Быстрое и точное определение сахара в мушмуле с помощью ближней ИК-спектроскопии и понятного ИИ
Содержание растворимых сухих веществ (TSSC) является одним из важнейших факторов, влияющих на вкус мушмулы, удовлетворенность потребителей и конкурентоспособность на рынке. Для улучшения оценки TSSC мушмулы был предложен метод, использующий ближнюю инфракрасную спектроскопию и интерпретируемый искусственный интеллект.
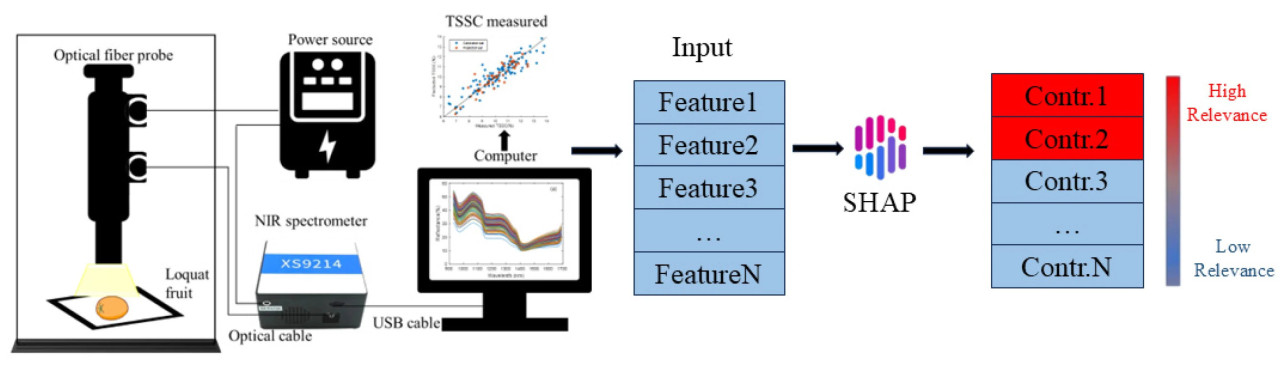
Аннотация
Спектры 156 свежих образцов мушмулы в ближней инфракрасной области в диапазоне длин волн 900–1700 нм были собраны и предварительно обработаны с использованием семи методов. Для устранения избыточности данных было выполнено выделение значимых длин волн с помощью шести методов извлечения признаков. Для установления взаимосвязи между характерным спектром и TSSC использовались линейные и нелинейные модели, с акцентом на сравнение и анализ прогностической эффективности.
Результаты показывают, что комбинация 26 спектральных диапазонов, отобранных методом SPA (последовательного проецирования на ортогональные пространства), и модели PLSR (частичной регрессии наименьших квадратов) обеспечила наилучшие прогностические результаты: R = 0,9031, RMSEP = 0,6171, RPD = 2,2803.
Вклад ключевых длин волн может быть получен с помощью метода SHAP, что позволяет объяснить различия в точности прогнозирования модели и служит ориентиром для применения метода определения TSSC в мушмуле.
1. Введение
Мушмула впервые появилась в Китае, и в настоящее время ее широко культивируют в странах по всему миру [1]. Мушмула богата витаминами, фенолами и другими питательными веществами, обладает уникальным вкусом, что делает ее интересным фруктовым вариантом для потребителей. Изменение качества мушмулы после сбора урожая приводит к различиям в сортировке и цене. TSSC является основным фактором, определяющим качество, и не обязательно связан с внешним видом плода. Следовательно, некоторые результаты сортировки по качеству, основанные только на внешних характеристиках, таких как вес, размер, цвет и т.д., недостаточно убедительны [2]. Обычное измерение TSS требует больших затрат труда и является инвазивной операцией, что приводит к определенным потерям количества плодов. Это не соответствует потребностям в больших объемах мушмулы, обнаружении в реальном времени и низких потерях в реальном производстве. Поэтому, как быстро и неразрушающе измерить TSSC мушмулы, чтобы обеспечить более точную основу для классификации по качеству, является проблемой, которую необходимо решить.
Многочисленные исследования подчеркивают эффективность ближней инфракрасной спектроскопии как неразрушающего метода испытаний в различных областях, включая сортировку чая по качеству [3,4,5], количественный анализ компонентов традиционной китайской медицины [6] и определение внутренних веществ во фруктах. Ближний инфракрасный спектр, работающий в электромагнитном спектре между видимым и средним инфракрасным светом, охватывает диапазон длин волн 780–2526 нм. Его происхождение заключается в удвоении частоты и комбинированном частотном поглощении водородсодержащих групп X–H (где X = C, N, O). Информация, отражаемая спектром, включает в себя детали состава и молекулярной структуры широкого спектра органических соединений, что облегчает анализ органических веществ. В частности, ближняя инфракрасная спектроскопия предлагает преимущества удобства, скорости и экономической эффективности, что делает ее пригодной для оценки тонкокожих фруктов и проведения TSSC-тестирования на коммерческом уровне [6]. Дополнительные достижения в области ближней инфракрасной спектроскопии способствовали измерению TSS в различных фруктах, таких как яблоки [7], манго [8], груши [9] и киви [10]. Исследования мушмулы были сосредоточены на идентификации ушибов [11,12] и интеллектуальном приготовлении компота из мушмулы [13], при этом ограниченное внимание уделялось обнаружению TSSC и его интерпретации.
Выбор переменных признаков является ключевым этапом для снижения вычислительной нагрузки и повышения точности в последующих модельных усилиях. Например, была продемонстрирована эффективность алгоритмов выбора признаков в прогнозировании содержания растворимых сухих веществ в дуриане за счет сокращения 92% полос, что привело к небольшому улучшению точности прогнозирования по сравнению с использованием полного диапазона. Sun и др. использовали алгоритм случайных прыжков лягушки для спектральной калибровки, что способствовало быстрой идентификации и визуализации оптимальных информационных интервалов [14]. Переменные, отобранные с помощью этого метода, демонстрировали минимальные ошибки при интеграции в модель прогнозирования, при этом среднее время обработки заняло второе место с конца. Yun и др. использовали гибридную стратегию выбора переменных, основанную на VCPA, для оптимизации пространства переменных, достигая превосходной минимизации ошибок в различных наборах данных [15].
Конечная цель большинства исследований состояла в моделировании оптимальных результатов, но результаты моделей различались после разного количества видов образцов, методов предварительной обработки и методов выбора признаков обработки, что затрудняет обращение к исследованиям в той же области. При прогнозировании TSSC томатов R PLSR составлял 0,78 в одних случаях и 0,525 в других [16,17]. Поэтому для конкретного объекта исследования и настройки модели необходимо объяснить обоснование и прояснить механизмы выбора признаков и действия модели, что поможет улучшить обобщаемость применения статьи. Zhao и др. объясняют превосходство моделей RNN в условиях недостаточного извлечения признаков и малых выборок, вычисляя значение вклада ключевых длин волн [18]. Akulich и др. используют различные методы интерпретируемого ИИ для объяснения результатов прогнозирования высокоразмерных, но ограниченных спектральных данных, делая процесс моделирования машинного обучения более ясным [19].
В контексте растущей потребности в прозрачности моделей, SHAP рассматривается как эффективная методика для объяснения машинного обучения, благодаря своему свойству учитывать прогностическую эффективность полной комбинации наборов признаков. Значения SHAP получаются через вклад длин волн признаков в процессе моделирования, что помогает сгладить взаимосвязь между многомерными признаками и прогнозами модели. Методика SHAP позволяет идентифицировать ключевые элементы в процессе принятия решений моделью, что предоставляет исследователям возможность лучше понять механизм работы модели, тем самым повышая надежность хемометрических прогнозов. В настоящее время осуществимость SHAP в объяснении вклада важных диапазонов для прогнозирования твердости сладкого картофеля [20], объяснении различий в моделях прогнозирования содержания питательных веществ в почве [21] и оценке диапазонов с высокими показателями значимости [22] была доказана.
Основываясь на коммерческих плодах мушмулы, было использовано несколько подходов к выбору признаков для выделения значимых длин волн TSSC, после чего был проведен анализ для оценки прогностической эффективности нескольких методов машинного обучения (PLS, BPNN и ELM). Наконец, с помощью интерпретируемого подхода искусственного интеллекта SHAP для визуализации вклада признаков были определены ключевые длины волн для прогнозирования содержания сахара в мушмуле. Этот процесс способствовал пониманию реакции комбинаций спектральных переменных на TSSC, тем самым направляя выбор признаков и выбор модели при решении таких задач.
2. Материалы и методы
2.1. Подготовка образцов
В апреле 2023 года мы собрали 163 спелых плода мушмулы в саду в Гуанчжоу, провинция Гуандун. После исключения образцов, не соответствовавших требованиям, осталось 156 образцов. Эти образцы состоят из полностью созревших плодов мушмулы, готовых к продаже. Они однородны по размеру, свежи, их внешняя кожица неповреждена, без каких-либо дефектов. Средний поперечный диаметр плода составляет 45,6 мм, средний продольный диаметр — 54 мм, средний боковой диаметр — 44,5 мм, а средний вес одного плода — 57,6 г. После сбора плоды следует хранить в холодильной камере при температуре 4 °C. Перед сбором данных образцы следует выдержать при комнатной температуре 20 °C в течение 8 часов.
2.2. Получение спектральных данных
Спектральные данные образцов мушмулы были получены с помощью ближнего инфракрасного спектрометра (Oceanhood optoelectronics XS9214, Shanghai Oceanhood Opto-electronics Tech Co., Шанхай, Китай) с диапазоном длин волн 900–1700 нм и разрешением 3,5 нм. Экспериментальная платформа показана на Рисунке 1 и состоит из ближнего инфракрасного спектрометра, источника света, темного ящика, волоконно-оптического зонда, вольфрамового источника света и компьютера. Программное обеспечение для получения спектров (Uspectral-PLUS, версия: 5.0) было использовано для визуализации и хранения спектров, в котором время интеграции было установлено на 50 мс, а среднее число — на 100, и был принят режим непрерывного получения.
