Автоматизированные подходы для раннего отличия амаранта Палмера от щирицы водяной
Амарант Палмера и щирица водяная — это два инвазивных вида щирицы, которые стали наиболее проблемными для сельскохозяйственных культур, особенно кукурузы и сои. Среди этих двух видов амарант Палмера наносит больший вред посевам, поскольку он растет быстрее, распространяется быстрее и значительно сильнее снижает урожайность по сравнению с щирицей водяной. Различение амаранта Палмера и щирицы водяной важно для эффективного управления сорняками и повышения урожайности. Однако дифференциация этих двух сорняков на ранней стадии значительно затруднена из-за их сходных морфологических характеристик.
Аннотация
В данном исследовании были использованы три подхода искусственного интеллекта, а именно машинное обучение (ML), глубокое обучение (DL) и обнаружение объектов (OD), для автоматизации идентификации выращенных в теплице амаранта Палмера и щирицы водяной в течение двух недель после появления всходов по их RGB-изображениям. Соотношение сторон, округлость и циркулярность были измерены и поданы на вход моделей классификации ML. Среди четырех использованных моделей ML модель случайного леса достигла наивысшей точности классификации — 70% — всего на 312 обучающих примерах.
В случае глубокого обучения предложенная сверточная нейронная сеть, обученная на однообъектных RGB-изображениях амаранта Палмера и щирицы водяной, достигла точности классификации 93%, превзойдя лучшую модель ML. Набор изображений для модели DL был увеличен с исходного размера 2000 до 16 000 с помощью различных методов аугментации.
Наконец, была разработана модель обнаружения объектов на основе трансферного обучения для локализованной идентификации сорняков. Модель OD была создана путем дообучения головной части YOLOv5, предварительно обученной на наборе данных COCO, с использованием 3200 однообъектных изображений (изображения с одной листвой либо амаранта Палмера, либо щирицы водяной). Модель OD, разработанная в этом исследовании, достигла точности 83,5% и может идентифицировать листья сорняков независимо от их размера и близости друг к другу.
1 Введение
Амарант Палмера (Amaranthus palmeri) и щирица водяная (Amaranthus tuberculatus) — это два инвазивных вида щирицы (Bradley и др., 2022; Roberts and Florentine, 2022), которые представляют серьезную угрозу для продуктивности ряда пропашных культур, особенно кукурузы и сои (Massinga и др., 2001; Bensch и др., 2003; Steckel and Sprague, 2004). Оба этих сорняка характеризуются быстрым ростом в идеальных условиях выращивания (Bradley и др., 2022; Roberts and Florentine, 2022). Они конкурируют с культурами за важнейшие ресурсы (свет, воду и питательные вещества) и вызывают резкое снижение их урожайности (Berger и др., 2015; Butts и др., 2018; Mahoney и др., 2021). Однако известно, что амарант Палмера является более агрессивным, чем щирица водяная, по нескольким причинам. Амарант Палмера может расти быстрее, чем щирица водяная; например, в исследовании, проведенном Perkins и др., зафиксирована скорость роста 55 мм в день для амаранта Палмера и 44 мм в день для щирицы водяной на необработанных покровных культурах (Perkins и др., 2021). Кроме того, виды амаранта демонстрируют большую способность к распространению по полям из-за меньшего размера семян, что приводит к более широкому заражению посевных площадей. Более того, широко распространены гербицидоустойчивые биотипы амаранта Палмера. Джонатон и Кристи (Kohrt and Sprague, 2017) сообщили, что амарант Палмера устойчив к шести сайтам действия гербицидов, включая глифосат. Chahal и др. (2015) сообщили, что амарант Палмера является одним из очень немногих сорняков в Соединенных Штатах, которые выработали устойчивость к группам гербицидов с множественными механизмами действия, включая ингибиторы 5-енолпирувилшикимат-3-фосфатсинтазы (EPSPS), ингибиторы сборки микротрубочек, ингибиторы ацетолактатсинтазы (ALS), ингибиторы гидроксифенилпируватдиоксигеназы (HPPD) и ингибиторы фотосистемы (PS) II (Heap, 2020). Эти аргументы свидетельствуют о необходимости распознавания амаранта Палмера и щирицы водяной для эффективного управления сорняками.
Полностью выросший амарант Палмера можно дифференцировать вручную от щирицы водяной по его морфологическим характеристикам, таким как форма листа, длина черешка, наличие водяного знака, наличие волосков на кончике листа и наличие прицветников (Ikley and Jenks, 2019). Сравнение морфологических характеристик амаранта Палмера и щирицы водяной подробно описано в Таблице 1. Хотя было проведено обширное исследование их морфологии растений для их идентификации (Trucco и др., 2006; Molin and Nandula, 2017), отсутствуют исследования, которые используют методы машинного обучения и глубокого обучения для их различения в поле в крупном масштабе. Кроме того, эти явные различия, наблюдаемые в их морфологии, отсутствуют на ранних стадиях их роста (в течение двух недель после появления всходов), и поразительное сходство амаранта Палмера с щирицей водяной на ранних стадиях представляет значительную проблему для идентификации отдельных сорняков. В качестве альтернативы, генетическое тестирование может быть надежно использовано на ранней стадии (Montgomery и др., 2019). Генетическое тестирование включает сбор образцов семян сорняков, проведение их геномного секвенирования, поиск специфических генетических различий и разработку генетических маркеров для отличия амаранта Палмера от других видов на основе ДНК (Jiang and Köhler, 2012). Однако процесс генетического тестирования (как тестирование ткани листьев, так и тестирование образцов семян) является дорогостоящим, а также трудоемким процессом, который включает ручное вмешательство на нескольких этапах тестирования. Таким образом, цель данного исследования — отличать амарант Палмера от щирицы водяной на ранних стадиях (в первые две недели после появления всходов) с использованием автоматизированных подходов, таких как методы машинного обучения, глубокого обучения и обнаружения объектов.
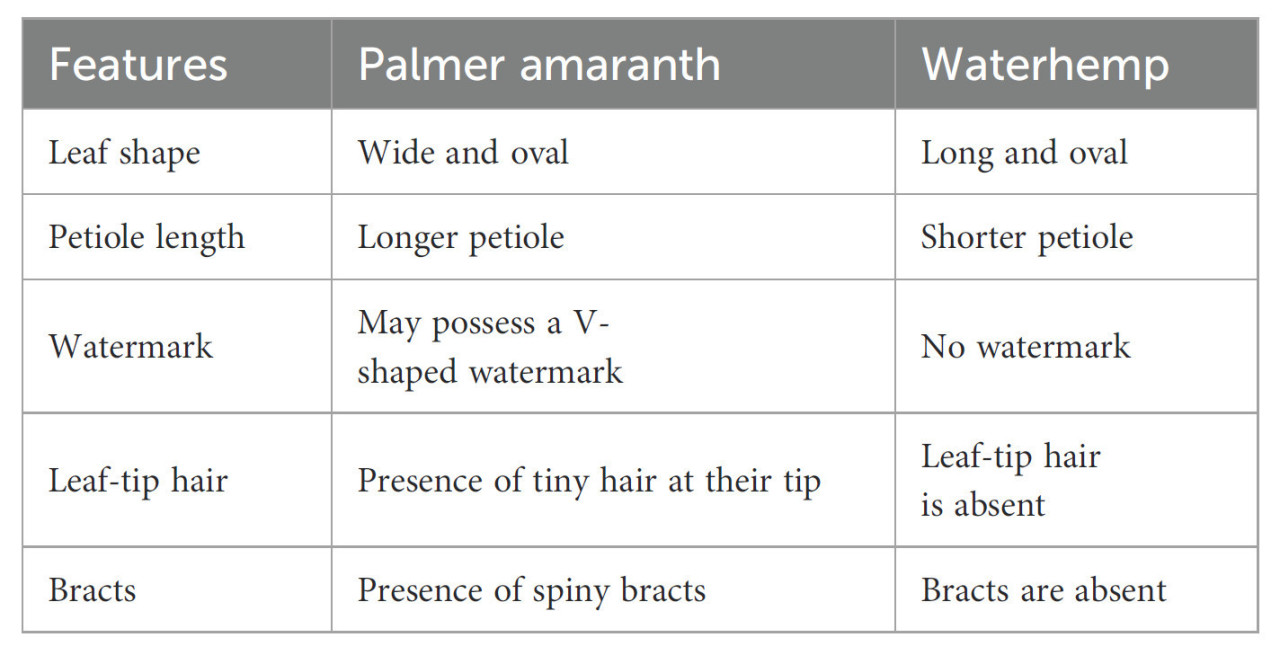
Таблица 1 Морфологические характеристики амаранта Палмера и щирицы водяной.
Мы предполагаем, что можно автоматически отличать амарант Палмера от щирицы водяной на ранних стадиях после появления всходов, используя только данные изображений. Общая цель этого исследования — обучить методы машинного обучения, глубокого обучения и локализованного обнаружения с использованием данных изображений для автоматического различения амаранта Палмера и щирицы водяной на ранних стадиях. Для этой цели используются несколько методов машинного обучения и подход глубокого обучения для различения амаранта Палмера и щирицы водяной с использованием признаков листьев и RGB-изображений соответственно. Кроме того, модель обнаружения объектов обучена для локализованной идентификации сорняков на изображениях, содержащих смешанную листву обоих сорняков. Хотя раннее обнаружение амаранта Палмера само по себе весьма выгодно, предложенные методы могут служить диагностическими методами до того, как будут применены более сложные и длительные процедуры обнаружения, такие как генетическое тестирование. Несмотря на это, предложенные методы в значительной степени зависят от точности обучающих данных и качества изображений, используемых для классификации сорняков.
Остальная часть рукописи организована следующим образом: Раздел 2 кратко описывает общий подход к исследованию, используемый в работе; Раздел 3 обсуждает процесс получения изображений сорняков и предварительную обработку; Раздел 4 описывает анализ геометрических параметров листьев; Разделы 5, 6 и 7 описывают детали моделей и результаты, полученные с помощью методов машинного обучения, глубокого обучения и обнаружения объектов, соответственно; Раздел 8 резюмирует выводы, сделанные из исследования; и, наконец, Раздел 9 подробно описывает ограничения и направление будущих исследований текущей работы.
2 Общий подход к исследованию
Текущее исследование сосредоточено на внедрении трех важных автоматизированных задач для управления сорняками и анализе производительности внедренных моделей. Тремя автоматизированными задачами являются: 1. Классификация двух видов сорняков (амаранта Палмера и щирицы водяной) с помощью популярных методов машинного обучения; 2. Классификация двух видов сорняков с использованием подхода глубокого обучения; и 3. Идентификация отдельных сорняков на изображении с помощью современной техники обнаружения объектов. Процесс исследования начинается с получения изображений растений амаранта Палмера и щирицы водяной в лабораторных условиях. Полученные изображения впоследствии предварительно обрабатываются для удаления незначительных признаков и становятся пригодными для обучения моделей ИИ (искусственного интеллекта). Затем из обработанных изображений извлекаются признаки листьев и анализируется распределение признаков листьев. После этого модели машинного обучения обучаются классифицировать два вида сорняков с использованием извлеченных признаков листьев из предварительно обработанных изображений, за чем следует обучение модели глубокого обучения с использованием непосредственно изображений. Производительность моделей анализируется и впоследствии сравнивается. Наконец, с использованием трансферного обучения обучается модель обнаружения объектов на изображениях, содержащих случайную смесь растений амаранта Палмера и щирицы водяной. Методология, использованная в этом исследовании, представлена на Рисунке 1.
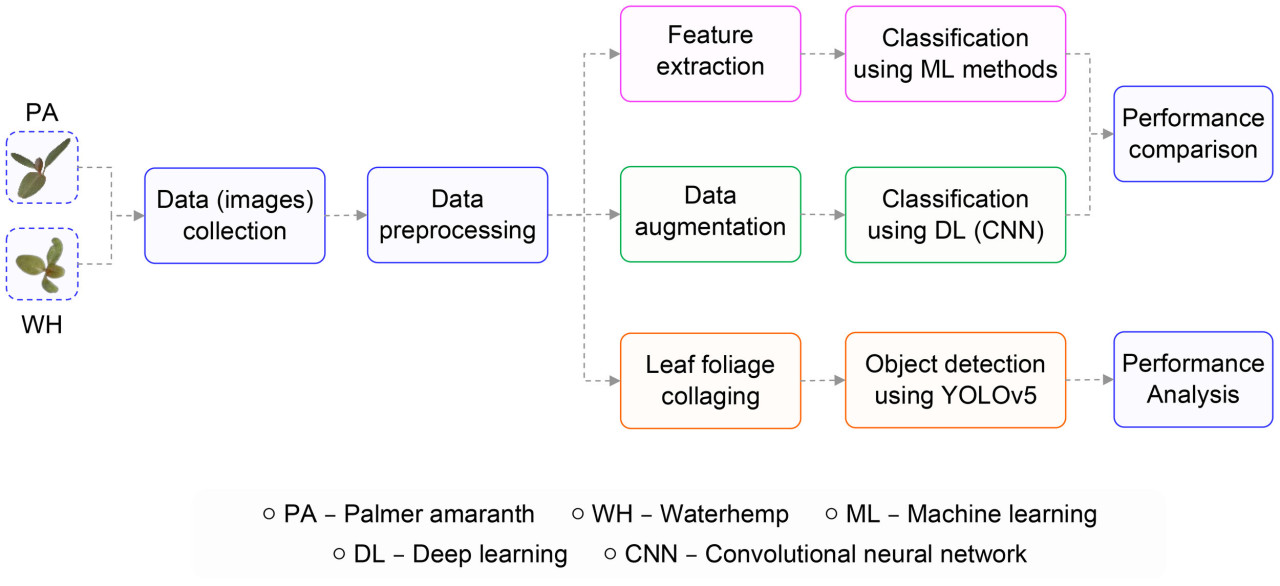
Рисунок 1 Иллюстрация методологии исследования, использованной в данной работе.
