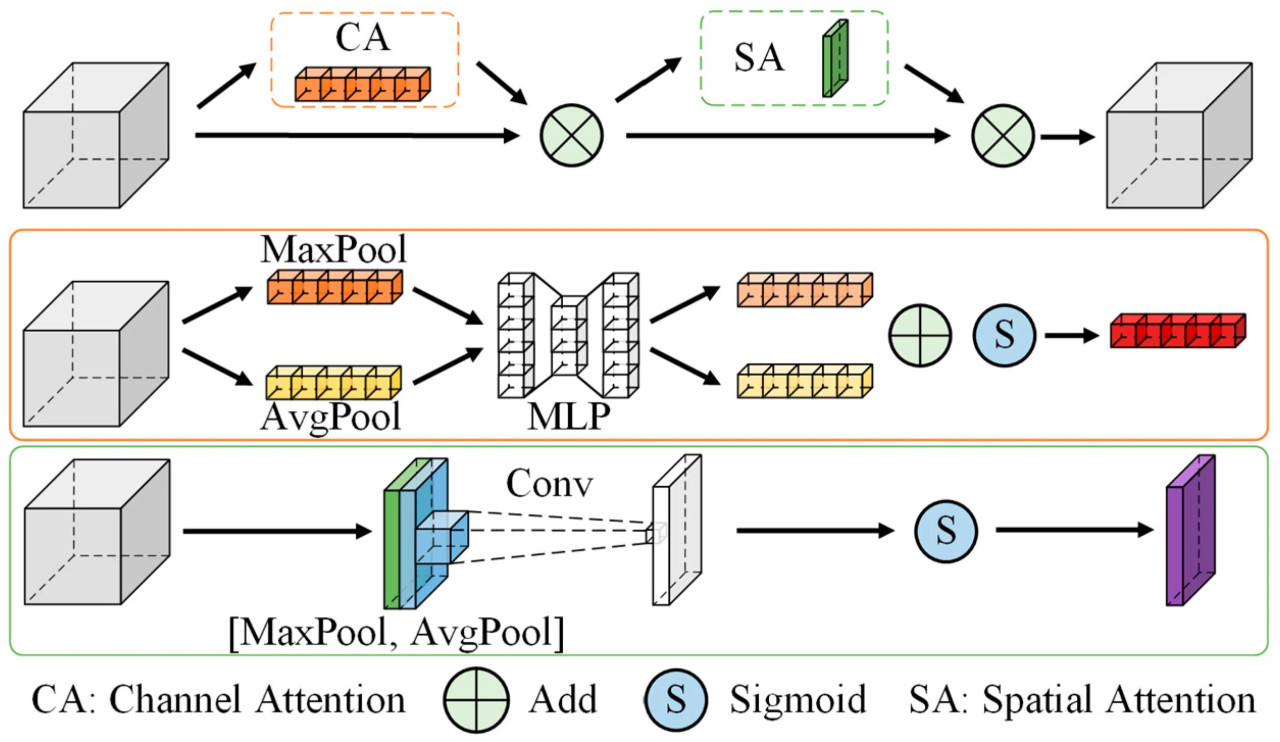
Рисунок 5. Структура модуля CBAM.
Кроме того, чтобы полностью использовать преимущества мультимодальных входов, модель добавляет модули CBAM к слоям ранних признаков карт RGB и глубины в магистральной сети. Это позволяет усилить признаки каждой модальности с помощью механизма внимания на раннем этапе. Канальное внимание улавливает важность различных каналов признаков, в то время как пространственное внимание фокусируется на значимых областях в карте признаков. В конечном итоге, эти улучшенные мультимодальные слои признаков могут полностью дополнять друг друга и взаимодействовать на этапе слияния. Это эффективно повышает надежность извлечения признаков, предоставляя более точные признаки для последующих задач обнаружения.
2.4. Функция потерь
Как показано на Рисунке 6, статистический анализ набора данных черри-помидоров (описанного ниже) выявил, что размеры плодов следовали значительному распределению с длинным хвостом. Среди 22 965 аннотированных ограничивающих рамок средняя ширина и высота объекта составляли 48,2 и 79,9 пикселя, в то время как максимальная ширина и высота достигли 223 и 387 пикселей соответственно, а минимальные значения были близки к нулю. При дальнейшем рассмотрении распределения ширин 55,47% целевых ширин были сконцентрированы в интервале [24,8, 49,6] пикселей, в то время как только 0,02% из них превышали 198,2 пикселя. Аналогично, 50,44% целевых высот находились в пределах [43,9, 86,8] пикселей, и только 0,02% из них были выше 344,1 пикселя. С точки зрения распределения площадей, 88,42% целей были ниже 8319 пикселей, в то время как только 0,01% из них были выше 66 549 пикселей. Эта статистика показывает, что множество объектов имеют маленькие размеры, в то время как очень небольшое количество объектов имеет значительно большие размеры, что приводит к несбалансированному распределению, которое создает значительные проблемы для традиционных моделей обнаружения объектов, особенно в балансировании высокого уровня обнаружения маленьких объектов и высокой позиционной точности крупных.
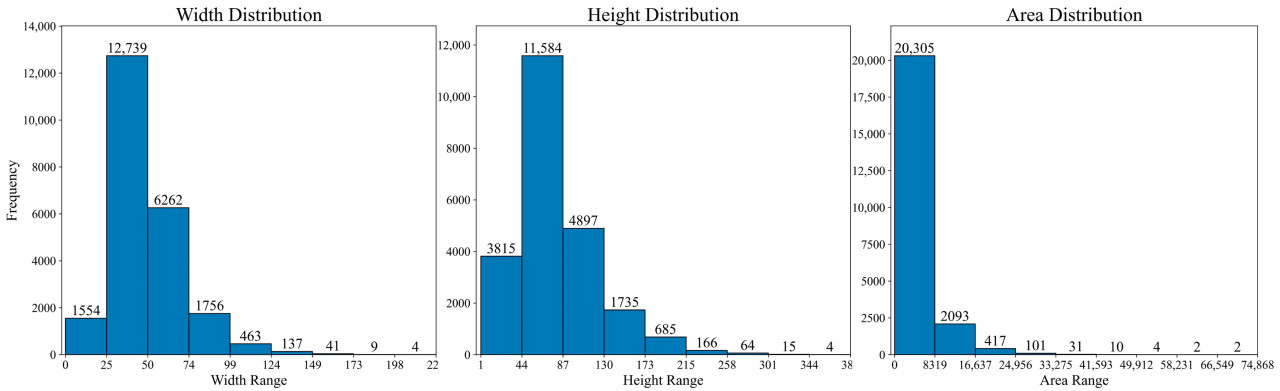
Рисунок 6. Статистический анализ набора данных черри-помидоров, использованного в текущем исследовании (единица измерения: пиксель).