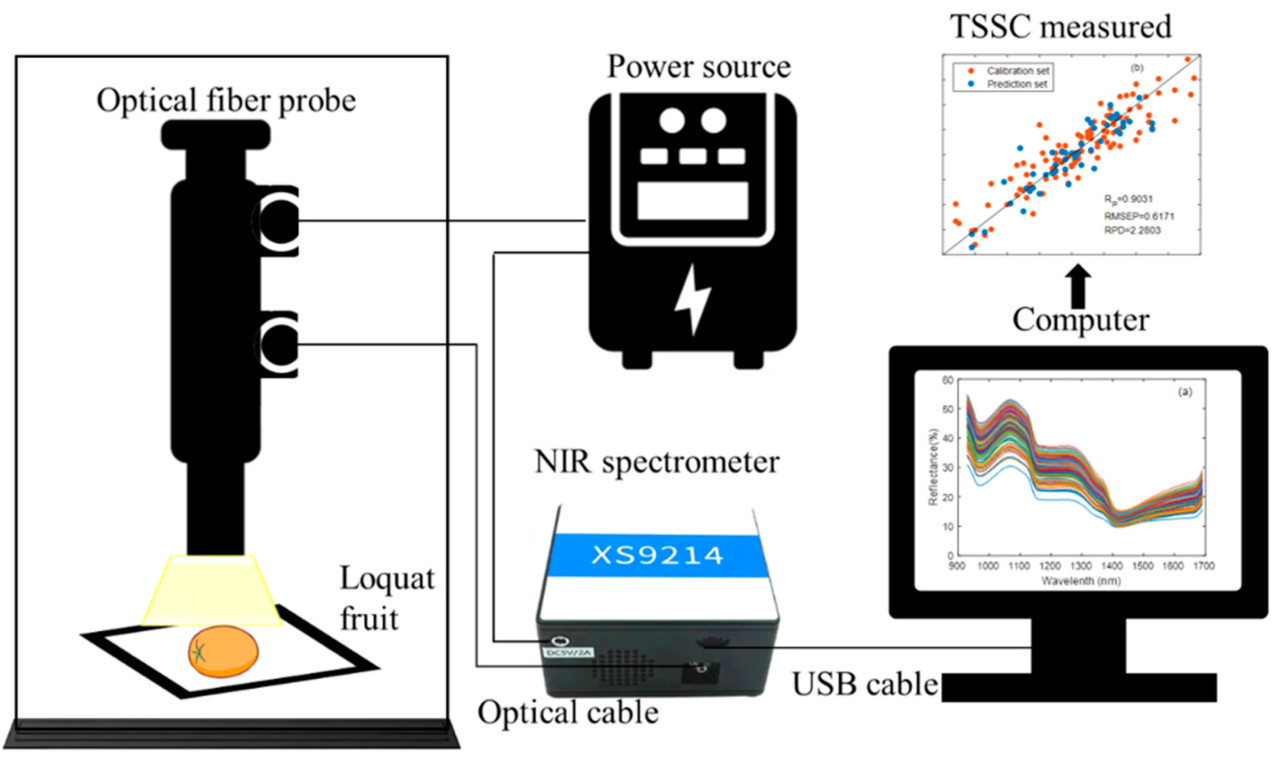
Рисунок 1. Платформа для измерения ближних инфракрасных спектров в диапазоне 900–1700 нм.
2.3. Измерение TSSC
Значение TSSC измеряется с помощью рефрактометра (ATAGO PAL-1, ATAGO Co., Ltd., Токио, Япония) на основе принципа оптической рефракции с точностью ±0,2% Brix. После сбора ближнего инфракрасного спектра проводят измерение TSSC. Очистите от кожуры и удалите семена из мушмулы, разомните мякоть, отфильтруйте остатки и поместите сок в тестовую зону рефрактометра для измерения. Повторите измерение три раза и примите среднее значение как конечное содержание сахара. Диапазон TSSC 156 плодов мушмулы был измерен на уровне 6,4–13,8 Brix.
2.4. Спектральные признаки и предварительная обработка
Чтобы уменьшить влияние шума, возникающего из-за факторов окружающей среды и приборов, используется набор методов предварительной обработки для повышения точности исходных данных при спектральном отображении анализируемых веществ. Алгоритмы предварительной обработки SG, MSC, SNV и DT будут реализованы для целей предварительной обработки, чтобы оценить и сравнить их оптимальную эффективность шумоподавления. Процесс предварительной обработки выполняется с использованием программного обеспечения Unscrambler X 10.4 (64-bit).
Фильтр SG — это метод шумоподавления, основанный на аппроксимации методом наименьших квадратов полиномами высокого порядка. Эффект сглаживания контролируется регулировкой ширины окна и порядка фильтра, что может эффективно сохранять форму и высоту спектральной волны. Учитывая, что большой размер окна приводит к более гладкой кривой, вызывая потерю некоторых признаков в пределах диапазонов, сглаживание и сравнение были выполнены с размерами окна 3, 5 и 7 [23]. Процесс расчета MSC заключается в установлении формулы линейной регрессии среднего спектра каждого образца и всех спектров и коррекции исходного спектра путем вычисления линейного переноса и наклона смещения формулы регрессии. SNV корректирует каждый спектр через среднее значение и стандартное отклонение спектральных данных для нормализации стандарта спектральных данных. В случае больших различий в образцах корректирующая способность сильнее. DT помогает удалить неспектральные помехи, такие как температура и влажность в спектре, делая спектральные данные более читаемыми и четкими.
2.5. Разделение образцов
Алгоритм SPXY был использован для разделения набора данных, при этом евклидово расстояние, учитывающее как векторы X, так и Y, рассчитывается, как показано в Уравнении (3), в качестве основы для разделения. Были выбраны два образца с наибольшим расстоянием, а затем из оставшихся образцов было рассчитано наименьшее расстояние до этих двух образцов. Среди образцов с наименьшим расстоянием тот, у которого расстояние наибольшее, выбирается в калибровочное подмножество, и следующий выбор повторяется до достижения требуемого числа образцов [24]. Этот метод может в наибольшей степени охарактеризовать распределение образцов, увеличить разнообразие и репрезентативность частей образцов, и было доказано, что он является более полным при оценке и классификации данных, собранных с помощью ближней инфракрасной спектроскопии [25].
Всего 156 образцов мушмулы были разделены на два набора данных в соотношении 3:1, чтобы получить 109 образцов для калибровочного набора и 47 образцов для прогнозного набора. Распределение TSSC показано в Таблице 1.
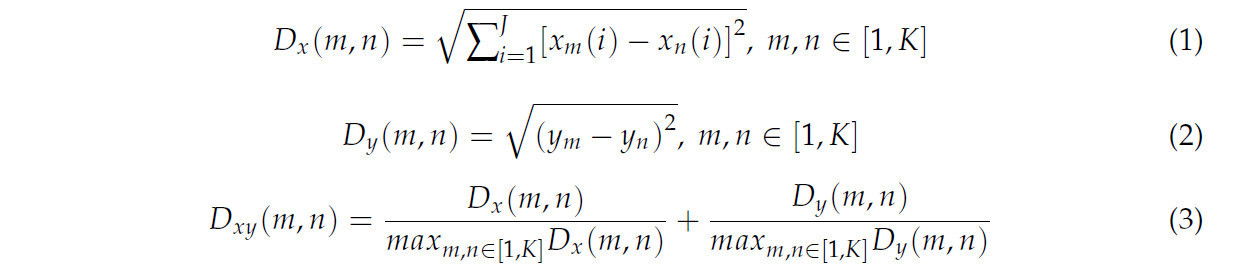
где m и n представляют порядковый номер образца, x_m (i) и x_n (i) — спектральное отражение, соответствующее i-му диапазону образцов m и n, а K — общее количество образцов.

Таблица 1. Распределение TSSC образцов мушмулы для калибровочного и прогнозного наборов.
2.6. Процесс выбора переменных
2.6.1. SPA
Алгоритм последовательного проецирования (SPA) — это метод поиска минимальных коллинеарных переменных с помощью итерационных вычислений. Процесс расчета требует установки начального диапазона и количества переменных, а затем выбора диапазона с наибольшей проекцией на начальный диапазон путем вычисления проекции невыбранного диапазона и начального диапазона. Затем выполняются итерационные вычисления до тех пор, пока не будет выбрано заданное количество переменных. Этот метод можно использовать для уменьшения количества избыточных переменных в последующем моделировании и достижения аналогичных или даже лучших результатов путем замены всех переменных некоторыми переменными для моделирования и прогнозирования.
2.6.2. UVE
Метод удаления неинформативных переменных (UVE) может удалять длины волн, которые вносят наименьший вклад в моделирование на основе алгоритма PLS, и выбирать переменные признаки с помощью статистики информации о нерелевантных переменных шума. Конкретные шаги заключаются в том, что UVE сначала добавляет набор переменных белого шума через модель PLS, а затем выполняет переменные суждения о статистическом распределении коэффициентов регрессии целевой матрицы на основе комбинированной матрицы независимых переменных, где статистическое распределение представлено отношением среднего значения и стандартного отклонения. Наконец, устанавливается порог для определения переменных признаков в соответствующем диапазоне. UVE-SPA сначала выбирает переменные в UVE, а затем выполняет вторичный выбор с помощью SPA для удаления избыточных переменных.
2.6.3. CARS
Алгоритм конкурентной адаптивной перевзвешенной выборки (CARS) выбирает количество переменных с помощью выборки модели Монте-Карло и оценивает важность переменных на основе абсолютных коэффициентов коэффициентов регрессии модели PLS. Адаптивная перевзвешенная выборка (ARS) используется для сохранения точек с большими абсолютными значениями весов коэффициентов регрессии в модели PLS в качестве новых подмножеств, удаляя веса для меньших точек. Затем на основе нового подмножества устанавливается модель PLS. После нескольких вычислений длина волны в подмножестве с наименьшей среднеквадратичной ошибкой перекрестной проверки (RMSECV) модели PLS выбирается в качестве характеристической длины волны [26].
2.6.4. R-Frog
Как алгоритм, основанный на популяции, Random Frog (R-frog) имитирует поведение лягушек, ищущих оптимальные места для кормления на болоте. Обычно выделяют три этапа: первый этап — оценка, инициализация группы лягушек и ее сортировка в порядке убывания в соответствии со значением пригодности. Второй этап — разделение отсортированных лягушек на несколько подгрупп, причем каждая группа может проводить локальный поиск независимо. После того как все подгруппы завершат локальный поиск, они переупорядочиваются и разделяются для следующего раунда локального обновления позиций. Решение проблемы завершается после чередования локального поиска подпопуляции и глобального поиска всей популяции [27].