3 Методы исследования
3.1 Методы сбора данных и предварительной обработки
Процесс сбора данных для этого исследования включает получение изображений двух целевых видов сорняков: амаранта Палмера (PA) и щирицы водяной (WH). Семена обоих видов были получены в отдельных упаковках, и перед посадкой было проведено генетическое тестирование для проверки идентичности видов. Пятьдесят растений каждого вида были выращены в горшках в контролируемых тепличных условиях в Университете штата Северная Дакота (NDSU), Фарго, Северная Дакота. Чтобы предотвратить любое смешение видов во время роста и сбора данных, растения амаранта Палмера и щирицы водяной выращивались в отдельных обозначенных зонах теплицы с постоянными напольными маркерами, указывающими вид.
Горшки постоянно орошались в контролируемых условиях, а получение изображений выполнялось с помощью высококачественной камеры (24.2 MP Canon EOS Rebel T7i DSLR, оснащенной объективом EF-S 18-55mm f/4-5.6 IS STM), установленной на стабильной платформе, с объективом, сфокусированным нормально к выровненной поверхности почвы горшка. Изображения были сделаны в контролируемых условиях освещения, при этом тепличные огни были выключены, чтобы предотвратить помехи процессу получения изображений. Также было уделено внимание тому, чтобы рост растений не затруднялся и не повреждался во время процесса получения изображений.
Чтобы обеспечить точную маркировку данных и предотвратить любое смешение изображений между видами, получение изображений проводилось последовательно — завершая все изображения для одного вида перед переходом к следующему. Во время получения изображений временный идентификационный лист с названием вида помещался в каждый кадр для последующего подтверждения. Изображения получались ежедневно со дня появления всходов с 13:00 до 15:00 и снимались на трех различных высотах: 5 см, 10 см и 20 см от поверхности почвы, с сохранением угла 90 градусов к поверхности почвы горшка. Детали экспериментальной установки предоставлены в Таблице 2. Всего было получено 2000 изображений: по 1000 изображений амаранта Палмера и щирицы водяной. Исходные изображения были получены в формате RAW и преобразованы в JPEG, состоящие из трех каналов (красный, зеленый и синий) с разрешением 4020 × 6024 пикселей. Полученные изображения прошли предварительную обработку для обучения моделей классификации и идентификации объектов. Протокол предварительной обработки включал систематическое удаление второстепенных признаков, таких как область горшка, мертвые листья, почвенный фон и временные идентификационные листы, с использованием инструмента Image Segmenter в MATLAB. Конечные предварительно обработанные изображения состоят только из растений на черном фоне, как показано на Рисунке 2.
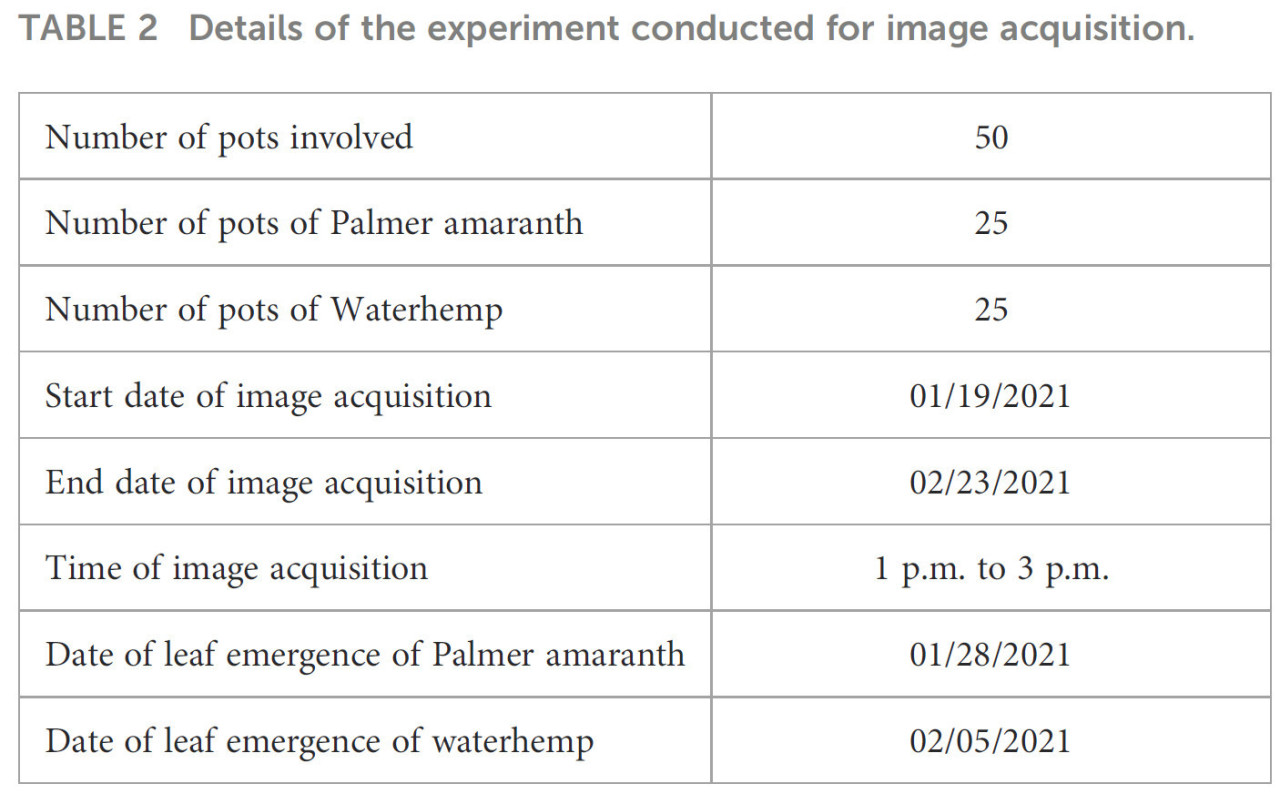
Таблица 2 Детали эксперимента, проведенного для получения изображений.

Рисунок 2 (A) Исходное изображение листвы сорняка, и (B) изображение после удаления посторонних признаков.
3.2 Методы оценки точности моделей классификации
В этом исследовании используются пять ключевых метрик для оценки производительности моделей искусственного интеллекта (ИИ): 1) точность классификации, 2) матрица ошибок (матрица неточностей, конфузионная матрица — переведено как "матрица ошибок" для естественности, т.к. "конфузионная" не используется в русскоязычной научной литературе. При необходимости могу заменить обратно.), 3) точность (precision), 4) полнота (recall) и 5) F1-показатель (F1-score). Для моделей классификации точность сообщается для всего набора данных, в то время как матрица ошибок, точность, полнота и F1-показатель применяются для оценки показателей по классам. Напротив, для модели обнаружения объектов используется только точность классификации, но она также оценивается на основе каждого класса. Детали этих метрик объяснены ниже. Точность классификации — это отношение количества правильно классифицированных экземпляров к общему количеству проверяемых экземпляров. Матрица ошибок является важным показателем производительности после точности классификации. Это таблица сопряженности, которая суммирует (в виде подсчетов или пропорций) правильные и неправильные классификации экземпляров данных отдельных классов. Строки матрицы ошибок соответствуют истинным классам, а столбцы матрицы ошибок соответствуют предсказанным классам. Размер матрицы ошибок составляет nc × nc. Здесь nc обозначает количество меток классов, в нашем случае nc = 2, так как меток классов две: «PA» (амарант Палмера) и «WH» (щирица водяная). Диагональные элементы матрицы ошибок фиксируют правильно классифицированные экземпляры каждого класса, а внедиагональные элементы фиксируют экземпляры каждого класса, неправильно классифицированные в другие классы. На Рисунке 3A показана иллюстративная матрица ошибок, использованная в этом исследовании. «PP», «PW», «WP», «WW» показаны как записи этой матрицы ошибок. Первая буква записи обозначает истинный класс, а вторая буква обозначает предсказанный класс. Например, «WP» представляет экземпляры, принадлежащие к классу щирицы водяной (W), классифицированные в класс амаранта Палмера (P). Точность, полнота и F1-показатель определяются с использованием записей матрицы ошибок. Эти три метрики вычисляются по классам (индивидуально для каждого класса) с использованием выражений, приведенных в Таблице 3. Точность — это отношение количества правильно предсказанных экземпляров класса к общему количеству предсказаний, сделанных для этого класса. Полнота — это отношение количества правильно предсказанных экземпляров класса к общему количеству экземпляров в этом классе. Точность измеряет точность предсказаний классов, тогда как полнота измеряет степень, в которой идентифицированы истинные экземпляры класса. F1-показатель объединяет обе эти метрики и является средним гармоническим точности и полноты.
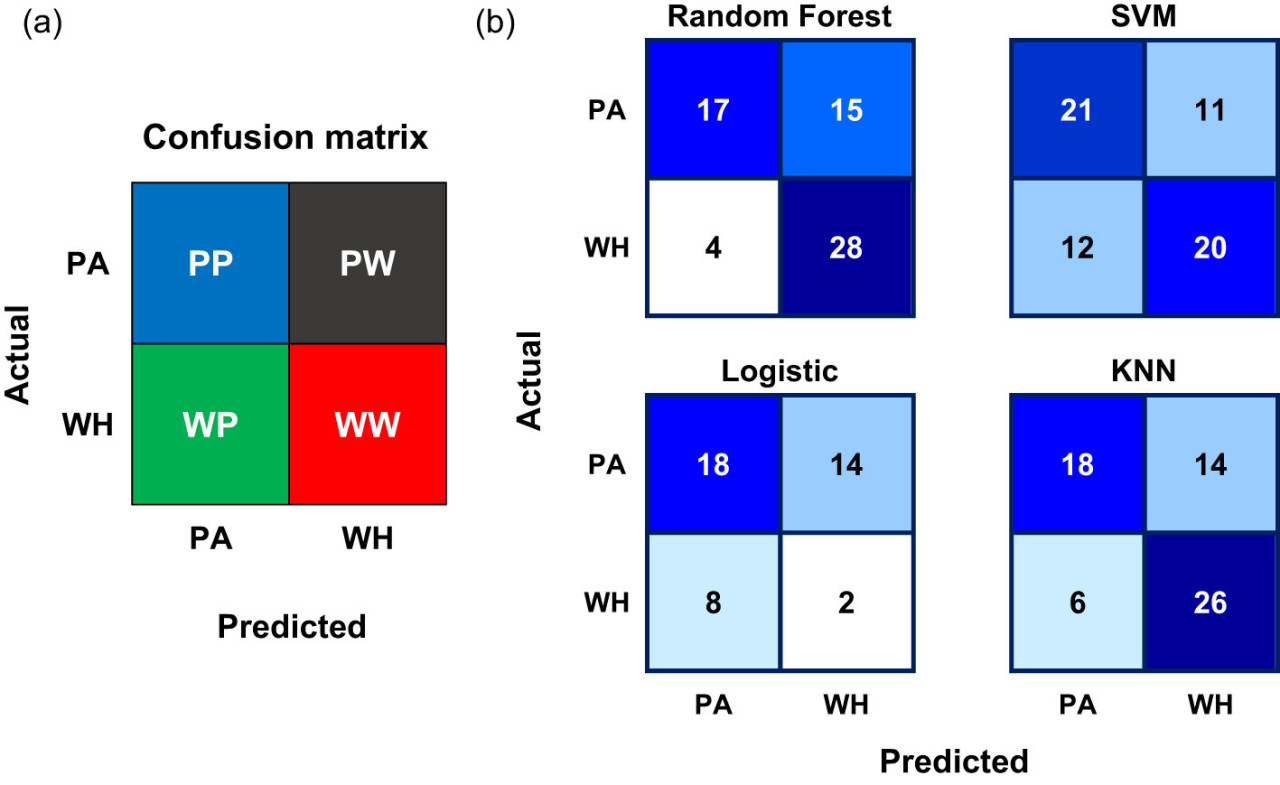
Рисунок 3 (A) Иллюстративная матрица ошибок для классификации амаранта Палмера (PA) и щирицы водяной (WH). Первая буква метки внутри ячейки матрицы обозначает истинную категорию, а вторая буква метки обозначает предсказанную категорию. (B) Матрицы ошибок моделей ML: 1. Случайный лес (RF), 2. Метод опорных векторов (SVM), 3. Логистическая регрессия (LR) и 4. Метод k-ближайших соседей (KNN), использованных для классификации PA и WH. Диагональные элементы матриц ошибок показывают количество правильно классифицированных экземпляров, а внедиагональные элементы показывают количество неправильно классифицированных экземпляров.