Чтобы решить вышеуказанную проблему, мы использовали Distribution Focal Loss (DFL) в функции потерь ограничивающей рамки [32]. В отличие от традиционных методов, которые предсказывают ограничивающие рамки как дискретные значения, DFL представляет местоположения ограничивающих рамок как непрерывные вероятностные распределения. Это может более точно описать неопределенность местоположения цели и оптимизировать внимание модели к целям различных размеров. В частности, DFL преобразует предсказанные ограничивающие рамки в вероятностное распределение и применяет к нему фокальную потерю для решения проблемы дисбаланса классов данных. Он способен достичь баланса между маленькими объектами, которые доминируют в наборе данных, и большими объектами, которые редки, но важны. В частности, формула DFL выглядит следующим образом:
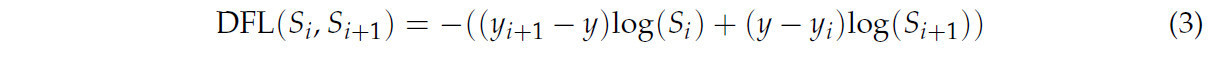
где y_i и y_(i+1) — две соседние дискретные точки предсказанной ограничивающей рамки, y — истинное значение, а S_i и S_(i+1) — предсказанные вероятности, соответствующие y_i и y_(i+1).
3. Эксперименты и результаты
Чтобы проверить эффективность и производительность предложенной DCFA-YOLO, была спроектирована и реализована серия абляционных и сравнительных экспериментов. С помощью абляционных экспериментов анализируется влияние каждого компонента на производительность модели. В то же время полная DCFA-YOLO сравнивается с несколькими современными сетями YOLO для всесторонней оценки ее производительности с точки зрения точности обнаружения, полноты, вычислительной сложности и количества параметров модели.
3.1. Экспериментальная установка и набор данных
Изображения черри-помидоров были получены в теплице в парке растительных наук и технологий в Дунгуане, Китай (Рисунок 7). Камера Microsoft Azure Kinect DK (Microsoft, Редмонд, Вашингтон, США) или TOF-камера Litemaze (Litemaze Technology, Шэньчжэнь, Китай), установленная на конце роботизированной руки, собрала 843 RGB-D пары изображений, включая RGB и соответствующие глубинные изображения. Целью было моделирование позы и расстояния роботизированной руки во время процесса сбора. Более детальные описания среды и процедур получения изображений были представлены в предыдущем исследовании по обнаружению одиночных черри-помидоров [22]. Исходные данные были расширены с использованием методов увеличения данных, таких как обрезка, отражение и случайное увеличение яркости, и в итоге было получено 3372 изображения. Грозди черри-помидоров в пределах 1 м от камеры были размечены с помощью LabelImg (версия 1.8.1). Наконец, набор данных был разделен на обучающий набор (2700 изображений), валидационный набор (336 изображений) и тестовый набор (336 изображений).

Рисунок 7. Сцена сбора набора данных. (a) Ранний сезон сбора урожая. (b) Поздний сезон сбора урожая.
Все эксперименты были проведены на настольной рабочей станции с процессором Intel(R) Core(TM) i7-14700K (Intel, Санта-Клара, Калифорния, США), 20 ядрами и 28 потоками, 64 ГБ памяти и графическим процессором Nvidia GeForce RTX 4070 Ti SUPER (Nvidia, Санта-Клара, Калифорния, США), и операционной системой Ubuntu 22.04. Все алгоритмы глубокого обучения выполнялись в одинаковой среде Windows 11, Cuda 12.6, Python 3.8, Pytorch-2.4.1 и Torchvision-0.19.1. Во всех экспериментах размер изображения был установлен на 640 × 640, batch_size — на 8, а количество эпох — на 200.
Начальная скорость обучения была установлена на 0,01, с минимальной скоростью обучения, сниженной до 1% от начального значения. Оптимизация использовала оптимизатор Stochastic Gradient Descent (SGD), настроенный с импульсом 0,937 и коэффициентом затухания веса 0,0005 для регуляризации параметров модели. Планирование скорости обучения следовало стратегии косинусоидального затухания, динамически регулируя скорость обучения в течение всего процесса обучения для улучшения сходимости и производительности.