2.6.5. VCPA-IRIV
VCPA-IRIV — это гибридная стратегия выбора переменных, основанная на непрерывном сжатии пространства переменных. Оптимизация выбора переменных достигается с помощью двух процессов: во-первых, анализ популяции комбинаций переменных (VCPA) используется для генерации различных комбинаций переменных с помощью стратегии выборки двоичной матрицы (BMS) и экспоненциальной функции затухания (EDF) для построения популяции подмодели. Два информационных вектора — частота появления переменных и коэффициент регрессии частичных наименьших квадратов — используются для оценки значения вклада каждой переменной для достижения начального сжатия пространства переменных. Во-вторых, итеративное сохранение информативных переменных (IRIV) и моделирование на основе подмножества переменных, отобранных на этапе VCPA, для исключения переменных, которые не улучшают прогностическую эффективность модели, для дальнейшей оптимизации выбора переменных [28].
2.7. Алгоритм моделирования
2.7.1. PLSR
Регрессия частичных наименьших квадратов (PLSR) — это метод линейного регрессионного моделирования, подходящий для задач, в которых количество переменных превышает количество образцов. Он не только учитывает главные компоненты независимой переменной и зависимой переменной, но также имеет преимущество максимизации корреляции главных компонентов независимой переменной и зависимой переменной соответственно. PLSR выполняется путем выбора первых n главных компонентов, которые могут обеспечить лучшую прогностическую способность, вместо всех главных компонентов. Количество главных компонентов определяется с помощью проверки перекрестной валидности для достижения наилучшей производительности модели [29].
2.7.2. BPNN
Нейронная сеть с обратным распространением (BPNN) — это нелинейный алгоритм, структура которого обычно состоит из трех слоев: входного слоя, одного или нескольких скрытых слоев и выходного слоя. Основной процесс обучения включает: прямое распространение информации и обратное распространение ошибки. Первый шаг прямого функционирования заключается в выполнении расчета первого слоя на основе входного вектора, и выходной результат используется как вход для перехода к следующему слою до тех пор, пока не будет выведен окончательный результат прогнозирования. Второй шаг обратного функционирования заключается в минимизации ошибки между прогнозируемым значением и истинным значением. Эта ошибка называется функцией потерь. Функция потерь — это многофункциональная функция, состоящая из весов и смещений нейронов в каждом слое. Процесс минимизации выполняется с помощью градиентного спуска. По мере выполнения алгоритма веса и смещения постепенно передаются обратно, так что параметры настраиваются до состояния, когда ошибка сетевой модели приближается к нулю [30].
2.7.3. ELM
Машина экстремального обучения (ELM) — это метод машинного обучения с преимуществами меньшего количества параметров обучения и быстрой скорости обучения. Процесс обучения разделен на два этапа: первый — случайное отображение признаков, которое случайным образом генерирует веса и смещения скрытого слоя в соответствии с любым непрерывным распределением вероятностей и использует функцию активации нелинейного отображения для отображения входных данных в новое пространство признаков. Этот способ определения значений параметров делает ELM высокой эффективностью обучения. Второй этап — решение для линейных параметров и минимизация ошибки обучения для нахождения весов скрытого слоя и выходного слоя.
2.8. Оценочные показатели
Три показателя были использованы для оценки производительности модели в прогнозировании TSSC мушмулы. Первый — это среднеквадратичная ошибка, которая оценивается как ошибка между прогнозируемым значением и фактическим значением для каждой модели. Чем ближе значение RMSE к 0, тем лучше прогностический эффект. RMSEC и RMSEP представляют ошибки калибровочного набора и прогнозного набора соответственно. Второй — это коэффициент корреляции R, который показывает эффект аппроксимации. R_c и R_P выражаются как результаты аппроксимации калибровочного набора и прогнозного набора с диапазоном значений от 0 до 1. Чем ближе значение к 1, тем лучше эффект аппроксимации модели. Третий — это остаточное прогностическое отклонение (RPD) прогнозируемого значения. Обычно, если значение находится между 1,4–2,0, модель считается более надежной, а если оно больше 2,0, модель считается высоконадежной и имеет хорошую практическую ценность.
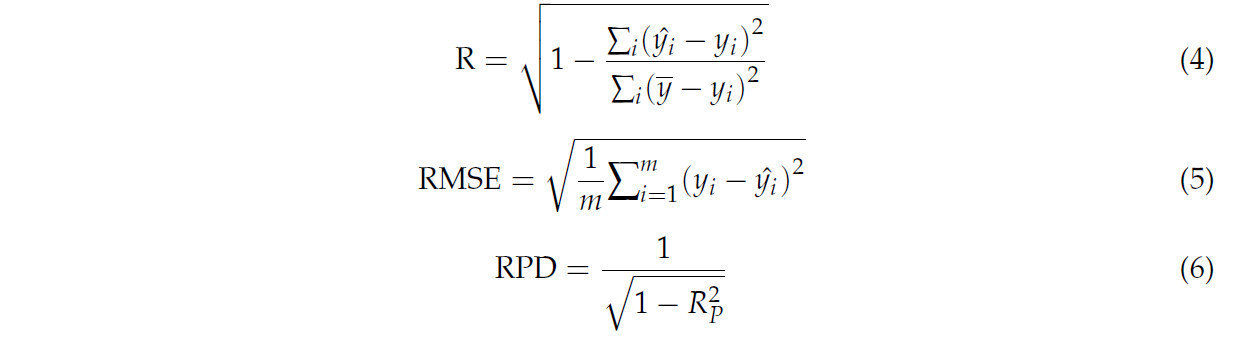
2.9. Объяснение модели
SHAP (Shapley Additive Explanations) основан на значениях Шепли в теории игр, и основная идея заключается в количественной оценке вклада каждого признака в выходной результат модели. Этот подход обеспечивает углубленное объяснение и анализ прогностических моделей как с макро-, так и с микроуровней. SHAP строит аддитивную объяснительную модель, в которой все признаки считаются «участниками», вычисляется влияние всех возможных комбинаций признаков на прогноз, а среднее значение вкладов каждого признака в различных комбинациях признаков включается в оценку SHAP. Признаки с более высоким вкладом ранжируются выше, а признаки с более низким вкладом — ниже.
SHAP имеет специальные интерпретаторы для различных типов моделей, что позволяет проводить всесторонний анализ производительности разных моделей. Кроме того, SHAP не только учитывает величину вклада, но и показывает, способствуют ли эти признаки положительному или отрицательному влиянию на генерацию прогностических результатов через положительные и отрицательные значения [31]. Уравнение (7) показывает формулу для расчета вклада каждого признака для одного образца.
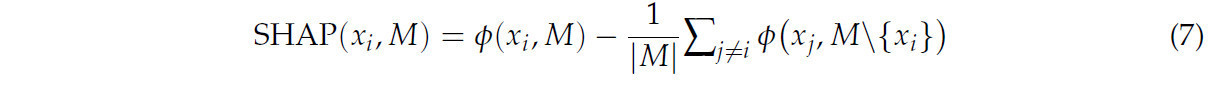
где SHAP(x_i,M) — это значение SHAP для x_i в наборе M. x_i — это i-й признак в модели. M — это набор признаков, включающий x_i и другие признаки. ϕ(x_i,M) — это вклад признака x_i в наборе признаков M в прогноз модели. ϕ(x_j,M\{x_i}) — это вклад признака x_j в прогноз модели в наборе признаков M за исключением x_i. |M| — это количество признаков в наборе признаков M.
В нашем исследовании график Beewarm используется для отображения важных признаков с упорядочением признаков, которое подразумевает информацию о величине влияния, комбинированное влияние признаков рассчитывается как среднее значение абсолютных значений SHAP для всех образцов, а также доступно конкретное распределение SHAP важных признаков.
3. Результаты и обсуждение
Этап предварительной обработки в этом исследовании был выполнен на Unscrambler X 10.4 (CAMO, Осло, Норвегия), а модельные расчеты выполнялись с использованием MATLAB 2018b (The Mathworks Inc., Natick, MA, USA). Вычислительный процесс выполнялся на вычислительной системе HP ENVY x360 с процессором Intel Core i5-10210U (Intel, Калифорния, США) и 16 ГБ ОЗУ в системе Microsoft Windows 10. Модель SHAP вычислялась с использованием Python 3.9 в системе Ubuntu 18.04.
3.1. Интерпретация спектра
Из-за таких факторов, как неравномерное распределение источника света и неправильная форма образца при сборе спектра, в начале и в конце исходного диапазона присутствует большой шум. Диапазоны длин волн 900–927 нм и 1691–1700 нм были исключены перед дополнительным анализом. Как проиллюстрировано на Рисунке 2a, общее спектральное отражение в диапазоне 928–1400 нм составляет от 10% до 55%, в то время как в диапазоне 1400–1600 нм оно находится между 10% и 25%. Мушмула имеет три пика поглощения при 950 нм, 1150 нм и 1410 нм в ближнем инфракрасном спектральном диапазоне. Характерные спектральные пики поглощения плодов мушмулы наблюдались около 950, 1150 и 1410 нм. Пик поглощения при 950 нм приписывается удвоению частоты второго порядка валентного колебания O–H, пик поглощения при 1150 нм — удвоению частоты первого и второго порядка валентного колебания C–H, включая комбинированную частоту удвоения первого порядка валентных колебаний, а пик поглощения при 1410 нм — удвоению частоты первого порядка валентного колебания O–H [32].