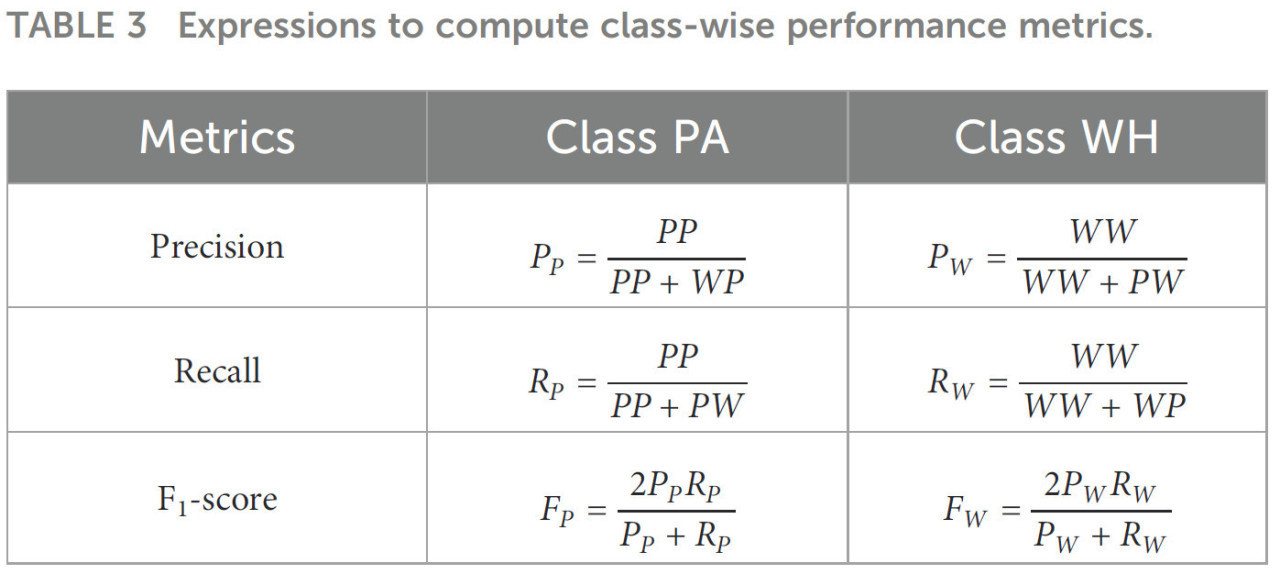
Таблица 3 Выражения для вычисления показателей производительности по классам.
4 Результаты и обсуждение
4.1 Классификация амаранта Палмера и щирицы водяной с использованием подхода машинного обучения
Модели машинного обучения (ML) — это компьютерные алгоритмы, которые могут принимать решения или делать прогнозы, неявно обучаясь на основе данных, переданных им. Подходы ML менее требовательны к данным и, таким образом, подходят, когда прогнозы должны быть сделаны с небольшим объемом данных (Mahesh, 2020). Соответственно, подходы ML требуют меньших вычислительных затрат и занимают меньший период обучения. В нашем текущем исследовании используются четыре популярных подхода машинного обучения, а именно метод опорных векторов (SVM), метод k-ближайших соседей (KNN), случайный лес (RF) и логистическая регрессия (LR), для классификации амаранта Палмера и щирицы водяной. Обучение этих моделей машинного обучения начинается с генерации данных посредством извлечения признаков, за которым следует подготовка структурированного (табличного) набора данных, конфигурация моделей классификации и последующий анализ производительности.
4.2 Генерация данных для подхода машинного обучения
Набор данных, необходимый для обучения моделей машинного обучения для классификации амаранта Палмера и щирицы водяной, включает два этапа: 1. Извлечение геометрических признаков видов сорняков из изображений листьев и 2. Вычисление безразмерных входных признаков (предикторов). Геометрические параметры были получены из предварительно обработанных изображений листьев амаранта Палмера и щирицы водяной, полученных с 8-го по 14-й день после появления всходов (см. Раздел 3). Всего было случайным образом отобрано 36 отдельных листьев каждого вида, что дало 312 наблюдений (по 156 на каждый вид). Изображения листьев с искажениями были исключены из анализа для обеспечения точных измерений. Геометрические параметры листьев, а именно длина (L), ширина (B), периметр (P) и площадь (A), были измерены на предварительно обработанных изображениях каждого вида сорняков (амарант Палмера и щирица водяная) с использованием программного обеспечения ImageJ. Длина (L) измерялась вдоль оси черешка (главной оси) листа, в то время как ширина (B) измерялась перпендикулярно главной оси. Периметр (P) и площадь (A) получали путем трассировки кривой вдоль границы листа. Затем геометрические параметры были использованы для вычисления безразмерных величин, включая соотношение сторон (θ), циркулярность (ψ) и округлость (R), с использованием формул, приведенных в Таблице 4. Эти безразмерные признаки были выбраны в качестве входных предикторов для моделей машинного обучения, потому что предыдущие исследования (Aakif and Khan, 2015; Salve и др., 2016; Elnemr, 2017) продемонстрировали, что они эффективно фиксируют важнейшую дискриминационную информацию из исходных геометрических параметров. Кроме того, использование безразмерных параметров гарантирует, что признаки не зависят от увеличения изображения, обеспечивая согласованность в различных масштабах изображений. Кроме того, использование меньшего количества признаков позволяет моделям машинного обучения обучаться более эффективно, часто требуя меньше примеров для выявления основных закономерностей.

Таблица 4 Выражения для вычисления безразмерных величин листа.
Где L и B — длина и ширина листа по главной и вспомогательной осям соответственно, A — площадь листа, а P — периметр.
4.3 Подготовка набора данных для подхода машинного обучения
Затем был подготовлен табличный набор данных с этими безразмерными геометрическими величинами листьев в качестве входных признаков (предикторов) из 312 экземпляров данных, поровну разделенных между двумя видами сорняков. Табличный набор данных D1 состоит из массива признаков X1 ∈ Rⁿˣᵐ и вектора меток Y1 ∈ Rⁿˣ¹, где n — количество экземпляров данных, а m — количество входных признаков. В данном случае n и m равны 312 и 3 соответственно. k-я строка массива признаков определяется как x⁽ᵏ⁾ = (x₁⁽ᵏ⁾, …, xₘ⁽ᵏ⁾), где x₁⁽ᵏ⁾, …, xₘ⁽ᵏ⁾ — входные признаки, а k изменяется от 1 до n. Табличный набор данных разделен на обучающий (D1,tn) и тестовый (D1,tt) наборы данных с соотношением 70:30. После этого модели ML, использованные в исследовании, обучаются на обучающем наборе данных Dtn. Производительность моделей затем оценивается с помощью тестового набора данных Dtt с использованием таких метрик, как точность классификации, матрица ошибок, точность, полнота и F1-показатель (Naser and Alavi, 2021).
4.4 Предварительный анализ данных об извлеченных данных
Перед применением моделей машинного обучения для классификации был проведен предварительный анализ данных для изучения эволюции безразмерных геометрических величин для каждого вида сорняков. Этот анализ был направлен на понимание того, как входные признаки (предикторы) — соотношение сторон (θ), циркулярность (ψ) и округлость (R) — изменяются с течением времени после появления всходов как для амаранта Палмера, так и для щирицы водяной. Эволюция средних значений этих величин с 8-го по 14-й день после появления всходов была построена на Рисунке 4. Средние соотношения сторон амаранта Палмера и щирицы водяной, построенные на Рисунке 4A, демонстрируют общую тенденцию к снижению в течение дней роста. Среднее соотношение сторон амаранта Палмера постепенно падает с 3,01 (день 8) до 2,74 (день 14), тогда как у щирицы водяной оно падает с 2,39 до 2,10. Рисунок 4A также иллюстрирует, что средние соотношения сторон амаранта Палмера значительно меньше, чем средние соотношения сторон щирицы водяной во все дни роста (день 8 – день 14). Рисунки 4B, C подтверждают общую тенденцию к увеличению средней циркулярности и средней округлости как для амаранта Палмера, так и для щирицы водяной. Однако обе эти величины демонстрируют лишь незначительные колебания в течение дней роста. Средняя циркулярность амаранта Палмера и щирицы водяной находится в диапазоне 0,64–0,67 и 0,74–0,78 соответственно, тогда как значения средней округлости находятся в диапазоне 0,38–0,42 и 0,46–0,54 соответственно. Рисунки 4B, C также показывают, что средняя циркулярность и округлость щирицы водяной значительно выше, чем у амаранта Палмера между 8 и 14 днем. Несмотря на то, что средние значения этих безразмерных параметров демонстрируют четкое различие между амарантом Палмера и щирицей водяной, разброс этих отдельных величин в каждый день роста (между 8 и 14 днем) демонстрирует более широкую вариацию и значительное перекрытие между двумя видами сорняков (см. Рисунок 5). Очевидно, что графики на Рисунках 5A–C демонстрируют необходимость моделей машинного обучения для точной классификации амаранта Палмера и щирицы водяной.
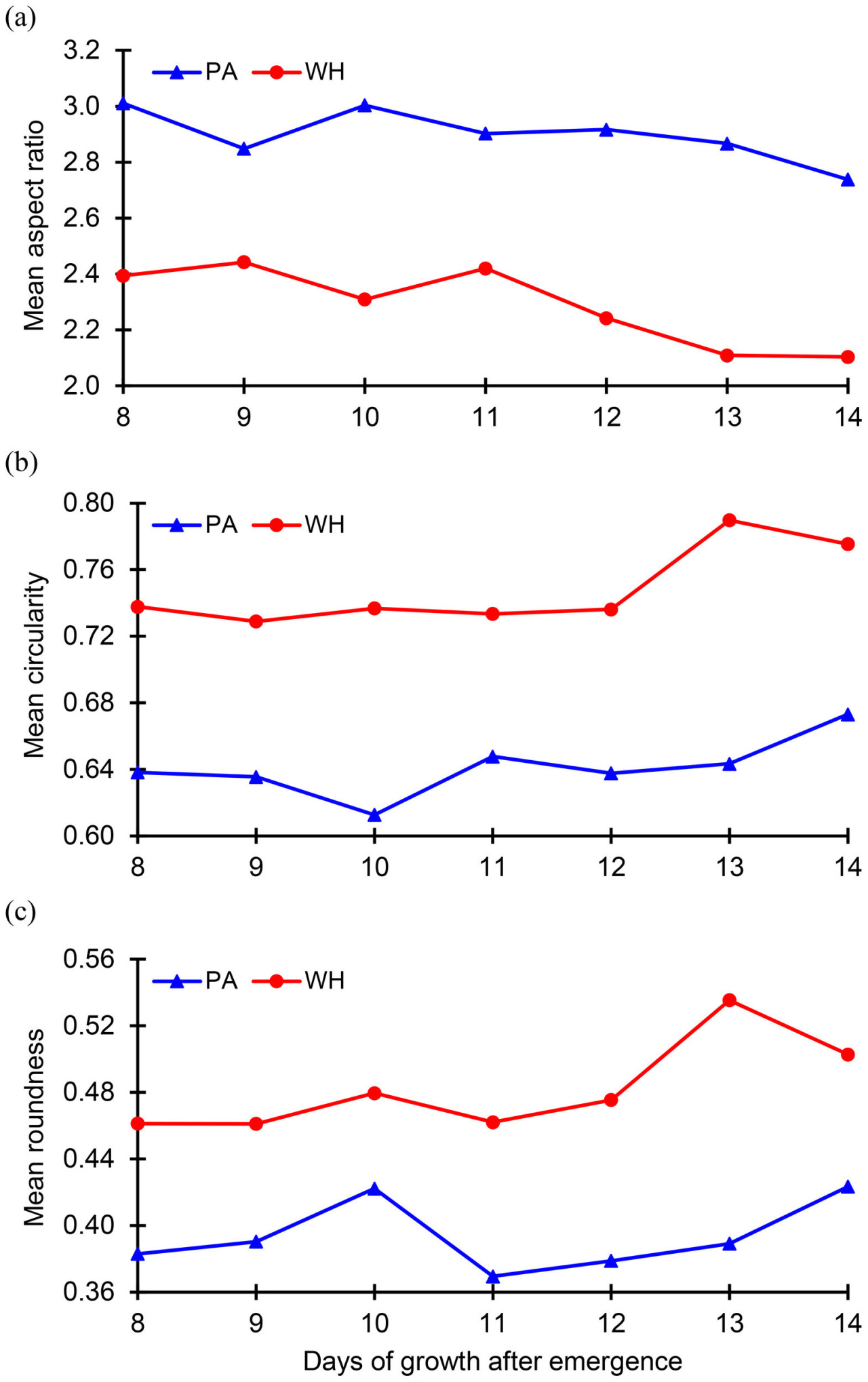
Рисунок 4 График (A) среднего соотношения сторон, (B) средней циркулярности и (C) средней округлости листьев сорняков в течение второй недели роста амаранта Палмера (PA) и щирицы водяной (WH).