3.2. Метрики оценки
Мы использовали точность (precision), полноту (recall), F1-меру и mAP в качестве базовых метрик оценки производительности обнаружения. Средняя средняя точность (mAP) является важным показателем для измерения глобальной производительности обнаружения модели. AP определяется как площадь под кривой точности-полноты, которая представляет всестороннюю оценку производительности обнаружения одной категории [33]. mAP50 представляет собой среднее значение точности, вычисленное при пороге Intersection over Union (IoU), равном 0,5, и является общепринятым критерием оценки в задачах обнаружения объектов. mAP75 — это средняя точность, вычисленная при более высоком пороге IoU (0,75), что требует от модели более точного предсказания положения цели и может отражать способность модели к локализации. mAP50-95 представляет собой среднюю mAP при различных порогах IoU (от 0,5 до 0,95 с интервалом 0,05), что позволяет более всесторонне оценить производительность обнаружения модели при различных требованиях к точности. Точность (Pre), полнота (Rec) и F1-мера (FS) рассчитываются следующим образом:
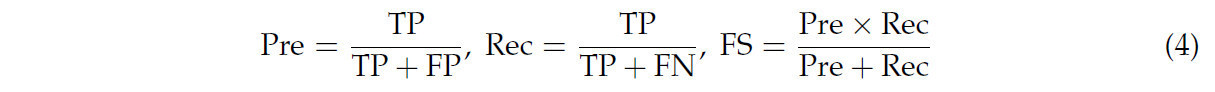
где TP, FP и FN представляют собой истинно положительные, ложноположительные и ложноотрицательные результаты. AP и mAP рассчитываются следующим образом:
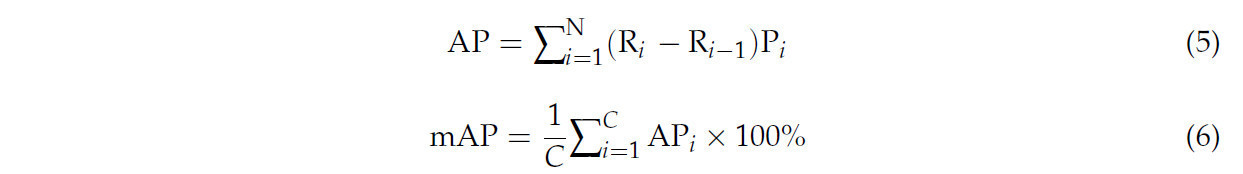
где N — количество уровней полноты; R_i и R_(i-1) — последовательные уровни полноты; P_i — точность на уровне полноты R_i; а C — количество классов.
Кроме того, мы также учитывали GFLOPs для измерения вычислительной сложности модели и параметры для отражения размера и сложности модели. Вместе эти метрики предоставили нам всестороннюю перспективу для оценки точности, надежности, эффективности и потребления ресурсов моделей в задачах обнаружения объектов.
3.3. Абляционные эксперименты
Базовой моделью является YOLOv8_n, реализованная третьей стороной. По сравнению с официальной YOLOv8_n, эта версия модели позволяет легче интегрировать ветви извлечения мультимодальных признаков и легковесные улучшения. Все абляционные эксперименты были проведены на основе этой модели для постепенной проверки эффективности каждого добавляемого модуля.
Дизайн абляционного эксперимента показан в Таблице 1. Во-первых, одномерный вход RGB использовался в качестве базового для построения начальной структуры обнаружения (Single-RGB). Затем, путем добавления глубинного канала, была построена базовая модель двумодального входа (Base_DM) для проверки улучшения производительности за счет мультимодального входа. На этой основе были введены несколько улучшенных модулей, включая модуль интерполяции (+Interpolate), модуль мультимодального перекрестного слияния (+Concat_BiFPN), легковесный модуль C2f_repghost (+C2f_repghost), легковесный модуль ShuffleNetV2 (+ShuffleNetV2), модуль канального и пространственного внимания CBAM (+CBAM) и модуль слияния SPPF и CBAM (+SPPF_CBAM). Последний случай представлял собой полную модель DCFA-YOLO.
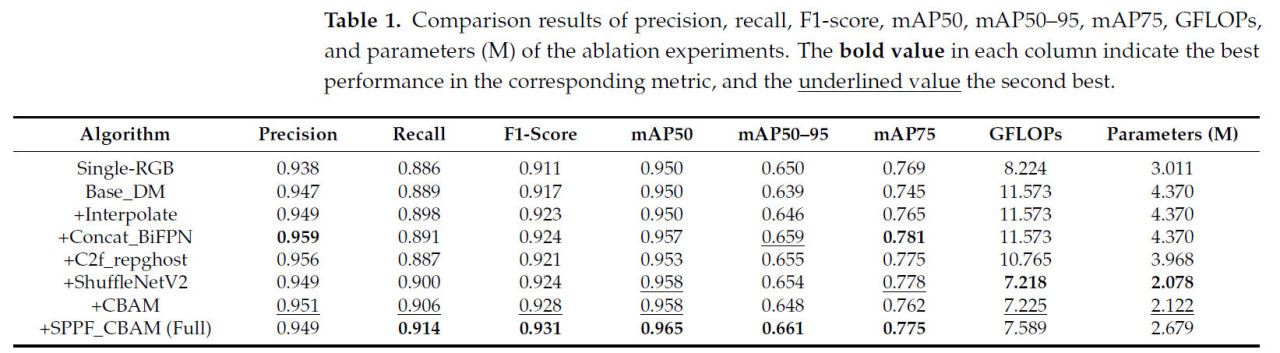
Таблица 1. Результаты сравнения точности, полноты, F1-меры, mAP50, mAP50–95, mAP75, GFLOPs и параметров (M) абляционных экспериментов. Полужирное значение в каждом столбце указывает на лучшую производительность по соответствующей метрике, а подчеркнутое значение — на вторую лучшую.
Базовая модель достигла базовой производительности: точность 0,938, полнота 0,886 и F1-мера 0,911 в одномерном режиме. С мультимодальным входом точность и F1-мера увеличились до 0,947 и 0,917, что подтверждает положительное влияние мультимодального входа. Добавление модуля интерполяции (+Interpolate) дополнительно улучшило точность и F1-меру до 0,949 и 0,923. Добавление модуля мультимодального перекрестного слияния (+Concat_BiFPN) дополнительно повысило точность до 0,959, F1-меру до 0,924 и mAP50 до 0,957. После дальнейшей замены на легковесный модуль C2f_repghost, хотя GFLOPs снизились до 10,765, а сложность модели уменьшилась, различные метрики лишь немного снизились. После добавления модуля ShuffleNetV2 GFLOPs дополнительно снизились до 7,218, в то время как точность составила 0,949, а F1-мера осталась на уровне 0,924. Внедрение модуля CBAM увеличило полноту до 0,906 и F1-меру до 0,928. Наконец, внедрение модуля SPPF_CBAM привело к наилучшей производительности. Эти результаты подтверждают, что улучшенная модель достигает хорошего баланса между повышением производительности и поддержанием легковесного дизайна.
Следует отметить, что после добавления модуля CBAM к шести выходам признаков магистрали производительность заметно улучшается за счет лучшего извлечения признаков. Однако когда мы дополнительно заменяем модуль SPPF на последнем слое на модуль SPPF_CBAM, эта небольшая корректировка приводит к наилучшей общей производительности с точки зрения точности, полноты, F1-меры и mAP50, сохраняя при этом легковесную модель. Это улучшение в первую очередь связано с эффективной комбинацией пространственного и канального внимания от CBAM с модулем пространственного пирамидального пулинга (SPPF), которая улучшает многоуровневое извлечение признаков, обеспечивая лучшую производительность без значительного увеличения вычислительных затрат.