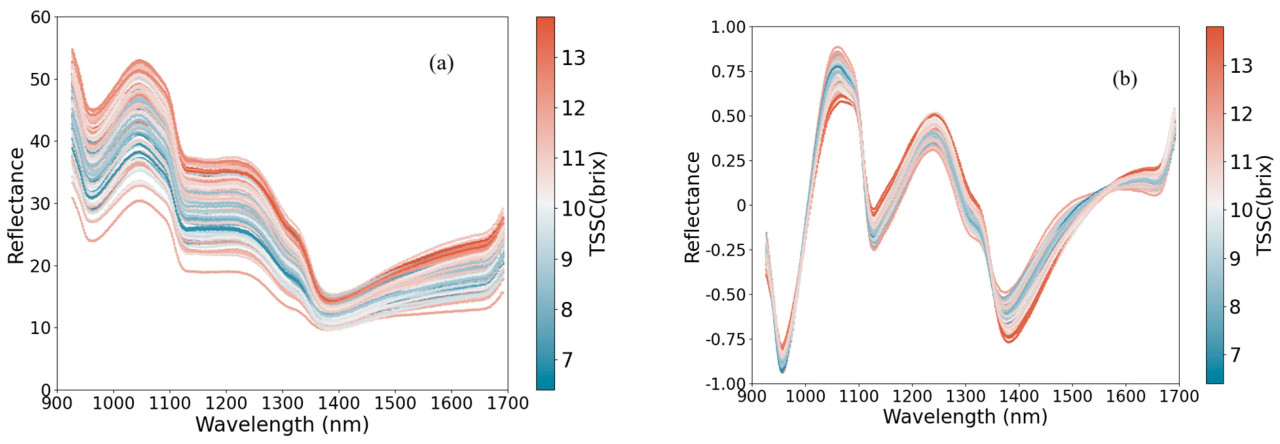
Рисунок 2. (a) Форма исходного спектра, (b) Форма спектра, предварительно обработанная методом SG-SNV-DT.
Растворимые сухие вещества включают растворимые сахара, такие как моносахариды, дисахариды и водорастворимые полисахариды, которые содержат элементы C, H и O, обладающие высокой поглощающей способностью к световой энергии. Кроме того, присутствуют различные органические соединения, включая характерные ароматические компоненты (такие как алканы, углеводороды), пектин, формирующий клеточную структуру, и связанные функциональные группы, ответственные за поглощение энергии, влияющие на изменения в спектре отражения [33].
3.2. Предварительная обработка
Исходный спектр предварительно обрабатывается семью способами, включая одинарные, двойные и многочленные методы, а оценочная модель эффекта предварительной обработки основана на модели PLSR. Как показано в Таблице 2, при использовании предварительно обработанных данных для моделирования как R_P, так и RPD увеличиваются, в то время как RMSE уменьшается, что свидетельствует о том, что предварительная обработка может улучшить качество данных и оказывать значительное положительное влияние на эффект моделирования. Комбинированный метод предварительной обработки SG(7)-SNV-DT имеет наилучший эффект среди всех методов обработки спектров с R_P = 0,8879, RMSEP = 6799 и RPD = 2,0697. Извлечение признаков и моделирование выполняются на спектральных данных, предварительно обработанных методом SG(7)-SNV-DT, и форма волны показана на Рисунке 2b.
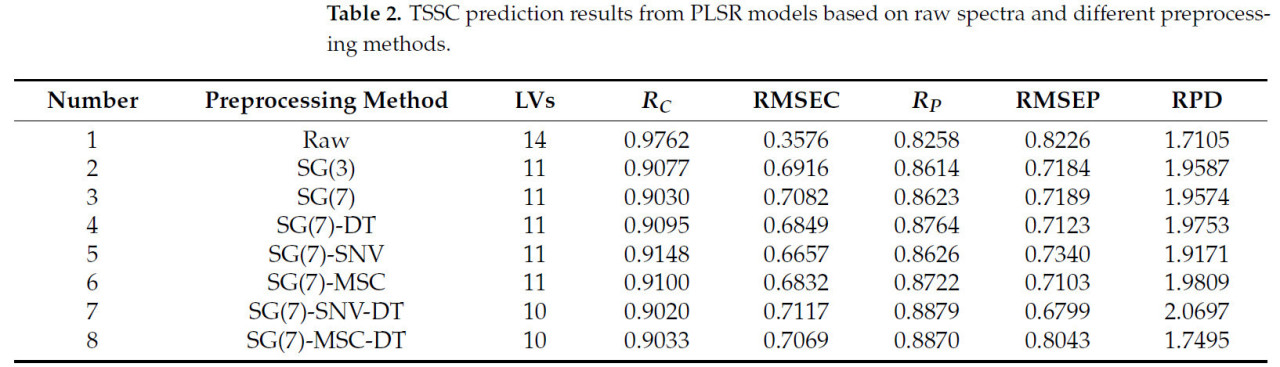
Таблица 2. Результаты прогнозирования TSSC на основе моделей PLSR с использованием исходных спектров и различных методов предварительной обработки.
3.3. Выбор переменных признаков
Предварительная обработка многомерных наборов данных, несомненно, предоставит богатую информацию для исследований и приложений, но также в определенной степени увеличит сложность интерпретируемости данных и последующую вычислительную нагрузку. Учитывая, что слепое сокращение показателей может привести к ошибочным выводам, диапазон, наилучшим образом выражающий спектральные характеристики, выбирается с использованием метода выбора переменных. Шесть методов выбора признаков, используемых для выбора переменных, показаны ниже.
Максимальное количество диапазонов для SPA установлено на 50, а минимальное значение — на 18. Комбинация характеристических диапазонов выбирается на основе RMSE. Когда количество диапазонов, рассматриваемых моделью, достигает 26, RMSE является наименьшей. Выбранный спектр составляет 5,74% от исходного спектра, а основное распределение диапазонов показано на Рисунке 3b.
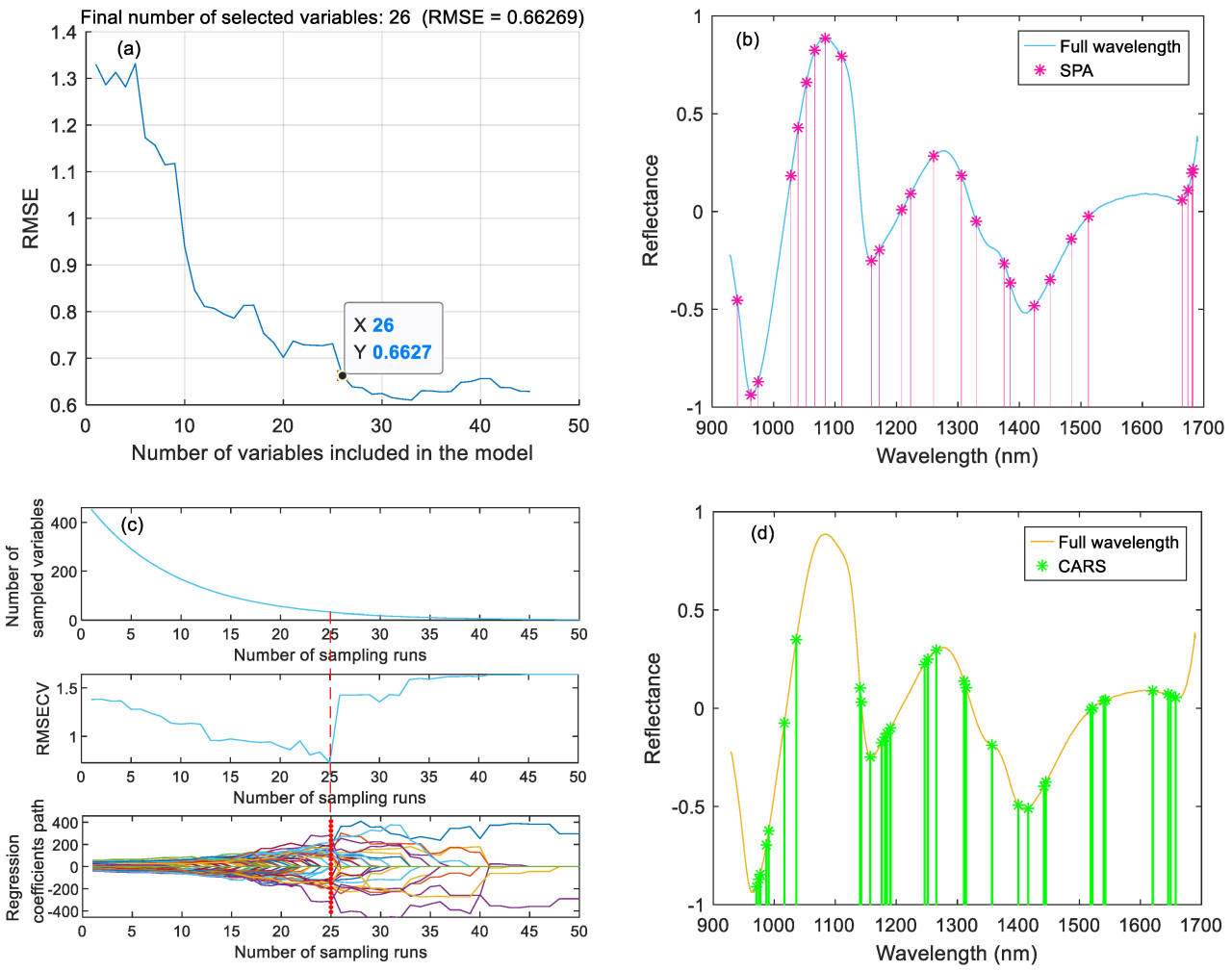
Рисунок 3. (a) Выбор переменных признаков на основе SPA, (b) Распределение переменных признаков, выбранных с помощью SPA, (c) Выбор переменных признаков на основе CARS, (d) Распределение переменных признаков, выбранных с помощью CARS.
При использовании CARS для выбора признаков количество сгибов перекрестной проверки установлено на 5, количество выборок Монте-Карло — на 50, а оптимальная переменная выбирается как соответствующее значение при достижении глобального минимума кривой RMSE. Количество переменных, RMSECV и коэффициенты регрессии во время 50 запусков выборки показаны на Рисунке 3c. Образцы выбираются с помощью экспоненциальной функции затухания, которая прошла два этапа: быстрое сокращение и медленное сокращение. По мере уменьшения переменных RMSECV также соответственно уменьшается. После того как количество запусков превышает критическую точку в 25 раз, больше переменных, содержащих важную информацию, удаляется, и ошибка показывает быструю тенденцию к росту. Поэтому, когда RMSECV минимальна, количество запусков выборки достигает 25 раз. Всего было выбрано 32 переменных, основное распределение показано на Рисунке 3d.
При использовании UVE для извлечения эффективных компонентов спектральных данных 99% абсолютного значения максимальной стабильности матрицы шума устанавливается в качестве порога исключения. На Рисунке 4a слева от вертикальной красной пунктирной линии находится значение стабильности спектра, а справа — значение стабильности шума. Значение, представленное горизонтальной пунктирной линией, представляет собой порог выбора ±64,06. Внутри двух линий находится бесполезная информация, а вне линий — полезная информация. Соответствующее значение является переменной признака, извлеченной UVE, всего 76 диапазонов.