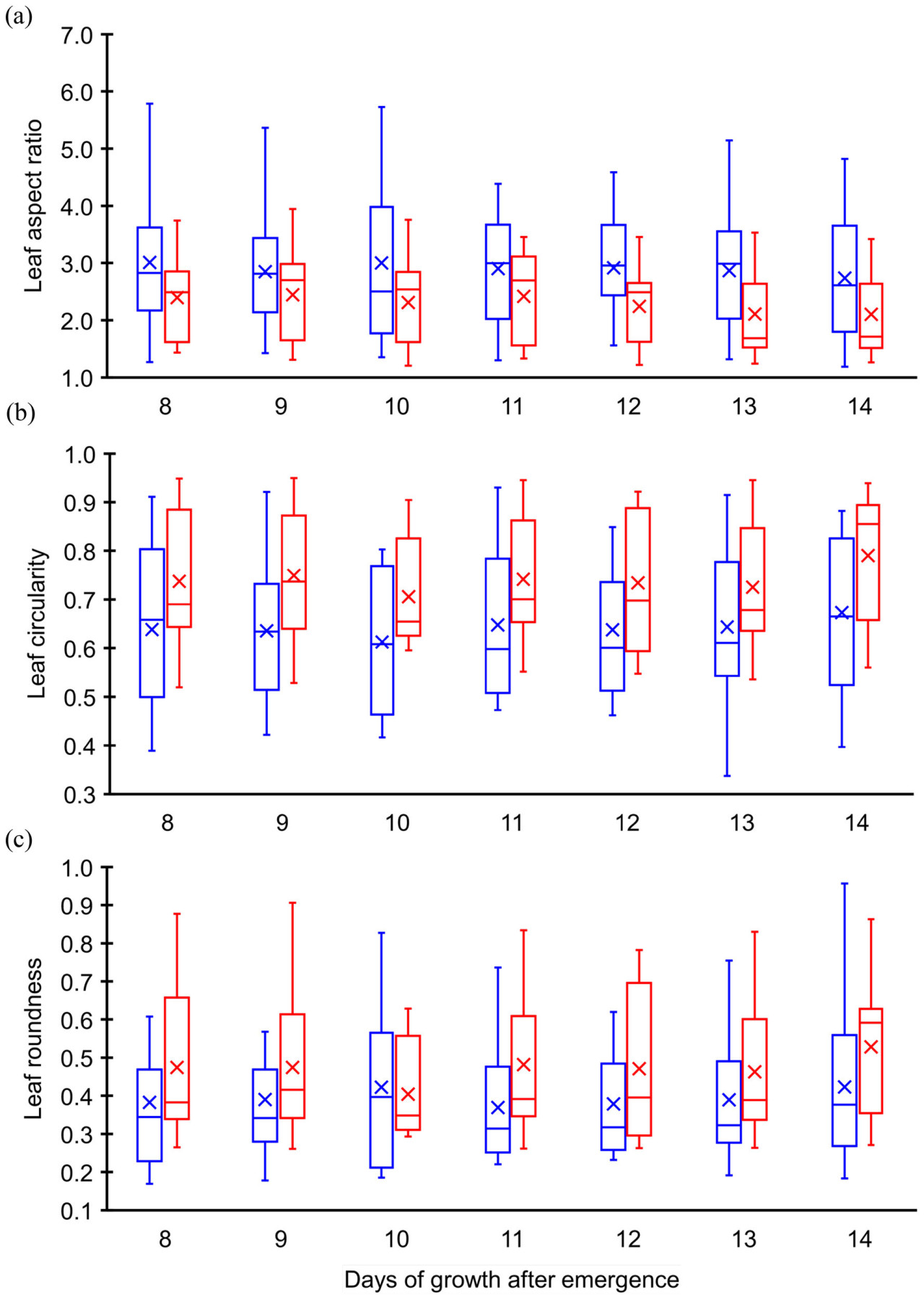
Рисунок 5 Сравнение с помощью коробчатой диаграммы (A) соотношения сторон листа, (B) циркулярности и (C) округлости. Синий (слева) представляет амарант Палмера, а красный (справа) представляет щирицу водяную.
4.5 Конфигурация моделей классификации машинного обучения
4.5.1 Метод опорных векторов
SVM (Pisner and Schnyer, 2020) — один из наиболее широко используемых алгоритмов машинного обучения с учителем, известный своей способностью классифицировать данные путем построения гиперплоскостей, которые максимизируют разрыв между опорными векторами. Для линейно разделимых данных применяется жесткий (hard) разрыв, в то время как для нелинейно разделимых данных используется мягкий (soft) разрыв. SVM также использует метод ядра для решения нелинейных задач классификации. Обычно используемые ядра включают линейное, полиномиальное ядро, ядро радиальной базисной функции (RBF) и сигмоидное ядро.
В этом исследовании мы использовали SVM с ядром RBF. Двумя ключевыми гиперпараметрами в SVM являются параметр штрафа (C) и коэффициент ядра (γ). Параметр C контролирует компромисс между максимизацией разрыва и минимизацией ошибок классификации путем наложения штрафа на неправильные классификации. Более высокое значение C приводит к модели с меньшим смещением и большей дисперсией, что означает, что она ставит целью минимизацию ошибок, но может переобучаться. Параметр γ определяет кривизну решающей границы, контролируя влияние каждой точки данных на границу. Более высокий γ делает модель более чувствительной к отдельным точкам данных, что приводит к более сложной решающей границе.
Чтобы найти оптимальные значения для C и γ, мы использовали поиск по сетке с перекрестной проверкой (с использованием метода GridSearchCV из пакета SciPy). В этом процессе C логарифмически изменялся от 10⁻¹ до 10³ с шагом в степени 10, в то время как γ изменялся от 10⁻⁴ до 1. Мы использовали пятикратную перекрестную проверку для оценки производительности в различных разбиениях набора данных, оптимизируя для наиболее точной модели. В результате этой настройки гиперпараметров лучшие оценки параметров для C и γ были найдены равными 100 и 1 соответственно.
4.5.2 Классификатор случайного леса
Классификатор RF (Probst и др., 2019) — это метод ансамблевого обучения, который состоит из нескольких классификаторов решающих деревьев, часто называемых оценщиками. Каждый оценщик строится путем случайного выбора подмножества признаков из входных данных, и он классифицирует входные данные, отдавая голос за конкретный класс. Окончательный прогноз классификатора RF определяется путем агрегирования голосов всех отдельных деревьев, при этом класс, получивший большинство голосов, выбирается в качестве выходных данных.
Несколько гиперпараметров влияют на производительность классификатора RF. Они включают количество оценщиков, которое определяет, сколько решающих деревьев используется; максимальную глубину, которая ограничивает глубину каждого дерева для предотвращения переобучения; минимальное количество выборок на лист, которое ограничивает количество выборок, необходимых в каждом узле-листе; и минимальное количество выборок для разделения, которое определяет, сколько выборок необходимо для разделения узла. Кроме того, может применяться бутстрэп (bootstrapping) для внесения дисперсии путем выборки подмножеств данных при построении деревьев.
В нашем исследовании мы варьировали эти гиперпараметры, проверяя количество оценщиков от 10 до 200, максимальную глубину от 10 до 100, минимальное количество выборок на лист со значениями 1, 2 и 4, минимальное количество выборок для разделения со значениями 2, 5 и 10, и мы рассматривали как бутстрэп, так и его отсутствие. Для эффективного поиска лучших гиперпараметров мы использовали метод случайного поиска со 100 итерациями и пятикратной перекрестной проверкой, как реализовано в RandomizedSearchCV SciPy. Этот подход, являющийся более вычислительно эффективной альтернативой поиску по сетке, помог определить оптимальные гиперпараметры: 73 оценщика, максимальная глубина 50, минимальное количество выборок для разделения 10, минимальное количество выборок на лист 4 и включенный бутстрэп. Эти настройки обеспечили лучшую производительность модели для классификатора RF в этом исследовании.
4.5.3 Метод k-ближайших соседей
Подход KNN (Taunk и др., 2019) включает функции расстояния для поиска группы из «k» экземпляров, которые наиболее близки к неизвестным образцам. Евклидово, Минковского, Манхэттенское и косинусное расстояние — вот некоторые из обычно используемых функций расстояния. В нашем исследовании используется евклидово расстояние, широко используемая функция расстояния. В KNN выбор k напрямую влияет на компромисс смещения и дисперсии модели. Более низкое значение k приводит к низкому смещению, но высокой дисперсии, что приводит к потенциальному переобучению, в то время как более высокое значение k приводит к высокому смещению и низкой дисперсии, рискуя недообучением. В этом исследовании мы варьировали значение k от 3 до 30 с шагом 1 и выбрали значение k, равное 5, как то, которое обеспечило наилучшую производительность на тестовом наборе.
4.5.4 Логистическая регрессия
LR (Gladence и др., 2015) моделирует взаимосвязь между входными признаками и целевой переменной с использованием сигмоидной функции, которая отображает выходные данные в вероятности между 0 и 1. Модель обучается с использованием оценки максимального правдоподобия в качестве функции потерь. Для бинарной классификации экземпляры данных с предсказанной вероятностью, меньшей или равной 0,5, классифицируются как класс 0, в то время как экземпляры с вероятностью более 0,5 классифицируются как класс 1. В отличие от других моделей, логистическая регрессия не требует настройки гиперпараметров, что делает ее простым и эффективным подходом для задач бинарной классификации.
Все эти четыре модели машинного обучения были обучены с оптимизацией гиперпараметров с использованием пакета SciPy 1.7.3 в среде Python.
4.6 Эффективность классификации обученных ML-моделей
Точности классификации использованных ML-моделей сравниваются на Рисунке 6, и из рисунка видно, что модель случайного леса достигла высшей точности классификации в 70%. Тем не менее, точности классификации других трех моделей не сильно отличаются от точности модели случайного леса. Точности классификации ML-моделей находятся в диапазоне от 64% до 70%. На Рисунке 3B показаны матрицы ошибок, полученные для четырех ML-моделей. Матрицы ошибок всех ML-моделей, кроме SVM, показывают, что количество неправильных классификаций экземпляров PA (в WH) выше, чем количество неправильных классификаций экземпляров WH (в PA). Следовательно, количество правильно классифицированных экземпляров PA меньше, чем количество правильно классифицированных экземпляров WH в матрицах ошибок этих моделей. Интересно, что, хотя неправильные классификации как PA, так и WH выше в SVM, чем в других трех моделях, это единственная модель, где неправильные классификации PA и WH почти равны или сбалансированы. Точность PA и WH для ML-моделей построена на Рисунке 7A, значения полноты построены на Рисунке 7B, а значения F1-показателя построены на Рисунке 7C. Точность PA (0,81) наибольшая для модели случайного леса. Точность WH почти одинакова во всех моделях (0,63–0,65) и ниже, чем точность PA во всех моделях, кроме модели SVM. Полнота PA наивысшая (0,66) для модели SVM, а полнота WH наивысшая (0,88) для модели случайного леса. F1-показатель PA наивысший (0,64) для модели SVM, а F1-показатель WH наивысший (0,75) для модели случайного леса. Модель случайного леса либо превосходит другие три модели, либо работает незначительно лучше них в большинстве случаев. Она показывает наихудшие результаты только в случае полноты PA (0,53).
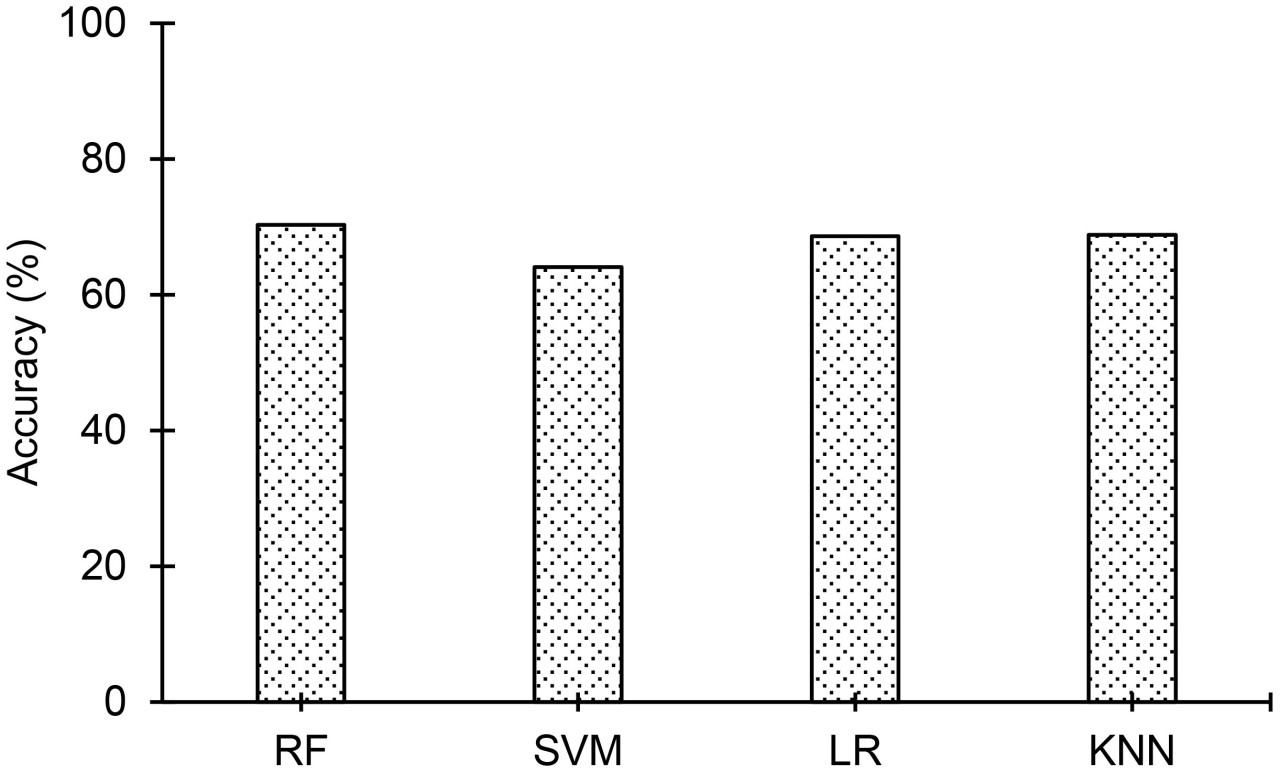
Рисунок 6 Сравнение точностей классификации ML-моделей: 1. Случайный лес (RF), 2. Метод опорных векторов (SVM), 3. Логистическая регрессия (LR) и 4. Метод k-ближайших соседей (KNN), использованных в исследовании. Модель случайного леса достигает высшей точности классификации — 70,3% — среди ML-моделей.