Рисунок 8 показывает сравнение тепловых карт для абляционных экспериментов. Базовая модель Single-RGB демонстрирует сфокусированное внимание на большинстве целей, но испытывает трудности с частично скрытыми гроздями черри-помидоров. Мультимодальная модель Base_DM улучшает внимание к этим целям. Последующие модули, такие как +Interpolate, +Concat_BiFPN и +C2f_repghost, показывают все более точное и сконцентрированное внимание на всех гроздьях черри-помидоров. Модули +ShuffleNetV2 и +CBAM улучшают распределение внимания, при этом +SPPF_CBAM достигает наилучшего фокуса на всех целях, особенно улучшая обнаружение частично скрытых гроздей.
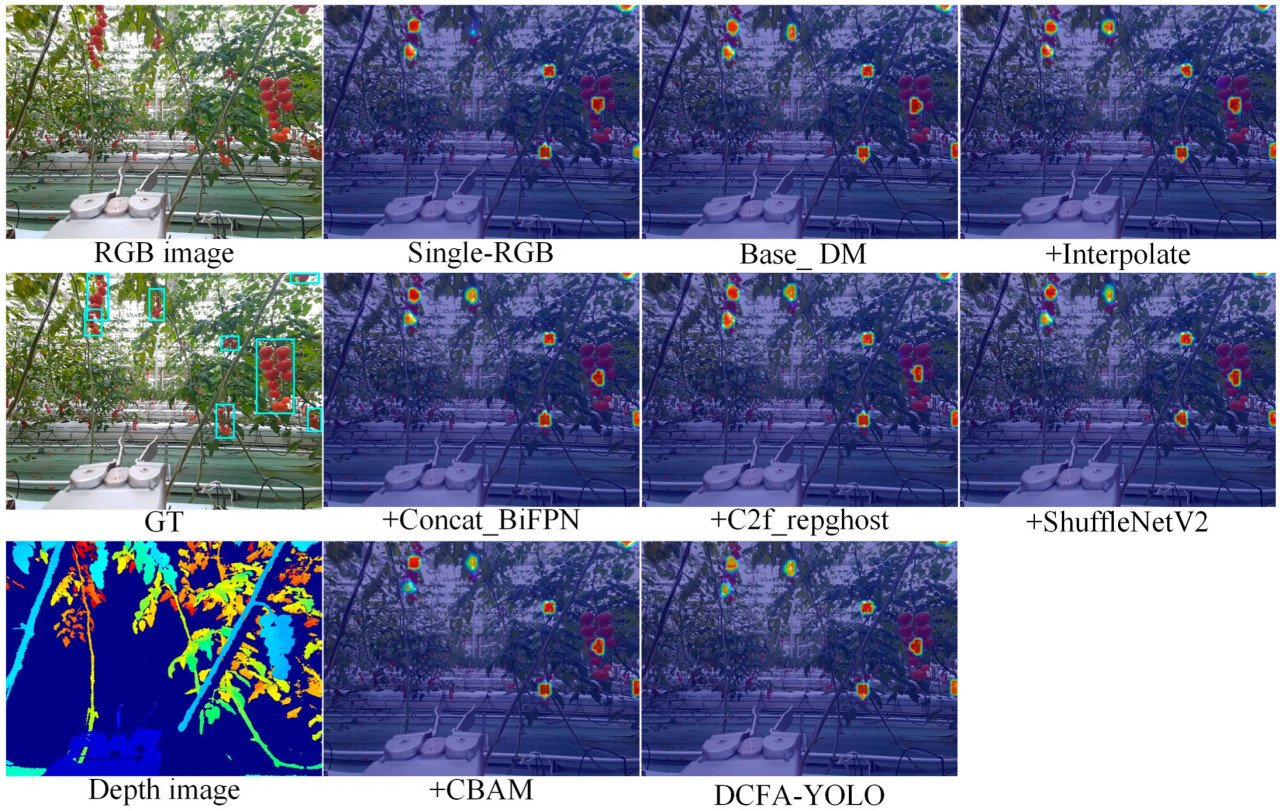
Рисунок 8. Сравнение тепловых карт для абляционных экспериментов.
3.4. Сравнение различных алгоритмов обнаружения
Чтобы сравнить производительность обнаружения DCFA-YOLO с другими моделями DNN, мы выбрали современные модели YOLO: YOLOv5_n [34], YOLOv8_n [30], YOLOv9_t [35], YOLOv10_n [36], YOLO11_n [37], EfficientDet [31], SSD [6] и CenterNet [38] для количественного и качественного сравнения с точки зрения метрик оценки и визуальных эффектов. Количественные результаты суммированы в Таблице 2.
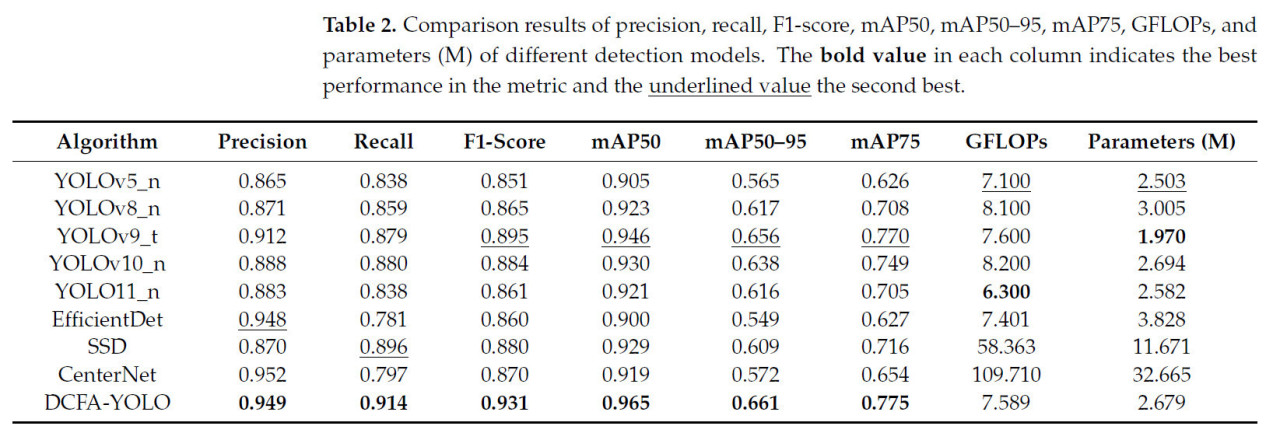
Таблица 2. Результаты сравнения точности, полноты, F1-меры, mAP50, mAP50–95, mAP75, GFLOPs и параметров (M) различных моделей обнаружения. Полужирное значение в каждом столбце указывает на лучшую производительность по метрике, а подчеркнутое значение — на вторую лучшую.