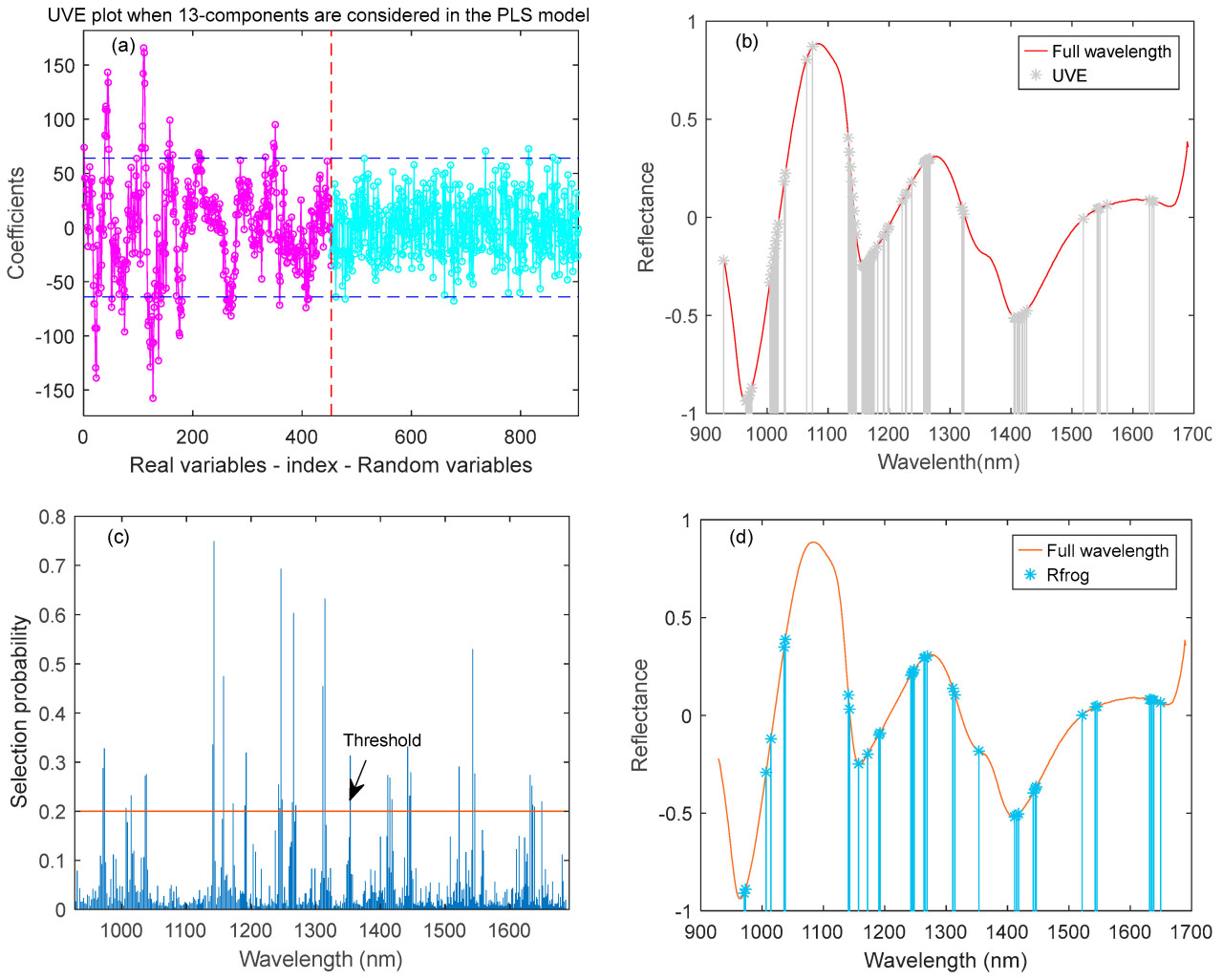
Рисунок 4. (a) Выбор переменных признаков на основе UVE, (b) Распределение переменных признаков, выбранных с помощью UVE, (c) Выбор переменных признаков на основе R-frog, (d) Распределение переменных признаков, выбранных с помощью R-frog.
Количество циклов итерации прыжков R-Frog установлено на 1000. Выбор основан на вероятности появления переменной. Чем выше значение, тем оно важнее. Как показано на Рисунке 4c, выбирается диапазон, соответствующий пороговому значению больше 0,2, и было выбрано 36 номеров диапазонов. Конкретное распределение показано на Рисунке 4d.
Для дополнительного извлечения полезной информации используется SPA для вторичного выбора. Как показано на Рисунке 5a, в итоге было отфильтровано 18 диапазонов.
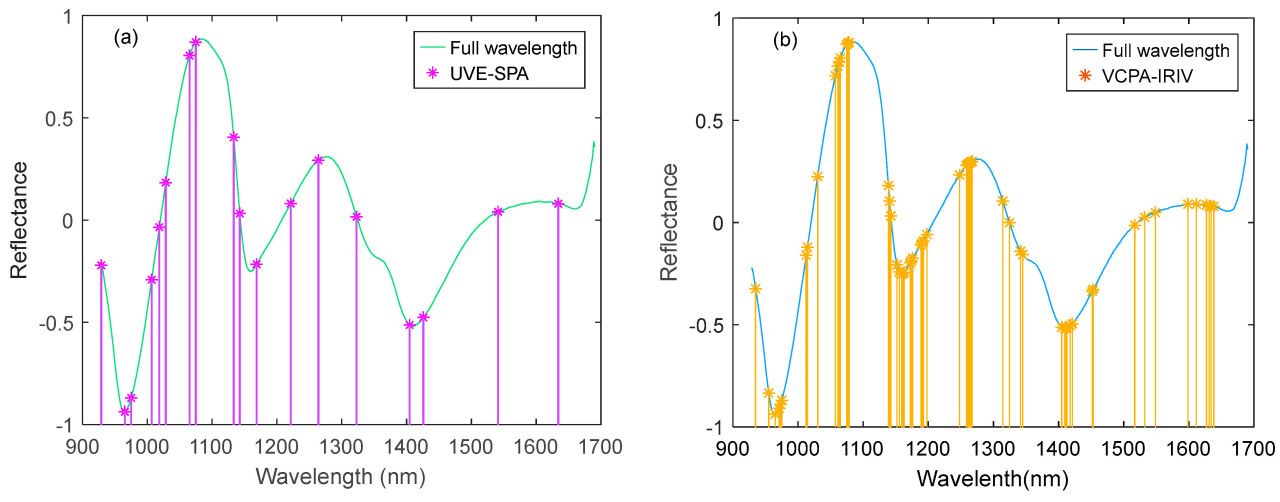
Рисунок 5. Распределение переменных признаков, выбранных методами UVE-SPA (a) и VCPA-IRIV (b).
В VCPA-IRIV BMS установлена на 1000, и будет случайным образом сгенерировано подмножество из 1000 переменных в качестве начальной популяции. Переменные моделируются в соответствии с PLSR, и коэффициент регрессии частичных наименьших квадратов (Reg) для каждой переменной и частота появления рассчитываются как вклад переменной в модель. Сокращение векторного пространства выполнялось с точки зрения величины вклада. Количество запусков EDF составило 50, а количество подмножеств переменных, оставшихся в конце сеанса EDF, L, было установлено на 100, что дает 100 переменных на более поздних этапах VCPA. Подмодель PLS строится на основе этих 100 переменных, и комбинация переменных, имеющая минимальную RMSEP, получается с помощью сеанса IRIV. Избыточные переменные исключаются, и окончательные 56 переменных сохраняются, как показано на Рисунке 5b.
3.4. Моделирование и результаты
Регрессионные модели по-разному реагировали на различные комбинации спектральных переменных, и способность регрессионных моделей, обусловленных спектральными переменными, к определению TSSC была протестирована и проанализирована. Когда полный спектр и диапазоны, выбранные SPA, UVE, CARS, R-Frog, UVE-SPA и VCPA-IRIV, используются в качестве входных данных, соответствующие максимальные главные компоненты модели PLSR составляют: 10, 12, 10, 12, 10, 11 и 9 соответственно, а оптимальное количество нейронов скрытого слоя, соответствующих ELM, составляет 38, 28, 35, 32, 20, 17 и 32 соответственно. В процессе моделирования различные параметры BPNN установлены следующим образом: скорость обучения установлена на 0,001, минимальная ошибка цели обучения — 0,0001, максимальная частота обучения установлена на 1000 раз, скрытых слоев — 1, а функция активации — функция sigmoid. Алгоритм Левенберга–Марквардта, который сочетает метод Ньютона и методы градиентного спуска, был использован для обучения модели. Количество нейронов во входном слое BPNN — это количество диапазонов полного спектра и количество переменных, отфильтрованных SPA, UVE, CARS, R-Frog, UVE-SPA и VCPA-IRIV. Оптимальное количество узлов для соответствующего скрытого слоя составляет 24, 12, 19, 8, 17, 6 и 14 соответственно.
Таблица 3 показывает результаты прогнозирования TSSC с помощью моделей PLSR, BPNN и ELM. В целом, калибровочные наборы моделей незначительно лучше прогнозных наборов, что соответствует общим правилам обучения моделей, а также доказывает эффективность и стабильность моделей. Коэффициенты корреляции PLSR, ELM и BPNN в полном спектре составляют около 0,8, что свидетельствует о наличии линейных и нелинейных отношений между ближним инфракрасным спектром мушмулы и TSSC. Коэффициент корреляции прогнозного набора BPNN ниже, чем у двух других моделей. Основная причина заключается в том, что BPNN значительно зависит от параметров модели, и значение, выбранное на основе опыта, не обязательно является наилучшей точностью, которой может достичь BPNN. Наивысшая точность полнодиапазонной PLSR свидетельствует о том, что линейные характеристики между спектральными данными и TSSC более значительны.