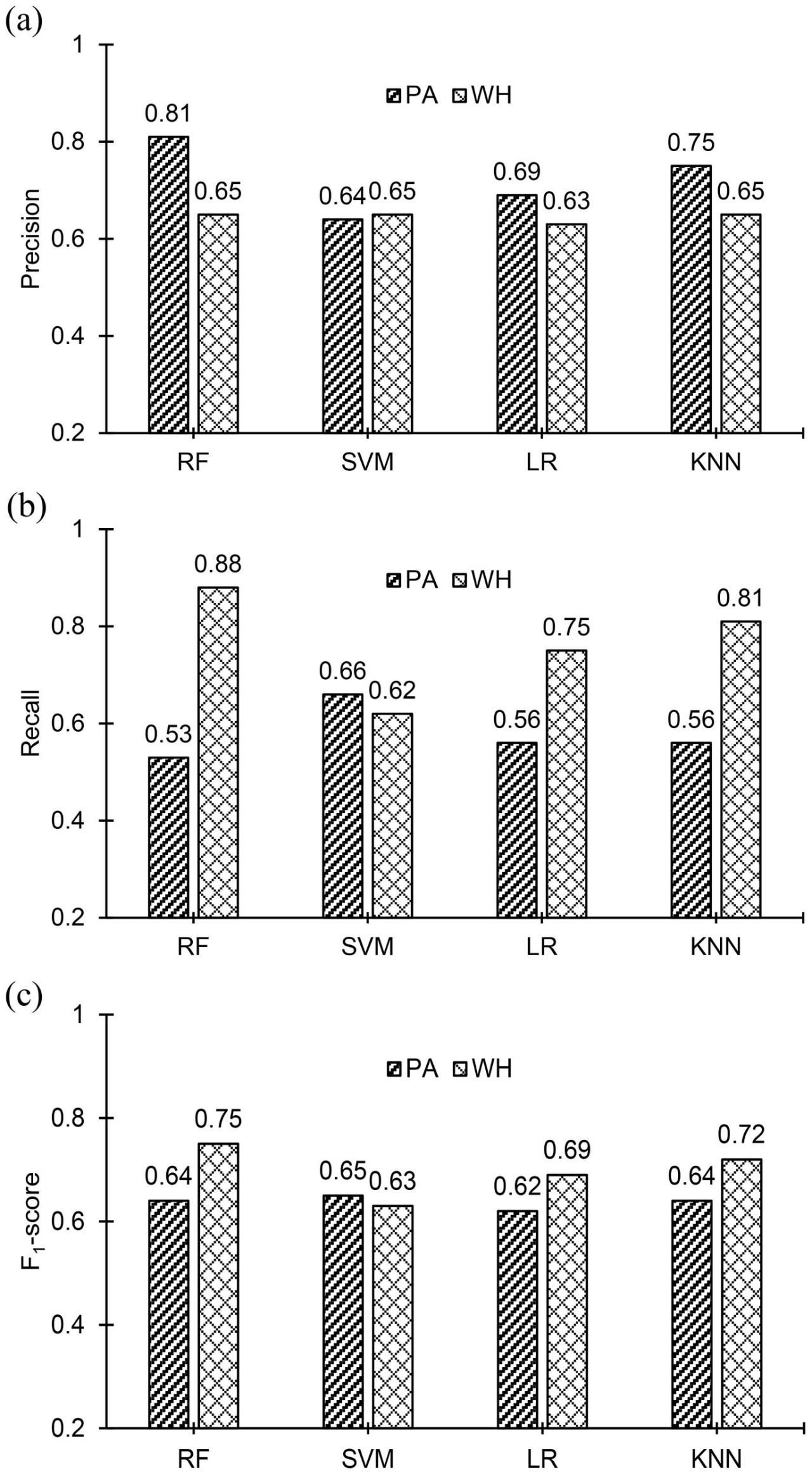
Рисунок 7 Сравнение (A) точности, (B) полноты и (C) F1-показателей для амаранта Палмера (PA) и щирицы водяной (WH) для использованных ML-моделей. Модель случайного леса имеет наивысшие значения точности как для PA, так и для WH. Наивысшее значение полноты PA и WH составляет 0,66 для модели SVM и 0,88 для модели случайного леса соответственно. F1-показатель PA почти одинаков для всех моделей, а наивысшее значение составляет 0,65 для SVM. Наивысший F1-показатель WH составляет 0,75 для модели случайного леса.
5 Классификация амаранта Палмера и щирицы водяной с использованием подхода глубокого обучения
Производительность ML-моделей, обсуждавшихся в предыдущем разделе (Раздел 5), ясно иллюстрирует неадекватность подхода ML для удовлетворительного различения амаранта Палмера и щирицы водяной. Более того, процесс ручного создания признаков, который включает извлечение морфологических характеристик и их преобразование для дальнейшей классификации ML-моделями, является трудоемким и отнимает много времени. В качестве альтернативы, амарант Палмера и щирица водяная могут быть классифицированы непосредственно по их изображениям с использованием сверточной нейронной сети (CNN), модели глубокого обучения, без необходимости извлечения их геометрических признаков листьев. Глубокое обучение, подмножество машинного обучения, предпочтительно, когда входные данные (изображения, тексты и другие медийные форматы) или взаимосвязь моделей слишком сложны для обработки стандартными подходами ML (Dargan и др., 2020).
5.1 Предыстория: Работа CNN
CNN — это искусственная нейронная сеть, широко используемая для задач, связанных с изображениями, в частности для классификации изображений. Стандартная CNN состоит из сверточных и объединяющих слоев в дополнение к полносвязным слоям. Сверточные и объединяющие слои образуют основу (нижние и промежуточные слои) сети CNN, а полносвязные слои образуют голову сети (верхние слои). Последний слой головы CNN — это выходной слой. Сверточные слои извлекают пространственно связанные признаки из входного изображения. Свертка включает матричные операции между входными данными и ядрами фильтров и приводит к картам признаков. Эти карты признаков дополнительно преобразуются с помощью функций активации для придания модели большей нелинейности. ReLU, tanH и eLU — некоторые часто используемые функции активации. Активированные карты признаков сверточного слоя или сверточного блока (стека сверточных слоев) обычно подвергаются объединению перед последующей сверткой. Объединение уменьшает пространственный размер свернутого признака путем объединения вывода группы нейронов одного слоя в один нейрон в следующем слое. Объединение бывает двух типов: максимальное объединение (max pooling) и среднее объединение (average pooling). Операция объединения включает скольжение окна по картам признаков и извлечение только наибольших (максимальное объединение) или средних (среднее объединение) значений карт признаков, ограниченных окном, как показано на Рисунке 8. Признаки высокого уровня, полученные в результате последовательных операций свертки и объединения, передаются дальше на полносвязный выходной слой. В случае классификации изображений для выходного слоя используется функция активации SoftMax для прогнозирования фактического вывода в one-hot кодировке, а для обучения модели используется функция кросс-энтропийных потерь. Пакетная нормализация и слои Dropout также используются в CNN для регуляризации (обобщения) сети. Слой пакетной нормализации нормализует входные пакеты промежуточных слоев (Bjorck и др., 2018), а слои Dropout блокируют заданную долю случайно выбранных нейронов от обучения (Baldi and Sadowski, 2013). Регуляризованная сеть демонстрирует сходные предсказательные показатели как для известных, так и для неизвестных данных.
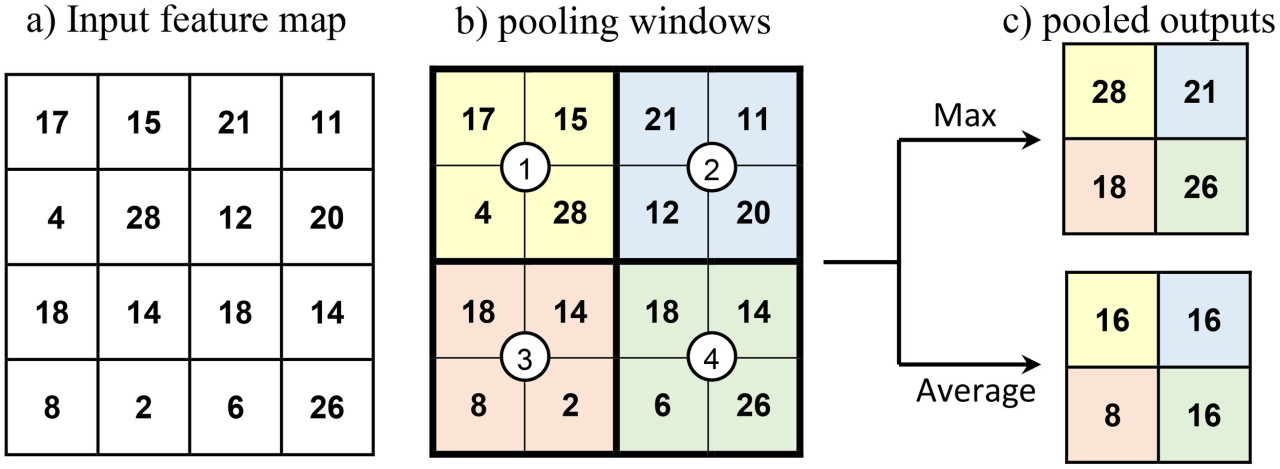
Рисунок 8 Иллюстрация операций объединения. (A) Карта признаков размером 4×4, подвергающаяся операциям объединения, (B) окно объединения размером 2×2 с шагом 2 перемещается по входным данным на каждом шаге, и обведенные кружком числа показывают положение шага центра окон объединения. Цветовые оттенки указывают области, участвующие в операции объединения на конкретном шаге, и (C) объединенные выходные данные входной карты признаков после максимального объединения и среднего объединения.
5.2 Подготовка набора данных для CNN
Набор данных изображений создан на основе полученных изображений амаранта Палмера и щирицы водяной для обучения и конфигурации модели CNN. Процесс получения данных изображений подробно описан в Разделе 3. Полученные изображения обрезаются и изменяют размер до 200×200 пикселей для получения более легкой модели (модели с меньшим количеством обучаемых сетевых параметров). Всего было получено 2000 изображений, по 1000 изображений для каждого вида сорняков. Однако, чтобы предотвратить переобучение модели, для каждого вида сорняков было добавлено 7000 изображений с помощью методов аугментации данных, которые включают изменение яркости, изменение контраста, преобразование в черно-белый формат, масштабирование и вращение исходных изображений. В Таблице 5 показано влияние каждого метода аугментации, использованного в этом анализе, на примере изображения. Окончательный обучающий набор данных состоит из 16 000 изображений размером 200×200 пикселей в двух классах (PA и WH) с 8000 изображений на класс. Окончательный аугментированный набор данных (D2) для этой задачи классификации состоит из массива изображений X2 ∈ Rⁿˣᴵˣᴵ и массива меток в one-hot кодировке Y2 ∈ Rⁿˣᶜ, где n — количество экземпляров изображений, I — размерность изображения, а c — количество классов, которые составляют 18 000, 200 и 2 соответственно для текущей задачи. Набор данных, используемый для обучения и тестирования, обозначен как D2,tn и D2,tt соответственно. Тестовый набор данных D2,tt состоит из 2000 экземпляров изображений, к которым добавлен гауссов шум интенсивностью 0,04. Это сделано для получения устойчивой модели, которая не приводит к значительной деградации производительности классификации для полевых изображений, загрязненных шумами. На Рисунке 9 показано примерное изображение с добавленным гауссовым шумом.

Таблица 5 Методы аугментации данных и их влияние на изображение.

Рисунок 9 (A) Предварительно обработанное изображение листвы сорняка, использованное в классификации глубокого обучения, и (B) то же изображение после добавления гауссова шума интенсивностью 0,04.
5.3 Обучение и конфигурация модели CNN (DL)
Модель CNN обучается и настраивается с использованием TensorFlow 2.6.2. Модель была подогнана к обучающему набору данных с использованием оптимизации ADAM (Kingma and Ba, 2014) со 100 эпохами. Было исследовано несколько конфигураций модели CNN путем увеличения количества фильтров и количества сверточных слоев для улучшения возможностей извлечения признаков. Кроме того, была протестирована пакетная нормализация для стабилизации и ускорения процесса обучения путем нормализации входных пакетов для промежуточных слоев. Для дальнейшего улучшения обобщающей способности модели мы исследовали значения dropout от 0,1 до 0,5. Основываясь на производительности классификации как на обучающем, так и на тестовом наборах данных, было выбрано значение dropout 0,2 как оптимальный баланс между недообучением и переобучением. Чтобы предотвратить переобучение и обеспечить наилучшее обобщение на неизвестные данные, были применены критерии ранней остановки. Это позволило модели остановить обучение, когда точность на тестовых данных начинала падать, эффективно выбирая модель с наилучшей обобщающей производительностью. Слои Dropout и ранняя остановка помогли гарантировать, что окончательная модель не переобучилась, достигая стабильной производительности классификации в обучающих и тестовых наборах данных. Архитектура окончательно настроенной модели CNN показана на Рисунке 10, а детали ее слоев суммированы в Таблице 6. Модель использовала активацию ReLU в сверточных слоях и SoftMax в выходном слое для классификации.