DCFA-YOLO показывает значительные улучшения почти по всем ключевым метрикам. По сравнению с YOLOv5_n, YOLOv8_n и YOLOv9_t, DCFA-YOLO достигает заметного увеличения точности, полноты, F1-меры и mAP50. В частности, ее точность улучшается с 0,871 (YOLOv8_n) до 0,949, а F1-мера возрастает с 0,865 до 0,931. Даже по сравнению с более производительной YOLOv9_t, DCFA-YOLO также показывает очевидные преимущества, особенно в F1-мере и mAP50, с заметным улучшением в обеих. Хотя YOLOv10_n и YOLO11_n имеют более низкие GFLOPs и параметры, DCFA-YOLO превосходит их по таким ключевым метрикам, как точность и mAP50. Более того, она превосходит такие модели, как EfficientDet и CenterNet. Это дополнительно показывает, что DCFA-YOLO достигла хорошего баланса между производительностью и легкостью, что делает ее отличной моделью как для точности, так и для вычислительной эффективности.
Рисунок 9 сравнивает кривые точности-полноты для различных моделей обнаружения, показывая, что DCFA-YOLO стабильно превосходит другие модели как по точности, так и по полноте. При внимательном изучении PR-кривой становится ясно, что улучшения производительности, отмеченные в Таблице 2, особенно в точности, полноте и F1-мере, визуально отражаются, демонстрируя сильные общие возможности обнаружения модели.
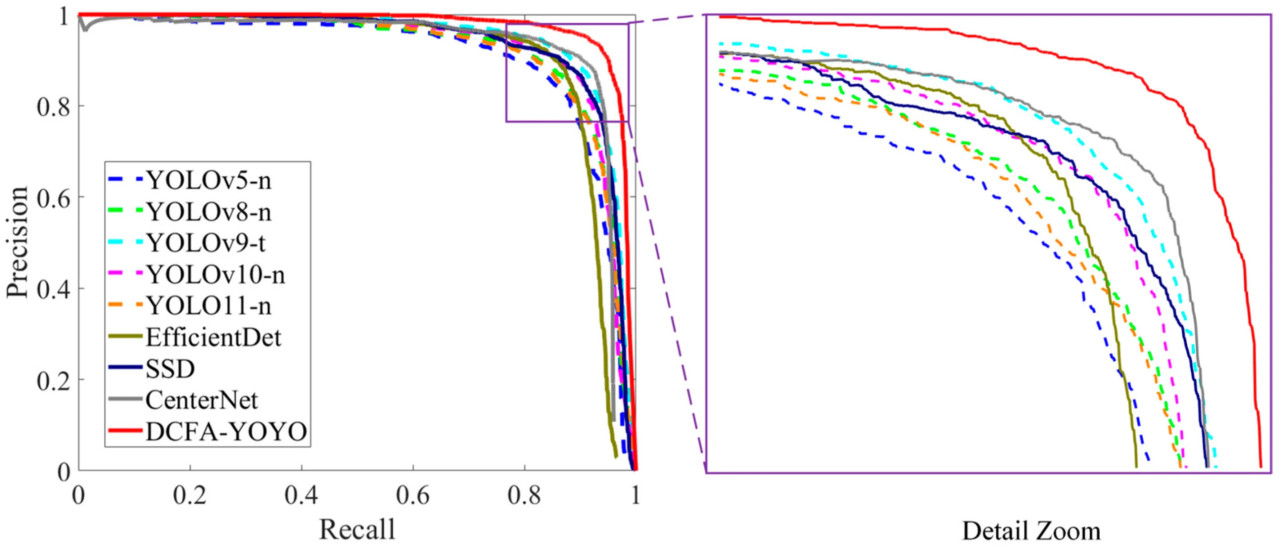
Рисунок 9. Кривые точности-полноты различных моделей обнаружения.
Рисунки 10, 11 и 12 представляют визуализацию результатов обнаружения при нормальном освещении, высоком освещении и низкой освещенности соответственно. При нормальном освещении (Рисунок 10) сравниваемые модели демонстрируют различные степени неполного обнаружения, часто пропуская маленькие или перекрывающиеся объекты и показывая субоптимальную точность границ. Напротив, DCFA-YOLO может обнаруживать грозди черри-помидоров более точно, значительно сокращая пропуски и ложные обнаружения.