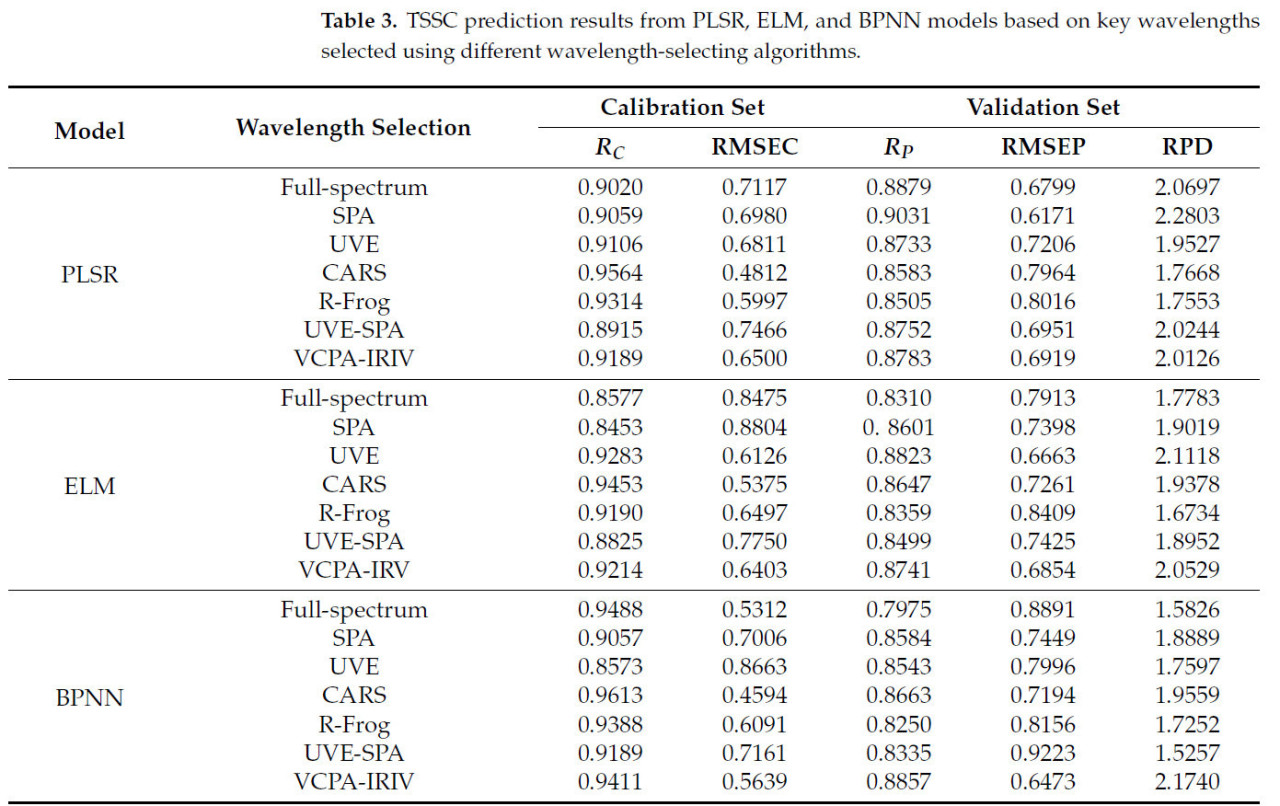
Таблица 3. Результаты прогнозирования TSSC с помощью моделей PLSR, ELM и BPNN на основе ключевых длин волн, выбранных с использованием различных алгоритмов выбора длин волн.
После уменьшения размерности полного спектра количество спектров значительно сокращается, а точность прогнозирования модели не слишком страдает. Любой из упомянутых методов выбора признаков может сделать точность прогнозирования выше, чем при полнодиапазонном моделировании. BPNN наиболее заметно реагирует на спектры с уменьшенной размерностью, а диапазоны после извлечения признаков также более благоприятны для обнаружения TSSC мушмулы с помощью ELM. Кроме того, SPA, CARS и R-Frog сокращают спектральные диапазоны более чем на 90%. SPA имеет лучшую адаптируемость к различным моделям и значительно улучшает точность прогнозирования всех трех моделей. Большее количество диапазонов, сохраненных UVE, играет лучшую роль в ELM. По сравнению с UVE, UVE-SPA выполняет вторичный выбор, сокращая количество переменных на 95%, что незначительно улучшает прогностический эффект модели PLSR, но снижает эффект моделей ELM и BPNN.
UVE-ELM является лучшей среди моделей ELM с коэффициентом корреляции, RMSE и RPD прогнозного набора, равными 0,8823, 0,6663 и 2,1118. Метод VCPA-IRIV оказывает значительное положительное влияние на прогноз модели BPNN с результатом прогнозного набора R_P = 0,8857, RMSEP = 0,6473, RPD = 2,1740. SPA-PLSR показывает наилучшую производительность среди всех моделей с 26 диапазонами, коэффициент корреляции, RMSEP и RPD прогнозного набора составляют 0,9031, 0,6171 и 2,2803 соответственно.
На Рисунке 6 показаны диаграммы рассеяния измеренного TSSC и прогнозируемого TSSC для трех моделей на основе полного диапазона и соответствующих оптимальных методов извлечения признаков. Эти точки показывают тенденцию к приближению к линии регрессии, что свидетельствует о том, что разумный выбор длин волн и моделирование могут приблизительно заменить фактические значения результатами прогнозирования. Отличные результаты прогнозирования были получены с помощью моделирования PLS в сочетании с методом SPA, ELM в сочетании с методом UVE и BPNN в сочетании с методом VCPA-IRIV. Поэтому эффективно проводить исследование измерения TSSC мушмулы с использованием ближней инфракрасной спектроскопии в сочетании с выбором спектральных переменных.
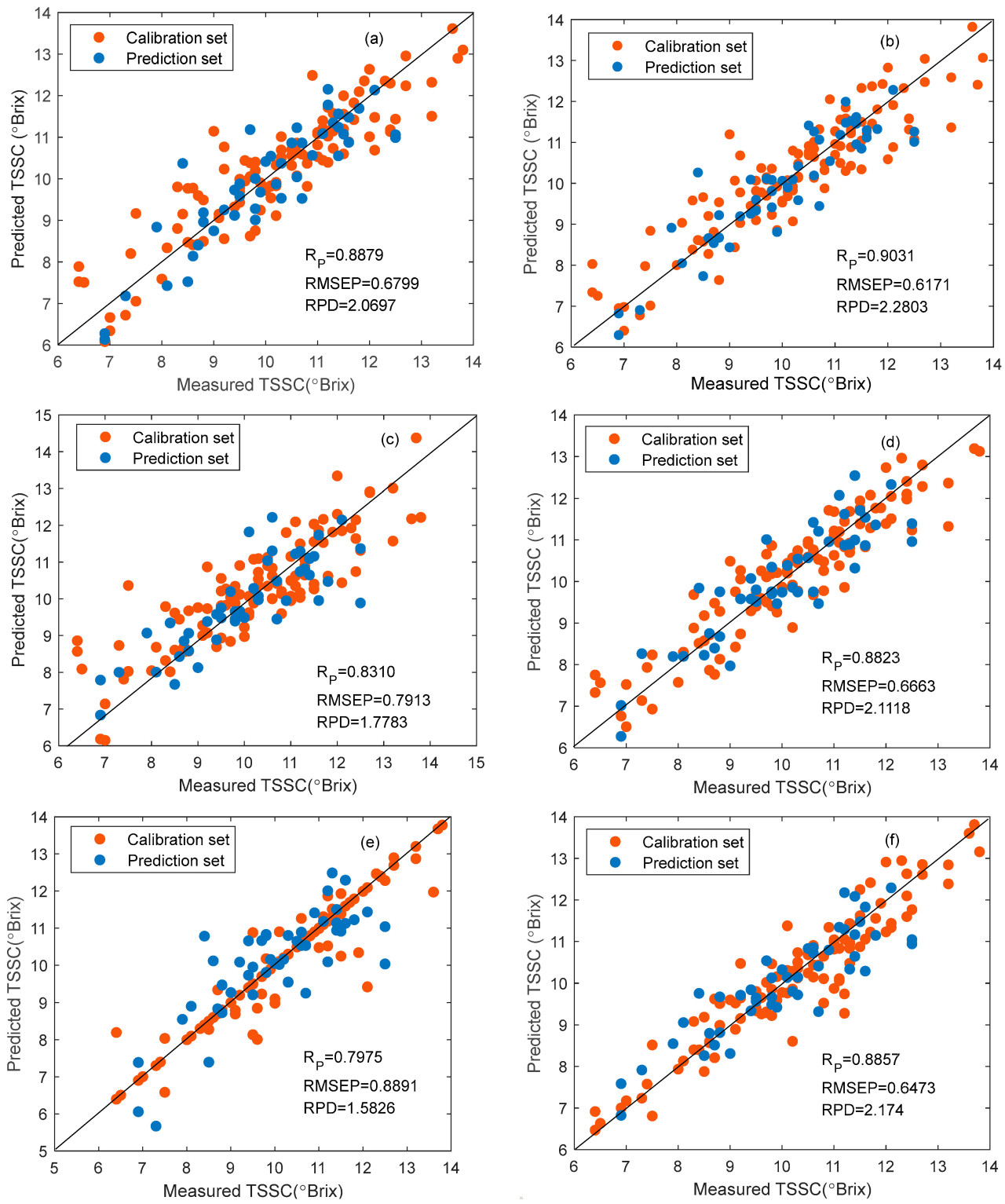
Рисунок 6. Диаграмма рассеяния измеренного TSSC и прогнозируемого TSSC на основе комбинации моделей и характеристических диапазонов. (a) PLSR-Полный спектр, (b) PLSR-SPA, (c) ELM-Полный спектр, (d) ELM-UVE, (e) BPNN-Полный спектр, (f) BPNN-VCPA.
3.5. Объяснимый анализ
В этом разделе исследуется объяснение различий в значениях SHAP на точности прогнозирования моделирования разных моделей с использованием SHAP для интерпретации анализа вклада характеристических длин волн в модель и дополнительного понимания влияния отфильтрованных диапазонов на результаты прогнозирования модели. На Рисунке 7 показаны значения SHAP для высоковлияющих признаков, смоделированных моделями PLS, BPNN и ELM на основе их комбинации признаков с наивысшей точностью прогнозирования соответственно.