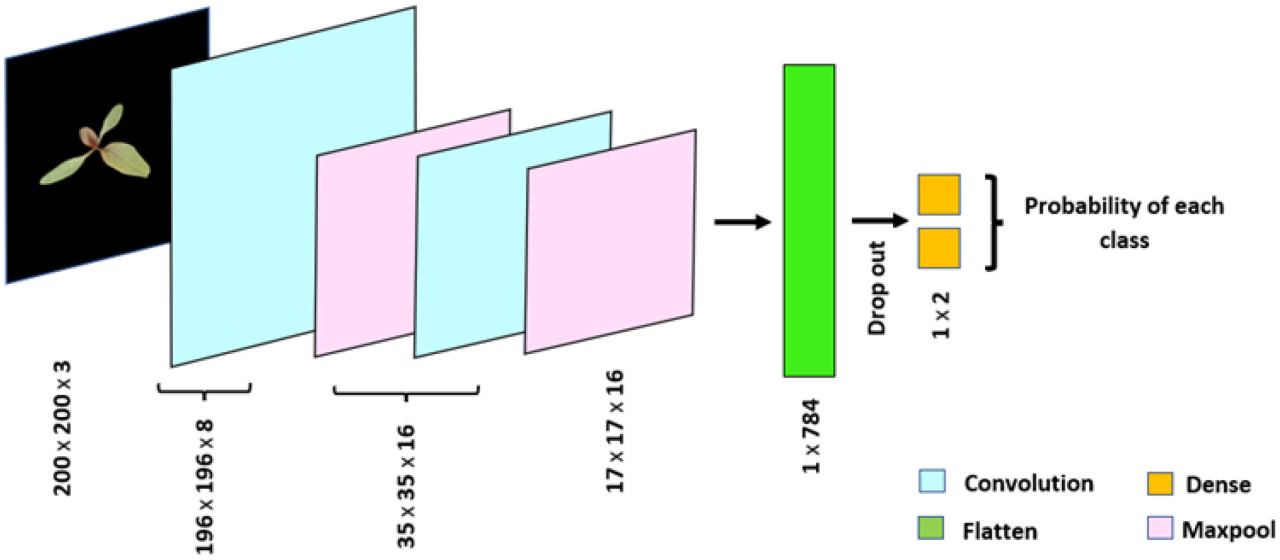
Рисунок 10 Архитектура сверточной нейронной сети, модели глубокого обучения, использованной в исследовании для классификации амаранта Палмера и щирицы водяной. Сеть состоит из 5 394 обучаемых параметров и достигла точности классификации 92,3% на тестовом наборе данных с добавленным гауссовым шумом.
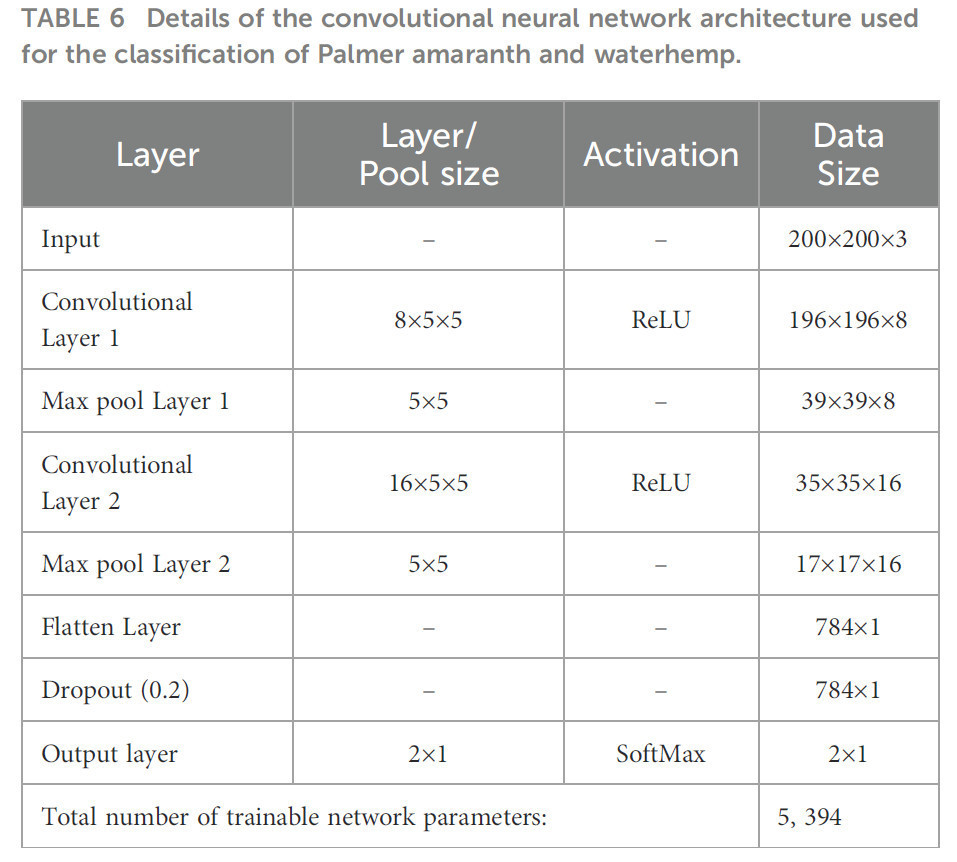
Таблица 6 Детали архитектуры сверточной нейронной сети, использованной для классификации амаранта Палмера и щирицы водяной.
5.4 Эффективность классификации CNN
Точности классификации 96,2% и 92,8% были получены для обучающего и тестового наборов данных соответственно с использованием настроенной модели. Небольшая положительная разница между точностями классификации обучающего (96,2%) и тестового (92,8%) наборов данных указывает на отсутствие значительного переобучения в модели, что свидетельствует о том, что модель хорошо обобщается на неизвестные данные. Небольшое расхождение может быть связано с включением зашумленных изображений в тестовый набор данных. Эти зашумленные изображения имитируют реальные условия и, естественно, делают классификацию более сложной, что может привести к незначительному снижению производительности по сравнению с более чистыми обучающими данными. Точность классификации (92,8%), полученная для модели CNN (модель глубокого обучения), значительно выше точности (70,3%) модели случайного леса (ML-модель). На Рисунке 11 показана матрица ошибок модели для тестовых данных вместе с матрицей ошибок модели случайного леса (лучшей ML-модели). Матрица ошибок показывает, что неточность модели в основном связана с неправильной классификацией 145 экземпляров изображений PA как WH. Соответственно, точность PA и полнота WH составляют 100%, в то время как точность WH и полнота PA составляют 87% и 85% соответственно. F1-показатели PA и WH почти равны и составляют примерно 92,5%. Показатели производительности по классам, а именно точность, полнота и F1-показатель модели CNN, сравниваются с показателями производительности модели случайного леса на Рисунке 12. Как видно на рисунках, показатели производительности по классам модели CNN также превосходят ML-модель.
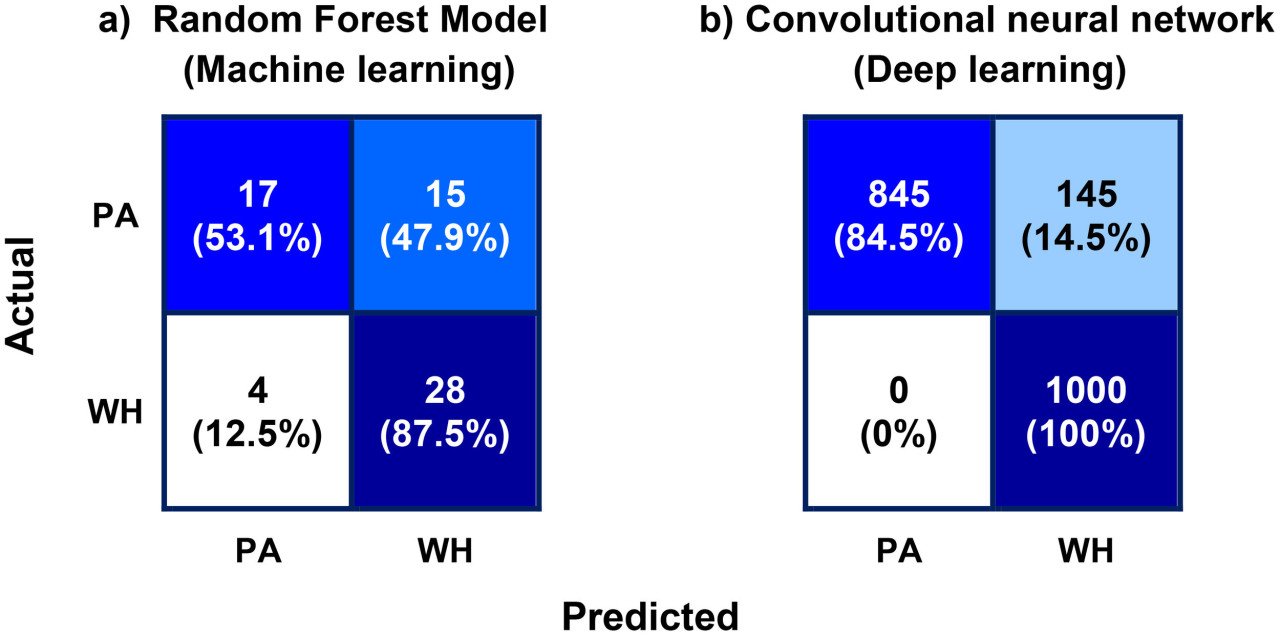
Рисунок 11 (A) Матрица ошибок наилучшей модели машинного обучения (модель случайного леса) и (B) матрица ошибок модели глубокого обучения (DL) (сверточная нейронная сеть, CNN). Каждая ячейка матриц ошибок показывает общее количество экземпляров (вверху) и процент экземпляров класса (внизу), которые относятся к соответствующим категориям ячеек. Неправильная классификация экземпляров амаранта Палмера (PA) как щирицы водяной (WH) значительно выше, чем неправильная классификация WH как PA, как в случае ML-модели, так и DL-модели.
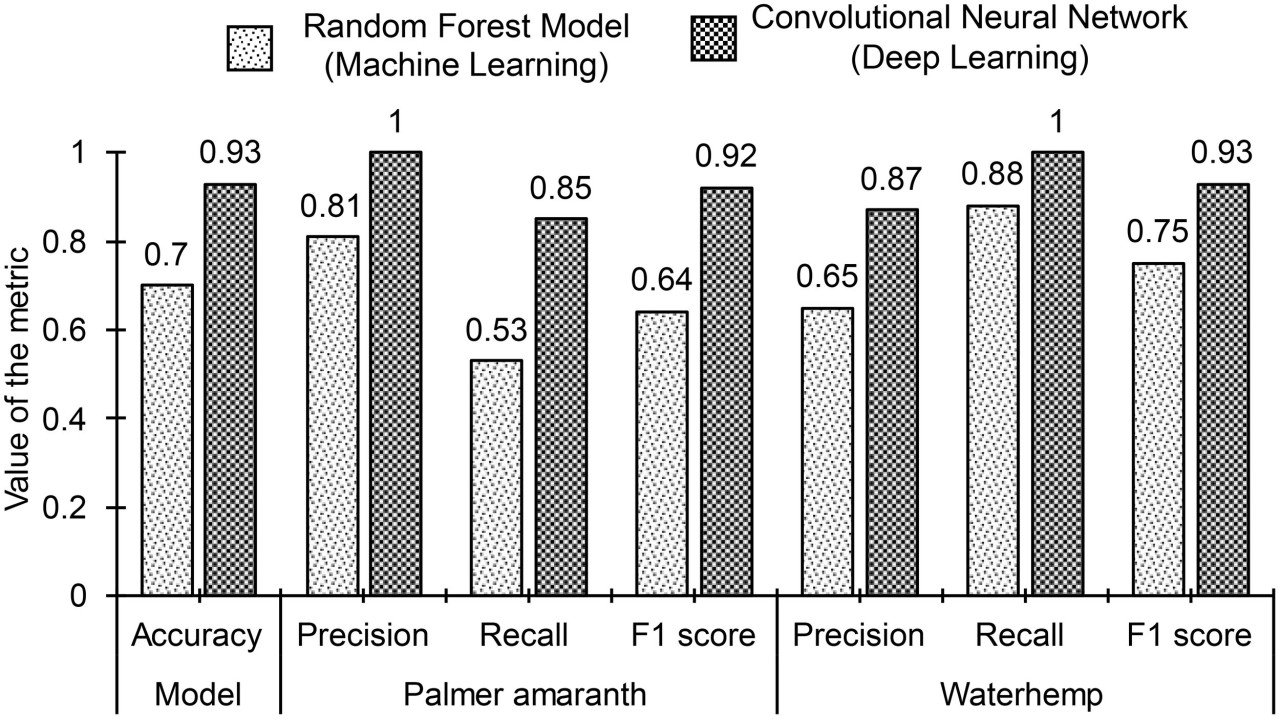
Рисунок 12 Сравнение производительности классификации наилучшей модели машинного обучения (модель случайного леса) и модели глубокого обучения (сверточная нейронная сеть). Модель глубокого обучения превосходит наилучшую модель машинного обучения по всем аспектам оценки производительности.