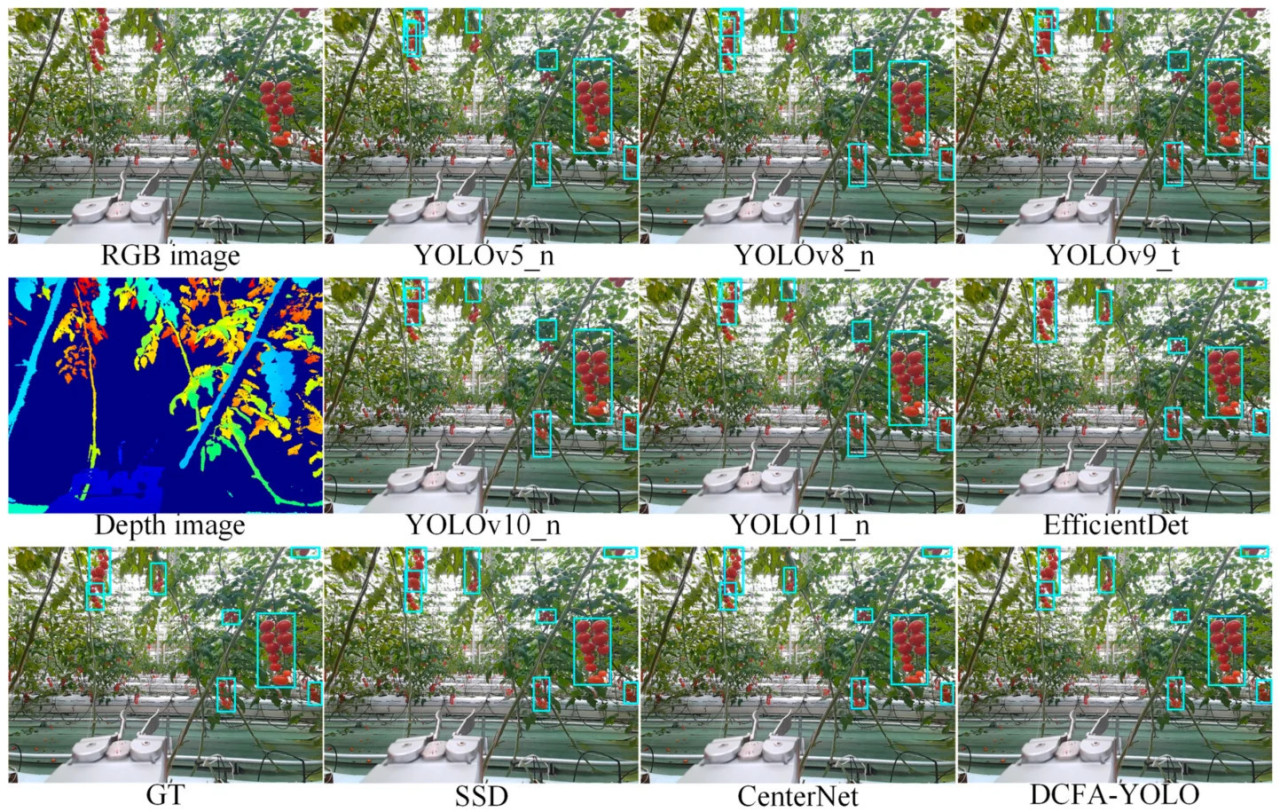
Рисунок 10. Визуализация результатов обнаружения различных моделей в условиях нормального освещения.
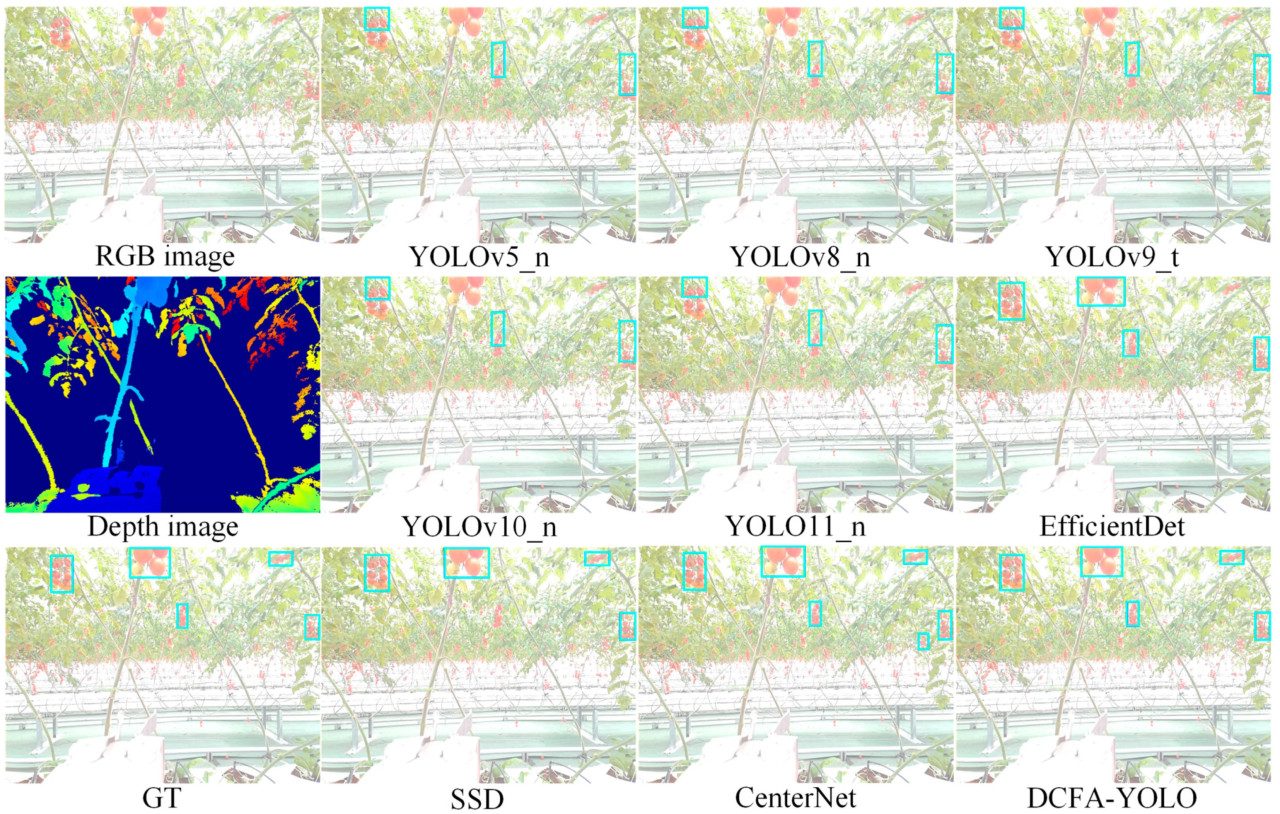
Рисунок 11. Визуализация результатов обнаружения различных моделей в условиях сильного освещения.

Рисунок 12. Визуализация результатов обнаружения различных моделей в условиях низкой освещенности.