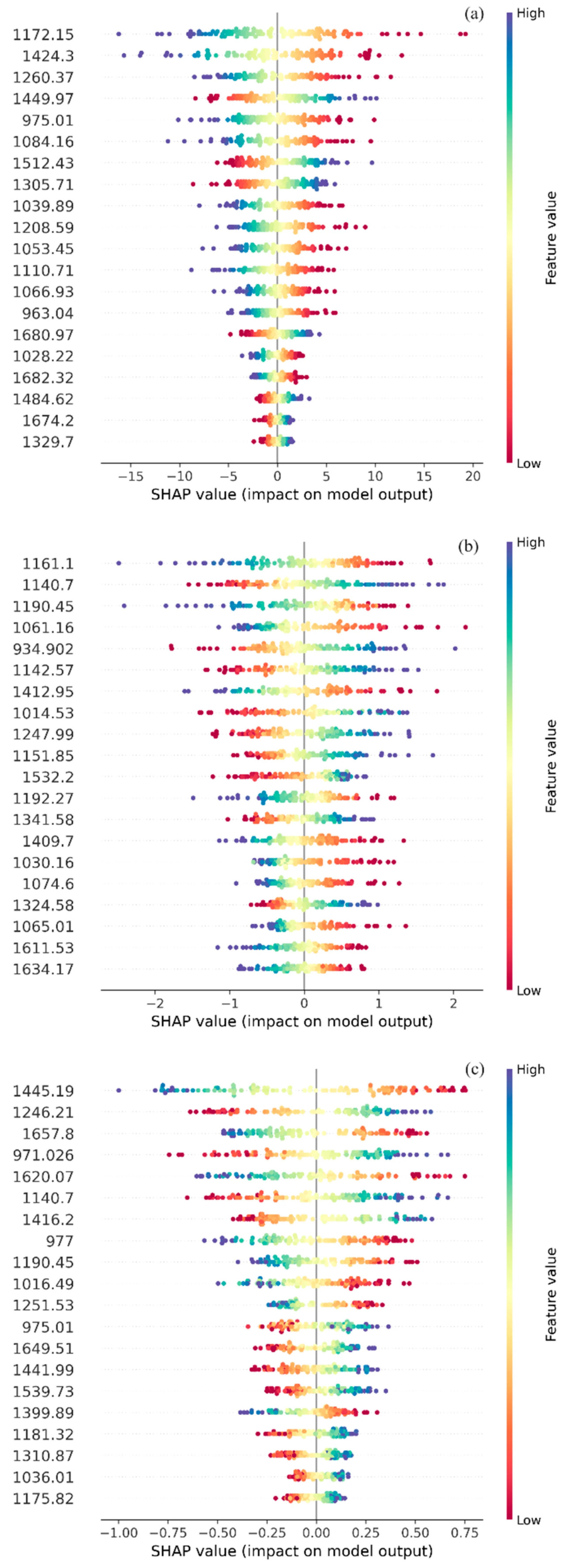
Рисунок 7. Визуализация важности признаков SHAP на основе комбинации моделей (a) PLSR + SPA, (b) ELM + UVE, (c) BPNN + VCPA.
Признаки на графике beeswarm отсортированы сверху вниз на основе среднего значения |SHAP|, и перечислены 20 переменных с наибольшим вкладом. Каждая строка данных на графике представляет распределение SHAP для одного диапазона признаков, причем каждая точка представляет собой отдельный образец, и все 156 образцов мушмулы показаны. Вертикальная ширина указывает на большие кластеры образцов для близких значений SHAP. Более темно-синий цвет точки указывает на большее значение признака, то есть большее значение отражательной способности, а более темно-красный цвет указывает на меньшее значение отражательной способности. Область, в которую попадают точки, имеет значение SHAP > 0, что означает, что признак оказывает положительное влияние на результаты, а значение SHAP < 0 означает, что признак оказывает отрицательное влияние на результаты. Чем шире поперечное распределение точек, тем больше влияние признака на прогнозы модели, и наоборот, чем ближе к 0, тем меньше его влияние на прогнозы.
Для модели PLSR характеристические длины волн, отобранные SPA, имеют наилучший эффект для их [34]. Из Рисунка 7a видно, что длины волн, которые находятся дальше назад в упорядочении, представляют явление, при котором значения SHAP сгруппированы около 0, что означает, что дальние длины волн имеют меньшее влияние на результаты [35]. Напротив, около 1150 нм (1172,15 нм, 1260 нм), 1410 нм (1424,3 нм, 1449,97 нм) и 975,01 нм, изменения которых оказывают большее влияние на прогноз PLS, являются основными диапазонами, которые соответствуют диапазону диапазонов ИК-спектроскопии в ответ на группы C–H, O–H в TSSC. Механизм реакции этих диапазонов на значения TSSC различен: образцы мушмулы с более высокими значениями TSSC имеют более высокие значения отражательной способности в диапазонах 1172,15, 1260, 1424,3 и 975,01 нм, тогда как более высокие значения отражательной способности в диапазоне 1449,97 нм соответствуют более низким значениям TSSC. Эти три диапазона оказывают наибольшее влияние на прогнозирование TSSC, и аналогичные выводы также были сделаны в исследовании [18].
BPNN показывает наилучшую реакцию при обработке диапазонов, отобранных VCPA, и большинство длин волн с высокими вкладами сосредоточены в диапазонах 1040–1190 нм и 1240–1412 нм, как видно из Рисунка 7b. Небольшая разница между уровнями вклада диапазонов, т.е. большее количество диапазонов вносит вклад в результаты модели, также приводит к тому, что некоторые неинформативные переменные попадают в фокус, что является потенциальной причиной более низкой точности прогнозирования по сравнению с PLS-SPA.
Как показано на Рисунке 7b, основные влияющие диапазоны в модели ELM на основе UVE в основном представлены диапазонами около 950 нм и 1150 нм. Диапазоны 1006,67 нм, 1016 нм имеют более широкое распределение значений SHAP, но важность признаков ранжируется дальше назад в случае, когда эти признаки могут влиять на результаты прогнозирования нелинейным способом, и нелинейная модель, такая как ELM, более чувствительна к нелинейным эффектам признаков, и поэтому эти признаки будут вызывать больше колебаний SHAP. Аналогично, диапазоны 973,019 нм, 973,019 нм и 1260,37 нм оказывают нелинейное влияние на результаты прогнозирования.
Каждая регрессионная прогностическая модель основана на различных принципах, которые адаптированы к конкретным практическим задачам [36]. Основываясь на вышеуказанном анализе, мы можем видеть некоторые общие характеристики: в условиях интенсивных стратегий предварительной обработки и выбора признаков PLSR может улавливать потенциальную связь между спектральными данными и показателем TSSC для проблемы мультиколлинеарности в объясняющих переменных, и в сочетании с алгоритмом SPA подходит для прогнозирования TSSC фруктов [37].
4. Выводы
В этом исследовании мы объединили ближнюю инфракрасную спектроскопию с интерпретируемым ИИ для определения и интерпретации TSSC мушмулы с помощью ряда процедур, таких как предварительная обработка, извлечение признаков и построение регрессионных прогностических моделей. Благодаря обширной предварительной обработке и стратегиям выбора, основанным на различных типах, PLSR более подходит для прогнозирования с коммерциализированным TSSC мушмулы в качестве переменной отклика по сравнению с моделями нейронных сетей для случая линейной связи между признаками и откликом, обработки многомерных данных и меньших выборок данных. Метод предварительной обработки SG + SNV + DT показал наилучший эффект моделирования на полном спектре, а модель SPA-PLS превзошла другие модели в определении TSSC (R = 0,9031, RMSEP = 0,6171, RPD = 2,2803). Значения SHAP объясняют это, поскольку длины волн с высокими вкладами SPA-PLS совпадают с длинами волн, связанными с TSSC, а более широкое распределение диапазонов, отобранных UVE и VCPA, более полезно для нелинейных моделей, таких как BPNN и ELM, чтобы использовать преимущества, в то время как больший диапазон диапазонов привносит некоторые посторонние переменные, делая их незначительно менее эффективными, чем SPA-PLS. Это исследование объясняет различия в моделях машинного обучения для определения TSSC мушмулы с помощью информации о спектральных переменных и повышает прозрачность и уверенность в прогнозировании TSSC коммерческой мушмулы.