6 Мульти-объектная классификация смеси листвы сорняков с использованием трансферного обучения
В Разделе 6 была разработана высокоточная модель CNN для классификации амаранта Палмера и щирицы водяной. Хотя модель является точной, она может определить только то, принадлежит ли данное изображение амаранту Палмеру или щирице водяной, и требует входных изображений с одним объектом. Здесь один объект означает отдельную листву любого из сорняков. Однако идентификация этих двух видов сорняков в реальном времени будет включать полевые изображения, которые содержат случайную смесь листвы обоих видов сорняков. Таким образом, важно локализовать каждый объект (листву любого вида сорняков), что означает идентификацию отдельных объектов на изображении и их классификацию по одному из классов. Это обуславливает необходимость модели обнаружения объектов для точной локализации листвы сорняков.
6.1 Предыстория: обнаружение объектов (мульти-объектная классификация)
Обнаружение объектов — это метод компьютерного зрения, который локализует отдельные объекты путем рисования ограничивающих рамок вокруг объектов и их маркировки в соответствии с их классами (Zou и др., 2019). Процесс обнаружения объектов включает три этапа: 1. Выбор информативных областей, на котором входные изображения сканируются с помощью многошкального скользящего окна для поиска всех возможных областей объектов; 2. Выбор признаков, на котором извлекаются визуальные признаки объектов на изображении для распознавания объектов; и 3. Классификация, на которой каждый объект маркируется в соответствии с его классом. Обучение точной модели обнаружения объектов с нуля требует полностью аннотированного набора данных изображений большого размера, который включает различные комбинации отдельных объектов. Создание таких больших наборов данных обычно является дорогостоящим и нецелесообразным во многих случаях. Однако модели обнаружения объектов желаемой точности могут быть разработаны с использованием меньших наборов данных с помощью трансферного обучения (Jose и др., 2022). Трансферное обучение (Zhuang и др., 2021), метод ML, использует знания, полученные в другой, но сходной задаче, для улучшения обучения текущей задачи. Трансферное обучение формально определяется с использованием двух важных определений, а именно «домен» и «задача». Домен D характеризуется пространством признаков F и маргинальным распределением P(X), где X (∈ F) — данные признаков, а F охватывает все возможные данные признаков. Задача T характеризуется пространством меток L и условным распределением P(Y|X), где Y (∈ T) — данные меток, а L охватывает все возможные данные меток. Формально трансферное обучение сосредоточено на изучении задачи TT в целевом домене DT с использованием знаний о задаче TS, выполняемой в исходном домене DS. Индексы S и T обозначают исходный и целевой соответственно. Трансферное обучение для обнаружения объектов выполняется со следующими тремя шагами: 1. Идентификация хорошо обученной модели обнаружения объектов с пространством признаков, которое может разместить наши данные признаков (мульти-объектные изображения сорняков); 2. Модификация головы модели обнаружения объектов путем добавления нескольких обучаемых слоев, включая выходной слой, для изменения пространства меток; и 3. Тонкая настройка обучаемых слоев для выполнения целевой задачи (обнаружения видов сорняков).
6.2 Подготовка набора данных
Аннотированный набор данных изображений создан для тонкой настройки головы модели обнаружения объектов. Аннотация изображений, используемых в наборе данных, включает рисование ограничивающих рамок вокруг объектов (листвы сорняков) на изображениях и получение классов объектов, координат и размеров ограничивающих рамок. Всего 3200 изображений, по 1600 на каждый класс сорняков, использованы для обучающего набора данных, и аннотация этих изображений была выполнена с использованием инструмента с открытым исходным кодом под названием LabelImg. Все эти изображения содержат только один объект (листву любого из классов сорняков). Таким образом, обучающий набор данных D3,tn, созданный для задачи обнаружения объектов, состоит из массива изображений X3,tn ∈ Rⁿˣᴵˣᴵ и массива аннотаций Y3,tn ∈ Rⁿˣᵖ. Здесь n, количество экземпляров, равно 3 200, а p, количество столбцов аннотаций, равно 5. k-я строка массива аннотаций определяется как yₖ = (l, x, y, b, h), где l — метка объекта, x и y — координаты ограничивающей рамки, а b и h — ширина и высота ограничивающей рамки соответственно. Для тестирования производительности обученной модели обнаружения объектов был создан тестовый набор данных D3,tn, состоящий из 12 мульти-объектных (более одного объекта на изображении) изображений размером 4 000 × 4 000 пикселей. Мульти-объектные изображения были созданы путем составления коллажей из 10–12 листьев амаранта Палмера и щирицы водяной на черном фоне. Листья сорняков были случайным образом выбраны из 132 изображений сорняков (по 61 на каждый класс), которые не входили в D3,tn. Для имитации полевых условий листья сорняков на мульти-объектном изображении были выбраны разного возраста и произвольно разбросаны как на близком, так и на дальнем расстоянии друг от друга. На Рисунке 13 показаны два примера мульти-объектных изображений, созданных для тестирования модели обнаружения объектов, а на Рисунке 14 показаны маркированные выходные изображения обученной модели обнаружения объектов для примеров изображений, показанных на Рисунке 13. Ограничивающие рамки красного цвета представляют класс амаранта Палмера, а розовые ограничивающие рамки представляют класс щирицы водяной.

Рисунок 13 Мульти-объектные изображения, разработанные для обучения модели обнаружения объектов. Эти изображения созданы путем распределения отдельных листьев (A) амаранта Палмера и (B) щирицы водяной на черном фоне.

Рисунок 14 Мульти-объектные изображения с предсказанными метками классов и оценками достоверности с помощью тонко настроенной модели YOLOv5. Красные и розовые ограничивающие рамки обозначают (A) амарант Палмера и (B) щирицу водяную соответственно.
6.3 Конфигурация модели обнаружения объектов
В этом исследовании современная модель обнаружения объектов YOLOv5, предварительно обученная на наборе данных COCO, используется для обнаружения сорняков. YOLOv5 (акроним от You Only Look Once) — это мощный одностадийный детектор объектов, который обнаруживает объекты, присутствующие на изображении, за один проход. Одностадийные детекторы объектов, хотя и несколько менее точны, являются более быстрыми, чем двухстадийные детекторы объектов. Одностадийные детекторы объектов делают прогнозы непосредственно на основе сгенерированных карт признаков, в то время как двухстадийные детекторы используют сеть предложения регионов для обработки карт признаков и прогнозирования на предложенных регионах. Модель YOLOv5 состоит из трех сетевых компонентов: основы, горловины и головы. Основа YOLOv5 использует сеть частичных кросс-стадийных (CSP) для извлечения богатых информацией признаков из изображения. Она также уменьшает разрешение изображения и улучшает его разрешение признаков. Горловина состоит из сети пространственного пирамидного пулинга (SPP) и сети агрегации путей (PANet) и отвечает за построение пирамид признаков. Пирамиды признаков важны для инвариантности к масштабу и обобщающей способности модели обнаружения объектов. Наконец, голова, которая состоит из трех сверточных слоев, предсказывает расположение и размер ограничивающих рамок, оценки объектов и классы объектов. Более подробно о YOLOv5 можно прочитать в другом месте (Thuan, 2021). Набор данных COCO (Lin и др., 2014), использованный для предварительного обучения YOLOv5, состоит из 330 000 изображений 80 различных общих категорий объектов (собака, кошка, лодка, самолет, растения и так далее). Последние три сверточных слоя YOLOv5 настроены для маркировки объекта на два класса сорняков: PA и WH.
6.4 Эффективность модели обнаружения объектов (мульти-объектная классификация)
Результаты модели обнаружения объектов, полученные для 12 тестовых изображений, суммированы в Таблице 7. На Рисунках 15, 16 показано графическое сравнение точностей классификации PA, WH и обоих PA и WH для тестовых изображений. Как видно на Рисунке 15, 75% тестовых изображений предсказаны с точностями обнаружения объектов 80% и выше, а средняя точность обнаружения объектов модели составляет 84,8% со стандартной ошибкой 3,53% (см. Рисунок 17). Из этих результатов видно, что модель достигает стабильно хороших точностей для большинства тестовых изображений. Средние точности модели для амаранта Палмера и щирицы водяной составляют 85,3% и 82,8% соответственно, а стандартные ошибки составляют 2,95% и 5,63% соответственно. Это показывает, что модель идентифицирует амарант Палмера более точно и стабильно, чем щирицу водяную. Однако модель в целом продемонстрировала удовлетворительную производительность в идентификации листвы сорняков независимо от их возраста и близости друг к другу и, таким образом, будет полезной моделью в реальных полевых условиях.
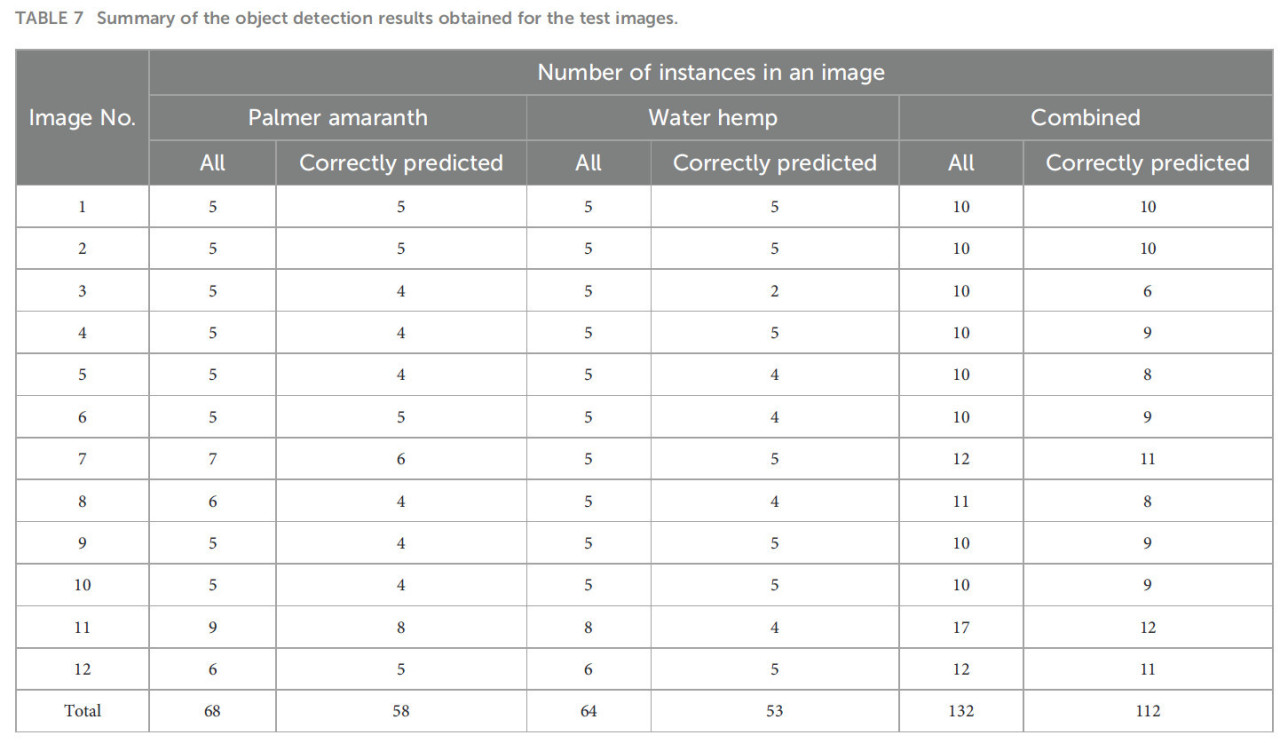
Таблица 7 Сводка результатов обнаружения объектов, полученных для тестовых изображений.
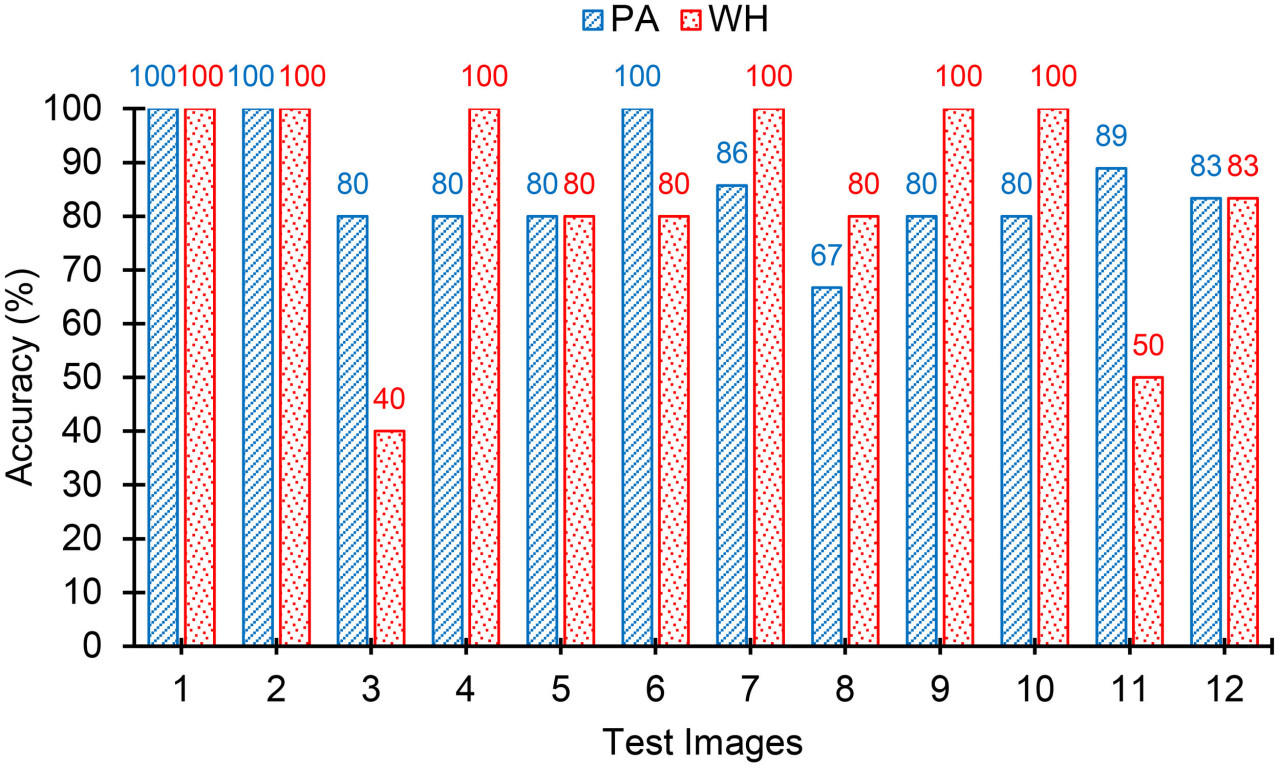
Рисунок 15 Сводка точностей обнаружения объектов для тестовых изображений для амаранта Палмера (PA) и щирицы водяной (WH). Точности как для PA, так и для WH выше 80% для большинства изображений.