Рисунки 11 и 12 иллюстрируют результаты обнаружения в сложных условиях освещения. В случае сильного освещения (Рисунок 11) чрезмерная яркость приводит к тому, что изображение выглядит выцветшим, что приводит к увеличению количества пропущенных обнаружений в большинстве моделей на основе YOLO и к избыточному обнаружению в CenterNet. В сценарии с низкой освещенностью (Рисунок 12) темнота изображения усугубляет пропуски обнаружения для моделей на основе YOLO, в то время как CenterNet снова страдает от избыточного обнаружения. Несмотря на эти проблемы, DCFA-YOLO демонстрирует превосходную адаптируемость в обоих сценариях, сохраняя высокую точность обнаружения с минимальным количеством ложных срабатываний или пропущенных целей.
4. Обсуждение
Предложенный метод DCFA-YOLO для мультимодального обнаружения гроздей черри-помидоров достигает наилучших результатов по шести метрикам оценки (точность, полнота, F1-мера, mAP50, mAP75 и mAP50–95) среди девяти сравненных DNN. Он занимает 5-е место среди девяти моделей по размеру параметров, а его GFLOPs занимают 4-е место с конца. Для роботизированного сбора урожая алгоритм обнаружения обычно выполняется на устройствах периферийных вычислений, поэтому точность и вычислительная стоимость обнаружения важны, и мы считаем, что DCFA-YOLO достигает отличного баланса между ними. Вычислительная платформа в текущем исследовании по сути является обычным ПК, и DCFA-YOLO выполняет обнаружение гроздей черри-помидоров с частотой кадров 52,93 кадра в секунду, что достаточно для практического роботизированного сбора в реальном времени. Достигая высокой точности с более низкими вычислительными затратами, DCFA-YOLO снижает нагрузку на оборудование, что может привести к более низкому энергопотреблению и эксплуатационным расходам в реальных приложениях. Она может быть интегрирована в сельскохозяйственные системы, такие как роботизированные уборочные машины или дроны, улучшая их восприятие для точного и эффективного сбора и измерения плодов.
В предыдущем исследовании по обнаружению гроздей черри-помидоров сообщалось о точности, полноте и F1-мере 98,9, 92,1 и 95,4 соответственно [39], что выше соответствующих значений 0,949, 0,914 и 0,931 в текущем исследовании. Однако два исследования были проведены с двумя весьма различными наборами данных, которые были собраны различными камерами (структурированный свет Intel RealSense против Microsoft Kinect TOF) на разных плантациях. Код и набор данных недоступны для прямого сравнения. Чтобы частично решить эту проблему, мы делаем код общедоступным на Github (см. Заявление о доступности данных). К сожалению, набор данных не может быть полностью обнародован из-за соглашения о неразглашении.
В этом исследовании мы протестировали только обнаружение гроздей черри-помидоров. Для таких кластерных плодов, как черри-помидоры, зависит от производственных потребностей в коммерческой среде, собирать ли отдельные плоды или гроздьями, и оба подхода использовались в предыдущих исследованиях [22,39,40]. Мы считаем, что DCFA-YOLO может быть применима также для обнаружения отдельных плодов, что будет исследовано в будущей работе. Однако важно отметить, что текущая модель может столкнуться с проблемами в более сложных сценариях, таких как сильные окклюзии или высоко плотные скопления, где точность обнаружения может быть снижена. Будущие улучшения могли бы сосредоточиться на повышении устойчивости модели к этим условиям, возможно, с помощью продвинутых механизмов внимания или методов многоуровневого слияния признаков.
Мы также хотели бы изучить применение DCFA-YOLO к другим фруктам; например, она может быть частично перенесена для обнаружения других плодов, растущих гроздьями/пучками, таких как виноград, лонган или личи. Следует отметить, что для этих плодов даже в спелом состоянии цветовые признаки менее выражены по сравнению с черри-помидорами. Таким образом, мы ожидаем, что влияние добавления глубинной информации для этих плодов, вероятно, будет более значительным, чем для черри-помидоров.
Более того, при интеграции с уборочными роботами DCFA-YOLO может внести вклад в устойчивость сельского хозяйства за счет повышения эффективности сбора урожая и сокращения пищевых отходов. Ее высокая точность обнаружения минимизирует пропущенные или поврежденные плоды, в то время как ее возможности в реальном времени обеспечивают более быстрый и точный сбор, в конечном итоге поддерживая более устойчивую и ресурсоэффективную сельскохозяйственную практику.
5. Выводы
Это исследование представляет DCFA-YOLO, легковесную модель обнаружения плодов с мультимодальным перекрестным слиянием. Благодаря интеграции механизма двуканального перекрестного слияния, динамически взвешенного модуля слияния признаков, оптимизированного легковесного дизайна вместе с механизмами внимания, модель демонстрирует заметные улучшения в эффективности и надежности для мультимодальных задач обнаружения. В частности, модель использует взаимодополняющую информацию цветных и глубинных изображений посредством целенаправленных улучшений магистральной сети и этапов слияния признаков. Эти улучшения эффективно снижают вычислительную сложность и параметры модели, сохраняя при этом высокую точность обнаружения, решая проблемы обнаружения мелких плодов в сложных сценариях. Экспериментальные результаты по обнаружению гроздей черри-помидоров дополнительно подтверждают превосходство модели, демонстрируя ее потенциал для практического применения в точном земледелии в качестве ключевого компонента роботизированного сбора черри-помидоров.