Ссылки
1. Gisbert, A.D.; Romero, C.; Martínez-Calvo, J.; Leida, C.; Llácer, G.; Badenes, M.L. Genetic Diversity Evaluation of a Loquat (Eriobotrya japonica (Thunb) Lindl) Germplasm Collection by SSRs and S-Allele Fragments. Euphytica 2009, 168, 121–134. [Google Scholar] [CrossRef]
2. Zhu, N.; Nie, Y.; Wu, D.; He, Y.; Chen, K. Feasibility Study on Quantitative Pixel-Level Visualization of Internal Quality at Different Cross Sections Inside Postharvest Loquat Fruit. Food Anal. Methods 2017, 10, 287–297. [Google Scholar] [CrossRef]
3. Ren, G.; Liu, Y.; Ning, J.; Zhang, Z. Assessing Black Tea Quality Based on Visible–near Infrared Spectra and Kernel-Based Methods. J. Food Compos. Anal. 2021, 98, 103810. [Google Scholar] [CrossRef]
4. Ren, G.; Sun, Y.; Li, M.; Ning, J.; Zhang, Z. Cognitive Spectroscopy for Evaluating Chinese Black Tea Grades (Camellia sinensis): Near-infrared Spectroscopy and Evolutionary Algorithms. J. Sci. Food Agric. 2020, 100, 3950–3959. [Google Scholar] [CrossRef] [PubMed]
5. Ren, G.; Wang, Y.; Ning, J.; Zhang, Z. Highly Identification of Keemun Black Tea Rank Based on Cognitive Spectroscopy: Near Infrared Spectroscopy Combined with Feature Variable Selection. Spectroc. Acta Part A Molec. Biomolec. Spectr. 2020, 230, 118079. [Google Scholar] [CrossRef]
6. Nie, L.; Dai, Z.; Ma, S. Enhanced Accuracy of Near-Infrared Spectroscopy for Traditional Chinese Medicine with Competitive Adaptive Reweighted Sampling. Anal. Lett. 2016, 49, 2259–2267. [Google Scholar] [CrossRef]
7. Zeng, S.; Zhang, Z.; Cheng, X.; Cai, X.; Cao, M.; Guo, W. Prediction of Soluble Solids Content Using Near-Infrared Spectra and Optical Properties of Intact Apple and Pulp Applying PLSR and CNN. Spectroc. Acta Part A Molec. Biomolec. Spectr. 2024, 304, 123402. [Google Scholar] [CrossRef] [PubMed]
8. Praiphui, A.; Kielar, F. Comparing the Performance of Miniaturized Near-Infrared Spectrometers in the Evaluation of Mango Quality. Food Meas. 2023, 17, 5886–5902. [Google Scholar] [CrossRef]
9. Qi, H.; Shen, C.; Chen, G.; Zhang, J.; Chen, F.; Li, H.; Zhang, C. Rapid and Non-Destructive Determination of Soluble Solid Content of Crown Pear by Visible/near-Infrared Spectroscopy with Deep Learning Regression. J. Food Compos. Anal. 2023, 123, 105585. [Google Scholar] [CrossRef]
10. Lee, J.S.; Kim, S.-C.; Seong, K.C.; Kim, C.-H.; Um, Y.C.; Lee, S.-K. Quality Prediction of Kiwifruit Based on Near Infrared Spectroscopy. Hort. Sci. Technol. 2012, 30, 709–717. [Google Scholar] [CrossRef]
11. Han, Z.; Li, B.; Wang, Q.; Yang, A.; Liu, Y. Detection Storage Time of Mild Bruise’s Loquats Using Hyperspectral Imaging. J. Spectrosc. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
12. Yin, H.; Li, B.; Liu, Y.; Zhang, F.; Su, C.; Ou-yang, A. Detection of Early Bruises on Loquat Using Hyperspectral Imaging Technology Coupled with Band Ratio and Improved Otsu Method. Spectroc. Acta Part A Molec. Biomolec. Spectr. 2022, 283, 121775. [Google Scholar] [CrossRef]
13. Ore Areche, F.; Flores, D.D.C.; Quispe-Solano, M.A.; Nayik, G.A.; Cruz-Porta, E.A.D.L.; Rodríguez, A.R.; Roman, A.V.; Chweya, R. Formulation, Characterization, and Determination of the Rheological Profile of Loquat Compote Mespilus germánica L. through Sustenance Artificial Intelligence. J. Food Qual. 2023, 2023, 1–12. [Google Scholar] [CrossRef]
14. Sun, J.; Yang, W.; Feng, M.; Liu, Q.; Kubar, M.S. An Efficient Variable Selection Method Based on Random Frog for the Multivariate Calibration of NIR Spectra. RSC Adv. 2020, 10, 16245–16253. [Google Scholar] [CrossRef] [PubMed]
15. Yun, Y.; Bin, J.; Liu, D.; Xu, L.; Yan, T.; Cao, D.; Xu, Q. A Hybrid Variable Selection Strategy Based on Continuous Shrinkage of Variable Space in Multivariate Calibration. Anal. Chim. Acta 2019, 1058, 58–69. [Google Scholar] [CrossRef] [PubMed]
16. Tan, F.; Mo, X.; Ruan, S.; Yan, T.; Xing, P.; Gao, P.; Xu, W.; Ye, W.; Li, Y.; Gao, X.; et al. Combining Vis-NIR and NIR Spectral Imaging Techniques with Data Fusion for Rapid and Nondestructive Multi-Quality Detection of Cherry Tomatoes. Foods 2023, 12, 3621. [Google Scholar] [CrossRef]
17. De Oliveira, G.A.; Bureau, S.; Renard, C.M.-G.C.; Pereira-Netto, A.B.; De Castilhos, F. Comparison of NIRS Approach for Prediction of Internal Quality Traits in Three Fruit Species. Food Chem. 2014, 143, 223–230. [Google Scholar] [CrossRef] [PubMed]
18. Zhao, M.; Cang, H.; Chen, H.; Zhang, C.; Yan, T.; Zhang, Y.; Gao, P.; Xu, W. Determination of Quality and Maturity of Processing Tomatoes Using Near-Infrared Hyperspectral Imaging with Interpretable Machine Learning Methods. LWT-Food Sci. Technol. 2023, 183, 114861. [Google Scholar] [CrossRef]
19. Akulich, F.; Anahideh, H.; Sheyyab, M.; Ambre, D. Explainable Predictive Modeling for Limited Spectral Data. Chemom. Intell. Lab. Syst. 2022, 225, 104572. [Google Scholar] [CrossRef]
20. Ahmed, M.T.; Villordon, A.; Kamruzzaman, M. Hyperspectral Imaging and Explainable Deep-Learning for Non-Destructive Quality Prediction of Sweetpotato. Postharvest Biol. Technol. 2025, 222, 113379. [Google Scholar] [CrossRef]
21. Zhang, G.; Abdulla, W. Explainable AI-Driven Wavelength Selection for Hyperspectral Imaging of Honey Products. Food Chem. Adv. 2023, 3, 100491. [Google Scholar] [CrossRef]
22. Zhong, L.; Guo, X.; Ding, M.; Ye, Y.; Jiang, Y.; Zhu, Q.; Li, J. SHAP Values Accurately Explain the Difference in Modeling Accuracy of Convolution Neural Network between Soil Full-Spectrum and Feature-Spectrum. Comput. Electron. Agric. 2024, 217, 108627. [Google Scholar] [CrossRef]
23. Fang, S.; Wu, S.; Chen, Z.; He, C.; Lin, L.L.; Ye, J. Recent Progress and Applications of Raman Spectrum Denoising Algorithms in Chemical and Biological Analyses: A Review. TrAC Trends Anal. Chem. 2024, 172, 117578. [Google Scholar] [CrossRef]
24. Yang, Z.; Nascimento, Y.M.; Monteiro, J.D.; Alves, B.E.B.; Melo, M.F.; Paiva, A.A.P.; Pereira, H.W.B.; Medeiros, L.G.; Morais, I.C.; Fagundes Neto, J.C.; et al. Fast Determination of Oxides Content in Cement Raw Meal Using NIR Spectroscopy with SPXY Algorithm. Anal. Methods 2018, 10, 1280–1285. [Google Scholar] [CrossRef]
25. Galvao, R.; Araujo, M.; Jose, G.; Pontes, M.; Silva, E.; Saldanha, T. A Method for Calibration and Validation Subset Partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef]
26. Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key Wavelengths Screening Using Competitive Adaptive Reweighted Sampling Method for Multivariate Calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
27. Sarkheyli, A.; Zain, A.M.; Sharif, S. The Role of Basic, Modified and Hybrid Shuffled Frog Leaping Algorithm on Optimization Problems: A Review. Soft Comput. 2015, 19, 2011–2038. [Google Scholar] [CrossRef]
28. Guo, J.; Huang, H.; He, X.; Cai, J.; Zeng, Z.; Ma, C.; Lü, E.; Shen, Q.; Liu, Y. Improving the Detection Accuracy of the Nitrogen Content of Fresh Tea Leaves by Combining FT-NIR with Moisture Removal Method. Food Chem. 2023, 405, 134905. [Google Scholar] [CrossRef]
29. Zhang, H.; Zhan, B.; Pan, F.; Luo, W. Determination of Soluble Solids Content in Oranges Using Visible and near Infrared Full Transmittance Hyperspectral Imaging with Comparative Analysis of Models. Postharvest Biol. Technol. 2020, 163, 111148. [Google Scholar] [CrossRef]
30. Yin, H.; Ma, F.; Wang, D.; He, X.; Yin, Y.; Song, C.; Zhao, L. Establishing a Prediction Model for Tea Leaf Moisture Content Using the Free-Space Method’s Measured Scattering Coefficient. Agriculture 2023, 13, 1136. [Google Scholar] [CrossRef]
31. Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
32. Yu, K.; Zhao, Y.; Liu, Z.; Li, X.; Liu, F.; He, Y. Application of Visible and Near-Infrared Hyperspectral Imaging for Detection of Defective Features in Loquat. Food Bioprocess Technol. 2014, 7, 3077–3087. [Google Scholar] [CrossRef]
33. Yuan, L.; You, L.; Yang, X.; Chen, X.; Huang, G.; Chen, X.; Shi, W.; Sun, Y. Consensual Regression of Soluble Solids Content in Peach by Near Infrared Spectrocopy. Foods 2022, 11, 1095. [Google Scholar] [CrossRef] [PubMed]
34. Luo, W.; Zhang, J.; Liu, S.; Huang, H.; Zhan, B.; Fan, G.; Zhang, H. Prediction of Soluble Solid Content in Nanfeng Mandarin by Combining Hyperspectral Imaging and Effective Wavelength Selection. J. Food Compos. Anal. 2024, 126, 105939. [Google Scholar] [CrossRef]
35. Çifci, A.; Kırbaş, İ. Fusion of Machine Learning and Explainable AI for Enhanced Rice Classification: A Case Study on Cammeo and Osmancik Species. Eur. Food Res. Technol. 2024. [Google Scholar] [CrossRef]
36. Zhao, Y.; Zhang, C.; Zhu, S.; Li, Y.; He, Y.; Liu, F. Shape Induced Reflectance Correction for Non-Destructive Determination and Visualization of Soluble Solids Content in Winter Jujubes Using Hyperspectral Imaging in Two Different Spectral Ranges. Postharvest Biol. Technol. 2020, 161, 111080. [Google Scholar] [CrossRef]
37. Sharma, A.; Kumar, R.; Kumar, N.; Kaur, K.; Saxena, V.; Ghosh, P. Chemometrics Driven Portable Vis-SWNIR Spectrophotometer for Non-Destructive Quality Evaluation of Raw Tomatoes. Chemom. Intell. Lab. Syst. 2023, 242, 105001. [Google Scholar] [CrossRef]

Luo Y, Jin Q, Lu H, Li P, Qiu G, Qi H, Li B, Zhou X. Advancing Loquat Total Soluble Solids Content Determination by Near-Infrared Spectroscopy and Explainable AI. Agriculture. 2025; 15(3):281. https://doi.org/10.3390/agriculture15030281
Перевод статьи «Advancing Loquat Total Soluble Solids Content Determination by Near-Infrared Spectroscopy and Explainable AI» авторов Luo Y, Jin Q, Lu H, Li P, Qiu G, Qi H, Li B, Zhou X., оригинал доступен по ссылке. Лицензия: CC BY. Изменения: переведено на русский язык
Фото: урожай вкусной мушмулы собирают в уезде Цяньси городского округа Бицзе /провинция Гуйчжоу, Юго-Западный Китай/. (Синьхуа). Источник: russian.news.cn. Синьхуа



















































































































Комментарии (0)