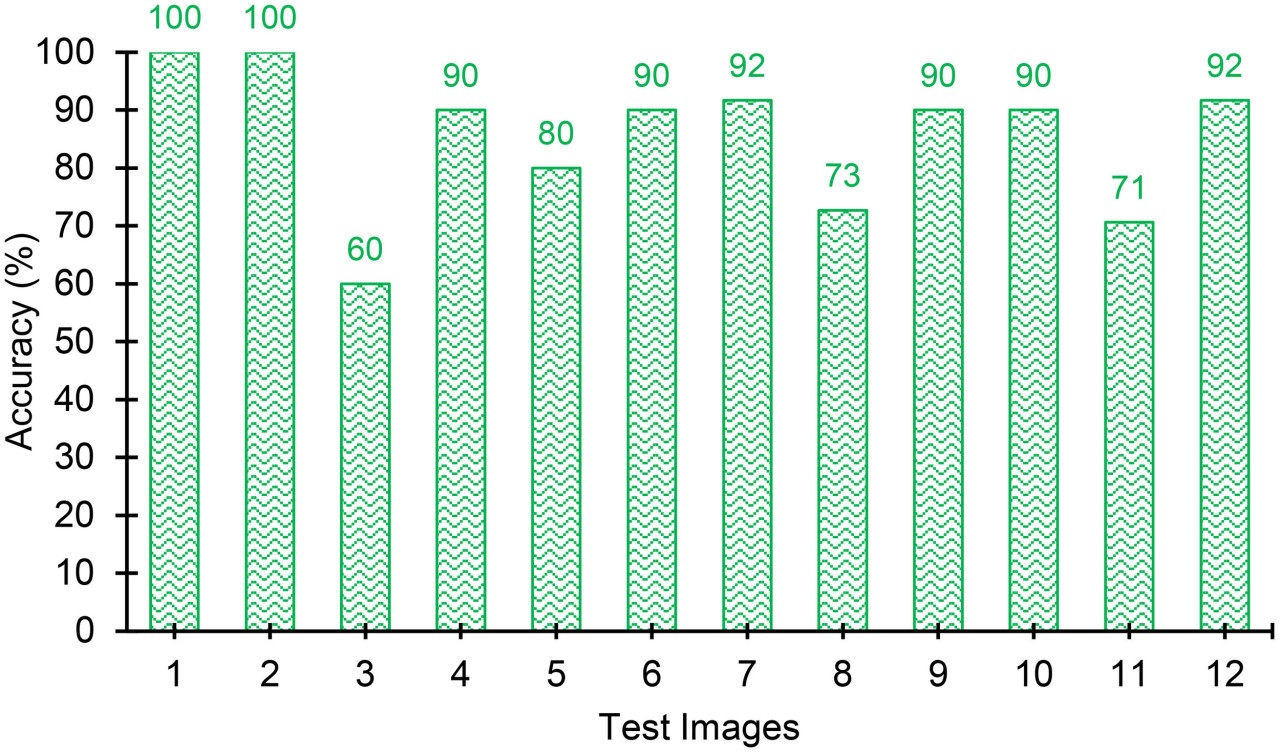
Рисунок 16 Совокупные точности (включая как амарант Палмера, так и щирицу водяную) для тестовых изображений. Модель достигает стабильно хороших точностей для большинства тестовых изображений.
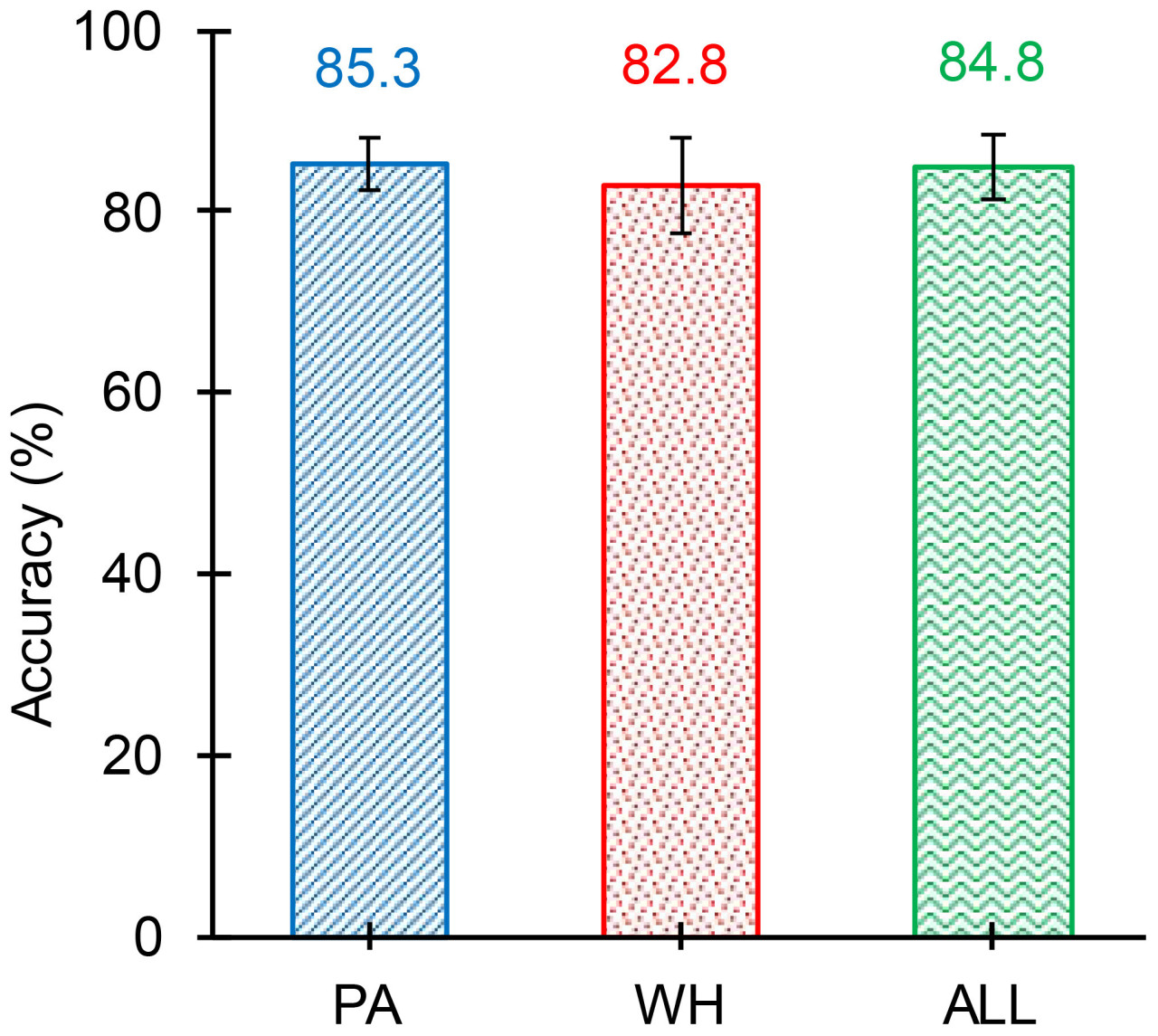
Рисунок 17 Средняя точность обнаружения объектов (усредненная по всем тестовым изображениям) модели для амаранта Палмера (PA), щирицы водяной (WH) и обоих PA и WH (ALL). Средняя точность WH немного ниже, чем PA, однако наблюдаемая разница незначительна. Изменчивость WH (стандартная ошибка — 5,63) больше, чем изменчивость PA (стандартная ошибка — 2,95). Общая точность обнаружения объектов модели составляет 84,8% со стандартной ошибкой 3,43%.
7 Выводы
Цель текущего исследования — автоматизировать обнаружение амаранта Палмера и щирицы водяной на ранних стадиях роста (в течение двух недель роста после прорастания). Для этого были использованы три различных подхода ИИ, а именно машинное обучение, глубокое обучение и обнаружение объектов, для обнаружения сорняков. Результаты и выводы, сделанные на основе анализа, проведенного в исследовании, и внедрения этих подходов, суммированы ниже:
1. Безразмерные параметры листа, такие как соотношение сторон, циркулярность и округлость, обычно используемые для дифференциации полностью выросших амаранта Палмера и щирицы водяной, могут быть измерены только на второй неделе после появления всходов (день 8 – день 14) из-за отсутствия видимого роста на первой неделе. Распределение этих безразмерных параметров амаранта Палмера и щирицы водяной на второй неделе роста продемонстрировало значительное и сложное перекрытие между ними.
2. Четыре лучшие ML-модели, а именно случайный лес, SVM, логистическая регрессия и KNN, были использованы для классификации амаранта Палмера и щирицы водяной. Случайный лес, являясь наилучшей ML-моделью, достиг точности классификации 70%. F1-показатели амаранта Палмера и щирицы водяной для модели случайного леса составили 0,64 и 0,75 соответственно. Хотя производительность классификации подхода ML не является удовлетворительной, ML-модели включали только небольшой объем данных (312 экземпляров данных с 156 экземплярами данных на класс) для обучения модели. Однако извлечение безразмерных признаков для такого небольшого объема данных является трудоемким и требует ручного вмешательства.
3. Сверточная нейронная сеть, использованная в качестве модели глубокого обучения, обеспечила хорошую точность классификации 93,2%. F1-показатели амаранта Палмера и щирицы водяной для модели случайного леса составили 0,92 и 0,93 соответственно. Подход глубокого обучения потребовал большего объема данных по сравнению с подходом ML, поэтому исходный размер данных 4000 (2000 экземпляров изображений на класс) был увеличен до 16 000 (8000 экземпляров изображений на класс) с использованием методов аугментации данных. Хотя подход DL является интенсивным к данным, он показал значительно лучшие результаты, чем наилучшая ML-модель.
4. Модель обнаружения объектов для локализованной идентификации сорняков на изображениях, смешанных с листвой амаранта Палмера и щирицы водяной, была разработана с использованием трансферного обучения. Путем тонкой настройки головы YOLOv5 (верхних 3 сверточных слоев), обученной на наборе данных COCO, была достигнута средняя точность обнаружения объектов 83,5%. Для тонкой настройки было использовано всего 3200 однообъектных изображений (изображения с отдельной листвой либо амаранта Палмера, либо щирицы водяной). Разработанная модель обнаружения объектов может идентифицировать листву сорняков независимо от их возраста и близости друг к другу и, таким образом, будет полезной моделью в реальных полевых условиях.
8 Ограничения и будущие исследования
Изображения, использованные для классификации и идентификации амаранта Палмера и щирицы водяной, были получены в лабораторных условиях с контролируемыми условиями освещения и на простом фоне. Эффективность этих автоматизированных подходов для изображений, полученных при различных углах падения света, с включениями растений и других посторонних признаков, различных экологических условиях и различных условиях освещения, необходимо изучить, поскольку на производительность моделей машинного обучения и глубокого обучения влиял процесс получения изображений. Хотя очевидно, что раннее распознавание амаранта Палмера и щирицы водяной является ценным для управления сорняками и, следовательно, для повышения урожайности, анализ затрат, количественно оценивающий финансовые последствия, будет полезен для сельскохозяйственного сообщества. В настоящее время исследование различает амарант Палмера и щирицу водяную, но оно может быть расширено для различения амаранта Палмера и других видов щирицы, а именно щирицы краснокорневой (Amaranthus retroflexus), щирицы гибридной (Amaranthus hybridus) и щирицы Пауэлла (Amaranthus powellii).



Venkataraju A, Arumugam D, Kiran R and Peters T (2024) Automated approaches for the early stage distinguishing of Palmer amaranth from waterhemp. Front. Agron.6:1425425. doi:10.3389/fagro.2024.1425425
Перевод статьи «Automated approaches for the early stage distinguishing of Palmer amaranth from waterhemp» авторов Venkataraju A, Arumugam D, Kiran R and Peters T., оригинал доступен по ссылке. Лицензия: CCBY. Изменения: переведено на русский язык
Фото: амарант Палмера



















































































































Комментарии (0)