Ссылки
1. Wang, Z.; Xun, Y.; Wang, Y.; Yang, Q. Review of smart robots for fruit and vegetable picking in agriculture. Int. J. Agric. Biol. Eng. 2022, 15, 33–54. [Google Scholar]
2. Agarwal, S.; Rao, A.V. Tomato lycopene and its role in human health and chronic diseases. CMAJ 2000, 163, 739–744. [Google Scholar] [PubMed]
3. Hua, X.; Li, H.; Zeng, J.; Han, C.; Chen, T.; Tang, L.; Luo, Y. A review of target recognition technology for fruit picking robots: From digital image processing to deep learning. Appl. Sci. 2023, 13, 4160. [Google Scholar] [CrossRef]
4. Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
5. Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
6. Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
7. Lyu, S.; Li, R.; Zhao, Y.; Li, Z.; Fan, R.; Liu, S. Green citrus detection and counting in orchards based on YOLOv5-CS and AI edge system. Sensors 2022, 22, 576. [Google Scholar] [CrossRef]
8. Wang, L.; Zhao, Y.; Xiong, Z.; Wang, S.; Li, Y.; Lan, Y. Fast and precise detection of litchi fruits for yield estimation based on the improved YOLOv5 model. Front. Plant Sci. 2022, 13, 965425. [Google Scholar] [CrossRef]
9. Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
10. Zhao, R.; Zhu, Y.; Li, Y. An end-to-end lightweight model for grape and picking point simultaneous detection. Biosyst. Eng. 2022, 223, 174–188. [Google Scholar] [CrossRef]
11. Yuan, T.; Lv, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.; Li, W.; Zhang, C.; Zhang, W. Robust cherry tomatoes detection algorithm in greenhouse scene based on SSD. Agriculture 2020, 10, 160. [Google Scholar] [CrossRef]
12. Fuentes-Peñailillo, F.; Carrasco Silva, G.; Pérez Guzmán, R.; Burgos, I.; Ewertz, F. Automating seedling counts in horticulture using computer vision and AI. Horticulturae 2023, 9, 1134. [Google Scholar] [CrossRef]
13. Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
14. Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
15. Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
16. He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
17. Hu, C.; Liu, X.; Pan, Z.; Li, P. Automatic detection of single ripe tomato on plant combining faster R-CNN and intuitionistic fuzzy set. IEEE Access 2019, 7, 154683–154696. [Google Scholar] [CrossRef]
18. Song, Z.; Fu, L.; Wu, J.; Liu, Z.; Li, R.; Cui, Y. Kiwifruit detection in field images using Faster R-CNN with VGG16. IFAC-PapersOnline 2019, 52, 76–81. [Google Scholar] [CrossRef]
19. Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
20. Tu, S.; Xue, Y.; Zheng, C.; Qi, Y.; Wan, H.; Mao, L. Detection of passion fruits and maturity classification using Red-Green-Blue Depth images. Biosyst. Eng. 2018, 175, 156–167. [Google Scholar] [CrossRef]
21. Cui, B.; Zeng, Z.; Tian, Y. A Yolov7 cherry tomato identification method that integrates depth information. In Proceedings of the Third International Conference on Optics and Image Processing (ICOIP 2023), Hangzhou, China, 14–16 April 2023; pp. 312–320. [Google Scholar]
22. Cai, Y.; Cui, B.; Deng, H.; Zeng, Z.; Wang, Q.; Lu, D.; Cui, Y.; Tian, Y. Cherry Tomato Detection for Harvesting Using Multimodal Perception and an Improved YOLOv7-Tiny Neural Network. Agronomy 2024, 14, 2320. [Google Scholar] [CrossRef]
23. Rong, J.; Zhou, H.; Zhang, F.; Yuan, T.; Wang, P. Tomato cluster detection and counting using improved YOLOv5 based on RGB-D fusion. Comput. Electron. Agric. 2023, 207, 107741. [Google Scholar] [CrossRef]
24. Kaukab, S.; Ghodki, B.M.; Ray, H.; Kalnar, Y.B.; Narsaiah, K.; Brar, J.S. Improving real-time apple fruit detection: Multi-modal data and depth fusion with non-targeted background removal. Ecol. Inform. 2024, 82, 102691. [Google Scholar] [CrossRef]
25. Liu, Z.; Wu, J.; Fu, L.; Majeed, Y.; Feng, Y.; Li, R.; Cui, Y. Improved kiwifruit detection using pre-trained VGG16 with RGB and NIR information fusion. IEEE Access 2019, 8, 2327–2336. [Google Scholar] [CrossRef]
26. Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
27. Wei, Z.; Guodong, Y.; Haoji, L.; Keke, G.; Wenhan, H.; Yuan, W.; Hongwei, X. Low-observable Target Detection Method for Autonomous Vehicles Based on Multi-modal Feature Fusion. China Mech. Eng. 2021, 32, 1114. [Google Scholar]
28. Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
29. Li, H.; Wu, X.-J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
30. Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 27–28 June 2024; pp. 529–545. [Google Scholar]
31. Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
32. Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
33. Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
34. Jocher, G. YOLOv5 by Ultralytics, Version 7.0; 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 23 January 2025).
35. Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 22–23 January 2025; pp. 1–21. [Google Scholar]
36. Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:14458. [Google Scholar]
37. Khanam, R.; Hussain, M. Yolov11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:17725. [Google Scholar]
38. Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
39. Li, Y.; Feng, Q.; Liu, C.; Xiong, Z.; Sun, Y.; Xie, F.; Li, T.; Zhao, C. MTA-YOLACT: Multitask-aware network on fruit bunch identification for cherry tomato robotic harvesting. Eur. J. Agron. 2023, 146, 126812. [Google Scholar] [CrossRef]
40. Chen, W.; Liu, M.; Zhao, C.; Li, X.; Wang, Y. MTD-YOLO: Multi-task deep convolutional neural network for cherry tomato fruit bunch maturity detection. Comput. Electron. Agric. 2024, 216, 108533. [Google Scholar] [CrossRef]

Chai S, Wen M, Li P, Zeng Z, Tian Y. DCFA-YOLO: A Dual-Channel Cross-Feature-Fusion Attention YOLO Network for Cherry Tomato Bunch Detection. Agriculture. 2025; 15(3):271. https://doi.org/10.3390/agriculture15030271
Перевод статьи «DCFA-YOLO: A Dual-Channel Cross-Feature-Fusion Attention YOLO Network for Cherry Tomato Bunch Detection» авторов Chai S, Wen M, Li P, Zeng Z, Tian Y., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: freepik

















































































































Комментарии (0)